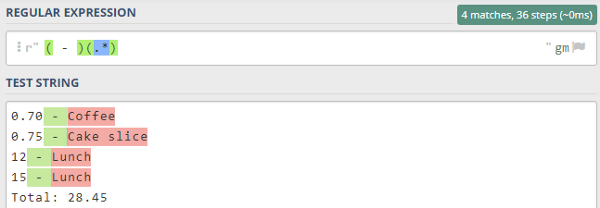
Regexp
Содержание:
- Metacharacters
- Квантификаторы — * + ? и {}
- Количество {n}
- Замена с помощью регулярных выражений¶
- Найти все / Заменить все
- Metacharacters
- Методы Javascript для работы с регулярными выражениями
- Точка и перенос строки
- Символьные классы
- Составление регулярных выражений
- Конструктор или литерал?
- Как использовать регулярные выражения с методами объекта RegExp?
- Как исправить?
- Жадность
- Скобочные группы ― ()
- Опережающая проверка
- Упрощённый пример
- Литерал регулярных выражений
- Область применения регулярных выражений
- Quantifiers
- Пример
- Ретроспективная проверка
- Объект RegExp
- Строковые методы, поиск и замена
Metacharacters
Metacharacters are characters with a special meaning:
| Metacharacter | Description |
|---|---|
| . | Find a single character, except newline or line terminator |
| \w | Find a word character |
| \W | Find a non-word character |
| \d | Find a digit |
| \D | Find a non-digit character |
| \s | Find a whitespace character |
| \S | Find a non-whitespace character |
| \b | Find a match at the beginning/end of a word, beginning like this: \bHI, end like this: HI\b |
| \B | Find a match, but not at the beginning/end of a word |
| \0 | Find a NULL character |
| \n | Find a new line character |
| \f | Find a form feed character |
| \r | Find a carriage return character |
| \t | Find a tab character |
| \v | Find a vertical tab character |
| \xxx | Find the character specified by an octal number xxx |
| \xdd | Find the character specified by a hexadecimal number dd |
| \udddd | Find the Unicode character specified by a hexadecimal number dddd |
Квантификаторы — * + ? и {}
abc* соответствует строке, в которой после ab следует 0 или более символов c -> тестabc+ соответствует строке, в которой после ab следует один или более символов cabc? соответствует строке, в которой после ab следует 0 или один символ cabc{2} соответствует строке, в которой после ab следует 2 символа cabc{2,} соответствует строке, в которой после ab следует 2 или более символов cabc{2,5} соответствует строке, в которой после ab следует от 2 до 5 символов ca(bc)* соответствует строке, в которой после ab следует 0 или более последовательностей символов bca(bc){2,5} соответствует строке, в которой после ab следует от 2 до 5 последовательностей символов bc
Количество {n}
Самый простой квантификатор — это число в фигурных скобках: .
Он добавляется к символу (или символьному классу, или набору и т.д.) и указывает, сколько их нам нужно.
Можно по-разному указать количество, например:
- Точное количество:
-
Шаблон обозначает ровно 5 цифр, он эквивалентен .
Следующий пример находит пятизначное число:
Мы можем добавить , чтобы исключить числа длиннее: .
- Диапазон: , от 3 до 5
-
Для того, чтобы найти числа от 3 до 5 цифр, мы можем указать границы в фигурных скобках:
Верхнюю границу можно не указывать.
Тогда шаблон найдёт последовательность чисел длиной и более цифр:
Давайте вернёмся к строке .
Число – это последовательность из одной или более цифр. Поэтому шаблон будет :
Замена с помощью регулярных выражений¶
Мы уже видели как нужно проверять строки на совпадение с шаблоном.
Также мы видели как можно извлекать часть строк соотвествующие шаблону в массив.
Теперь давайте рассмотрим как заменять части строки на основе шаблона.
