Array.length
Содержание:
- Что такое массив?
- forEach
- Неточные вычисления
- Замены в строке
- Нюансы сравнения строк
- Методы String
- Типы данных и массивы
- Перевод строки в верхний или нижний регистр.
- Немного о «length»
- clientWidth/Height
- str.replace(str|regexp, str|func)
- Array.isArray
- Замена подстроки
- Поиск подстроки в строке средствами sql
- Эффективность
- Как создать строку из массива
- Методы pop/push и shift/unshift
- Замена содержимого строки
- str.match(regexp)
- Спецсимволы
Что такое массив?
К счастью, структуры не являются единственным агрегированным типом данных в языке C++. Есть еще массив — совокупный тип данных, который позволяет получить доступ ко всем переменным одного и того же типа данных через использование одного идентификатора.
Рассмотрим случай, когда нужно записать результаты тестов 30 студентов в классе. Без использования массива нам придется выделить почти 30 одинаковых переменных!
// Выделяем 30 целочисленных переменных (каждая с разным именем)
int testResultStudent1;
int testResultStudent2;
int testResultStudent3;
// …
int testResultStudent30;
|
1 |
// Выделяем 30 целочисленных переменных (каждая с разным именем) inttestResultStudent1; inttestResultStudent2; inttestResultStudent3; // … inttestResultStudent30; |
С использованием массива всё гораздо проще. Следующая строка эквивалентна коду, приведенному выше:
int testResult; // выделяем 30 целочисленных переменных, используя фиксированный массив
| 1 | inttestResult30;// выделяем 30 целочисленных переменных, используя фиксированный массив |
В объявлении переменной массива мы используем квадратные скобки , чтобы сообщить компилятору, что это переменная массива (а не обычная переменная), а в скобках — количество выделяемых элементов (это называется длиной или размером массива).
В примере, приведенном выше, мы объявили фиксированный массив с именем и длиной 30. Фиксированный массив (или «массив фиксированной длины») представляет собой массив, размер которого известен во время компиляции. При создании , компилятор выделит 30 целочисленных переменных.
forEach
Синтаксис метода:
имя_массива.forEach(callback, thisArg)
В качестве первого аргумента указывается callback-функция, которую метод forEach() будет вызывать для каждого элемента массива. Реализацию вызываемой функции-обработчика нужно писать самим. Вызываемая функция должна иметь три параметра: первый параметр принимает в качестве аргумента — значение элемента массива, второй — индекс элемента, и третий — сам массив. Однако, если нужно использовать только значения элементов массива, можно написать функцию только с одним параметром. Второй аргумент — thisArg (необязательный) будет передан в качестве значения this.
var arr = ;
function foo(value) {
var sum = value * this;
return document.write(sum + "");
}
arr.forEach(foo, 5); //второй аргумент будет передан в качестве значения this
//пример с тремя параметрами
var a = ;
a.forEach(function(el, idx, a) {
document.write('a = '+el+' в <br>');
});
Попробовать »
Неточные вычисления
Внутри JavaScript число представлено в виде 64-битного формата IEEE-754. Для хранения числа используется 64 бита: 52 из них используется для хранения цифр, 11 из них для хранения положения десятичной точки (если число целое, то хранится 0), и один бит отведён на хранение знака.
Если число слишком большое, оно переполнит 64-битное хранилище, JavaScript вернёт бесконечность:
Наиболее часто встречающаяся ошибка при работе с числами в JavaScript – это потеря точности.
Посмотрите на это (неверное!) сравнение:
Да-да, сумма и не равна .
Странно! Что тогда, если не ?
Но почему это происходит?
Число хранится в памяти в бинарной форме, как последовательность бит – единиц и нулей. Но дроби, такие как , , которые выглядят довольно просто в десятичной системе счисления, на самом деле являются бесконечной дробью в двоичной форме.
Другими словами, что такое ? Это единица делённая на десять — , одна десятая. В десятичной системе счисления такие числа легко представимы, по сравнению с одной третьей: , которая становится бесконечной дробью .
Деление на гарантированно хорошо работает в десятичной системе, но деление на – нет. По той же причине и в двоичной системе счисления, деление на обязательно сработает, а становится бесконечной дробью.
В JavaScript нет возможности для хранения точных значений 0.1 или 0.2, используя двоичную систему, точно также, как нет возможности хранить одну третью в десятичной системе счисления.
