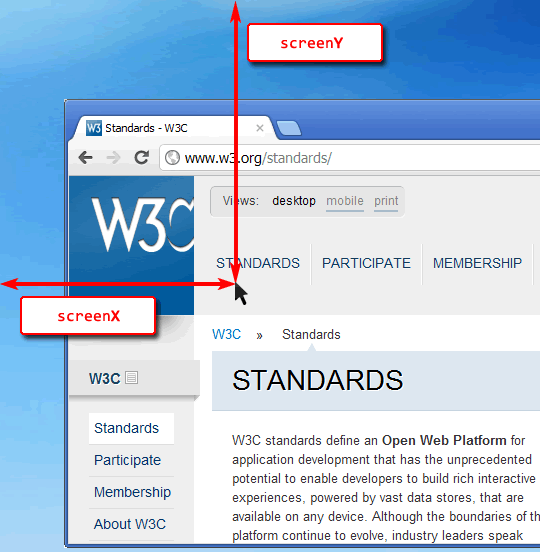
List.indexof method
Содержание:
- Код
- Значения параметров
- Определение и применение
- JavaScript
- 2 Поиск подстрок
- Методы строк
- Array.isArray
- Поиск подстроки или символа в строке в Java
- Содержит ли строка текст?Does a string contain text?
- Эффективные варианты обработки данных
- Сравнение строк
- Строки и класс System.String
- Где искомый текст находится в строке?Where does the sought text occur in a string?
- Нюансы сравнения строк
- Извлечение символов и подстрок
Код
1 /*
2 Строковые функции indexOf() и lastIndexOf()
3
4 Несколько примеров того, как анализировать строки, а также искать и заменять в них определенные символы.
5
6 Создан 27 июля 2010,
7 модифицирован 2 апреля 2012 Томом Иго (Tom Igoe)
8
9 http://arduino.cc/en/Tutorial/StringIndexOf
10
11 Этот код не защищен авторским правом.
12 */
13
14 void setup() {
15 // Инициализируем последовательную передачу данных и ждем открытия порта:
16 Serial.begin(9600);
17 while (!Serial) {
18 ; // ждем подключения последовательного порта (нужно только для Leonardo)
19 }
20
21 // Отсылаем вступительную часть:
22 Serial.println("\n\nString indexOf() and lastIndexOf() functions:");
23 Serial.println();
24 }
25
26 void loop() {
27 // Функция indexOf() возвращает самую первую позицию (т.е. индекс) определенного символа, находящегося в строке.
28 // Ее можно использовать, например, при анализе HTML-тегов:
29 String stringOne = "<HTML><HEAD><BODY>";
30 int firstClosingBracket = stringOne.indexOf('>');
31 Serial.println("The index of > in the string " + stringOne + " is " + firstClosingBracket);
32
33 stringOne = "<HTML><HEAD><BODY>";
34 int secondOpeningBracket = firstClosingBracket + 1;
35 int secondClosingBracket = stringOne.indexOf('>', secondOpeningBracket );
36 Serial.println("The index of the second > in the string " + stringOne + " is " + secondClosingBracket);
37
38 // Кроме того, при помощи indexOf() можно искать и совокупности символов
39 // или даже целые строки:
40 stringOne = "<HTML><HEAD><BODY>";
41 int bodyTag = stringOne.indexOf("<BODY>");
42 Serial.println("The index of the body tag in the string " + stringOne + " is " + bodyTag);
43
44 stringOne = "<UL><LI>item<LI>item<LI>item</UL>";
45 int firstListItem = stringOne.indexOf("<LI>");
46 int secondListItem = stringOne.indexOf("item", firstListItem + 1 );
47 Serial.println("The index of the second list item in the string " + stringOne + " is " + secondClosingBracket);
48
49 // Функция lastIndexOf() возвращает самый последний индекс заданного символа, находящегося в строке:
50 int lastOpeningBracket = stringOne.lastIndexOf('<');
51 Serial.println("The index of the last < in the string " + stringOne + " is " + lastOpeningBracket);
52
53 int lastListItem = stringOne.lastIndexOf("<LI>");
54 Serial.println("The index of the last list item in the string " + stringOne + " is " + lastListItem);
55
56
57 // при помощи lastIndexOf() тоже можно искать совокупности символов и строки:
58 stringOne = "<p>Lorem ipsum dolor sit amet</p><p>Ipsem</p><p>Quod</p>";
59 int lastParagraph = stringOne.lastIndexOf("<p");
60 int secondLastGraf = stringOne.lastIndexOf("<p", lastParagraph - 1);
61 Serial.println("The index of the second last paragraph tag " + stringOne + " is " + secondLastGraf);
62
63 // Пока условие верно, ничего не делаем:
64 while(true);
65 }
Значения параметров
| Параметр | Описание |
|---|---|
