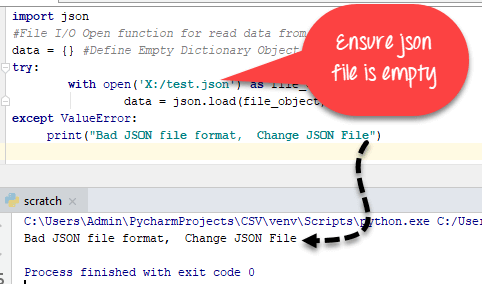
Python requests post
Содержание:
- Python Tutorial
- Потоки
- Редиректы и история
- Legacy interface¶
- Производительность
- Задержка
- Содержимое ответа
- Аутентификация
- Python NumPy
- Аутентификация
- Parameter Values
- Создание запроса
- Параллелизм
- Асинхронность
- Python Tutorial
- Python NumPy
- Краткий обзор запросов HTTP
- Анализаторы типов мультимедиа
- Заголовки запросов
- Как послать Multipart-Encoded файл
- Использование Translate API
Python Tutorial
Python HOMEPython IntroPython Get StartedPython SyntaxPython CommentsPython Variables
Python Variables
Variable Names
Assign Multiple Values
Output Variables
Global Variables
Variable Exercises
Python Data TypesPython NumbersPython CastingPython Strings
Python Strings
Slicing Strings
Modify Strings
Concatenate Strings
Format Strings
Escape Characters
String Methods
String Exercises
Python BooleansPython OperatorsPython Lists
Python Lists
Access List Items
Change List Items
Add List Items
Remove List Items
Loop Lists
List Comprehension
Sort Lists
Copy Lists
Join Lists
List Methods
List Exercises
Python Tuples
Python Tuples
Access Tuples
Update Tuples
Unpack Tuples
Loop Tuples
Join Tuples
Tuple Methods
Tuple Exercises
Python Sets
Python Sets
Access Set Items
Add Set Items
Remove Set Items
Loop Sets
Join Sets
Set Methods
Set Exercises
Python Dictionaries
Python Dictionaries
Access Items
Change Items
Add Items
Remove Items
Loop Dictionaries
Copy Dictionaries
Nested Dictionaries
Dictionary Methods
Dictionary Exercise
Python If…ElsePython While LoopsPython For LoopsPython FunctionsPython LambdaPython ArraysPython Classes/ObjectsPython InheritancePython IteratorsPython ScopePython ModulesPython DatesPython MathPython JSONPython RegExPython PIPPython Try…ExceptPython User InputPython String Formatting
Потоки
Еще одна эффективная оптимизация скорости — это потоковая передача запросов. При отправке запроса по умолчанию все тело ответа загружается немедленно. Лучший способ не загружать весь контент в память сразу при запросе. Для этого есть параметра stream, в библиотеке requests или атрибут content в aiohttp.
Потоковая передача с requests
import requests
# Use `with` to make sure the response stream is closed and the connection can
# be returned back to the pool.
with requests.get('http://example.org', stream=True) as r:
print(list(r.iter_content()))
Потоковая передача с aiohttp
import aiohttp
import asyncio
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.content.read()
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(get("http://example.com"))]
loop.run_until_complete(asyncio.wait(tasks))
print("Results: %s" % )
Не загружать полный контент крайне важно, чтобы избежать ненужного выделения сотен мегабайт памяти. Если вашей программе не требуется доступ ко всему содержимому в целом, но она может работать с частями
Например, если вы собираетесь сохранить и записать содержимое в файл, чтение только куска и одновременная запись будет гораздо более эффективным, чем чтение всего тела HTTP, выделяя огромную кучу памяти , и только после этого записать его на диск.
Редиректы и история
По умолчанию будет выполнять редиректы для всех HTTP методов, кроме . Мы можем использовать свойство объекта , чтобы отслеживать редиректы. Список содержит объекты , которые были созданы во время выполнения запроса. Список сортируется от более ранних к более поздним ответам.
Например, GitHub перенаправляет все HTTP запросы на HTTPS:
>>> r = requests.get('http://github.com')
>>> r.url 'https://github.com/'
>>> r.status_code
200
>>> r.history
>]
Если вы используете , , , , или , вы можете отключить обработку редиректов с помощью параметра :
>>> r = requests.get('http://github.com', allow_redirects=False)
>>> r.status_code
301
>>> r.history
[]
Если вы используете , вы можете включить обработку редиректов:
>>> r = requests.head('http://github.com', allow_redirects=True)
>>> r.url 'https://github.com/'
>>> r.history
>]
Legacy interface¶
The following functions and classes are ported from the Python 2 module
(as opposed to ). They might become deprecated at
some point in the future.
