Регулярные выражения javascript — шпаргалка
Содержание:
- Опережающие и ретроспективные проверки — (?=) and (?
- Заключение
- Поиск: str.match
- Символьные классы — \d \w \s и .
- Объект RegExp
- test()
- Получение наименования расходов
- Альтернативы¶
- Примеры
- Соответствие определенному набору символов
- Строковые методы, поиск и замена
- Ретроспективная проверка
- Конструктор или литерал?
- Как использовать регулярные выражения с методами объекта RegExp?
- search()
- Методы Javascript для работы с регулярными выражениями
- Метасимволы
- Как выглядят регулярные выражения¶
- Механизм работы регулярных выражений
- Количество {n}
- Символ пробела в excel
Опережающие и ретроспективные проверки — (?=) and (?
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> тест(?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения -> тест
Вы можете использовать оператор отрицания !
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> тест(?<!r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения -> тест
Заключение
Как вы могли убедиться, области применения регулярных выражений разнообразны. Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими:
- Валидация данных (например, правильно ли заполнена строка time)
- Сбор данных (особенно веб-скрапинг, поиск страниц, содержащих определённый набор слов в определённом порядке)
- Обработка данных (преобразование сырых данных в нужный формат)
- Парсинг (например, достать все GET параметры из URL или текст внутри скобок)
- Замена строк (даже во время написания кода в IDE, можно, например преобразовать Java или C# класс в соответствующий JSON объект, заменить “;” на “,”, изменить размер букв, избегать объявление типа и т.д.)
- Подсветка синтаксиса, переименование файла, анализ пакетов и многие другие задачи, где нужно работать со строками (где данные не должны быть текстовыми).
Перевод статьи Jonny Fox: Regex tutorial — A quick cheatsheet by examples
Поиск: str.match
Как уже говорилось, использование регулярных выражений интегрировано в методы строк.
Метод для строки возвращает совпадения с регулярным выражением .
У него есть три режима работы:
Если у регулярного выражения есть флаг , то он возвращает массив всех совпадений:
Обратите внимание: найдены и и , благодаря флагу , который делает регулярное выражение регистронезависимым.
Если такого флага нет, то возвращает только первое совпадение в виде массива, в котором по индексу находится совпадение, и есть свойства с дополнительной информацией о нём:
В этом массиве могут быть и другие индексы, кроме , если часть регулярного выражения выделена в скобки. Мы разберём это в главе Скобочные группы.
И, наконец, если совпадений нет, то, вне зависимости от наличия флага , возвращается .
Это очень важный нюанс
При отсутствии совпадений возвращается не пустой массив, а именно . Если об этом забыть, можно легко допустить ошибку, например:
Если хочется, чтобы результатом всегда был массив, можно написать так:
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее. У операторов , и также есть отрицания ― исоответственно
У операторов , и также есть отрицания ― исоответственно.
Например, оператор будет искать соответствия противоположенные .
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например , необходимо выделять обратным слешем .
\$\d соответствует строке, в которой после символа $ следует одна цифра -> тест
Непечатаемые символы также можно искать, например табуляцию , новую строку , возврат каретки .
Объект RegExp
Объект типа , или, короче, регулярное выражение, можно создать двумя путями
/pattern/флаги
new RegExp("pattern")
— регулярное выражение для поиска (о замене — позже), а флаги — строка из любой комбинации символов (глобальный поиск), (регистр неважен) и (многострочный поиск).
Первый способ используется часто, второй — иногда. Например, два таких вызова эквивалентны:
var reg = /ab+c/i
var reg = new RegExp("ab+c", "i")
При втором вызове — т.к регулярное выражение в кавычках, то нужно дублировать
// эквивалентны
re = new RegExp("\\w+")
re = /\w+/
При поиске можно использовать большинство возможностей современного PCRE-синтаксиса.
test()
Для работы с регулярными выражениями есть несколько методов. Простейший из них —. При использовании этого метода необходимо передать функции проверяемую строку в качестве аргумента. В результате метод возвращает булево значение: — если в строке есть совпадения с шаблоном, — если совпадений нет.
