Кодировка символов windows-1251
Содержание:
- Изменение кодировки в Linux
- Кодировка HTML-страниц
- Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
- Неправильная кодировка HTML страниц
- Что такое кодировка текста и с чем ее едят?
- Программы для определения кодировки в Linux
- О программе
- Навигатор по конфигурации базы 1С 8.3 Промо
- Кодировка сайта utf 8 или Windows 1251?
- Таблицы
- Самый простой (и самый неудобный) способ
- Локали в Windows
- Методика оптимизации программного кода 1С: проведение документов
- Инструктор. Прототип инструмента создания быстрых пользовательских инструкций
- Функции перекодировки
- Как «увидеть», что скрывается за непонятными символами на сайте?
- Групповая проверка доработок
- Заключение
- Ввод и вывод на консоль
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
iconv опция iconv опции -f из-кодировки -t в-кодировку файл(ы) ввода -o файлы вывода
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
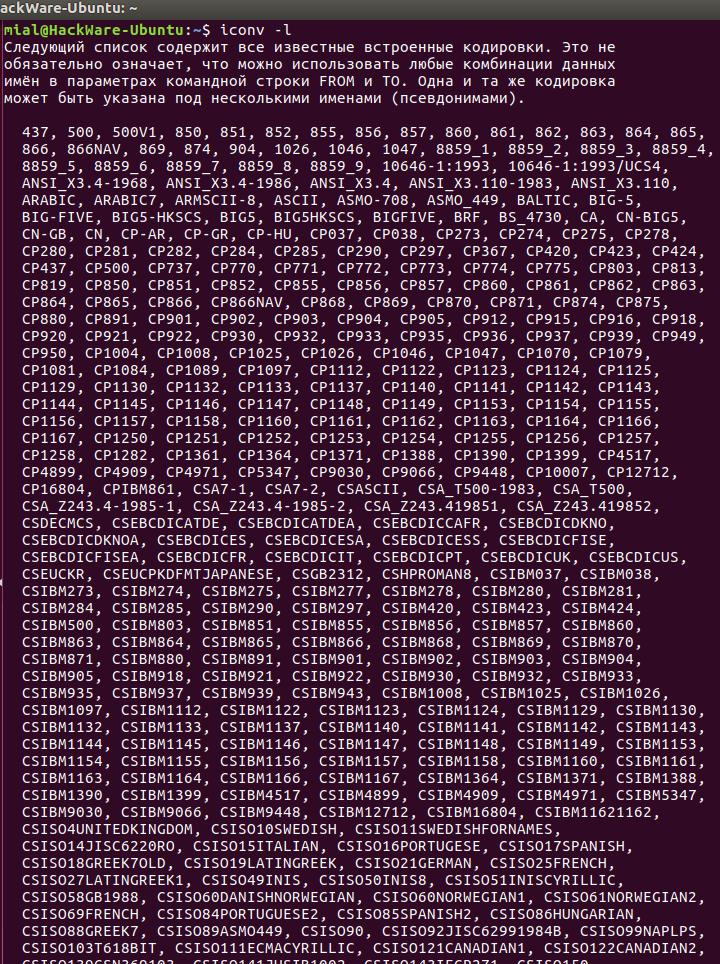
Чтобы вывести список всех кодировок, запустите команду:
iconv -l
Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
������� � �������� ������ ����...
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
enca -i mypoem_draft.txt cat mypoem_draft.txt iconv -f CP1251 -t UTF-8//TRANSLIT mypoem_draft.txt -o poem.txt cat poem.txt enca -i poem.txt

Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
enca -x UTF-8 mypoem_draft.txt
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
echo $'СТРОКА_ДЛЯ_ИЗМЕНЕНИЯ_КОДИРОВКИ' | iconv -f 'ЖЕЛАЕМАЯ_КОДИРОВКА'
Пример:
echo $'\xed\xe5 \xed\xe0\xe9\xe4\xe5\xed \xf3\xea\xe0\xe7\xe0\xed\xed\xfb\xe9 \xec\xee\xe4\xf3\xeb\xfc' | iconv -f 'Windows-1251' не найден указанный модуль

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
Кодировка HTML-страниц
Объявить кодировку html-страницы можно двумя способами: через заголовки и мета-тег в самой странице. Мета-тег используется только в статичных страницах.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"> |
Я не буду его разбирать, это проблемы html. Во всех остальных случаях предпочтительней использовать HTTP-заголовок Content-Type.
