Параллельные потоки в python
Содержание:
Usage
ThreadPooled
Mostly it is required decorator: submit function to ThreadPoolExecutor on call.
Note
API quite differs between Python 3 and Python 2.7. See API section below.
threaded.ThreadPooled.configure(max_workers=3)
Note
By default, if executor is not configured — it configures with default parameters: max_workers=CPU_COUNT * 5
@threaded.ThreadPooled
def func():
pass
concurrent.futures.wait()
Python 3.5+ usage with asyncio:
Note
if loop_getter is not callable, loop_getter_need_context is ignored.
loop = asyncio.get_event_loop()
@threaded.ThreadPooled(loop_getter=loop, loop_getter_need_context=False)
def func():
pass
loop.run_until_complete(asyncio.wait_for(func(), timeout))
Python 3.5+ usage with asyncio and loop extraction from call arguments:
loop_getter = lambda tgt_loop tgt_loop
@threaded.ThreadPooled(loop_getter=loop_getter, loop_getter_need_context=True) # loop_getter_need_context is required
def func(*args, **kwargs):
pass
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait_for(func(loop), timeout))
During application shutdown, pool can be stopped (while it will be recreated automatically, if some component will request).
threaded.ThreadPooled.shutdown()
Threaded
Classic threading.Thread. Useful for running until close and self-closing threads without return.
Usage example:
@threaded.Threaded
def func(*args, **kwargs):
pass
thread = func()
thread.start()
thread.join()
Without arguments, thread name will use pattern: 'Threaded: ' + func.__name__
Note
If func.__name__ is not accessible, str(hash(func)) will be used instead.
Override name can be don via corresponding argument:
@threaded.Threaded(name='Function in thread')
def func(*args, **kwargs):
pass
Thread can be daemonized automatically:
@threaded.Threaded(daemon=True)
def func(*args, **kwargs):
pass
Also, if no any addition manipulations expected before thread start,
it can be started automatically before return:
@threaded.Threaded(started=True)
def func(*args, **kwargs):
pass
Проблемы, которые создает многопоточность
Deadlock
- Поток-1 перестанет работать с Объектом-1 и переключится на Объект-2, как только Поток-2 перестанет работать с Объектом 2 и переключится на Объект-1.
- Поток-2 перестанет работать с Объектом-2 и переключится на Объект-1, как только Поток-1 перестанет работать с Объектом 1 и переключится на Объект-2.
Потоки никогда не поменяются местами и будут ждать друг друга вечно. deadlock
Поток-0 достает яйца из холодильника.
Поток-1 включает плиту.
Поток-2 достает сковородку и ставит на плиту.
Поток-3 зажигает огонь на плите.
Поток-4 выливает на сковороду масла.
Поток-5 разбивает яйца и выливает их на сковороду.
Поток-6 выбрасывает скорлупу в мусорное ведро.
Поток-7 снимает готовую яичницу с огня.
Поток-8 выкладывает яичницу в тарелку.
Поток-9 моет посуду.Выполнен поток Thread-0
Выполнен поток Thread-2
Выполнен поток Thread-1
Выполнен поток Thread-4
Выполнен поток Thread-9
Выполнен поток Thread-5
Выполнен поток Thread-8
Выполнен поток Thread-7
Выполнен поток Thread-3
Выполнен поток Thread-6
Классификация потоков по уровню реализации
-
Реализация потоков на уровне ядра. Проще говоря, это классическая 1:1 модель. Под эту категорию подпадают:
- Потоки Win32.
- Реализация Posix Threads в Linux — Native Posix Threads Library (NPTL). Дело в том, что до версии ядра 2.6 pthreads в Linux был целиком и полностью реализован в режиме пользователя (LinuxThreads). LinuxThreads реализовывалf модель 1:1 следующим образом: при создании нового потока, библиотека осуществляла системный вызов clone, и создавало новый процесс, который тем не менее разделял единое адресное пространство с родительским. Это породило множество проблем, к примеру потоки имели разные идентификаторы процесса, что противоречило некоторым аспектам стандарта Posix, которые касаются планировщика, сигналов, примитивов синхронизации. Также модель вытеснения потоков, работала во многих случаях с ошибками, по этому поддержку pthread решено было положить на плечи ядра. Сразу две разработки велись в данном направлении компаниями IBM и Red Hat. Однако, реализация IBM не снискала должной популярности, и не была включена ни в один из дистрибутивов, потому IBM приостановила дальнейшую разработку и поддержку библиотеки (NGPT). Позднее NPTL вошли в библиотеку glibc.