У объекта в JavaScript есть метод , который можно использовать без регулярных выражений для одной замены в строке:
Этот метод также может принимать и регулярное выражение в качестве аргумента:
Использование флага — это единственный способ заменить несколько вхождений в строке на ванильном JavaScript:
Группы позволяют нам делать больше причудливых вещей, менять местами части строк:
Вместо строки можно использовать функцию, чтобы делать ещё более интересные вещи. В неё будет передан ряд аргументов, таких как возвращают методы или , где количество аргументов зависит от количества групп:
Найти все / Заменить все
Эти две задачи решаются в javascript принципиально по-разному.
Начнем с «простого».
Для замены всех вхождений используется метод String#replace.
Он интересен тем, что допускает первый аргумент — регэксп или строку.
Если первый аргумент — строка, то будет осуществлен поиск подстроки, без преобразования в регулярное выражение.
Попробуйте:
alert("2 ++ 1".replace("+", "*"))
Каков результат? Как, заменился только один плюс, а не два? Да, вот так.
В режиме регулярного выражения плюс придется заэкранировать, но зато заменит все вхождения (при указании флага ):
alert("2 ++ 1".replace(/\+/g, "*"))
Вот такая особенность работы со строкой.
Очень полезной особенностью является возможность работать с функцией вместо строки замены. Такая функция получает первым аргументом — все совпадение, а последующими аргументами — скобочные группы.
Следующий пример произведет операции вычитания:
var str = "count 36 - 26, 18 - 9"
str = str.replace(/(\d+) - (\d+)/g, function(a,b,c) { return b-c })
alert(str)
В javascript нет одного универсального метода для поиска всех совпадений.
Для поиска без запоминания скобочных групп — можно использовать String#match:
var str = "count 36-26, 18-9" var re = /(\d+)-(\d+)/g result = str.match(re) for(var i=0; i<result.length; i++) alert(result)
Как видите, оно исправно ищет все совпадения (флаг у регулярного выражения обязателен), но при этом не запоминает скобочные группы. Эдакий «облегченный вариант».
В сколько-нибудь сложных задачах важны не только совпадения, но и скобочные группы. Чтобы их найти, предлагается использовать многократный вызов RegExp#exec.
Для этого регулярное выражение должно использовать флаг . Тогда результат поиска, запомненный в свойстве объекта используется как точка отсчета для следующего поиска:
var str = "count 36-26, 18-9"
var re = /(\d+)-(\d+)/g
var res
while ( (res = re.exec(str)) != null) {
alert("Найдено " + res + ": ("+ res+") и ("+res+")")
alert("Дальше ищу с позиции "+re.lastIndex)
}
Проверка нужна т.к. значение является хорошим и означает, что вхождение найдено в самом начале строки (поиск успешен). Поэтому необходимо сравнивать именно с .
Metacharacters
Metacharacters are characters with a special meaning:
| Metacharacter | Description |
|---|---|
| . | Find a single character, except newline or line terminator |
| \w | Find a word character |
| \W | Find a non-word character |
| \d | Find a digit |
| \D | Find a non-digit character |
| \s | Find a whitespace character |
| \S | Find a non-whitespace character |
| \b | Find a match at the beginning/end of a word, beginning like this: \bHI, end like this: HI\b |
| \B | Find a match, but not at the beginning/end of a word |
| \0 | Find a NULL character |
| \n | Find a new line character |
| \f | Find a form feed character |
| \r | Find a carriage return character |
| \t | Find a tab character |
| \v | Find a vertical tab character |
| \xxx | Find the character specified by an octal number xxx |
| \xdd | Find the character specified by a hexadecimal number dd |
| \udddd | Find the Unicode character specified by a hexadecimal number dddd |
Методы Javascript для работы с регулярными выражениями
В Javascript Существует 6 методов для работы с регулярными выражениями. Чаще всего мы будем использовать только половину из них.