PHP позволяет работать с HTTP-заголовками посредством функции header():
// Объявление типа содержимого и его кодировки
header('Content-Type: text/html; charset=utf-8');
|
Но браузер отобразит страницу корректно только в том случае, когда php-файлы сами были созданы в кодировке cp1251. Также нужно понимать, что заголовки должны быть отправлены до любого вывода на экран.
При необходимости перекодировать страницы «на лету», достаточно воспользоваться буферизацией и iconv:
Код - динамическая перекодировка |
|
123456789 |
<?php
iconv_set_encoding('internal_encoding', 'WINDOWS-1251'); // Исходная кодировка файлов
iconv_set_encoding('output_encoding' , 'UTF-8'); // Конечная кодировка
ob_start('ob_iconv_handler'); // буферизация
header('Content-Type: text/html; charset=utf-8');
?>
Привет, мир!
|
Надпись «Привет, мир!» будет выведена в юникоде, при этом браузер получит информацию о кодировке через заголовки и правильно отобразит страницу
Но важно понимать, что внутри скрипта и при соединении с базой данных надо использовать windows-1251 (cp1251), поскольку страница должна быть сформирована в одной кодировке
Важно помнить, что функции iconv доступны не всегда, и проверка на доступность этих функций не будет лишней
Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
Simple WMS Client – это визуальный конструктор мобильного клиента для терминала сбора данных(ТСД) или обычного телефона на Android. Приложение работает в онлайн режиме через интернет или WI-FI, постоянно общаясь с базой посредством http-запросов (вариант для 1С-клиента общается с 1С напрямую как обычный клиент). Можно создавать любые конфигурации мобильного клиента с помощью конструктора и обработчиков на языке 1С (НЕ мобильная платформа). Вся логика приложения и интеграции содержится в обработчиках на стороне 1С. Это очень простой способ создать и развернуть клиентскую часть для WMS системы или для любой другой конфигурации 1С (УТ, УПП, ERP, самописной) с минимумом программирования. Например, можно добавить в учетную систему адресное хранение, учет оборудования и любые другие задачи. Приложение умеет работать не только со штрих-кодами, но и с распознаванием голоса от Google. Это бесплатная и открытая система, не требующая обучения, с возможностью быстро получить результат.
5 стартмани
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
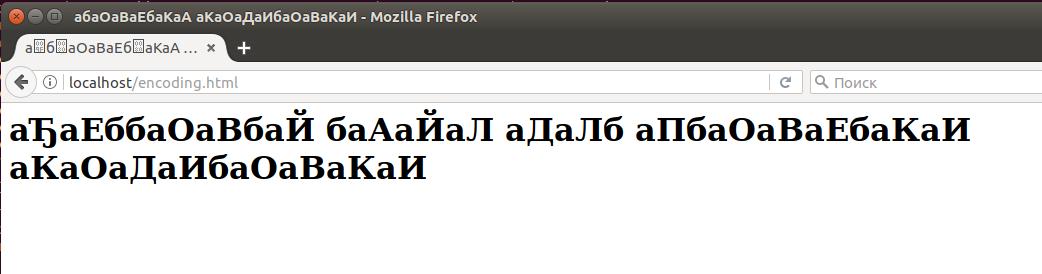
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:
Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:

Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8
Что такое кодировка текста и с чем ее едят?
Начать хотелось бы с того, что этой статьи могло бы и не быть, т.к. компьютерно-юзательная жизнь автора этих строк протекала вполне себе спокойно и достойно. Но вот в один прекрасный день, шляясь по просторам сети Интернет не со своего ПК, я столкнулся с непонятными явлениями на некоторых сайтах. Заходя на интернет-ресурсы, я видел не привычный нам русский алфавит и красивый понятный текст, а какую-то ересь в виде непонятной последовательности символов. Выглядела она примерно вот так (см. изображение).

Сначала я подумал, что моя любимая Мозилка (браузер Firefox) перегрелась и ей пора вызывать неотложку, но потом начал понимать, что проблема, скорее всего, на стороне ресурса сети и кроется она в неправильно настроенной кодировке. Это действительно оказалось так, и пошаманив немного с бубном, проблемка была оперативно решена. Результатом же всех моих любовных похождений и стал сегодняшний материал. Собственно, поехали разбираться в деталях.
Всю информацию, представленную в цифровом виде и находящуюся в глобальной паутине, нужно рассматривать с двух сторон: первая — со стороны пользователя (красивый и ухоженный текст на экране монитора) и вторая – со стороны поисковой машины (некий программный код, состоящий из различных тегов/метатегов, таблицы символов и прочее).
