Часть 1. введение в sql
Содержание:
- Доступ к значениям столбца
- Что у нас хорошего?
- Modify the build.xml file
- Хранимые процедуры
- Distributed Transactions
- Подключение к базе данных
- Дизайн СУБД
- Выполнение команд. Метод executeUpdate
- Базы данных
- Транзакции
- Пример использования объекта JDBC PreparedStatement — удаление записи
- Тип ResultSet, параллелизм и удерживаемость
- JDBC Architecture
Доступ к значениям столбца
При переборе ResultSet вы хотите получить доступ к значениям столбцов каждой записи. Вы делаете это, вызывая один или несколько методов getXXX(). Вы передаете имя столбца, чтобы получить значение многих методов getXXX(). Например:
while(result.next()) {
result.getString ("name");
result.getInt ("age");
result.getBigDecimal("coefficient");
// etc.
}
Есть много методов getXXX(), которые вы можете вызвать, которые возвращают значение столбца в виде определенного типа данных, например String, int, long, double, BigDecimal и т. Д. Все они берут имя столбца, чтобы получить столбец значение для, как параметр. Вот список быстрых примеров этих методов getXXX():
result.getArray("columnName");
result.getAsciiStream("columnName");
result.getBigDecimal("columnName");
result.getBinaryStream("columnName");
result.getBlob("columnName");
result.getBoolean("columnName");
result.getBlob("columnName");
result.getBoolean("columnName");
result.getByte("columnName");
result.getBytes("columnName");
result.getCharacterStream("columnName");
result.getClob("columnName");
result.getDate("columnName");
result.getDouble("columnName");
result.getFloat("columnName");
result.getInt("columnName");
result.getLong("columnName");
result.getNCharacterStream("columnName");
result.getObject("columnName");
result.getRef("columnName");
result.getRowId("columnName");
result.getShort("columnName");
result.getSQLXML("columnName");
result.getString("columnName");
result.getTime("columnName");
result.getTimestamp("columnName");
result.getUnicodeStream("columnName");
result.getURL("columnName");
Методы getXXX() также существуют в версиях, которые принимают индекс столбца вместо имени столбца. Например:
while(result.next()) {
result.getString (1);
result.getInt (2);
result.getBigDecimal(3);
// etc.
}
Индекс столбца обычно зависит от индекса столбца в операторе SQL. Например, оператор SQL
select name, age, coefficient from person
имеет три столбца. Имя столбца указывается первым и, следовательно, будет иметь индекс 1 в ResultSet. Возраст столбца будет иметь индекс 2, а коэффициент столбца будет иметь индекс 3.
Иногда вы не знаете индекс определенного столбца раньше времени. Например, если вы используете SQL-запрос select * from, вы не знаете последовательность столбцов.
Если вы не знаете индекс определенного столбца, вы можете найти индекс этого столбца, используя метод ResultSet.findColumn(String columnName), например:
int nameIndex = result.findColumn("name");
int ageIndex = result.findColumn("age");
int coeffIndex = result.findColumn("coefficient");
while(result.next()) {
String name = result.getString (nameIndex);
int age = result.getInt (ageIndex);
BigDecimal coefficient = result.getBigDecimal(coeffIndex);
}
Что у нас хорошего?
- Поддержка MySQL 5.1.41 / 5.5.8, Oracle XE 10.2.0.1.0, DB2 9.7, PostGreSQL 9.0, H2 1.3.154, HSQLDB 2.1.0, SQLite, Derby 10.7
- Планируется поддержка Sybase, MSSQL, Ingres, Firebird
- Поддержка генерации кода не только для таблиц / полей, но и представлений, хранимых процедур, UDF, сложных типов вроде ENUM в MySQL, Blob (можно представить их в виде обычных byte[])
- Поскольку вся схема базы данных представлена классами, в IDE работает автозавершение языковых конструкций
- Отсутствие уязвимости SQL Injection при правильном использовании — jooq пользуется шаблонами параметров в запросах
- По большей части независимый от базы данных синтаксис
- Использование обобщенных типов обеспечивает достаточное количество проверок еще при компиляции кода. Плюс невозможно забыть исправить какой-либо кусочек кода, если вы вдруг переименовали столбец в таблице БД. После повторного парсинга БД некорректный код просто не скомпилируется
- Базовая поддержка ActiveRecord (полученную из базы данных запись можно изменить и записать назад одним-двумя строчками)
- Поддержка не только SELECT запросов, но и INSERT, UPDATE.