Метод exec()
Метод RegExp, который выполняет поиск совпадения в строке. Он возвращает массив данных. Например:
var str = 'Some fruit: Banana - 5 pieces. For 15 monkeys.'; var re = /(\w+) - (\d) pieces/ig; var result = re.exec(str); window.console.log(result); // result = // Так же мы можем посмотреть позицию совпадения - result.index
В результате мы получим массив, первым элементом которого будет вся совпавшая по паттерну строка, а дальше содержимое скобочных групп. Если совпадений с паттерном нету, то .
Метод test()
Метод RegExp, который проверяет совпадение в строке, возвращает либо true, либо false. Очень удобен, когда нам необходимо проверить наличие или отсутствие паттерна в тексте. Например:
var str = 'Balance: 145335 satoshi'; var re = /Balance:/ig; var result = re.test(str); window.console.log(result); // true
В данном примере, есть совпадение с паттерном, поэтому получаем true.
Метод search()
Метод String, который тестирует на совпадение в строке. Он возвращет индекс совпадения, или -1 если совпадений не будет найдено. Очень похож на метод indexOf() для работы со строками. Минус этого метода — он ищет только первое совпадение. Для поиска всех совпадений используйте метод match().
var str = "Умея автоматизировать процессы, можно зарабатывать миллионы"; window.console.log(str.search(/можно/igm)); // 60 window.console.log(str.search(/атата/igm)); // -1
Метод match()
Метод String, который выполняет поиск совпадения в строке. Он возвращет массив данных либо null если совпадения отсутствуют.
// Без использования скобочных групп
var str = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz';
var regexp = //gi;
var matches_array = str.match(regexp);
window.console.log(matches_array); //
// С использованием скобочных групп без флага g
var str = 'Fruits quantity: Apple - 5, Banana - 7, Orange - 12. I like fruits.';
var found = str.match(/(\d{1,2})/i);
window.console.log(found); // Находит первое совпадение и возвращает объект
// {
// 0: "5"
// 1: "5"
// index: 25
// input: "Fruits quantity: Apple -...ge - 12. I like fruits."
// }
// С использованием скобочных групп с флагом g
var found = str.match(/(\d{1,2})/igm);
window.console.log(found); //
Если совпадений нету — возвращает null.
Метод replace()
Метод String, который выполняет поиск совпадения в строке, и заменяет совпавшую подстроку другой подстрокой переданной как аргумент в этот метод. Мы уже использовали эту функцию для работы о строками, регулярные выражения привносят новые возможности.
// Обычная замена var str = 'iMacros is awesome, and iMacros is give me profit!'; var newstr = str.replace(/iMacros/gi, 'Javascript'); window.console.log(newstr); // Javascript is awesome, and Javascript is give me profit! // Замена, используя параметры. Меняем слова местами: var re = /(\w+)\s(\w+)/; var str = 'iMacros JS'; var newstr = str.replace(re, '$2, $1'); // в переменных $1 и $2 находятся значения из скобочных групп window.console.log(newstr); // JS iMacros
У метода replace() есть очень важная особенность — он имеет свой каллбэк. То есть, в качестве аргумента мы можем подавать функцию, которая будет обрабатывать каждое найденное совпадение.
Нестандартное применение метода replace():
var str = `
I have some fruits:
Orange - 5 pieces
Banana - 7 pieces
Apple - 15 pieces
It's all.
`;
var arr = []; // Сюда складируем данные о фруктах и их количестве
var newString = str.replace(/(\w+) - (\d) pieces/igm, function (match, p1, p2, offset, string) {
window.console.log(arguments);
arr.push({
name: p1,
quantity: p2
});
return match;
});
window.console.log(newString); // Текст не изменился, как и было задумано
window.console.log(arr); // Мы получили удобный массив объектов, с которым легко и приятно работать
Как вы видите, мы использовали этот метод для обработки каждого совпадения. Мы вытащили из паттерна название фрукта и количество и поместили эти значения в массив объектов, как мы уже делали ранее
Обратите внимание на аргумент функции offset — это будет индекс начала совпадения, этот параметр нам потом пригодится. В нашем случае, мы имеем 2 скобочные группы в паттерне, поэтому у нас в функции 5 аргументов, но их там может быть и больше
Метод split()
Метод String, который использует регулярное выражение или фиксированую строку чтобы разбить строку на массив подстрок.
var str = "08-11-2016";
// Разбиваем строку по разделителю
window.console.log(str.split('-')); //
// Такой же пример с регэкспом
window.console.log(str.split(/-/)); //
Точка и перенос строки
Для поиска в многострочном режиме почти все модификации перловых регэкспов используют специальный multiline-флаг.