- Легковесные ядерны потоки (Leight Weight Kernel Threads — LWKT), например в DragonFlyBSD. Отличие этих потоков, от других потоков режима ядра в том, что легковесные ядерные потоки могут вытеснять другие ядерные потоки. В DragonFlyBSD существует множество ядерных потоков, например поток обслуживания аппаратных прерываний, поток обслуживания программных прерываний и т.д. Все они работают с фиксированным приоритетом, так вот LWKT могут вытеснять эти потоки (preempt). Конечно это уже более специфические вещи, про которые можно говорить бесконечно, но приведу еще два примера. В Windows все потоки ядра выполняются либо в контексте потока инициировавшего системный вызов/IO операцию, либо в контексте потока системного процесса system. В Mac OS X существует еще более интересная система. В ядре есть лишь понятие task, т.е. задачи. Все операции ядра выполняются в контексте kernel_task. Обработка аппаратного прерывания, к примеру, происходит в контексте потока драйвера, который обслуживает данное прерывание.
-
Реализация потоков в пользовательском режиме. Так как, системный вызов и смена контекста — достаточно тяжелые операции, идея реализовать поддержку потоков в режиме пользователя витает в воздухе давно. Множество попыток было сделано, однако данная методика популярности не обрела:
- GNU Portable Threads — реализация Posix Threads в пользовательском режиме. Основное преимущество — высокая портабельность данной библиотеки, проще говоря она может быть легко перенесена на другие ОС. Проблему вытиснения потоков в данной библиотеке решили очень просто — потоки в ней не вытесняются 🙂 Ну и конечно ни о какой мультмпроцессорности речь идти не может. Данная библиотека реализует модель N:1.
- Carbon Threads, которые я упоминал уже не раз, и RealBasic Threads.
- Гибридная реализация. Попытка использовать все преимущества первого и второго подхода, но как правило подобные мутанты обладают гораздо бОльшими недостатками, нежели достоинствами. Один из примеров: реализация Posix Threads в NetBSD по модели N:M, которая была посже заменена на систему 1:1. Более подробно вы можете прочесть в публикации Scheduler Activations: Effective Kernel Support for the User-Level Management of Parallelism.
Starting a New Thread
To spawn another thread, you need to call the following method available in the thread module −
_thread.start_new_thread ( function, args )
This method call enables a fast and efficient way to create new threads in both Linux and Windows.
The method call returns immediately and the child thread starts and calls function with the passed list of args. When the function returns, the thread terminates.
Here, args is a tuple of arguments; use an empty tuple to call function without passing any arguments. kwargs is an optional dictionary of keyword arguments.
Example
#!/usr/bin/python3
import _thread
import time
# Define a function for the thread
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# Create two threads as follows
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: unable to start thread")
while 1:
pass
Output
When the above code is executed, it produces the following result −
Thread-1: Fri Feb 19 09:41:39 2016 Thread-2: Fri Feb 19 09:41:41 2016 Thread-1: Fri Feb 19 09:41:41 2016 Thread-1: Fri Feb 19 09:41:43 2016 Thread-2: Fri Feb 19 09:41:45 2016 Thread-1: Fri Feb 19 09:41:45 2016 Thread-1: Fri Feb 19 09:41:47 2016 Thread-2: Fri Feb 19 09:41:49 2016 Thread-2: Fri Feb 19 09:41:53 2016
Program goes in an infinite loop. You will have to press ctrl-c to stop
Although it is very effective for low-level threading, the thread module is very limited compared to the newer threading module.
Semaphore Objects¶
This is one of the oldest synchronization primitives in the history of computer
science, invented by the early Dutch computer scientist Edsger W. Dijkstra (he
used the names and instead of and
).
A semaphore manages an internal counter which is decremented by each
call and incremented by each
call. The counter can never go below zero; when
finds that it is zero, it blocks, waiting until some other thread calls
.
Semaphores also support the .
- class (value=1)
-
This class implements semaphore objects. A semaphore manages an atomic
counter representing the number of calls minus the number of
calls, plus an initial value. The method
blocks if necessary until it can return without making the counter negative.
If not given, value defaults to 1.The optional argument gives the initial value for the internal counter; it
defaults to . If the value given is less than 0, is
raised.Changed in version 3.3: changed from a factory function to a class.
