Как узнать историю домена и сайта на нём?
Содержание:
- Reasons for using the Wayback Downloader
- Блокировка Архива Интернета[ | код]
- Как полностью скачать сайт из веб-архива
- Возможности использования веб-архивов
- Как найти нужный веб-архив и восстановить сайт без бекапа
- FAQ
- Поиск сайтов в Wayback Machine
- HTML верстка и анализ содержания сайта
- archive.md
- Проекты[ | код]
- r-tools.org
- Переделка сайта
Reasons for using the Wayback Downloader
What possible reasons can you have to download sites from the Wayback Machine?
- Missed hosting payments. Let’s say you’re super responsible webmaster. You always update and keep fresh content. You do security updates. You’re on top of things. But one day, you visit your website and all your content is gone! It’s in this moment that you remember that you forgot to change that credit card that was linked to your hosting account. Now all your content is gone! Dashed away by one false move..or is it? Enter our web Archive download bot. With a few simple clicks, you can be on your way to restoring a whole website — exactly like it used to be.
- Nostalgia. Maybe you played a computer game as a teenager or you used to frequently visit some hobby website. Many of these websites change or go offline, but with an archive.org download order, you can recover all your nostalgic memories.Simply go to our wayback machine download site and create your own web.archive.org download. This includes your whole website, up to 10 levels deep, which means all pages that are 10 clicks away from the front page.
- Your site was hacked. What if a more sinister plot involving a hacker compromising the security of your site arises? He’s hijacked your site, and now all your content has been deleted and replaced with ads for his own benefit. Not to worry! We have you covered with a nice Wayback machine download of your website, as it was before disaster struck.
- Legal evidence. Should you ever find yourself embroiled in a legal battle over whatever the issue may be, The Wayback Downloader can help here too. Make a copy of the web archive data for use as evidence in lawsuits. For example, patent law and evidence of prior art. The Wayback Machine accepts removal requests, so it’s a good idea to have your own copy in case the website disappears from the web archive.
- Internet Marketeers. Another neat feature of the Wayback Machine Downloader is the ability to recover content from a site that you may have purchased for purposes of SEO. Got a new PBN site that you want to revamp to include the old content it used to contain and maintain Google’s trust? The Wayback Machine Downloader steps in here and makes a seamless transition to the way the site was before.
- Take content from a bankrupt competitor. What if one of your biggest competitors has gone out of business, and with their exit from the business they also took down their website? Remember the URL? Voila! You’ve got yourself a ton of useable information to populate your new site with one less competitor to worry about. Basically, this can be for any site in your industry that was taken offline.
- For recovering expired content Sometimes you have good expired content — perhaps you found it with our service or with software like the Expired Article Hunter. Let’s say you have a good PBN domain with high metrics, and you have another domain with good expired content. Now you can merge the two domains and rebuilding the expired content on the domain with high metrics. It’s one of the quickest and best methods to build a PBN
- Use it as an alternative to httrack. Httrack is software to scrape live websites, but it doesn’t do a very good job at scraping the internet archive. We rebuild websites as they once were, while httrack simply copies a complete site, including all the headers and archive URLs
As you can see there are plenty of reasons to use the Wayback Machine Downloader. It is the perfect solution to download site from wayback machine. If you need help with any of the above, don’t hesitate to send us a message. We are glad to help you out.
Блокировка Архива Интернета[ | код]
В России | код
| Внешние изображения |
|---|
В октябре 2014 года Роскомнадзор заблокировал на территории РФ доступ к некоторым страницам Архива Интернета за видеоролик «Звон мечей» экстремистской группировки «Исламское государство Ирака и Леванта» (нынешнее название — «Исламское государство»). Ранее блокировались только ссылки на отдельные материалы в архиве, однако 24 октября 2014 года в реестр запрещённых сайтов временно был включён сам домен и его IP-адрес.
16 июня 2015 года на основании статьи 15.3 закона «Об информации, информационных технологиях и о защите информации» генпрокуратура РФ приняла решение о блокировке страницы «Одиночный джихад в России», содержащей, по её мнению, «призывы к массовым беспорядкам, осуществлению экстремистской деятельности, участию в массовых мероприятиях, проводимых с нарушением установленного порядка», в действительности на территории России был заблокирован доступ ко всему сайту, кроме .
С апреля 2016 года Роскомнадзор решил убрать сайт из блокировок, и он доступен в России.