// Синтаксис метода test()// /шаблон/.test('проверяемый текст')// Проверка строки,// когда test() не находит совпаденийmyPattern.test('There was a cat and dog in the house.')// false// Создание переменной,// которой присваивается текст для проверкиconst myString = 'The world of code.'// Создание шаблонаconst myPattern = /code/// Проверка текста с помощью шаблона,// когда test() находит совпадениеmyPattern.test(myString)// true
Получение наименования расходов
Со стоимостью разобрались, самая трудная часть позади. Теперь необходимо просто сопоставить остальные данные в соответствующей строке, то есть дефис, разделяющий стоимость и наименование, а также само наименование.
Паттерн для извлечения наименования расходов
Давайте вспомним, как выглядит одна строка из списка расходов:
То есть за стоимостью следует пробел, затем дефис, затем еще один пробел и, наконец, само наименование, которое представляет собой последовательность символов (букв, цифр, пробелов и т. д.).
Затем можно создать две простые группы для этого паттерна: одну, которая соответствует дефису и пробелам вокруг него, и вторую, соответствующую наименованию. Поскольку наименование может состоять из символов различного типа, на этот раз мы используем возможности точки, то есть добавляем ее, чтобы она соответствовала любому символу. Опять же, звездочка соответствует нулю или более символов в последовательности:
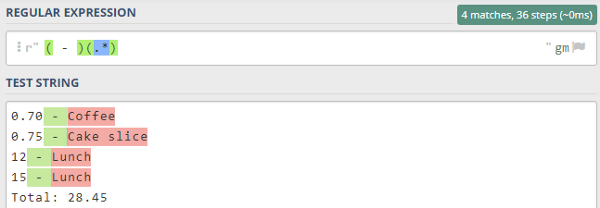 Тест паттерна наименований
Тест паттерна наименований
Ни дефис, ни окружающие его пробелы не являются частью расходов как таковых, но они являются важнейшими текстовыми обозначениями для сопоставления расходов.
Альтернативы¶
Выражения в списке альтернатив разделяются .
Таким образом, будет соответствовать любому из , или (также как и ).
Первое выражение включает в себя все от последнего разделителя шаблона (, или начало шаблона) до первого , а последнее выражение содержит все от последнего к следующему разделителю шаблона.
Звучит сложно, поэтому обычной практикой является заключение списка альтернатив в скобки, чтобы минимизировать путаницу относительно того, где он начинается и заканчивается.
Выражения в списке альтернатив пробуются слева направо, принимается первое же совпадение.
Например, регулярное выражение в строке будет соответствовать — первое же совпадение.
Также помните, что в квадратных скобках воспринимается просто как символ, поэтому, если вы напишите , это тоже самое что .
Примеры
Разберём скобки на примерах.
Без скобок шаблон означает символ и идущий после него символ , который повторяется один или более раз. Например, или .
Скобки группируют символы вместе. Так что означает , , и т.п.
Сделаем что-то более сложное – регулярное выражение, которое соответствует домену сайта.
Например:
Как видно, домен состоит из повторяющихся слов, причём после каждого, кроме последнего, стоит точка.
На языке регулярных выражений :
Поиск работает, но такому шаблону не соответствует домен с дефисом, например, , так как дефис не входит в класс .
Можно исправить это, заменим на везде, кроме как в конце: .
Итоговый шаблон:
Соответствие определенному набору символов
Следующие спецсимволы используются для определения соответствия определенному набору символов.
\w – Соответствует буквенному или цифровому символу, а также знаку подчёркивания
\W – Соответствует любому символу, за исключением буквенного, цифрового и знака подчеркивания.