Если Вы хоть немного знакомы с языком разметки гипертекста (HTML), то должны быть в курсе, что сайт глазами поисковых машин (Google, Яндекс) видится не как обычный текст, а как структурированный документ, состоящий из последовательностей различного рода тегов. Чтобы было понятней, о чем я говорю, давайте взглянем на всеми нами любимый сайт Заметки Сис.Админа” проекта , но не глазами обычного пользователя, а «глазами» поисковика. Для этого нажимаем сочетание клавиш Сtrl+U (для браузеров Firefox и Chrome) и видим следующую картину (см. изображение):
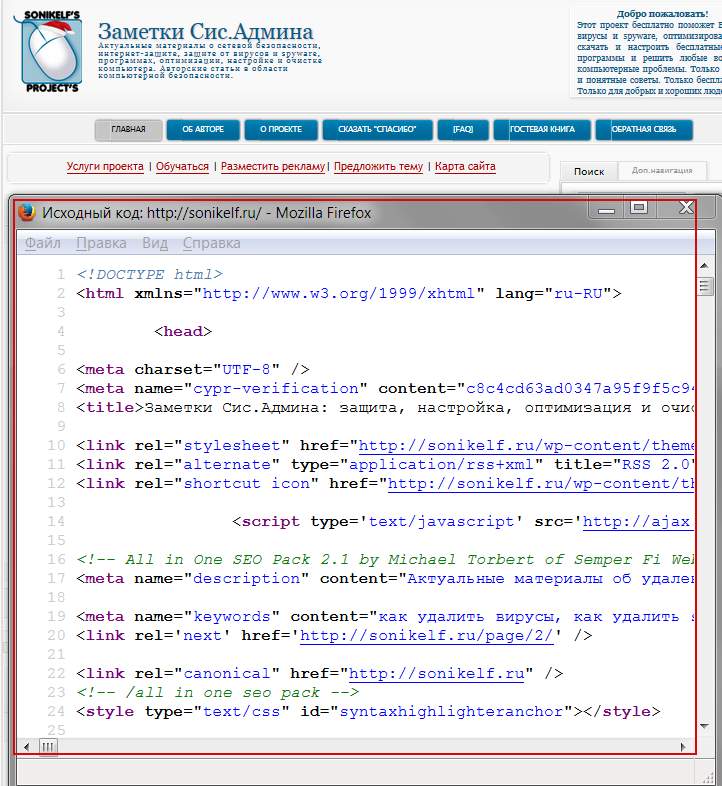
Перед нами машинный вариант sonikelf.ru, вот в таком вот непрезентабельном виде он подается поисковым системам и именно в таком виде они его и кушают. Если бы мы просто взяли и “засандалили” варианты статей из блокнота или Word обычным текстом, машины бы им не то что подавились, они бы даже и есть его не стали. Итак, перед нами главная страница проекта в HTML-виде
Обратите внимание на строку с надписью UTF-8, это не что иное, как пресловутая кодировка текста страницы, именно она и отвечает за формат вывода информации в презентабельном виде, в результате чего через браузер мы видим нормальный текст
Теперь давайте разберемся, почему же происходит так, что порой на экране монитора мы видим кракозябры. Все очень просто, проблема кроется в открытии файла в неверной кодировке. Если перевести на бытовой язык, то допустим Вас послали в магазин за молоком, а Вы притарабанили хлеб, вроде бы тоже съестное, но совсем другой формат продукта.
Итак, теперь давайте разбираться с теорией и для этого введем некоторые определения.
- Кодировка (или “Charset”) – соответствие набора символов набору числовых значений. Нужна для “сливания” информации в интернет, т.е. текстовая информация преобразуется в биты данных;
- Кодовая страница (“Codepage”) – 1 байтовая (8 бит) кодировка;
- Количество значений, принимаемое 1 байтом – 256 (два в восьмой).
Соответствие “символ-изображение” задается с помощью специальных кодовых таблиц, где каждому символу уже присвоен свой конкретный числовой код. Таких таблиц существует достаточно много, и в разных таблицах один и тот же символ может идентифицироваться по-разному (ему могут соответствовать разные числовые коды).
Все кодировки различаются количеством байт и набором специальных знаков, в которые преобразуется каждый символ исходного текста.
Примечание:Декодирование – операция, в результате которой происходит преобразование кода символа в изображение. В результате этой операции информация выводится на экран монитора пользователя.