По состоянию на 22 августа 2019 года в Мосгорсуде находятся на рассмотрении иски Ассоциации по защите авторских прав в интернете (АЗАПИ), в которых заявлено требование о блокировке интернет-портала archive.org на территории России в связи с нарушениями авторских прав.
В других странах СНГ | код
Архив блокировался на территории Казахстана в 2015 году.
Также в 2017 году сообщалось о блокировках архива в Киргизии.
В Индии | код
В Индии Архив был частично заблокирован судебным решением в августе 2017 года. Решение Madras High Court перечисляло 2,6 тыс. адресов в сети Интернет, которые способствовали пиратскому распространению ряда фильмов двух местных кинокомпаний. Представители проекта безуспешно пытались связаться с министерствами.
Как полностью скачать сайт из веб-архива
Если вы хотите восстановить удалённый сайт, то вам поможет программа Wayback Machine Downloader.
Программа загрузит последнюю версию каждого файла, присутствующего в Архиве Интернета Wayback Machine, и сохранить его в папку вида ./websites/example.com/. Она также пересоздаст структуру директорий и автоматически создаст страницы index.html чтобы скаченный сайт без каких либо изменений можно было бы поместить на веб-сервер Apache или Nginx.
Об установке программы и дополнительных опциях смотрите на странице https://kali.tools/?p=5211
Пример скачивания полной копии сайта suip.biz из веб-архива:
wayback_machine_downloader https://suip.biz

Структура скаченных файлов:
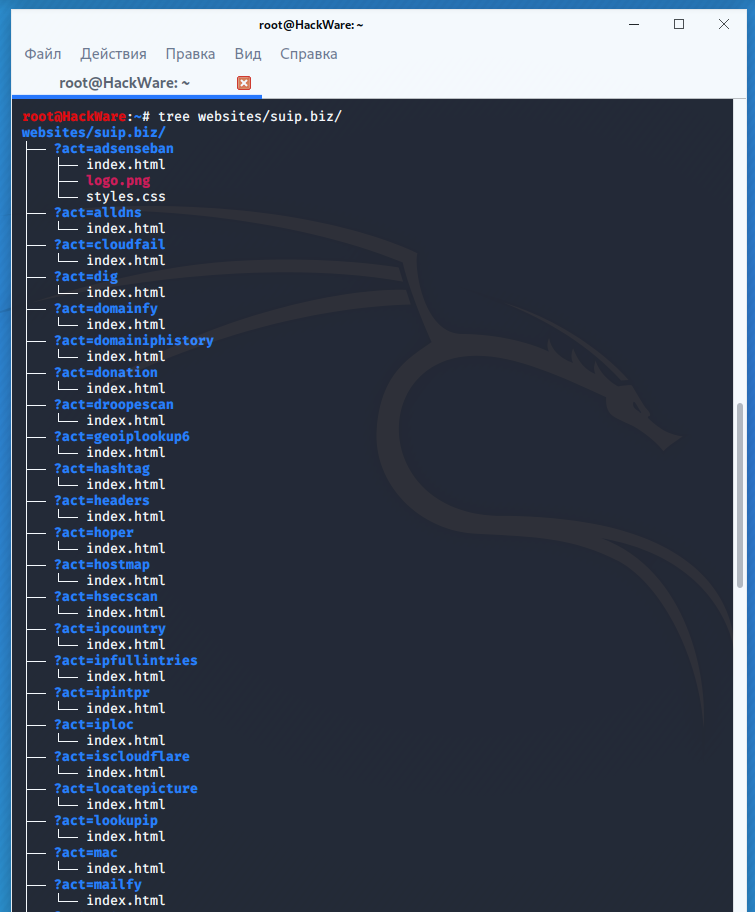
Локальная копия сайта, обратите внимание на провайдера Интернет услуг:

Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
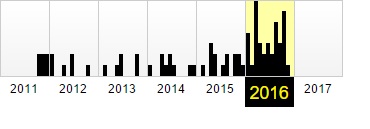 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Как найти нужный веб-архив и восстановить сайт без бекапа
По архивам можно перемещаться и с помощью временной шкалы расположенной вверху страницы, где вертикальными черными черточками отмечены имеющиеся для этого сайта слепки. Иногда, веб-архивы могут быть битыми, тогда придется открыть ближайший к нему слепок.
Щелкнув по голубому кружочку мы можем увидеть ссылки на несколько архивов, отличающихся временем их снятия.
