Тип данных
Содержание:
- Определение
- Классы памяти
- Символьный тип
- Числовое расширение
- Что такое JavaScript?
- Десятичный тип данных
- Конвертация чисел в экспоненциальную запись
- Вещественные типы данных
- Размер основных типов данных в C++
- Массивы
- Вещественные типы
- Примечания
- Мультимедиа данные
- Типы данных Access
- Базовые типы
- Объединения
- Деление целочисленных переменных
- Конвертация C-style
- Структуры
- Примитивный тип данных (Primitive)
- nan и inf
Определение
Тип данных характеризует одновременно:
- множество допустимых значений, которые могут принимать данные, принадлежащие к этому типу;
- набор операций, которые можно осуществлять над данными, принадлежащими к этому типу.
Первое свойство можно рассматривать как теоретико-множественное определение понятия типа; второе — как процедурное (или поведенческое) определение.
Кроме этого, в программировании используется низкоуровневое определение типа — как заданных размерных и структурных характеристик ячейки памяти, в которую можно поместить некое значение, соответствующее этим характеристикам. Такое определение является частным случаем теоретико-множественного. На практике, с ним связан ряд важных свойств (обусловленных особенностями организации памяти компьютера), требующих отдельного рассмотрения.
Теоретико-множественное определение, особенно в низкоуровневом варианте, чаще всего используется в императивном программировании. Процедурное определение в большей степени связывается с параметрическим полиморфизмом. Объектно-ориентированное программирование использует процедурное определение при описании взаимодействия компонентов программы, и теоретико-множественное — при описании реализации этих компонентов на ЭВМ, соответственно, рассматривая «класс-как-поведение» и «класс-как-объект в памяти»[источник не указан 1326 дней].
Операция назначения типа информационным сущностям называется типизацией. Назначение и проверка согласования типов может осуществляться заранее (статическая типизация), непосредственно при использовании (динамическая типизация) или совмещать оба метода. Типы могут назначаться «раз и навсегда» (сильная типизация) или позволять себя изменять (слабая типизация).
Типы позволяют избежать парадокса Рассела, в частности, Чёрч ввёл типы в лямбда-исчисление именно с этой целью.
В естественном языке за типизацию отвечают вопросительные местоимения.
Единообразная обработка данных разных типов называется полиморфизмом.
Понятие типобезопасности опирается преимущественно на процедурное определение типа. Например, попытка деления числа на строку будет отвергнута большинством языков, так как для этих типов не определено соответствующее поведение. Слабо типизированные языки тяготеют к низкоуровневому определению. Например, «число» и «запись» имеют различное поведение, но адреса «записи» в памяти ЭВМ может иметь то же низкоуровневое представление, что и «число». Слабо типизированные языки предоставляют возможность нарушить систему типов, назначив этому значению поведение «числа» посредством операции приведения типа. Подобные трюки могут использоваться для повышения эффективности программ, но несут в себе риск крахов, и поэтому в безопасных языках не допускаются, либо жёстко обособляются.
К неполным по Тьюрингу языкам описания данных (таким как SGML) процедурное определение обычно неприменимо[источник не указан 1326 дней].
Классы памяти
Переменные, независимо от их типа, имеют свою область видимости и время существования.

Классы памяти:
- auto;
- static;
- extern;
- register.
Все переменные в языке Си по умолчанию являются локальными. Они могут использоваться только внутри функции или блока. По завершении функции их значение уничтожается.
Статическая переменная также является локальной, но вне своего блока может иметь другое значение, а между вызовами функции значение сохраняется.
Внешняя переменная является глобальной. Она доступна в любой части кода и даже в другом файле.
Регистровая переменная рекомендует компилятору сохранять значение в оперативную память.
Спецификаторы типов данных в Си могут не указываться в таких случаях:
- Все переменные внутри блока не являются переменными, соответственно, если предполагается использование именно этого класса памяти, то спецификатор auto не указывается.
- Все функции, объявленные вне блока или функции, являются по умолчанию глобальными, поэтому спецификатор extern не обязателен.
Символьный тип
Значениями символьного типа являются символы, которые можно набрать на клавиатуре компьютера. Это позволяет представить в программе текст и производить над ним различные операции: вставлять, удалять отдельные буквы и слова, форматировать и т.д.
Символьный тип обозначается зарезервированным словом Char и предназначен для хранения одного символа. Данные символьного типа в памяти занимают один байт.