- Поддержка вложенных запросов, произвольных полей, агрегатных функций, UNION запросов, арифметических и других операций
- Удобные методы получения результатов выполнения запроса — fetch(), fetchAny(), fetchLazy(), fetchMap() и другие.
- Хорошая поддержка SLF4J в том числе и для профайлинга внутреннего устройства Jooq.
- Много чего запланировано
- Автор постоянно в интернете, очень оперативно отвечает на вопросы в jooq Google Group и на тикеты в баг-трекере.
- Поддержка Maven. Дистрибутивы jooq доступны через Maven Central.
- Поддержка как DSL синтаксиса (select().from().where()) конструирования запросов, так и ООП (a=new Query(); a.addSelect(); a.addFrom())
- Результаты запросов и сами объекты запросов сериализуемы.
Modify the build.xml file
The file is the build file that Apache Ant uses to compile and execute the JDBC samples. The files and contain additional Apache Ant properties required for Java DB and MySQL, respectively. The files and contain properties required by the sample.
Modify these XML files as follows:
Modify build.xml
In the file, modify the property to refer to either or , depending on your DBMS. For example, if you are using Java DB, your file would contain this:
<property
name="ANTPROPERTIES"
value="properties/javadb-build-properties.xml"/>
<import file="${ANTPROPERTIES}"/>
Similarly, if you are using MySQL, your file would contain this:
<property
name="ANTPROPERTIES"
value="properties/mysql-build-properties.xml"/>
<import file="${ANTPROPERTIES}"/>
Modify database-specific properties file
In the or file (depending on your DBMS), modify the following properties, as described in the following table:
| Property | Description |
|---|---|
| The full path name of your Java compiler, | |
| The full path name of your Java runtime executable, | |
| The name of the properties file, either or | |
| The full path name of your MySQL driver. For Connector/J, this is typically . | |
| The full path name of your Java DB driver. This is typically . | |
| The full path name of the directory that contains Apache Xalan. | |
| The class path that the JDBC tutorial uses. You do not need to change this value. | |
| The full path name of the file . | |
| A value of either or depending on whether you are using Java DB or MySQL, respectively. The tutorial uses this value to construct the URL required to connect to the DBMS and identify DBMS-specific code and SQL statements. | |
| The fully qualified class name of the JDBC driver. For Java DB, this is . For MySQL, this is . | |
| The host name of the computer hosting your DBMS. | |
| The port number of the computer hosting your DBMS. | |
| The name of the database the tutorial creates and uses. | |
| The connection URL used to connect to your DBMS when creating a new database. You do not need to change this value. | |
| The connection URL used to connect to your DBMS. You do not need to change this value. | |
| The name of the user that has access to create databases in the DBMS. | |
| The password of the user specified in . | |
| The character used to separate SQL statements. Do not change this value. It should be the semicolon character (). |
Хранимые процедуры
В этой главе мы расмотрим что такое хранимые процедуры и как их использовать вместе с JDBC. Для примера мы будем использовать хранимые процедуры MySQL.
Хранимые процедуры это набор операторов SQL как часть логической единицы исполнения и выполнения определенной задачи. Они очень полезны для инкапсулирования группы операций, которые будут выполняться в базе данных.
Первым делом мы создадим процедуру в нашей MySQL БД, следующий скрипт поможет нам с этой задачей:
delimiter // CREATE PROCEDURE spanish (OUT population_out INT) BEGIN SELECT COUNT(*) INTO population_out FROM countries; END// delimiter ; CALL simpleproc(@a);
Скрипт выше создает процедуру, которая называется spanish с одним выходным атрибутом типа Int и без входных параметров. Процедура возвращает количество всех стран в базе данных.