- (blocking=True, timeout=None)
-
Acquire a semaphore.
When invoked without arguments:
-
If the internal counter is larger than zero on entry, decrement it by
one and return immediately. -
If the internal counter is zero on entry, block until awoken by a call to
. Once awoken (and the counter is greater
than 0), decrement the counter by 1 and return . Exactly one
thread will be awoken by each call to . The
order in which threads are awoken should not be relied on.
When invoked with blocking set to false, do not block. If a call
without an argument would block, return immediately; otherwise, do
the same thing as when called without arguments, and return .When invoked with a timeout other than , it will block for at
most timeout seconds. If acquire does not complete successfully in
that interval, return . Return otherwise.Changed in version 3.2: The timeout parameter is new.
-
- ()
-
Release a semaphore, incrementing the internal counter by one. When it
was zero on entry and another thread is waiting for it to become larger
than zero again, wake up that thread.
- class (value=1)
-
Class implementing bounded semaphore objects. A bounded semaphore checks to
make sure its current value doesn’t exceed its initial value. If it does,
is raised. In most situations semaphores are used to guard
resources with limited capacity. If the semaphore is released too many times
it’s a sign of a bug. If not given, value defaults to 1.Changed in version 3.3: changed from a factory function to a class.
Класс Thread
В Java функциональность отдельного потока заключается в классе Thread. И чтобы создать новый поток, нам надо создать
объект этого класса. Но все потоки не создаются сами по себе. Когда запускается программа, начинает работать главный поток этой программы.
От этого главного потока порождаются все остальные дочерние потоки.
С помощью статического метода Thread.currentThread() мы можем получить текущий поток выполнения:
public static void main(String[] args) { Thread t = Thread.currentThread(); // получаем главный поток System.out.println(t.getName()); // main }
По умолчанию именем главного потока будет .
Для управления потоком класс Thread предоставляет еще ряд методов. Наиболее используемые из них:
-
getName(): возвращает имя потока
-
setName(String name): устанавливает имя потока
-
getPriority(): возвращает приоритет потока
-
setPriority(int proirity): устанавливает приоритет потока. Приоритет является одним из ключевых факторов для выбора
системой потока из кучи потоков для выполнения. В этот метод в качестве параметра передается числовое значение приоритета — от 1 до 10.
По умолчанию главному потоку выставляется средний приоритет — 5. -
isAlive(): возвращает true, если поток активен
-
isInterrupted(): возвращает true, если поток был прерван
-
join(): ожидает завершение потока
-
run(): определяет точку входа в поток
-
sleep(): приостанавливает поток на заданное количество миллисекунд
-
start(): запускает поток, вызывая его метод
Мы можем вывести всю информацию о потоке:
public static void main(String[] args) {
Thread t = Thread.currentThread(); // получаем главный поток
System.out.println(t); // main
}
Консольный вывод:
Thread
Первое будет представлять имя потока (что можно получить через ), второе значение 5 предоставляет приоритет
потока (также можно получить через ), и последнее представляет имя группы потоков, к которому относится текущий — по умолчанию также main
(также можно получить через )
Недостатки при использовании потоков
Далее мы рассмотрим, как создавать и использовать потоки. Это довольно легко. Однако при создании многопоточного приложения нам следует учитывать ряд обстоятельств,
которые негативно могут сказаться на работе приложения.
На некоторых платформах запуск новых потоков может замедлить работу приложения. Что может иметь большое значение, если нам критичная производительность
приложения.
Для каждого потока создается свой собственный стек в памяти, куда помещаются все локальные переменные и ряд других данных, связанных с выполнением
потока. Соответственно, чем больше потоков создается, тем больше памяти используется. При этом надо помнить, в любой системе размеры используемой памяти ограничены.
Кроме того, во многих системах может быть ограничение на количество потоков. Но даже если такого ограничения нет, то в любом случае
имеется естественное ограничение в виде максимальной скорости процессора.
НазадВперед
Python Threading Tutorial Theory
Before we can dive into parallelism, we should cover some theory. In fact, this section will explain why you need parallelism. After that, it will cover the basic jargon you need to know.
Why do we need parallelism?
Parallelism is a simple concept. It means that your program runs some of its parts at the same time. They might be different parts or even multiple instances of the same part. However, each is running independently from the other.