И javascript здесь не исключение.
Попробуем же сделать поиск и замену многострочного вхождения. Скажем, будем заменять на тэг подчеркивания: :
function bbtagit(text) {
text = text.replace(/\(.*?)\[\/u\]/gim, '<u>$1</u>')
return text
}
var line = "мой\n текст"
alert( bbtagit(line) )
Попробуйте запустить. Заменяет? Как бы не так!
Дело в том, что в javascript мультилайн режим (флаг ) влияет только на символы ^ и $, которые начинают матчиться с началом и концом строки, а не всего текста.
Точка по-прежнему — любой символ, кроме новой строки. В javascript нет флага, который устанавливает мультилайн-режим для точки. Для того, чтобы заматчить совсем что угодно — используйте .
Работающий вариант:
function bbtagit(text) {
text = text.replace(/\(*)\[\/u\]/gim, '<u>$1</u>')
return text
}
var line = "мой\n текст"
alert( bbtagit(line) )
Символьные классы
Символьные классы — это своеобразные сокращения для разных типов символов. К примеру, есть свои классы для букв, цифр, пробелов и т. д.
/* Символьный класс - Значение */. - любой символ, кроме первой строки\d - одноразрядное число (то же, что и )\w - отдельный буквенно-числовой словообразующий символ из латинского алфавита, включая подчёркивание (то же, что и )\D - отдельный нечисловой символ (то же, что и)\W - отдельный несловообразующий символ из латинского алфавита (то же, что и )\S - отдельный символ, который не является разделителем (то же, что и ).
Примеры:
// . - любой символ, кроме первой строкиconst myPattern = /./console.log(myPattern.test(''))// falseconsole.log(myPattern.test('word'))// trueconsole.log(myPattern.test('9'))// true// \d - одноразрядное числоconst myPattern = /\d/console.log(myPattern.test('3'))// trueconsole.log(myPattern.test('word'))// false// \w - отдельный буквенно-числовой словообразующий символconst myPattern = /\w/console.log(myPattern.test(''))// falseconsole.log(myPattern.test('word'))// trueconsole.log(myPattern.test('9'))// true// \s - отдельный символ разделителяconst myPattern = /\s/console.log(myPattern.test(''))// falseconsole.log(myPattern.test(' '))// trueconsole.log(myPattern.test('foo'))// false// \D - отдельный нечисловой символconst myPattern = /\D/console.log(myPattern.test('Worm'))// trueconsole.log(myPattern.test('1'))// false// \W - отдельный несловообразующий символconst myPattern = /\W/console.log(myPattern.test('Worm'))// falseconsole.log(myPattern.test('1'))// falseconsole.log(myPattern.test('*'))// trueconsole.log(myPattern.test(' '))// true// \S - отдельный символ, который не является разделителемconst myPattern = /\S/console.log(myPattern.test('clap'))// trueconsole.log(myPattern.test(''))// falseconsole.log(myPattern.test('-'))// true
Составление регулярных выражений
Для поиска символов определенного вида в регулярных выражениях есть «классы символов». Например ищет одну цифру. Есть и другие классы.
Основные классы
- – цифры.
- – не-цифры.
- – пробельные символы, переводы строки.
- – всё, кроме \s.
- – латиница, цифры, подчёркивание ‘_’.
- – всё, кроме \w.
- – символ табуляции
- – символ перевода строки
- – точка обозначает любой символ, кроме перевода строки.