| searchElement | Значение, которое требуется найти внутри массива. Обязательное значение. |
| fromIndex | Целое число, определяющее индекс массива, с которого начинается поиск элемента массива (поиск осуществляется в порядке убывания индекса). Необязательное значение, если не указано, то поиск осуществляется с последнего индекса в массиве. Допускается использование отрицательных значений, в этом случае индекс с которого будет произведено сравнение элементов будет расчитан по следующей формуле: length (длина массива) + fromIndex. Если рассчитанный индекс окажется меньше 0, массив не просматривается. |
Определение и применение
JavaScript метод findIndex() возвращает значение индекса элемента в массиве, который соответствует условию в переданной функции, или -1, если ни один элемент не удовлетворяет условию в переданной функции.
Обращаю Ваше внимание, что функция обратного вызова, переданная в качестве параметра метода findIndex() не будет вызвана для пропущенных элементов массива. Метод findIndex() не изменяет массив для которого он был вызван
Диапазон элементов, обрабатываемых с помощью метода findIndex() устанавливается перед первым вызовом функции обратного вызова. Если элементы были добавлены к массиву после её вызова, то на таких элементах функция вызвана не будет.
Если значения существующих элементов массива изменяются в момент выполнения, то в качестве передаваемого значения функции будет значение в тот момент времени, когда метод findIndex() посещает их.
JavaScript
JS Array
concat()
constructor
copyWithin()
entries()
every()
fill()
filter()
find()
findIndex()
forEach()
from()
includes()
indexOf()
isArray()
join()
keys()
length
lastIndexOf()
map()
pop()
prototype
push()
reduce()
reduceRight()
reverse()
shift()
slice()
some()
sort()
splice()
toString()
unshift()
valueOf()
JS Boolean
constructor
prototype
toString()
valueOf()
JS Classes
constructor()
extends
static
super
JS Date
constructor
getDate()
getDay()
getFullYear()
getHours()
getMilliseconds()
getMinutes()
getMonth()
getSeconds()
getTime()
getTimezoneOffset()
getUTCDate()
getUTCDay()
getUTCFullYear()
getUTCHours()
getUTCMilliseconds()
getUTCMinutes()
getUTCMonth()
getUTCSeconds()
now()
parse()
prototype
setDate()
setFullYear()
setHours()
setMilliseconds()
setMinutes()
setMonth()
setSeconds()
setTime()
setUTCDate()
setUTCFullYear()
setUTCHours()
setUTCMilliseconds()
setUTCMinutes()
setUTCMonth()
setUTCSeconds()
toDateString()
toISOString()
toJSON()
toLocaleDateString()
toLocaleTimeString()
toLocaleString()
toString()
toTimeString()
toUTCString()
UTC()
valueOf()
JS Error
name
message
JS Global
decodeURI()
decodeURIComponent()
encodeURI()
encodeURIComponent()
escape()
eval()
Infinity
isFinite()
isNaN()
NaN
Number()
parseFloat()
parseInt()
String()
undefined
unescape()
JS JSON
parse()
stringify()
JS Math
abs()
acos()
acosh()
asin()
asinh()
atan()
atan2()
atanh()
cbrt()
ceil()
clz32()
cos()
cosh()
E
exp()
expm1()
floor()
fround()
LN2
LN10
log()
log10()
log1p()
log2()
LOG2E
LOG10E
max()
min()
PI
pow()
random()
round()
sign()
sin()
sqrt()
SQRT1_2
SQRT2
tan()
tanh()
trunc()
JS Number
constructor
isFinite()
isInteger()
isNaN()
isSafeInteger()
MAX_VALUE
MIN_VALUE
NEGATIVE_INFINITY
NaN
POSITIVE_INFINITY
prototype
toExponential()
toFixed()
toLocaleString()
toPrecision()
toString()
valueOf()
JS OperatorsJS RegExp
constructor
compile()
exec()
g
global
i
ignoreCase
lastIndex
m
multiline
n+
n*
n?
