Распознаем текст онлайн с картинок, отсканированных документов бесплатно и без регистрации
Содержание:
- Microsoft OneNote
- Особенности работы сервисов для распознавания текста с картинки
- Распознавание текста онлайн без регистрации
- Тессеракт
- Как извлечь текст из изображений с помощью ABBY FineReader
- Веб-приложение Free-OCR
- Особенности OCR в DocuFreezer
- Adobe Reader скачать
- Abbyy Screenshot Reader
- Сервисы бесплатного распознавания текста с фото онлайн
- ABBYY FineReader
- ABBYY FineReader
Microsoft OneNote
OneNote – это впечатляющее многофункциональное приложение для создания заметок, с которым легко начать работу. Тем не менее, заметки не единственное, в чем они хороши. Если вы используете OneNote как часть вашего рабочего процесса, вы можете использовать его для основное извлечение текстаБлагодаря доброте OCR, встроенной в него.
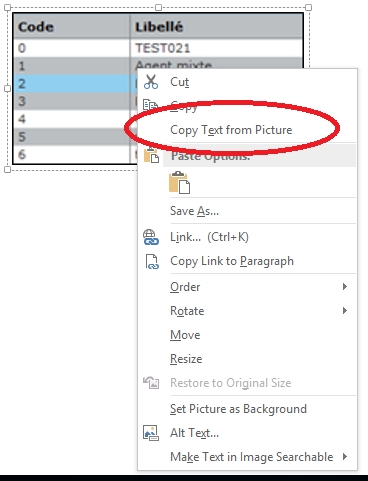
Использование OneNote для извлечения текста из изображений смехотворно просто. Если вы используете настольное приложение, все, что вам нужно сделать, это использовать Вставить Возможность добавить изображение в любой из блокнотов или разделов. Как только это будет сделано, просто щелкните правой кнопкой мыши на изображение и выберите Копировать текст с картинки вариант. Весь текстовый контент с изображения будет скопирован в буфер обмена и может быть вставлен (и, следовательно, отредактирован) куда угодно, согласно требованию. Будь то PNG, JPG, BMP или TIFF, OneNote поддерживает практически все основные форматы изображений.
Однако возможности OneNote по извлечению текста весьма ограничены, и он не может работать с изображениями, имеющими сложные макеты текстового содержимого, такие как таблицы и подразделы. Так что это то, что вы должны иметь в виду.
Доступность платформы: Windows и macOS
Цена: Свободно
Особенности работы сервисов для распознавания текста с картинки
В сети присутствует достаточное количество сервисов, позволяющих прочитать надпись с изображения online. Обычно в их названии (или описании) упоминается аббревиатура «OCR» (Optical Recognition Technology – Технология оптического распознавания).
В большинстве своём такие сервисы имеют условно-бесплатный характер, по которому бесплатное идентифицирование текста доступно объёмом до 10 страниц (изображений). Если же пользователь желает распознать текст большего объёма, сервис потребует приобрести платный функционал.
Качество распознавания русскоязычного текста зависит от качества источника, и варьируется от хорошего к среднему. Высоким уровнем распознавания могут похвастаться лишь несколько источников (к примеру, Гугл Диск), другие альтернативы распознают текст довольно посредственно.
Принцип работы с такими ресурсами довольно прост:
- Вы выполняете переход на такой сайт, загружаете на него картинку (или нужный pdf-файл).
- Выбираете язык обработки.
- Жмёте на кнопку активации распознавания.
- Через некоторое время, зависящее от объёма файла и скорости работы ресурса, вы получите возможность скачать полученный результат на ПК.
Полученный текст рекомендуется вычитать, дабы избавиться от допущенных сервисами огрехов. Давайте рассмотрим список инструментов, позволяющих определить содержание текста с любой картинки в режиме онлайн.
Распознавание текста онлайн без регистрации
Online OCR
Online OCR http://www.onlineocr.net/ – единственный наряду с Abbyy Finereader сервис, который позволяет сохранять в выходном формате картинки вместе с текстом. Вот как выглядит распознанный вариант с выходным форматом Word:
 Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG, GIF |
| Выходные форматы | Word, Excel, Adobe PDF, Text Plain |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Распознает не более 15 картинок в час без регистрации |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Abbyy Finereader – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
Как пользоваться
- Загрузите файл (щелкните «Select File»)
- Выберите язык и выходной формат
- Введите капчу и щелкните «Convert»
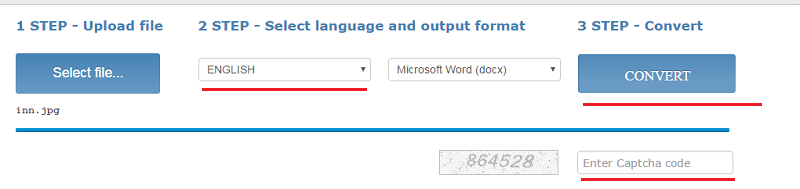
Внизу появится ссылка на выходной файл (текст с картинками) и окно с текстовым содержимым
Free Online OCR
Free Online OCR https://www.newocr.com/ позволяет выделить часть изображения. Выдает результат в текстовом формате (картинки не сохраняются).
| Входные форматы | PDF, DjVu JPEG, PNG, GIF, BMP, TIFF |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Ограничения на количество нет |
| Качество | Качество распознавания свидетельства инн плохое. |
Как пользоваться
- Выберите файл или вставьте url файла и щелкните «Preview» – картинка загрузится и появится в окне браузера
- Выберите область сканирования (можно оставить целиком как есть)
- Выберите языки, на которых написан текст на картинке и щелкните кнопку «OCR»
- Внизу появится окно с текстом
OCR Convert
OCR Convert http://www.ocrconvert.com/ txt
| Входные форматы | Многостраничные PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 5Мб общий размер файлов за один раз. |
| Ограничения | Одновременно до 5 файлов. Сколько угодно раз. |
| Качество | Качество распознавания свидетельства инн среднее. (ФИО распознано частично). Лучше, чем Google, хуже, чем Finereader |
Как пользоваться
-
-
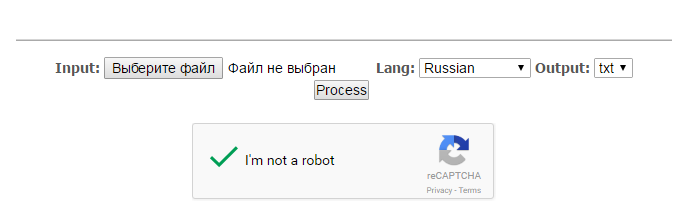
- Загрузите файл, выберите язык и щелкните кнопку «Process»
-
-
-
- Появится ссылка на файл с распознанным текстом
-