Помимо классов, есть наборы символов, причем помимо стандартных, можно самому создавать набор символов, используя .
Наборы символов
- – произвольный символ от a до z
- произвольный символ от B до G в верхнем регистре
- – то же самое, что и \d, любая цифра от 0 до 9
- – любая цифра или буква, можно комбинировать диапазоны
- – диапазон «кроме», ищет любые символы, кроме цифр
Обратите внимание, в квадратных скобках, большинство специальных символов можно использовать без экранирования
Не экранируем в квадратных скобках
- Точка .
- Плюс .
- Круглые скобки .
- Дефис , если он находится в начале или конце квадратных скобок, то есть не выделяет диапазон.
- Символ каретки , если не находится в начале квадратных скобок.
- А также открывающая квадратная скобка .
Квантификаторы +, *, ? и {n}
- Количество {n} — 5 цифр — одна или больше цифр — от одной до 5 цифр
- Один или более +, аналог {1,} — одна или более цифр — одна или более букв от a до z
- Ноль или один ?, аналог {0,1} — найдет color и colour
- Означает «ноль или более» *, аналог {0,} — найдет «1» и «100» в строке «1 100», символ может повторяться много раз или вообще отсутствовать.
Скобочные группы
Вы можете заключить одну или несколько частей шаблона в скобки — это и будет называться скобочной группой. Основной профит — при использовании методов match, exec, replace — можно вытащить значения в скобках в отдельный элемент массива. И еще, если поставить квантификатор после скобки, то он применится ко всей скобке, а не к одному символу. Еще вы можете использовать вложенные скобки, то есть разбивать большой шаблон на несколько маленьких.
Пример использования вы можете посмотреть выше — в нестандартном применении метода replace().
Простым языком, это «ИЛИ».
— аналог \d -любая цифра — найдет «imacros» или «js»
Начало строки ^ и конец $
Знак каретки ‘^’ и доллара ‘$’ имеют в регулярном выражении особый смысл. Их называют «якорями» (anchor – англ.).
Каретка совпадает в начале текста, а доллар – в конце. Знак доллара $ используют, чтобы указать, что паттерн должен заканчиваться в конце текста, знак каретки ^ — что паттерн должен начинаться с первого символа строки.
Конструктор или литерал?
Конструктор и литерал выполняют одну функцию, но есть одно важное различие. Регулярное выражение, созданное при помощи конструктора, компилируется при выполнении программы, литерал — на этапе загрузки скрипта
Это значит, что литерал нельзя изменить динамически, в то время как конструктор — можно.
Таким образом, если вам нужно (или может понадобиться) изменить шаблон на лету, создавайте регулярное выражение с помощью конструктора. Также конструктор будет лучшим решением, если шаблон нужно создавать динамически. С другой стороны, если вам не понадобится менять или создавать шаблон, вы можете воспользоваться литералом.
Как использовать регулярные выражения с методами объекта RegExp?
Прежде чем приступить к созданию шаблонов, давайте кратко рассмотрим, как они используются. С помощью описанных ниже методов мы сможем в дальнейшем применять разные способы создания шаблонов.
Как исправить?
Есть два основных подхода, как это исправить.
Первый – уменьшить количество возможных комбинаций.
Перепишем регулярное выражение так: – то есть, будем искать любое количество слов с пробелом , после которых идёт (но не обязательно) обычное слово .
Это регулярное выражение эквивалентно предыдущему (ищет то же самое), и на этот раз всё работает:
Почему же проблема исчезла?
Теперь звёздочка стоит после вместо . Стало невозможно разбить одно слово на несколько разных . Исчезли и потери времени на перебор таких комбинаций.
Например, с предыдущим шаблоном слово могло быть представлено как два подряд :
Предыдущий шаблон из-за необязательности допускал варианты , , и т.п.
С переписанным шаблоном , такое невозможно: может быть или , но не . Так что общее количество комбинаций сильно уменьшается.