Однажды создав процедуру мы можем работать с ней из нашего Java приложения. Для вызова хранимой процедуры нам надо использовать специальные операторы интерфейса java.sql.CallableStatement, эти операторы позволяют программистам выполнять хранимые процедуры с указанием выходных атрибутов и входных параметров, которые будут использоваться. В нашем простом примере используются только выходные аргументы, вот и сам пример:
CallableStatement callableStatement = null;
// the procedure should be created in the database
String spanishProcedure = "{call spanish(?)}";
// callable statement is used
callableStatement = connect.prepareCall( spanishProcedure );
// out parameters, also in parameters are possible, not in this case
callableStatement.registerOutParameter( 1, java.sql.Types.VARCHAR );
// execute using the callable statement method executeUpdate
callableStatement.executeUpdate();
// attributes are retrieved by index
String total = callableStatement.getString( 1 );
System.out.println( "amount of spanish countries " + total );
Мы можем определить, где хранить выходные данные процедуры и как выполнить ее с помощью метода java.sql.PreparedStatement.executeUpdate(). Хранимые процедуры поддерживаются большинством БД, но их синтаксис и поведение может быть различным, поэтому могут быть различия в приложениях Java в обработке хранимых процедур в зависимости от баз данных, где хранятся процедуры.
Distributed Transactions
The classes and interfaces used for distributed transactions are:
The interface is derived from the
interface, so what applies to a pooled connection
also applies to a connection that is part of a distributed transaction.
A transaction manager in the middle tier handles everything transparently.
The only change in application code is that an application cannot do anything
that would interfere with the transaction manager’s handling of the transaction.
Specifically, an application cannot call the methods
or , and it cannot set the connection to be in
auto-commit mode (that is, it cannot call
).
An application does not need to do anything special to participate in a
distributed transaction.
It simply creates connections to the data sources it wants to use via
the method, just as it normally does.
The transaction manager manages the transaction behind the scenes. The
interface creates objects, and
each object creates an object
that the transaction manager uses to manage the connection.
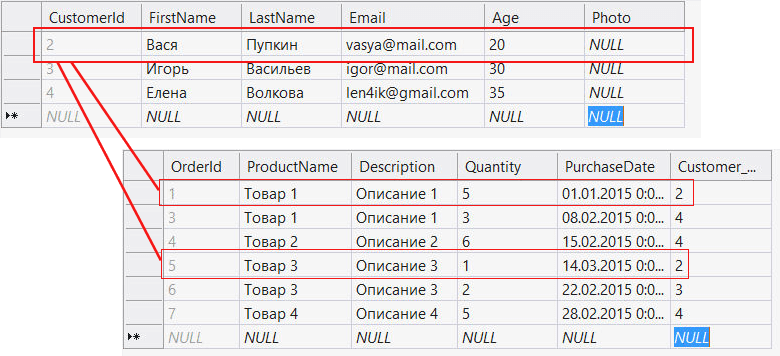
Подключение к базе данных
Последнее обновление: 08.08.2018
Вначале создадим на сервере MySQL пустую базу данных, которую назовем store и с которой мы будет работать в приложении на Java. Для создания базы данных применяется выражение SQL:
CREATE DATABASE store;
Его можно выполнить либо из консольного клиента MySQL Command Line Client, либо из графического клиента MySQL Workbench, которые устанавливются
вместе с сервером MySQL. Подробнее про создание базы данных можно прочитать в статье Создание и удаление базы данных.
Для подключения к базе данных необходимо создать объект java.sql.Connection. Для его создаия применяется метод:
Connection DriverManager.getConnection(url, username, password)
Метод в качестве параметров принимает адрес источника данных, логин и пароль. В качестве логина и пароля передаются
логин и пароль от сервера MySQL. Адрес локальной базы данных MySQL указывается в следующем формате:
Пример создания подключения к созданной выше локальной базе данных store:
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost/store", "root", "password");
После завершения работы с подключением его следует закрыть с помощью метода close():
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost/store", "root", "password");
// работа с базой данных
connection.close();
Либо мы можем использовать конструкцию try:
try (Connection conn = DriverManager.getConnection("jdbc:mysql://localhost/store", "root", "password")){
// работа с базой данных
}
Возможные проблемы с часовыми поясами и SSL
При подключении к базе данных MySQL мы можем столкнуться с рядом проблем. Например, определим следующий код подключения:
import java.sql.Connection;
import java.sql.DriverManager;
public class Program{
public static void main(String[] args) {
try{
String url = "jdbc:mysql://localhost/store";
String username = "root";
String password = "password";
Class.forName("com.mysql.cj.jdbc.Driver").getDeclaredConstructor().newInstance();
try (Connection conn = DriverManager.getConnection(url, username, password)){
System.out.println("Connection to Store DB succesfull!");
}
}
catch(Exception ex){
System.out.println("Connection failed...");
System.out.println(ex);
}
}
}
Даже если указаны правильно адрес базы данных, логин, пароль, мы все равно можем столкнуться с ошибками:
Из консольного вывода видно, что проблема заключается с SSL и часовым поясом. Чтобы решить данную проблему, необходимо указать в адресе подключения часовой пояс бд и
параметры для использования ssl. В частности, я указываю, что SSL не будет использоваться и что часовым поясом будет московский часовой пояс:
String url = "jdbc:mysql://localhost/store?serverTimezone=Europe/Moscow&useSSL=false";
Файлы конфигурации
Мы можем определить все данные для подключения непосредственно в программе. Однако что если какие-то данные были изменены? В этом случае потребуется перекомпиляция приложения. Иногда это не всегда удобно, например, отсутствует досуп к исходникам,
или перекомпиляция займет довольно продолжительное время. В этом случае мы можем хранить настройки в файле.