Числовой формат IEEE-754 решает эту проблему путём округления до ближайшего возможного числа. Правила округления обычно не позволяют нам увидеть эту «крошечную потерю точности», но она существует.
Пример:
И когда мы суммируем 2 числа, их «неточности» тоже суммируются.
Вот почему – это не совсем .
Не только в JavaScript
Справедливости ради заметим, что ошибка в точности вычислений для чисел с плавающей точкой сохраняется в любом другом языке, где используется формат IEEE 754, включая PHP, Java, C, Perl, Ruby.
Можно ли обойти проблему? Конечно, наиболее надёжный способ — это округлить результат используя метод toFixed(n):
Также можно временно умножить число на 100 (или на большее), чтобы привести его к целому, выполнить математические действия, а после разделить обратно. Суммируя целые числа, мы уменьшаем погрешность, но она все равно появляется при финальном делении:
Таким образом, метод умножения/деления уменьшает погрешность, но полностью её не решает.
Забавный пример
Попробуйте выполнить его:
Причина та же – потеря точности. Из 64 бит, отведённых на число, сами цифры числа занимают до 52 бит, остальные 11 бит хранят позицию десятичной точки и один бит – знак. Так что если 52 бит не хватает на цифры, то при записи пропадут младшие разряды.
Интерпретатор не выдаст ошибку, но в результате получится «не совсем то число», что мы и видим в примере выше. Как говорится: «как смог, так записал».
Два нуля
Другим забавным следствием внутреннего представления чисел является наличие двух нулей: и .
Все потому, что знак представлен отдельным битом, так что, любое число может быть положительным и отрицательным, включая нуль.
В большинстве случаев это поведение незаметно, так как операторы в JavaScript воспринимают их одинаковыми.
Замены в строке

-
Простой способ замены слова в строке:
let s = 'Hello world world!'; let s_new = s.replace(' world', ''); console.log(s_new); // Hello world!Недостаток: будет заменено только первое найденное совпадение.
-
Замена всех совпадений:
let s = 'Hello world world!'; let Regex = / world/gi; let s_new = s.replace(Regex, ''); console.log(s_new); // Hello!
Флаг «g» указывает на то, что регулярное выражение должно проверять все возможные сопоставления. Директива «i» указывает на поиск без учета регистра. То есть, слово « World» тоже будет заменено.
-
Этот же способ применим для замены года. Регулярное выражение укажем сразу внутри функции.
let s = 'Happy new 2020 year!'; let s_new = s.replace(/(\d+)/, '2021'); console.log(s_new); // Happy new 2021 year!
Нюансы сравнения строк
Если мы
проверяем строки на равенство, то никаких особых проблем в JavaScript это не
вызывает, например:
if("abc" == "abc") console.log( "строки равны" );
if("abc" != "ABC") console.log( "строки не равны" );
Но, когда мы
используем знаки больше/меньше, то строки сравниваются в лексикографическом
порядке. То есть:
1. Если код
текущего символа одной строки больше кода текущего символа другой строки, то
первая строка больше второй (остальные символы не имеют значения), например:
console.log( "z" > "Za" ); //true
2. Если код
текущего символа одной строки меньше кода текущего символа другой строки, то
первая строка меньше второй:
console.log( "B" < "a" ); //true
3. При равенстве
символов больше та строка, которая содержит больше символов:
console.log( "abc" < "abcd" ); //true
4. В остальных
случаях строки равны:
console.log( "abc" == "abc" ); //true
Но в этом
алгоритме есть один нюанс. Например, вот такое сравнение:
console.log( "Америка" > "Japan" ); //true
Дает значение true, так как
русская буква A имеет больший
код, чем латинская буква J. В этом легко убедиться,
воспользовавшись методом
str.codePointAt(pos)
который
возвращает код символа, стоящего в позиции pos:
console.log( "А".codePointAt(), "J".codePointAt() );
Сморите, у буквы
А код равен 1040, а у буквы J – 74. Напомню,
что строки в JavaScript хранятся в
кодировке UTF-16. К чему
может привести такой результат сравнения? Например, при сортировке мы получим
на первом месте страну «Japan», а потом «Америка». Возможно, это не
то, что нам бы хотелось? И здесь на помощь приходит специальный метод для
корректного сравнения таких строк:
str.localeCompare(compareStr)
он возвращает
отрицательное число, если str < compareStr, положительное
при str > compareStr и 0 если строки
равны. Например:
console.log( "Америка".localeCompare("Japan") ); // -1
возвращает -1
как и должно быть с учетом языкового сравнения. У этого метода есть два
дополнительных аргумента, которые указаны в документации JavaScript. Первый
позволяет указать язык (по умолчанию берётся из окружения) — от него зависит
порядок букв. Второй позволяет определять дополнительные правила, например, чувствительность
к регистру.