Жадность
Это не совсем особенность, скорее фича, но все же достойная отдельного абзаца.
Все регулярные выражения в javascript — жадные. То есть, выражение старается отхватить как можно больший кусок строки.
Например, мы хотим заменить все открывающие тэги
На что и почему — не так важно
text = '1 <A href="#">...</A> 2' text = text.replace(/<A(.*)>/, 'TEST') alert(text)
При запуске вы увидите, что заменяется не открывающий тэг, а вся ссылка, выражение матчит ее от начала и до конца.
Это происходит из-за того, что точка-звездочка в «жадном» режиме пытается захватить как можно больше, в нашем случае — это как раз до последнего .
Последний символ точка-звездочка не захватывает, т.к. иначе не будет совпадения.
Как вариант решения используют квадратные скобки: :
text = '1 <A href="#">...</A> 2' text = text.replace(/<A(*)>/, 'TEST') alert(text)
Это работает. Но самым удобным вариантом является переключение точки-звездочки в нежадный режим. Это осуществляется простым добавлением знака «» после звездочки.
В нежадном режиме точка-звездочка пустит поиск дальше сразу, как только нашла совпадение:
text = '1 <A href="#">...</A> 2' text = text.replace(/<A(.*?)>/, 'TEST') alert(text)
В некоторых языках программирования можно переключить жадность на уровне всего регулярного выражения, флагом.
В javascript это сделать нельзя.. Вот такая особенность. А вопросительный знак после звездочки рулит — честное слово.
Скобочные группы ― ()
a(bc) создаём группу со значением bc -> тестa(?:bc)* оперетор ?: отключает группу -> тестa(?<foo>bc) так, мы можем присвоить имя группе -> тест
Этот оператор очень полезен, когда нужно извлечь информацию из строк или данных, используя ваш любимый язык программирования. Любые множественные совпадения, по нескольким группам, будут представлены в виде классического массива: доступ к их значениям можно получить с помощью индекса из результатов сопоставления.
Если присвоить группам имена (используя ), то можно получить их значения, используя результат сопоставления, как словарь, где ключами будут имена каждой группы.
Опережающая проверка
Синтаксис опережающей проверки: .
Он означает: найди при условии, что за ним следует . Вместо и здесь может быть любой шаблон.
Для целого числа, за которым идёт знак , шаблон регулярного выражения будет :
Обратим внимание, что проверка – это именно проверка, содержимое скобок не включается в результат. При поиске движок регулярных выражений, найдя , проверяет есть ли после него
Если это не так, то игнорирует совпадение и продолжает поиск дальше
При поиске движок регулярных выражений, найдя , проверяет есть ли после него . Если это не так, то игнорирует совпадение и продолжает поиск дальше.
Возможны и более сложные проверки, например означает:
- Найти .
- Проверить, идёт ли сразу после (если нет – не подходит).
- Проверить, идёт ли сразу после (если нет – не подходит).
- Если обе проверки прошли – совпадение найдено.
То есть, этот шаблон означает, что мы ищем при условии, что за ним идёт и и .
Такое возможно только при условии, что шаблоны и не являются взаимно исключающими.
Например, ищет при условии, что за ним идёт пробел, и где-то впереди есть :
В нашей строке это как раз число .
Упрощённый пример
В чём же дело? Почему регулярное выражение «зависает»?
Чтобы это понять, упростим пример: уберём из него пробелы . Получится .
И, для большей наглядности, заменим на . Получившееся регулярное выражение тоже будет «зависать», например:
В чём же дело, что не так с регулярным выражением?
Внимательный читатель, посмотрев на , наверняка удивится, ведь оно какое-то странное. Квантификатор здесь выглядит лишним. Если хочется найти число, то с тем же успехом можно искать .
Действительно, это регулярное выражение носит искусственный характер, но, разобравшись с ним, мы поймём и практический пример, данный выше. Причина их медленной работы одинакова. Поэтому оставим как есть.