n{X}
n{X,Y}
n{X,}
n$
^n
?=n
?!n
source
test()
toString()
(x|y)
.
\w
\W
\d
\D
\s
\S
\b
\B
\0
\n
\f
\r
\t
\v
\xxx
\xdd
\uxxxx
JS Statements
break
class
continue
debugger
do…while
for
for…in
for…of
function
if…else
return
switch
throw
try…catch
var
while
JS String
charAt()
charCodeAt()
concat()
constructor
endsWith()
fromCharCode()
includes()
indexOf()
lastIndexOf()
length
localeCompare()
match()
prototype
repeat()
replace()
search()
slice()
split()
startsWith()
substr()
substring()
toLocaleLowerCase()
toLocaleUpperCase()
toLowerCase()
toString()
toUpperCase()
trim()
valueOf()
2 Поиск подстрок
Вторая по популярности операция после сравнения строк — это поиск одной строки в другой. Для этого у класса String тоже есть немного методов:
| Методы | Описание |
|---|---|
| Ищет строку в текущей строке. Возвращает индекс первого символа встретившийся строки. | |
| Ищет строку в текущей строке, пропустив первых символов. Возвращает индекс найденного вхождения. | |
| Ищет строку в текущей строке с конца. Возвращает индекс первого вхождения. | |
| Ищет строку в текущей строке с конца, пропустив первых символов. | |
| Проверяет, что текущая строка совпадает с шаблоном, заданным регулярным выражением. |
Методы и часто используются в паре. Первый позволяет найти первое вхождение переданной подстроки в текущей строке. А второй метод позволяет найти второе, третье и т.д. вхождения за счет того, что пропускает первые index символов.
Допустим, у нас есть url типа такого: «https://domen.ru/about/reviews», и мы хотим заменить имя домена на javarush.ru. Домены в урлах могут быть разными, но мы знаем, что:
- Перед именем домена идут два слеша
- После имени домена идет одинарный слеш
Вот как бы выглядел код такой программы:
| Код | Примечания |
|---|---|
| Создание объекта Scanner Чтение строки с консоли Получаем индекс первого вхождения строки Получаем индекс первого вхождения строки , но ищем только после символов . Получаем строку от начала и заканчивая символами Получаем строку от и до конца. Склеиваем строки и новый домен. |
Методы и работают точно так же, только поиск ведется с конца строки к началу.