Так, создадим в папке программы новый текстовый файл database.properties, в котором определим настройки подключения:
url = jdbc:mysql://localhost/store?serverTimezone=Europe/Moscow&useSSL=false username = root password = password
Загрузим эти настройки в программе:
import java.sql.*;
import java.nio.file.*;
import java.io.*;
import java.util.*;
public class Program{
public static void main(String[] args) {
try{
Class.forName("com.mysql.cj.jdbc.Driver").getDeclaredConstructor().newInstance();
try (Connection conn = getConnection()){
System.out.println("Connection to Store DB succesfull!");
}
}
catch(Exception ex){
System.out.println("Connection failed...");
System.out.println(ex);
}
}
public static Connection getConnection() throws SQLException, IOException{
Properties props = new Properties();
try(InputStream in = Files.newInputStream(Paths.get("database.properties"))){
props.load(in);
}
String url = props.getProperty("url");
String username = props.getProperty("username");
String password = props.getProperty("password");
return DriverManager.getConnection(url, username, password);
}
}
НазадВперед
Дизайн СУБД
Описание приложения
- Существуют акции, стоимость которых может меняться в течение торгового дня по заданным правилам;
- есть трейдеры с начальным капиталом;
- трейдеры могут покупать и продавать акции, согласно своему алгоритму.
тиками
Структура данных эмуляции биржи
Акция:
| Атрибут | Тип | Описание |
|---|---|---|
| Srting | Наименование | |
| int | Вероятность смены курса в процентах на каждом тике | |
| BigDecimal | Начальная стоимость | |
| int | Максимальная величина в процентах, на которую может смениться текущая стоимость |
Курс акции:
| Атрибут | Тип | Описание |
|---|---|---|
| LocalDateTime | Время (тик) выставления курса | |
| Акция | Ссылка на акцию | |
| BigDecimal | Курс акции |
Трейдер:
| Атрибут | Тип | Описание |
|---|---|---|
| String | Время (тик) выставления курса | |
| int | Частота совершения операций. Задана периодом, в тиках, спустя который трейдер совершает операции | |
| BigDecimal | Сумма денег, помимо акций | |
| int | Используемый трейдером алгоритм. Зададим его числом-константой, реализация алгоритма будет (в следующих частях) в Java-коде | |
| int | Вероятность выполнения операции, в процентах | |
| String | Вероятность смены курса, в процентах, на каждом тике |
Действия трейдеров:
| Атрибут | Тип | Описание |
|---|---|---|
| int | Тип операции (покупка или продажа) | |
| Трейдер | Ссылка на трейдера | |
| Курс акции | Ссылка на курс акции (соответственно на саму акцию, её курс и время его выставление) | |
| Long | Количество акций, участвующих в операции |
longуникальным
- размер данных существенно превышает объем доступной оперативной памяти;
- доступ к данным предполагается с десятка разных мест;
- необходима возможность одновременного модифицирования и чтения данных;
- нужно обеспечить правила формирования и целостности данных;
Хранения данных в СУБД
- Данные в СУБД организованы в таблицы (TABLE), представляющие собой набор записей.
- Все записи имеют одинаковые наборы полей. Они задаются при создании таблицы.
- Для поля можно выставить значение по умолчанию (DEFAULT).
- Для таблицы можно выставить ограничения (CONSTRAINT), описывающие требования к её данным чтобы обеспечить их целостность. Это можно сделать на этапе создания таблицы (CREATE TABLE) или добавить позже (ALTER TABLE … ADD CONSTRAINT).
