3 ways to replace all string occurrences in javascript
Содержание:
- Квантификаторы
- Поиск совпадений: метод exec
- Символьные классы — \d \w \s и .
- Строковые методы, поиск и замена
- Флаги
- Сложно, по полезно¶
- Статические свойства
- Статические свойства
- Как выглядят регулярные выражения¶
- str.replace(str|regexp, str|func)
- Регулярные выражения
- Найти все / Заменить все
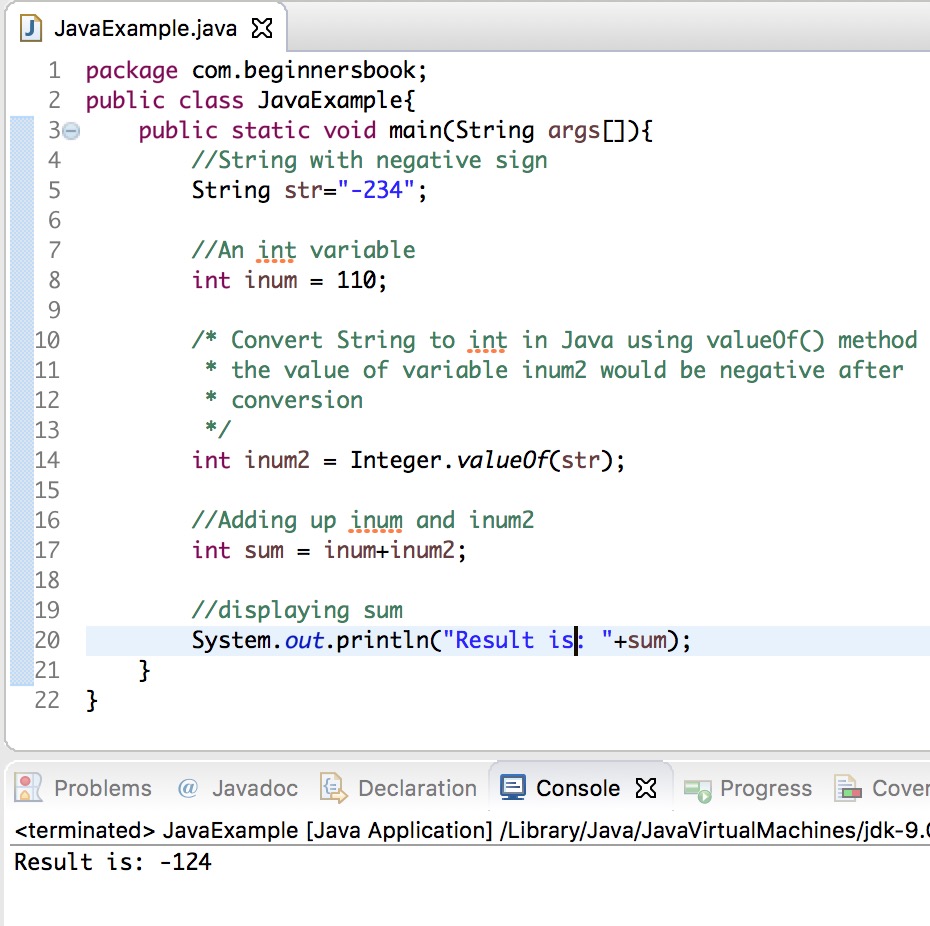
- Синтаксис
- Опережающие и ретроспективные проверки — (?=) and (?
- Заключение
- Пример использования
- Точка – это любой символ
- Объект RegExp
- Жадность
- 4. Key takeaway
- Точка и перенос строки
- Заключение
Квантификаторы
| Символ | Описание |
|---|---|
| n* | Сопостовление происходит с любой строкой, содержащей ноль или более вхождений символа n. |
| n+ | Сопостовление происходит с любой строкой, содержащей хотя бы один символ n. |
| n? | Сопостовление происходит с любой строкой с предшествующим элементом n ноль или один раз. |
| n{x} | Соответствует любой строке, содержащей последовательность символов n определенное количество раз x. X должно быть целым положительным числом. |
| n{x,} | Соответствует любой строке, содержащей по крайней мере x вхождений предшествующего элемента n. X должно быть целым положительным числом. |
| n{x, y} | Соответствует любой строке, содержащей по крайней мере x, но не более, чем с y вхождениями предшествующего элемента n. X и y должны быть целыми положительными числами. |
| n*? n+? n?? n{x}? n{x,}? n{x,y}? |
Сопостовление происходит по аналогии с квантификаторами *, +, ? и {…}, однако при этом поиск идет минимально возможного сопоставления. По умолчанию используется «жадный» режим, ? в конце квантификатора позволяет задать «нежадный» режим при котором повторение сопоставления происходит минимально возможное количество раз. |
| x(?=y) | Позволяет сопоставить x, только если за x следует y. |
| x(?!y) | Позволяет сопоставить x, только если за x не следует y. |
| x|y | Сопоставление происходит с любой из указанных альтернатив. |
Поиск совпадений: метод exec
Метод возвращает массив и ставит свойства регулярного выражения.