\d – Соответствует цифровому символу. Любые цифры от 0 до 9
\D – Соответствует не цифровому символу. Любые символы за исключением цифр от 0 до 9
\s – Соответствует пробельным символам. К ним относятся: пробел, табуляция и перевод строки
\S – Все символы за исключением пробельных
. – Соответствует любому символу за исключением перевода строки
– Обозначает диапазон символов. Например, выражение – соответствует символам “A”, “B”, “C”, “D” и “E”
– Соответствует перечисленным в символам в выражении. Например, – сработает только с символами “A”, “M” и “T”.
– Соответствует символам, не представленным в выражении. Например, с помощью найдутся все символы за исключением, “A”, “B”, “C”, “D” и “E”.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Ретроспективная проверка
Опережающие проверки позволяют задавать условия на то, что «идёт после».
Ретроспективная проверка выполняет такую же функцию, но с просмотром назад. Другими словами, она находит соответствие шаблону, только если перед ним есть что-то заранее определённое.
Синтаксис:
- Позитивная ретроспективная проверка: , ищет совпадение с при условии, что перед ним ЕСТЬ .
- Негативная ретроспективная проверка: , ищет совпадение с при условии, что перед ним НЕТ .
Чтобы протестировать ретроспективную проверку, давайте поменяем валюту на доллары США. Знак доллара обычно ставится перед суммой денег, поэтому для того чтобы найти , мы используем – число, перед которым идёт :
Если нам необходимо найти количество индеек – число, перед которым не идёт , мы можем использовать негативную ретроспективную проверку :
Конструктор или литерал?
Конструктор и литерал выполняют одну функцию, но есть одно важное различие. Регулярное выражение, созданное при помощи конструктора, компилируется при выполнении программы, литерал — на этапе загрузки скрипта
Это значит, что литерал нельзя изменить динамически, в то время как конструктор — можно.
Таким образом, если вам нужно (или может понадобиться) изменить шаблон на лету, создавайте регулярное выражение с помощью конструктора. Также конструктор будет лучшим решением, если шаблон нужно создавать динамически. С другой стороны, если вам не понадобится менять или создавать шаблон, вы можете воспользоваться литералом.
Как использовать регулярные выражения с методами объекта RegExp?
Прежде чем приступить к созданию шаблонов, давайте кратко рассмотрим, как они используются. С помощью описанных ниже методов мы сможем в дальнейшем применять разные способы создания шаблонов.
search()
Первый метод, , ищет в строке заданный шаблон. Если он находит совпадение, то возвращает позицию в строке, где это совпадение начинается. Если совпадения нет, возвращается . Нужно запомнить, что метод возвращает позицию только первого совпадения. После нахождения первого совпадения он прекращает работу.
// Синтаксис метода search()// 'проверяемый текст'.search(/шаблон/)// Создание текста для проверкиconst myString = 'The world of code is not full of code.'// Описание шаблонаconst myPattern = /code/// Использование search() для поиска//совпадения строки с шаблоном,//когда search() находит совпадениеmyString.search(myPattern)// -13// Вызов search() прямо на строке,// когда search() не находит совпадений'Another day in the life.'.search(myPattern)// -1
Методы Javascript для работы с регулярными выражениями
В Javascript Существует 6 методов для работы с регулярными выражениями. Чаще всего мы будем использовать только половину из них.
Метод exec()
Метод RegExp, который выполняет поиск совпадения в строке. Он возвращает массив данных. Например:
var str = 'Some fruit: Banana - 5 pieces. For 15 monkeys.'; var re = /(\w+) - (\d) pieces/ig; var result = re.exec(str); window.console.log(result); // result = // Так же мы можем посмотреть позицию совпадения - result.index
В результате мы получим массив, первым элементом которого будет вся совпавшая по паттерну строка, а дальше содержимое скобочных групп. Если совпадений с паттерном нету, то .
Метод test()
Метод RegExp, который проверяет совпадение в строке, возвращает либо true, либо false. Очень удобен, когда нам необходимо проверить наличие или отсутствие паттерна в тексте. Например:
var str = 'Balance: 145335 satoshi'; var re = /Balance:/ig; var result = re.test(str); window.console.log(result); // true
В данном примере, есть совпадение с паттерном, поэтому получаем true.
