Поисковые подсказки яндекса, google и youtube: зачем нужны, как собирать быстро и правильно
Содержание:
- Фильтрация полученных ключевых фраз
- Группировка запросов
- Как формируются поисковые подсказки в Google и Яндекс
- Поисковые подсказки
- Другие эксперименты с дизайном
- Преимущества настройки поиска на сайте через Google и «Яндекс»
- Сработает ли идея?
- Виды подсказок
- Как сделать подсказку в видео на YouTube
- Дальнейшие улучшения
- По каким запросам пользователь осуществляет поиск информации на сайте
- С чего начать
- Где найти поисковые подсказки в виде вопросов и как собрать
- Что в итоге
Фильтрация полученных ключевых фраз
Используя данные методы можно быстро почистить список полученных ключевых запросов от нецелевых.
Составление списка стоп-слов
Если при просмотре списка запросов встречается слово, которое не подходит, нужно кликнуть на иконку «Стоп-слова» слева от запроса. Далее, в появившемся окне, отметить слово галочкой и нажать «Добавить в стоп-слова». В результате, все фразы в списке, которые содержат данное слово, будут отмечены галочками и их можно будет легко удалить.
В случае, если имеется уже готовый список стоп-слов, во вкладке «Сбор данных» нужно выбрать пункт «Стоп-слова». В появившемся окне нажать опцию «Добавить списком» или «Загрузить из файла». Отметить галочками нужные стоп-слова, нажать «ОК» и кликнуть на иконку «Отметить фразы в таблице». Если отмеченные фразы действительно являются лишними, их можно удалять.
Функция регулярных выражений
В колонке «Фраза» нужно кликнуть на иконку «Редактировать условия фильтрации» и выбрать опцию «удовлетворяет рег. выражению» и вставить в поле какое-либо регулярное выражение.
Например, для того чтобы выбрать все фразы, содержащие цифры, используется следующее выражение — «\d+». А для того, чтобы обозначить все запросы, которые представляют собой вопросы, в строку вписываем «^как». Тогда получится список фраз, которые начинаются со слова «как», а также «какой», «какая», «какие». В случае использования выражения «бесплатно$», получим все запросы, которые заканчиваются на слово .
Существует ряд других регулярных выражений, которые могут быть полезны и позволят существенно сэкономить время фильтрации списка запросов:
| Регулярное выражение | Обозначение |
| \d+ | выбрать все фразы, содержащие цифры |
| ^скачать | выбрать все фразы, начинающиеся со слова «скачать» |
| скачать$ | выбрать все фразы, заканчивающиеся на слово «скачать» |
| скачать | выбрать все фразы, содержащие слово «скачать» |
| скачать|купить|продать | выбрать все фразы, содержащие любое из слов: «скачать», «купить» или «продать» |
| ^пластиковые(.)*цены$ | выбрать все фразы, начинающиеся на «пластиковые» и заканчивающиеся на «цены» (.)* — в регулярном выражении означает последовательность символов любой длины |
| ^(\S+?\s\S+?)$ | выбрать все фразы, содержащие точно 2 слова |
| ^(\S+?\s\S+?\s\S+?)$ | выбрать все фразы, содержащие точно 3 слова |
| ^(\S+?\s\S+?\s\S+?\s\S+?)$ | выбрать все фразы, содержащие точно 4 слова |
| ^(\S+?\s\S+?\s\S+?\s\S+?\s\S+?)$ | выбрать все фразы, содержащие точно 5 слов |
Анализ неявных дублей
Неявные дубли представляют собой запросы, в которых одинаковые слова расположены в разном порядке. Например: «циклевка паркета спб» и «паркет циклевка спб».
Вводя в строку Яндекс.Вордстат данные запросы, получаем одинаковые или очень близкие значения ТЧ.
При использовании операторов Яндекс.Директ можно посмотреть точные вхождения данных запросов, и станет понятно, как именно набирают запрос пользователи. Тогда ТЧ данных двух запросов будут сильно отличаться, например, если поставить « » зафиксируется порядок ввода слов в запросе:
Если к запросу добавить оператор « ! » , тогда зафиксируется словоформа и можно будет увидеть совсем другую картину:
Во вкладке «Данные» нужно выбрать пункт «Анализ неявных дублей». В пункте «Параметры умной группировки» выбрать «Отметить все кроме самых высокочастотных в каждой группе». Затем нажать «Умная отметка». Те запросы, точная частотность которых ниже, отмечаются программой автоматически и их можно удалить.
Быстрый фильтр
Быстрый фильтр удобен тем, что если ввести в строку слово или часть слова, например «паркет» и нажать Enter, получится список всех возможных словоформ введенного слова: «паркетный», «паркета», «паркетной».
Группировка запросов
После фильтрации запросов нужно посчитать для них отношение БЧ к ТЧ и распределить по смысловым группам.
Отношение базовой частотности к точной показывает насколько эффективным является поисковый запрос. Если значение отношения БЧ к ТЧ большое, скорее всего запрос «пустой» и не стоит его использовать при продвижении страницы сайта.
Процесс группировки запросов занимает большое количество времени, чтобы сократить его, используется приложение «Подбор и кластеризация запросов» от Megaindex. Все что нужно сделать, это ввести доменное имя целевого сайта, добавить свой список запросов и запустить процесс кластеризации. Через некоторое время получается файл с разгруппированными запросами, которые нужно сопоставить с исходным файлом запросов, в котором есть значения частотностей и отношение БЧ к ТЧ. В данном случае пригодится функция ВПР для Excel. Функция позволит найти и перенести искомые значения частотностей из столбцов общего списка запросов в столбцы списка разгруппированных запросов.