Методы String
| Метод | Описание |
|---|---|
| charAt() | Возвращает символ строки с указанным индексом (позицией). |
| charCodeAt() | Возвращает числовое значение Unicode символа, индекс которого был передан методу в качестве аргумента. |
| concat() | Возвращает строку, содержащую результат объединения двух и более предоставленных строк. |
| fromCharCode() | Возвращает строку, созданную с помощью указанной последовательности значений символов Unicode. |
| indexOf() | Возвращает позицию первого символа первого вхождения указанной подстроки в строке. |
| lastIndexOf() | Возвращает позицию последнего найденного вхождения подстроки или -1, если подстрока не найдена. |
| localeCompare() | Возвращает значение, указывающее, эквивалентны ли две строки в текущем языковом стандарте. |
| match() | Ищет строку, используя предоставленный шаблон регулярного выражения, и возвращает результат в виде массива. Если совпадений не найдено, метод возвращает значение null. |
| replace() | Ищет строку для указанного значения или регулярного выражения и возвращает новую строку, где указанные значения будут заменены. Метод не изменяет строку, для которой он вызывается. |
| search() | Возвращает позицию первого соответствия указанной подстроки или регулярного выражения в строке. |
| slice() | Позволяет извлечь подстроку из строки. Первый аргумент указывает индекс с которого нужно начать извлечение. Второй необязательный аргумент указывает позицию, на которой должно остановиться извлечение. Если второй аргумент не указан, то извлечено будет все с той позиции, которую указывает первый аргумент, и до конца строки. |
| split() | Разбивает строку на подстроки, возвращая массив подстрок. В качестве аргумента можно передать символ разделитель (например запятую), используемый для разбора строки на подстроки. |
| substr() | Позволяет извлечь подстроку из строки. Первый аргумент указывает индекс с которого нужно начать извлечение. Второй аргумент указывает количество символов, которое нужно извлечь. |
| substring() | Извлекает символы из строки между двух указанных индексов, если указан только один аргумент, то извлекаются символы от первого индекса и до конца строки. |
| toLocaleLowerCase() | Преобразует символы строки в нижний регистр с учетом текущего языкового стандарта. |
| toLocaleUpperCase() | Преобразует символы строки в верхний регистр с учетом текущего языкового стандарта. |
| toLowerCase() | Конвертирует все символы строки в нижний регистр и возвращает измененную строку. |
| toString() | Возвращает строковое представление объекта. |
| toUpperCase() | Конвертирует все символы строки в верхний регистр и возвращает измененную строку. |
| trim() | Удаляет пробелы в начале и конце строки и возвращает измененную строку. |
| valueOf() | Возвращает примитивное значение объекта. |
Типы данных и массивы
Массив может быть любого типа данных. Например, объявляем массив типа double:
#include <iostream>
int main()
{
double array; // выделяем 3 переменные типа double
array = 3.5;
array = 2.4;
array = 3.4;
std::cout << «The average is » << (array + array + array) / 3 << «\n»;
return 0;
}
|
1 |
#include <iostream> intmain() { doublearray3;// выделяем 3 переменные типа double array=3.5; array1=2.4; array2=3.4; std::cout<<«The average is «<<(array+array1+array2)3<<«\n»; return; } |
Результат выполнения программы:
Массивы также можно сделать из структур, например:
struct Rectangle
{
int length;
int width;
};
Rectangle rects; // объявляем массив с 4-мя прямоугольниками
|
1 |
structRectangle { intlength; intwidth; }; Rectangle rects4;// объявляем массив с 4-мя прямоугольниками |
Чтобы получить доступ к члену структуры из элемента массива, сначала нужно выбрать элемент массива, затем использовать оператор выбора члена структуры, а затем требуемый член структуры:
rects.length = 15;
| 1 | rects.length=15; |
Перевод строки в верхний или нижний регистр.
