Используем инструменты: grep, xargs и sed
Содержание:
- Основное регулярное выражение
- sed: синтаксический анализ и преобразование текста
- Context line control
- Опции uniq
- Рекурсивный поиск
- Регулярные выражения в терминале Linux
- Синтаксис
- EXAMPLE top
- Basic vs. extended regular expressions
- Берем то, что нам нужно
- Основные параметры команды find
- Example usage
- Краткий обзор
- Character classes and bracket expressions
- 8. Как перечислить только имена файлов, которые соответствуют Grep
- grep — что это и зачем может быть нужно
- Примеры использования sed
Основное регулярное выражение
GNU Grep имеет два набора функций регулярных выражений, Basic и Extended. По умолчанию интерпретирует шаблон как основное регулярное выражение.
При использовании в основном режиме регулярных выражений все остальные символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу. Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (символ каретки), чтобы сопоставить выражение в начале строки. В следующем примере строка ^kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
grep «^kangaroo» file.txt
Используйте символ $ (доллар), чтобы соответствовать выражению в конце строки. В следующем примере строка kangaroo$ будет соответствовать только в том случае, если она встречается в самом конце строки.
grep «kangaroo$» file.txt
Используйте . (точка) символ для соответствия любому отдельному символу. Например, чтобы сопоставить все, что начинается с kan затем имеет два символа и заканчивается строкой roo, вы можете использовать следующий шаблон:
grep «kan..roo» file.txt
использование (скобки) для соответствия любому отдельному символу, заключенному в скобки. Например, найдите строки, которые содержат accept или « accent, вы можете использовать следующий шаблон:
grep «accet» file.txt
использование (скобки) для соответствия любому отдельному символу, заключенному в скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a, такой как coca, cobalt и т. Д., Но не будет совпадать со строками, содержащими cola,
grep «coa» file.txt
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
sed: синтаксический анализ и преобразование текста
sed — это специальный потоковый редактор, который ищет шаблон в тексте и применяет к нему необходимые изменения.
Данный редактор может быть в том числе пакетным или неинтерактивным редактором. Его функции заключаются в том, что он считывает из файла или из (при наличии каналов) по одной строке за раз. При этом исходный входной файл остается неизменным (так как sed также является фильтром), после чего результаты преобразуются в стандартные выходные данные.
Анатомия типичной sed-команды
Опции sed:
- адрес — может быть номером строки, диапазоном или совпадением. Может быть оставлен по умолчанию, либо являться файлом целиком;
- команда — :substitute (замена), :print (печать), :delete (удалить), :append (добавить), :insert (вставить), :quit (завершить);
- regex — регулярные выражения;
- знак-разграничитель — в данном случае необязательно использовать «», можно также применять «» или «» или любой другой символ;
- модификатор — его роль может выполнять число , которое применяет команду к N-му вхождению, применяет ко всей строке в целом;
- общие признаки состояния sed — (без печати), (несколько операций), (чтение sed из файла), (на месте редактирования).
Полезные примеры sed:
- — печать строк с 5 по 9;
- — влияет на 1-е вхождение в стр. 20–30;
- — печать последней строки;
- — удалить первые 3 строки;
- — удалить все пустые строки;
- — заменить всё, кроме York;
- .
Context line control
| -A NUM, —after-context=NUM | Print NUM lines of trailing context after matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -B NUM, —before-context=NUM | Print NUM lines of leading context before matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -C NUM, —NUM, —context=NUM | Print NUM lines of output context. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
Опции uniq
У команды uniq есть такие основные опции:
- -u (—unique) — выводит исключительно те строки, у которых нет повторов.
- -d (—repeated) — если какая-либо строка повторяется несколько раз, она будет выведена лишь единожды.
- -D — выводит только повторяющиеся строки.
- —all-repeated — то же самое, что и -D, но при использовании этой опции между группами из одинаковых строк при выводе будет отображаться пустая строка. может иметь одно из трех значений — none (применяется по умолчанию), separate или prepend.
- —group — выводит весь текст, при этом разделяя группы строк пустой строкой. имеет значения separate (по умолчанию), prepend, append и both, среди которых нужно выбрать одно.
Вместе с основными опциями могут применяться дополнительные. Они нужны для более тонких настроек работы команды:
- -f (—skip-fields=N) — будет проведено сравнение полей, начиная с номера, который следует после указанного вместо буквы N. Поля — это слова, хотя, называть их словами в прямом смысле слова нельзя, ведь словом команда считает любую последовательность символов, отделенную от других последовательностей пробелом либо табуляцией.
- -i (—ignore-case) — при сравнении не будет иметь значение регистр, в котором напечатаны символы (строчные и заглавные буквы).
- -s (—skip-chars=N) — работает по аналогии с -f, однако, игнорирует определенное количество символов, а не строк.
- -c (—count) — в начале каждой строки выводит число, которое обозначает количество повторов.
- -z (—zero-terminated) — вместо символа новой строки при выводе будет использован разделитель строк NULL.
- -w (—check-chars=N) — указание на то, что нужно сравнивать только первые N символов в строках.
Рекурсивный поиск
Для рекурсивного поиска шаблона используйте параметр (или ). Это позволит выполнить поиск по всем файлам в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно. Чтобы по всем символическим ссылкам, используйте опцию (или ).
В следующем примере мы ищем строку во всех файлах в каталоге :
Команда выведет соответствующие строки с префиксом полного пути к файлу.
Если вместо вы используете опцию будет следовать по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода. Эта строка не печатается в приведенном выше примере, потому что файлы в каталоге с Nginx являются символическими ссылками на файлы конфигурации в каталоге
Регулярные выражения в терминале Linux
Регулярное выражение (regex) — это язык описания шаблона строк.
Точка «» является специальным символом, который будет соответствовать любому символу (кроме новой строки). Например, будет соответствовать bat, bbt, b%t и так далее, но при этом сюда не подойдут bt, xbt.
Класс символов: один из элементов в квадратных скобках будет совпадать, при этом допускаются последовательности:
— соотносится с Cat и cat. — соотносится с fate, gate, hate.
Символ «» внутри класса символов означает отрицание, например:
будет соответствовать brat, но не boat или beat.
Расширенные выражения запускаются с помощью или , при этом:
«» соответствует нулю или более, «» соответствует одному или более, «» соответствует нулю или разовому появлению предыдущего символа, например:
будет соответствовать hat, cat, hhat, chat, cchhat и т. д.
«» является разделителем для нескольких шаблонов, а «» и «» позволяют группировать шаблоны, например:
будет соответствовать cat, Cat, dog и Dog.
«» может использоваться для указания диапазона повторения, например:
будет соответствовать baat, baaat и baaaat, но не bat.
Примеры grep
Строки, которые заканчиваются двумя гласными:
Проверка 5 строк до и после строки, где встречается «little»:
Комментируйте команды и выполняйте поиск последних использованных в истории:
Удостоверьтесь, что вы правильно написали все команды и избежали возможных двусмысленностей:
— ещё одна очень полезная комбинация вам на заметку.
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*

Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*

Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test

Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root

Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»

Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file

Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file

Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
EXAMPLE top
The following example outputs the location and contents of any line
containing “f” and ending in “.c”, within all files in the current
directory whose names contain “g” and end in “.h”. The -n option
outputs line numbers, the -- argument treats expansions of “*g*.h”
starting with “-” as file names not options, and the empty file
/dev/null causes file names to be output even if only one file name
happens to be of the form “*g*.h”.
$ grep -n -- 'f.*\.c$' *g*.h /dev/null
argmatch.h:1:/* definitions and prototypes for argmatch.c
The only line that matches is line 1 of argmatch.h. Note that the
regular expression syntax used in the pattern differs from the glob‐
bing syntax that the shell uses to match file names.
Basic vs. extended regular expressions
In basic regular expressions the metacharacters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{, \|, \(, and \).
Traditional versions of egrep did not support the { metacharacter, and some egrep implementations support \{ instead, so portable scripts should avoid { in grep -E patterns and should use to match a literal {.
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification. For example, the command grep -E ‘{1’ searches for the two-character string {1 instead of reporting a syntax error in the regular expression. POSIX allows this behavior as an extension, but portable scripts should avoid it.
Берем то, что нам нужно
Нахождение текста — это очень общая задача, но, как правило, необходимо извлечь необходимый текст после того, как он был найден. Другими словами, нужно достать иголку и отбросить стог сена.
Регулярное выражение извлекает информацию через захват. Если необходимо отделить необходимый текст от остального, то нужно поставить шаблон в скобки. Раньше мы уже использовали скобки для объединения выражений; по умолчанию скобки осуществляют захват автоматически.
Чтобы продемонстрировать захват, перейдем на Perl. (Утилита не поддерживает захват, так как ее цель — это печать строк, содержащих шаблон.)
Команда:
perl -n -e '/^The\s+(.*)$/ && print "$1\n"' heroes.txt
выведет:
Tick Punisher
Команда позволяет запустить команду на языке Perl прямо из командной строки. Команда запускает программу для каждой строки входного файла. Часть команды, являющаяся регулярным выражением, текст между двумя слешами () говорит: «Найти строку, начинающуюся буквами ‘T’, ‘h’, ‘e’, за которыми следует один или более пробелов, , затем захватить все символы до конца строки«.
Захваченный в Perl текст помещается в специальные переменные Perl, начиная с . Оставшаяся часть программы на Perl печатает захваченный текст.
Каждая вложенная пара скобок, считая слева с учетом уровня вложенности скобок, захватывает текст в соответствующую числовую переменную Perl (, и так далее). Например,
perl -n -e '/^(\w)+-(\w+)$/ && print "$1 $2"'
дает следующий результат:
Spider Man Ant Man Spider Woman
Захвата нужного текста обычно недостаточно. Как правило, необходимо заменить его на какой-нибудь другой. Редакторы, такие как и Emacs, объединяют шаблоны поиска и замены, чтобы найти и сразу же заменить текст. Также можно изменять текст из командной строки, используя шаблоны замены и редактор .
Основные параметры команды find
Я не буду перечислять здесь все параметры, рассмотрим только самые полезные.
-P никогда не открывать символические ссылки
-L — получает информацию о файлах по символическим ссылкам
Важно для дальнейшей обработки, чтобы обрабатывалась не ссылка, а сам файл.
-maxdepth — максимальная глубина поиска по подкаталогам, для поиска только в текущем каталоге установите 1.
-depth — искать сначала в текущем каталоге, а потом в подкаталогах
-mount искать файлы только в этой файловой системе.
-version — показать версию утилиты find
-print — выводить полные имена файлов
-type f — искать только файлы
-type d — поиск папки в Linux
Example usage
Let’s say want to quickly locate the phrase «our products» in HTML files on your machine. Let’s start by searching a single file. Here, our PATTERN is «our products» and our FILE is product-listing.html.

A single line was found containing our pattern, and grep outputs the entire matching line to the terminal. The line is longer than our terminal width so the text wraps around to the following lines, but this output corresponds to exactly one line in our FILE.
Note
The PATTERN is interpreted by grep as a regular expression. In the above example, all the characters we used (letters and a space) are interpreted literally in regular expressions, so only the exact phrase will be matched. Other characters have special meanings, however — some punctuation marks, for example. For more information, see: Regular expression quick reference.
If we use the —color option, our successful matches will be highlighted for us:

Viewing line numbers of successful matches
It will be even more useful if we know where the matching line appears in our file. If we specify the -n option, grep will prefix each matching line with the line number:

Our matching line is prefixed with «18:» which tells us this corresponds to line 18 in our file.
Performing case-insensitive grep searches
What if «our products» appears at the beginning of a sentence, or appears in all uppercase? We can specify the -i option to perform a case-insensitive match:

Using the -i option, grep finds a match on line 23 as well.
Searching multiple files using a wildcard
If we have multiple files to search, we can search them all using a wildcard in our FILE name. Instead of specifying product-listing.html, we can use an asterisk («*«) and the .html extension. When the command is executed, the shell expands the asterisk to the name of any file it finds (in the current directory) which ends in «.html«.
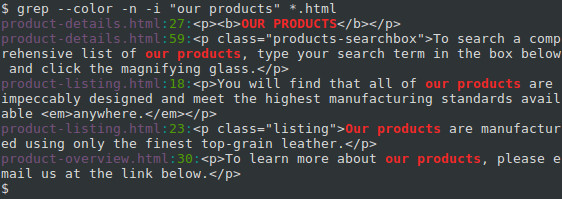
Notice that each line starts with the specific file where that match occurs.
Recursively searching subdirectories
We can extend our search to subdirectories and any files they contain using the -r option, which tells grep to perform its search recursively. Let’s change our FILE name to an asterisk («*«), so that it matches any file or directory name, and not only HTML files:
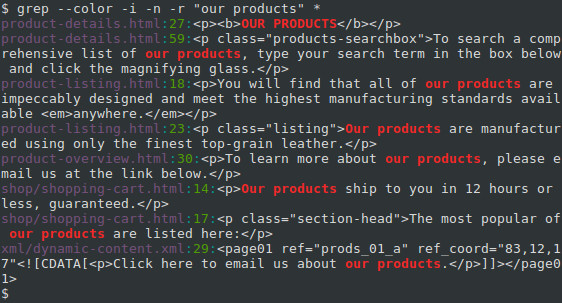
This gives us three additional matches. Notice that the directory name is included for any matching files that are not in the current directory.
Using regular expressions to perform more powerful searches
The true power of grep is that it can match regular expressions. (That’s what the «re» in «grep» stands for). Regular expressions use special characters in the PATTERN string to match a wider array of strings. Let’s look at a simple example.
Let’s say you want to find every occurrence of a phrase similar to «our products» in your HTML files, but the phrase should always start with «our» and end with «products». We can specify this PATTERN instead: «our.*products».
In regular expressions, the period («.«) is interpreted as a single-character wildcard. It means «any character that appears in this place will match.» The asterisk («*«) means «the preceding character, appearing zero or more times, will match.» So the combination «.*» will match any number of any character. For instance, «our amazing products«, «ours, the best-ever products«, and even «ourproducts» will match. And because we’re specifying the -i option, «OUR PRODUCTS» and «OuRpRoDuCtS will match as well. Let’s run the command with this regular expression, and see what additional matches we can get:
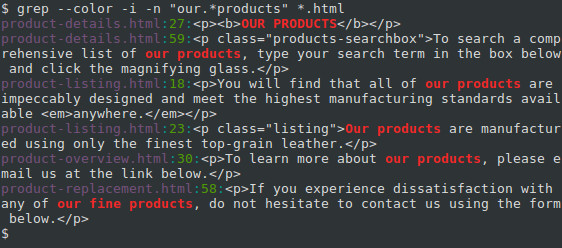
Here, we also got a match from the phrase «our fine products«.
Grep is a powerful tool to help you work with text files, and it gets even more powerful when you become comfortable using regular expressions.
Краткий обзор
Из этой статьи вы узнаете об основных приемах поиска текста в текстовых файлах с использованием регулярных выражений в Linux. Вы научитесь:
- Строить простые регулярные выражения.
- Выполнять поиск в файлах и файловой системе с использованием регулярных выражений.
- Использовать регулярные выражения совместно с sed.
Об этой серии
Эта серия статей поможет вам освоить задачи администрирования операционной системы Linux. Вы также можете использовать материал этих статей для подготовки к экзаменам первого уровня сертификации профессионального института Linux (LPIC-1).
Чтобы посмотреть описания статей этой серии и получить ссылки на них, обратитесь к нашему перечню материалов для подготовки к экзаменам LPIC-1. Этот перечень постоянно дополняется новыми статьями по мере их готовности и содержит самые последние (по состоянию на апрель 2009 года) цели экзаменов сертификации LPIC-1. Если какая-либо статья отсутствует в перечне, можно найти ее более раннюю версию, соответствующую предыдущим целям LPIC-1 (до апреля 2009 года), обратившись к нашим руководствам для подготовки к экзаменам института Linux Professional Institute.
Эта статья поможет вам подготовиться к сдаче экзамена LPI 101 на администратора начального уровня (LPIC-1) и содержит материалы цели 103.7 темы 103. Цель имеет вес 2.
Чтобы извлечь наибольшую пользу из наших статей, необходимо обладать базовыми знаниями о Linux и иметь работоспособный компьютер с Linux, на котором можно будет выполнять все встречающиеся команды. Иногда различные версии программ выводят результаты по-разному, поэтому содержимое листингов и рисунков может отличаться от того, что вы увидите на вашем компьютере. В основе этой статьи лежит концепция, описанная в одной из предыдущих статей этой серии «Изучаем Linux 101: текстовые потоки и фильтры».
Character classes and bracket expressions