В общем.. С определениями разобрались, а теперь давайте узнаем, какие же (кодировки) бывают.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:
file -i mypoem_draft.txt file -i mynovel.txt
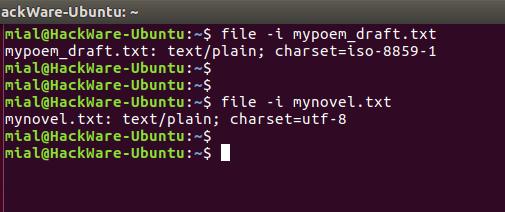
Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
sudo apt install enca
Примеры использования:
enca mypoem_draft.txt enca mynovel.txt
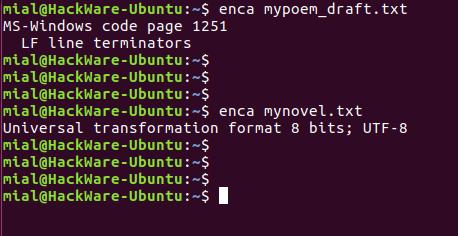
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
MS-Windows code page 1251 LF line terminators
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
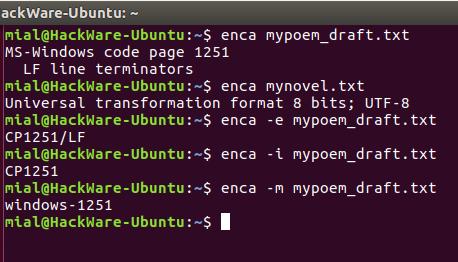
enca -e mypoem_draft.txt CP1251/LF
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
enca -i mypoem_draft.txt CP1251
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
enca -m mypoem_draft.txt windows-1251
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
enca -m -L russian mypoem_draft.txt
Чтобы узнать список доступных языков наберите:
enca --list languages
Вы увидите:
belarusian: CP1251 IBM866 ISO-8859-5 KOI8-UNI maccyr IBM855 KOI8-U
bulgarian: CP1251 ISO-8859-5 IBM855 maccyr ECMA-113
czech: ISO-8859-2 CP1250 IBM852 KEYBCS2 macce KOI-8_CS_2 CORK
estonian: ISO-8859-4 CP1257 IBM775 ISO-8859-13 macce baltic
croatian: CP1250 ISO-8859-2 IBM852 macce CORK
hungarian: ISO-8859-2 CP1250 IBM852 macce CORK
lithuanian: CP1257 ISO-8859-4 IBM775 ISO-8859-13 macce baltic
latvian: CP1257 ISO-8859-4 IBM775 ISO-8859-13 macce baltic
polish: ISO-8859-2 CP1250 IBM852 macce ISO-8859-13 ISO-8859-16 baltic CORK
russian: KOI8-R CP1251 ISO-8859-5 IBM866 maccyr
slovak: CP1250 ISO-8859-2 IBM852 KEYBCS2 macce KOI-8_CS_2 CORK
slovene: ISO-8859-2 CP1250 IBM852 macce CORK
ukrainian: CP1251 IBM855 ISO-8859-5 CP1125 KOI8-U maccyr
chinese: GBK BIG5 HZ
none:
О программе
Здравствуйте! Эта страница может пригодиться, если вам прислали текст (предположительно на кириллице), который отображается в виде странной комбинации загадочных символов. Программа попытается угадать кодировку, а если не получится, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую.
Использование
- Скопируйте текст в большое текстовое поле дешифратора. Несколько первых слов будут проанализированы, поэтому желательно, чтобы в них содержалась (закодированная) кириллица.
- Программа попытается декодировать текст и выведет результат в нижнее поле.
- В случае удачной перекодировки вы увидите текст в кириллице, который можно при необходимости скопировать и сохранить.
- В случае неудачной перекодировки (текст не в кириллице, состоящий из тех же или других нечитаемых символов) можно выбрать из нового выпадающего списка вариант в кириллице (если их несколько, выбирайте самый длинный). Нажав OK вы получите корректный перекодированный текст.
- Если текст перекодирован лишь частично, попробуйте выбрать другие варианты кириллицы из выпадающего списка.
Ограничения
- Если текст состоит из вопросительных знаков («???? ?? ??????»), то проблема скорее всего на стороне отправителя и восстановить текст не получится. Попросите отправителя послать текст заново, желательно в формате простого текстового файла или в документе LibreOffice/OpenOffice/MSOffice.
-
Не любой текст может быть гарантированно декодирован, даже если есть вы уверены на 100%, что он написан в кириллице.
- Анализируемый и декодированный тексты ограничены размером в 100 Кб.
- Программа не всегда дает стопроцентную точность: при перекодировке из одной кодовой страницы в другую могут пропасть некоторые символы, такие как болгарские кавычки, реже отдельные буквы и т.п.