Если совпадений нет, то возвращается null.
Например,
// Найти одну d, за которой следует 1 или более b, за которыми одна d
// Запомнить найденные b и следующую за ними d
// Регистронезависимый поиск
var myRe = /d(b+)(d)/ig;
var myArray = myRe.exec("cdbBdbsbz");
В результате выполнения скрипта будут такие результаты:
| Объект | Свойство/Индекс | Описания | Пример |
| Содержимое . | |||
| Индекс совпадения (от 0) | |||
| Исходная строка. | |||
| Последние совпавшие символы | |||
| Совпадения во вложенных скобках, если есть. Число вложенных скобок не ограничено. | |||
| Индекс, с которого начинать следующий поиск. | |||
| Показывает, что был включен регистронезависимый поиск, флаг «». | |||
| Показывает, что был включен флаг «» поиска совпадений. | |||
| Показывает, был ли включен флаг многострочного поиска «». | |||
| Текст паттерна. |
Если в регулярном выражении включен флаг «», Вы можете вызывать метод много раз для поиска последовательных совпадений в той же строке. Когда Вы это делаете, поиск начинается на подстроке , с индекса . Например, вот такой скрипт:
var myRe = /ab*/g;
var str = "abbcdefabh";
while ((myArray = myRe.exec(str)) != null) {
var msg = "Found " + myArray + ". ";
msg += "Next match starts at " + myRe.lastIndex;
print(msg);
}
Этот скрипт выведет следующий текст:
Found abb. Next match starts at 3 Found ab. Next match starts at 9
В следующем примере функция выполняет поиск по input. Затем делается цикл по массиву, чтобы посмотреть, есть ли другие имена.
Предполагается, что все зарегистрированные имена находятся в массиве А:
var A = ;
function lookup(input)
{
var firstName = /\w+/i.exec(input);
if (!firstName)
{
print(input + " isn't a name!");
return;
}
var count = 0;
for (var i = 0; i < A.length; i++)
{
if (firstName.toLowerCase() == A.toLowerCase())
count++;
}
var midstring = (count == 1) ? " other has " : " others have ";
print("Thanks, " + count + midstring + "the same name!")
}
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее. У операторов , и также есть отрицания ― исоответственно
У операторов , и также есть отрицания ― исоответственно.
Например, оператор будет искать соответствия противоположенные .
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например , необходимо выделять обратным слешем .
\$\d соответствует строке, в которой после символа $ следует одна цифра -> тест
Непечатаемые символы также можно искать, например табуляцию , новую строку , возврат каретки .
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Флаги
Регулярные выражения могут иметь флаги, которые влияют на поиск.
В JavaScript их всего шесть:
- С этим флагом поиск не зависит от регистра: нет разницы между и (см. пример ниже).
- С этим флагом поиск ищет все совпадения, без него – только первое.
- Многострочный режим (рассматривается в главе Многострочный режим якорей ^ $, флаг «m»).
- Включает режим «dotall», при котором точка может соответствовать символу перевода строки (рассматривается в главе Символьные классы).
- Включает полную поддержку юникода. Флаг разрешает корректную обработку суррогатных пар (подробнее об этом в главе Юникод: флаг «u» и класс \p{…}).
- Режим поиска на конкретной позиции в тексте (описан в главе Поиск на заданной позиции, флаг «y»)
Цветовые обозначения
Здесь и далее в тексте используется следующая цветовая схема:
- регулярное выражение –
- строка (там где происходит поиск) –
- результат –
Сложно, по полезно¶
Новичкам регулярные выражения могут показаться абсолютной ерундой, а зачастую даже и профессиональным разработчикам, если не вкладывать время необходимое для их понимания.
Регулярные выражения сложно писать, сложно читать и сложно поддерживать/изменять.
Но иногда регулярные выражения это единственный разумный способ выполнить какие-то манипуляции над строками, поэтому они являются очень ценным инструментом.