Вводим формулу в первую ячейку столбца базовых частотностей:
- искомое значение – нужно выделить первую фразу в столбце кластеризованных запросов;
- таблица – выделить таблицу общего списка запросов;
- номер столбца – ввести номер столбца (например, столбец с базовой частотностью второй);
- интервальный просмотр – поставить 0.
Затем нужно протянуть значения вниз, предварительно поставив знаки доллара у выделенного интервала таблицы.
После того, как все столбцы со значениями будут перенесены, их нужно выделить и нажать копировать. Затем, нажав правую кнопку мышки, выбрать пункт «Специальная вставка» и там выбрать вариант для вставки «значения».
Таким образом перенесенные значения больше не будут ссылаться на искомые и их можно будет удалить.
Когда запросы разбиты на группы, нужно отнести наиболее запрашиваемые в группу «А», а все остальные в группу «Б». Данные запросы будут продвигаться в первую очередь.
Теперь запросам группы «А» назначаются посадочные страницы.
Есть правило — один КС должен соответствовать одной посадочной странице. В одной группе может быть несколько запросов, которые содержат дополнительные слова или похожи между собой и отображают какую-то одну суть.
Например: «циклевка паркета в спб», «циклевка паркета в спб недорого цены», «циклевка пола», «циклевка пола цены спб».
Эти запросы относятся к одной посадочной странице, которая должна быть оптимизирована именно под них и должна быть релевантной, т.е. в полной мере давать ответ на запрос пользователя. Если пользователь не найдет для себя нужной информации и сразу покинет страницу, это будет плохим сигналом для ПС и может плохо повлиять на дальнейшее продвижение сайта.
Как формируются поисковые подсказки в Google и Яндекс
На основании реальных запросов в сети. Чем популярнее запрос, тем с большей вероятностью он окажется в списке.
Также формирование напрямую связано с:
- история предыдущих запросов данного пользователя;
- актуальность — скорее система выдаст те ключевые слова и фразы, которые были использованы недавно в полном обьёме;
- язык, который выбран как основной используемый;
- геопринадлежность — показываются наиболее популярные в конкретном регионе, городе запросы.
Поисковые системы обновляют подсказки для поддержания функции поиска в актуальном состоянии. Удаление происходит в следующих случаях:
- Если она потеряла свою актуальность.
- При наличии личной информации.
- По требованию суда.
- В случае очевидной накрутки.
- Призывы к насильственным действиям или расовой ненависти.
- Связанные с порнографической тематикой.
Многие оптимизаторы пытаются «поставить» бренд в рекомендации. Хотя поисковики ведут активную борьбу с этим явлением, иногда они пропускают бренды в выдачу:
- при составлении рекламы, стимулирующей пользователей искать сайт, можно обеспечить большое количество запросов по данному бренду. Что, в свою очередь, становится «пропускным билетом» бренда в подсказки;
- участие в масштабных мероприятиях также привлекает большое количество пользователей, ищущих информацию о нем. Если бренд выступает в качестве спонсора или участника мероприятия, это может способствовать его появлению в подсказках, но с меньшей вероятностью, чем предыдущий способ;
- сервис «В подсказке» также дает возможность оказаться в выдаче по запросу. Происходит это путем добавления брендированного запроса в сервисе. Таким образом дается задание участникам, отобранным по их географическому положению, искать сайт по данному запросу. Это позволяет обеспечить не только быстрый рост запросов по бренду, но и длительный интерес. Такая ситуация помогает попасть в поисковики.
Поисковые подсказки