Есть 4 метода для перевода. Первые 2 переводят строку в верхний регистр:
var stringOne = "Speak up, I can't hear you."; var stringTwo = stringOne.toLocaleUpperCase(); // "SPEAK UP, I CAN'T HEAR YOU" var stringThree = stringOne.toUpperCase(); // "SPEAK UP, I CAN'T HEAR YOU"
Другие 2 переводят строку в нижний регистр:
var stringOne = "YOU DON'T HAVE TO YELL"; var stringTwo = stringOne.toLocaleLowerCase(); // "you don't have to yell" var stringThree = stringOne.toLowerCase(); // "you don't have to yell"
Лучше использовать «locale» методы, т.к. в разных местах, например, в Турции отображение регистров работает не совсем так, как мы привыкли и поэтому результат может быть тот, который мы хотели. Если использовать «locale» методы, то таких проблем не будет.
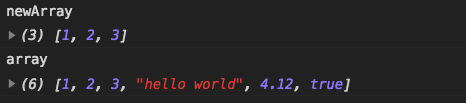
Немного о «length»
Свойство автоматически обновляется при изменении массива. Если быть точными, это не количество элементов массива, а наибольший цифровой индекс плюс один.
Например, единственный элемент, имеющий большой индекс, даёт большую длину:
Обратите внимание, что обычно мы не используем массивы таким образом. Ещё один интересный факт о свойстве – его можно перезаписать
Ещё один интересный факт о свойстве – его можно перезаписать.
Если мы вручную увеличим его, ничего интересного не произойдёт. Зато, если мы уменьшим его, массив станет короче. Этот процесс необратим, как мы можем понять из примера:
Таким образом, самый простой способ очистить массив – это .
clientWidth/Height
Эти свойства – размер элемента внутри рамок .
Они включают в себя ширину содержимого вместе с полями , но без прокрутки.
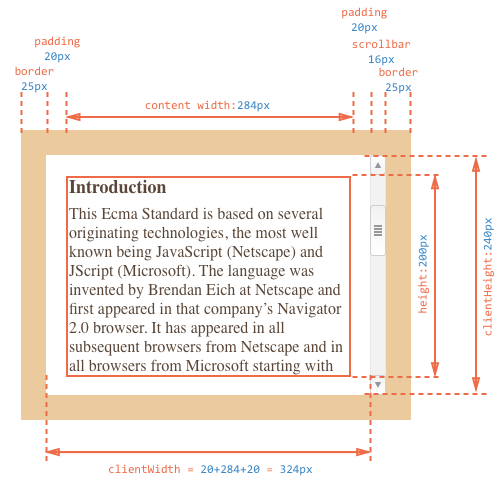
На рисунке выше посмотрим вначале на , её посчитать проще всего. Прокрутки нет, так что это в точности то, что внутри рамок: CSS-высота плюс верхнее и нижнее поля (по ), итого .
На рисунке нижний заполнен текстом, но это неважно: по правилам он всегда входит в. Теперь – ширина содержимого здесь не равна CSS-ширине, её часть «съедает» полоса прокрутки.
Поэтому в входит не CSS-ширина, а реальная ширина содержимого плюс левое и правое поля (по ), итого
Теперь – ширина содержимого здесь не равна CSS-ширине, её часть «съедает» полоса прокрутки.
Поэтому в входит не CSS-ширина, а реальная ширина содержимого плюс левое и правое поля (по ), итого .
Если нет, то в точности равны размеру области содержимого, внутри рамок и полосы прокрутки.

Поэтому в тех случаях, когда мы точно знаем, что нет, их используют для определения внутренних размеров элемента.
str.replace(str|regexp, str|func)
Это универсальный метод поиска-и-замены, один из самых полезных. Этакий швейцарский армейский нож для поиска и замены в строке.
Мы можем использовать его и без регулярных выражений, для поиска-и-замены подстроки:
Хотя есть подводный камень.
Когда первый аргумент является строкой, он заменяет только первое совпадение.
Вы можете видеть это в приведённом выше примере: только первый заменяется на .
