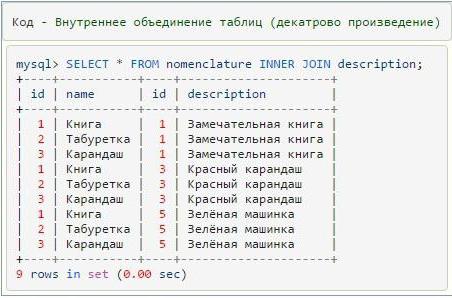
Как применять оператор sql union для объединения результатов запросов
Содержание:
- Set Operator
- UNION vs. UNION ALL Examples With Sort on Non-indexed Column
- Объединение множеств. UNION
- Пример — одиночное поле с тем же именем
- Часто задаваемые вопросы
- Пример — одиночное поле с тем же именем
- Пример с одним полем
- Outer Join
- Пример использования ORDER BY
- Example — Single Field With Same Name
- SQL References
- Example — Different Field Names
- Примеры
- How to use SQL Union with Group and Having clauses
- Rules to UNION data
- Пример — разные имена полей
- Execution plan difference in SQL Union vs Union All operator
Set Operator
Let’s get into the details of Set Operators in SQL Server, and how to use them
There are four basic Set Operators in SQL Server:
- Union
- Union All
- EXCEPT
- INTERSECT
Union
The Union operator combines the results of two or more queries into a distinct single result set that includes all the rows that belong to all queries in the Union. In this operation, it combines two more queries and removes the duplicates.
For example, the table ‘A’ has 1,2, and 3 and the table ‘B’ has 3,4,5.
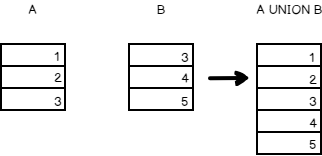
The SQL equivalent of the above data is given below
|
1 |
( SELECT1ID UNION SELECT2 UNION SELECT3 ) SELECT3 UNION SELECT4 UNION SELECT5 ); |
In the output, you can see a distinct list of the records from the two result sets
Union All
When looking at Union vs Union All we find they are quite similar, but they have some important differences from a performance results perspective.
The Union operator combines the results of two or more queries into a single result set that includes all the rows that belong to all queries in the Union. In simple terms, it combines the two or more row sets and keeps duplicates.
For example, the table ‘A’ has 1,2, and 3 and the table ‘B’ has 3,4,5.
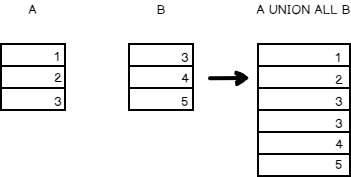
The SQL equivalent of the above data is given below
|
1 |
( SELECT1ID UNION SELECT2 UNION SELECT3 ) UNIONALL ( SELECT3 UNION SELECT4 UNION SELECT5 ); |
In the output, you can see all the rows that include repeating records as well.
INTERSECT
The interest operator keeps the rows that are common to all the queries
For the same dataset from the aforementioned example, the intersect operator output is given below
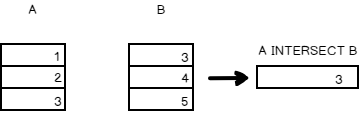
The SQL Representation of the above tables
|
1 |
( SELECT1ID UNION SELECT2 UNION SELECT3 ) SELECT3 UNION SELECT4 UNION SELECT5 ); |
The row ‘3’ is common between the two result sets.
EXCEPT
The EXCEPT operator lists the rows in the first that are not in the second.
For the same dataset from the aforementioned example, the Except operator output is given below
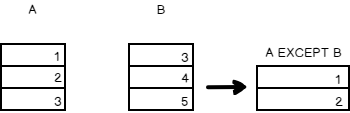
The SQL representation of the above tables with EXCEPT operator is given below
|
1 |
( SELECT1Non-CommonfromonlyA UNION SELECT2 UNION SELECT3 ) SELECT3B UNION SELECT4 UNION SELECT5 ); |
List the non-common rows from the first set.
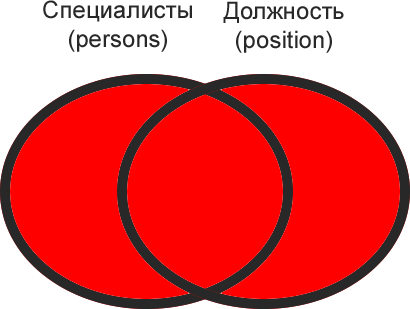
Note: It is very easy to visualize a set operator using a Venn diagram, where each of the tables is represented by intersecting shapes. The intersections of the shapes, where the tables overlap, are the rows where a condition is met.