Иногда не обязательно открывать выдачу, чтобы получить ответ на свой запрос. Поисковые подсказки помогают пользователям искать то, что им нужно. Они позволяют генерировать итоговые запросы, загружая поисковую выдачу ещё до того, как пользователь нажмет кнопку «Найти»:
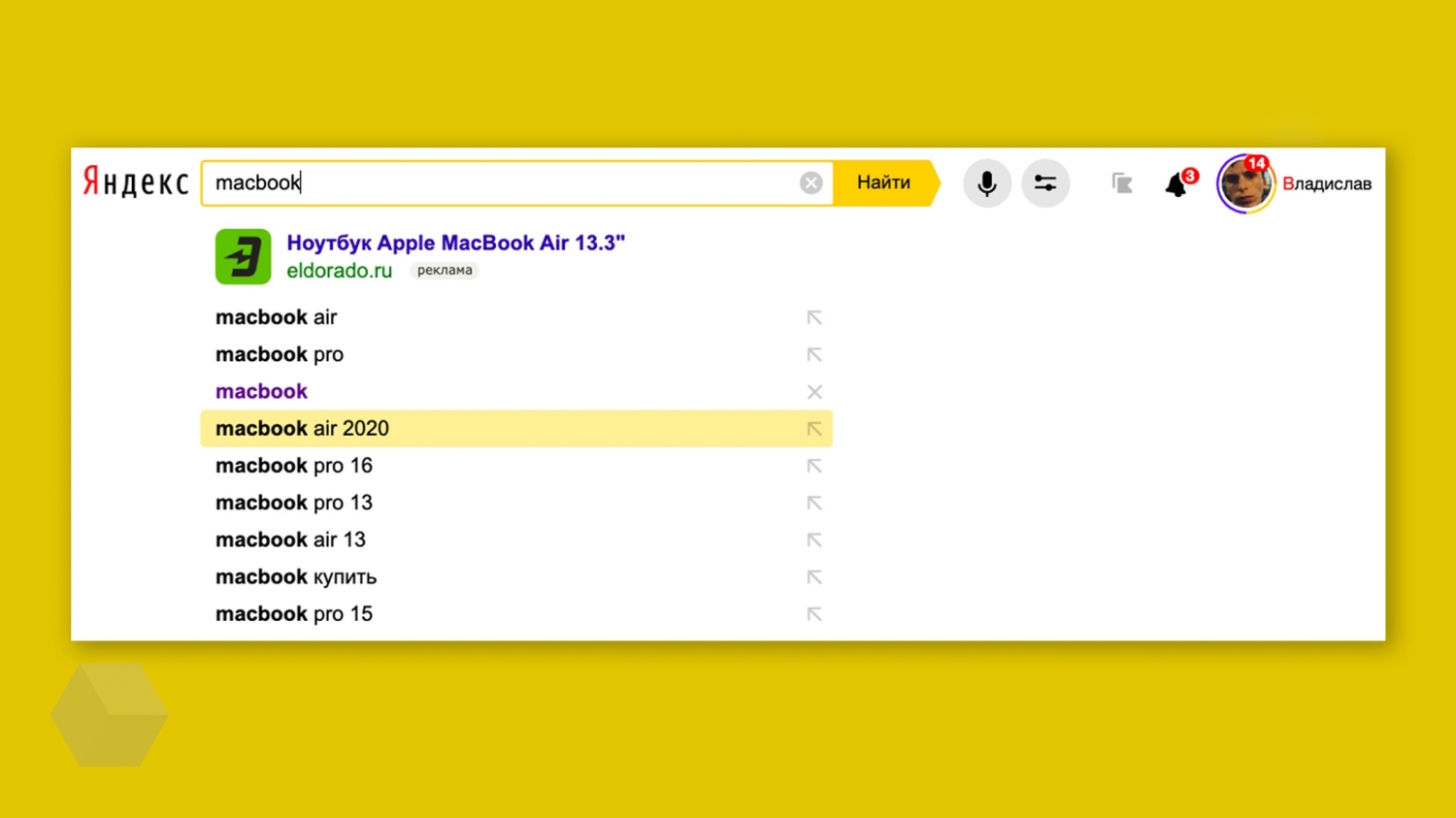
Когда пользователь начинает вводить запрос, алгоритмы попутно составляют итоговые формулировки. Это очень удобно и привычно: если мы, допустим, вводим «macbook», то «Яндекс» предложит его модели. А если пишем «купить билет», то получим соответствующие варианты типа «на самолет», «на поезд» и так далее. Тем самым поисковик экономит время пользователя на ввод запроса.
Кстати, на мобильных устройствах подсказки выглядят тоже очень удобно. Начинаем вводить запрос «когда закончится», а в результате получаем предложения наподобие «эпидемия коронавируса», «карантин» и так далее:

Если речь идет о вопросах, ответ на который будет состоять максимум из пары слов, то сразу же в поисковой строке будет отображаться, например, время в Берлине, курс доллара или погода в Риге.
И это ещё не всё. Мы можем мгновенно получить в поисковой выдаче ответ, если попытаемся узнать, допустим, автора музыки «Миллион алых роз» или вес игры Dota 2.

По данным «Яндекса», поисковые подсказки экономят пользователям в среднем примерно 15 секунд — это приблизительное время поиска нужного ответа на странице поисковой выдачи.
Другие эксперименты с дизайном
Когда стало ясно, что дизайнерские изменения в поисковых подсказках способны существенно влиять на метрики, фантазию было уже не остановить.
Для начала, попробуем усилить эффект от полнотекстовых подсказок. Если все пословные вытянуть в одну линию (с возможность скролла), для полнотекстовых подсказок будет больше места и, возможно, ввод станет ещё более быстрым.
С другой стороны, можно попробовать что-либо совсем уж странное. Давайте всегда подсказывать вероятные продолжения для наиболее вероятного следующего слова в отдельном столбце! Так родился вариант, который мы называем «саджест в виде графа»:
Саджест в виде графа производил фурор на всех UX-исследованиях. Все пользователи, впервые увидевшие его, говорили буквально следующее: «оооо, наконец-то мне помогают вводить запрос!». Тот, кто до сих пор не подозревал, что в поиске присутствуют подсказки, наконец их замечал. Тот, кто знал об их существовании, начинал пользоваться ими чаще.
Помимо этого, мы ещё пробовали изменять размер кнопок в пословных подсказках и их цвет. В целом, мысль была понятной: нужно как-то увеличить заметность подсказок, ведь они полезны и ими нужно чаще пользоваться!
Однако при проверке в онлайне обе гипотезы были отброшены. Тут же выяснились различия между метриками «доля использований саджеста» и «скорость ввода». К сожалению, слишком заметные подсказки вредят пользователям: они начинают слишком часто перескакивать глазами между саджестом и клавиатурой, а в результате вводят слишком медленно. Кроме того, это был один из редких случаев, когда тотальный успех на UX-исследованиях сопровождается столь же провальным выступлением в онлайне.
Преимущества настройки поиска на сайте через Google и «Яндекс»

Когда на веб-ресурсе накапливается масса контента, позаботьтесь о создании удобного поиска слов по сайту. Если CMS ресурса содержит соответствующий функционал, задействуйте его. Для статичных сайтов, состоящих из отдельных HTML-страничек, подключите скрипт, прочёсывающий HTML-код и формирующий список совпадений. Есть и третий вариант, наиболее оптимальный: воспользоваться поисковым плагином от «Яндекса» или «Гугла».
У плагинов, предоставляемых поисковыми системами, ряд весомых преимуществ:
- Сервисы создавались профессионалами, разработавшими поисковые системы. Поэтому о качестве и точности алгоритмов можно не волноваться.