Возможно, что это делается во избежании потери данных за счет неизбежной порчи жестких дисков в хранилищах. Перейдя к просмотру одного из веб-архивов, вы увидите копию своего (в данном примере моего) сайта с работающими внутренними ссылками и подключенным стилевым оформлением. Правда, не идеально работающим.
Например, кое-что из дизайна у меня все же перекосило и боковое меню работающее на ДжаваСкрипте полностью исчезло:
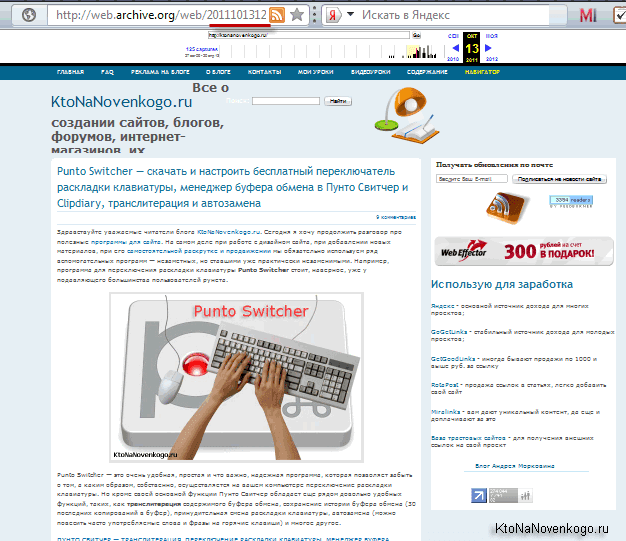
Но это не столь важно, ибо в исходном коде страницы с web.archive.org это меню, естественно, присутствует. Однако, просто так скопировать текст этой страницы к себе на сайт взамен утерянной не получится
Почему? Да потому что путешествие внутри сайта из прошлого будет возможно лишь в случае замены всех внутренних ссылок на те, что генерит Webarchive (в противном случае вас перебросило бы на современную версию ресурса).
Выглядят эти ссылки примерно так:
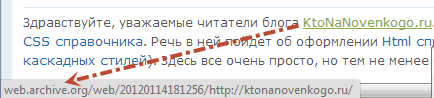
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/seo/search/samostoyatelnoe-prodvizhenie-sajta-kak-prodvigat-samomu-vnutrennej-optimizaciej.html
Понятно, что можно будет вручную отсечь вступительную часть ссылок (), получив таким образом рабочий вариант. Можно этот процесс даже автоматизировать с помощью инструмента поиска и замены редактора Notepad, но еще проще будет воспользоваться встроенной в этот сервис возможностью замены внутренних ссылок на оригинальные.
Для этого копируете адрес страницы с нужным слепком вашего сайта (из адресной строки браузера — начинается с ). Он будет иметь примерно такой вид:
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/
И вставляете в него конструкцию «id_» в конце даты (), чтобы получилось так:
http://web.archive.org/web/20111013120145id_/https://ktonanovenkogo.ru/
Теперь измененный адрес обратно возвращаете в адресную строку браузера и жмете на Enter. После этого страница c архивом вашего сайта обновится и все внутренние ссылки станут прямыми. Можно будет копировать текст статьи из исходного кода вебархива.
Понятно, что восстановление таким образом огромного сайта займет чудовищное количество времени, но когда другого варианта нет, то и такой покажется манной небесной. К тому же, страдают невозвратной потерей контента обычно только начинающие вебмастера, у которых этого самого контента было мало, а более-менее опытные сайтовладельцы, уж не раз обжигавшиеся на подобных вещах, делают бэкапы файлов и базы по пять раз на дню.
Если вы захотите увидеть все страницы вашего (или чужого) сайта, которые содержатся в недрах этого мастодонта, то вам нужно будет вставить в адресную строку браузера следующий адрес и нажать Enter:
http://wayback.archive.org/web/*/ktonanovenkogo.ru*
Вместо моего домена можно использовать свой. На открывшейся странице вы получите возможность наложить фильтр в предназначенной для этого форме:
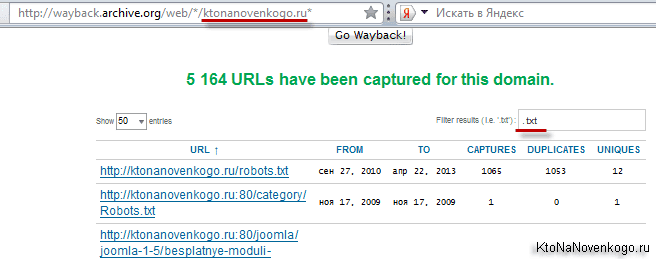
Например, я захотел увидеть лишь текстовые файлы своего блога, которые заглотил Web Archive. Зачем — не знаю, но захотел.