- (url, filename=None, reporthook=None, data=None)
-
Copy a network object denoted by a URL to a local file. If the URL
points to a local file, the object will not be copied unless filename is supplied.
Return a tuple where filename is the
local file name under which the object can be found, and headers is whatever
the method of the object returned by returned (for
a remote object). Exceptions are the same as for .The second argument, if present, specifies the file location to copy to (if
absent, the location will be a tempfile with a generated name). The third
argument, if present, is a callable that will be called once on
establishment of the network connection and once after each block read
thereafter. The callable will be passed three arguments; a count of blocks
transferred so far, a block size in bytes, and the total size of the file. The
third argument may be on older FTP servers which do not return a file
size in response to a retrieval request.The following example illustrates the most common usage scenario:
>>> import urllib.request >>> local_filename, headers = urllib.request.urlretrieve('http://python.org/') >>> html = open(local_filename) >>> html.close()If the url uses the scheme identifier, the optional data
argument may be given to specify a request (normally the request
type is ). The data argument must be a bytes object in standard
application/x-www-form-urlencoded format; see the
function.will raise when it detects that
the amount of data available was less than the expected amount (which is the
size reported by a Content-Length header). This can occur, for example, when
the download is interrupted.The Content-Length is treated as a lower bound: if there’s more data to read,
urlretrieve reads more data, but if less data is available, it raises the
exception.You can still retrieve the downloaded data in this case, it is stored in the
attribute of the exception instance.If no Content-Length header was supplied, urlretrieve can not check the size
of the data it has downloaded, and just returns it. In this case you just have
to assume that the download was successful.
- ()
-
Cleans up temporary files that may have been left behind by previous
calls to .
- class (proxies=None, **x509)
-
Deprecated since version 3.3.
Base class for opening and reading URLs. Unless you need to support opening
objects using schemes other than , , or ,
you probably want to use .By default, the class sends a User-Agent header
of , where VVV is the version number.
Applications can define their own User-Agent header by subclassing
or and setting the class attribute
to an appropriate string value in the subclass definition.The optional proxies parameter should be a dictionary mapping scheme names to
proxy URLs, where an empty dictionary turns proxies off completely. Its default
value is , in which case environmental proxy settings will be used if
present, as discussed in the definition of , above.Additional keyword parameters, collected in x509, may be used for
authentication of the client when using the scheme. The keywords
key_file and cert_file are supported to provide an SSL key and certificate;
both are needed to support client authentication.objects will raise an exception if the server
returns an error code.- (fullurl, data=None)
-
Open fullurl using the appropriate protocol. This method sets up cache and
proxy information, then calls the appropriate open method with its input
arguments. If the scheme is not recognized, is called.
The data argument has the same meaning as the data argument of
.This method always quotes fullurl using .
- (fullurl, data=None)
-
Overridable interface to open unknown URL types.
- (url, filename=None, reporthook=None, data=None)
-
If the url uses the scheme identifier, the optional data
argument may be given to specify a request (normally the request type
is ). The data argument must in standard
application/x-www-form-urlencoded format; see the
function.
-
Variable that specifies the user agent of the opener object. To get
to tell servers that it is a particular user agent, set this in a
subclass as a class variable or in the constructor before calling the base
constructor.
Производительность
Ниже приведен фрагмент HTTP-клиента, отправляющего запросы на httpbin.org, HTTP-API, который обеспечивает (среди прочего) конечную точку, имитирующую длинный запрос. Этот пример реализует все методы, перечисленные выше.
Программа для сравнения производительности использования различных запросов
import contextlib
import time
import aiohttp
import asyncio
import requests
from requests_futures import sessions
URL = "http://httpbin.org/delay/1"
TRIES = 10
@contextlib.contextmanager
def report_time(test):
t0 = time.time()
yield
print("Time needed for `%s' called: %.2fs"
% (test, time.time() - t0))
with report_time("serialized"):
for i in range(TRIES):
requests.get(URL)
session = requests.Session()
with report_time("Session"):
for i in range(TRIES):
session.get(URL)
session = sessions.FuturesSession(max_workers=2)
with report_time("FuturesSession w/ 2 workers"):
futures =
for f in futures:
f.result()
session = sessions.FuturesSession(max_workers=TRIES)
with report_time("FuturesSession w/ max workers"):
futures =
for f in futures:
f.result()
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
await response.read()
loop = asyncio.get_event_loop()
with report_time("aiohttp"):
loop.run_until_complete(
asyncio.gather(*))
Запуск этой программы дает следующий вывод:
Time needed for `serialized' called: 12.12s Time needed for `Session' called: 11.22s Time needed for `FuturesSession w/ 2 workers' called: 5.65s Time needed for `FuturesSession w/ max workers' called: 1.25s Time needed for `aiohttp' called: 1.19s
Не удивительно, что более медленный результат приходит с сериализованной версией, поскольку все запросы выполняются один за другим без повторного использования соединения — 12 секунд на 10 запросов.