Free OCR
Free OCR www.free-ocr.com распознал документ хуже всех.
| Входные форматы | PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 6Мб |
| Ограничения | У PDF-файла распознается только первая страница |
| Качество | Качество распознавания свидетельства инн низкое – правильно распознано только три слова. |
Как пользоваться
-
-
- Выберите файл
- Выберите языки на картинке
- Щелкните кнопку “Start”
-

I2OCR
I2OCR http://www.i2ocr.com/ неплохой сервис со средним качеством выходного файла. Отличается приятным дизайном, отсутствием ограничений на количество распознаваемых картинок. Но временами зависает.
| Входные форматы | JPG, PNG, BMP, TIF, PBM, PGM, PPM |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 10Мб |
| Ограничения | нет |
| Качество | Качество распознавания свидетельства инн среднее – сравнимо с OCR Convert.
Замечено, что сервис временами не работает. |
Как пользоваться
- Выберите язык
- Загрузите файл
- Введите капчу
- Щелкните кнопку «Extract text»
- По кнопке «Download» можно загрузить выходной файл в нужном формате
Тессеракт
Тессеракт, пожалуй, самое мощное и передовое программное обеспечение для распознавания текста в этом списке, и я скажу вам почему. Прежде всего, немного истории. Он был разработан HP в 1994 году, но вскоре компания выпустила его под лицензией Apache для разработки с открытым исходным кодом. В 2006 году Google принял проект и спонсировал разработчиков для работы над Tesseract. Перенесемся вперед, и Tesseract стал самым мощным Механизм распознавания текста, который использует Deep Learning для извлечения текстов из изображений (BMP, PNG, JPEG, TIFF и т. Д.) И файлов PDF., Существует множество онлайн-сервисов, которые используют OCR API Tesseract для распознавания и преобразования больших массивов изображений и файлов PDF. И самое приятное, что он доступен для всех основных операционных систем, включая Windows, macOS и Linux. Не говоря уже о том, что в отличие от ABBYY и Adobe, Tesseract и вы можете использовать его для преобразования тысяч изображений в текст, не платя ни копейки.