Формат объявления символьной переменной:
<имя переменной>: Char;
При определении значения символьной переменной символ записывается в апострофах. Кроме того, задать требуемый символ можно указанием непосредственно его числового значения ASCII-кода. В этом случае необходимо перед числом, обозначающим код ASCII необходимого символа, поставить знак #.
Пример использования переменных символьного типа:
Var
c:char; {c – переменная символьного типа}
Begin
c:=’A’; {переменной c присваивается символ ’A’}
c:=#65; {переменной c также присваивается символ A. Его ASCII код равен 65}
c:=’5’; {переменной c присваивается символ 5,
End. здесь 5 это уже не число}
Числовое расширение
Когда значение из одного типа данных конвертируется в другой тип данных побольше (по размеру и по диапазону значений), то это называется числовым расширением. Например, тип int может быть расширен в тип long, а тип float может быть расширен в тип double:
long l(65); // расширяем значение типа int (65) в тип long
double d(0.11f); // расширяем значение типа float (0.11) в тип double
|
1 |
longl(65);// расширяем значение типа int (65) в тип long doubled(0.11f);// расширяем значение типа float (0.11) в тип double |
В языке C++ есть два варианта расширений:
Интегральное расширение (или «целочисленное расширение»). Включает в себя преобразование целочисленных типов, меньших, чем int (bool, char, unsigned char, signed char, unsigned short, signed short) в int (если это возможно) или unsigned int.
Расширение типа с плавающей точкой. Конвертация из типа float в тип double.
Интегральное расширение и расширение типа с плавающей точкой используются для преобразования «меньших по размеру» типов данных в типы int/unsigned int или double (они наиболее эффективны для выполнения разных операций).
Важно: Числовые расширения всегда безопасны и не приводят к потере данных
Что такое JavaScript?
Изначально JavaScript был создан, чтобы «сделать веб-страницы живыми».
Программы на этом языке называются скриптами. Они могут встраиваться в HTML и выполняться автоматически при загрузке веб-страницы.
Скрипты распространяются и выполняются, как простой текст. Им не нужна специальная подготовка или компиляция для запуска.
Это отличает JavaScript от другого языка – Java.
Почему JavaScript?
Когда JavaScript создавался, у него было другое имя – «LiveScript». Однако, язык Java был очень популярен в то время, и было решено, что позиционирование JavaScript как «младшего брата» Java будет полезно.
Со временем JavaScript стал полностью независимым языком со своей собственной спецификацией, называющейся ECMAScript, и сейчас не имеет никакого отношения к Java.
Сегодня JavaScript может выполняться не только в браузере, но и на сервере или на любом другом устройстве, которое имеет специальную программу, называющуюся «движком» JavaScript.
У браузера есть собственный движок, который иногда называют «виртуальная машина JavaScript».
Разные движки имеют разные «кодовые имена». Например:
- V8 – в Chrome и Opera.
- SpiderMonkey – в Firefox.
- …Ещё есть «Trident» и «Chakra» для разных версий IE, «ChakraCore» для Microsoft Edge, «Nitro» и «SquirrelFish» для Safari и т.д.
Эти названия полезно знать, так как они часто используются в статьях для разработчиков. Мы тоже будем их использовать. Например, если «функциональность X поддерживается V8», тогда «Х», скорее всего, работает в Chrome и Opera.
Как работают движки?
Движки сложны. Но основы понять легко.
- Движок (встроенный, если это браузер) читает («парсит») текст скрипта.
- Затем он преобразует («компилирует») скрипт в машинный язык.
- После этого машинный код запускается и работает достаточно быстро.
Движок применяет оптимизации на каждом этапе. Он даже просматривает скомпилированный скрипт во время его работы, анализируя проходящие через него данные, и применяет оптимизации к машинному коду, полагаясь на полученные знания. В результате скрипты работают очень быстро.
Десятичный тип данных
Для представления чисел с плавающей точкой высокой точности предусмотрен также
десятичный тип decimal, который предназначен для применения в финансовых расчетах. Этот тип
имеет разрядность 128 бит для представления числовых значений в пределах от 1Е-28
до 7,9Е+28. Вам, вероятно, известно, что для обычных арифметических вычислений
с плавающей точкой характерны ошибки округления десятичных значений. Эти ошибки исключаются при использовании типа decimal, который позволяет представить
числа с точностью до 28 (а иногда и 29) десятичных разрядов. Благодаря тому что этот
тип данных способен представлять десятичные значения без ошибок округления, он
особенно удобен для расчетов, связанных с финансами:
Результатом работы данной программы будет:
Конвертация чисел в экспоненциальную запись
Для конвертации чисел в экспоненциальную запись необходимо следовать процедуре, указанной ниже:
Ваш экспонент начинается с нуля.