Использование объекта Session и, следовательно, повторное использование соединения означает экономию 8% времени, что уже является большим и легким выигрышем. Как минимум, вы всегда должны использовать Session.
Если ваша система и программа допускают использование потоков, рекомендуется использовать их для распараллеливания запросов. Однако у потоков есть некоторые накладные расходы, и они не менее весовые. Они должны быть созданы, запущены и затем присоединены.
Если вы не используете старые версии Python, то, без сомнения, использование aiohttp должно быть вашим выбором, если вы хотите написать быстрый и асинхронный HTTP-клиент. Это самое быстрое и масштабируемое решение, поскольку оно может обрабатывать сотни параллельных запросов.
Задержка
Часто бывает нужно ограничить время ожидания ответа. Это можно сделать
с помощью параметра timeout
Перейдите на
раздел — / #/ Dynamic_data / delete_delay__delay_
и изучите документацию — если делать запрос на этот url можно выставлять время, через которое
будет отправлен ответ.
Создайте файл timeout_demo.py следующего содержания
Задержка равна одной секунде. А ждать ответ можно до трёх секунд.
python3 tiemout_demo.py
<Response >
Измените код так, чтобы ответ приходил заведомо позже чем наш таймаут в три секунды.
Задержка равна семи секундам. А ждать ответ можно по-прежнему только до трёх секунд.
python3 tiemout_demo.py
Traceback (most recent call last):
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 421, in _make_request
six.raise_from(e, None)
File «<string>», line 3, in raise_from
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 416, in _make_request
httplib_response = conn.getresponse()
File «/usr/lib/python3.8/http/client.py», line 1347, in getresponse
response.begin()
File «/usr/lib/python3.8/http/client.py», line 307, in begin
version, status, reason = self._read_status()
File «/usr/lib/python3.8/http/client.py», line 268, in _read_status
line = str(self.fp.readline(_MAXLINE + 1), «iso-8859-1»)
File «/usr/lib/python3.8/socket.py», line 669, in readinto
return self._sock.recv_into(b)
File «/usr/lib/python3/dist-packages/urllib3/contrib/pyopenssl.py», line 326, in recv_into
raise timeout(«The read operation timed out»)
socket.timeout: The read operation timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «/usr/lib/python3/dist-packages/requests/adapters.py», line 439, in send
resp = conn.urlopen(
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 719, in urlopen
retries = retries.increment(
File «/usr/lib/python3/dist-packages/urllib3/util/retry.py», line 400, in increment
raise six.reraise(type(error), error, _stacktrace)
File «/usr/lib/python3/dist-packages/six.py», line 703, in reraise
raise value
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 665, in urlopen
httplib_response = self._make_request(
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 423, in _make_request
self._raise_timeout(err=e, url=url, timeout_value=read_timeout)
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 330, in _raise_timeout
raise ReadTimeoutError(
urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «timeout_demo.py», line 4, in <module>
r = requests.get(‘https://httpbin.org/delay/7’, timeout=3)
File «/usr/lib/python3/dist-packages/requests/api.py», line 75, in get
return request(‘get’, url, params=params, **kwargs)
File «/usr/lib/python3/dist-packages/requests/api.py», line 60, in request
return session.request(method=method, url=url, **kwargs)
File «/usr/lib/python3/dist-packages/requests/sessions.py», line 533, in request
resp = self.send(prep, **send_kwargs)
File «/usr/lib/python3/dist-packages/requests/sessions.py», line 646, in send
r = adapter.send(request, **kwargs)
File «/usr/lib/python3/dist-packages/requests/adapters.py», line 529, in send
raise ReadTimeout(e, request=request)
requests.exceptions.ReadTimeout: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
Если такая обработка исключений не вызывает у вас восторга — измените код используя try except
python3 tiemout_demo.py
Response is taking too long.
Содержимое ответа
Мы можем читать содержимое ответа сервера. Рассмотрим тайм-лайн GitHub снова:
>>> import requests
>>> r = requests.get('https://api.github.com/events')
>>> r.text
u'[{"repository":{"open_issues":0,"url":"https://github.com/...
будет автоматически декодировать содержимое ответа сервера. Большинство Unicode кодировок без проблем декодируются.