Тем не менее, есть одна небольшая проблема. Tesseract не предлагает интерфейс с графическим интерфейсом. Вам придется использовать механизм OCR в командной строке, который не является чашкой чая для всех. Чтобы решить эту проблему, разработчики создали клиенты с графическим интерфейсом использование исходного кода Tesseract для различных операционных систем. Я протестировал несколько из них и отсортировал лучшие клиенты Tesseract GUI для различных операционных систем. Если вы хотите быстро преобразовать изображения или PDF-файлы в редактируемый текст, используйте OCR Space (ссылка ниже) в веб-браузере. Это очень быстро и делает отличную работу. Если вы на Windows тогда используйте gImageReader; для Linux используйте OCRFeeder, а для macOS – PDF OCR X. Это все, но если вы хотите самостоятельно протестировать больше клиентов с графическим интерфейсом, перейдите к этому ссылка на сайт, Кроме того, если у вас есть опыт, то вы, конечно, можете использовать Tesseract в командной строке.
Доступность платформы: Интернет, Windows, macOS и Linux
Цена: Свободно
Скачать: Веб-браузер, Windows, Macos, Linux, Командная строка
Как извлечь текст из изображений с помощью ABBY FineReader
Существует две версии этой программы. Одна работает в автоматическом режиме онлайн, другая же — десктопная, ее придется скачать и установить на компьютер. Обе — платные. Однако в онлайн-версии можно бесплатно распознать текст с не более 5 страниц, а в установленной программе первое время действует пробный бесплатный период. На сегодня это один из лучших инструментов для распознавания текста с картинки.
Онлайн версия
-
Шаг 1. Перейдите на сайт FineReader.
- Шаг 2. Загрузите изображение. Выберите нужный вам язык и нажмите на кнопку регистрации. Следуйте указаниям на сайте. Как только вы зарегистрируетесь, сайт перенаправит вас на другую страницу. Нажмите на кнопку «Распознать» и дождитесь окончания процесса.
 Загружаем файл, выбираем язык, выбираем формат сохранения
Загружаем файл, выбираем язык, выбираем формат сохранения
Текст сохранится в формате docs. Скачайте его.
Десктопная версия
- Шаг 1. Запустите FreeReader и нажмите «Сканировать изображение», чтобы выбрать файл, содержащий текст. Он загрузится в программу, при необходимости их можно отредактировать, чтобы улучшить распознаваемость текста. Программа предложит вам выделить область, текст с которой нужно распознать.
-
Шаг 2. Извлечение текста. Нажмите «Распознать», чтобы извлечь текст из выделения. Выбранный текст будет отображаться в текстовом окне через несколько секунд.
Шаг 3. Проверка. В этой программе есть функция проверки. Нажав на эту кнопку, пользователь на экране будет видеть некорректно распознанные слова и фрагмент оригинала. На этом этапе можно быстро исправить практически все ошибки программы.
Шаг 4. Сохраните текст любым из предложенных способов.
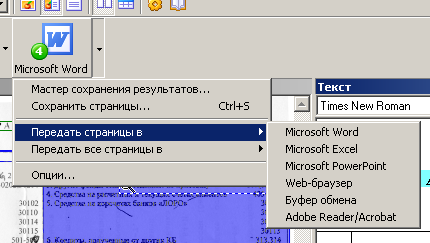 Сохраняем текст
Сохраняем текст
Обратите внимание:
- Во-первых, вам нужно убедиться, что исходное изображение четкое, хорошего качества.
- Во-вторых, выбор правильного механизма OCR важен, и вам нужно учитывать их сильные и слабые стороны.
- В-третьих, убедитесь, что ваши изображения масштабированы до нужного размера (не менее 300 DPI).
- Низкая контрастность приведет к плохому OCR, поэтому вам необходимо исправить это до распознавания.
- Удалите шумы и дефекты.
- Если изображение перекошено, отредактируйте его.
Веб-приложение Free-OCR
Главное преимущество данного сервиса – возможность работы практически со всеми форматами картинок.
К примеру, большинство сервисов распознавания текста не поддерживают такие форматы, как gif, bmp или tif.
Внешний вид сайта очень простой, таким образом каждый пользователь сможет справиться с поставленной задачей.