FAQ
I download from Wayback Machine but can use only a home page of the site, why?
The site you download from Wayback Machine needs to be installed on the server. You can’t just view all its pages on your PC. Also, make sure you’ve installed thefile called .htaccess on the server – it is responsible for the correctness of URLs working. Mind that it is compatible with Apache servers only. Finally, checkwhether you used a demo or paid archive.org Downloader. The demo version has a limit of 4 pages.
Why does Wayback Machine Downloader work slowly?
Sometimes, when you download Wayback Machine sites, you have to wait for several hours until the process is completed, especially is the site is large. This is primarily the fault of the Web Archive itself rather than the archive.org Downloader. The Archive is slow; moreover, it can block IPs, which try to downloadWayback Machine files too fast. The speed can further drop down if the original site contains many broken links.
Don’t I break the copyright laws by using the Wayback Machine Downloader?
If you use the archive.org Downloader to restore your own site, then, obviously, you don’t violate any laws, and the content belongs to you. When it comes to accessing third-party sites by using Wayback downloads, the legislative norms can vary from one country to another. But anyway, the risk is minimal, as few peoplecare much about their former websites. Thus, there are no recorded cases of complaints about using third-party expired content.
How long should I wait for the delivery of a WordPress conversion?
The conversion itself usually takes no more than 1-2 business days. But you need to keep in mind that depending on the Wayback Machine download site size, thedownload process can take from several hours to several days.
Will the Downloader tool archive entire website or a single page that I specify?
The Wayback Machine Downloader always extracts entire sites (up to 20 thousand pages per domain.) All the pages that can be accessed from the starting page willbe automatically downloaded.
What is the total number of files the Wayback Machine Downloader can extract?
The Wayback Machine Downloader will try to get all files that are found on the domain. But sometimes, attempts fail if the Web Archive declines the requests. Commonly, the webarchive extractor makes up to five attempts using different IP-addresses.
If you have additional questions of how to download from archive.org effectively and correctly, read the full review on the official site of the download WaybackMachine tool. It contains detailed guides and instructions on archive downloading, extracting, installing, and using.
Поиск сайтов в Wayback Machine
Wayback Machine
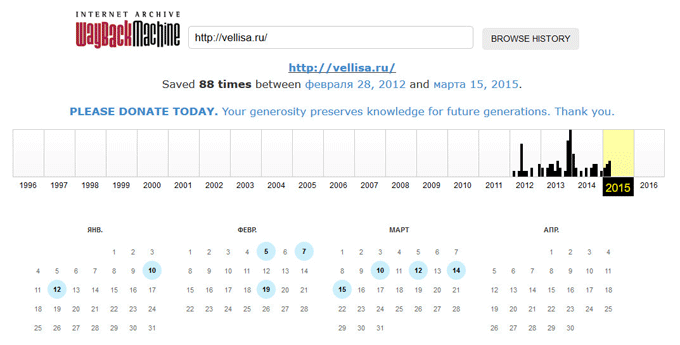
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
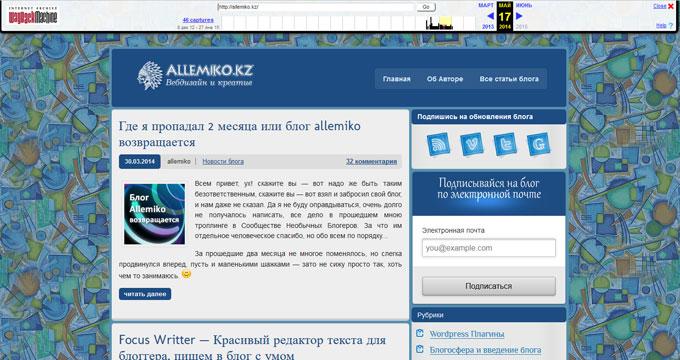
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.