Переместите разделительную точку (которая разделяет целую и дробную части) влево, чтобы слева от нее осталась только одна ненулевая цифра:
каждое перемещение точки влево увеличивает экспонент на ;
каждое перемещение точки вправо уменьшает экспонент на .
Откиньте все нули перед первой ненулевой цифрой в целой части.
Откиньте все конечные нули в правой (дробной) части, только если исходное число является целым (без разделительной точки).
Рассмотрим примеры:
Самое главное, что нужно запомнить — это то, что цифры в мантиссе (часть перед ) называются значащими цифрами. Количество значащих цифр определяет точность самого значения. Чем больше цифр в мантиссе, тем точнее значение.
Вещественные типы данных
В языке C существует три типа чисел с плавающей точкой: float и double (двойной точности) и long double. Также существует три формата вывода вещественных чисел, причем они не связаны с типами, а связаны с удобством представления числа. Вещественные числа могут иметь высокую точность, очень маленькое или очень большое значение. Если выполнить функции printf() с такими параметрами:
double a = 0.0005;
printf("%f\n", a);
printf("%g\n", 0.0005);
printf("%g\n", 0.00005);
printf("%e\n", 0.0005);
, то на экране мы увидим следующее:
0.000500 0.0005 5e-05 5.000000e-04
В первом случае (%f) выводится число в обычном виде. По умолчанию точность представления числа равна шести знакам после точки.
Во втором случае (%g) число выводится как обычно, если количество значащих нулей не больше четырех. Если количество значащих нулей четыре и больше, то число выводится в нормализованном виде (третий случай). Запись 5e-5 означает 5 * 10-5, что равно 0.00005. А, например, запись 4.325e+3 является экспоненциальной записью 4.325 * 103, что равно 4325. Если с такой формой представления чисел вы сталкиваетесь первый раз, то почитайте дополнительные источники, например, статью в Википедии «Экспоненциальная запись».
Четвертый формат (%e) выведет число исключительно в нормализованном виде, каким бы это вещественное число ни было.
Если при выводе требуется округлить число до определенной точности, то перед буквой-форматом ставят точку и число-указатель точности. Например, printf(«%.2f», 0.23) выведет на экран 0.23, а не 0.230000. Когда требуется указать еще и поле, то его ширину прописывают перед точкой, например, %10.3f.
Размер основных типов данных в C++
Возникает вопрос: «Сколько памяти занимают переменные разных типов данных?». Вы можете удивиться, но размер переменной с любым типом данных зависит от компилятора и/или архитектуры компьютера!
Язык C++ гарантирует только их минимальный размер:
| Категория | Тип | Минимальный размер |
| Логический тип данных | bool | 1 байт |
| Символьный тип данных | char | 1 байт |
| wchar_t | 1 байт | |
| char16_t | 2 байта | |
| char32_t | 4 байта | |
| Целочисленный тип данных | short | 2 байта |
| int | 2 байта | |
| long | 4 байта | |
| long long | 8 байт | |
| Тип данных с плавающей запятой | float | 4 байта |
| double | 8 байт | |
| long double | 8 байт |
Фактический размер переменных может отличаться на разных компьютерах, поэтому для его определения используют оператор sizeof.