Внешний вид веб-приложения
Удобнее всего переводить текст в Word, ведь данная программа способна отобразить огромное количество различных текстовых кодировок, а также элементы дизайна входящего файла.
Данный сервис является абсолютно бесплатным и не требует пользовательской регистрации.
Единственное ограничение — размер входящего файла должен быть меньше, чем 6 мегабайт, поэтому распознавать большие документы с помощью данной программы не получиться.
Самое точное направление распознавания – с формата JPEG в ворд.
Тематические видеоролики:
Онлайн распознавание текста — ТОП-3 сервиса
Онлайн распознавание текста — ТОП-3 сервиса
Как распознать текст с картинки онлайн — Google Диск
Как распознать текст с картинки, фотографии или PDF документа онлайн, бесплатно с помощью Google Диска или Документов Гугл
8 Рейтинг
Краткий обзор
Весьма простые сервисы для онлайн-распознавания текста с изображений. На их освоение даже не нужно время, ведь там все элементарно и просто. Огромным плюсом является отсутствие необходимости вкладывать в работу с этими сервисами деньги.
Сложность использования
7
Время на освоение
7
Стоимость
10
Особенности OCR в DocuFreezer
Распознавание текста происходит автоматически, прямо во время групповой конвертации добавленных файлов. Ниже представлены некоторые особенности встроенной функции OCR в DocuFreezer.
|
Поддерживаемые входные типы файлов |
Поддерживаемые выходные типы файлов |
|
|
|
Поддерживаемые языки |
Поддерживаемые виды документов |
|
|
Как указано выше, на выходе вы получите простой текст TXT или PDF с возможностью поиска текста. Чтобы найти и выделить нужный текст в получившемся PDF-файле, достаточно открыть документ, нажать комбинацию клавиш Ctrl + F и ввести нужные слова или символы. Также текст внутри PDF-а можно будет выделять мышкой и копировать.
Adobe Reader скачать
Популярный просмотрщик всех видов PDF-файлов с базовыми функциями работы с документацией. Позволяет просматривать, копировать, менять ориентацию или отправлять на печать документы. Для слабовидящих юзеров доступна опция масштабирования, увеличивающая размер шрифта до нужных параметров. Также можно воспользоваться функцией трёхмерного изображения и воспроизведения интегрированных в мультимедийный контент объектов. Доступен поиск в PDF картах, портфолио и файлах, а также комментирование файлов, присоединение электронных подписей и настройка плагинов для веб-навигаторов. Из минусов бесплатной версии отметим ограниченный только просмотром функционал.
Abbyy Screenshot Reader

<Рис. 7 Abbyy Screenshot Reader>
Abbyy Screenshot Reader – специфическая программа от того же разработчика, что и первый софт в ТОПе.
Она довольно необычна и предназначена для работы не со сканированным или сфотографированным текстом, а именно со скриншотами экрана, что очень удобно, когда требуется работать с текстом, защищенным от копирования.
В связи с этим базовый функционал программы несколько необычен.
Она не способна сканировать, а также плохо работает с изображениями низкого качества, но может осуществлять перевод и проверку орфографии. Не предназначена для работы с рукописным текстом, но при наличии небольших его фрагментов вполне способна распознать его. Распространяется платно, но имеет бесплатный пробный период.
Позитив:
- Качественная работа со скриншотами любого разрешения;
- Наличие встроенного переводчика и проверка орфографии;
- Высокое качество распознавания.
Негатив:
- Очень узкую специализированность;
- Не всегда качественное распознавание шрифтов и структур;
- Платное распространение, хотя есть бесплатный пробный период на 2 недели.
https://youtube.com/watch?v=svcgCNzgyEw
Сервисы бесплатного распознавания текста с фото онлайн
Хочу заменить, что качество, получаемое при считывании текста с картинки, зависит от следующих факторов:
- качества исходника;
- размера элементов и четкости символов на отсканированном материале;
- формата файла.
Вашему вниманию представляю подборку сервисов, позволяющих преобразовать картинку в текст онлайн. Большинство из них бесплатные, а об имеющихся ограничениях, я упомяну в отдельной таблице. Большинство сайтов на английском языке.
Сравнение онлайн распознавателей текста с фото или PDF смотрите в таблице ниже:

Сервис от Гугл
Чтобы перевести с текст с фото в ворд понадобится электронная почта gmail. С ее помощью вы получите доступ ко многим сервисам от Google. Ограничений по количеству файлов нет, как и по их объему.