Это руководство нацелено на то чтобы самым простым способом дать вам некоторое представление о регулярных выражениях в JavaScript и предоставить информацию о том как читать и создавать регулярные выражения.
Эмпирическое правило заключается в том, что простые регулярные выражения просты для чтения и записи, в то время как сложные регулярные выражения могут быстро превратиться в беспорядок, если вы не глубоко понимаете основы.
Статические свойства
Ну и напоследок — еще одна совсем оригинальная особенность регулярных выражений.
Вот — одна интересная функция.
Запустите ее один раз, запомните результат — и запустите еще раз.
function rere() {
var re1 = /0/, re2 = new RegExp('0')
alert()
re1.foo = 1
re2.foo = 1
}
rere()
В зависимости от браузера, результат первого запуска может отличаться от второго. На текущий момент, это так для Firefox, Opera. При этом в Internet Explorer все нормально.
С виду функция создает две локальные переменные и не зависит от каких-то внешних факторов.
Почему же разный результат?
Ответ кроется в стандарте ECMAScript, :
Цитата…
A regular expression literal is an input element that is converted to a RegExp object (section 15.10)
when it is scanned. The object is created before evaluation of the containing program or function begins.
Evaluation of the literal produces a reference to that object; it does not create a new object.
То есть, простыми словами, литеральный регэксп не создается каждый раз при вызове .
Вместо этого браузер возвращает уже существующий объект, со всеми свойствами, оставшимися от предыдущего запуска.
В отличие от этого, всегда создает новый объект, поэтому и ведет себя в примере по-другому.
Статические свойства
Ну и напоследок — еще одна совсем оригинальная особенность регулярных выражений.
Вот — одна интересная функция.
Запустите ее один раз, запомните результат — и запустите еще раз.
function rere() {
var re1 = /0/, re2 = new RegExp('0')
alert()
re1.foo = 1
re2.foo = 1
}
rere()
В зависимости от браузера, результат первого запуска может отличаться от второго. На текущий момент, это так для Firefox, Opera. При этом в Internet Explorer все нормально.
С виду функция создает две локальные переменные и не зависит от каких-то внешних факторов.
Почему же разный результат?
Ответ кроется в стандарте ECMAScript, :
Цитата…
A regular expression literal is an input element that is converted to a RegExp object (section 15.10)
when it is scanned. The object is created before evaluation of the containing program or function begins.
Evaluation of the literal produces a reference to that object; it does not create a new object.
То есть, простыми словами, литеральный регэксп не создается каждый раз при вызове .
Вместо этого браузер возвращает уже существующий объект, со всеми свойствами, оставшимися от предыдущего запуска.
В отличие от этого, всегда создает новый объект, поэтому и ведет себя в примере по-другому.
Как выглядят регулярные выражения¶
В JavaScript регулярные выражения это объект, который может быть определён двумя способами.
Первый способ заключается в создании нового объекта RegExp с помощью конструктора:
Второй способ заключается в использовании литералов регулярных выражений:
Вы знаете что в JavaScript есть литералы объектов и литералы массивов? В нём также есть литералы regexp.
В приведённом выше примере называется шаблоном. В литеральной форме он находится между двумя слэшами, а в случае с конструктором объекта, нет.
Это первое важное отличие между двумя способами определения регулярных выражений, остальные мы увидим позже
str.replace(str|regexp, str|func)
Это универсальный метод поиска-и-замены, один из самых полезных. Этакий швейцарский армейский нож для поиска и замены в строке.
Мы можем использовать его и без регулярных выражений, для поиска-и-замены подстроки:
Хотя есть подводный камень.
Когда первый аргумент является строкой, он заменяет только первое совпадение.
Вы можете видеть это в приведённом выше примере: только первый заменяется на .
Чтобы найти все дефисы, нам нужно использовать не строку , а регулярное выражение с обязательным флагом :
Второй аргумент – строка замены. Мы можем использовать специальные символы в нем:
| Спецсимволы | Действие в строке замены |
|---|---|
| вставляет | |
| вставляет всё найденное совпадение | |
| вставляет часть строки до совпадения | |
| вставляет часть строки после совпадения | |
| если это 1-2 значное число, то вставляет содержимое n-й скобки | |
| вставляет содержимое скобки с указанным именем |
Например:
Для ситуаций, которые требуют «умных» замен, вторым аргументом может быть функция.
Она будет вызываться для каждого совпадения, и её результат будет вставлен в качестве замены.