A bracket expression is a list of characters enclosed by and . It matches any single character in that list; if the first character of the list is the caret ^ then it matches any character not in the list. For example, the regular expression matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, is equivalent to . Many locales sort characters in dictionary order, and in these locales is often not equivalent to ; it might be equivalent to , for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are , , , , , , , , , , and . For example, ] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as . (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most metacharacters lose their special meaning inside bracket expressions. To include a literal place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal —, place it last.
8. Как перечислить только имена файлов, которые соответствуют Grep
grep -l 'term' * .c
Параметры команды Grep
Далее мы увидим различные переменные, которые Grep предлагает нам для управления в Linux:
-num: с этой опцией совпадающие строки будут рядом с предыдущим и последующим номерами строк.
-А нет, —after-context = NUM: Отображает количество строк контекста после того, как они соответствуют указанным.
-B num, —before-context = NUM: при использовании этой опции контекстные строки будут отображаться перед теми, которые соответствуют поиску.
-V, —version: отображает используемый номер версии grep.
-b, —byte-offset: этот параметр отображает смещение в байтах от начала входного файла перед каждой выходной строкой этого файла.
-c, —count: подсчитать количество строк, соответствующих указанному термину.
-h, —no-filename: подавить печать имен файлов в результате.
i, —ignore-case: не учитывает, являются ли буквы прописными или строчными.
-L, —files-without-match: эта опция показывает имя каждого входного файла, в котором не найдено совпадений.
-l, —files-with-match: показывает имя каждого входного файла, который может генерировать некоторый результат.
-n, —line-number: назначить каждой выходной строке соответствующий номер строки в файле поиска.
-q, —quiet: активирует тихий режим, который подавляет нормальный вывод, и поиск заканчивается при первом совпадении.
-s, —silent: подавить сообщения об ошибках.
-v, — invert-match: эта опция меняет смысл поиска, то есть отображает результаты, которые не соответствуют искомому термину.
w, —word-regexp: этот параметр выбирает только те строки, которые содержат совпадения, образующие целые слова.
-x, —line-regexp: эта опция выбирает только совпадения, которые состоят из всей строки.
grep — что это и зачем может быть нужно
Про «репку» (как я её называю) почему-то в курсе не многие, что печалит. «Унылая» (не в обиду) формулировка из Википедии звучит примерно так:
grep — утилита командной строки, которая находит на вводе строки, отвечающие заданному регулярному выражению, и выводит их, если вывод не отменён специальным ключом.
Не сильно легче, но доступнее, можно сформулировать так:
grep — утилита командной строки, используется для поиска и фильтрации текста в файлах, на основе шаблона, который (шаблон) может быть регулярным выражением.
Если всё еще ничего не понятно, то условно говоря это удобный поиск текста везде и всюду, в особенности в файлах, директория в и тп. Удобно распарсивать логи и их содержимое, не прибегая к софту, как это бывает в Windows.
Справку можно вычленить так же как по find, т.е методом pgrep, fgrep, egrep и черт знает что еще:
Или:
Расписывать все ключи и даже основные тут (вы еще помните, что это блоговая часть сайта?) не буду, так как в отличии от find’а, последних тут вообще страшное подмножество, особенно учитывая, что существуют pgrep, fgrep, egrep и черт знает что еще, которые, в некотором смысле тоже самое, но для определенных целей.
Потрясающе удобная штука, которая жизненно необходима, особенно, если Вы что-то когда-то где-то зачем-то администрировали. Взглянем на примеры.
Примеры использования sed
Теперь рассмотрим примеры sed Linux, чтобы у вас сложилась целостная картина об этой утилите. Давайте сначала выведем из файла стройки с пятой по десятую. Для этого воспользуемся командой -p. Мы используем опцию -n чтобы не выводить содержимое буфера шаблона на каждой итерации, а выводим только то, что нам надо. Если команда одна, то опцию -e можно опустить и писать без неё:

Или можно вывести весь файл, кроме строк с первой по двадцатую:

Здесь наоборот, опцию -n не указываем, чтобы выводилось всё, а с помощью команды d очищаем ненужное. Дальше рассмотрим замену в sed. Это самая частая функция, которая применяется вместе с этой утилитой. Заменим вхождения слова root на losst в том же файле и выведем всё в стандартный вывод:

Флаг g заменяет все вхождения, также можно использовать флаг i, чтобы сделать регулярное выражение sed не зависимым от регистра. Для команд можно задавать адреса. Например, давайте выполним замену 0 на 1000, но только в строках с первой по десятую:

Переходим ещё ближе к регулярным выражением, удалим все пустые строки или строи с комментариями из конфига Apache:

Под это регулярное выражение (адрес) подпадают все строки, которые начинаются с #, пустые, или начинаются с пробела, а за ним идет решетка. Регулярные выражения можно использовать и при замене. Например, заменим все вхождения p в начале строки на losst_p:

Если вам надо записать результат замены в обратно в файл можно использовать стандартный оператор перенаправления вывода > или утилиту tee. Например:
Также можно использовать опцию -i, тогда утилита не будет выполнять изменения в переданном ей файле:

Если надо сохранить оригинальный файл, достаточно передать опции -i в параметре расширение для файла резервной копии.