Когда вы делаете запрос, делает предположение о кодировке, основанное на заголовках HTTP. Кодировка текста, угаданная , используется при обращение к . Вы можете узнать, какую кодировку использует , и изменить её воспользовавшись свойством :
>>> r.encoding 'utf-8' >>> r.encoding = 'ISO-8859-1'
Если вы измените кодировку, Requests будет использовать новое значение всякий раз, когда вы будете использовать . Вы можете сделать это в любой ситуации, где нужна более специализированная логика работы с кодировкой содержимого ответа. Например, в HTML и XML есть возможность задавать кодировку прямо в теле документа. В подобных ситуациях вы должны использовать , чтобы найти кодировку, а затем установить . Это позволит вам использовать с правильной кодировкой.
Requests может также использовать пользовательские кодировки в случае, если вы в них нуждаетесь. Если вы создали свою собственную кодировку и зарегистрировали её в модуле , вы можете просто использовать название кодека в качестве значения , и будет работать с этой кодировкой для вас.
Аутентификация
Рассмотрим базовую аутентификацию на сайте httpbin
Придумайте любое имя пользоватлея и пароль к нему.
Я придумал andrey с паролем heihei
Перейдите на
httpbin.org
. Убедитесь, что в адресной строке стоит basic-auth/andrey/heihei
либо те логин и пароль, что придумали вы.
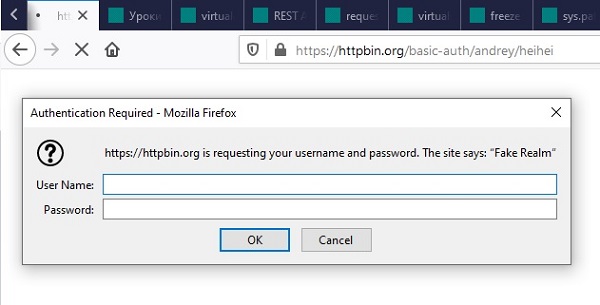
Введите ваши логин и пароль
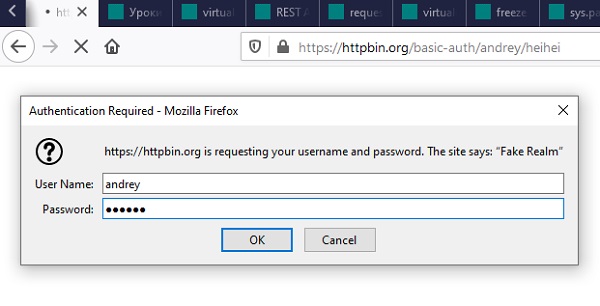
Убедитесь, что аутентификация прошла успешно
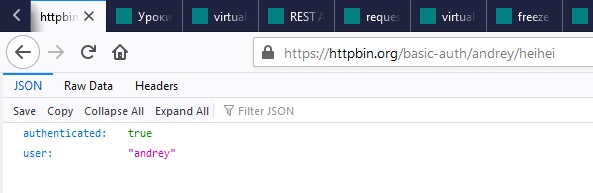
Теперь проделаем такую же аутентификацию с помощью Python
Создайте файл auth_demo.py со следующим кодом
python3 auth_demo.py
{
«authenticated»: true,
«user»: «andrey»
}
Ответ совпадает с тем что мы уже получали в браузере
Выполните такой же запрос, но с неправильным паролем. Убедитесь в том, что text ничего не содержит. Замените
print(r.text) на print(r) и убедитесь, что полученный объект это
<Response >
Python NumPy
NumPy IntroNumPy Getting StartedNumPy Creating ArraysNumPy Array IndexingNumPy Array SlicingNumPy Data TypesNumPy Copy vs ViewNumPy Array ShapeNumPy Array ReshapeNumPy Array IteratingNumPy Array JoinNumPy Array SplitNumPy Array SearchNumPy Array SortNumPy Array FilterNumPy Random
Random Intro
Data Distribution
Random Permutation
Seaborn Module
Normal Distribution
Binomial Distribution
Poisson Distribution
Uniform Distribution
Logistic Distribution
Multinomial Distribution
Exponential Distribution
Chi Square Distribution
Rayleigh Distribution
Pareto Distribution
Zipf Distribution
NumPy ufunc
ufunc Intro
ufunc Create Function
ufunc Simple Arithmetic
ufunc Rounding Decimals
ufunc Logs
ufunc Summations
ufunc Products
ufunc Differences
ufunc Finding LCM
ufunc Finding GCD
ufunc Trigonometric
ufunc Hyperbolic
ufunc Set Operations
Аутентификация
Простая HTTP-аутентификация
Простая HTTP-аутентификация может быть достигнута с помощью следующего:
Технически это короткая рука для следующего:
Дайджест-аутентификация HTTP
Проверка подлинности дайджеста HTTP выполняется очень похожим способом, для этого Requests предоставляет другой объект:
Пользовательская аутентификация
В некоторых случаях встроенных механизмов аутентификации может быть недостаточно, представьте этот пример:
Сервер настроен на прием аутентификации, если отправитель имеет правильную строку агента пользователя, определенное значение заголовка и предоставляет правильные учетные данные через HTTP Basic Authentication. Для достижения этого должен быть подготовлен пользовательский класс аутентификации, подклассифицирующий AuthBase, который является основой для реализаций аутентификации запросов:
Это можно затем использовать с помощью следующего кода:
Parameter Values
| Parameter | Description | |
|---|---|---|
| url | Try it | Required. The url of the request |
| data | Try it | Optional. A dictionary, list of tuples, bytes or a file object to send to the specified url |
| json | Try it | Optional. A JSON object to send to the specified url |
| files | Try it | Optional. A dictionary of files to send to the specified url |
