Устранение проблем с кодировкой в windows 7
Содержание:
- Выбор кодировки при сохранении файла
- Параметры веб-страницы HTML
- Виды кодировок текста
- Выбор подходящей кодировкиChoosing the right encoding
- Текст и параметры XML
- Как «увидеть», что скрывается за непонятными символами на сайте?
- О программе
- Кракозябры вместо русских букв в Windows 10
- Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
- Что такое кодировка текста и с чем ее едят?
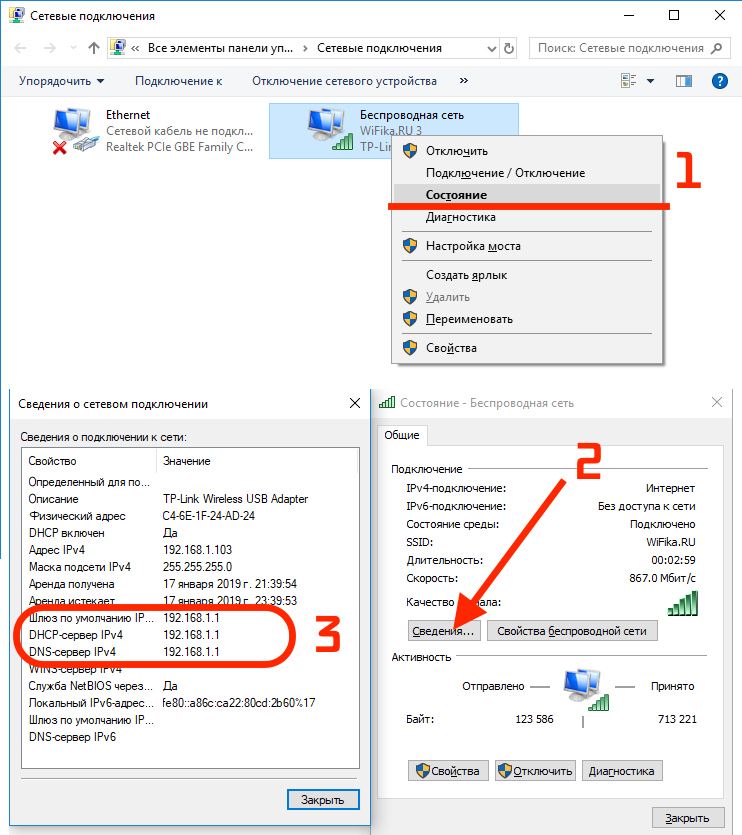
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание:
Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк
и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в полеЗавершать строки .
Параметры веб-страницы HTML
Одна страница HTML
Указывает, что при экспорте в формат HTML создается один файл HTML. Чтобы добавить панель навигации, включите следующие параметры:
Добавить кадр навигации на базе заголовков
Добавить кадр навигации на базе закладок
Несколько страниц HTML
Указывает, что при экспорте в формат HTML создается несколько файлов HTML. Чтобы разделить документ на несколько файлов HTML, выберите один из критериев.
Разделить по заголовкам документа
Разделить по закладкам документа
Указывает, экспортировать ли изображения при экспорте файла PDF в HTML.
Найти и удалить верхний и нижний колонтитулы
Указывает, необходимо ли удалить содержимое верхнего и нижнего колонтитулов в документе PDF из файлов HTML.
Распознать текст при необходимости
Распознает текст, если файл PDF содержит изображения с текстом.
Указывает язык для оптического распознавания символов.
Виды кодировок текста
А их, в общем-то, хватает.
ASCII
Одной из самых “древних” считается американская кодировочная таблица (ASCII, читается как “аски”), принятая национальным институтом стандартов. Для кодировки она использовала 7 битов, в первых 128 значениях размещался английский алфавит (в нижнем и верхнем регистрах), а также знаки, цифры и символы. Она больше подходила для англоязычных пользователей и не была универсальной.
Кириллица
Отечественный вариант кодировки, для которого стали использовать вторую часть кодовой таблицы – символы с 129 по 256. Заточена под русскоязычную аудиторию.
Кодировки семейства MS Windows: Windows 1250-1258.
8-битные кодировки, появились как следствие разработки самой популярной операционной системы, Windows. Номера с 1250 по 1258 указывают на язык, под который они заточены, например, 1250 – для языков центральной Европы; 1251 – кириллический алфавит.
Код обмена информацией 8 бит – КОИ8
KOI8-R, KOI8-U, KOI-7 – стандарт для русской кириллицы в юникс-подобных операционных системах.