Функция вызывается с аргументами :
- – найденное совпадение,
- – содержимое скобок (см. главу Скобочные группы).
- – позиция, на которой найдено совпадение,
- – исходная строка,
- – объект с содержимым именованных скобок (см. главу Скобочные группы).
Если скобок в регулярном выражении нет, то будет только 3 аргумента: .
Например, переведём выбранные совпадения в верхний регистр:
Заменим каждое совпадение на его позицию в строке:
В примере ниже две скобки, поэтому функция замены вызывается с 5-ю аргументами: первый – всё совпадение, затем два аргумента содержимое скобок, затем (в примере не используются) индекс совпадения и исходная строка:
Если в регулярном выражении много скобочных групп, то бывает удобно использовать остаточные аргументы для обращения к ним:
Или, если мы используем именованные группы, то объект с ними всегда идёт последним, так что можно получить его так:
Использование функции даёт нам максимальные возможности по замене, потому что функция получает всю информацию о совпадении, имеет доступ к внешним переменным и может делать всё что угодно.
Регулярные выражения
Регулярное выражение (оно же «регэксп», «регулярка» или просто «рег»), состоит из шаблона (также говорят «паттерн») и необязательных флагов.
Существует два синтаксиса для создания регулярного выражения.
«Длинный» синтаксис:
…И короткий синтаксис, использующий слеши :
Слеши говорят JavaScript о том, что это регулярное выражение. Они играют здесь ту же роль, что и кавычки для обозначения строк.
Регулярное выражение в обоих случаях является объектом встроенного класса .
Основная разница между этими двумя способами создания заключается в том, что слеши не допускают никаких вставок переменных (наподобие возможных в строках через ). Они полностью статичны.
Слеши используются, когда мы на момент написания кода точно знаем, каким будет регулярное выражение – и это большинство ситуаций. А – когда мы хотим создать регулярное выражение «на лету» из динамически сгенерированной строки, например:
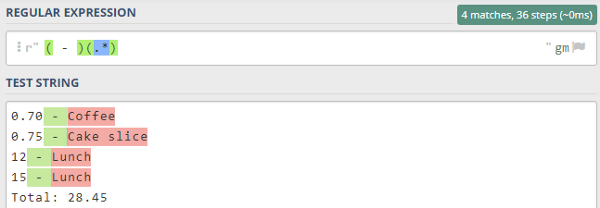
Найти все / Заменить все
Эти две задачи решаются в javascript принципиально по-разному.
Начнем с «простого».
Для замены всех вхождений используется метод String#replace.
Он интересен тем, что допускает первый аргумент — регэксп или строку.
Если первый аргумент — строка, то будет осуществлен поиск подстроки, без преобразования в регулярное выражение.
Попробуйте:
alert("2 ++ 1".replace("+", "*"))
Каков результат? Как, заменился только один плюс, а не два? Да, вот так.
В режиме регулярного выражения плюс придется заэкранировать, но зато заменит все вхождения (при указании флага ):
alert("2 ++ 1".replace(/\+/g, "*"))
Вот такая особенность работы со строкой.
Очень полезной особенностью является возможность работать с функцией вместо строки замены. Такая функция получает первым аргументом — все совпадение, а последующими аргументами — скобочные группы.
Следующий пример произведет операции вычитания:
var str = "count 36 - 26, 18 - 9"
str = str.replace(/(\d+) - (\d+)/g, function(a,b,c) { return b-c })
alert(str)
В javascript нет одного универсального метода для поиска всех совпадений.
Для поиска без запоминания скобочных групп — можно использовать String#match:
var str = "count 36-26, 18-9" var re = /(\d+)-(\d+)/g result = str.match(re) for(var i=0; i<result.length; i++) alert(result)
Как видите, оно исправно ищет все совпадения (флаг у регулярного выражения обязателен), но при этом не запоминает скобочные группы. Эдакий «облегченный вариант».
В сколько-нибудь сложных задачах важны не только совпадения, но и скобочные группы. Чтобы их найти, предлагается использовать многократный вызов RegExp#exec.
Для этого регулярное выражение должно использовать флаг . Тогда результат поиска, запомненный в свойстве объекта используется как точка отсчета для следующего поиска:
var str = "count 36-26, 18-9"
var re = /(\d+)-(\d+)/g
var res
while ( (res = re.exec(str)) != null) {
alert("Найдено " + res + ": ("+ res+") и ("+res+")")
alert("Дальше ищу с позиции "+re.lastIndex)
}
Проверка нужна т.к. значение является хорошим и означает, что вхождение найдено в самом начале строки (поиск успешен). Поэтому необходимо сравнивать именно с .