- Учитывается всё морфологическое разнообразие языка.
- Существуют подсказки для пользователя.
- Опечатки, ошибки тут же автоматически исправляются.
- Ведётся статистика поиска.
Плагин Google для поиска по сайту предоставляет следующие возможности:
- Персонализация. Оформление поискового модуля по усмотрению клиента: настройка цветовой гаммы и прочих параметров (даже логотип «Гугла» можно заменить своим).
- Мультиязычность – поддержка всех языков для поиска. Язык по умолчанию выбираем самостоятельно или оставляем на усмотрение системы.
- Ранжирование результатов. Способ формирования выборки задаётся вручную. Можно, например, придать новым публикациям более высокий приоритет в выдаче.
- Уточнение и создание ярлыков. Аналогично уточнению результатов в «Яндексе», но в соответствии с категорией контента, в пределах которой посетитель ищет нужную информацию.
- Поиск картинок и вывод превью в результаты. Настраивается вручную, но, если этого не сделать, превью сформируются сами.
- Отсутствие рекламы.
- Ручное управление индексацией. Обновили сайт – можете заставить поискового робота прочесать весь ресурс и учесть обновления.
- Синонимы. База запросов постоянно пополняется синонимами и вариантами написания (например, Nissan и «Ниссан»), аббревиатурами и сокращениями (с расшифровками).
- Управление подсказками: их тоже можно установить вручную.
- Охват поиском сразу нескольких сайтов.
- Интеграция с остальными продуктами Google, прежде всего Analytics (показывает всю статистику по пользовательскому поведению и запросам) и AdWords (позволяет заработать, сделав сайт частью партнёрской сети для транслирования контекстной рекламы).
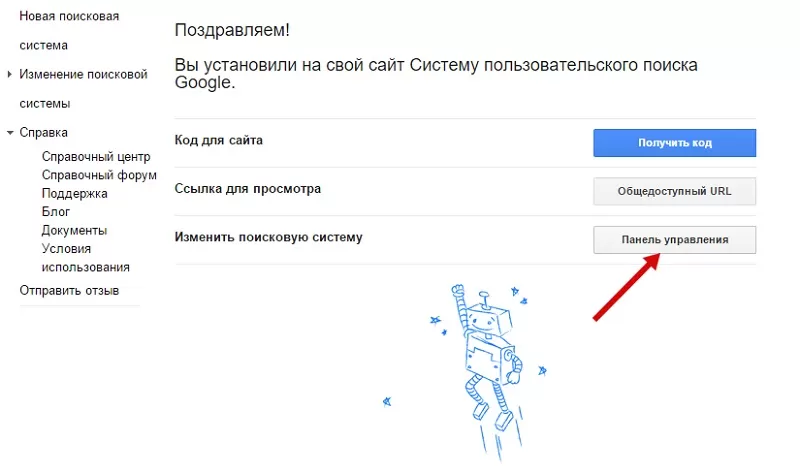
Первый шаг:
- Укажите URL сайта, где будет установлен плагин поиска.
- Выберите язык по умолчанию.
- Определите название поиска.
- Выберите платную либо бесплатную версию.
- Примите соглашение об условиях.
Второй шаг включает в себя всё, что касается визуального оформления поисковой формы. В разделе «Испытайте возможности» выберите один из готовых шаблонов. Затем, нажав кнопку «Настроить», перейдите в интерфейс редактирования внешнего вида поиска и оформите его в соответствии с общей стилистикой ресурса. После чего вы получите код поискового плагина, который копируется и вставляется в нужное место страницы или шаблона сайта. Даже на этом, третьем, шаге всё ещё можно изменять настройки поиска.
Чей бы готовый сервис поиска по сайту вы ни выбрали (от «Яндекса» или от «Гугла»), имейте в виду, что он прочёсывает не собственно сайт, а только страницы, проиндексированные роботом. Перед установкой поиска убедитесь, что все целевые рубрики открыты для индексации и попали в индекс поисковика.
Сработает ли идея?
В исследовательских задачах редко заранее бывает очевидно, что хорошее решение существует. И в нашем случае мы тоже изначально не знали, какие данные необходимы для того, чтобы построить достаточно хороший классификатор. В такой ситуации полезно начать с нескольких очень простых моделей, которые позволят оценить потенциальную пользу от разработки.
Самой простой идеей оказалась следующая: будем загружать выдачу по первой подсказке из поискового саджеста; когда подсказка меняется, мы выкидываем предыдущую загрузку и начинаем скачивать уже нового кандидата. Оказалось, что такой алгоритм работает неплохо и почти все запросы удаётся предзагрузить, однако соответственно возрастает нагрузка на поисковые бекенды и соответственно же возрастает пользовательский трафик. Ясно, что такое решение внедрить не получится.
Следующая идея тоже была достаточно простой: необходимо загружать вероятные поисковые подсказки не во всех случаях, а только тогда, когда мы в достаточной степени уверены, что они и правда нужны. Самым простым решением будет классификатор, работающий прямо в рантайме по тем данным, которые и так есть у саджеста.
Первый классификатор был построен с использованием всего десяти факторов. Эти факторы зависели от распределения вероятностей по множеству подсказок (идея: чем больше «вес» первой подсказки, тем более вероятно, что именно она и будет введена) и длины ввода (идея: чем меньше букв осталось ввести пользователю, тем безопасней предзагружать выдачу). Прелесть этого классификатора была ещё и в том, что для его построения не нужно было ничего релизить. Нужные факторы для кандидата можно собрать, сделав один http-запрос в саджестовый демон, а таргеты строятся по простейшим логам: кандидат считается «хорошим», если итоговый запрос пользователя полностью с ним совпадает. Собрать такой пул, обучить несколько логистических регрессий и построить диаграмму рассеяния оказалось возможным буквально за несколько часов.