Оператор sizeof — это унарный оператор, который вычисляет и возвращает размер определенной переменной или определенного типа данных в байтах. Вы можете скомпилировать и запустить следующую программу, чтобы выяснить, сколько занимают разные типы данных на вашем компьютере:
#include <iostream>
int main()
{
std::cout << «bool:\t\t» << sizeof(bool) << » bytes» << std::endl;
std::cout << «char:\t\t» << sizeof(char) << » bytes» << std::endl;
std::cout << «wchar_t:\t» << sizeof(wchar_t) << » bytes» << std::endl;
std::cout << «char16_t:\t» << sizeof(char16_t) << » bytes» << std::endl;
std::cout << «char32_t:\t» << sizeof(char32_t) << » bytes» << std::endl;
std::cout << «short:\t\t» << sizeof(short) << » bytes» << std::endl;
std::cout << «int:\t\t» << sizeof(int) << » bytes» << std::endl;
std::cout << «long:\t\t» << sizeof(long) << » bytes» << std::endl;
std::cout << «long long:\t» << sizeof(long long) << » bytes» << std::endl;
std::cout << «float:\t\t» << sizeof(float) << » bytes» << std::endl;
std::cout << «double:\t\t» << sizeof(double) << » bytes» << std::endl;
std::cout << «long double:\t» << sizeof(long double) << » bytes» << std::endl;
return 0;
}
|
1 |
#include <iostream> intmain() { std::cout<<«bool:\t\t»<<sizeof(bool)<<» bytes»<<std::endl; std::cout<<«char:\t\t»<<sizeof(char)<<» bytes»<<std::endl; std::cout<<«wchar_t:\t»<<sizeof(wchar_t)<<» bytes»<<std::endl; std::cout<<«char16_t:\t»<<sizeof(char16_t)<<» bytes»<<std::endl; std::cout<<«char32_t:\t»<<sizeof(char32_t)<<» bytes»<<std::endl; std::cout<<«short:\t\t»<<sizeof(short)<<» bytes»<<std::endl; std::cout<<«int:\t\t»<<sizeof(int)<<» bytes»<<std::endl; std::cout<<«long:\t\t»<<sizeof(long)<<» bytes»<<std::endl; std::cout<<«long long:\t»<<sizeof(longlong)<<» bytes»<<std::endl; std::cout<<«float:\t\t»<<sizeof(float)<<» bytes»<<std::endl; std::cout<<«double:\t\t»<<sizeof(double)<<» bytes»<<std::endl; std::cout<<«long double:\t»<<sizeof(longdouble)<<» bytes»<<std::endl; return; } |
Вот результат, полученный на моем компьютере:
Ваши результаты могут отличаться, если у вас другая архитектура, или другой компилятор
Обратите внимание, оператор sizeof не используется с типом void, так как последний не имеет размера
Если вам интересно, что значит в коде, приведенном выше, то это специальный символ, который используется вместо клавиши TAB. Мы его использовали для выравнивания столбцов. Детально об этом мы еще поговорим на соответствующих уроках.
Интересно то, что sizeof — это один из 3-х операторов в языке C++, который является словом, а не символом (еще есть new и delete).
Вы также можете использовать оператор sizeof и с переменными:
#include <iostream>
int main()
{
int x;
std::cout << «x is » << sizeof(x) << » bytes» << std::endl;
}
|
1 |
#include <iostream> intmain() { intx; std::cout<<«x is «<<sizeof(x)<<» bytes»<<std::endl; } |
Результат выполнения программы:
На следующих уроках мы рассмотрим каждый из фундаментальных типов данных языка С++ по отдельности.
Массивы
Переменные, содержащие массивы, в языке программирования C объявляются, например, так:
int arr5, numsN; float f_arr100; char str80;
Если при указании количества элементов используется константа, она должна быть определена до своего использования следующим образом (чаще константы определяют вне функций):
#define N 100
На самом деле #define является командой препроцессора, используемой не только для определения констант. Когда препроцессор обрабатывает исходный файл программы, он подставляет во все места, где была упомянута константа, ее значение.
Индексация массивов в языке программирования C начинается с нуля.
Присваивание значений элементам массивов можно произвести сразу или в процессе выполнения программы. Например:
char vowels = {'a', 'e', 'i', 'o', 'u', 'y'};
float f_arr6;
f_arr = 25.3;
f_arr4 = 34.2;
printf("%c, %.2f\n", vowels4, f_arr);
Когда переменная-массив объявляется и сразу определяется (как в случае vowels), то размер массива можно не указывать, т. к. он вычисляется по количеству элементов, переданных в фигурных скобках.
Вещественные типы
Значения вещественных типов в компьютере представляются приближенно. Диапазон изменения данных вещественного типа определяется пятью стандартными типами: вещественный ( Real ), с одинарной точностью ( Single ), двойной точностью ( Double ), с повышенной точностью ( Extended ), сложный ( Comp ) и представлен в таблице:
| Тип | Диапазон | Число значащих цифр | Размер в байтах |
| Real | 2.9E-39…1.7E+38 | 11-12 | 6 |
| Single | 1.5E-45…3.4E+38 | >7-8 | 4 |
| Double | 5E-324…1.7E+308 | 15-16 | 8 |
| Extended | 3.4E-4951…1.1E+4932 | 19-20 | 10 |
| Comp | -2E+63+1…+2E+63-1 | 19-20 | 8 |
Вещественные числа могут быть представлены в двух форматах: с фиксированной и плавающей точкой.