Метод search()
Метод String, который тестирует на совпадение в строке. Он возвращет индекс совпадения, или -1 если совпадений не будет найдено. Очень похож на метод indexOf() для работы со строками. Минус этого метода — он ищет только первое совпадение. Для поиска всех совпадений используйте метод match().
var str = "Умея автоматизировать процессы, можно зарабатывать миллионы"; window.console.log(str.search(/можно/igm)); // 60 window.console.log(str.search(/атата/igm)); // -1
Метод match()
Метод String, который выполняет поиск совпадения в строке. Он возвращет массив данных либо null если совпадения отсутствуют.
// Без использования скобочных групп
var str = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz';
var regexp = //gi;
var matches_array = str.match(regexp);
window.console.log(matches_array); //
// С использованием скобочных групп без флага g
var str = 'Fruits quantity: Apple - 5, Banana - 7, Orange - 12. I like fruits.';
var found = str.match(/(\d{1,2})/i);
window.console.log(found); // Находит первое совпадение и возвращает объект
// {
// 0: "5"
// 1: "5"
// index: 25
// input: "Fruits quantity: Apple -...ge - 12. I like fruits."
// }
// С использованием скобочных групп с флагом g
var found = str.match(/(\d{1,2})/igm);
window.console.log(found); //
Если совпадений нету — возвращает null.
Метод replace()
Метод String, который выполняет поиск совпадения в строке, и заменяет совпавшую подстроку другой подстрокой переданной как аргумент в этот метод. Мы уже использовали эту функцию для работы о строками, регулярные выражения привносят новые возможности.
// Обычная замена var str = 'iMacros is awesome, and iMacros is give me profit!'; var newstr = str.replace(/iMacros/gi, 'Javascript'); window.console.log(newstr); // Javascript is awesome, and Javascript is give me profit! // Замена, используя параметры. Меняем слова местами: var re = /(\w+)\s(\w+)/; var str = 'iMacros JS'; var newstr = str.replace(re, '$2, $1'); // в переменных $1 и $2 находятся значения из скобочных групп window.console.log(newstr); // JS iMacros
У метода replace() есть очень важная особенность — он имеет свой каллбэк. То есть, в качестве аргумента мы можем подавать функцию, которая будет обрабатывать каждое найденное совпадение.
Нестандартное применение метода replace():
var str = `
I have some fruits:
Orange - 5 pieces
Banana - 7 pieces
Apple - 15 pieces
It's all.
`;
var arr = []; // Сюда складируем данные о фруктах и их количестве
var newString = str.replace(/(\w+) - (\d) pieces/igm, function (match, p1, p2, offset, string) {
window.console.log(arguments);
arr.push({
name: p1,
quantity: p2
});
return match;
});
window.console.log(newString); // Текст не изменился, как и было задумано
window.console.log(arr); // Мы получили удобный массив объектов, с которым легко и приятно работать
Как вы видите, мы использовали этот метод для обработки каждого совпадения. Мы вытащили из паттерна название фрукта и количество и поместили эти значения в массив объектов, как мы уже делали ранее
Обратите внимание на аргумент функции offset — это будет индекс начала совпадения, этот параметр нам потом пригодится. В нашем случае, мы имеем 2 скобочные группы в паттерне, поэтому у нас в функции 5 аргументов, но их там может быть и больше
Метод split()
Метод String, который использует регулярное выражение или фиксированую строку чтобы разбить строку на массив подстрок.
var str = "08-11-2016"; // Разбиваем строку по разделителю window.console.log(str.split('-')); // // Такой же пример с регэкспом window.console.log(str.split(/-/)); //
Метасимволы
Символ точки () является метасимволом. Метасимволы — это символы, которые имеют особое значение. Они помогают создавать более интересные шаблоны, чем просто набор конкретных символов. Практически всё, что мы будем рассматривать — будет метасимволами.