- Программа проверяет максимум 7245 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Обычно возможные и отображаемые верные варианты находятся между 32 и 255.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
Условия использования
Пожалуйста, обратите внимание на то, что данная бесплатная программа создана с надеждой, что она будет полезна, но без каких-либо явных или косвенных гарантий пригодности для любого практического использования. Вы можете пользоваться ей на свой страх и риск.. Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Переводчики
Русский (Russian) : chAlx ; Пётр Васильев (http://yonyonson.livejournal.com/)
Страница подготовки переводов на другие языки находится тут.
Что нового
October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
На английской версии страницы доступен changelog программы.
Вернуться к кириллической виртуальной клавиатуре.
Навигатор по конфигурации базы 1С 8.3 Промо
Универсальная внешняя обработка для просмотра метаданных конфигураций баз 1С 8.3.
Отображает свойства и реквизиты объектов конфигурации, их количество, основные права доступа и т.д.
Отображаемые характеристики объектов: свойства, реквизиты, стандартные рекизиты, реквизиты табличных частей, предопределенные данные, регистраторы для регистров, движения для документов, команды, чужие команды, подписки на события, подсистемы.
Отображает структуру хранения объектов базы данных, для регистров доступен сервис «Управление итогами».
Платформа 8.3, управляемые формы. Версия 1.1.0.71 от 01.12.2020
3 стартмани
Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, необходимо немного понять, что такое кодировка и чем они отличаются. Текстовая информация, как впрочем, и любая другая, в компьютере хранится в закодированном виде. Нам легче представить ее как числа. Каждый символ может занимать один или более байт. Windows 1251 является однобайтной кодировкой, а UTF-8 восьмибайтной. Это значит, что в Windows 1251 можно закодировать всего 256 символов. Так как все сводится к двоичной системе исчисления, а байт – это 8 бит (0 и 1), то и максимальное число сочетаний составляет 28 = 256. Юникод позволяет представлять куда большее число символов, да и на каждый может быть выделен больший размер.
Отсюда и следуют преимущества Юникода:
- В шапке сайта следует указать кодировку, которая используется. Иначе вместо символов отобразятся «кракозяблы». А Юникод является стандартным для всех браузеров – они ловят его «на лету» как установленный по умолчанию.
- Символы сайта останутся одними и теми же, независимо от того, в какой стране загружается ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочих станций клиента. Житель Португалии, очевидно, использует клавиатуру и все ПО, включая операционную систему, на родном языке. В его компьютере, скорее всего вообще отсутствует Windows 1251. А если это так, то и сайты на русском языке корректно открываться не будут. Юникод, в свою очередь, «зашит» в любую ОС на любом языке.
- UTF-8 позволяет закодировать большее количество символов. На данный момент используется 6 байт из 8-ми, а русские символы кодируются двумя байтами. Именно поэтому предпочтительней использовать универсальную кодировку, а не узкоспециализированную, которая применяется только в славянских странах.
Таблицы
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают шестнадцатеричный код подходящего символа в Юникоде.
Кодировка Windows-1251
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ђ402 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Љ409 | ‹2039 | Њ40A | Ќ40C | Ћ40B | Џ40F |
| 9. | ђ452 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | љ459 | ›203A | њ45A | ќ45C | ћ45B | џ45F | |
| A. | A0 | Ў40E | ў45E | Ј408 | ¤A4 | Ґ490 | ¦A6 | §A7 | Ё401 | A9 | Є404 | AB | ¬AC | AD | AE | Ї407 |
| B. | °B0 | ±B1 | І406 | і456 | ґ491 | µB5 | ¶B6 | ·B7 | ё451 | №2116 | є454 | BB | ј458 | Ѕ405 | ѕ455 | ї457 |
| C. | А410 | Б411 | В412 | Г413 | Д414 | Е415 | Ж416 | З417 | И418 | Й419 | К41A | Л41B | М41C | Н41D | О41E | П41F |
| D. | Р420 | С421 | Т422 | У423 | Ф424 | Х425 | Ц426 | Ч427 | Ш428 | Щ429 | Ъ42A | Ы42B | Ь42C | Э42D | Ю42E | Я42F |
| E. | а430 | б431 | в432 | г433 | д434 | е435 | ж436 | з437 | и438 | й439 | к43A | л43B | м43C | н43D | о43E | п43F |
| F. | р440 | с441 | т442 | у443 | ф444 | х445 | ц446 | ч447 | ш448 | щ449 | ъ44A | ы44B | ь44C | э44D | ю44E | я44F |
Официальная кодировка Amiga-1251 (Amiga Inc., 2004 г.)