Что же происходит во время поиска в строке (укоротим для ясности), почему всё так долго?
-
Первым делом, движок регулярных выражений пытается найти . Плюс является жадным по умолчанию, так что он хватает все цифры, какие может:
Затем движок пытается применить квантификатор , но больше цифр нет, так что звёздочка ничего не даёт.
Далее по шаблону ожидается конец строки , а в тексте символ , так что соответствий нет:
-
Так как соответствие не найдено, то «жадный» квантификатор уменьшает количество повторений, возвращается на один символ назад.
Теперь – это все цифры, за исключением последней:
-
Далее движок снова пытается продолжить поиск, начиная уже с позиции ().
Звёздочка теперь может быть применена – она даёт второе число :
Затем движок ожидает найти , но это ему не удаётся, ведь строка оканчивается на :
-
Так как совпадения нет, то поисковый движок продолжает отступать назад. Общее правило таково: последний жадный квантификатор уменьшает количество повторений до тех пор, пока это возможно. Затем понижается предыдущий «жадный» квантификатор и т.д.
Перебираются все возможные комбинации. Вот их примеры.
Когда первое число содержит 7 цифр, а дальше число из 2 цифр:
Когда первое число содержит 7 цифр, а дальше два числа по 1 цифре:
Когда первое число содержит 6 цифр, а дальше одно число из 3 цифр:
Когда первое число содержит 6 цифр, а затем два числа:
…И так далее.
Существует много способов как разбить на числа набор цифр . Если быть точным, их , где – длина набора.
В случае их порядка миллиона, при – ещё в тысячу раз больше. На их перебор и тратится время.
Что же делать?
Может нам стоит использовать «ленивый» режим?
К сожалению, нет: если мы заменим на , то регулярное выражение всё ещё будет «зависать». Поменяется только порядок перебора, но не общее количество комбинаций.
Некоторые движки регулярных выражений содержат хитрые проверки и конечные автоматы, которые позволяют избежать полного перебора в таких ситуациях или кардинально ускорить его, но не все движки и не всегда.
Литерал регулярных выражений
Второй способ — использование литерала. Как и конструктор, литерал регулярных выражений состоит из двух частей. Первая часть — это описываемый шаблон. Он заключается в слэши (). После закрывающего слэша идёт вторая часть — флаги. Они необязательны.
// Синтаксис литерала регулярных выражений/pattern/flags// Создание регулярного выражения// с помощью литерала// без флаговconst myPattern = //// Создание регулярного выражения// с помощью литерала// с одним флагомconst myPattern = //g
Примечание: два слэша в литерале регулярных выражений используются для того, чтобы заключить в них шаблон. Если ваш шаблон предполагает использование ещё одного или нескольких прямых слэшей, их необходимо экранировать обратным слэшем (), то есть
Область применения регулярных выражений
В прошлом уроке мы разбирали работу со строками и там было несколько функций для поиска и извлечения искомых подстрок. Может возникнуть вопрос, а зачем придумывать что-то еще, если у нас уже есть достаточно богатый функционал для раздербанивания и анализа строк? Отвечаю, при работе с огромным количество текста, особенно, который генерируется динамически, можно проследить некоторые паттерны(повторяющиеся фрагменты и структура текста в-целом). Допустим, нам нужно выдрать из таблички все названия товаров и цены, а сколько данных будет в таблице — нам не известно. Можно в цикле использовать и, но код получится громоздким и не очень надежным. Регулярные выражения очень удобно использовать для валидации данных, например для электронной почты, номера телефона, даты и т.д.
Помните задачку из прошлого урока «Определение баланса биткойн-крана»? Там мы находили определенный тэг и из него извлекали текст, после чего получали оттуда цифру. Если мы попытались бы использовать тот же скрипт на другом кране — не факт, что он заработал бы, поскольку сведения о балансе могли находится в совершенно другом тэге с другим классом и другими атрибутами.
При помощи регулярных выражений мы можем сделать универсальный скрипт, который будет искать баланс крана не по тэгу, а в тексте страницы.