Метрики для пререндера устроены не совсем так, как в обычной бинарной классификации. Важны всего два параметра, но это не точность и не полнота.
Пусть — общее количество запросов, — общее количество всех пререндеров, — общее количество удачных пререндеров, т.е. таких, которые в итоге совпали с пользовательским вводом. Тогда две интересные характеристики вычисляются следующим образом:
Скажем, если совершается ровно один пререндер на один запрос, а успешными оказывается половина пререндеров, то эффективность пререндера составит 50%, и это означает, что удалось ускорить загрузку половины запросов. При этом для тех запросов, в которых пререндер сработал успешно, дополнительный трафик не был создан; для тех запросов, в которых пререндер сработал неуспешно, пришлось задать один дополнительный запрос; так что общее количество запросов в полтора раза больше исходного, «лишних» запросов 50% от исходного количества, поэтому .
В этих координатах я и нарисовал первый scatter plot. Он выглядел вот так:
Эти значения содержали изрядное количество допущений, но по крайней мере было уже понятно, что, скорее всего, хороший классификатор получится: ускорять загрузку для нескольких десятков процентов запросов, увеличивая нагрузку на несколько десятков процентов — интересный размен.
Интересно было наблюдать за тем, как срабатывает классификатор. Действительно, оказалось, что очень сильным фактором является длина запроса: если пользователь уже почти ввёл первую подсказку, и она при этом достаточно вероятна, можно осуществить префетч. Так что предсказание классификатора резко возрастает к концу запроса.
Пререндер будет полезен, даже если он произошёл в момент ввода самой последней буквы запроса. Дело в том, что пользователи всё-таки тратят некоторое время на то, чтобы нажать на кнопку «Найти» после ввода запроса. Это время тоже можно сэкономить.
Виды подсказок
Пословные
Работают в мобильных приложениях и в «Яндекс.Браузере». Люди вбивают запрос из одного слова, затем им предлагается список, из которого нужно выбрать одно слово. По такой цепочке можно сформировать длинный запрос, корректируя каждое отдельное слово.
Полнотекстовые
Десктоп подразумевает использование полнотекстовых подсказок, так как пользователи гораздо быстрее вбивают запрос на ПК. Удобнее сразу напечатать основную часть запроса, а затем выбрать подходящий «хвост».
Подсказки-фактоиды
Для пользователей мобильных гаджетов при вводе таких запросов как «погода», «факты», «пробки» автоматически отображаются подсказки в виде информации.
Например, если вы вбиваете в мобильном поиске запрос «погода Санкт-Петербург», то под поисковой строкой отобразится текущая температура.
Реализованы подобные подсказки и в сервисе «Яндекс.Видео», где пользователям выводятся номера сезонов и серий. В первую очередь вы выбираете сезон, затем серию. При поиске по названию фильма, система предлагает прямую ссылку на него в виде подсказки.
Длинные
В последние годы отмечается тенденция увеличения длины поисковых запросов. Учитывая это, поисковые системы начали использовать и длинные поисковые подсказки. Они выводятся в основной поисковой выдаче, а также при поиске видео и картинок.
Исторические
Поисковые системы «следят» за пользователями, поэтому знают какие поисковые запросы они вводили в прошлом. На основе этой информации подсвечивают сайты, на которых они ранее искали информацию. Ранее это применялось только в десктопе, но сейчас они стали доступны для пользователей мобильных гаджетов и внедрены в поисковые сервисы «Яндекс».
Как сделать подсказку в видео на YouTube
Чтобы расставить подсказки в своих роликах выполните следующее:
Шаг 1. Зайдите в «Творческую студию YouTube».
Шаг 2. Перейдите в раздел «Менеджер видео» и кликните по первому разделу.

Выберете видео, где вы хотите поставить подсказки и нажмите на «Изменить».
Шаг 3. Перед вами откроется меню, где нужно выбрать «Подсказки». Нажимаем на синюю клавишу «Добавить подсказку».

Внизу под роликом вы можете видеть тайминг и места, где уже расставлены эти инструменты. Далее, мы рассмотрим создание подсказок разного вида.
Видео или плейлист
Кликнув на первую кнопку можно выбрать контент из имеющегося на канале или вставить ссылку, если вы рекламируете другой канал. После этого нужно нажать на синюю кнопку внизу и сохранить изменения.
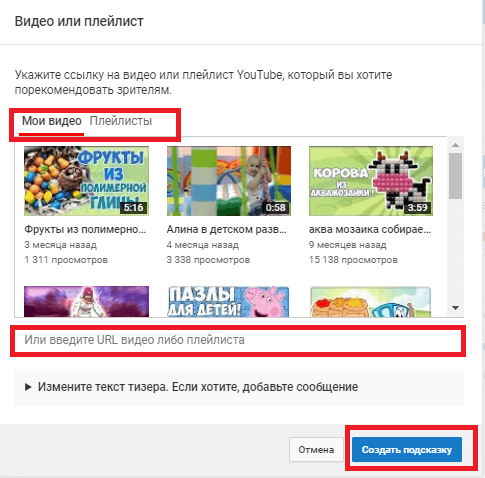
Статья в тему: Как создать плейлист на Ютубе
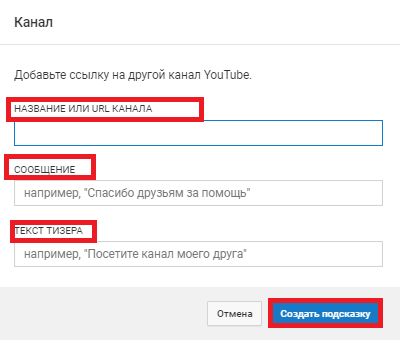
Канал
После нажатия на кнопку появится меню, где можно добавить ссылку или найти канал по поиску на YouTube. Помимо того, что в ваших роликах появится чужой канал, вы можете написать сообщение и тизер, что привлечёт ваших подписчиков перейти на другой аккаунт.