UNION vs. UNION ALL Examples With Sort on Non-indexed Column
Here is another example doing the same thing, but this time doing a SORT on a
non indexed column. As you can see the execution plans are again identical for these
two queries, but this time instead of using a MERGE JOIN, a CONCATENATION and SORT
operations are used.
Next Steps
- Take a look at these other tips that may be useful for using the union operators
-
Comparing Multiple Datasets with the INTERSECT
and EXCEPT operators - SQL Server Four-part naming
-
Compare SQL Server Results of Two Queries using UNION
-
Comparing Multiple Datasets with the INTERSECT


About the author
Greg Robidoux is the President of Edgewood Solutions and a co-founder of MSSQLTips.com.
View all my tips
Related Resources
- SQL Server Join Example…
- Join SQL Server tables where columns include NULL …
- UNION vs. UNION ALL in SQL Server…
- Compare SQL Server Datasets with INTERSECT and EXC…
- SQL Server CROSS APPLY and OUTER APPLY…
- More Database Developer Tips…
Become a paid author
Объединение множеств. UNION
Последнее обновление: 24.03.2018
Оператор UNION позволяет объединить два множества (условно две таблицы). Но в отличие от inner/outer join
объединения соединяют не столбцы разных таблиц, а два однотипных набора в один. Формальный синтаксис объединения:
SELECT_выражение1 UNION SELECT_выражение2 SELECT_выражениеN]
Например, пусть в базе данных будут две отдельные таблицы для клиентов банка (таблица Customers) и для сотрудников банка (таблица Employees):
CREATE TABLE Customers
(
Id SERIAL PRIMARY KEY,
FirstName VARCHAR(20) NOT NULL,
LastName VARCHAR(20) NOT NULL,
AccountSum NUMERIC DEFAULT 0
);
CREATE TABLE Employees
(
Id SERIAL PRIMARY KEY,
FirstName VARCHAR(20) NOT NULL,
LastName VARCHAR(20) NOT NULL
);
INSERT INTO Customers(FirstName, LastName, AccountSum) VALUES
('Tom', 'Smith', 2000),
('Sam', 'Brown', 3000),
('Paul', 'Ins', 4200),
('Victor', 'Baya', 2800),
('Mark', 'Adams', 2500),
('Tim', 'Cook', 2800);
INSERT INTO Employees(FirstName, LastName) VALUES
('Homer', 'Simpson'),
('Tom', 'Smith'),
('Mark', 'Adams'),
('Nick', 'Svensson');
Здесь мы можем заметить, что обе таблицы, несмотря на наличие различных данных, могут характеризоваться двумя общими атрибутами —
именем (FirstName) и фамилией (LastName). Выберем сразу всех клиентов банка и его сотрудников из обеих таблиц:
SELECT FirstName, LastName FROM Customers UNION SELECT FirstName, LastName FROM Employees;
В данном случае из первой таблицы выбираются два значения — имя и фамилия клиента. Из второй таблицы Employees также
выбираются два значения — имя и фамилия сотрудников. То есть при объединении количество выбираемых столбцов и их тип
совпадают для обеих выборок.
Если оба объединяемых набора содержат в строках идентичные значения, то при объединении повторяющиеся строки удаляются.
В случае с таблицами Customers и Employees сотрудники банка могут быть одновременно его клиентами и содержаться в обеих таблицах.
При объединении в примерах выше всех дублирующиеся строки удалялись. Например, исходя из начальных данных, мы видим, что два человека: Tom Smith и Mark Adams располагаются в обеих таблицах. Однако при объединении дубли не считаются,
поэтому один человек учитывается только один раз.
Если же необходимо при объединении сохранить все, в том числе повторяющиеся строки, то для этого необходимо использовать оператор ALL:
SELECT FirstName, LastName FROM Customers UNION ALL SELECT FirstName, LastName FROM Employees;
При этом названия столбцов объединенной выборки будут совпадать с названия столбцов первой выборки. И если мы захотим при этом еще произвести сортировку,
то в выражениях ORDER BY необходимо ориентироваться именно на названия столбцов первой выборки:
SELECT FirstName || ' ' || LastName AS FullName FROM Customers UNION SELECT FirstName || ' ' || LastName AS EmployeeName FROM Employees ORDER BY FullName;
В данном случае каждая выборка имеет по одному столбцу, который представляет объединение имени и фамилии клиента или сотрудника.