This, of course, adds a little bit of complexity, so why would we do that? Couldn’t we just use a monolithic program that does everything in sequence? We could, but the performance will be far lower. In fact, parallelism has two main benefits.
- Horizontal scalability: you can distribute tasks among cores on your PC, or even among different computers. This means you can access more power, and you can have more just by adding computers in the cluster. This is the opposite of vertical scalability, where you need to upgrade the hardware of the same computer.
- Efficiency: imagine that parts of your script need to wait for something, but some parts do not. You can have only the parts that really need to wait do the waiting, while the others move forward.
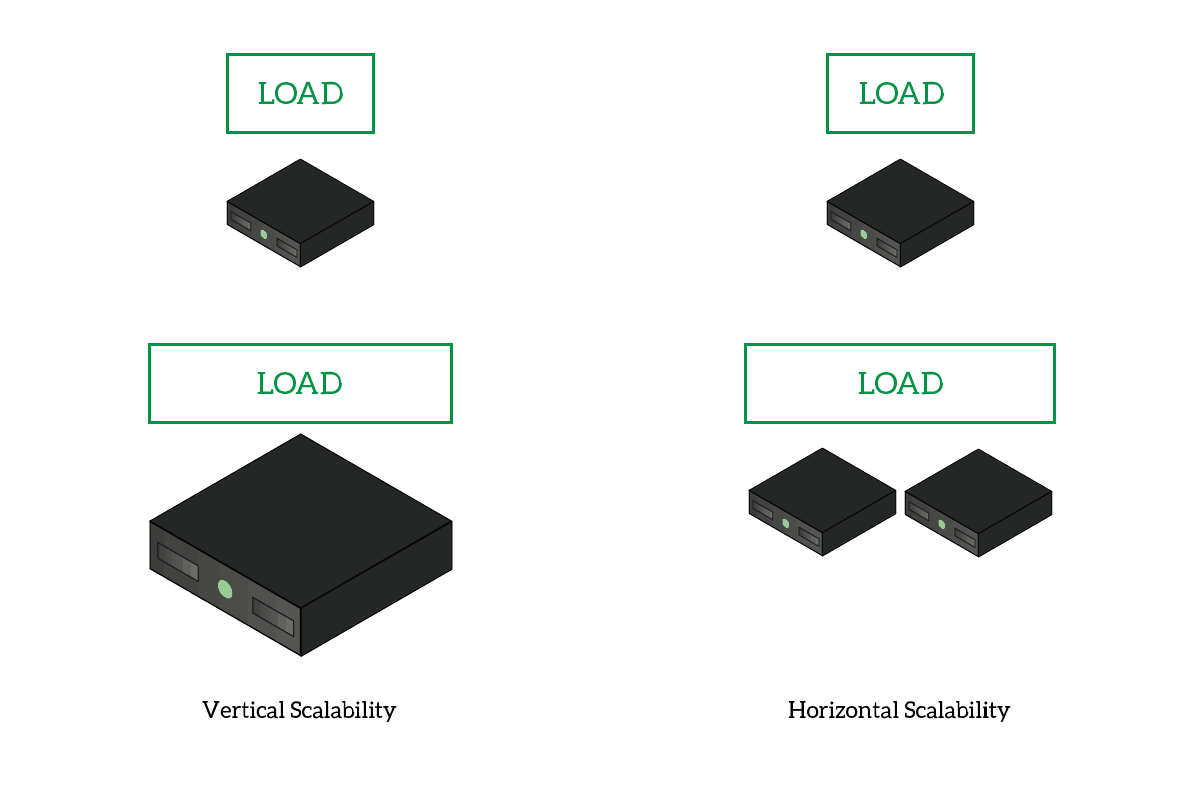 With vertical scalability, you need to enhance the power of your PC. With horizontal scalability, you can add more PCs.
With vertical scalability, you need to enhance the power of your PC. With horizontal scalability, you can add more PCs.
We have different ways of implementing parallelism in Python. Since this is a python threading tutorial, we are going to cover multithreading. However, you should know that other options exist.
Multithreading and Multiprocessing
When it comes to parallelism, we have two main ways to go: multithreading and multiprocessing. The two can achieve similar results in two different ways.
A process is a program running on a computer. The operating system will dedicate some RAM to that process, and allocate some meta-information that it needs to work with that process. You can literally see this as a whole program in execution. Instead, a thread is somehow a lightweight version of a process. It is not a program in execution, but part of it. It is part of a process and shares the memory with other threads in the same process. On top of that, the operating system doesn’t have to allocate the meta-information for the thread.