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A. | A0 | ¡A1 | ¢A2 | £A3 | €20AC | ¥A5 | ¦A6 | §A7 | Ё401 | A9 | №2116 | AB | ¬AC | AD | AE | ¯AF |
| B. | °B0 | ±B1 | ²B2 | ³B3 | ´B4 | µB5 | ¶B6 | ·B7 | ё451 | ¹B9 | ºBA | BB | ¼BC | ½BD | ¾BE | ¿BF |
Официальная кодировка KZ-1048 (казахский стандарт)
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ђ402 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Љ409 | ‹2039 | Њ40A | Қ49A | Һ4BA | Џ40F |
| 9. | ђ452 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | љ459 | ›203A | њ45A | қ49B | һ4BB | џ45F | |
| A. | A0 | Ұ4B0 | ұ4B1 | Ә4D8 | ¤A4 | Ө4E8 | ¦A6 | §A7 | Ё401 | A9 | Ғ492 | AB | ¬AC | AD | AE | Ү4AE |
| B. | °B0 | ±B1 | І406 | і456 | ө4E9 | µB5 | ¶B6 | ·B7 | ё451 | №2116 | ғ493 | BB | ә4D9 | Ң4A2 | ң4A3 | ү4AF |
Кодировка Windows-1251 (чувашский вариант)
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ђ402 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Љ409 | ‹2039 | Ӑ4D0 | Ӗ4D6 | Ҫ4AA | Ӳ4F2 |
| 9. | ђ452 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | љ459 | ›203A | ӑ4D1 | ӗ4D7 | ҫ4AB | ӳ4F3 |
Татарский вариант
Эта кодировка была официально принята в Татарстане в г.
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | Ә4D8 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Ө4E8 | ‹2039 | Ү4AE | Җ496 | Ң4A2 | Һ4BA |
| 9. | ә4D9 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | ө4E9 | ›203A | ү4AF | җ497 | ң4A3 | һ4BB |
Самый простой (и самый неудобный) способ
Работать в «родной» для консоли кодовой странице, в cp866. Т.е. все строки с кириллицей в исходном коде программы должны быть написаны в кодировке cp866. В этой же кодировке должны быть все входные файлы для программы. И в этой же кодировке будут и все выходные файлы. Полное впечатление, что мы вернулись на 20 лет назад, в MS DOS.
Если под рукой есть IDE, которая работает в консоли — особых проблем не возникнет. Если же использовать среду разработки под Windows GUI, то возникают вполне понятные сложности, поскольку IDE обычно работают в кодировке cp1251, «родной» для Windows. Кстати, как бы ни хаяли MS Visual Studio, она умеет работать с исходными текстами программ в различных кодировках, корректно их отображая в своем редакторе.
Локали в Windows
Для того, чтобы узнать, какие локали доступны в Windows, нужно зайти в панель управления, «Язык и региональные стандарты».
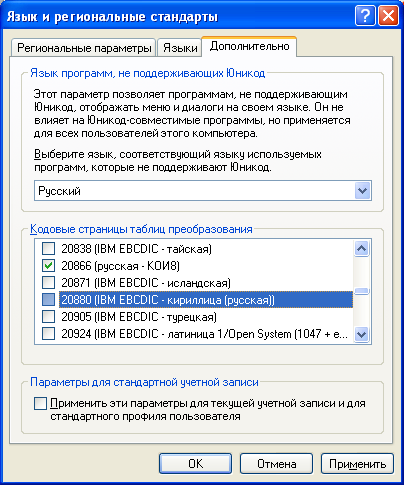
На вкладке «Дополнительно», в разделе «Кодовые страницы таблиц преобразования» показан список всех возможных локалей для Windows, которые можно использовать в PHP. Кодовые страницы, которые отмечены в списке, из PHP могут быть использованы по их номеру. В общем случае, использование выглядит по следующей схеме: Для России это может выглядеть как (cp1251) или (KOI8-R). Для Украины — (cp1251). Вместо длинных названий можно использовать сокращённые , , и так далее. При этом кодовая страница выставится с учётом региональных настроек, для России и Украины — 1251, для Америки — 1252. |
Единственная кодировка, с которой у меня возникли проблемы, как ни странно, оказалась UTF-8. При попытке выставить эту кодировку, выставляются все категории локалей, кроме основной. Вывод локализованных сообщений при этом идёт в cp1251.
Пример - установка локали UTF-8 на Windows |
<?