Формат записи числа с фиксированной точкой совпадает с обычной математической записью десятичного числа с дробной частью. Дробная часть отделяется от целой части с помощью точки, например
34.5, -4.0, 77.001, 100.56
Формат записи с плавающей точкой применяется при записи очень больших или очень малых чисел. В этом формате число, стоящее перед символом «E», умножается на число 10 в степени, указанной после символа «E».
| 1E-4 | 1*10-4 |
| 3.4574E+3 | 3.4574*10+3 |
| 4.51E+1 | 4.51*10+1 |
Примеры чисел с плавающей точкой:
| Число | Запись на Паскале |
| 0,0001 | 1E-4 |
| 3457,4 | 34574E-1 |
| 45,1 | 451E-1 |
| 40000 | 4E+4 |
| 124 | 0.124E+3 |
| 124 | 1.24E+2 |
| 124 | 12.4E+1 |
| 124 | 1240E-1 |
| 124 | 12400E-2 |
В таблице с 5 по 9 строку показана запись одного и того же числа 124. Изменяя положение десятичной точки в мантиссе (точка «плывет», отсюда следует название «запись числа с плавающей точкой») и одновременно изменяя величину порядка, можно выбрать наиболее подходящую запись числа.
Пример описания переменных вещественного типа.
Var x,y,z:real;
Примечания
- IEEE Std 1320.2-1998 (R2004) IEEE Standard for Conceptual Modeling Language Syntax and Semantics for IDEF1X97:a set of values and operations on those values
- IEEE Std 1320.2-1998 (R2004) IEEE Standard for Conceptual Modeling Language Syntax and Semantics for IDEF1X97:a categorization of an abstract set of possible values, characteristics, and set of operations for an attribute
- ISO/IEC 19500-2:2003, Information technology — Open Distributed Processing — Part 2: General Inter-ORB Protocol (GIOP)/Internet Inter-ORB Protocol (IIOP):a categorization of values operation arguments, typically covering both behavior and representation
- С. J. Date. On The Logical Differences Between Types, Values, and Variables // Date on database: Writings 2000—2006, Apress, 2006, ISBN 978-1-59059-746-0
- , 3.6.4. Polymorphism, p. 36—37.
- , 2. Typeful languages, p. 5.
- .
Мультимедиа данные
Определение 1
Под мультимедиа-данными понимаются текстовые, графические, звуковые данные, данные с эффектами анимации, видеоданные и т.д.
Реляционные системы могут только хранить мультимедиа-данные, а создавать и редактировать такие данные способны только специализированные программы.
В реляционных системах для хранения данных предназначены таблицы. Для возможности хранения мультимедиа-данных в таблицах предусматриваются соответствующие поля. Также мультимедиа-данные могут быть сохранены в отчетах и экранных формах.
Главным отличием названных способов является связь мультимедиа-данных с каждой записью базы в первом случае и включение их в отчет или экранную форму один раз – во втором.
Мультимедиа-данные включаются в отчеты и экранные формы с целью повышения их наглядности при отображении на экране.
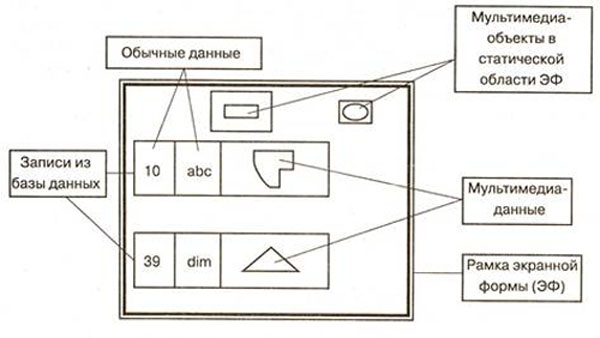
Различные СУБД содержат разные механизмы поддержки мультимедиа-данных. Зачастую для их размещения и хранения используют BLOB-поля (Binary Large OBject – большие двоичные объекты). Т.к. мультимедиа-данные могут быть различных видов (графические, аудио-, видео- и т.д.), а каждый вид может иметь разные форматы (например, графическая информация хранится в файлах с расширениями gif, tif, bmp и др.), удобно привязывать их к средствам обработки с помощью механизма OLE.
Поэтому наиболее распространенным типом BLOB-полей являются поля OLE.
Пример 1
Например, MS Access поддерживает поле объекта OLE, система Paradox позволяет создавать кроме того поля типа binary и graphic.