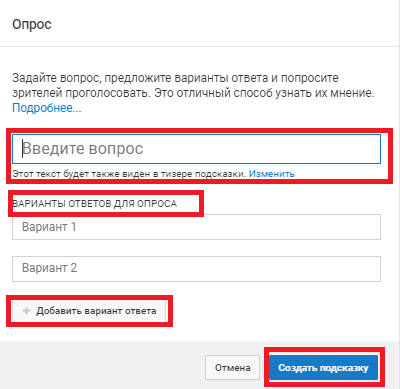
Как сделать подсказку-опрос
Сделав опрос на своём видео, вам необходимо прописать вопрос для зрителей и варианты ответов. Нажав на «Изменить» вы ещё можете прописать текст тизера. Если вам нужно прописать больше 2 вариантов, нажмите на «Добавить вариант ответа».
Ссылка
С недавнего времени добавлять ссылки на внешние сайты могут участники партнёрки Youtube. Вы можете ставить ссылки не только на свой личный сайт или магазин, а также на благотворительные акции и сборы средств.
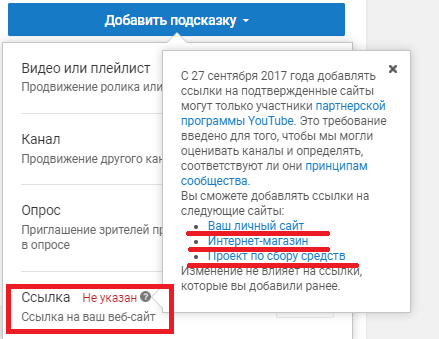
Важно! Подсказки сохраняются автоматически, вы можете их расставить и закрыть страницу менеджера видео
Дальнейшие улучшения
Хотя внедрение и оказалось удачным, решение было всё ещё крайне несовершенным. Внимательное изучение логов срабатываний показало, что есть несколько проблем.
-
Классификатор нестабилен. Например, может так оказаться, что по префиксу «янд» он предсказывает запрос «яндекс», по префиксу «янде» он не предсказывает ничего, а по префиксу «яндек» он снова предсказывает запрос «яндекс». Тогда наша первая прямолинейная реализация делает два запроса, хотя вполне могла обойтись и одним.
-
Пререндер не умеет обрабатывать пословные подсказки. Клик по пословной подсказке приводит к появлению в запросе дополнительного пробела. Например, если пользователь ввёл «яндекс», его первой подсказкой будет запрос «яндекс»; но если пользователь воспользовался пословной подсказкой, вводом будет уже строка «яндекс », а первой подсказкой — «яндекс карты». Это приведёт к плачевным последствиям: уже загруженный запрос «яндекс» будет выкинут, вместо него загрузится запрос «яндекс карты». После этого пользователь нажмёт на кнопку «Найти» и… будет дожидаться полной загрузки выдачи по запросу «яндекс».
-
В некоторых случаях у кандидатов нет никаких шансов стать успешными. В саджесте работает поиск по неточному совпадению, так что кандидат может, например, содержать только одно слово из введённых пользователем; либо пользователь может совершить опечатку, и тогда первая подсказка никогда не совпадёт в точности с его вводом.
Конечно, оставлять пререндер с такими несовершенствами было обидно, пусть даже он и полезен. Особенно мне было обидно за проблему с пословными подсказками. Я считаю внедрение пословных подсказок в мобильном поиске Яндекса одним из лучших своих внедрений за всё время работы в компании, а тут пререндер не умеет с ними работать! Позор, не иначе.
В первую очередь мы исправили проблему нестабильности классификатора. Решение выбрали крайне простое: даже если классификатор вернул негативное предсказание, мы не прекращаем загрузку предыдущего кандидата. Это помогает экономить дополнительные запросы, поскольку, когда этот же кандидат вернётся в следующий раз, не нужно будет качать соответствующую выдачу заново. В то же время, это позволяет загружать выдачи быстрее, так как кандидат скачивается в тот момент, когда классификатор впервые сработал для него.
Затем настал черед пословных подсказок. Саджестовый сервер является stateless-демоном, так что в нём тяжело реализовать логику, связанную с обработкой предыдущего кандидата для того же пользователя. Осуществлять поиск подсказок одновременно для запроса пользователя и для запроса пользователя без концевого пробела означает фактически удвоить RPS на саджестовый демон, так что это тоже не было хорошим вариантом. В итоге мы сделали так: клиент передаёт специальным параметром текст кандидата, который загружается прямо сейчас; если этот кандидат с точностью до пробелов похож на пользовательский ввод, мы отдаём его, даже если кандидат для текущего ввода поменялся.
После этого релиза наконец-то стало можно вводить запросы при помощи пословных подсказок и наслаждаться префетчем! Довольно забавно, что до этого релиза префетчем пользовались только те пользователи, что заканчивали ввод своего запроса при помощи клавиатуры, без саджеста.
Наконец, с третьей проблемой мы разобрались при помощи ML: добавили факторов про источники подсказок, совпадение с пользовательским вводом; кроме того, благодаря первому запуску мы смогли собрать побольше статистики и обучиться по месячным данным.