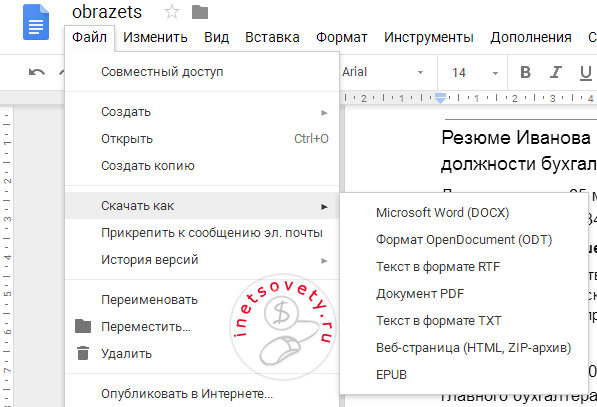
После этого кликаете по нему правой кнопкой и выбираете в меню открыть с помощью “Google Документы”:

Результат перевода текста с картинки в ворд будет помещен в Google Документы и откроется на соседней вкладке. Далее вы можете его там редактировать или скопировать на компьютер в одном из форматов:
Abbyy Finereader Online
Это онлайн распознаватель текста с pdf или изображения в word, аналог одноименной программы для ПК. Файн ридер онлайн позволяет бесплатно распознать до 5 страниц в месяц и то только после регистрации. Плюс бонусом предоставляется 10 страниц после подтверждения имейла. Стоимость платного пакета услуг — 129 € / год на 5000 страниц.
Как использовать сервис показано на скрине — всего 5 шагов к получению текста с фото или pdf в ворд онлайн:

Ссылка для перехода finereaderonline.com
Online OCR
Отличный сервис распознавания текста с фото или из pdf с приемлемыми ограничениями в формате гостевого доступа, т.е. без регистрации на сайте. Позволяет произвести преобразование картинки в текст онлайн в количестве до 15 штук в час или 15 страниц в многостраничном PDF файле
Обратите внимание, что для работы с PDF документами понадобится регистрация
Ссылка на сам сервис OnlineOCR.net
Как вытащить текст из картинки в word этим сервисом смотрите ниже на скрине:

Отличительная особенность — в получаемых результатах изображения сохраняются с текстом. В других сервисах, что будут описаны ниже такого нет.
Free Online OCR
Довольно неплохой бесплатный и не имеющий ограничений по количеству файлов переводчик текста с картинки онлайн. Один его недостаток — сохранение результата без изображений с источника.
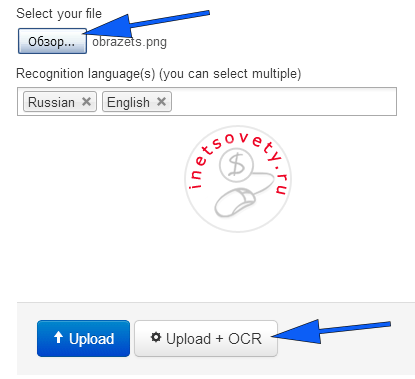
Для открытия сайта кликните newocr.com
Выбираем файл, ниже уже будет добавлено 2 языка, при необходимости добавьте другие. Кликните по кнопке «Upload & OCR»:
Изображение будет автоматически загружено и распознано. Результаты можно сохранить в документ или скопировать прямо из сайта:
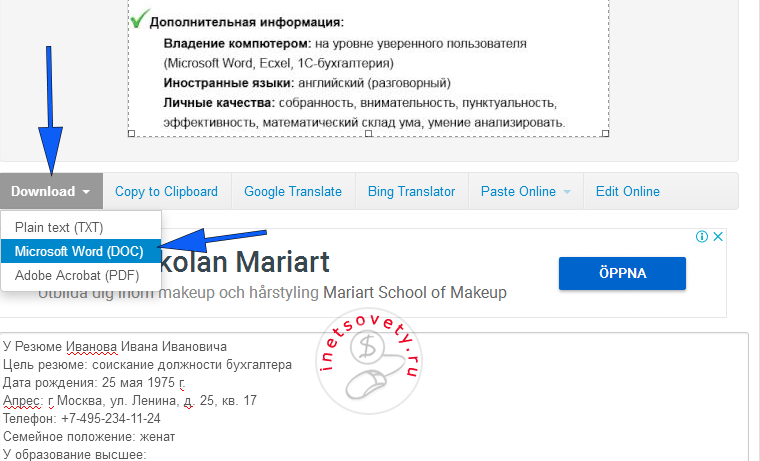
Есть возможность выделить участок на изображении для распознавания. А также несколько разных языков.
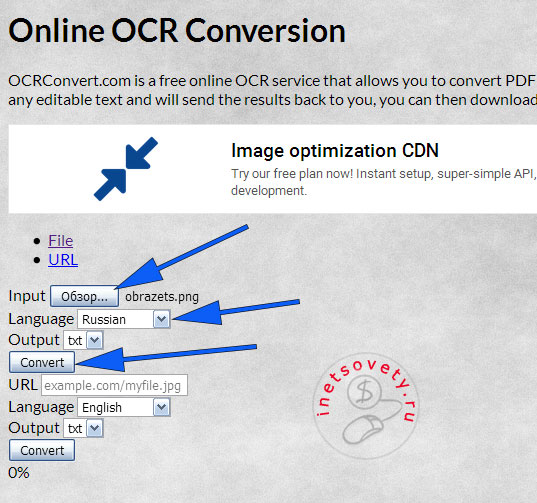
OCR Convert
Распознавание текста с картинки онлайн сервисом OCR Convert происходит не мгновенно! Вам предлагают оставить имейл, на который придет оповещении об удачном завершении распознавания. И скачать готовый файл можно в течении 24 часов, дальше он будет удален автоматически. Это главный минус данного сайта!
Работать просто, выберите файл, язык и кликните по кнопке «Convert»:
Soda PDF OCR
Многофункциональный сервис для работы с PDF документами. Полный список возможностей представлен на скрине ниже, но нас в первую очередь интересует распознавание текста из pdf в word онлайн.