- Наиболее распространённые CONSTRAINT:
- Первичный ключ PRIMARY (Id в нашем случае).
- Уникальное значение поле UNIQUE (VIN для таблицы автотранспорта).
- Проверка поля CHECK (значение процентов не может быть больше 100). Одно из частных ограничений на поле – NOT NULL или NULL, запрещающее/разрешающее хранить NULL в поле таблицы.
- Ссылка на стороннюю таблицу FOREIGN KEY (ссылка на акцию в таблице курсов акций).
- Индекс INDEX (индексирование поля для ускорения поиска значений по нему).
- Выполнение модификации записи (INSERT, UPDATE) не произойдёт, если значение её полей противоречат ограничениям (CONSTRAINT).
- Каждая таблица может иметь ключевое поле (или несколько), по которой можно однозначно определить запись. Такое поле (или поля, если они формируют составной ключ) образует первичный ключ таблицы — PRIMARY KEY.
- Первичный ключ обеспечивает уникальность записи в таблице, по нему создается индекс, что дает быстрый доступ по значению ключа ко всей записи.
- Наличие первичного ключа существенно облегчает создание ссылок между таблицами. Далее мы будем использовать искусственный первичный ключ: для первой записи , каждая следующая запись будет вставляться в таблицу с увеличенным на единицу значением id. Такой ключ часто называют AutoIncrement или AutoIdentity.
Выполнение команд. Метод executeUpdate
Последнее обновление: 08.08.2018
Для взаимодействия с базой данных приложение отправляет серверу MySQL команды на языке SQL. Чтобы выполнить команду, вначале необходимо создаеть объект
Statement.
Для его создания у объекта Connection вызывается метод createStatement():
Statement statement = conn.createStatement();
Для выполнения команд SQL в классе Statement определено три метода:
-
executeUpdate: выполняет такие команды, как INSERT, UPDATE, DELETE, CREATE TABLE, DROP TABLE. В качестве результата
возвращает количество строк, затронутых операцией (например, количество добавленных, измененных или удаленных строк), или 0, если ни одна строка не затронута операцией или если
команда не изменяет содержимое таблицы (например, команда создания новой таблицы) -
executeQuery: выполняет команду SELECT. Возвращает объект ResultSet, который содержит результаты запроса.
-
execute(): выполняет любые команды и возвращает значение boolean: true — если команда возвращает набор строк (SELECT), иначе
возвращается false.
Рассмотрим метод executeUpdate(). В качестве параметра в него передается собственно команда SQL:
int executeUpdate("Команда_SQL")
Ранее была создана база данных store, но она пустая, в ней нет таблиц и соответственно данных. Создадим таблицу и добавим в нее начальные данные:
import java.sql.*;
public class Program{
public static void main(String[] args) {
try{
String url = "jdbc:mysql://localhost/store?serverTimezone=Europe/Moscow&useSSL=false";
String username = "root";
String password = "password";
Class.forName("com.mysql.cj.jdbc.Driver").getDeclaredConstructor().newInstance();
// команда создания таблицы
String sqlCommand = "CREATE TABLE products (Id INT PRIMARY KEY AUTO_INCREMENT, ProductName VARCHAR(20), Price INT)";
try (Connection conn = DriverManager.getConnection(url, username, password)){
Statement statement = conn.createStatement();
// создание таблицы
statement.executeUpdate(sqlCommand);
System.out.println("Database has been created!");
}
}
catch(Exception ex){
System.out.println("Connection failed...");
System.out.println(ex);
}
}
}
То есть в данном случае мы выполняем команду ,
которая создает таблицу Products с тремя столбцами: Id — индентификатор стоки, ProductName — строковое название товара и Price — числовая цена товара.
При этом если необходимо выполнить сразу несколько команд, то необязательно создавать новый объект Statement:
Statement statement = conn.createStatement();
statement.executeUpdate("Команда_SQL1");
statement.executeUpdate("Команда_SQL2");
statement.executeUpdate("Команда_SQL3");
НазадВперед
Базы данных
JDBC поддерживает большое количество БД. Он абстрагирует их различия и способы работы используя различные драйверы. Класс DriverManager отвечает за загрузку правильной БД, после этого загруженный код для выборки и изменения данных в БД останется (более или менее) без изменений.
Вот список поддерживаемых БД(оффициально зарегестрированных Oracle): http://www.oracle.com/technetwork/java/index-136695.html.