Юникод (Unicode)
Универсальный стандарт кодирования символов, позволяющий описать знаки практически всех письменных языков. Обозначение “U+xxxx” (хххх – 16-ричные цифры). Самые распространенные семейства кодировок UTF (Unicode Transformation Format): UTF-8, 16, 32.
В настоящее время, как говорится, “рулит” UTF-8 – именно она обеспечивают наилучшую совместимость со старыми ОС, которые использовали 8-битные символы. В UTF-8 кодировке находятся большинство сайтов в сети Интернет и именно этот стандарт является универсальным (поддержка кириллицы и латиницы).
Разумеется, я привел не все виды кодировок, а только наиболее ходовые. Если же Вы хотите для общего развития знать их все, то полный список можно отыскать в самом браузере. Для этого достаточно пройти в нем на вкладку “Вид-Кодировка-Выбрать список” и ознакомиться со всевозможными их вариантами (см. изображение).
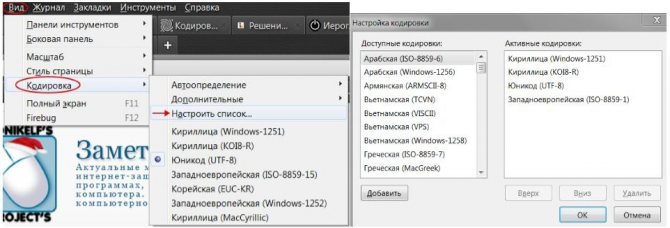
Думаю возник резонный вопрос: “Какого лешего столько кодировок?”. Их изобилие и причины возникновения можно сравнить с таким явлением, как кроссбраузерность/кроссплатформенность. Это когда один и тот же сайт сайт отображается по-разному в различных интернет-обозревателях и на различных гаджет-устройствах. Кстати у сайта «Заметки Сис.Админа» с этим, как Вы заметили всё в порядке :).
Все эти кодировки – рабочие варианты, созданные разработчиками “под себя” и решение своих задач. Когда же их количество перевалило за все разумные пределы, а в поисковиках стали плодиться запросы типа: “Как убрать кракозябры в браузере?” — разработчики стали ломать голову над приведением всей этой каши к единому стандарту, чтобы, так сказать, всем было хорошо. И кодировка Unicode, в общем-то, это “хорошо” и сделала. Теперь если такие проблемы и возникают, то они носят локальный характер, и не знают как их исправить только совсем непросвещенные пользователи (впрочем, часто беда с кодировкой и отображением сайтов появляется из-за того, что веб-мастер указал на стороне сервера некорректный формат, и приходится переключать кодировку в браузере).
Ну вот, собственно, пока вся «базово необходимая» теория, которая позволит Вам “не плавать” в кодировочных вопросах, теперь переходим к практической части статьи.
Выбор подходящей кодировкиChoosing the right encoding
Различные системы и приложения могут использовать различные кодировки:Different systems and applications can use different encodings:
- В .NET Standard, в Интернете и в среде Linux теперь в основном используется кодировка UTF-8.In .NET Standard, on the web, and in the Linux world, UTF-8 is now the dominant encoding.
- Во многих приложениях .NET Framework используется UTF-16.Many .NET Framework applications use UTF-16. По историческим причинам ее иногда называют «Юникод»; сейчас этот термин относится к более широкому стандарту, охватывающему UTF-8 и UTF-16.For historical reasons, this is sometimes called «Unicode», a term that now refers to a broad standard that includes both UTF-8 and UTF-16.
- В Windows многие приложения, которые были созданы еще до распространения Юникода, по-прежнему могут по умолчанию использовать Windows-1252.On Windows, many native applications that predate Unicode continue to use Windows-1252 by default.
Кодировки Юникода также используют понятие метки порядка следования байтов (BOM).Unicode encodings also have the concept of a byte-order mark (BOM). BOM ставится в начале текста, чтобы декодер мог определить, какая кодировка используется в тексте.BOMs occur at the beginning of text to tell a decoder which encoding the text is using. Для многобайтовых кодировок BOM также указывает порядок следования байтов кодировки.For multi-byte encodings, the BOM also indicates endianness of the encoding. BOM представляются байтами, которые редко встречаются в тексте в Юникоде. Это позволяет сделать обоснованное предположение, что текст записан в Юникоде, если присутствует метка BOM.BOMs are designed to be bytes that rarely occur in non-Unicode text, allowing a reasonable guess that text is Unicode when a BOM is present.