Для объединения строк применяется оператор ||. Но в случае с клиентами столбец будет называться FullName, а в случае с
сотрудниками — EmployeeName. Тем не менее для сортировки применяется название столбца из первой выборки и он же будет в результирующей выборке:
Если же в одной выборке больше столбцов, чем в другой, то они не смогут быть объединены. Например, в следующем случае объединение завершится с ошибкой:
SELECT FirstName, LastName, AccountSum FROM Customers UNION SELECT FirstName, LastName FROM Employees;
Также соответствующие столбцы должны соответствовать по типу. Так, следующий пример завершится с ошибкой из-за не соответствия по типу данных:
SELECT FirstName, LastName FROM Customers UNION SELECT Id, LastName FROM Employees;
Здесь первый столбец первой выборки имеет тип CHARACTER VARYING, то есть хранит строку. Первый столбец второй выборки — Id имеет тип INTEGER, то есть
хранит число.
Объединять выборки можно и из одной и той же таблицы. Например, в зависимости от суммы на счете клиента нам надо начислять ему определенные проценты:
SELECT FirstName, LastName, AccountSum + AccountSum * 0.1 AS TotalSum FROM Customers WHERE AccountSum < 3000 UNION SELECT FirstName, LastName, AccountSum + AccountSum * 0.3 AS TotalSum FROM Customers WHERE AccountSum >= 3000
В данном случае если сумма меньше 3000, то начисляются проценты в размере 10% от суммы на счете. Если на счете больше 3000, то
проценты увеличиваются до 30%.
НазадВперед
Пример — одиночное поле с тем же именем
Давайте посмотрим, как использовать SQL оператор UNION ALL, который возвращает одно поле. В этом простом примере поле в обоих операторах SELECT будет иметь одинаковое имя и тип данных. Например.
PgSQL
SELECT supplier_id
FROM suppliers
UNION ALL
SELECT supplier_id
FROM orders
ORDER BY supplier_id;
|
1 2 3 4 5 6 |
SELECTsupplier_id FROMsuppliers UNIONALL SELECTsupplier_id FROMorders ORDERBYsupplier_id; |
Этот SQL пример UNION ALL будет возвращать supplier_id несколько раз в наборе результатов, если это же значение появилось в таблицах suppliers и orders. SQL оператор UNION ALL не удаляет дубликаты. Если вы хотите удалить дубликаты, попробуйте использовать оператор UNION. Теперь давайте рассмотрим этот пример, далее приведем некоторые данные. Если у вас была таблица suppliers, заполненная следующими записями.
| supplier_id | supplier_name |
|---|---|
| 1000 | Microsoft |
| 2000 | Oracle |
| 3000 | Apple |
| 4000 | Samsung |
И таблица orders заполнена следующими записями.
| order_id | order_date | supplier_id |
|---|---|---|
| 2019-07-01 | 2000 | |
| 2019-07-01 | 6000 | |
| 2019-07-02 | 7000 | |
| 2019-07-03 | 8000 |
И вы выполнили следующий оператор UNION ALL.
PgSQL
SELECT supplier_id
FROM suppliers
UNION ALL
SELECT supplier_id
FROM orders
ORDER BY supplier_id;
|
1 2 3 4 5 6 |
SELECTsupplier_id FROMsuppliers UNIONALL SELECTsupplier_id FROMorders ORDERBYsupplier_id; |
Вы получите следующие результаты.
| supplier_id |
|---|
| 1000 |
| 2000 |
| 2000 |
| 3000 |
| 4000 |
| 6000 |
| 7000 |
| 8000 |
Как видно из этого примера, UNION ALL взял все значения supplier_id из таблицы suppliers, а также из таблицы orders и возвратил комбинированный набор результатов. Дубликаты не были удалены, как вы можете видеть по значению supplier_id 2000, которое дважды появляется в наборе результатов.
Часто задаваемые вопросы
Вопрос: Мне нужно сравнить две даты и вернуть количество строк поля, основанного на значении дат. Например, у меня есть в таблице поле даты, которое называется дата последнего обновления. Я должен проверить, если TRUNC (last_updated_date)> = TRUNC (Sysdate-13).