Синтаксис
regexp
Объект регулярного выражения . Сопоставление заменяется возвращаемым значением второго параметра.
substr
Строка, которая должна быть заменена на
Обратите внимание, будет заменено только первое вхождение искомой строки.
newSubStr
Строка, которая заменяет подстроку, полученную из первого параметра. Поддерживает несколько специальных шаблонов замены.
function
Функция, вызываемая для создания новой подстроки, размещаемой вместо подстроки из первого параметра.
flags
Строка, содержащая любую комбинацию флагов : g – глобальное соответствие, i – игнорировать регистр, m – соответствие по нескольким строкам
Этот параметр используется, только если первый параметр является строкой.
Опережающие и ретроспективные проверки — (?=) and (?
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> тест(?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения -> тест
Вы можете использовать оператор отрицания !
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> тест(?<!r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения -> тест
Заключение
Как вы могли убедиться, области применения регулярных выражений разнообразны. Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими:
- Валидация данных (например, правильно ли заполнена строка time)
- Сбор данных (особенно веб-скрапинг, поиск страниц, содержащих определённый набор слов в определённом порядке)
- Обработка данных (преобразование сырых данных в нужный формат)
- Парсинг (например, достать все GET параметры из URL или текст внутри скобок)
- Замена строк (даже во время написания кода в IDE, можно, например преобразовать Java или C# класс в соответствующий JSON объект, заменить “;” на “,”, изменить размер букв, избегать объявление типа и т.д.)
- Подсветка синтаксиса, переименование файла, анализ пакетов и многие другие задачи, где нужно работать со строками (где данные не должны быть текстовыми).
Перевод статьи Jonny Fox: Regex tutorial — A quick cheatsheet by examples
Пример использования
Использование флагов g и i с методом replace()
const str = 'Ты кто такой? Что ты делаешь?'; // инициализируем строковое значение const newstr = str.replace(/ты/gi, 'вы'); console.log(newstr); // "вы кто такой? Что вы делаешь?"
Перестановка слов местами
const str = 'Boris Britva'; // инициализируем строковое значение const newstr = str.replace(/(\w+)\s(\w+)/, '$2 $1'); console.log(newstr); // Britva Boris
Перевод первых букв всех слов в верхний регистр с помощью функции замены
const str = 'андрей, артем, иван, вазген'; // инициализируем строковое значение const func = (word) => word.substring(0,1).toUpperCase() + word.substring(1); // инициализируем функцию замены const newstr = str.replace(/(+)/g, func); console.log(newstr); // "Андрей, Артем, Иван, Вазген"
Определенный символ в качестве разделителя числа
const num = 123456789; // инициализируем числовое значение
const re = /\B(?=(\d{3})+(?!\d))/g; // инициализируем регулярное выражение
const newstr = num.toString().replace(re, ','); // запятые в качестве разделителя числа
const newstr2 = num.toString().replace(re, ' '); // пробелы в качестве разделителя числа
console.log(newstr); // "123,456,789"
console.log(newstr2); // "123 456 789"
JavaScript String
Точка – это любой символ
Точка – это специальный символьный класс, который соответствует «любому символу, кроме новой строки».
Для примера:
Или в середине регулярного выражения:
Обратите внимание, что точка означает «любой символ», но не «отсутствие символа». Там должен быть какой-либо символ, чтобы соответствовать условию поиска:. Обычно точка не соответствует символу новой строки
Обычно точка не соответствует символу новой строки .
То есть, регулярное выражение будет искать символ и затем , с любым символом между ними, кроме перевода строки :
Но во многих ситуациях точкой мы хотим обозначить действительно «любой символ», включая перевод строки.
Как раз для этого нужен флаг . Если регулярное выражение имеет его, то точка соответствует буквально любому символу:
Внимание, пробелы!
Обычно мы уделяем мало внимания пробелам. Для нас строки и практически идентичны.
Но если регулярное выражение не учитывает пробелы, оно может не сработать.
Давайте попробуем найти цифры, разделённые дефисом:
Исправим это, добавив пробелы в регулярное выражение :
Пробел – это символ. Такой же важный, как любой другой.
Нельзя просто добавить или удалить пробелы из регулярного выражения, и ожидать, что оно будет также работать.
Другими словами, в регулярном выражении все символы имеют значение, даже пробелы.