// Кодировка страницы windows-1251
header('Content-Type: text/html; charset=utf-8');
echo '<pre>';
// Локаль устанавливаем UTF-8
echo setlocale(LC_ALL, 'Russian_Russia.65001'), PHP_EOL;
// Но данные будут выводиться всё равно в cp1251 :(((
echo strftime('%A'), PHP_EOL;
?>
LC_COLLATE=Russian_Russia.65001;LC_CTYPE=Russian_Russia.1251;
LC_MONETARY=Russian_Russia.65001;LC_NUMERIC=Russian_Russia.65001;
LC_TIME=Russian_Russia.65001
пятница
|
Пока это можно списать на внутренний механизм PHP работы со строками. С шестой версии PHP вся обработка строк должна будет вестись в UTF-8, но до тех пор надо просто знать об этом и делать поправку.
Ещё одной странностью при работе с локалями в PHP на Windows является неправильная работа с категориями локалей. Так, например, я выставляю локаль на функции времени KOI8-R, , но почему-то выставляется cp1251 на все категории. Суть проблемы я так и не понял, возможно, это просто баг (проверялось на PHP 5.2.3), а возможно, что внутренний механизм Windows просто не позволяет этого делать. Хотя по мне, так это чистой воды баг.
В общем-то, на этом можно и закончить разговор о локалях на Windows. Главное, запомнить, что локали, которые портированы из UNIX, под WIndows работают только для «галочки». Шаг влево, шаг вправо и результат будет непредсказуемым. Безопасно можно использовать только cp1251 (windows-1251) и KOI8-R, и только для .
Код — установка локали на Windows
<?php // Устновка локалей для Windows
// Кодировка Windows-1251
setlocale(LC_ALL, ‘Russian_Russia.1251’);
// Кодировка KOI8-R
setlocale(LC_ALL, ‘Russian_Russia.20866’);
// Кодировка UTF-8 (использовать осторожно)
setlocale(LC_ALL, ‘Russian_Russia.65001’);
?>
Методика оптимизации программного кода 1С: проведение документов
Описание простого метода анализа производительности программного кода 1С, способов его оптимизации и оценки результатов в виде числовых показателей прироста производительности. Не требует сторонних программных продуктов, используются только типовые возможности платформ 1С.
Методика проверена на линейке платформ начиная с 1С:Предприятие 8.2 (обычные формы, управляемые формы). Позволяет ускорить проведение проблемных документов в 3 и более раз, провести проверку корректности формирования проводок оптимизированным кодом и подтвердить результаты оптимизации реальными замерами производительности в режиме предприятия.
К публикации приложены демонстрационные базы для режимов обычного и управляемого приложения на платформе 1С:Предприятие 8.3 (8.3.9.2033).
1 стартмани
Инструктор. Прототип инструмента создания быстрых пользовательских инструкций
Прототип дружелюбного и эффективного инструмента для написания пользовательских экспресс-инструкций.
Задействована штатная утилита Windows, о существовании которой многие не знают и которая умеет делать огромную работу по логированию действий и снятию скриншотов на всех ПК с Windows (начиная с версии Win7).
«Инструктор» не требует никакой установки и дополнительных библиотек!
Это означает, что инструмент будет работать и на домашнем ПК и на «чужом ноутбуке» и на терминальном win-сервере у заказчика, где ваши права сильно ограничены.
Вы просто подключаете легкую файловую базу 1С и получаете инструмент по снятию скриншотов с интересной функциональностью…
1 стартмани
Функции перекодировки
В Windows API есть две (а точнее, четыре пары) функции, осуществляющие перекодировку OEM <->ANSI (так сказано в документации). Проще говоря, в контексте рассматриваемого вопроса, это перекодировка между cp866 (OEM) и cp1251 (ANSI).
«Опасные» функции без контроля длины строки:
В качестве параметров получают указатели на входной и выходной буферы. Нулевой символ считается концом входной строки.
«Безопасные» функции с контролем длины строки:
В качестве параметров получают указатели на входной и выходной буферы и количество символов для входной строки. Нулевые символы не считаются концом строки. Преобразуется указанное количество символов.
На самом деле перечисленные функции являются макросами, которые раскрываются, к примеру для , в (при поддержке Unicode) или в (ANSI — без поддержки Unicode). Но о таких тонкостях обычно можно не вспоминать.
Эти функции полезны, когда вывод идёт в одной кодировке, а ввод — в другой. Такая ситуация складывается, например, при использовании только функции : вывод осуществляется в cp1251, а ввод — в cp866. Следуя первому правилу, введенную строку надо преобразовать к cp1251. Для этого используется .
Также эти функции могут быть использованы перед выводом строки в файл или после ввода строки из файла, в случае, если кодировки не совпадают.