На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
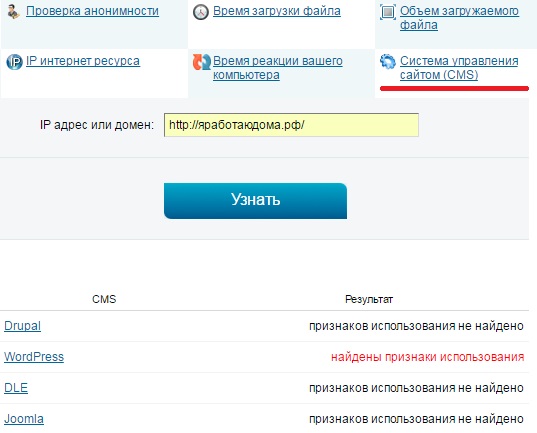
HTML верстка и анализ содержания сайта
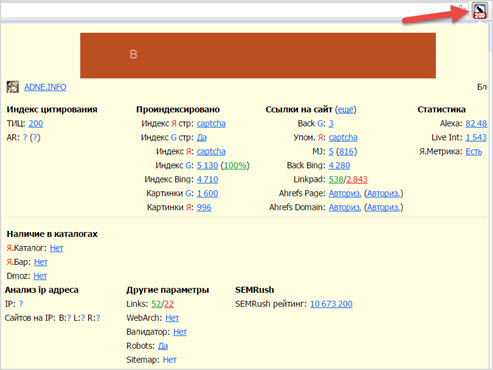
Размещённая в данном блоке информация используется оптимизаторами для контроля наполнения контентом главной страницы сайта, количества ссылок, фреймов, графических элементов, объёма теста, определения «тошноты» страницы.
Отчёт содержит анализ использования Flash-элементов, позволяет контролировать использование на сайте разметки (микроформатов и Doctype).
IFrame – это плавающие фреймы, которые находится внутри обычного документа, они позволяет загружать в область заданных размеров любые другие независимые документы.
Flash — это мультимедийная платформа компании для создания веб-приложений или мультимедийных презентаций. Широко используется для создания рекламных баннеров, анимации, игр, а также воспроизведения на веб-страницах видео- и аудиозаписей.
Микроформат — это способ семантической разметки сведений о разнообразных сущностях (событиях, организациях, людях, товарах и так далее) на веб-страницах с использованием стандартных элементов языка HTML (или XHTML).
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
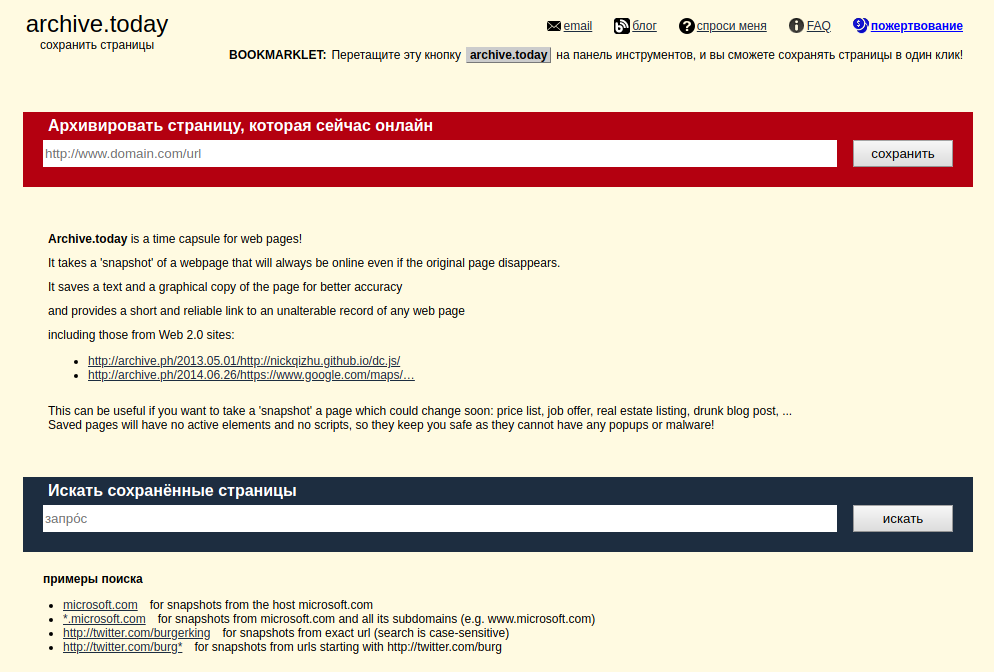
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Проекты[ | код]
Wayback Machine | код
Логотип Wayback Machine
The Wayback Machine — веб-сервис Архива. Содержание веб-страниц время от времени фиксируется c помощью бота или при ручном указании посетителем сайта адреса страницы для фиксации. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Легальность | код
На сервис не раз подавались судебные иски в связи с тем, что публикация контента может быть нелегальной. По этой причине сервис удаляет материалы из публичного доступа по требованию их правообладателей или, если доступ к страницам сайтов не разрешён в файле robots.txt владельцами этих сайтов.