BOM не являются обязательными; в мире Linux они не так популярны, поскольку во всех прочих местах используется надежное соглашение UTF-8.BOMs are optional and their adoption isn’t as popular in the Linux world because a dependable convention of UTF-8 is used everywhere. Большинство приложений Linux предполагают, что текстовый ввод кодируется в UTF-8.Most Linux applications presume that text input is encoded in UTF-8. Хотя многие приложения Linux могут распознавать и правильно обрабатывать BOM, некоторые этого не делают, что приводит к появлению артефактов в тексте, открываемом с помощью этих приложений.While many Linux applications will recognize and correctly handle a BOM, a number do not, leading to artifacts in text manipulated with those applications.
Таким образом :Therefore :
- Если вы работаете в основном с приложениями Windows и Windows PowerShell, следует предпочтительно использовать такие кодировки, как UTF-8 с BOM или UTF-16.If you work primarily with Windows applications and Windows PowerShell, you should prefer an encoding like UTF-8 with BOM or UTF-16.
- Если вы работаете на разных платформах, следует отдавать предпочтение UTF-8 с BOM.If you work across platforms, you should prefer UTF-8 with BOM.
- Если вы работаете главным образом в контексте Linux, следует отдавать предпочтение UTF-8 без BOM.If you work mainly in Linux-associated contexts, you should prefer UTF-8 without BOM.
-
Windows-1252 и latin-1 — устаревшие кодировки, которых по возможности следует избегать.Windows-1252 and latin-1 are essentially legacy encodings that you should avoid if possible.
Тем не менее некоторые приложения предыдущих версий в Windows зависят от их.However, some older Windows applications may depend on them. - Также стоит отметить, что подписывание скриптов зависит от кодировки, то есть изменение кодировки в подписанном скрипте потребует повторного подписывания.It’s also worth noting that script signing is encoding-dependent, meaning a change of encoding on a signed script will require resigning.
Текст и параметры XML
Двоичные значения на основе международных стандартов, используемых для представления текстовых символов. UTF-8 – кодировка Юникода, в которой на каждый символ приходится один или несколько байтов по 8 бит, а в кодировке UTF-16 используются байты по 16 бит. ISO-Latin-1 – 8-битовое представление символов, являющееся расширением набора ASCII. UCS-4 – универсальный набор символов с кодировкой в 4 октетах. HTML/ASCII – 7-битовое представление символов, разработанное Американским национальным институтом стандартизации.
В таблице преобразования по умолчанию используется кодировка по умолчанию, определенная в таблицах преобразования, расположенных в папке Plug-ins/SaveAsXML/MappingTables. Такие таблицы соответствия определяют различные характеристики вывода данных, включая следующие стандартные кодировки: UTF-8 (сохранение в виде XML или HTML 4.0.1) и HTML/ASCII (сохранение в виде HTML 3.2).
Создает закладки для перехода по содержимому документов HTML или XML. Закладки размещаются в начале создаваемого документа HTML или XML.
Создать теги в файлах, в которых они отсутствуют
Создает теги для файлов, в которых они отсутствуют (например, для файлов PDF, созданных с помощью Acrobat 4.0 или более ранних версий). Если этот параметр не установлен, неразмеченные файлы не преобразуются.
Теги создаются только в процессе преобразования, затем они удаляются. С помощью этого метода нельзя создавать файлы PDF с тегами из устаревших файлов
Контролирует преобразование изображений. Ссылки на преобразованные файлы изображений находятся в документах XML и HTML.
Использовать вложенную папку
Задает папку, в которую сохраняются созданные изображения. По умолчанию используется папка Images.
Задает префикс, добавляемый к именам файлов изображений (на тот случай, если будет создано нескольких версий одного файла изображения). Изображениям присваиваются имена в формате имяфайла_img_#.
Задает выходной формат изображений. Формат по умолчанию – JPG.
Понижает разрешение графических файлов до заданного разрешения. Если эта опция не используется, файлы изображений сохраняются с разрешением исходных файлов. Увеличение разрешения файлов не используется никогда.
На посты, размещаемые в Twitter и Facebook, условия Creative Commons не распространяются.
Как «увидеть», что скрывается за непонятными символами на сайте?
Если вы зашли на веб-страницу, видите «кракозябры» и хотите увидеть нормальный текст, то тут только два пути:
- сообщить сайтовладельцу, чтобы всё настроил как следует
- попытаться угадать кодировку самостоятельно. Делается это стандартными средствами браузеров. В Chrome, например, нужно в меню щёлкнуть «Инструменты => Кодировка» и из огромного списка выбрать подходящий набор символов (т.е. угадать).
К счастью, практически все современные веб-проекты делаются в кодировке UTF-8, которая является «универсальной» для разных алфавитов и поэтому всё менее и менее вероятно увидеть эти непонятные символы в Интернет.