Ответ: Поскольку вы используете функцию COUNT, которая является агрегатной функцией, то мы рекомендуем использовать Oracle оператор UNION. Например, вы можете попробовать следующее:
Oracle PL/SQL
SELECT a.code AS Code, a.name AS Name, COUNT(b.Ncode)
FROM cdmaster a, nmmaster b
WHERE a.code = b.code
AND a.status = 1
AND b.status = 1
AND b.Ncode <> ‘a10’
AND TRUNC(last_updated_date) <= TRUNC(sysdate-13)
GROUP BY a.code, a.name
UNION
SELECT a.code AS Code, a.name AS Name, COUNT(b.Ncode)
FROM cdmaster a, nmmaster b
WHERE a.code = b.code
AND a.status = 1
AND b.status = 1
AND b.Ncode <> ‘a10’
AND TRUNC(last_updated_date) > TRUNC(sysdate-13)
GROUP BY a.code, a.name;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECTa.codeASCode,a.nameASName,COUNT(b.Ncode) FROMcdmastera,nmmasterb WHEREa.code=b.code ANDa.status=1 ANDb.status=1 ANDb.Ncode<>’a10′ ANDTRUNC(last_updated_date)<=TRUNC(sysdate-13) GROUPBYa.code,a.name SELECTa.codeASCode,a.nameASName,COUNT(b.Ncode) FROMcdmastera,nmmasterb WHEREa.code=b.code ANDa.status=1 ANDb.status=1 ANDb.Ncode<>’a10′ ANDTRUNC(last_updated_date)>TRUNC(sysdate-13) GROUPBYa.code,a.name; |
Oracle оператор UNION позволит выполнить подсчет на основе одного набора критериев.
TRUNC(last_updated_date)
А также выполнить подсчет на основе другого набора критериев.
TRUNC(last_updated_date) > TRUNC(sysdate-13)
Пример — одиночное поле с тем же именем
Давайте посмотрим, как использовать SQL оператор UNION, который возвращает одно поле. В этом простом примере поле в обоих операторах SELECT будет иметь одинаковое имя и тип данных. Например.
PgSQL
SELECT supplier_id
FROM suppliers
UNION
SELECT supplier_id
FROM orders
ORDER BY supplier_id;
|
1 2 3 4 5 6 |
SELECTsupplier_id FROMsuppliers UNION SELECTsupplier_id FROMorders ORDERBYsupplier_id; |
В этом SQL примере оператора UNION, если supplier_id появилось в таблицах suppliers и orders, оно будет один раз в вашем наборе результатов. Оператор UNION удаляет дубликаты. Если вы не хотите удалить дубликаты, попробуйте использовать оператор UNION ALL. Теперь давайте рассмотрим этот пример, далее приведем некоторые данные. Если у вас была таблица suppliers, заполненная следующими записями.
| supplier_id | supplier_name |
|---|---|
| 1000 | Yandex |
| 2000 | |
| 3000 | Oracle |
| 4000 | Bing |
И таблица orders заполнена следующими записями.
| order_id | order_date | supplier_id |
|---|---|---|
| 2019-07-01 | 2000 | |
| 2019-07-01 | 6000 | |
| 2019-07-02 | 7000 | |
| 2019-07-03 | 8000 |
И вы выполнили следующий запрос UNION.
PgSQL
SELECT supplier_id
FROM suppliers
UNION
SELECT supplier_id
FROM orders
ORDER BY supplier_id;
|
1 2 3 4 5 6 |
SELECTsupplier_id FROMsuppliers UNION SELECTsupplier_id FROMorders ORDERBYsupplier_id; |
Вы получите следующие результаты.
| supplier_id |
|---|
| 1000 |
| 2000 |
| 3000 |
| 4000 |
| 6000 |
| 7000 |
| 8000 |
Как видно из этого примера, UNION взял все значения supplier_id из таблицы suppliers, а также из таблицы orders и возвратил комбинированный набор результатов. Поскольку оператор UNION удалил дубликаты между результирующими наборами, поле supplier_id 2000 отображается только один раз, даже если оно находится в таблицах suppliers и orders. Если вы не хотите удалять дубликаты, попробуйте вместо этого использовать оператор UNION ALL.
Пример с одним полем
Следующий пример Oracle оператора UNION, возвращает одно поле из двух запросов SELECT (и оба поля имеют один и тот же тип данных):
Oracle PL/SQL
SELECT supplier_id
FROM suppliers
UNION
SELECT supplier_id
FROM order_details;
|
1 2 3 4 5 |
SELECTsupplier_id FROMsuppliers SELECTsupplier_id FROMorder_details; |
В этом примере оператора UNION, если supplier_id присутствует в обоих таблицах suppliers и order_details, то supplier_id появляется один в наборе результатов. Оператор Oracle UNION удаляет дубликаты. Если вы не хотите, чтобы дубликаты были удалены, попробуйте использовать Oracle оператора UNION ALL.