P. S. Не судите строго — это мой первый опыт в написании статьи. Я так посмотрел, люди пишут, а чем я хуже? Тем более, что появилось чем поделиться. А оказалось, что это трудно. И написать, и ошибки проверить, и иллюстрации подготовить.
На написание статьи меня сподвиг вопрос о «кракозябрах в XP». Под это дело из руин даже был извлечен старый комп с XP. И оказалось, что проблема действительно имеет место. Пришлось провести небольшое исследование, результаты которого я здесь и изложил. Также скомпилировал доступную информацию по этой теме из материалов сайта, что бы все было в одном месте. Насколько у меня это получилось — решать вам. Буду рад замечаниям и дополнениям в комментариях к статье.
С уважением, Макар.
Как «увидеть», что скрывается за непонятными символами на сайте?
Если вы зашли на веб-страницу, видите «кракозябры» и хотите увидеть нормальный текст, то тут только два пути:
- сообщить сайтовладельцу, чтобы всё настроил как следует
- попытаться угадать кодировку самостоятельно. Делается это стандартными средствами браузеров. В Chrome, например, нужно в меню щёлкнуть «Инструменты => Кодировка» и из огромного списка выбрать подходящий набор символов (т.е. угадать).
К счастью, практически все современные веб-проекты делаются в кодировке UTF-8, которая является «универсальной» для разных алфавитов и поэтому всё менее и менее вероятно увидеть эти непонятные символы в Интернет.
Случайные публикации:
Какой хостинг выбрать? На что обратить внимание, выбирая хостинг для сайта (мощность сервера, технологии, цены, uptime…)Выбирая хостинг для своего будущего проекта в Интернете, желатель…
BaZZaro.ru — партнерка для юридического трафикаДавно я не делал обзоры партнерских программ в блоге, в этом месяце точно. Ис…
Чем может быть полезен инструмент Проверить URL от Яндекса?…как сделать 301 редирект в WP?
Для чего нужна и какой должна быть
Как активировать карту Яндекс.Денег и получить пин-код? Снятие наличных в банкоматах и комиссииПосле моей статьи о банковской карте Яндекс.Денег у многих во…
Как заказать пластиковую карту QIWI Visa Plastic (QVP)…росто и наглядно.
Официальное видео (почему-то без звука):
В общем, оформляется . Оставьте комментарий:
Оставьте комментарий:
Групповая проверка доработок
Обработка для массовой проверки доработок конфигурации: Открытие форм, Печать, Формирование отчетов, Проведение документов, Запись справочников, ПВХ, ПВР.
Выдает список обнаруженных ошибок.
Рекомендуется применять для тестирования обновленной конфигурации, перед установкой пользователям.
В коде используются универсальные методы поэтому подходит для большинства конфигураций, построенных на базе библиотеки стандартных подсистем.
Проверялась на Зарплата и управление персоналом КОРП 3.1.8.216, Управление торговлей 11, 1С:ERP Управление предприятием 2.4.7.141, Бухгалтерия предприятия КОРП 3.0.68.66.
2 стартмани
Заключение
Для безопасной разработки русскоязычных веб-проектов необходимо включать в файл с общими настройками следующие команды:
Код - файл общих настроек |
|
1234567891011121314 |
<?php
// Файл общих настроек
...
// Вывод заголовка с данными о кодировке страницы
header('Content-Type: text/html; charset=utf-8');
// Настройка локали
setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251', 'russian');
// Настройка подключения к базе данных
mysql_query('SET names "cp1251"');
?>
|
Как ни странно, но эти три строчки кода значительно повышают портируемость веб-проектов.
Ввод и вывод на консоль
В качестве единственного параметра обеим функциям передается номер кодовой страницы. В нашем случае (кириллица) — это 1251.
Этот способ работает и для Windows XP, и для Windows 7. Опробовано с Dev-C++ 5.6.3 (компилятор TDM-GCC 4.8.1 32-bit) и MS Visual Studio 2012.
Следующая тестовая программа демонстрирует вывод кириллицы на консоль, ввод кириллической строки с консоли, контрольный вывод введенной строки, сравнение введенной строки с эталонной и вывод введенной строки в файл.
Исходный текст в кодировке cp1251:
Эта программа также удобна для экспериментов с различными кодовыми таблицами и их сочетаниями.
Для практических целей можно использовать шаблон:
Здесь я намеренно оставил закомментированный вызов . На ввод-вывод кириллицы он уже не влияет, но может потребоваться для других национальных настроек (разделитель дробной части числа, формат даты, времени и пр.)