Случайные публикации:
Какой хостинг выбрать? На что обратить внимание, выбирая хостинг для сайта (мощность сервера, технологии, цены, uptime…)Выбирая хостинг для своего будущего проекта в Интернете, желатель…
BaZZaro.ru — партнерка для юридического трафикаДавно я не делал обзоры партнерских программ в блоге, в этом месяце точно. Ис…
Чем может быть полезен инструмент Проверить URL от Яндекса?…как сделать 301 редирект в WP?
Для чего нужна и какой должна быть
Как активировать карту Яндекс.Денег и получить пин-код? Снятие наличных в банкоматах и комиссииПосле моей статьи о банковской карте Яндекс.Денег у многих во…
Как заказать пластиковую карту QIWI Visa Plastic (QVP)…росто и наглядно.
Официальное видео (почему-то без звука):
В общем, оформляется . Оставьте комментарий:
Оставьте комментарий:
О программе
Здравствуйте! Эта страница может пригодиться, если вам прислали текст (предположительно на кириллице), который отображается в виде странной комбинации загадочных символов. Программа попытается угадать кодировку, а если не получится, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую.
Использование
- Скопируйте текст в большое текстовое поле дешифратора. Несколько первых слов будут проанализированы, поэтому желательно, чтобы в них содержалась (закодированная) кириллица.
- Программа попытается декодировать текст и выведет результат в нижнее поле.
- В случае удачной перекодировки вы увидите текст в кириллице, который можно при необходимости скопировать и сохранить.
- В случае неудачной перекодировки (текст не в кириллице, состоящий из тех же или других нечитаемых символов) можно выбрать из нового выпадающего списка вариант в кириллице (если их несколько, выбирайте самый длинный). Нажав OK вы получите корректный перекодированный текст.
- Если текст перекодирован лишь частично, попробуйте выбрать другие варианты кириллицы из выпадающего списка.
Ограничения
- Если текст состоит из вопросительных знаков («???? ?? ??????»), то проблема скорее всего на стороне отправителя и восстановить текст не получится. Попросите отправителя послать текст заново, желательно в формате простого текстового файла или в документе LibreOffice/OpenOffice/MSOffice.
-
Не любой текст может быть гарантированно декодирован, даже если есть вы уверены на 100%, что он написан в кириллице.
- Анализируемый и декодированный тексты ограничены размером в 100 Кб.
- Программа не всегда дает стопроцентную точность: при перекодировке из одной кодовой страницы в другую могут пропасть некоторые символы, такие как болгарские кавычки, реже отдельные буквы и т.п.
- Программа проверяет максимум 7245 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Обычно возможные и отображаемые верные варианты находятся между 32 и 255.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
Условия использования
Пожалуйста, обратите внимание на то, что данная бесплатная программа создана с надеждой, что она будет полезна, но без каких-либо явных или косвенных гарантий пригодности для любого практического использования. Вы можете пользоваться ей на свой страх и риск.. Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Переводчики
Русский (Russian) : chAlx ; Пётр Васильев (http://yonyonson.livejournal.com/)
Страница подготовки переводов на другие языки находится тут.
Что нового
October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
На английской версии страницы доступен changelog программы.
Вернуться к кириллической виртуальной клавиатуре.
Кракозябры вместо русских букв в Windows 10
В процессе работы в Windows 10 может возникнуть ситуация, когда русские символы в системе перестают корректно отображаться. Вместо них мы видим нечто невразумительное, некие иероглифы или кракозябры, не обладающие каким-либо практическим смыслом. Обычно такое случается, когда неправильно выбрана локаль в региональных настройках.
Частенько это имеет место быть, когда вы работаете с русскоязычными символами в операционке с английской локализацией, поскольку в ней для русскоязычной программы по умолчанию отсутствуют средства обработки кириллицы, да и какого-либо другого языка с нелатинскими символами, будь это греческая, китайская либо японская языковая конструкция. В этой статье я расскажу, как убрать кракозябры в Windows 10, и вместо них работать с корректно отображающимися русскими символами.
Обычно кракозябры отображаются не везде. К примеру, кириллические символы в названиях программ на рабочем столе написаны абсолютно правильно, без ошибок, а вот если запустить на инсталляцию один из дистрибутивов с поддержкой русского языка, то тут же все начинает идти вкривь и вкось, текст становится нечитаемым, и вы буквально не знаете, что делать.
Ниже я расскажу, как избавиться от этой проблемы, решив ее в свою пользу раз и навсегда.