Outer Join
Последнее обновление: 22.05.2018
В предыдущей теме рассматривля Inner Join или внутреннее соединение таблиц. Но также в MySQL мы можем использовать и так называемое
внешнее соединение или Outer Join. В отличие от Inner Join внешнее соединение возвращает все строки одной или двух таблиц, которые участвуют в
соединении.
Outer Join имеет следующий формальный синтаксис:
SELECT столбцы
FROM таблица1
{LEFT|RIGHT} JOIN таблица2 ON условие1
JOIN таблица3 ON условие2]...
Перед оператором JOIN указывается одно из ключевых слов LEFT или
RIGHT, которые определяют тип соединения:
-
LEFT: выборка будет содержать все строки из первой или левой таблицы
-
RIGHT: выборка будет содержать все строки из второй или правой таблицы
Также перед оператором JOIN может указываться ключевое слово OUTER, но его применение необязательно.
Далее после JOIN указывается присоединяемая таблица, а затем идет условие соединения.
Например, соединим таблицы Orders и Customers:
SELECT FirstName, CreatedAt, ProductCount, Price, ProductId FROM Orders LEFT JOIN Customers ON Orders.CustomerId = Customers.Id
Таблица Orders является первой или левой таблицей, а таблица Customers — правой таблицей. Поэтому, так как здесь используется
выборка по левой таблице, то вначале будут выбираться все строки из Orders, а затем к ним по условию будут
добавляться связанные строки из Customers.
По вышеприведенному результату может показаться, что левостороннее соединение аналогично INNER Join, но это не так.
Inner Join объединяет строки из дух таблиц при соответствии условию. Если одна из таблиц содержит строки, которые не соответствуют этому условию, то данные строки
не включаются в выходную выборку. Left Join выбирает все строки первой таблицы и затем присоединяет к ним строки правой таблицы. К примеру, возьмем таблицу Customers и добавим к покупателям информацию об их заказах:
#INNER JOIN SELECT FirstName, CreatedAt, ProductCount, Price FROM Customers JOIN Orders ON Orders.CustomerId = Customers.Id; #LEFT JOIN SELECT FirstName, CreatedAt, ProductCount, Price FROM Customers LEFT JOIN Orders ON Orders.CustomerId = Customers.Id;
В случае с LEFT JOIN MySQL выбирает сначала всех покупателей из таблицы Customers, затем сопоставляет их с заказами из таблицы Orders через
условие . Однако не у всех покупателей есть заказы. В этом случае покупателю для соответствующих столбцов
устанавливаются значения NULL.
Изменим в примере выше тип соединения для OUTER JOIN с левостороннего на правостороннее:
SELECT FirstName, CreatedAt, ProductCount, Price FROM Customers RIGHT JOIN Orders ON Orders.CustomerId = Customers.Id;
Теперь будут выбираться все строки из Orders (из правой таблицы), а к ним уже будет присоединяться связанные по условию строки из таблицы Customers:
Используем левостороннее соединение для добавления к заказам информации о пользователях и товарах:
SELECT Customers.FirstName, Orders.CreatedAt,
Products.ProductName, Products.Manufacturer
FROM Orders
LEFT JOIN Customers ON Orders.CustomerId = Customers.Id
LEFT JOIN Products ON Orders.ProductId = Products.Id;
И также можно применять более комплексные условия с фильтрацией и сортировкой. Например, выберем все заказы с информацией о клиентах и товарах по тем товарам,
у которых цена меньше 45000, и отсортируем по дате заказа:
SELECT Customers.FirstName, Orders.CreatedAt,
Products.ProductName, Products.Manufacturer
FROM Orders
LEFT JOIN Customers ON Orders.CustomerId = Customers.Id
LEFT JOIN Products ON Orders.ProductId = Products.Id
WHERE Products.Price > 45000
ORDER BY Orders.CreatedAt;
Или выберем всех пользователей из Customers, у которых нет заказов в таблице Orders:
SELECT FirstName FROM Customers LEFT JOIN Orders ON Customers.Id = Orders.CustomerId WHERE Orders.CustomerId IS NULL;
Также можно комбинировать Inner Join и Outer Join:
SELECT Customers.FirstName, Orders.CreatedAt,
Products.ProductName, Products.Manufacturer
FROM Orders
JOIN Products ON Orders.ProductId = Products.Id AND Products.Price > 45000
LEFT JOIN Customers ON Orders.CustomerId = Customers.Id
ORDER BY Orders.CreatedAt;
Вначале по условию к таблице Orders через Inner Join присоединяется связанная информация из Products, затем через Outer Join
добавляется информация из таблицы Customers.