Методы строк
| Метод | Описание | Chrome | Firefox | Opera | Safari | IExplorer | Edge |
|---|---|---|---|---|---|---|---|
| charAt() | Возвращает символ по заданному индексу внутри строки. | Да | Да | Да | Да | Да | Да |
| charCodeAt() | Возвращает числовое значение символа по указанному индексу в стандарте кодирования символов Unicode (Юникод). | Да | Да | Да | Да | Да | Да |
| codePointAt() | Возвращает неотрицательное целое число, являющееся значением кодовой точки в стандарте кодирования символов Unicode (Юникод). | 41.0 | 29.0 | 28.0 | 10.0 | Нет | Да |
| concat() | Используется для объединения двух, или более строк в одну, при этом метод не изменяет существующие строки, а возвращает новую строку. | Да | Да | Да | Да | Да | Да |
| endsWith() | Определяет, совпадает ли конец данной строки с указанной строкой, или символом, возвращая при этом логическое значение. | 41.0 | 17.0 | 28.0 | 9.0 | Нет | Да |
| fromCharCode() | Преобразует значение или значения кодовых точек в стандарте кодирования символов UTF-16 (Юникод) в символы и возвращает строковое значение. | Да | Да | Да | Да | Да | Да |
| fromCodePoint() | Преобразует значение или значения кодовых точек в стандарте кодирования символов Юникод в символы и возвращает строковое значение. Позволяет работать со значениями выше 65535. | 41.0 | 29.0 | 28.0 | 10.0 | Нет | Да |
| includes() | Определяет, содержится ли одна строка внутри другой строки, возвращая при этом логическое значение. | 41.0 | 40.0* | 28.0 | 9.0 | Нет | Да |
| indexOf() | Возвращает позицию первого найденного вхождения указанного значения в строке. | Да | Да | Да | Да | Да | Да |
| lastIndexOf() | Возвращает позицию последнего найденного вхождения указанного значения в строке. | Да | Да | Да | Да | Да | Да |
| localeCompare() | Сравнивает две строки и определяет являются ли они эквивалентными в текущем языковом стандарте. | Да | Да | Да | Да | Да* | Да |
| match() | Производит поиск по заданной строке с использованием регулярного выражения (глобальный объект RegExp) и возвращает массив, содержащий результаты этого поиска. | Да | Да | Да | Да | Да | Да |
| normalize() | Возвращает форму нормализации в стандарте кодирования символов Unicode (Юникод) для указанной строки. | 34.0 | 31.0 | Да | 10.0 | Нет | Да |
| padEnd() | Позволяет дополнить текущую строку, начиная с её конца (справа) с помощью пробельного символа (по умолчанию), или заданной строкой, таким образом чтобы результирующая строка достигла заданной длины. | 57.0 | 48.0 | 44.0 | 10.0 | Нет | 15.0 |
| padStart() | Позволяет дополнить текущую строку, начиная с её начала (слева) с помощью пробельного символа (по умолчанию), или заданной строкой, таким образом чтобы результирующая строка достигла заданной длины. | 57.0 | 48.0 | 44.0 | 10.0 | Нет | 15.0 |
| raw() | Возвращает необработанную строковую форму строки шаблона. | 41.0 | 34.0 | 28.0 | 10.0 | Нет | Да |
| repeat() | Возвращает новый строковый объект, который содержит указанное количество соединённых вместе копий строки на которой был вызван метод. | 41.0 | 24.0 | 28.0 | 9.0 | Нет | Да |
| replace() | Выполняет внутри строки поиск с использованием регулярного выражения (объект RegExp), или строкового значения и возвращает новую строку, в которой будут заменены найденные значения. | Да | Да | Да | Да | Да | Да |
| search() | Выполняет поиск первого соответствия (сопоставления) регулярному выражению (объект RegExp) внутри строки. | Да | Да | Да | Да | Да | Да |
| slice() | Позволяет возвратить новую строку, которая содержит копии символов, вырезанных из исходной строки. | Да | Да | Да | Да | Да | Да |
| split() | Позволяет разбить строки на массив подстрок, используя заданную строку разделитель для определения места разбиения. | Да | Да | Да | Да | Да | Да |
| startsWith() | Определяет, совпадает ли начало данной строки с указанной строкой, или символом, возвращая при этом логическое значение. | 41.0 | 17.0 | 28.0 | 9.0 | Нет | Да |
| substr() | Позволяет извлечь из строки определенное количество символов, начиная с заданного индекса. | Да | Да | Да | Да | Да | Да |
| substring() | Позволяет извлечь символы из строки (подстроку) между двумя заданными индексами, или от определенного индекса до конца строки. | Да | Да | Да | Да | Да | Да |