For a simple task, like running a function, working with multiple threads is the best way to go. In fact, this python threading tutorial will cover how to achieve parallelism with threads. You could apply the same concepts to multiprocessing as well.
Multithreading Jargon
This section of this python threading tutorial is important. If you get the jargon right, understanding the whole article will be a lot easier. Despite being a complex topic, the jargon of python threading is not complex at all.
Sync and Async
 With an async thread, some instructions may be executed concurrently.
With an async thread, some instructions may be executed concurrently.
Asynchronous is the buzzword here. A simple program is going to be synchronous, which means instructions will be executed in order. The program will run each instruction after another, in the order you prepared. However, with threading, you can run parts of the programs asynchronously. This means parts of the code may run before or after some other parts, as they are now unrelated.
This of course is the behavior we require, but we might need to have some thread waiting for the execution of another. In that case, we need to sync the threads. No worries, we will explain how to do it.
Running threads
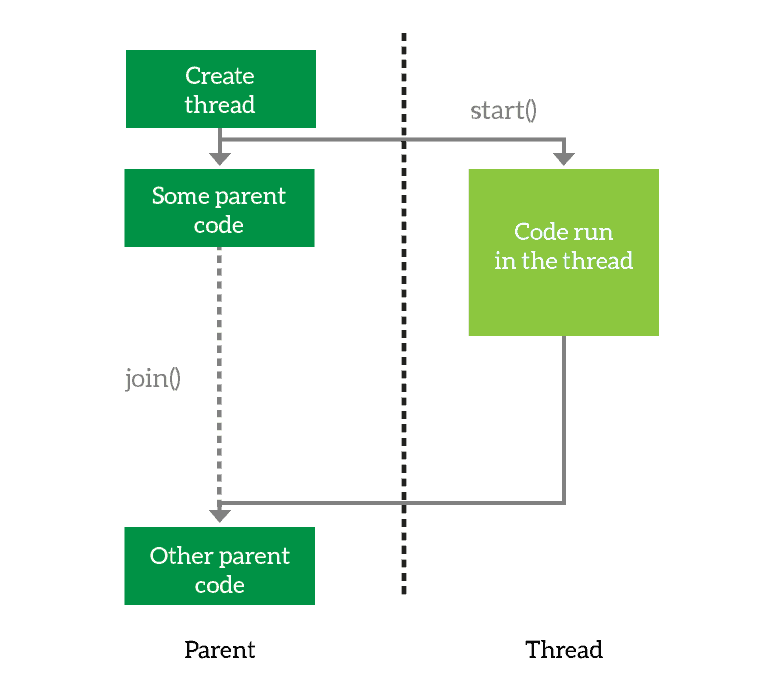 You create a thread, then you launch it. Optionally, you can join it, which means wait for it to finish.
You create a thread, then you launch it. Optionally, you can join it, which means wait for it to finish.
When working with threads, but also with processes, we need to know some common operations.
The first thing you need to do is to define the thread. You basically prepare it for execution and tell it what it will have to do. However, you are not executing the thread just yet. When you want the thread to start working, you simply start it. Then, the thread will run asynchronously from your main program. However, you may want your program to wait for the thread to finish. In that case, you join the thread. This tells your program to wait for its thread to terminate, and you can join multiple threads as well.
Looking at the above example, we create the thread and launch it. Then, we run some code in the parent and after that, we wait for the thread to finish.
Блокировки (Lock)
В следующем примере будут созданы три потока, каждый из которых будет считывать стартовую страницу по указанному Web-адресу. В примере имеется глобальный ресурс – список урлов – – доступ к которому будет блокироваться с помощью блокировки . Объект имеет методы:
– делает запрос на запирание замка. Если параметр не указан или является истиной, то поток будет ожидать освобождения замка.
Если параметр не был задан, метод не возвратит значения.
Если был задан и истинен, метод возвратит True (после успешного овладения замком).
Если блокировка не требуется (т.е. задан ), метод вернет , если замок не был заперт и им успешно овладел данный поток. В противном случае будет возвращено .
– запрос на отпирание замка.