НазадВперед
Пример использования ORDER BY
Oracle оператор UNION может использовать оператор ORDER BY, чтобы упорядочить результаты запроса.
Например:
Oracle PL/SQL
SELECT supplier_id, supplier_name
FROM suppliers
WHERE supplier_id <= 500
UNION
SELECT company_id, company_name
FROM companies
WHERE company_name = ‘Apple’
ORDER BY 2;
|
1 2 3 4 5 6 7 8 |
SELECTsupplier_id,supplier_name FROMsuppliers WHEREsupplier_id<=500 SELECTcompany_id,company_name FROMcompanies WHEREcompany_name=’Apple’ ORDERBY2; |
В этом примере UNION, так как имена столбцов в двух запросах SELECT отличаются, то в ORDER BY выгоднее ссылаться на положение столбцов в результирующем наборе. В этом примере, мы отсортировали результаты по supplier_name / company_name в порядке возрастания, как это обозначено в ORDER BY 2.
Поля supplier_name / company_name находятся в позиции # 2 в результирующем наборе.
Example — Single Field With Same Name
Let’s look at how to use the SQL UNION operator that returns one field. In this simple example, the field in both SELECT statements will have the same name and data type.
For example:
SELECT supplier_id FROM suppliers UNION SELECT supplier_id FROM orders ORDER BY supplier_id;
In this SQL UNION operator example, if a supplier_id appeared in both the suppliers and orders table, it would appear once in your result set. The UNION operator removes duplicates. If you do not wish to remove duplicates, try using the UNION ALL operator.
Now, let’s explore this example further will some data.
If you had the suppliers table populated with the following records:
| supplier_id | supplier_name |
|---|---|
| 1000 | Microsoft |
| 2000 | Oracle |
| 3000 | Apple |
| 4000 | Samsung |
And the orders table populated with the following records:
| order_id | order_date | supplier_id |
|---|---|---|
| 1 | 2015-08-01 | 2000 |
| 2 | 2015-08-01 | 6000 |
| 3 | 2015-08-02 | 7000 |
| 4 | 2015-08-03 | 8000 |
And you executed the following UNION statement:
SELECT supplier_id FROM suppliers UNION SELECT supplier_id FROM orders ORDER BY supplier_id;
You would get the following results:
| supplier_id |
|---|
| 1000 |
| 2000 |
| 3000 |
| 4000 |
| 6000 |
| 7000 |
| 8000 |
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL Quick Ref
Example — Different Field Names
It is not necessary that the corresponding columns in each SELECT statement have the same name, but they do need to be the same corresponding data types.
When you don’t have the same column names between the SELECT statements, it gets a bit tricky, especially when you want to order the results of the query using the ORDER BY clause.
Let’s look at how to use the UNION operator with different column names and order the query results.
For example:
SELECT supplier_id, supplier_name FROM suppliers WHERE supplier_id > 2000 UNION SELECT company_id, company_name FROM companies WHERE company_id > 1000 ORDER BY 1;
In this SQL UNION example, since the column names are different between the two SELECT statements, it is more advantageous to reference the columns in the ORDER BY clause by their position in the result set. In this example, we’ve sorted the results by supplier_id / company_id in ascending order, as denoted by the . The supplier_id / company_id fields are in position #1 in the result set.
Now, let’s explore this example further with data.
If you had the suppliers table populated with the following records:
| supplier_id | supplier_name |
|---|---|
| 1000 | Microsoft |
| 2000 | Oracle |
| 3000 | Apple |
| 4000 | Samsung |
And the companies table populated with the following records:
| company_id | company_name |
|---|---|
| 1000 | Microsoft |
| 3000 | Apple |
| 7000 | Sony |
| 8000 | IBM |
And you executed the following UNION statement:
SELECT supplier_id, supplier_name FROM suppliers WHERE supplier_id > 2000 UNION SELECT company_id, company_name FROM companies WHERE company_id > 1000 ORDER BY 1;
You would get the following results:
| supplier_id | supplier_name |
|---|---|
| 3000 | Apple |
| 4000 | Samsung |
| 7000 | Sony |
| 8000 | IBM |
First, notice that the record with supplier_id of 3000 only appears once in the result set because the UNION query removed duplicate entries.
Second, notice that the column headings in the result set are called supplier_id and supplier_name. This is because these were the column names used in the first SELECT statement in the UNION.