| toLocaleLowerCase() | Преобразует строку в строчные буквы (нижний регистр) с учетом текущего языкового стандарта. | Да | Да | Да | Да | Да | Да |
| toLocaleUpperCase() | Преобразует строку в заглавные буквы (верхний регистр) с учетом текущего языкового стандарта. | Да | Да | Да | Да | Да | Да |
| toLowerCase() | Преобразует строку в строчные буквы (нижний регистр). | Да | Да | Да | Да | Да | Да |
| toString() | Возвращает значение строкового объекта. | Да | Да | Да | Да | Да | Да |
| toUpperCase() | Преобразует строку в заглавные буквы (верхний регистр). | Да | Да | Да | Да | Да | Да |
| trim() | Позволяет удалить пробелы с обоих концов строки. | Да | Да | Да | Да | 9.0 | Да |
| valueOf() | Возвращает примитивное значение строкового объекта в виде строкового типа данных. | Да | Да | Да | Да | Да | Да |
Array.isArray
Массивы не
образуют отдельный тип языка. Они основаны на объектах. Поэтому typeof не может
отличить простой объект от массива:
console.log(typeof {}); // object
console.log (typeof ); // тоже object
Но массивы
используются настолько часто, что для этого придумали специальный метод: Array.isArray(value). Он возвращает
true, если value массив, и false, если нет.
console.log(Array.isArray({})); // false
console.log(Array.isArray()); // true
Подведем итоги
по рассмотренным методам массивов. У нас получился следующий список:
|
Для |
|
|
push(…items) |
добавляет элементы в конец |
|
pop() |
извлекает элемент с конца |
|
shift() |
извлекает элемент с начала |
|
unshift(…items) |
добавляет элементы в начало |
|
splice(pos, deleteCount, …items) |
начиная с индекса pos, удаляет |
|
slice(start, end) |
создаёт новый массив, копируя в него |
|
concat(…items) |
возвращает новый массив: копирует все |
|
Для поиска |
|
|
indexOf/lastIndexOf(item, pos) |
ищет item, начиная с позиции pos, и |
|
includes(value) |
возвращает true, если в массиве |
|
find/filter(func) |
фильтрует элементы через функцию и |
|
findIndex(func) |
похож на find, но возвращает индекс |
|
Для перебора |
|
|
forEach(func) |
вызывает func для каждого элемента. |
|
Для |
|
|
map(func) |
создаёт новый массив из результатов |
|
sort(func) |
сортирует массив «на месте», а потом |
|
reverse() |
«на месте» меняет порядок следования |
|
split/join |
преобразует строку в массив и обратно |
|
reduce(func, initial) |
вычисляет одно значение на основе |
Видео по теме
JavaScipt #1: что это такое, с чего начать, как внедрять и запускать
JavaScipt #2: способы объявления переменных и констант в стандарте ES6+
JavaScript #3: примитивные типы number, string, Infinity, NaN, boolean, null, undefined, Symbol
JavaScript #4: приведение типов, оператор присваивания, функции alert, prompt, confirm
JavaScript #5: арифметические операции: +, -, *, /, **, %, ++, —
JavaScript #6: условные операторы if и switch, сравнение строк, строгое сравнение
JavaScript #7: операторы циклов for, while, do while, операторы break и continue
JavaScript #8: объявление функций по Function Declaration, аргументы по умолчанию
JavaScript #9: функции по Function Expression, анонимные функции, callback-функции
JavaScript #10: анонимные и стрелочные функции, функциональное выражение
JavaScript #11: объекты, цикл for in
JavaScript #12: методы объектов, ключевое слово this
JavaScript #13: клонирование объектов, функции конструкторы
JavaScript #14: массивы (array), методы push, pop, shift, unshift, многомерные массивы
JavaScript #15: методы массивов: splice, slice, indexOf, find, filter, forEach, sort, split, join
JavaScript #16: числовые методы toString, floor, ceil, round, random, parseInt и другие
JavaScript #17: методы строк — length, toLowerCase, indexOf, includes, startsWith, slice, substring
JavaScript #18: коллекции Map и Set
JavaScript #19: деструктурирующее присваивание
JavaScript #20: рекурсивные функции, остаточные аргументы, оператор расширения
JavaScript #21: замыкания, лексическое окружение, вложенные функции
JavaScript #22: свойства name, length и методы call, apply, bind функций
JavaScript #23: создание функций (new Function), функции setTimeout, setInterval и clearInterval
Поиск подстроки или символа в строке в Java
В класс включена поддержка поиска определенного символа или подстроки, для этого в нем имеются два метода — и .