Объект RegExp
Объект типа , или, короче, регулярное выражение, можно создать двумя путями
/pattern/флаги
new RegExp("pattern")
— регулярное выражение для поиска (о замене — позже), а флаги — строка из любой комбинации символов (глобальный поиск), (регистр неважен) и (многострочный поиск).
Первый способ используется часто, второй — иногда. Например, два таких вызова эквивалентны:
var reg = /ab+c/i
var reg = new RegExp("ab+c", "i")
При втором вызове — т.к регулярное выражение в кавычках, то нужно дублировать
// эквивалентны
re = new RegExp("\\w+")
re = /\w+/
При поиске можно использовать большинство возможностей современного PCRE-синтаксиса.
Жадность
Это не совсем особенность, скорее фича, но все же достойная отдельного абзаца.
Все регулярные выражения в javascript — жадные. То есть, выражение старается отхватить как можно больший кусок строки.
Например, мы хотим заменить все открывающие тэги
На что и почему — не так важно
text = '1 <A href="#">...</A> 2' text = text.replace(/<A(.*)>/, 'TEST') alert(text)
При запуске вы увидите, что заменяется не открывающий тэг, а вся ссылка, выражение матчит ее от начала и до конца.
Это происходит из-за того, что точка-звездочка в «жадном» режиме пытается захватить как можно больше, в нашем случае — это как раз до последнего .
Последний символ точка-звездочка не захватывает, т.к. иначе не будет совпадения.
Как вариант решения используют квадратные скобки: :
text = '1 <A href="#">...</A> 2' text = text.replace(/<A(*)>/, 'TEST') alert(text)
Это работает. Но самым удобным вариантом является переключение точки-звездочки в нежадный режим. Это осуществляется простым добавлением знака «» после звездочки.
В нежадном режиме точка-звездочка пустит поиск дальше сразу, как только нашла совпадение:
text = '1 <A href="#">...</A> 2' text = text.replace(/<A(.*?)>/, 'TEST') alert(text)
В некоторых языках программирования можно переключить жадность на уровне всего регулярного выражения, флагом.
В javascript это сделать нельзя.. Вот такая особенность. А вопросительный знак после звездочки рулит — честное слово.
4. Key takeaway
The primitive approach to replace all occurrences is to split the string into chunks by the search string, the join back the string placing the replace string between chunks: . This approach works, but it’s hacky.
Another approach is to use with a regular expression having the global flag enabled.
Unfortunately, you cannot easily generate regular expressions from a string at runtime, because the special characters of regular expressions have to be escaped. And dealing with a regular expression for a simple replacement of strings is overwhelming.
Finally, the new string method replaces all string occurrences. The method is a proposal at stage 4, and hopefully, it will land in a new JavaScript standard pretty soon.
My recommendation is to use to replace strings.
Точка и перенос строки
Для поиска в многострочном режиме почти все модификации перловых регэкспов используют специальный multiline-флаг.
И javascript здесь не исключение.
Попробуем же сделать поиск и замену многострочного вхождения. Скажем, будем заменять на тэг подчеркивания: :
function bbtagit(text) {
text = text.replace(/\(.*?)\[\/u\]/gim, '<u>$1</u>')
return text
}
var line = "мой\n текст"
alert( bbtagit(line) )
Попробуйте запустить. Заменяет? Как бы не так!
Дело в том, что в javascript мультилайн режим (флаг ) влияет только на символы ^ и $, которые начинают матчиться с началом и концом строки, а не всего текста.
Точка по-прежнему — любой символ, кроме новой строки. В javascript нет флага, который устанавливает мультилайн-режим для точки. Для того, чтобы заматчить совсем что угодно — используйте .
Работающий вариант:
function bbtagit(text) {
text = text.replace(/\(*)\[\/u\]/gim, '<u>$1</u>')
return text
}
var line = "мой\n текст"
alert( bbtagit(line) )
Заключение
В предыдущих статьях, были рассмотрены основы регулярных выражений, а также некоторые более сложные выражения, которые могут оказаться полезными. В следующих двух статьях объясняется, как разные символы или последовательности символов работают в регулярных выражениях.
Если после прочтения приведённых выше статей вы все еще путаетесь в регулярных выражениях, советуем вам продолжить практиковаться на примерах того, как другие люди придумывают регулярные выражения.
Оригинал статьи: https://code.tutsplus.com/tutorials/a-simple-regex-cheat-sheet—cms-31278/
Перевод: Земсков Матвей