Стоит понимать, что вся проблема в том, что в вашей операционной системе изначально отсутствует поддержка кириллицы. Скорее всего, вы установили дистрибутив на английском языке, и поверх него установили расширенный пакет для русификации системы, но это не решает всех проблем. Текст все равно является нечитаемым, а описанная проблема остается и никуда не исчезает.
Первое, что может прийти в голову в данной ситуации — это переставить ОС с нуля на русскую версию, где изначально уже присутствует поддержка кириллических символов. Но предположим, что этот вариант для вас не годится, поскольку вы хотите работать именно в англоязычной среде, где все символы кириллицы отображаются корректно и без багов. Именно о такой ситуации и пойдет речь в моей инструкции, которая в этом случае и придется вам как никогда кстати.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:

Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Что такое кодировка текста и с чем ее едят?
Начать хотелось бы с того, что этой статьи могло бы и не быть, т.к. компьютерно-юзательная жизнь автора этих строк протекала вполне себе спокойно и достойно. Но вот в один прекрасный день, шляясь по просторам сети Интернет не со своего ПК, я столкнулся с непонятными явлениями на некоторых сайтах. Заходя на интернет-ресурсы, я видел не привычный нам русский алфавит и красивый понятный текст, а какую-то ересь в виде непонятной последовательности символов. Выглядела она примерно вот так (см. изображение).
Сначала я подумал, что моя любимая Мозилка (браузер Firefox) перегрелась и ей пора вызывать неотложку, но потом начал понимать, что проблема, скорее всего, на стороне ресурса сети и кроется она в неправильно настроенной кодировке. Это действительно оказалось так, и пошаманив немного с бубном, проблемка была оперативно решена. Результатом же всех моих любовных похождений и стал сегодняшний материал. Собственно, поехали разбираться в деталях.
Всю информацию, представленную в цифровом виде и находящуюся в глобальной паутине, нужно рассматривать с двух сторон: первая — со стороны пользователя (красивый и ухоженный текст на экране монитора) и вторая – со стороны поисковой машины (некий программный код, состоящий из различных тегов/метатегов, таблицы символов и прочее).
Если Вы хоть немного знакомы с языком разметки гипертекста (HTML), то должны быть в курсе, что сайт глазами поисковых машин (Google, Яндекс) видится не как обычный текст, а как структурированный документ, состоящий из последовательностей различного рода тегов. Чтобы было понятней, о чем я говорю, давайте взглянем на всеми нами любимый сайт Заметки Сис.Админа” проекта , но не глазами обычного пользователя, а «глазами» поисковика. Для этого нажимаем сочетание клавиш Сtrl+U (для браузеров Firefox и Chrome) и видим следующую картину (см. изображение):
Перед нами машинный вариант sonikelf.ru, вот в таком вот непрезентабельном виде он подается поисковым системам и именно в таком виде они его и кушают. Если бы мы просто взяли и “засандалили” варианты статей из блокнота или Word обычным текстом, машины бы им не то что подавились, они бы даже и есть его не стали. Итак, перед нами главная страница проекта в HTML-виде
Обратите внимание на строку с надписью UTF-8, это не что иное, как пресловутая кодировка текста страницы, именно она и отвечает за формат вывода информации в презентабельном виде, в результате чего через браузер мы видим нормальный текст
Теперь давайте разберемся, почему же происходит так, что порой на экране монитора мы видим кракозябры. Все очень просто, проблема кроется в открытии файла в неверной кодировке. Если перевести на бытовой язык, то допустим Вас послали в магазин за молоком, а Вы притарабанили хлеб, вроде бы тоже съестное, но совсем другой формат продукта.
Итак, теперь давайте разбираться с теорией и для этого введем некоторые определения.
- Кодировка (или “Charset”) – соответствие набора символов набору числовых значений. Нужна для “сливания” информации в интернет, т.е. текстовая информация преобразуется в биты данных;
- Кодовая страница (“Codepage”) – 1 байтовая (8 бит) кодировка;
- Количество значений, принимаемое 1 байтом – 256 (два в восьмой).
Соответствие “символ-изображение” задается с помощью специальных кодовых таблиц, где каждому символу уже присвоен свой конкретный числовой код. Таких таблиц существует достаточно много, и в разных таблицах один и тот же символ может идентифицироваться по-разному (ему могут соответствовать разные числовые коды).
Все кодировки различаются количеством байт и набором специальных знаков, в которые преобразуется каждый символ исходного текста.
Примечание:Декодирование – операция, в результате которой происходит преобразование кода символа в изображение. В результате этой операции информация выводится на экран монитора пользователя.
В общем.. С определениями разобрались, а теперь давайте узнаем, какие же (кодировки) бывают.