| allow_redirects | Try it | Optional. A Boolean to enable/disable redirection.Default (allowing redirects) |
| auth | Try it | Optional. A tuple to enable a certain HTTP authentication.Default |
| cert | Try it | Optional. A String or Tuple specifying a cert file or key.Default |
| cookies | Try it | Optional. A dictionary of cookies to send to the specified url.Default |
| headers | Try it | Optional. A dictionary of HTTP headers to send to the specified url.Default |
| proxies | Try it | Optional. A dictionary of the protocol to the proxy url.Default |
| stream | Try it | Optional. A Boolean indication if the response should be immediately downloaded (False) or streamed (True).Default |
| timeout | Try it | Optional. A number, or a tuple, indicating how many seconds to wait for the client to make a connection and/or send a response.Default which means the request will continue until the connection is closed |
| verify |
Try it Try it |
Optional. A Boolean or a String indication to verify the servers TLS certificate or not.Default |
Создание запроса
Создание запроса с помощью — это очень просто. Начните с импорта модуля:
>>> import requests
Теперь попробуем получить веб-страницу. Например, давайте получим публичный тайм-лайн GitHub.
>>> r = requests.get('https://api.github.com/events')
Теперь у нас есть объект с именем . Мы можем получить всю необходимую информацию из этого объекта.
Простой API Requests означает, что все формы HTTP запросов являются очевидными. Например, вот как вы можете сделать HTTP запрос:
>>> r = requests.post("http://httpbin.org/post")
Круто? А как насчет других типов HTTP запроса: , , и ? Их выполнить так же просто:
>>> r = requests.put("http://httpbin.org/put")
>>> r = requests.delete("http://httpbin.org/delete")
>>> r = requests.head("http://httpbin.org/get")
>>> r = requests.options("http://httpbin.org/get")
Это уже хорошо. Даже здорово. Но это далеко не все из того, что может делать .
Параллелизм
requests также имеют один существенный недостаток: эта библиотека синхронна. Вызов request.get («http://example.org») блокирует программу до тех пор, пока HTTP-сервер не ответит полностью. Недостатком может быть то, что приложение во время запроса ожидает ответа и ничего не делает. Вполне возможно, что программа могла бы делать что-то еще, а не сидеть без дела.
Интеллектуальное приложение может смягчить эту проблему, используя пул потоков, подобных тем, которые предоставляются concurrent.futures. Это позволяет очень быстро распараллеливать HTTP-запросы.
Использование futures с requests
from concurrent import futures
import requests
with futures.ThreadPoolExecutor(max_workers=4) as executor:
futures = [
executor.submit(
lambda: requests.get("http://example.org"))
for _ in range(8)
]
results =
print("Results: %s" % results)
Этот шаблон довольно полезен, он был упакован в библиотеку requests-futures. С помощью его можно легко использовать объект Session:
from requests_futures import sessions
session = sessions.FuturesSession()
futures = [
session.get("http://example.org")
for _ in range(8)
]
results =
print("Results: %s" % results)
По умолчанию создается worker с двумя потоками, но программа может легко настроить это значение, передав аргумент max_workers или даже своего собственного исполнителя объекту FuturSession — например, так: FuturesSession (executor = ThreadPoolExecutor (max_workers = 10)).
Асинхронность
Как объяснялось ранее, requests полностью синхронен. Он блокирует приложение в ожидании ответа сервера, замедляя работу программы. Создание HTTP-запросов в потоках является одним из решений, но потоки имеют свои собственные накладные расходы, и это подразумевает параллелизм, который не всегда каждый рад видеть в программе.
Начиная с версии 3.5, Python предлагает асинхронность внутри своего ядра, используя aiohttp. Библиотека aiohttp предоставляет асинхронный HTTP-клиент, построенный поверх asyncio. Эта библиотека позволяет отправлять запросы последовательно, но не дожидаясь первого ответа, прежде чем отправлять новый. В отличие от конвейерной передачи HTTP, aiohttp отправляет запросы по нескольким соединениям параллельно, избегая проблемы, описанной ранее.