If you had wanted to, you could have aliased the columns as follows:
SELECT supplier_id AS ID_Value, supplier_name AS Name_Value FROM suppliers WHERE supplier_id > 2000 UNION SELECT company_id AS ID_Value, company_name AS Name_Value FROM companies WHERE company_id > 1000 ORDER BY 1;
Now the column headings in the result will be aliased as ID_Value for the first column and Name_Value for the second column.
Примеры
Использование UNION при выборке из двух таблиц
Даны две таблицы:
| person | amount |
|---|---|
| Иван | 1000 |
| Алексей | 2000 |
| Сергей | 5000 |
| person | amount |
|---|---|
| Иван | 2000 |
| Алексей | 2000 |
| Петр | 35000 |
При выполнении следующего запроса:
(SELECT * FROM sales2005) UNION (SELECT * FROM sales2006);
получается результирующий набор, однако порядок строк может произвольно меняться, поскольку ключевое выражение не было использовано:
| person | amount |
|---|---|
| Иван | 1000 |
| Алексей | 2000 |
| Иван | 2000 |
| Сергей | 5000 |
| Петр | 35000 |
В результате отобразятся две строки с Иваном, так как эти строки различаются значениями в столбцах. Но при этом в результате присутствует лишь одна строка с Алексеем, поскольку значения в столбцах полностью совпадают.
Использование UNION ALL при выборке из двух таблиц
Применение дает другой результат, так как дубликаты не скрываются. Выполнение запроса:
(SELECT * FROM sales2005) UNION ALL (SELECT * FROM sales2006);
даст следующий результат, выводимый без упорядочивания ввиду отсутствия выражения :
| person | amount |
|---|---|
| Иван | 1000 |
| Иван | 2000 |
| Алексей | 2000 |
| Алексей | 2000 |
| Сергей | 5000 |
| Петр | 35000 |
Использование UNION при выборке из одной таблицы
Аналогичным образом можно объединять два разных запроса из одной и той же таблицы (хотя вместо этого, как правило, необходимые параметры комбинируют в одном запросе при помощи ключевых слов AND и OR в условии WHERE):
(SELECT person, amount FROM sales2005 WHERE amount=1000) UNION (SELECT person, amount FROM sales2005 WHERE person like 'Сергей');
В результате получится:
| person | amount |
|---|---|
| Иван | 1000 |
| Сергей | 5000 |
Использование UNION как внешнее объединение
При помощи можно создавать также (иногда используется в случае отсутствия встроенной прямой поддержки внешних объединений):
(SELECT *
FROM employee
LEFT JOIN department
ON employee.DepartmentID = department.DepartmentID)
UNION
(SELECT *
FROM employee
RIGHT JOIN department
ON employee.DepartmentID = department.DepartmentID);
Но при этом необходимо помнить, что это все же не одно и то же, что и оператор .
How to use SQL Union with Group and Having clauses
The following examples use the Union operator to combine the result of the table that all have the conditional clause defined using Group by and Having clause.
The lastname is parsed by specifying the conditions in the having clause.
The following example is based on rule 5.
|
1 |
SELECTpp.lastname, COUNT(*)repeatedtwice, Repeatedthrice FROMPerson.PersonASpp JOINHumanResources.EmployeeASeONe.BusinessEntityID=pp.BusinessEntityID GROUPBYpp.lastname HAVINGCOUNT(*)=2 UNION SELECTpp.LastName, , COUNT(*)NtoZRange FROMPerson.PersonASpp JOINHumanResources.EmployeeASeONe.BusinessEntityID=pp.BusinessEntityID GROUPBYpp.LastName HAVINGCOUNT(*)>2; |
We can see that the last names are derived into two different columns using the Union operator
That’s all for now…
Rules to UNION data
- Each query must have the same number of columns
- Each column must have compatible data types
- Column names for the final result set are taken from the first query
- ORDER BY and COMPUTE clauses can only be issued for the overall result set
and not within each individual result set - GROUP BY and HAVING clauses can only be issued for each individual result
set and not for the overall result set
Tip: If you don’t have the exact same columns in all queries use a default value or a NULL value such as:
SELECT firstName, lastName, company FROM businessContacts UNION SELECT firstName, lastName, NULL FROM nonBusinessContacts or SELECT firstName, lastName, createDate FROM businessContacts UNION ALL SELECT firstName, lastName, getdate() FROM nonBusinessContacts
Пример — разные имена полей
Нет необходимости, чтобы соответствующие столбцы в каждом операторе SELECT имели одинаковые имена, но они должны быть с одинаковыми, соответствующими типами данных. Если у вас нет одинаковых имен столбцов между операторами SELECT, это становится немного сложнее, особенно если вы хотите упорядочить результаты запроса, используя оператор ORDER BY. Давайте посмотрим, как использовать оператор UNION с разными именами столбцов и упорядочиванием результатов запроса. Например.