— ищет первое вхождение символа или подстроки.
— ищет последнее вхождение символа или подстроки.
Каждый из этих методов возвращает индекс того символа, который вы хотели найти, либо индекс начала искомой подстроки. В любом случае, если поиск оказался неудачным, методы возвращают значение -1.
Чтобы найти первое или последнее вхождение символа, применяйте:
Здесь символ, который нужно искать. Чтобы найти первое или последнее вхождение подстроки, применяйте:
Вы можете указать начальную позицию для поиска, воспользовавшись следующими формами:
Рассмотрим применение этих методов на следующем примере:
Содержит ли строка текст?Does a string contain text?
Методы String.Contains, String.StartsWith и String.EndsWith выполняют поиск определенного текста в строке.The String.Contains, String.StartsWith, and String.EndsWith methods search a string for specific text. В следующем примере показано использование каждого из этих методов, а также сценарии поиска без учета регистра:The following example shows each of these methods and a variation that uses a case-insensitive search:
В предыдущем примере показано важное правило использования этих методов.The preceding example demonstrates an important point for using these methods. По умолчанию поиск выполняется с учетом регистра.Searches are case-sensitive by default
Чтобы выполнить поиск без учета регистра, используйте значение перечисления .You use the enumeration value to specify a case-insensitive search.
Эффективные варианты обработки данных
Синтаксис и семантика JavaScript, особенно в отношении объектно-ориентированного программирования, заслуживают уважения, однако это не мешает разработчику формулировать свои алгоритмы согласно его «собственной семантике».
Любая задача несет в себе уникальный смысл, который можно уложить в предлагаемые языком структуры данных и конструкции их обработки. Но гораздо проще строить объекты решаемой задачи, и в их терминах формулировать её решение.
Это не только более эффективный результат, но и более понимаемый алгоритм, меньшее количество ошибок в коде и хорошая модифицируемость результата впоследствии: не будет необходимости вспоминать: что было сделано и зачем.

В программировании очень важен понятный и читаемый код, особенно, когда предстоит его дальнейшее развитие через некоторое время.
В этом контексте программист может представить данные в обычных строках, строки разместить в объектах, а смысловую нагрузку разместить по методам, которые через indexOf будут выбирать нужные элементы в нужное время.
Сравнение строк
Для простого сравнения
строк используются методы equals() (с учетом регистра) и equalsIgnoreCase()
(без учета регистра). Оба метода в качестве параметра принимают строку, с
которой сравниваются:
String str1 = "Hello"; String str2 = "hello"; System.out.println(str1.equals(str2)); // false System.out.println(str1.equalsIgnoreCase(str2)); // true
Обратите
внимание, что в отличие сравнения числовых и других данных примитивных типов
для сравнения строк не рекомендуется использовать оператор ==. То есть,
записывать вот такое сравнение лучше не использовать:
if(str1 == str2) System.out.println("Сроки равны");
(хотя, оно тоже
будет работать). Вместо этого следует использовать метод equals() класса String.
Другая пара методов:
int compareTo(String str) и int compareToIgnoreCase(String str)
также сравнивают
строки между собой, но в отличие от equals() они еще
позволяют узнать больше ли одна строка другой или нет. Если возвращаемое
значение этих методов больше 0, то первая строка больше второй, если меньше
нуля, то, наоборот, вторая больше первой. Если строки равны, то возвращается 0.
