Команды linux для работы с файлами
Содержание:
- Дополнительные возможности
- Использование ls в Linux
- Примеры использования
- Linux поиск по содержимому файлов командой locate
- Common Linux Find Commands and Syntax
- find — синтаксис и зачем оно нужно
- Use the ‘find’ Command to Locate a File in Linux
- Примеры использования команды find
- Примеры использования
- Search Location Shortcuts
- Поиск больших файлов командой find
- grep — что это и зачем может быть нужно
- Как посмотреть количество файлов в папке Linux
- Пути файлов в Linux
- Основная информация о Find
Дополнительные возможности
Важной альтернативой параметру является параметр ; его поведение такое же, как у , но перед выполнением какой-либо команды над найденным файлом он выводит предупреждение пользователю. Предположим, что необходимо файл за файлом (file-by-file) удалить большую часть .txt-файлов в домашнем каталоге
При автоматизированном поиске операции удаления, такие как команда в UNIX, опасны, поскольку возможно непреднамеренное удаление важных файлов; возможно, следует изучить все найденные файлы перед тем как удалять их.
Следующая команда выводит список всех .txt-файлов в домашнем каталоге. Чтобы удалить эти файлы, необходимо, когда команда выведет имя файла, ввести или :
$ find $HOME/. -name *.txt -ok rm {} \;
Каждый найденный файл выводится подобным образом, а система делает паузу для ввода или . Система не удалит файл, если нажать клавишу Enter. содержит пример результатов работы команды .
Листинг 1. Пример результатов
< rm ... /home/bill/./.kde/share/apps/karm/karmdata.txt > ? < rm ... /home/bill/./archives/LDDS.txt > ? < rm ... /home/bill/./www/txt/textfile1.txt > ? < rm ... /home/bill/./www/txt/faq.txt > ? < rm ... /home/bill/./www/programs/MIKE.txt > ? < rm ... /home/bill/./www/programs/EESTRING.txt > ? . . .
После каждого вопросительного знака система останавливается; в этом случае для перехода к следующему файлу была нажата клавиша Enter (никакие файлы не были удалены). Параметр позволяет управлять автоматической обработкой каждого файла, делая более безопасным процесс автоматического удаления файлов.
Бывает так, что при использовании параметра требуется подтверждать или отклонять удаление слишком большого количества файлов по отдельности. В таком случае для вывода имен всех файлов, которые надо удалить, следует выполнить команду с параметром . Затем, изучив список и убедившись, что важные файлы не будут удалены, выполните команду еще раз, заменив на .
И и – полезные параметры, однако прежде чем их использовать, нужно решить, какой из них наиболее подходит для конкретной ситуации. Помните, что безопасность превыше всего!
Использование ls в Linux
Как вы уже поняли, ls — это сокращение от list, эта команда представляет из себя аналог команды dir для Linux. Самый простой способ использовать команду, запустить ее без параметров и посмотреть содержимое текущей папки:

Чтобы посмотреть список файлов в папке linux для точно заданной папки, вам нужно указать путь к ней. Например, смотрим содержимое корневой папки:

Или папки /bin:

По умолчанию включен цветной вывод, поэтому вы видите столько различных цветов. Например, исполняемые файлы обозначаются салатовым, а ссылки голубым. Теперь посмотрим содержимое домашней папки снова, только на этот раз в виде списка с максимальным количеством информации:

Тут вывод уже разделен на отдельные колонки, в первой колонке указаны права доступа к файлу в формате владелец группа остальные. Следующая колонка — это тип файла или папки, дальше владелец и группа, затем размер, дата создания и последний параметр — имя. Если вы еще хотите знать кто создал файл, можно использовать опцию author:

Колонка создателя будет добавлена после группы. Дальше размер. Он выводится в байтах, килобайтах или еще в чем-то и нам не совсем понятно что там происходит, поэтому добавьте опцию -h чтобы выводить размер в более удобном виде:

Для папок размер выводится не сумой всех размеров всех файлов, а всего лишь то место, которое занимает сама папка, поэтому давайте посмотрим пример с файлами:


Если вы хотите видеть скрытые файлы, а в домашней папке их просто море, то используйте опцию -a:

Или смотрим скрытые файлы без ссылок на текущую и родительскую папку:

Теперь нас будет интересовать сортировка. Сначала отсортируем файлы по размеру:

Обратите внимание, что файлы расположены от большего к меньшему. Теперь мы можем включить обратный порядок:

С помощью опции -r мы вывели файлы в обратном порядке. Теперь отсортируем по алфавиту:

Или сортируем по времени последней модификации:

Обратите внимание на колонку времени, действительно, самые новые файлы будут вверху списка. Если вы хотите посмотреть какие метки SELinux присвоены файлу, необходимо использовать опцию -Z:

Но это возможно только в системах, где установлена надстройка SELinux. Если вы хотите рекурсивно вывести содержимое всех папок, используйте опцию -R:

Если же вам нужно список папок и файлов в директории через запятую, что можно использовать -m:

Примеры использования
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
Поиск текста в файлах
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после неё:
Выведет целевую строку и 4 строчки до неё:
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки — спецсимвол «$»:
Найдём все строки, которые содержат цифры:
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
Рекурсивное использование grep
Если вам нужно провести поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах, например в файлах конфигурации Apache — /etc/apache2/, используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займётся поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
Получим:
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Linux поиск по содержимому файлов командой locate
Поиск, производимый командой locate весьма быстр. Однако учитывайте тот факт, что системная база данных может быть не живой на момент осуществления операции. Механизм сканирования файловой системы, время его проведения и вобщем наличие такого инструмента может разниться в различных дистрибутивах Linux. Команда locate может быть полезна лишь при поиске файла по его имени. Однако для проверки текстового содержимого документов на вступление искомых данных нужно использовать другой инструмент.
Данная команда, как правило, работает быстрее и может с легкостью производить поиск (в широком смысле — стремление добиться чего-либо, найти что-либо; действия субъекта, направленные на получение нового или утерянного (забытого): новой информации (поиск информации), данных,) по всей файловой системы. Linux имеет специальную команду grep, какая принимает шаблон для поиска и имя файла (именованная область данных на носителе информации). В случае нахождения совпадений, они будут выведены в терминал. В всеобщем виде выражение можно составить как «grep шаблон_поиска имя_файла». Чтобы отыскать файлы с помощью команды locate, просто используйте следующий синтаксис:
К образцу, чтобы возвращать только файлы, содержащие сам запрос, вместо того чтобы вводить каждый файл, который содержит запрос в ведущих к нему каталогах, можно утилизировать флаг –b (чтоб искать только basename, базовое имя файла):
Команды find и locate – отличные инструменты для поиска файлов в UNIX‐подобных операционных системах. Любая из этих утилит имеет свои преимущества. Мы рассмотрели использование команд для поиска и фильтрации вывода бригад в операционной системе Linux. При правильном применении эта утилита станет мощным инструментом в ваших руках. Несмотря на то, что команды find и locate сами по себе очень мощны, их действие возможно расширить, комбинируя их с другими командами. Научившись работать с find и locate, попробуйте чистить их результаты при помощи команд wc, sort и grep.