В этой главе мы рассмотрим как использовать различные БД: MySQL и HSQLDB. Первая хорошо знакома программистам и широко используется, вторая, HSQLDB, очень полезна для целей тестирования и предлагает возможность работы в памяти. Мы увидим, как использовать обе, и обнаружим, что кроме загрузки соответствующего драйвера JDBC, остальная часть приложения остается без изменений:
MySQL пример:
public static void main( String[] args ) throws ClassNotFoundException, SQLException {
// connection to JDBC using mysql driver
Class.forName( "com.mysql.jdbc.Driver" );
Connection connect = DriverManager.getConnection("jdbc:mysql://localhost/countries?"
+ "user=root&password=root" );
selectAll( connect );
// close resources, in case of exception resources are not properly cleared...
}
/**
* select statement and print out results in a JDBC result set
*
* @param conn
* @throws SQLException
*/
private static void selectAll( java.sql.Connection conn ) throws SQLException {
Statement statement = conn.createStatement();
ResultSet resultSet = statement.executeQuery( "select * from COUNTRIES" );
while( resultSet.next()) {
String name = resultSet.getString( "NAME" );
String population = resultSet.getString( "POPULATION" );
System.out.println( "NAME: " + name );
System.out.println( "POPULATION: " + population );
}
}
В памяти (HSQLDB) пример:
public static void main( String[] args ) throws ClassNotFoundException, SQLException {
// Loading the HSQLDB JDBC driver
Class.forName( "org.hsqldb.jdbc.JDBCDriver" );
// Create the connection with the default credentials
java.sql.Connection conn = DriverManager.getConnection( "jdbc:hsqldb:mem:mydb", "SA", "" );
// Create a table in memory
String countriesTableSQL = "create memory table COUNTRIES (NAME varchar(256) not null primary key, POPULATION varchar(256) not null);";
// execute the statement using JDBC normal Statements
Statement st = conn.createStatement();
st.execute( countriesTableSQL );
// nothing is in the database because it is just in memory, non persistent
selectAll( conn );
// after some insertions, the select shows something different, in the next execution these
// entries will not be there
insertRows( conn );
selectAll( conn );
}
...
/**
* select statement and print out results in a JDBC result set
*
* @param conn
* @throws SQLException
*/
private static void selectAll( java.sql.Connection conn ) throws SQLException {
Statement statement = conn.createStatement();
ResultSet resultSet = statement.executeQuery( "select * from COUNTRIES" );
while( resultSet.next()) {
String name = resultSet.getString( "NAME" );
String population = resultSet.getString( "POPULATION" );
System.out.println( "NAME: " + name );
System.out.println( "POPULATION: " + population );
}
}
Как мы можем видеть в последних примерах, код метода selectAll одинаковый, только JDBC драйвер загружается и подключение создает изменения; мы можем представить насколько это может быть полезно когда приходится работать с различным окружением. Версия HSQLDB содержит также фрагмент кода, отвечающего за создание базы данных в памяти и вставки нескольких строк, но это только для демонстрации и ясности целей и может быть сделано по-разному.
Транзакции
JDBC поддерживает транзакции и содержит методы и функциональные возможности для реализации приложений на основе транзакций. Мы расмотрим наиболее важные в этой главе.
- java.sql.Connection.setAutoCommit(boolean): Этот метод принимает параметр boolean, по умолчанию true, все SQL выражения будут сохранены автоматически в БД. Иначе если передано false изменения не будут сохранены автоматически, а будут ожидать метода java.sql.Connection.commit().
- java.sql.Connection.commit(): Этот метод может быть использован только если autocommit имеет значение false или отключен. Когда данный метод выполняется, все изменения с последнего коммита или отката(rollback) будут сохранены в БД.
- java.sql.Connection.rollback(): Этот метод может быть использован когда autocommit отключен. Он отменяет или возвращает все изменения, сделанные в текущей транзакции.
И вот пример использования где мы можем видеть как отключить autocommit. Все изменения фиксируются при вызове commit() и текущие изменения транзакции откатываются с помощью метода rollback():
Class.forName( "com.mysql.jdbc.Driver" );
Connection connect = null;
try {
// connection to JDBC using mysql driver
connect = DriverManager.getConnection( "jdbc:mysql://localhost/countries?"