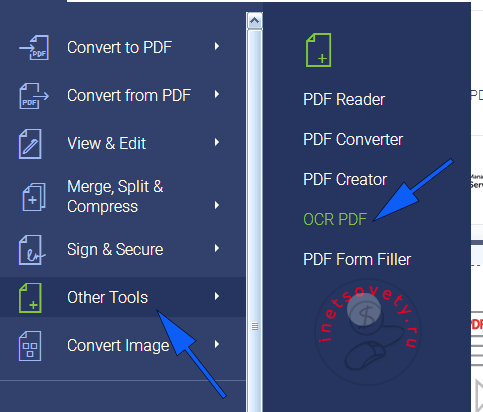
Загрузите файл и получите расшифрованный документ.
I2OCR
Работать с сайтом просто, всего 4 действия, чтобы преобразовать фото в текст:
- Выбираем язык.
- Загружаем файл.
- Подтверждаем, что мы не робот.
- Кликаем по кнопке «Extract».

Ожидаем минутку и появляется возможность скопировать текст с картинки онлайн на свой компьютер в одном из форматов по кнопке «Download».
OCR от Яндекс
Его назначение — перевод текста из подгруженного изображения, но с задачей сканировать текст с фотографии онлайн он успешно справляется. Работает без регистрации и каких-либо ограничений.