Common Linux Find Commands and Syntax
expressions take the following form:
- The attribute will control the behavior and optimization method of the process.
- The attribute will define the top level directory where begins filtering.
- The attribute controls the tests that search the directory hierarchy to produce output.
Consider the following example command:
This command enables the maximum optimization level (-O3) and allows to follow symbolic links (). searches the entire directory tree beneath for files that end with .
Basic Examples
| Command | Description |
|---|---|
| Find a file called testfile.txt in current and sub-directories. | |
| Find all files in the and sub-directories. | |
| Find an empty file within the current directory. | |
| Find all files (ignoring text case) modified in the last 7 days by a user named exampleuser. |
find — синтаксис и зачем оно нужно
find — утилита поиска файлов по имени и другим свойствам, используемая в UNIX‐подобных операционных системах. С лохматых тысячелетий есть и поддерживаться почти всеми из них.
Базовый синтаксис ключей (забран с Вики):
-name — искать по имени файла, при использовании подстановочных образцов параметр заключается в кавычки
Опция `-name’ различает прописные и строчные буквы; чтобы использовать поиск без этих различий, воспользуйтесь опцией `-iname’;
-type — тип искомого: f=файл, d=каталог, l=ссылка (link), p=канал (pipe), s=сокет;
-user — владелец: имя пользователя или UID;
-group — владелец: группа пользователя или GID;
-perm — указываются права доступа;
-size — размер: указывается в 512-байтных блоках или байтах (признак байтов — символ «c» за числом);
-atime — время последнего обращения к файлу (в днях);
-amin — время последнего обращения к файлу (в минутах);
-ctime — время последнего изменения владельца или прав доступа к файлу (в днях);
-cmin — время последнего изменения владельца или прав доступа к файлу (в минутах);
-mtime — время последнего изменения файла (в днях);
-mmin — время последнего изменения файла (в минутах);
-newer другой_файл — искать файлы созданные позже, чем другой_файл;
-delete — удалять найденные файлы;
-ls — генерирует вывод как команда ls -dgils;
-print — показывает на экране найденные файлы;
-print0 — выводит путь к текущему файлу на стандартный вывод, за которым следует символ ASCII NULL (код символа 0);
-exec command {} \; — выполняет над найденным файлом указанную команду; обратите внимание на синтаксис;
-ok — перед выполнением команды указанной в -exec, выдаёт запрос;
-depth или -d — начинать поиск с самых глубоких уровней вложенности, а не с корня каталога;
-maxdepth — максимальный уровень вложенности для поиска. «-maxdepth 0» ограничивает поиск текущим каталогом;
-prune — используется, когда вы хотите исключить из поиска определённые каталоги;
-mount или -xdev — не переходить на другие файловые системы;
-regex — искать по имени файла используя регулярные выражения;
-regextype тип — указание типа используемых регулярных выражений;
-P — не разворачивать символические ссылки (поведение по умолчанию);
-L — разворачивать символические ссылки;
-empty — только пустые каталоги.
Примерно тоже самое, только больше и в не самом удобочитаемом виде, т.к надо делать запрос по каждому ключу отдельно, можно получить по
Результатам будет нечто такое из чего можно вычленять справку по отдельному ключу или команде (кликабельно):
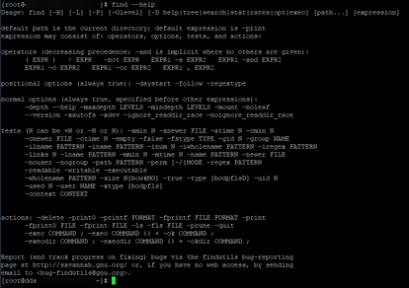
В качестве развлечения можно использовать:
Дабы получить мануал из самой системы по базису и ключам (тоже кликабельно);