Использование aiohttp
import aiohttp
import asyncio
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return response
loop = asyncio.get_event_loop()
coroutines = [get("http://example.com") for _ in range(8)]
results = loop.run_until_complete(asyncio.gather(*coroutines))
print("Results: %s" % results)
Все эти решения (с использованием Session, thread, futures или asyncio) предлагают разные подходы к ускорению работы HTTP-клиентов. Но какая между ними разница с точки зрения производительности?
Python Tutorial
Python HOMEPython IntroPython Get StartedPython SyntaxPython CommentsPython Variables
Python Variables
Variable Names
Assign Multiple Values
Output Variables
Global Variables
Variable Exercises
Python Data TypesPython NumbersPython CastingPython Strings
Python Strings
Slicing Strings
Modify Strings
Concatenate Strings
Format Strings
Escape Characters
String Methods
String Exercises
Python BooleansPython OperatorsPython Lists
Python Lists
Access List Items
Change List Items
Add List Items
Remove List Items
Loop Lists
List Comprehension
Sort Lists
Copy Lists
Join Lists
List Methods
List Exercises
Python Tuples
Python Tuples
Access Tuples
Update Tuples
Unpack Tuples
Loop Tuples
Join Tuples
Tuple Methods
Tuple Exercises
Python Sets
Python Sets
Access Set Items
Add Set Items
Remove Set Items
Loop Sets
Join Sets
Set Methods
Set Exercises
Python Dictionaries
Python Dictionaries
Access Items
Change Items
Add Items
Remove Items
Loop Dictionaries
Copy Dictionaries
Nested Dictionaries
Dictionary Methods
Dictionary Exercise
Python If…ElsePython While LoopsPython For LoopsPython FunctionsPython LambdaPython ArraysPython Classes/ObjectsPython InheritancePython IteratorsPython ScopePython ModulesPython DatesPython MathPython JSONPython RegExPython PIPPython Try…ExceptPython User InputPython String Formatting
Python NumPy
NumPy IntroNumPy Getting StartedNumPy Creating ArraysNumPy Array IndexingNumPy Array SlicingNumPy Data TypesNumPy Copy vs ViewNumPy Array ShapeNumPy Array ReshapeNumPy Array IteratingNumPy Array JoinNumPy Array SplitNumPy Array SearchNumPy Array SortNumPy Array FilterNumPy Random
Random Intro
Data Distribution
Random Permutation
Seaborn Module
Normal Distribution
Binomial Distribution
Poisson Distribution
Uniform Distribution
Logistic Distribution
Multinomial Distribution
Exponential Distribution
Chi Square Distribution
Rayleigh Distribution
Pareto Distribution
Zipf Distribution
NumPy ufunc
ufunc Intro
ufunc Create Function
ufunc Simple Arithmetic
ufunc Rounding Decimals
ufunc Logs
ufunc Summations
ufunc Products
ufunc Differences
ufunc Finding LCM
ufunc Finding GCD
ufunc Trigonometric
ufunc Hyperbolic
ufunc Set Operations
Краткий обзор запросов HTTP
Запросы HTTP лежат в основе всемирной сети. Каждый раз, когда вы открываете веб-страницу, ваш браузер направляет множество запросов на сервер этой веб-страницы. Сервер отвечает на них, пересылая все необходимые данные для вывода страницы, и ваш браузер отображает страницу, чтобы вы могли увидеть ее.
В целом этот процесс выглядит так: клиент (например браузер или скрипт Python, использующий библиотеку Requests) отправляет данные на URL, а сервер с этим URL считывает данные, решает, что с ними делать, и отправляет клиенту ответ. После этого клиент может решить, что делать с полученными в ответе данными.
В составе запроса клиент отправляет данные по методу запроса. Наиболее распространенными методами запроса являются GET, POST и PUT. Запросы GET обычно предназначены только для чтения данных без их изменения, а запросы POST и PUT обычно предназначаются для изменения данных на сервере. Например, Stripe API позволяет использовать запросы POST для тарификации, чтобы пользователь мог купить что-нибудь в вашем приложении.
Примечание. В этой статье рассказывается о запросах GET, поскольку мы не собираемся изменять никакие данные на сервере.
При отправке запроса из скрипта Python или веб-приложения вы как разработчик решаете, что отправлять в каждом запросе и что делать с полученными ответами. Для начала отправим запрос на Scotch.io и используем API для перевода.
Анализаторы типов мультимедиа
Slim выглядит как тип медиа-запроса и, если он его распознает, будет анализировать его на структурированные данные, доступные через . Обычно это массив, но является объектом для типов media XML.