По каким запросам пользователь осуществляет поиск информации на сайте
Существует несколько стандартных типов поисковых запросов, чаще всего применяемых аудиторией сайта.
1. Поиск по названию товара.
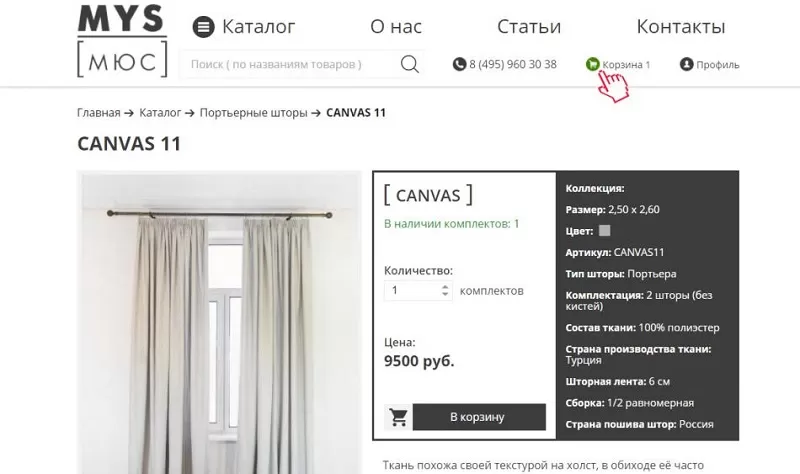
Некоторые клиенты аккуратно набирают в поиске полное и правильное наименование товара, поскольку чётко знают, что им нужно. Название они берут из разных источников:
- копируют его с других сайтов (например, если ищут самую выгодную цену);
- где-то слышали о продукте, а теперь хотят узнать о нём подробнее. Тут вероятность ошибок уже выше: на слух трудно воспринимать названия, особенно иностранные. Поисковый сервис должен правильно работать с типичными ошибками.
Узнать запросы можно с помощью «Вордстата», «Яндекс.Метрики» и Google Analytics. Эти сервисы дают точную картину происходящего, не исключая ошибочного варианта их написания, альтернативных наименований.
Настроить поиск по названию непросто, но обойтись без этого нельзя: товара, который клиенты не смогли найти на вашем сайте, не существует для них.
2. Поиск по имени категории.
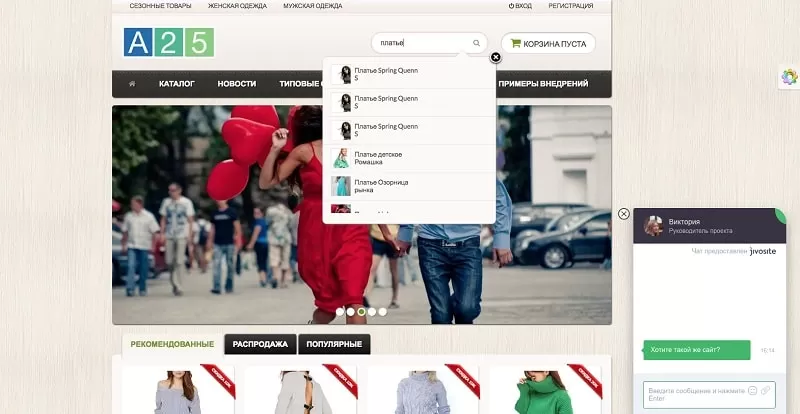
Те, кто ещё не определился с конкретной моделью, будут выбирать по тематическим категориям и набирать общие, абстрактные запросы: «амортизатор», «газонокосилка» и т. п. Поэтому поиск на сайте должен охватывать все возможные синонимы, которые только могут прийти в голову пользователю: от самых очевидных до сленговых и профессиональных. Например, один посетитель ищет копир, другой – ксерокс (хотя фактически это одно и то же).
Рекомендуемые статьи по данной теме:
- Что делать, если упала посещаемость сайта
- Юзабилити сайта: от разработки до апгрейда
- Проверка индексации сайта: 4 варианта
3. Поиск по описанию проблемы.
4. Информационный запрос.

Сюда относят любые запросы, не сводящиеся к поиску конкретного товара. Это, например, способы доставки, условия возврата и прочая подобная информация, обычно в виде текста. Предусмотрите и такой вариант тоже.
5. Запросы-характеристики.
Иногда потенциальный клиент применяет поиск на сайте для подбора товара, обладающего какой-либо характеристикой, например, «чёрный айфон». Чаще всего это параметры следующих типов:
- цвет;
- материал;
- спецификация;
- стоимость;
- формат;
- бренд.
6. Субъективные запросы.
Для некоторых потребителей важны свойства товара, не представляющие интереса для владельцев сайта: «дорогая сумка», «дешёвый сыр», «качественный планшет». Чтобы поиск по сайту сработал, требуются более тонкие настройки. Например, слово «качественный» в запросе должно обеспечивать выдачу целевых продуктов, у которых много отзывов или высокий рейтинг; слова, связанные с ценой, – давать выборку, отсортированную по стоимости от дорогих позиций к дешёвым или наоборот.
7. Аббревиатуры и символы.
С помощью внутреннего поиска нередко ищут сокращённые наименования, общепринятые аббревиатуры, номера моделей, цены. Например, «вино белое 1200 р.». Предусмотрите это при настройке поиска по сайту, чтобы не растерять лиды. Поручить задачу лучше программисту, работающему в связке с сео-специалистом.
С чего начать
2) Запустите скачанный файл, чтобы установить программу на компьютер. Обновите до новой версии, если выходит такое окно:
Далее переходим к настройке программы Словоеб.