Чтобы найти все дефисы, нам нужно использовать не строку , а регулярное выражение с обязательным флагом :
Второй аргумент – строка замены. Мы можем использовать специальные символы в нем:
| Спецсимволы | Действие в строке замены |
|---|---|
| вставляет | |
| вставляет всё найденное совпадение | |
| вставляет часть строки до совпадения | |
| вставляет часть строки после совпадения | |
| если это 1-2 значное число, то вставляет содержимое n-й скобки | |
| вставляет содержимое скобки с указанным именем |
Например:
Для ситуаций, которые требуют «умных» замен, вторым аргументом может быть функция.
Она будет вызываться для каждого совпадения, и её результат будет вставлен в качестве замены.
Функция вызывается с аргументами :
- – найденное совпадение,
- – содержимое скобок (см. главу Скобочные группы).
- – позиция, на которой найдено совпадение,
- – исходная строка,
- – объект с содержимым именованных скобок (см. главу Скобочные группы).
Если скобок в регулярном выражении нет, то будет только 3 аргумента: .
Например, переведём выбранные совпадения в верхний регистр:
Заменим каждое совпадение на его позицию в строке:
В примере ниже две скобки, поэтому функция замены вызывается с 5-ю аргументами: первый – всё совпадение, затем два аргумента содержимое скобок, затем (в примере не используются) индекс совпадения и исходная строка:
Если в регулярном выражении много скобочных групп, то бывает удобно использовать остаточные аргументы для обращения к ним:
Или, если мы используем именованные группы, то объект с ними всегда идёт последним, так что можно получить его так:
Использование функции даёт нам максимальные возможности по замене, потому что функция получает всю информацию о совпадении, имеет доступ к внешним переменным и может делать всё что угодно.
Array.isArray
Массивы не
образуют отдельный тип языка. Они основаны на объектах. Поэтому typeof не может
отличить простой объект от массива:
console.log(typeof {}); // object
console.log (typeof ); // тоже object
Но массивы
используются настолько часто, что для этого придумали специальный метод: Array.isArray(value). Он возвращает
true, если value массив, и false, если нет.
console.log(Array.isArray({})); // false
console.log(Array.isArray()); // true
Подведем итоги
по рассмотренным методам массивов. У нас получился следующий список:
|
Для |
|
|
push(…items) |
добавляет элементы в конец |
|
pop() |
извлекает элемент с конца |
|
shift() |
извлекает элемент с начала |
|
unshift(…items) |
добавляет элементы в начало |
|
splice(pos, deleteCount, …items) |
начиная с индекса pos, удаляет |
|
slice(start, end) |
создаёт новый массив, копируя в него |
|
concat(…items) |
возвращает новый массив: копирует все |
|
Для поиска |
|
|
indexOf/lastIndexOf(item, pos) |
ищет item, начиная с позиции pos, и |
|
includes(value) |
возвращает true, если в массиве |
|
find/filter(func) |
фильтрует элементы через функцию и |
|
findIndex(func) |
похож на find, но возвращает индекс |
|
Для перебора |
|
|
forEach(func) |
вызывает func для каждого элемента. |
|
Для |
|
|
map(func) |
создаёт новый массив из результатов |
|
sort(func) |
сортирует массив «на месте», а потом |
|
reverse() |
«на месте» меняет порядок следования |
|
split/join |
преобразует строку в массив и обратно |
|
reduce(func, initial) |
вычисляет одно значение на основе |
Видео по теме
JavaScipt #1: что это такое, с чего начать, как внедрять и запускать
JavaScipt #2: способы объявления переменных и констант в стандарте ES6+
JavaScript #3: примитивные типы number, string, Infinity, NaN, boolean, null, undefined, Symbol
JavaScript #4: приведение типов, оператор присваивания, функции alert, prompt, confirm
JavaScript #5: арифметические операции: +, -, *, /, **, %, ++, —
JavaScript #6: условные операторы if и switch, сравнение строк, строгое сравнение
JavaScript #7: операторы циклов for, while, do while, операторы break и continue
JavaScript #8: объявление функций по Function Declaration, аргументы по умолчанию
JavaScript #9: функции по Function Expression, анонимные функции, callback-функции
JavaScript #10: анонимные и стрелочные функции, функциональное выражение
JavaScript #11: объекты, цикл for in
JavaScript #12: методы объектов, ключевое слово this
JavaScript #13: клонирование объектов, функции конструкторы
JavaScript #14: массивы (array), методы push, pop, shift, unshift, многомерные массивы
JavaScript #15: методы массивов: splice, slice, indexOf, find, filter, forEach, sort, split, join
JavaScript #16: числовые методы toString, floor, ceil, round, random, parseInt и другие
JavaScript #17: методы строк — length, toLowerCase, indexOf, includes, startsWith, slice, substring
JavaScript #18: коллекции Map и Set
JavaScript #19: деструктурирующее присваивание
JavaScript #20: рекурсивные функции, остаточные аргументы, оператор расширения
JavaScript #21: замыкания, лексическое окружение, вложенные функции
JavaScript #22: свойства name, length и методы call, apply, bind функций
JavaScript #23: создание функций (new Function), функции setTimeout, setInterval и clearInterval
Замена подстроки
Чтобы заменить вхождение подстроки в строке на другую подстроку, вы можете использовать replace():
var slugger = "Josh Hamilton";
var betterSlugger = slugger.replace("h Hamilton", "e Bautista");
console.log(betterSlugger); // "Jose Bautista"
Первый аргумент — то, что вы хотите заменить и второй аргумент — новая строка. Функция заменяет только первое вхождение подстроки в строку.