Следующие типы носителей распознаются и анализируются:
- application/x-www-form-urlencoded
- application/json
- application/xml & text/xml
Если вы хотите, чтобы Slim анализировал контент с другого media type, вам нужно либо самостоятельно разобрать исходный media, либо зарегистрировать новый парсер. Парсеры media — это просто вызывающие элементы, которые принимают строку и возвращают анализируемый объект или массив.
Зарегистрируйте новый медиасервер в промежуточном программном приложении или маршруте
Обратите внимание, что вы должны зарегистрировать парсер, прежде чем пытаться получить доступ к анализируемому телу в первый раз
Например, для автоматического разбора JSON, который отправляется с типом контента, вы регистрируете парсер типа медиа в промежуточном программном обеспечении следующим образом:
Заголовки запросов
Каждый HTTP-запрос имеет заголовки. Это метаданные, которые описывают HTTP-запрос, но не отображаются в теле запроса. Объект запроса PSR 7 Slim предоставляет несколько методов для проверки своих заголовков.
Получить все заголовки
Вы можете получить все заголовки HTTP-запросов в качестве ассоциативного массива с помощью метода объекта запроса PSR 7 . Результирующие ключи ассоциативного массива — это имена заголовков, и его значения сами представляют собой числовой массив строковых значений для их соответствующего заголовка.
Figure 5: Извлечение и повторение всех заголовков HTTP-запросов в качестве ассоциативного массива.
Получить один заголовок
Вы можете получить значения одного заголовка с помощью метода объекта PSR 7 Request. Это возвращает массив значений для данного заголовка. Помните, что один HTTP-заголовок может иметь более одного значения!
Figure 6: Получить значения для определенного HTTP-заголовка.
Вы также можете получить строку, разделенную запятыми, со всеми значениями для данного заголовка с помощью метода объекта запроса PSR 7 . В отличие от метода, этот метод возвращает строку, разделенную запятыми.
Figure 7: Get single header’s values as comma-separated string.
Обнаружение заголовка
Вы можете проверить наличие заголовка с помощью метода объекта PSR 7 Request .
Figure 8: Обнаружение присутствия определенного заголовка HTTP-запроса.
Как послать Multipart-Encoded файл
Requests позволяет легко послать на сервер Multipart-Encoded файлы:
>>> url = 'http://httpbin.org/post'
>>> files = {'file': open('report.xls', 'rb')}
>>> r = requests.post(url, files=files)
>>> r.text
{ ... "files": { "file": "<censored...binary...data>" }, ... }
Вы можете установить имя файла, content-type и заголовки в явном виде:
>>> url = 'http://httpbin.org/post'
>>> files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})}
>>> r = requests.post(url, files=files)
>>> r.text
{ ... "files": { "file": "<censored...binary...data>" }, ... }
При желании, вы можете отправить строки, которые будут приняты в виде файлов:
>>> url = 'http://httpbin.org/post'
>>> files = {'file': ('report.csv', 'some,data,to,send\nanother,row,to,send\n')}
>>> r = requests.post(url, files=files)
>>> r.text
{ ... "files": { "file": "some,data,to,send\nanother,row,to,send\n" }, ... }
В случае, если вы отправляете очень большой файл как , вы можете захотеть отправить запрос потоком. По умолчанию не поддерживает этого, но есть отдельный пакет, который это делает — .
Для отправки нескольких файлов в одном запросе, обратитесь к дополнительной документации.
Использование Translate API
Теперь перейдем к чему-то более интересному. Мы используем API Яндекс.Перевод (Yandex Translate API) для выполнения запроса на перевод текста на другой язык.
Чтобы использовать API, нужно предварительно войти в систему. После входа в систему перейдите к Translate API и создайте ключ API. Когда у вас будет ключ API, добавьте его в свой файл в качестве константы. Далее приведена ссылка, с помощью которой вы можете сделать все перечисленное: https://tech.yandex.com/translate/
script.py
Ключ API нужен, чтобы Яндекс мог проводить аутентификацию каждый раз, когда мы хотим использовать его API. Ключ API представляет собой облегченную форму аутентификации, поскольку он добавляется в конце URL запроса при отправке.
Чтобы узнать, какой URL нам нужно отправить для использования API, посмотрим документацию Яндекса.
Там мы найдем всю информацию, необходимую для использования их Translate API для перевода текста.

Если вы видите URL с символами амперсанда (&), знаками вопроса (?) или знаками равенства (=), вы можете быть уверены, что это URL запроса GET. Эти символы задают сопутствующие параметры для URL.