Для решения прикладных задач, в которых используются различные виды информации и преобладает символьно-числовая информация удобно использовать реляционную систему, которая содержит достаточно развитые средства поддержки мультимедиа-данных.
Типы данных Access
Типы данных Access разделяются на следующие группы:
- Текстовый – максимально 255 байтов.
- Мемо — до 64000 байтов.
-
Числовой — 1,2,4 или 8 байтов.Для числового типа размер поля м.б. следующим:
- байт — целые числа от -0 до 255, занимает при хранении 1 байт
- целое — целые числа от -32768 до 32767, занимает 2 байта
- длинное целое — целые числа от -2147483648 до 2147483647, занимает 4 байта
- с плавающей точкой — числа с точностью до 6 знаков от –3,4*1038 до 3,4*1038, занимает 4 байта
- с плавающей точкой — числа с точностью от –1,797*10308 до 1,797*10308, занимает 8 байт
- Дата-время — 8 байтов
- Денежный — 8 байтов, данные о денежных суммах, хранящиеся с 4 знаками после запятой.
- Счетчик — уникальное длинное целое, генерируемое Access при создании каждой новой записи — 4 байта.
- Логический — логические данные 1бит.
- Поле объекта OLE — до 1 гигабайта, картинки, диаграммы и другие объекты OLE из приложений Windows. Объекты OLE могут быть связанными или внедренными.
- Гиперссылки — поле, в котором хранятся гиперссылки. Гиперссылка может быть либо типа UNC (стандартный формат для указания пути с включением сетевого сервера файлов), либо URL(адрес объекта, документа, страницы или объекта другого типа в Интернете или Интранете. Адрес URL определяет протокол для доступа и конечный адрес).
- Мастер подстановок — поле, позволяющее выбрать значение из другой таблицы Accesss или из списка значений, используя поле со списком. Чаще всего используется для ключевых полей. Имеет тот же размер, что и первичный ключ, являющийся также и полем подстановок, обычно 4 байта. (Первичный ключ – одно или несколько полей, комбинация значений которых однозначно определяет каждую запись в таблице Accesss. Не допускает неопределенных .Null. значений, всегда должен иметь уникальный индекс. Служит для связывания таблицы с вторичными ключами других таблиц).
Базовые типы
Для указания простых типов указываются спецификаторы int, char, float или double. К переменным могут подставляться модификаторы unsigned (беззнаковый), signed (знаковый), short, long, long long.
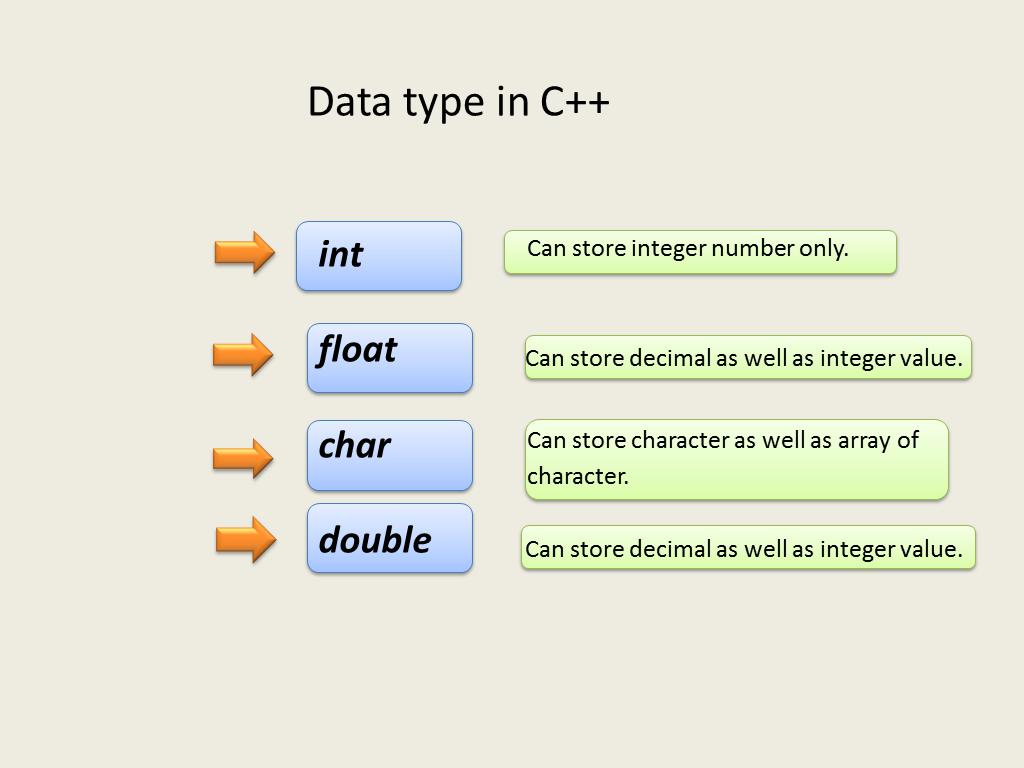
По умолчанию все числа являются знаковыми, соответственно, могут находиться в диапазоне только положительных чисел. Чтобы определить переменную типа char как знаковую, пишется signed char. Long, long long и short указывают, как много места в памяти отводится для хранения. Наибольшее — long long, наименьшее — short.