Немного о примерах использования. Точно так же, оттуда же и тп. Просто для понимания как оно работает вообще. Наиболее просто, конечно, осознать это потренировавшись в той же консоли на реальной системе.
Use the ‘find’ Command to Locate a File in Linux
The command used to search for files is called find.
The basic syntax of the find command is as follows:
The currently active path marks the search location, by default. To search the entire drive, type the following:
If, however, you want to search the folder you are currently in, use the following syntax:
When you search by name across the entire drive, use the following syntax:
- The first part of the find command is the find command.
- The second part is where to start searching from.
- The next part is an expression that determines what to find.
- The last part is the name of the file to find.
To access the shell (sometimes called the terminal window) in most distributions, click the relevant icon or press Ctrl+Alt+T.
Примеры использования команды find
Команда find – это один из мощнейших инструментов linux-администратора.
Ниже приведена шпаргалка по этой замечательной команде.
Найти файл по имени без учета регистра
начиная с текущего каталога рекурсивно:
find -iname "MyCProgram.c"
в каталоге рекурсивно:
find /var -iname syslog*
ограничить поиск только текущей файловой системой (-xdev должен быть после пути поиска но до аргументов поиска)
find /var -xdev -iname syslog*
Найти файл по Inode и переименовать
Это может понадобиться, если к примеру в имени файла есть спец. символы, и переименовать стандартными методами не получается
~# find /var -iname syslog -exec ls -i1 {} \;
3932232 /var/log/syslog
3932189 /var/log/installer/syslog
~# find /var -inum 3932232 -exec mv {} new-test-file-name \;
файлы и каталоги
find /var/log -empty
только файлы
find /var/log -empty -type f
только каталоги
find /var/log -empty -type d
Поиск файлов на основании размера
найти файлы больше чем
find /var/log -size +100M
найти файлы меньше чем
find /var/log -size -100M
найти файлы точно в размер
find /var/log -size 100M
Ключи -ctime -mtime -atime -amin – cmin – mmin
Access time – время доступаModification time – время изменения содержимого в файлеChange time – время обновления файла. (например если мы поменяли атрибуты доступа, то изменится ctime в то же время mtime не изменится)
Опции и означают дни и минуты
Выполнение операций над найденными файлами
Общий синтаксис:
find <CONDITION_to_Find_files> -exec <OPERATION> \;
Где это команда или скрипт.
Для передачи имени найденного файла используется конструкция из двух скобок
пример:
найти все файлы с именем и вывести их
find /var -name syslog -type f -exec ls -i1 {} \;
*скобки можно применять в рамках только одной команды! *
например вот эта команда сработает без проблем:
find -name "*.txt" cp {} {}.bkup \;
а вот эта команда сработает не верно! Здесь отработают только скобки в команде mv:
find -name "*.txt" -exec mv {} `basename {} .htm`.html \;
Для того, что бы осуществить задачу нужно создать отдельный скрипт и запустить его из , передав в качестве аргумента :
echo "mv "$1" "`basename "$1" .htm`.html"" > mv.sh
find -name "*.html" -exec ./mv.sh '{}' \;
Форматированный вывод
find /var -type file -name syslog -prinf '<FORMAT>'
usable ключи форматирования:
\a Alarm bell.
\n Newline.
\t Horizontal tab.
%c File's last status change time in the format returned by the C
`ctime' function.
%f File's name with any leading directories removed (only the last ele‐
ment).
%g File's group name, or numeric group ID if the group has no name.
%h Leading directories of file's name (all but the last element). If
the file name contains no slashes (since it is in the current direc‐
tory) the %h specifier expands to ".".
%i File's inode number (in decimal).
%k The amount of disk space used for this file in 1K blocks. Since disk
space is allocated in multiples of the filesystem block size this is
usually greater than %s1024, but it can also be smaller if the file
is a sparse file.
%b The amount of disk space used for this file in 512-byte blocks. Since
disk space is allocated in multiples of the filesystem block size
this is usually greater than %s512, but it can also be smaller if
the file is a sparse file.
%m File's permission bits (in octal). This option uses the `tradi‐
tional' numbers which most Unix implementations use, but if your par‐
ticular implementation uses an unusual ordering of octal permissions