Обычно все, что размещено в квадратных скобках ([]), будет необязательным. В данном случае для запроса необязательны формат, опции и обратная связь, но обязательны параметры key, text и lang.
Добавим код для отправки на этот URL. Замените первый созданный нами запрос на следующий:
script.py
Существует два способа добавления параметров. Мы можем прямо добавить параметры в конец URL, или библиотека Requests может сделать это за нас. Для последнего нам потребуется создать словарь параметров. Нам нужно указать три элемента: ключ, текст и язык. Создадим словарь, используя ключ API, текст и язык , т. к. нам требуется перевод с английского на испанский.
Другие коды языков можно посмотреть здесь. Нам нужен столбец 639-1.
Мы создаем словарь параметров, используя функцию , и передаем ключи и значения, которые хотим использовать в нашем словаре.
script.py
Теперь возьмем словарь параметров и передадим его функции .
script.py
Когда мы передаем параметры таким образом, Requests автоматически добавляет параметры в URL за нас.
Теперь добавим команду печати текста ответа и посмотрим, что мы получим в результате.
script.py
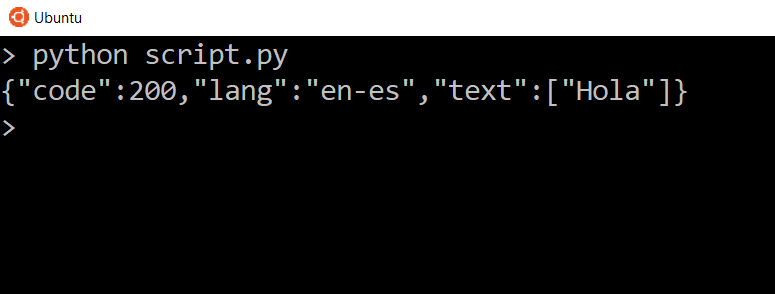
Мы видим три вещи. Мы видим код состояния, который совпадает с кодом состояния ответа, мы видим заданный нами язык и мы видим переведенный текст внутри списка. Итак, мы должны увидеть переведенный текст .
Повторите эту процедуру с кодом языка en-fr, и вы получите ответ .
script.py

Посмотрим заголовки полученного ответа.
script.py

Разумеется, заголовки должны быть другими, поскольку мы взаимодействуем с другим сервером, но в данном случае мы видим тип контента application/json вместо text/html. Это означает, что эти данные могут быть интерпретированы в формате JSON.
Если ответ имеет тип контента application/json, библиотека Requests может конвертировать его в словарь и список, чтобы нам было удобнее просматривать данные.
Для обработки данных в формате JSON мы используем метод на объекте response.
Если вы распечатаете его, вы увидите те же данные, но в немного другом формате.
script.py
 Причина отличия заключается в том, что это уже не обычный текст, который мы получаем из файла res.text. В данном случае это печатная версия словаря.
Причина отличия заключается в том, что это уже не обычный текст, который мы получаем из файла res.text. В данном случае это печатная версия словаря.
Допустим, нам нужно получить доступ к тексту. Поскольку сейчас это словарь, мы можем использовать ключ текста.
script.py
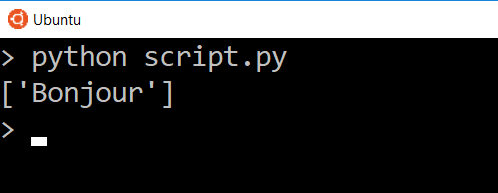 Теперь мы видим данные только для этого одного ключа. В данном случае мы видим список из одного элемента, так что если мы захотим напрямую получить текст в списке, мы можем использовать указатель для доступа к нему.
Теперь мы видим данные только для этого одного ключа. В данном случае мы видим список из одного элемента, так что если мы захотим напрямую получить текст в списке, мы можем использовать указатель для доступа к нему.
script.py
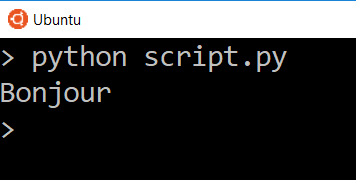
Теперь мы видим только переведенное слово.
Разумеется, если мы изменим параметры, мы получим другие результаты. Изменим переводимый текст с на , изменим язык перевода на испанский и снова отправим запрос.
script.py
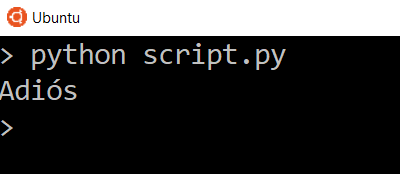 Попробуйте перевести более длинный текст на другие языки и посмотрите, какие ответы будет вам присылать API.
Попробуйте перевести более длинный текст на другие языки и посмотрите, какие ответы будет вам присылать API.