Char — самый маленький тип данных в Си. Для хранения значений выделяется всего 1 байт памяти. Переменной типа character обычно присваиваются символы, реже — цифры. Символьные значения берутся в кавычки.
Тип int хранит целые числа, его размер не определен — занимает до 4 байт памяти, в зависимости от архитектуры компьютера.
Явное преобразование беззнаковой переменной задается так:
Неявное выглядит так:
Float и double определяют числа с точкой. Числа float представляются в виде -2.3 или 3.34. Double используется для большей точности — после разделителя целой и дробной части указывается больше цифр. Этот тип занимает больше места в памяти, чем float.
Void имеет пустое значение. Он определяет функции, которые ничего не возвращают. С помощью этого спецификатора указывается пустое значение в аргументах методов. Указатели, которые могут принимать любой тип данных, также определяются как void.
Объединения
Объединениями называют сложный тип данных, позволяющий размещать в одном и том же месте оперативной памяти данные различных типов.
Размер оперативной памяти, требуемый для хранения объединений, определяется размером памяти, необходимым для размещения данных того типа, который требует максимального количества байт.
Когда используется элемент меньшей длины, чем наиболее длинный элемент объединения, то этот элемент использует только часть отведенной памяти. Все элементы объединения хранятся в одной и той же области памяти, начиная с одного адреса.
Общая форма объявления объединения
union ИмяОбъединения{ тип ИмяОбъекта1; тип ИмяОбъекта2; . . . тип ИмяОбъектаn;};
Объединения применяются для следующих целей:
- для инициализации объекта, если в каждый момент времени только один из многих объектов является активным;
- для интерпретации представления одного типа данных в виде другого типа.
Например, удобно использовать объединения, когда необходимо вещественное число типа float представить в виде совокупности байтов
123456789101112131415161718
#define _CRT_SECURE_NO_WARNINGS#include <stdio.h>#include <stdlib.h>union types{ float f; unsigned char b;};int main(){ types value; printf(«N = «); scanf(«%f», &value.f); printf(«%f = %x %x %x %x», value.f, value.b, value.b, value.b, value.b); getchar(); getchar(); return 0;}
 Пример
Пример
123456789101112131415161718192021222324
#define _CRT_SECURE_NO_WARNINGS#include <stdio.h>#include <stdlib.h>int main() { char temp; system(«chcp 1251«); system(«cls»); union { unsigned char p; unsigned int t; } type; printf(«Введите число : «); scanf(«%d», &type.t); printf(«%d = %x шестн.\n», type.t, type.t); // Замена байтов temp = type.p; type.p = type.p; type.p = temp; printf(«Поменяли местами байты, получили\n»); printf(«%d = %x шестн.\n», type.t, type.t); getchar(); getchar(); return 0;}
Результат выполнения
Деление целочисленных переменных
В языке C++ при делении двух целых чисел, где результатом является другое целое число, всё довольно предсказуемо:
#include <iostream>
int main()
{
std::cout << 20 / 4 << std::endl;
return 0;
}
|
1 |
#include <iostream> intmain() { std::cout<<204<<std::endl; return; } |
Результат:
Но что произойдет, если в результате деления двух целых чисел мы получим дробное число? Например:
#include <iostream>
int main()
{
std::cout << 8 / 5 << std::endl;
return 0;
}
|
1 |
#include <iostream> intmain() { std::cout<<85<<std::endl; return; } |
Результат:
В языке C++ при делении целых чисел результатом всегда будет другое целое число. А такие числа не могут иметь дробь (она просто отбрасывается, не округляется!).
Рассмотрим детально вышеприведенный пример: . Но как мы уже знаем, при делении целых чисел результатом является другое целое число. Таким образом, дробная часть () значения отбрасывается и остается .