– возвращает текущее состояние замка ( – заперт, – открыт).
import threading
from urllib import urlopen
class WorkerThread(threading.Thread):
def __init__(self,url_list,url_list_lock):
super(WorkerThread,self).__init__()
self.url_list=url_list
self.url_list_lock=url_list_lock
def run(self):
while (1):
nexturl = self.grab_next_url()
if nexturl==None:break
self.retrieve_url(nexturl)
def grab_next_url(self):
self.url_list_lock.acquire(1)
if len(self.url_list)<1:
nexturl=None
else:
nexturl = self.url_list
del self.url_list
self.url_list_lock.release()
return nexturl
def retrieve_url(self,nexturl):
text = urlopen(nexturl).read()
print text
print '################### %s #######################' % nexturl
url_list=['http://linux.org.ru','http://kernel.org','http://python.org']
url_list_lock = threading.Lock()
workerthreadlist=[]
for x in range(0,3):
newthread = WorkerThread(url_list,url_list_lock)
workerthreadlist.append(newthread)
newthread.start()
for x in range(0,3):
workerthreadlist.join()
Barrier Objects¶
Nouveau dans la version 3.2.
This class provides a simple synchronization primitive for use by a fixed number
of threads that need to wait for each other. Each of the threads tries to pass
the barrier by calling the method and will block until
all of the threads have made their calls. At this point,
the threads are released simultaneously.
The barrier can be reused any number of times for the same number of threads.
As an example, here is a simple way to synchronize a client and server thread:
b = Barrier(2, timeout=5)
def server():
start_server()
b.wait()
while True
connection = accept_connection()
process_server_connection(connection)
def client():
b.wait()
while True
connection = make_connection()
process_client_connection(connection)
- class (parties, action=None, timeout=None)
-
Create a barrier object for parties number of threads. An action, when
provided, is a callable to be called by one of the threads when they are
released. timeout is the default timeout value if none is specified for
the method.- (timeout=None)
-
Pass the barrier. When all the threads party to the barrier have called
this function, they are all released simultaneously. If a timeout is
provided, it is used in preference to any that was supplied to the class
constructor.The return value is an integer in the range 0 to parties — 1, different
for each thread. This can be used to select a thread to do some special
housekeeping, e.g.:i = barrier.wait() if i == # Only one thread needs to print this print("passed the barrier")If an action was provided to the constructor, one of the threads will
have called it prior to being released. Should this call raise an error,
the barrier is put into the broken state.If the call times out, the barrier is put into the broken state.
This method may raise a exception if the
barrier is broken or reset while a thread is waiting.
- ()
-
Return the barrier to the default, empty state. Any threads waiting on it
will receive the exception.Note that using this function may require some external
synchronization if there are other threads whose state is unknown. If a
barrier is broken it may be better to just leave it and create a new one.
- ()
-
Put the barrier into a broken state. This causes any active or future
calls to to fail with the . Use
this for example if one of the threads needs to abort, to avoid deadlocking the
application.It may be preferable to simply create the barrier with a sensible
timeout value to automatically guard against one of the threads going
awry.
-
The number of threads required to pass the barrier.
-
The number of threads currently waiting in the barrier.
-
A boolean that is if the barrier is in the broken state.
Использование Queues
Очередь(Queues Python) может быть использована для стековых реализаций «пришел первым – ушел первым» (first-in-first-out (FIFO)) или же «пришел последним – ушел последним» (last-in-last-out (LILO)) , если вы используете их правильно.
В данном разделе, мы смешаем потоки и создадим простой скрипт файлового загрузчика, чтобы продемонстрировать, как работает Queues Python со случаями, которые мы хотим паралеллизировать. Чтобы помочь объяснить, как работает Queues, мы перепишем загрузочный скрипт из предыдущей секции для использования Queues. Приступим!