3) Зайдите в «Настройки» в левом верхнем меню, которое появляется при нажатии значка программы:
4) В разделе «Парсинг» задайте его параметры. Уберите значок «+» из поля «Фильтрация символов»
Остальное оставьте, как задано по умолчанию.
Не забудьте сохранить изменения (далее сохраняйте их отдельно на каждой вкладке).
5) Настройте аккаунты Яндекс.Директа специально для сбора семантики.
Обратите особое внимание на следующее.
Использовать нужно специально созданные под парсинг аккаунты, проще говоря – «фейковые». Пусть вас это не пугает: Яндекс лоялен к парсерам, так как с помощью них рекламодатели могут настроить более качественные рекламные объявления, что на руку самой системе – ведь она на этом тоже зарабатывает
Это с одной стороны.
С другой – рабочий аккаунт, в котором ведется реклама, использовать ни в коем случае нельзя. Яндекс может его забанить за нарушение правил пользования сервисом
В этом случае лучше рискнуть потерять доступ к «фейковому» аккаунту, а не к настоящему.
Итак, далее придется выполнить небольшую рутинную работу по регистрации почтовых ящиков аккаунтов в Яндексе.
Важно! Несмотря на то, что аккаунты «фейковые», задавайте им читабельные имена пользователей, чтобы впредь процесс не тормозили капчи Яндекса, и работа продвигалась быстрее.
Затем перейдите на вкладку «Yandex.Direct» и в поле «Настройки аккаунтов Yandex» задайте их, а здесь введите их логины и пароли в любом из форматов. Чем больше, тем лучше, но достаточно и 3-5 аккаунтов.
В поле «Количество потоков» впишите количество созданных аккаунтов:
6) Ту же самую цифру задайте на вкладке «Yandex.Wordstat»:
7) В разделе «Интерфейс» на вкладке «Экспорт» выберите, в каком формате будете экспортировать результаты парсинга:
Дополнительно можете подключить автораспознавание капчи, чтобы она вас не преследовала
Особенно если вы планируете парсить большие объемы ключей. Стоимость сервисов по автоматическому распознаванию символическая, актуальные цифры смотрите в разделе «Антикапча» по ссылкам:
На этом основные настройки парсинга готовы, Словоеб готов к сбору данных. Переходим к самому процессу.
Где найти поисковые подсказки в виде вопросов и как собрать
Эти сервисы по-своему удобны. Но есть сервис, наиболее подходящий для работы SEO-оптимизатора по созданию семантического ядра для конкретного сайта. Этот сервис называется Prodvigator.
Его особенность в том, что он дает возможность получить рекомендации в виде вопросов. Эти вопросы — реальные запросы пользователей. Отвечая на эти вопросы, можно привлечь большое количество посетителей на ресурс. Пользоваться сервисом достаточно просто:
- Нужно ввести в строку поиска заданный запрос, выбрать поисковую систему и перейти во вкладку «Поисковые подсказки», выйдет большое количество ключевых фраз.
- Более точные данные позволит получить настройка парсинга. Для этого в фильтрах нужно выбрать «Только ключевые слова без топонимов» и прописать вручную слова, которые требуется очистить из выдачи. Перед каждым таким словом необходимо поставить знак минуса. После нажатия кнопки «Применить» выходит уже гораздо меньшее количество ключевых фраз.
- Переход во вкладку «Только вопросы» поможет увидеть список фраз, которые состоят только из вопросов. Их можно использовать для написания статьи, релевантной запросам пользователей.
- Функция «пакетный экспорт» позволит просмотреть поисковые подсказки по нескольким ключевым фразам. Сервис дает возможность ввести до 200 таких фраз и получить поисковые подсказки в Яндексе по каждой в виде отчета. Для этого ключевые фразы вводятся в нужное поле, результаты фильтруются по топонимам и выбираются лишь вопросительные варианты.
Использование этой возможности в создании или расширении существующего семантического ядра позволяет получить список релевантных и актуальных фраз, которые обязательно приведут на сайт трафик. Ведь это именно те запросы, что используют для нахождения товаров и/или услуг реальные пользователи.
По работе с поисковыми подсказками вышла не так давно книга, нашего соотечественника Скорых Михаила. Для того, чтобы вникнуть в суть работы подсказок, как работать с негативными подсказками, формирование их для длинных запросов, какие бонусы это может принести, рекомендуем начать с нее.
Что в итоге
Каждый из этих релизов давал рост количества мгновенно загружаемых выдач на десятки процентов. Самое приятное в том, что нам удалось улучшить показатели пререндера более чем в два раза, практически не трогая часть про machine learning, а лишь улучшая физику процесса. Это важный урок: зачастую качество классификатора не является самым узким местом в продукте, зато его улучшение является самой интересной задачей и поэтому разработка отвлекается именно на него.
К сожалению, мгновенно загруженные выдачи — это ещё не полный успех; загруженную выдачу нужно ещё отрендерить, что происходит не мгновенно. Так что нам ещё предстоит работать над тем, чтобы лучше конвертировать мгновенные загрузки данных в мгновенные отрисовки поисковых выдач.
К счастью, сделанные внедрения уже позволяют говорить о пререндере как о достаточно стабильно работающей фиче; мы дополнительно проверили внедрения, описанные в пункте 2: они все вместе тоже приводят к тому, что пользователи сами по себе начинают чаще совершать поисковые сессии. Отсюда ещё один полезный урок: значительные улучшения в скорости работы сервиса могут статистически значимо влиять на его retention.
На видео ниже можно посмотреть, как сейчас работает пререндер на моём телефоне.