Точка () представляет собой любой символ. В следующем примере мы ищем символ , за которым следует любой символ, а за ним символ :
Важно отметить, что точка () соответствует только одному символу. Мы можем заставить её соответствовать более чем одному символу, используя множители, которые мы рассмотрим ниже
Кроме того, вы также можете искать несколько символов с помощью точки следующим образом:
В примере, приведенном выше, мы сопоставляем букву , за которой следуют любые два символа, и за которыми следует .
Как выглядят регулярные выражения¶
В JavaScript регулярные выражения это объект, который может быть определён двумя способами.
Первый способ заключается в создании нового объекта RegExp с помощью конструктора:
Второй способ заключается в использовании литералов регулярных выражений:
Вы знаете что в JavaScript есть литералы объектов и литералы массивов? В нём также есть литералы regexp.
В приведённом выше примере называется шаблоном. В литеральной форме он находится между двумя слэшами, а в случае с конструктором объекта, нет.
Это первое важное отличие между двумя способами определения регулярных выражений, остальные мы увидим позже
Механизм работы регулярных выражений
Теперь, когда у вас есть представление о том, что такое регулярные выражения, мы можем рассмотреть то, что происходит «под капотом».
Итак, мы имеем указатель, который постепенно перемещается по строке поиска. Как только он сталкивается с символом, который соответствует началу регулярного выражения, он останавливается. Теперь запускается второй указатель, который перемещается вперед от первого указателя, символ за символом, проверяя с каждым шагом, сохраняется ли соответствие шаблону или нет. Если мы доберемся до конца шаблона и сохранится соответствие, то мы нашли совпадение. Если на любом шаге происходит сбой, то второй указатель отбрасывается, а основной указатель продолжает движение по строке.
Количество {n}
Самый простой квантификатор — это число в фигурных скобках: .
Он добавляется к символу (или символьному классу, или набору и т.д.) и указывает, сколько их нам нужно.
Можно по-разному указать количество, например:
- Точное количество:
-
Шаблон обозначает ровно 5 цифр, он эквивалентен .
Следующий пример находит пятизначное число:
Мы можем добавить , чтобы исключить числа длиннее: .
- Диапазон: , от 3 до 5
-
Для того, чтобы найти числа от 3 до 5 цифр, мы можем указать границы в фигурных скобках:
Верхнюю границу можно не указывать.
Тогда шаблон найдёт последовательность чисел длиной и более цифр:
Давайте вернёмся к строке .
Число – это последовательность из одной или более цифр. Поэтому шаблон будет :
Символ пробела в excel
Други — срочно!кто знает как в множестве ячеек листа избавиться от ненужного символа переноса строки?чертов квадратик не дает вычислять и корректно конвертировать содержимое. имею ввиду символ нажатия «enter» , который приводит к переносу вводимого текста на строку ниже.
Добавление от 12.12.2004 01:23:
замена сработала с кодом 010 — НО! после этого функция замены вырубается как пофиксить? и еще — нужно в пустые ячейки автоматом вставлять некое значение — возможно ли? — путем автозамены? или только вручную? — большой гимор.
спасибо за ответы
после конвенртирования данных из 1с в Excel имеем: часть данных конвертируется некорректно, имея в ячейках спецсимвол, с этим почти разобрались — см. выше.некоторые массивы имеют хаотично разбросанные пустые поля, которые надо заполнить одинаковым значением, в моем случае — нулями, иначе не работает формулы вычисления для соседних ячеек, итоговая автосумма по столбцу и т.п.
вопрос — можно ли в ПУСТЫЕ ячейки забить нули автозаменой? похоже нет. а лопатить огромные листы на тысячи позиций и вручную заполнять пустые позиции — это тупо и долго.
Наверно мы с Вами говорим о разных вещах.
Настоящая автозамена, это когда мы вводим в ячейку, например z, а получаем 0 (Сервис-Автозамена)Естественно, что для этого нам необходимо предварительно указать, что z — это неправильный вариант, а 0 — правильный.