Для определения
больше или меньше одна строка, чем другая, используется лексикографический
порядок. То есть, например, строка «A» меньше, чем строка
«B», так как символ ‘A’ в алфавите стоит перед символом ‘B’. Если
первые символы строк равны, то в расчет берутся следующие символы. Например:
String str1 = "hello"; String str2 = "world"; String str3 = "hell"; System.out.println(str1.compareTo(str2)); // -15 - str1 меньше чем str2 System.out.println(str1.compareTo(str3)); // 1 - str1 больше чем str3 System.out.println(str1.compareTo(str1)); // 0 - str1 равна str1
Еще один
специальный метод
regionMatches()
сравнивает
отдельные подстроки в пределах двух строк. Он имеет такие реализации:
boolean
regionMatches(int toffset, String other, int oofset, int len)
boolean
regionMatches(boolean ignoreCase, int toffset, String other, int oofset, int
len)
-
ignoreCase:
надо ли игнорировать регистр символов при сравнении (если значение true, то регистр
игнорируется); -
toffset:
начальный индекс в вызывающей строке, с которого начнется сравнение; -
other:
строка, с которой сравнивается вызывающая; -
oofset: начальный
индекс в сравниваемой строке, с которого начнется сравнение; -
len: количество
сравниваемых символов в обеих строках.
Например, ниже в
строке str1 сравнивается
подстрока wor с подстрокой wor строки str2:
String str1 = "Hello world"; String str2 = "I work"; boolean result = str1.regionMatches(6, str2, 2, 3); System.out.println(result); // true
Строки и класс System.String
Последнее обновление: 31.10.2015
Довольно большое количество задач, которые могут встретиться при разработке приложений, так или
иначе связано с обработкой строк — парсинг веб-страниц, поиск в тексте, какие-то аналитические задачи, связанные с извлечением нужной информации
из текста и т.д
Поэтому в этом плане работе со строками уделяется особое внимание
В языке C# строковые значения представляет тип string, а вся функциональность работы с данным типом сосредоточена в классе
System.String. Собственно является псевдонимом для класса System.String. Объекты этого класса представляют текст как последовательность символов Unicode. Максимальный размер объекта String может составлять в памяти 2 ГБ, или около 1 миллиарда символов.
Создание строк
Создавать строки можно, как используя переменную типа string и присваивая ей значение, так и применяя один из конструкторов класса String:
string s1 = "hello";
string s2 = null;
string s3 = new String('a', 6); // результатом будет строка "aaaaaa"
string s4 = new String(new char[]{'w', 'o', 'r', 'l', 'd'});
Конструктор String имеет различное число версий. Так, вызов конструктора создаст строку «aaaaaa».
И так как строка представляет ссылочный тип, то может хранить значение null.
Строка как набор символов
Так как строка хранит коллекцию символов, в ней определен индексатор для доступа к этим символам:
public char this {get;}
Применяя индексатор, мы можем обратиться к строке как к массиву символов и получить по индексу любой из ее символов:
string s1 = "hello"; char ch1 = s1; // символ 'e' Console.WriteLine(ch1); Console.WriteLine(s1.Length);
Используя свойство , как и в обычном массиве, можно получить длину строки.
Основные методы строк
Основная функциональность класса String раскрывается через его методы, среди которых можно выделить следующие:
-
Compare: сравнивает две строки с учетом текущей культуры (локали) пользователя
-
CompareOrdinal: сравнивает две строки без учета локали
-
Contains: определяет, содержится ли подстрока в строке
-
Concat: соединяет строки
-
CopyTo: копирует часть строки, начиная с определенного индекса в массив
-
EndsWith: определяет, совпадает ли конец строки с подстрокой
-
Format: форматирует строку
-
IndexOf: находит индекс первого вхождения символа или подстроки в строке
-
Insert: вставляет в строку подстроку
-
Join: соединяет элементы массива строк
-
LastIndexOf: находит индекс последнего вхождения символа или подстроки в строке
-
Replace: замещает в строке символ или подстроку другим символом или подстрокой
-
Split: разделяет одну строку на массив строк
-
Substring: извлекает из строки подстроку, начиная с указанной позиции
-
ToLower: переводит все символы строки в нижний регистр
-
ToUpper: переводит все символы строки в верхний регистр
-
Trim: удаляет начальные и конечные пробелы из строки
Разберем работу этих методов.