+ "user=root&password=root" );
connect.setAutoCommit( false );
System.out.println( "Inserting row for Japan..." );
String sql = "INSERT INTO COUNTRIES (NAME,POPULATION) VALUES ('JAPAN', '45000000')";
PreparedStatement insertStmt = connect.prepareStatement( sql );
// insert statement using executeUpdate
insertStmt.executeUpdate( sql );
connect.rollback();
System.out.println( "Updating row for Japan..." );
// update statement using executeUpdate -> will cause an error, update will not be
// executed becaues the row does not exist
sql = "UPDATE COUNTRIES SET POPULATION='1000000' WHERE NAME='JAPAN'";
PreparedStatement updateStmt = connect.prepareStatement( sql );
updateStmt.executeUpdate( sql );
connect.commit();
}
catch( SQLException ex ) {
ex.printStackTrace();
//undoes all changes in current transaction
connect.rollback();
}
finally {
connect.close();
}
Пример использования объекта JDBC PreparedStatement — удаление записи
Для выполнения операции удаления записи из таблицы с помощью объекта типа PreparedStatement используется метод executeUpdate(). Ниже показан пример такого действия. package ru.j4web.examples.java.jdbc.jdbcpreparedstatementdeleteexample; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.SQLException; import java.util.logging.Level; import java.util.logging.Logger; public class JDBCPreparedStatementDeleteExample { private static final String DB_URL = «jdbc:mysql://dev-server/sampledb» + «?user=sampleuser&password=samplepassword»; private static final String SQL_STATEMENT = «DELETE FROM users WHERE …
Читать далее »
Тип ResultSet, параллелизм и удерживаемость
Когда вы создаете ResultSet, вы можете установить три атрибута. Эти:
- Тип
- совпадение
- Holdability
Вы устанавливаете их уже при создании Statement или PreparedStatement, например так:
Statement statement = connection.createStatement(
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY,
ResultSet.CLOSE_CURSORS_OVER_COMMIT
);
PreparedStatement statement = connection.prepareStatement(sql,
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY,
ResultSet.CLOSE_CURSORS_OVER_COMMIT
);
Что именно означают эти атрибуты, объясняется далее в этом тексте. Но теперь вы сейчас, где их указать.
JDBC Architecture
Two-tier and Three-tier Processing Models
The JDBC API supports both two-tier and three-tier processing models for database access.
Figure 1: Two-tier Architecture for Data Access.
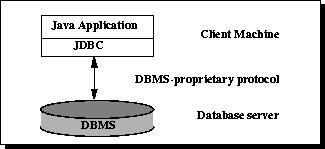
In the two-tier model, a Java applet or application talks directly to the data source. This requires a JDBC driver that can communicate with the particular data source being accessed. A user’s commands are delivered to the database or other data source, and the results of those statements are sent back to the user. The data source may be located on another machine to which the user is connected via a network. This is referred to as a client/server configuration, with the user’s machine as the client, and the machine housing the data source as the server. The network can be an intranet, which, for example, connects employees within a corporation, or it can be the Internet.
In the three-tier model, commands are sent to a «middle tier» of services, which then sends the commands to the data source. The data source processes the commands and sends the results back to the middle tier, which then sends them to the user. MIS directors find the three-tier model very attractive because the middle tier makes it possible to maintain control over access and the kinds of updates that can be made to corporate data. Another advantage is that it simplifies the deployment of applications. Finally, in many cases, the three-tier architecture can provide performance advantages.
Figure 2: Three-tier Architecture for Data Access.
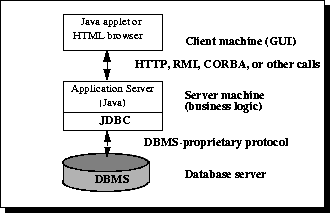
Until recently, the middle tier has often been written in languages such as C or C++, which offer fast performance. However, with the introduction of optimizing compilers that translate Java bytecode into efficient machine-specific code and technologies such as Enterprise JavaBeans, the Java platform is fast becoming the standard platform for middle-tier development. This is a big plus, making it possible to take advantage of Java’s robustness, multithreading, and security features.
With enterprises increasingly using the Java programming language for writing server code, the JDBC API is being used more and more in the middle tier of a three-tier architecture. Some of the features that make JDBC a server technology are its support for connection pooling, distributed transactions, and disconnected rowsets. The JDBC API is also what allows access to a data source from a Java middle tier.