PgSQL
SELECT supplier_id,
supplier_name
FROM suppliers
WHERE supplier_id > 2000
UNION
SELECT company_id,
company_name
FROM companies
WHERE company_id > 1000
ORDER BY 1;
|
1 2 3 4 5 6 7 8 9 10 |
SELECTsupplier_id, supplier_name FROMsuppliers WHEREsupplier_id>2000 UNION SELECTcompany_id, company_name FROMcompanies WHEREcompany_id>1000 ORDERBY1; |
В этом SQL примере UNION, поскольку имена столбцов в двух операторах SELECT различаются, более выгодно ссылаться на столбцы в ORDER BY по их положению в наборе результатов. В этом примере мы отсортировали результаты по supplier_id / company_id в порядке возрастания, как обозначено . Поля supplier_id / company_id находятся в позиции № 1 в наборе результатов.
Теперь давайте рассмотрим этот пример подробнее с данными. Если у вас была таблица suppliers, заполненная следующими записями.
| supplier_id | supplier_name |
|---|---|
| 1000 | Microsoft |
| 2000 | Oracle |
| 3000 | Apple |
| 4000 | Samsung |
И таблица companies заполнилась следующими записями.
| company_id | company_name |
|---|---|
| 1000 | Microsoft |
| 3000 | Apple |
| 7000 | Sony |
| 8000 | IBM |
И вы выполнили следующий оператор UNION.
PgSQL
SELECT supplier_id,
supplier_name
FROM suppliers
WHERE supplier_id > 2000
UNION
SELECT company_id, company_name
FROM companies
WHERE company_id > 1000
ORDER BY 1;
|
1 2 3 4 5 6 7 8 9 |
SELECTsupplier_id, supplier_name FROMsuppliers WHEREsupplier_id>2000 UNION SELECTcompany_id,company_name FROMcompanies WHEREcompany_id>1000 ORDERBY1; |
Вы получите следующие результаты.
| supplier_id | supplier_name |
|---|---|
| 3000 | Apple |
| 4000 | Samsung |
| 7000 | Sony |
| 8000 | IBM |
Во-первых, обратите внимание, что запись с supplier_id, равной 3000, появляется только один раз в наборе результатов, поскольку запрос UNION удалил повторяющиеся записи. Во-вторых, обратите внимание, что заголовки столбцов в наборе результатов называются supplier_id и supplier_name
Это потому, что это были имена столбцов, использованных в первом операторе SELECT в UNION. Если бы вы хотели, вы могли бы присвоить псевдонимы столбцам следующим образом.
PgSQL
SELECT supplier_id AS ID_Value,
supplier_name AS Name_Value
FROM suppliers
WHERE supplier_id > 2000
UNION
SELECT company_id AS ID_Value,
company_name AS Name_Value
FROM companies
WHERE company_id > 1000
ORDER BY 1;
|
1 2 3 4 5 6 7 8 9 10 |
SELECTsupplier_idASID_Value, supplier_nameASName_Value FROMsuppliers WHEREsupplier_id>2000 UNION SELECTcompany_idASID_Value, company_nameASName_Value FROMcompanies WHEREcompany_id>1000 ORDERBY1; |
Теперь заголовки столбцов в результате будут иметь псевдоним как ID_Value для первого столбца и Name_Value для второго столбца.
| ID_Value | Name_Value |
|---|---|
| 3000 | Apple |
| 4000 | Samsung |
| 7000 | Sony |
| 8000 | IBM |
Execution plan difference in SQL Union vs Union All operator
We get better query performance once we combine the result set of Select statement with SQL Union All operator. We can look at the difference using execution plans in SQL Server.
Note: In this article, I am using ApexSQL Plan, a SQL query execution plan viewer to generate an execution plan of Select statements.
The execution plan for the SQL Union Operator
We can click on Sort operator, and it shows Distinct – True.
- It gets the data individual Select statement
- SQL Server does a Concatenation for all of the data returned by Select statements
- It performs a distinct operator to remove duplicate rows
The execution plan for SQL Union All operator
In the execution plan of both SQL Union vs Union All, we can see the following difference.
- SQL Union contains a Sort operator having cost 53.7% in overall batch operators
- Sort operator could be more expensive if we work with large data sets