Чтобы заменить все вхождения, нужно использовать регулярное выражение с глобальным флагом:
var myString = "She sells automotive shells on the automotive shore"; var newString = myString.replace(/automotive/g, "sea"); console.log(newString); // "She sells sea shells on the sea shore"
Второй аргумент может включать специальный шаблон или функцию. Подробней можно почитать здесь.
Поиск подстроки в строке средствами sql
Для вычисления позиции подстроки в строке в языке sql существует несколько функций. Первая, которую мы рассмотрим, функция POSITION:
integer POSITION(substr string IN str string)
Возвращает номер позиции первого вхождения подстроки substr в строке str и возвращает 0 если подстрока не найдена. Функция POSITION может работать с многобайтовыми символами.
Пример:
SELECT POSITION (‘cd’ IN ‘abcdcde’);
Результат: 3
SELECT POSITION (‘xy’ IN ‘abcdcde’);
Результат: 0
Следующая функция LOCATE позволяет начинать поиск подстроки с определенной позиции:
integer LOCATE(substr string, str string, pos integer)
Возвращает позицию первого вхождения подстроки substr в строке str, начиная с позиции pos. Если параметр pos не задан, то поиск осуществляется с начала строки. Если подстрока substr не найдена, то возвращает 0. Поддерживает многобайтовые символы.
Пример:
SELECT LOCATE (‘cd’, ‘abcdcdde’, 5);
Результат: 5
SELECT LOCATE (‘cd’, ‘abcdcdde’);
Результат: 3
Аналогом функций POSITION и LOCATE является функция INSTR:
integer INSTR(str string, substr string)
Также как и функции выше возвращает позицию первого вхождения подстроки substr в строке str. Единственное отличие от функций POSITION и LOCATE то, что аргументы поменяны местами.
Далее рассмотрим функции, которые помогают получить подстроку.
Первыми рассмотрим сразу две функции LEFT и RIGHT, которые похожи по своему действию:
string LEFT(str string, len integer)string RIGHT(str string, len integer)
Функция LEFT возвращает len первых символов из строки str, а функция RIGHT столько же последних. Поддерживают многобайтовые символы.
Пример:
SELECT LEFT (‘Москва’, 3);
Результат: Мос
SELECT RIGHT (‘Москва’, 3);
Результат: ква
Далее рассмотрим одинаковые по итоговому результату функции SUBSTRING и MID:
string SUBSTRING(str string, pos integer, len integer)string MID(str string, pos integer, len integer)
Функции позволяют получить подстроку строки str длиною len символов с позиции pos. В случае если параметр len не задан, то возвращается вся подстрока начиная с позиции pos.
Пример:
SELECT SUBSTRING (‘г. Москва — столица России’, 4, 6);
Результат: Москва
SELECT SUBSTRING (‘г. Москва — столица России’, 4);
Результат: Москва — столица России
Примеры с функцией MID не привожу, потому что результаты будут аналогичные.