bits, you will see a difference between the actual value of the
file's mode and the output of %m. Normally you will want to have a
leading zero on this number, and to do this, you should use the #
flag (as in, for example, `%#m').
%M File's permissions (in symbolic form, as for ls). This directive is
supported in findutils 4.2.5 and later.
%p File's name.
%P File's name with the name of the command line argument under which it
was found removed.
%s File's size in bytes
%t File's last modification time in the format returned by the C `ctime'
function.
%u File's user name, or numeric user ID if the user has no name.
%U File's numeric user ID
%Y File's type (like %y), plus follow symlinks L=loop, N=nonexistent
Можно запускать два поиска в одной команде
Профит в том, что за один проход по файловой системе выполняется несколько поисков.
Например следующая команда рекурсивно проходит по файловой системе один раз, при этом сохраняет список файлов с флагом в файл , а список с большими файлами в
find / \( -perm -4000 -fprintf /root/suid.txt '%#m %u %p\n' \) , \ \( -size +100M -fprintf /root/big.txt '%-10s %p\n' \)
Enjoy!
Примеры использования
А теперь давайте рассмотрим примеры find, чтобы вы лучше поняли, как использовать эту утилиту.
2. Поиск файлов в определенной папке
Показать все файлы в указанной директории:
Искать файлы по имени в текущей папке:
Не учитывать регистр при поиске по имени:
5. Несколько критериев
Поиск командой find в Linux по нескольким критериям, с оператором исключения:
Найдет все файлы, начинающиеся на test, но без расширения php. А теперь рассмотрим оператор ИЛИ:
8. Поиск по разрешениям
Найти файлы с определенной маской прав, например, 0664:
Найти файлы с установленным флагом suid/guid:
Или так:
Поиск файлов только для чтения:
Найти только исполняемые файлы:
Найти все файлы, принадлежащие пользователю:
Поиск файлов в Linux принадлежащих группе:
10. Поиск по дате модификации
Поиск файлов по дате в Linux осуществляется с помощью параметра mtime. Найти все файлы модифицированные 50 дней назад:
Поиск файлов в Linux открытых N дней назад:
Найти все файлы, модифицированные между 50 и 100 дней назад:
Найти файлы измененные в течении часа:
Найти все файлы размером 50 мегабайт:
От пятидесяти до ста мегабайт:
Найти самые маленькие файлы:
Самые большие:
13. Действия с найденными файлами
Для выполнения произвольных команд для найденных файлов используется опция -exec. Например, выполнить ls для получения подробной информации о каждом файле:
Удалить все текстовые файлы в tmp
Удалить все файлы больше 100 мегабайт:
Search Location Shortcuts
The first argument after the find command is the location you wish to search. Although you may specify a specific directory, you can use a metacharacter to serve as a substitute. The three metacharacters that work with this command include:
- Period (.): Specifies the current and all nested folders.
- Forward Slash (/): Specifies the entire filesystem.
- Tilde (~): Specifies the active user’s home directory.
Searching the entire filesystem may generate access-denied errors. Run the command with elevated privileges (by using the sudo command) if you need to search in places your standard account normally cannot access.
Поиск больших файлов командой find
Простой поиск
Команда find имеет опцию -size, которая позволяет указать размер файлов для поиска.
Найдем файлы, которые занимают больше 1Gb:
- Символ точка . после самой команды find, означает, что поиск нужно вести в текущей директории. Вместо точки вы можете указать, например, корневой раздел или путь до любой другой директории.
- -mount означает, что в процессе поиска не нужно переходить на другие файловые системы.
- -type f означает, что мы ищем файлы.
-
-size +1G означает, что нужно найти файлы, размер которых превышает 1Gb. Размер можно указать в различных форматах:
- b — блоки размером 512 байт. Числом указывается количество блоков.
- c — в байтах. Например: -size +128с
- w — в двухбайтовых словах
- k — в килобайтах
- M — в мегабайтах
- G — в гигабайтах
- 2>/dev/null используется, чтобы не показывать ошибки (например, если нет доступа к файлу).
В результате выполнения команды будет выведен список файлов без какой-либо дополнительной информации.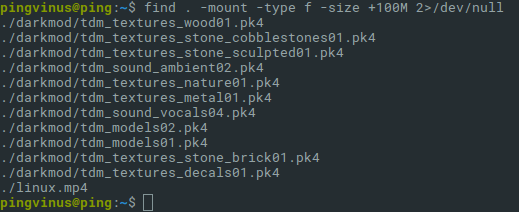
Вывод подробной информации
Добавим в вывод информацию о каждом файле и отсортируем список по размеру. Выполняем команду