Правило: Будьте осторожны при делении целых чисел, так как любая дробная часть всегда отбрасывается.
Конвертация C-style
В программировании на языке Cи явное преобразование типов данных выполняется с помощью оператора . Внутри круглых скобок мы пишем тип, в который нужно конвертировать. Этот способ конвертации типов называется конвертацией C-style. Например:
int i1 = 11;
int i2 = 3;
float x = (float)i1 / i2;
|
1 |
inti1=11; inti2=3; floatx=(float)i1i2; |
В программе, приведенной выше, мы используем круглые скобки, чтобы сообщить компилятору о необходимости преобразования переменной (типа int) в тип float. Поскольку переменная станет типа float, то также затем автоматически преобразуется в тип float, и выполнится деление типа с плавающей точкой!
Язык C++ также позволяет использовать этот оператор следующим образом:
int i1 = 11;
int i2 = 3;
float x = float(i1) / i2;
|
1 |
inti1=11; inti2=3; floatx=float(i1)i2; |
Конвертация C-style не проверяется компилятором во время компиляции, поэтому она может быть неправильно использована, например, при конвертации типов const или изменении типов данных, без учета их диапазонов (что приведет к ).
Следовательно, конвертацию C-style лучше не использовать.
Правило: Не используйте конвертацию C-style.
Структуры
Структура — такой тип данных в Си, который облегчает написание и понимание программ, помогает группировать данные.

Структура наподобие массива представляет совокупность данных, но ее элементы могут быть различного типа, а обращение производится по имени, а не по индексу.
Объявление структурной переменной происходит после закрывающих фигурных скобок.
Доступ к полям осуществляется с помощью оператора “.”. Чтобы обратиться к переменной title, пишем:
Таким образом, инициализируем переменную
Для обращения к указателям используется оператор “->”.
или оператор «.».
Вторая разновидность списков с данным — enum (перечисление). Он содержит целочисленные переменные.
В примере объявлено анонимное перечисление, содержащее три члена red, blue, green. Перед обращением к элементам объявляется перечислительная переменная.
В этом случае name1 является именем перечисления, а varname — имя переменной. В моменте создания структуры можно задать несколько переменных. Они перечисляются через запятую.
Доступ к членам перечисления задается при помощи оперетора «.».
Примитивный тип данных (Primitive)
Примитивные типы Java не являются объектами. Всего их восемь, к ним относятся: byte, short, int, long, float, double, charи boolean.
Каждый примитивный тип как член класса имеет значение по умолчанию:
| Примитивный тип | Значение по умолчанию |
| byte, short, int, long | |
| float | 0.0F |
| double | 0.0D |
| char | 0; или ‘\u0000’ |
| boolean | false |
Если использовать локальную переменную без инициализации компилятор выдаст ошибку.
Пример.
В классе объявим несколько полей класса примитивного типа без инициализации, в конструкторе выведем их значения.
public class Test {
int x;
char ch;
boolean f;
double d;
// конкструтор
public Test()
{
System.out.println("x=" + x);
System.out.println("ch=" + ch);
System.out.println("f=" + f);
System.out.println("d=" + d);
}
}
nan и inf
Есть две специальные категории чисел типа с плавающей запятой:
inf (или «бесконечность», от англ «infinity»), которая может быть либо положительной, либо отрицательной.
nan (или «не число», от англ «not a number»). Их есть несколько видов (обсуждать все виды здесь мы не будем).
Рассмотрим примеры на практике:
#include <iostream>
int main()
{
double zero = 0.0;
double posinf = 5.0 / zero; // положительная бесконечность
std::cout << posinf << «\n»;
double neginf = -5.0 / zero; // отрицательная бесконечность
std::cout << neginf << «\n»;
double nan = zero / zero; // не число (математически некорректно)
std::cout << nan << «\n»;
return 0;
}
|
1 |
#include <iostream> intmain() { doublezero=0.0; doubleposinf=5.0zero;// положительная бесконечность std::cout<<posinf<<«\n»; doubleneginf=-5.0zero;// отрицательная бесконечность std::cout<<neginf<<«\n»; doublenan=zerozero;// не число (математически некорректно) std::cout<<nan<<«\n»; return; } |
Результат выполнения программы:
означает «бесконечность», а означает «неопределенный» (от англ. «indeterminate»)
Обратите внимание, результаты вывода и зависят от компилятора/архитектуры компьютера, поэтому ваш результат выполнения вышеприведенной программы может отличаться от моего результата