Интересная функция SUBSTRING_INDEX:
string SUBSTRING_INDEX(str string, delim string, count integer)
Функция возвращает подстроку строки str, полученную путем удаления символов, идущих после разделителя delim, находящимся в позиции count. Параметр count может быть как положительным, так отрицательным. Если count положительный, то отсчет позиции разделителя будет вестись слева и удаляться будут символы находящиеся справа от разделителя. Если count отрицательный, то отсчет позиции разделителя ведется справа и удаляются символы находящиеся слева от разделителя. Возможно, описание получилось слишком запутанным, но на примерах станет понятней.
Пример:
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, 1);
Результат: www
В данном примере функция находит, первое вхождения символа точки в строке «www.mysql.ru» и удаляет все символы, идущие после нее, включая сам разделитель.
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, 2);
Результат: www.mysql
Здесь функция ищет второе вхождение точки, удаляет все символы справа от нее и возвращает получившуюся подстроку. И еще один пример с отрицательным значением параметра count:
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, -2);
Результат: mysql.ru
В этом примере функция SUBSTRING_INDEX ищет вторую точку, отсчитывая позицию справа, удаляет символы слева от нее и выдает полученную подстроку.
Эффективность
Методы выполняются быстро, а методы – медленно.
Почему работать с концом массива быстрее, чем с его началом? Давайте посмотрим, что происходит во время выполнения:
Просто взять и удалить элемент с номером недостаточно. Нужно также заново пронумеровать остальные элементы.
Операция должна выполнить 3 действия:
- Удалить элемент с индексом .
- Сдвинуть все элементы влево, заново пронумеровать их, заменив на , на и т.д.
- Обновить свойство .
Чем больше элементов содержит массив, тем больше времени потребуется для того, чтобы их переместить, больше операций с памятью.
То же самое происходит с : чтобы добавить элемент в начало массива, нам нужно сначала сдвинуть существующие элементы вправо, увеличивая их индексы.
А что же с ? Им не нужно ничего перемещать. Чтобы удалить элемент в конце массива, метод очищает индекс и уменьшает значение .
Действия при операции :
Метод не требует перемещения, потому что остальные элементы остаются с теми же индексами. Именно поэтому он выполняется очень быстро.
Аналогично работает метод .
Как создать строку из массива
Могут быть ситуации, когда вы просто хотите создать строку, объединив элементы массива. Для этого вы можете использовать метод join(). Этот метод принимает необязательный параметр, который является строкой-разделителем, которая добавляется между каждым элементом. Если вы опустите разделитель, то JavaScript будет использовать запятую (,) по умолчанию. В следующем примере показано, как это работает:
var colors = ;
document.write(colors.join()); // Результат: Red,Green,Blue
document.write(colors.join("")); // Результат: RedGreenBlue
document.write(colors.join("-")); // Результат: Red-Green-Blue
document.write(colors.join(", ")); // Результат: Red, Green, Blue
Вы также можете преобразовать массив в строку через запятую, используя toString(). Этот метод не принимает параметр разделителя, как это делает join(). Пример работы метода toString():
var colors = ; document.write(colors.toString()); // Результат: Red,Green,Blue
Методы pop/push и shift/unshift
Рассмотрим методы pop() и push(). Эти методы позволяют работать с массивами как со стеками. Стек — это структура данных, в которой доступ к элементам организован по принципу LIFO (англ. last in — first out, «последним пришёл — первым ушел»). Принцип работы стека можно сравнить со стопкой тарелок: чтобы взять вторую сверху, нужно снять верхнюю. Как это работает изображено на рисунке:

И так вернемся к рассмотрению методов push() и pop(). Метод push() добавляет один или несколько новых элементов в конец массива и возвращает его новую длину. Метод pop() — удаляет последний элемент массива, уменьшает длину массива и возвращает удаленное им значение
Стоит обратить внимание на то, что оба эти метода изменяют массив на месте, а не создают его модифицированную копию
var foo = []; // foo: []
foo.push(1,2); // foo: Возвращает 2
foo.pop(); // foo: Возвращает 2
foo.push(3); // foo: Возвращает 2
foo.pop(); // foo: Возвращает 3
foo.push(); // foo: ] Возвращает 2
foo.pop() // foo: Возвращает
foo.pop(); // foo: [] Возвращает 1
var fruits = ;
var picked = fruits.pop();
document.write("Вы сорвали мои " + picked);
Попробовать »
Методы shift() и unshift() ведут себя во многом также, как pop() и push(), за исключением того, что они вставляют и удаляют элементы в начале массива. Метод unshift() смещает существующие элементы в сторону больших индексов для освобождения места под новые элементы, добавляет один или несколько элементов в начало массива и возвращает новую длину массива. Метод shift() удаляет первый элемент массива и возвращает его значение, смещая все последующие элементы для занятия свободного места в начале массива.