НазадВперед
Где искомый текст находится в строке?Where does the sought text occur in a string?
Методы IndexOf и LastIndexOf также ищут текст в строках.The IndexOf and LastIndexOf methods also search for text in strings. Эти методы возвращают расположение текста, поиск которого выполняется.These methods return the location of the text being sought. Если текст не найден, возвращается .If the text isn’t found, they return . В следующем примере происходит поиск первого и последнего вхождения слова «methods» и отображение текста, находящегося между ними.The following example shows a search for the first and last occurrence of the word «methods» and displays the text in between.
Нюансы сравнения строк
Если мы
проверяем строки на равенство, то никаких особых проблем в JavaScript это не
вызывает, например:
if("abc" == "abc") console.log( "строки равны" );
if("abc" != "ABC") console.log( "строки не равны" );
Но, когда мы
используем знаки больше/меньше, то строки сравниваются в лексикографическом
порядке. То есть:
1. Если код
текущего символа одной строки больше кода текущего символа другой строки, то
первая строка больше второй (остальные символы не имеют значения), например:
console.log( "z" > "Za" ); //true
2. Если код
текущего символа одной строки меньше кода текущего символа другой строки, то
первая строка меньше второй:
console.log( "B" < "a" ); //true
3. При равенстве
символов больше та строка, которая содержит больше символов:
console.log( "abc" < "abcd" ); //true
4. В остальных
случаях строки равны:
console.log( "abc" == "abc" ); //true
Но в этом
алгоритме есть один нюанс. Например, вот такое сравнение:
console.log( "Америка" > "Japan" ); //true
Дает значение true, так как
русская буква A имеет больший
код, чем латинская буква J. В этом легко убедиться,
воспользовавшись методом
str.codePointAt(pos)
который
возвращает код символа, стоящего в позиции pos:
console.log( "А".codePointAt(), "J".codePointAt() );
Сморите, у буквы
А код равен 1040, а у буквы J – 74. Напомню,
что строки в JavaScript хранятся в
кодировке UTF-16. К чему
может привести такой результат сравнения? Например, при сортировке мы получим
на первом месте страну «Japan», а потом «Америка». Возможно, это не
то, что нам бы хотелось? И здесь на помощь приходит специальный метод для
корректного сравнения таких строк:
str.localeCompare(compareStr)
он возвращает
отрицательное число, если str < compareStr, положительное
при str > compareStr и 0 если строки
равны. Например:
console.log( "Америка".localeCompare("Japan") ); // -1
возвращает -1
как и должно быть с учетом языкового сравнения. У этого метода есть два
дополнительных аргумента, которые указаны в документации JavaScript. Первый
позволяет указать язык (по умолчанию берётся из окружения) — от него зависит
порядок букв. Второй позволяет определять дополнительные правила, например, чувствительность
к регистру.
Извлечение символов и подстрок
Для извлечения
символов по индексу в классе String определен метод
char charAt(int
index)
Он принимает
индекс, по которому надо получить символов, и возвращает извлеченный символ:
String str = "Java"; char c = str.charAt(2); System.out.println(c); // v
(здесь как и в
массивах первый индекс равен 0).
Если надо
извлечь сразу группу символов или подстроку, то можно использовать метод
getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)
Он принимает
следующие параметры:
-
srcBegin:
индекс строки, с которого начинается извлечение символов; -
srcEnd:
индекс строки, до которого идет извлечение символов; -
dst:
массив символов, в который будут извлекаться символы; -
dstBegin:
индекс массива dst, с которого надо добавлять извлеченные из строки символы.
String str = "Hello world!"; int start = 6; int end = 11; char dst=new charend - start; str.getChars(start, end, dst, ); System.out.println(dst); // world