Алгоритм такой:
- Мы получаем содержимое всей страницы в текстовом формате
- Составляем паттерн на основе строки Balance: 145335 satoshi. Логически это выглядит примерно так
- Ищем в тексте все совпадения с нашим паттерном и при успехе, вытаскиваем значение из 1-9 цифр.
Выглядеть это будет так:
var str = window.document.querySelector('body').textContent;
var re = /Balance:\s{0,}(\d{1,9})\s{0,}satoshi/igm;
var result = re.exec(str);
window.console.log(result); //
window.console.log(result); // 145335 - это баланс нашего крана
Я пока не буду подробно разбирать этот код, все подробности ниже.Что действительно круто, регулярные выражения работают очень быстро и позволяют просто с хирургической точностью вытаскивать нужные данные и мы можем легко проанализировать все совпадения с заданным паттерном.
Quantifiers
| Quantifier | Description |
|---|---|
| n+ | Matches any string that contains at least one n |
| n* | Matches any string that contains zero or more occurrences of n |
| n? | Matches any string that contains zero or one occurrences of n |
| n{X} | Matches any string that contains a sequence of X n‘s |
| n{X,Y} | Matches any string that contains a sequence of X to Y n‘s |
| n{X,} | Matches any string that contains a sequence of at least X n‘s |
| n$ | Matches any string with n at the end of it |
| ^n | Matches any string with n at the beginning of it |
| ?=n | Matches any string that is followed by a specific string n |
| ?!n | Matches any string that is not followed by a specific string n |
Пример
Допустим, у нас есть строка, и мы хотим проверить, что она состоит из слов , после каждого слова может быть пробел .
Используем регулярное выражение , которое задаёт 0 или более таких слов.
Проверим, чтобы убедиться, что оно работает:
Результат верный. Однако, на некоторых строках оно выполняется очень долго. Так долго, что интерпретатор JavaScript «зависает» с потреблением 100% процессора.
Если вы запустите пример ниже, то, скорее всего, ничего не увидите, так как JavaScript «подвиснет»
В браузере он перестанет реагировать на другие события и, скорее всего, понадобится перезагрузить страницу, так что осторожно с этим:. Некоторые движки регулярных выражений могут справиться с таким поиском, но большинство из них – нет
Некоторые движки регулярных выражений могут справиться с таким поиском, но большинство из них – нет.
Ретроспективная проверка
Опережающие проверки позволяют задавать условия на то, что «идёт после».
Ретроспективная проверка выполняет такую же функцию, но с просмотром назад. Другими словами, она находит соответствие шаблону, только если перед ним есть что-то заранее определённое.
Синтаксис:
- Позитивная ретроспективная проверка: , ищет совпадение с при условии, что перед ним ЕСТЬ .
- Негативная ретроспективная проверка: , ищет совпадение с при условии, что перед ним НЕТ .
Чтобы протестировать ретроспективную проверку, давайте поменяем валюту на доллары США. Знак доллара обычно ставится перед суммой денег, поэтому для того чтобы найти , мы используем – число, перед которым идёт :
Если нам необходимо найти количество индеек – число, перед которым не идёт , мы можем использовать негативную ретроспективную проверку :
Объект RegExp
Объект типа , или, короче, регулярное выражение, можно создать двумя путями
/pattern/флаги
new RegExp("pattern")
— регулярное выражение для поиска (о замене — позже), а флаги — строка из любой комбинации символов (глобальный поиск), (регистр неважен) и (многострочный поиск).
Первый способ используется часто, второй — иногда. Например, два таких вызова эквивалентны:
var reg = /ab+c/i
var reg = new RegExp("ab+c", "i")
При втором вызове — т.к регулярное выражение в кавычках, то нужно дублировать
// эквивалентны
re = new RegExp("\\w+")
re = /\w+/
При поиске можно использовать большинство возможностей современного PCRE-синтаксиса.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}