Книга, изготовленная в течение 20 минут в рамках проекта Book-on-demand, на основе электронной книги из Архива
В 2002 году часть архивных копий веб-страниц, содержащих критику саентологии, была удалена из архива с пояснением, что это было сделано по «просьбе владельцев сайта». В дальнейшем выяснилось, что этого потребовали юристы Церкви саентологии, тогда как настоящие владельцы сайта не желали удаления своих материалов. Некоторые пользователи сочли это проявлением интернет-цензуры.
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к сайтам: как и сервис кэшированных копий страниц от поисковых систем, Архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование Архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам.
Open Library | код
Основная статья: Open Library
Книжный сканер Архива
Open Library — общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта, включая изображения и документы в формате PDF. Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Scan-on-demand — бесплатная оцифровка желаемых публикаций из фондов Бостонской общественной библиотеки, относится к проекту «Открытая библиотека».
Собрание фильмов, аудио, текстов и программного обеспечения, которые являются общественным достоянием или распространяются под лицензией Creative Commons.
r-tools.org

Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Переделка сайта
 Сегодня закончена очередная, небольшая переделка сайта для улучшения его показателей. Что-то сразу было сделано не так, что-то нужно сделать в связи с произошедшими изменениями в Интернете. Опыт показывает, периодические переделки сайтов вполне нормальное явление, хотя есть и минусы.
Сегодня закончена очередная, небольшая переделка сайта для улучшения его показателей. Что-то сразу было сделано не так, что-то нужно сделать в связи с произошедшими изменениями в Интернете. Опыт показывает, периодические переделки сайтов вполне нормальное явление, хотя есть и минусы.
Итак, мой блог был создан в начале 2013 года. Несмотря на наличие уроков, мной было допущено достаточно много различных ошибок, которые не позволяли блогу нормально развиваться. Приходилось учиться, вникать и понимать, какие вопросы должны быть обязательно сделаны. Кроме того в Интернете многое меняется и то, что работало еще год назад, сегодня может уже не работать. Теперь интересно сравнить новый и старый блог. Мы это обязательно сделаем, когда будем рассматривать вопрос, как посмотреть историю сайта.
В январе 2016 года, был полностью заменен шаблон моего блога, он был выполнен специалистами по дизайну и верстке. Старый шаблон поднадоел, да и был он серийным, не у меня одного был установлен такой шаблон. В процессе переделки блога, возникало много мелких вопросов, которые устранялись по ходу. В результате полученного опыта на блоге была опубликована статья «Как и где заказывать сайт». Думаю, статья многим помогла не наступать на грабли.
За прошедший год выявились небольшие недочеты, выявились резервы. По этой причине снова сделана его небольшая переделка. В футер перенесен виджет моей группы Вконтакте, дополнительно установлен виджет моей группы на Facebook, а также установлен виджет от Google+. Всё лишнее из футера удалено. Можете перейти в футер и посмотреть сами.
В последнее время были проблемы на хостинге из-за превышения нагрузки на CPU ядро. Естественно, нужно было решить часть вопросов. По рекомендации специалиста, который делал мне верстку блога и делал его переделку, установлен плагин WP Smush.
Плагин WP Smush ужимает все изображения, которые есть в статьях, это уменьшает время загрузки сайта. Оптимизирована и работа слайдера. Позже нужно будет с ним поработать еще. Убраны внешние ссылки, которые получались от привязки к JustClick. Любая переделка отрицательно влияет на позиции блога. В результате статьи, которые были в Топ 1-5, провалились и теперь они находятся на позициях 20-40. Сколько времени потребуется на их возврат в исходное состояние неизвестно. Вот такой получился краткий отчет о модернизации моего блога.
Если Вы тоже хотите сделать редизайн своего ресурса, блога, хотите сделать новый дизайн или оформить группу с оригинальным дизайном в соцсетях, могу рекомендовать Вам сайт Юлии — профессионала дизайнерского мастерства. Можно сделать, как обычный дизайн, строгий, графический, так и мультяшный.