Python
# -*- coding: utf-8 -*-
import os
import threading
import urllib.request
from queue import Queue
class Downloader(threading.Thread):
«»»Потоковый загрузчик файлов»»»
def __init__(self, queue):
«»»Инициализация потока»»»
threading.Thread.__init__(self)
self.queue = queue
def run(self):
«»»Запуск потока»»»
while True:
# Получаем url из очереди
url = self.queue.get()
# Скачиваем файл
self.download_file(url)
# Отправляем сигнал о том, что задача завершена
self.queue.task_done()
def download_file(self, url):
«»»Скачиваем файл»»»
handle = urllib.request.urlopen(url)
fname = os.path.basename(url)
with open(fname, «wb») as f:
while True:
chunk = handle.read(1024)
if not chunk:
break
f.write(chunk)
def main(urls):
«»»
Запускаем программу
«»»
queue = Queue()
# Запускаем потом и очередь
for i in range(5):
t = Downloader(queue)
t.setDaemon(True)
t.start()
# Даем очереди нужные нам ссылки для скачивания
for url in urls:
queue.put(url)
# Ждем завершения работы очереди
queue.join()
if __name__ == «__main__»:
urls = [«http://www.irs.gov/pub/irs-pdf/f1040.pdf»,
«http://www.irs.gov/pub/irs-pdf/f1040a.pdf»,
«http://www.irs.gov/pub/irs-pdf/f1040ez.pdf»,
«http://www.irs.gov/pub/irs-pdf/f1040es.pdf»,
«http://www.irs.gov/pub/irs-pdf/f1040sb.pdf»]
main(urls)
|
1 |
# -*- coding: utf-8 -*- importos importthreading importurllib.request fromqueueimportQueue classDownloader(threading.Thread) «»»Потоковый загрузчик файлов»»» def__init__(self,queue) «»»Инициализация потока»»» threading.Thread.__init__(self) self.queue=queue defrun(self) «»»Запуск потока»»» whileTrue # Получаем url из очереди url=self.queue.get() # Скачиваем файл self.download_file(url) # Отправляем сигнал о том, что задача завершена self.queue.task_done() defdownload_file(self,url) «»»Скачиваем файл»»» handle=urllib.request.urlopen(url) fname=os.path.basename(url) withopen(fname,»wb»)asf whileTrue chunk=handle.read(1024) ifnotchunk break f.write(chunk) defmain(urls) «»» Запускаем программу queue=Queue() # Запускаем потом и очередь foriinrange(5) t=Downloader(queue) t.setDaemon(True) t.start() # Даем очереди нужные нам ссылки для скачивания forurl inurls queue.put(url) # Ждем завершения работы очереди queue.join() if__name__==»__main__» urls=»http://www.irs.gov/pub/irs-pdf/f1040.pdf», «http://www.irs.gov/pub/irs-pdf/f1040a.pdf», «http://www.irs.gov/pub/irs-pdf/f1040ez.pdf», «http://www.irs.gov/pub/irs-pdf/f1040es.pdf», «http://www.irs.gov/pub/irs-pdf/f1040sb.pdf» main(urls) |
Давайте притормозим. В первую очередь, нам нужно взглянуть на определение главной функции для того, чтобы увидеть, как все протекает. Здесь мы видим, что она принимает список url адресов. Далее, функция main создаете экземпляр очереди, которая передана пяти демонизированным потокам. Основная разница между демонизированным и недемонизированным потоком в том, что вам нужно отслеживать недемонизированные потоки и закрывать их вручную, в то время как поток «демон» нужно только запустить и забыть о нем. Когда ваше приложение закроется, закроется и поток. Далее мы загрузили очередь (при помощи метода put) вместе с переданными url. Наконец, мы указываем очереди подождать, пока потоки выполнят свои процессы через метод join. В классе download у нас есть строчка self.queue.get(), которая выполняет функцию блока, пока очередь делает что-либо для возврата. Это значит, что потоки скромно будут дожидаться своей очереди. Также это значит, чтобы поток получал что-нибудь из очереди, он должен вызывать метод очереди под названием get. Таким образом, добавляя что-нибудь в очередь, пул потоков, поднимет или возьмет эти объекты и обработает их. Это также известно как dequeing. После того, как все объекты в очередь обработаны, скрипт заканчивается и закрывается. На моем компьютере были загружены первые 5 документов за секунду.
Задачи с ограничением скорости вычислений и ввода-вывода
Время выполнения задач, ограниченных скоростью вычислений, полностью зависит от производительности процессора, тогда как в задачах I/O Bound скорость выполнения процесса ограничена скоростью системы ввода-вывода.
В задачах с ограничением скорости вычислений программа расходует большую часть времени на использование центрального процессора, то есть на выполнение вычислений. К таким задачам можно отнести программы, занимающиеся исключительно перемалыванием чисел и проведением расчётов.
В задачах, ограниченных скоростью ввода-вывода, программы обрабатывают большие объёмы данных с диска в сравнении с необходимым объёмом вычислений. К таким задачам можно отнести, например, подсчёт количества строк в файле.