Вы, по всей видимости, имеете ввиду меню Правка — команда Заменить
Но это не важно, так как в принципе нам ничего не мешает выделить диапазон ячеек, содержащий пустые ячейки, а затем ввести 0 сразу во все эти ячейки. — Выделяете диапазон ячеек (можно выделить несмежные и не обязательно выделять строго пустые ячейки), затем в меню Правка-Перейти-Выделить-Пустые ячейки-ОК— Вводим 0, затем CTRL + ENTER *
— Выделяете диапазон ячеек (можно выделить несмежные и не обязательно выделять строго пустые ячейки), затем в меню Правка-Перейти-Выделить-Пустые ячейки-ОК— Вводим 0, затем CTRL + ENTER *
SS-18Чтобы определить код символа можно воспользоваться функцией КОДСИМВ.Допустим, символ переноса строки находится на пятой позиции в ячейке G30, тогда формула:=КОДСИМВ(ПСТР(G30;5;1))возвратит значение 10
Удалить этот символ из ячейки можно с помощью формулы:=ПОДСТАВИТЬ(G30;СИМВОЛ(10);»»)
В некоторых случаях может понадобиться заменить этот символ другим, например, пробелом:=ПОДСТАВИТЬ(G30;СИМВОЛ(10);СИМВОЛ(32))
Другой способ удалить символ с кодом 10 — использовать функцию ПЕЧСИМВ:=ПЕЧСИМВ(G30)
SS-18замена сработала с кодом 010 — НО! после этого функция замены вырубается
Когда вызываешь Замену во второй раз, в полях ввода ОСТАЮТСЯ предыдущие значения!То есть там стоИт сомвол 010, но его не видно, ты дописываешь что-то. и такая комбинация символов, действительно, не встречается.Метод: после вызова Замены поставить курсор в поле «Что» и несколько раз нажать BackSpace и Delete.
Забить пустые ячейки нулями? Нет проблем!Выдели ячейку где-то внутри таблицы, можно в первой строке, где заголовки.Правка-Перейти-Выделить-Текущую область (выделил всю таблицу).Ctrl-H — Что:пустая строка, Заменить на:0 — Заменить все.
Поторопился я обрадоваться — не помогает стирание спецсимвола и не работает функция замены после его удаления. Стирание поля в графе «заменить» — не приводит к ее активизации. — не работают оба способа замены массивы пустых ячеек на ноль — в способе Nosorogвыделяется ТОЛЬКО вся таблица ( включая заголовки и графы с названием) и нули вставляются ТОЛЬКО вокруг ячеек массива. в способе Vitaly K.вообще не активна функция ОПЕРАЦИИ в специальной вставке — ее просто НЕТ ТАМ.
Попробуй задействовать такой макрос:
код: Он, собственно, применяет функцию ПЕЧСИМВ к каждой ячейке таблицы, и пишет 0 в каждую пустую ячейку.
2pashulkaхммм.. уточняю — у меня дома стоит excel 2000-й. попытка использовать режим «правка-спецвставка» показывает окошко в котором и в помине нет группы ОПЕРАЦИЯ, а есть только выбор вида текста.. ну там Unicode или другой. и больше никаких .. -отсюда вопрос — как в Excel 2000 получить указанный режим функции спец вставка?Vic_KСпасибо за вопрос, но я не знаю как формируется файл из 1С.. знаю, что у жены на работе что-то сбито в ее настройках, после того как там покопался вызванный программист по 1С. а вызывать их на каждый сбой ох как дорого, да еще с такими результатами. все вышеописанные глюки появились именно после визита программиста. т.е. справеливее сказать, что он настраивал именно то, что просили добавить, но потом обнаруживались ужасные последствия в других местах.Политика у них такая что-ли, чтобы делать людей зависимыми от их «услуг» и на бабки разводить?
извините, ответил не квалифицировано, как смог.