Вот таким не хитрым способом, используя яндекс переводчик не по назначению нам удалось скопировать текст с картинки онлайн.
ABBYY FineReader
Когда дело доходит до оптического распознавания символов, вряд ли найдется что-то, что даже близко подходит к ABBYY FineReader. ABBYY FineReader позволяет загружать текст со всех видов изображений на одном дыхании.
Несмотря на широкий набор функций, ABBYY FineReader очень прост в использовании. Он может извлекать текст практически из всех популярных форматы изображений, такие как PNG, JPG, BMP и TIFF. И это еще не все. ABBYY FineReader также может извлекать текст из файлов PDF и DJVU. После загрузки исходного файла или изображения (которое предпочтительно должно иметь разрешение не менее 300 т / д для оптимального сканирования) программа анализирует его и автоматически определяет различные разделы файла, имеющие извлекаемый текст. Вы можете либо извлечь весь текст, либо выбрать только некоторые конкретные разделы. После этого все, что вам нужно сделать, это использовать опцию Сохранить, чтобы выбрать формат вывода, а ABBYY FineReader позаботится обо всем остальном. Поддерживаются многочисленные форматы вывода, такие как TXT, PDF, RTF и даже EPUB.
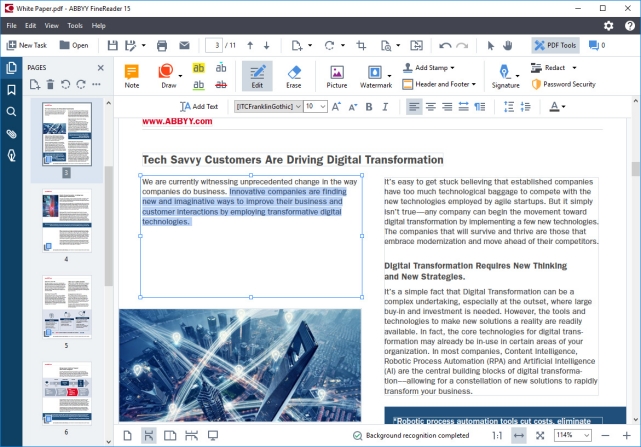
Выводимый текст является полностью редактируемым, и текст даже из самых содержательных документов (например, имеющих несколько столбцов и сложные макеты) извлекается безупречно. Другие функции включают в себя обширная языковая поддержка, многочисленные стили шрифтов / размеры и инструменты коррекции изображения для файлов, полученных из сканеров и камер.
Сказав все это, то, что отличает ABBYY FineReader от остальных программ, это его почти идеальная точность. С новым обновлением Finereader 15, теперь программное обеспечение использует AI для улучшения распознавания символов, AI особенно используется при извлечении текстов из документов, написанных на японском, корейском и китайском языках. Таким образом, если вы хотите получить абсолютно лучшее программное обеспечение для оптического распознавания текста с расширенными функциями, расширенным форматом ввода-вывода и поддержкой обработки, выберите ABBYY FineReader.
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются с $ 199, доступна 30-дневная бесплатная пробная версия
ABBYY FineReader
ABBYY FineReader — программа для работы с PDF-документами. Утилита дает возможность распознавать отсканированные тексты разных форматов. Всего поддерживается 192 языка для распознавания. При необходимости можно конвертировать документ из одного формата в другой.
Приложение полностью совместимо с операционной системой Windows (32/64 бит). Для загрузки доступна полностью русская версия. Программа работает на Windows 7 и новее, доступна возможность работы на серверных операционных системах. Модель распространения утилиты ABBYY FineReader — платная. Для получения полной версии приложения необходимо купить лицензию. Стоимость электронной версии на 1 год составляет 3190 рублей. Цена бессрочной версии — 6990 рублей. Утилита доступна только для домашнего использования.
Чтобы ознакомиться со всеми функциями программы, можно загрузить бесплатную демо-версию. Срок действия ознакомительной версии — 30 дней. После запуска утилиты откроется главное окно «Новая задача». Здесь доступно несколько основных разделов: открыть, сканировать и сравнить.
В разделе «Открыть» доступно много инструментов.
- Открыть PDF-документ для просмотра и редактирования файла: с помощью этого инструмента пользователи могут установить защиту на документ, оставлять комментарии на страницы или для отдельных текстовых блоков.
- OCR-редактор: используется для продвинутой конвертации документов, проверки распознания текста, ручной разметки областей распознавания.
- Конвертирование документа из одного формата в другой: PDF, Word, Excel. Пункт «Конвертировать в другие форматы» дает возможность пользователям выбрать нужный формат.
- Раздел «Сканировать» используется для сканирования документов различных форматов: PDF, Word, Excel, графические изображения и т.д. Доступна возможность сканирования в OCR-редактор. Здесь расположена функция распознавания текста. Можно обучить приложение распознавать нестандартные символы и шрифты.
- «Сравнение» — этот раздел используется для сравнение нескольких версий документов. Инструмент помогает быстро найти различия в текстах — найденные отличия выделяются цветом. Воспользоваться инструментом для сравнения файлов можно только в лицензионной версии программы ABBYY FineReader.
Преимущества ABBYY FineReader:
- простой и удобный интерфейс с поддержкой русского языка;
- большой набор инструментов для распознавания текста;
- возможность конвертирования файлов из одного формата в другой;
- функция сравнения текстов для поиска отличий.
Недостатки:
не поддерживается операционная система Windows XP и старше.