var f = []; // f:[] f.unshift(1); // f: Возвращает: 1 f.unshift(22); // f: Возвращает: 2 f.shift(); // f: Возвращает: 22 f.unshift(3,); // f:,1] Возвращает: 3 f.shift(); // f:,1] Возвращает: 3 f.shift(); // f: Возвращает: f.shift(); // f:[] Возвращает: 1
Замена содержимого строки
Метод Replace () заменяет указанное значение другим значением в строке:
Пример
str = «Please visit Microsoft!»;
var n = str.replace(«Microsoft», «W3Schools»);
Метод Replace () не изменяет строку, в которой он вызывается. Возвращает новую строку.
По умолчанию функция Replace () заменяет только первое совпадение:
Пример
str = «Please visit Microsoft and Microsoft!»;
var n = str.replace(«Microsoft», «W3Schools»);
По умолчанию функция Replace () учитывает регистр. Написание Microsoft (с верхним регистром) не будет работать:
Пример
str = «Please visit Microsoft!»;
var n = str.replace(«MICROSOFT», «W3Schools»);
Чтобы заменить регистр без учета регистра, используйте регулярное выражение с пометкой » i » (нечувствительно):
Пример
str = «Please visit Microsoft!»;
var n = str.replace(/MICROSOFT/i, «W3Schools»);
Обратите внимание, что регулярные выражения записываются без кавычек. Чтобы заменить все совпадения, используйте регулярное выражение с флагом /g (глобальное совпадение):
Чтобы заменить все совпадения, используйте регулярное выражение с флагом /g (глобальное совпадение):
Пример
str = «Please visit Microsoft and Microsoft!»;
var n = str.replace(/Microsoft/g, «W3Schools»);
Вы узнаете намного больше о регулярных выражениях в главе регулярные выражения JavaScript.
str.match(regexp)
Метод ищет совпадения с в строке .
У него есть три режима работы:
-
Если у регулярного выражения нет флага , то он возвращает первое совпадение в виде массива со скобочными группами и свойствами (позиция совпадения), (строка поиска, равна ):
-
Если у регулярного выражения есть флаг , то он возвращает массив всех совпадений, без скобочных групп и других деталей.
-
Если совпадений нет, то, вне зависимости от наличия флага , возвращается .
Это очень важный нюанс. При отсутствии совпадений возвращается не пустой массив, а именно . Если об этом забыть, можно легко допустить ошибку, например:
Если хочется, чтобы результатом всегда был массив, можно написать так:
Спецсимволы
Если мы применяем одинарные либо двойные кавычки, мы тоже можем создавать многострочные строки. Для этого понадобится символ перевода строки \n:
let guestList = "Guests:\n * Bob\n * Petr\n * Maria"; alert(guestList); // список гостей из нескольких строк
Две строки ниже являются эквивалентными. Разница в том, что они по-разному записаны:
// используем спецсимвол перевода строки let str1 = "Hello\nWorld"; // используем обратные кавычки let str2 = `Hello World`; alert(str1 == str2); // true
Существует и масса других спецсимволов:

Рассмотрим парочку примеров с Юникодом:
//
alert( "\u00A9" );
// Длинные коды
// 佫, редкий китайский иероглиф
alert( "\u{20331}" );
// , улыбающийся смайлик с глазами-сердечками
alert( "\u{1F60D}" );
Как правило, спецсимволы начинаются с символа экранирования, представляющего собой обратный слеш \. Его можно использовать и для того, чтобы вставлять в строки кавычки:
alert( 'I\'m the God!' ); // I'm the God!
Но экранировать нужно только тогда, когда внутри строки мы используем такие же кавычки, в которые эта самая строка заключена. Таким образом, можно поступать проще:
alert( `I'm the Walrus!` ); // I'm the Walrus!
Как видите, мы поместили строку в косые кавычки, а раздели I’m одинарной кавычкой. Просто и элегантно.
Кстати, если вдруг потребуется добавить в нашу строку сам обратный слеш, то мы экранируем его вторым обратным слешем:
alert( `The backslash: \\` ); // The backslash: \