Данная команда состоит из трех частей:
- Команда find ищет файлы, которые имеют размер больше 512 мегабайт.
- Результирующий список файлов передается команде xargs, которая, в свою очередь, запускает команду ls -lh над этим списком файлов. В результате получается таблица с файлами и информацией о файлах.
Опция -r, команды xarg, используется для того, чтобы не запускать команду ls, если команда find вернула пустой результат (не нашла файлов). Вместо -r можно использовать длинную запись — опцию —no-run-if-emptyОпция -d ’\n’ используется, чтобы разделять список файлов только по символу новой строки (по \n). А у нас так и есть — каждый файл на новой строке. Иначе неправильно будут обработаны файлы, в названии которых содержится пробел, так как по умолчанию команда xarg в качестве разделителя использует одновременно пробел, табуляцию или символ новой строки.
Примечание: Для BSD-систем вместо -d ’\n’ нужно использовать опцию −0, а у команды find вместо -print использовать -print0. Пример: find . -mount -type f -size +512M -print0 2>/dev/null | xargs -0 ls -lh | sort -k5,5 -h -r
- Затем результат команды ls передается команде sort, которая выполняет сортировку списка (таблицы) по пятой колонке — 5-я колонка содержит размеры файлов.Ключ -h означает, что результат нужно вывести в удобно-читаемом виде (human-readable).Ключ -r означает, что сортировку нужно выполнять по убыванию (reverse).
grep — что это и зачем может быть нужно
Про «репку» (как я её называю) почему-то в курсе не многие, что печалит. «Унылая» (не в обиду) формулировка из Википедии звучит примерно так:
grep — утилита командной строки, которая находит на вводе строки, отвечающие заданному регулярному выражению, и выводит их, если вывод не отменён специальным ключом.
Не сильно легче, но доступнее, можно сформулировать так:
grep — утилита командной строки, используется для поиска и фильтрации текста в файлах, на основе шаблона, который (шаблон) может быть регулярным выражением.
Если всё еще ничего не понятно, то условно говоря это удобный поиск текста везде и всюду, в особенности в файлах, директория в и тп. Удобно распарсивать логи и их содержимое, не прибегая к софту, как это бывает в Windows.
Справку можно вычленить так же как по find, т.е методом pgrep, fgrep, egrep и черт знает что еще:
Или:
Расписывать все ключи и даже основные тут (вы еще помните, что это блоговая часть сайта?) не буду, так как в отличии от find’а, последних тут вообще страшное подмножество, особенно учитывая, что существуют pgrep, fgrep, egrep и черт знает что еще, которые, в некотором смысле тоже самое, но для определенных целей.
Потрясающе удобная штука, которая жизненно необходима, особенно, если Вы что-то когда-то где-то зачем-то администрировали. Взглянем на примеры.
Как посмотреть количество файлов в папке Linux
Самый простой способ решить эту задачу — использовать утилиту ls вместе с утилитой wc. Они покажут сколько файлов находится в текущей папке:

В моем случае утилита выдала результат 21, но поскольку ls выводит размер всех файлов в папке строкой total, то у нас файлов на один меньше. Нужно учесть, что тут отображаются еще и директории. Каждая директория начинается с символа «d», а каждый файл с «-«. Для символических ссылок используется «l». Посмотрите внимательно на вывод ls:

Чтобы их отсеять используйте grep:

Эта конструкция выберет только те строки, которые начинаются на дефис. Если вас интересуют не только обычные файлы, но и скрытые, то можно использовать опцию -a:

Так можно подсчитать количество папок:

А так символических ссылок:

Если вам нужно подсчитать количество файлов во всех подпапках, то можно использовать опцию -R:

С фильтром только файлы нам уже не страшно, что команда будет выводить служебную информацию. Если вы не хотите использовать ls, можно воспользоваться утилитой find:

Если нужно смотреть не только количество файлов в папке, но и подпапок, просто не нужно использовать -type f:

Только папки отдельно:

А в случае, когда необходимо перебрать все файлы во всех подпапках, не устанавливайте параметр -maxdepth:

Все эти команды это очень хорошо, но есть еще одно, более удобное средство посчитать количество файлов linux, это утилита tree.
Пути файлов в Linux
Файловая система Linux очень сильно отличается от Windows. Мы не будем рассматривать ее структуру, это было сделано ранее. Мы сосредоточимся на работе с файлами.
Самое главное отличие, в том что адрес файла начинается не с диска, например, C:\ или D:\ как это происходит в Windows, а с корня, корневого системного каталога, к которому подключены все другие. Его адрес — /. И тут нужно сказать про адреса. Пути файлов linux используют прямой слеш «/» для разделения каталогов в адресе, и это отличается от того, что вы привыкли видеть в Windows — \.
Например, если в Windows полный путь к файлу на рабочем столе выглядел C:\Users\Sergiy\Desktop\ то в путь файла в linux будет просто /home/sergiy/desktop/. С этим пока все просто и понятно. Но проблемы возникают дальше.
В операционной системе Linux может быть несколько видов путей к файлу. Давайте рассмотрим какие бывают пути в linux:
- Полный, абсолютный путь linux от корня файловой системы — этот путь вы уже видели в примере выше, он начинается от корня «/» и описывает весь путь к файлу;
- Относительный путь linux — это путь к файлу относительно текущей папки, такие пути часто вызывают путаницу.
- Путь относительно домашний папки текущего пользователя. — путь в файловой системе, только не от корня, а от папки текущего пользователя.
Рассмотрим теперь подробнее как выглядят эти пути в linux, а также разберем несколько примеров, чтобы было окончательно понятно. Для демонстрации будем пользоваться утилитой ls, которая предназначена для просмотра содержимого каталогов.
Например, у нас есть такой каталог в домашней папке с четырьмя файлами в нем:

Вот так будет выглядеть полный путь linux к одному из файлов:

Это уже относительный путь linux, который начинается от домашней папки, она обозначается ~/. Заметьте, не ~, а именно ~/. Дальше вы уже можете указывать подпапки, в нашем случае tmp:

Ну или путь файла в linux, относительно текущей папки:
В каждой папке есть две скрытые ссылки, мы сможем их увидеть с помощью ls, выполнив ее с параметром -a:

Первая ссылка указывает на текущую папку (.), вторая (..) указывает на папку уровнем выше. Это открывает еще более широкие возможности для навигации по каталогам. Например, чтобы сослаться на файл в текущей папке можно использовать конструкцию:

Это бесполезно при просмотре содержимого файла
Но очень важно при выполнении программы. Поскольку программа будет сначала искаться в среде PATH, а уже потом в этой папке
А потому, если нужно запустить программу, которая находится в текущей папке и она называется точно также как и та что в каталоге /bin, то без явной ссылки что файл нужно искать в текущей папке ничего не получится.
Вторая ссылка вам позволяет получить доступ к файлам в папке выше текущей. Например:

Такие конструкции могут довольно часто встречаться при компиляции программ. Все эти символы и пути файлов linux вы можете применять не только в терминале, но и в любом файловом менеджере, что может быть очень удобно.
Но терминал Linux предоставляет еще более широкие возможности. Вы можете использовать простые символы замены прямо в адресах файлов или каталогов. Например, можно вывести все файлы, начинающиеся на f:


Или даже можно искать не только в папке tmp, а в любой подпапке домашней папки:
И все это будет работать, возможно, это не всегда нужно и практично. Но в определенных ситуациях может очень сильно помочь. Эти функции реализуются на уровне оболочки Bash, поэтому вы можете применять их в любой команде. Оболочка смотрит сколько файлов было найдено и для каждого из них вызывает команду.
Основная информация о Find
Find — это одна из наиболее важных и часто используемых утилит системы Linux. Это команда для поиска файлов и каталогов на основе специальных условий. Ее можно использовать в различных обстоятельствах, например, для поиска файлов по разрешениям, владельцам, группам, типу, размеру и другим подобным критериям.
Утилита find предустановлена по умолчанию во всех Linux дистрибутивах, поэтому вам не нужно будет устанавливать никаких дополнительных пакетов. Это очень важная находка для тех, кто хочет использовать командную строку наиболее эффективно.
Команда find имеет такой синтаксис:
find критерий шаблон
Папка — каталог в котором будем искать
Параметры — дополнительные параметры, например, глубина поиска, и т д
Критерий — по какому критерию будем искать: имя, дата создания, права, владелец и т д.
Шаблон — непосредственно значение по которому будем отбирать файлы.