Optimization 2019: ошибки текстовых анализаторов
Содержание:
- Как проверить качество сканирования
- Наглядная проверка текста по закону Ципфа
- Что нужно чтобы стать копирайтером и как заработать?
- История создания
- Анализатор по умолчаниюDefault analyzer
- 2.
- Извлечение именованных сущностей
- Копирайтинг и его виды
- Зачем нужны частоты
- Just Magic
- Морфологический анализ
- Профессия копирайтер: плюсы и минусы
- Vaal
- Параметры SEO анализа текстов
Как проверить качество сканирования
Если говорить о покрытии языков программирования, то здесь все просто: информация о списке поддерживаемых языков либо опубликована, либо есть в интерфейсе самого анализатора. Проверить качество сканирования сложнее. Можно протестировать несколько анализаторов, «прогоняя» через них одно и то же приложение, но по времени это может быть довольно затратной задачей.
Другой вариант — обратиться к исследованиям независимых организаций, занимающихся профильными вопросами. Примером может служить сообщество OWASP — открытый проект, посвященный обеспечению безопасности веб-приложений, в него входят корпорации, образовательные учреждения и частные лица со всего мира. OWASP работает над созданием статей, учебных пособий, документации, инструментов и технологий, находящихся в свободном доступе.
В части проверки качества сканирования OWASP сформировал ряд эталонных тестов, которые представляют собой код с известным числом уязвимостей. Запуская анализ этого кода на испытуемых анализаторах, можно понять, как они справляются с поиском уязвимостей. Результаты испытаний можно представить в виде графика (см. рисунок). Если анализатор не нашел ни одной уязвимости, но показал ложные срабатывания, то он отражается в правом нижнем углу графика. Если анализатор нашел все уязвимости и не показал ни одного ложного срабатывания, то он отображается в верхнем левом углу графика. По диагонали располагаются те анализаторы, которые, нашли не все уязвимости и показали ложные срабатывания. Подробнее на странице проекта OWASP Benchmark.
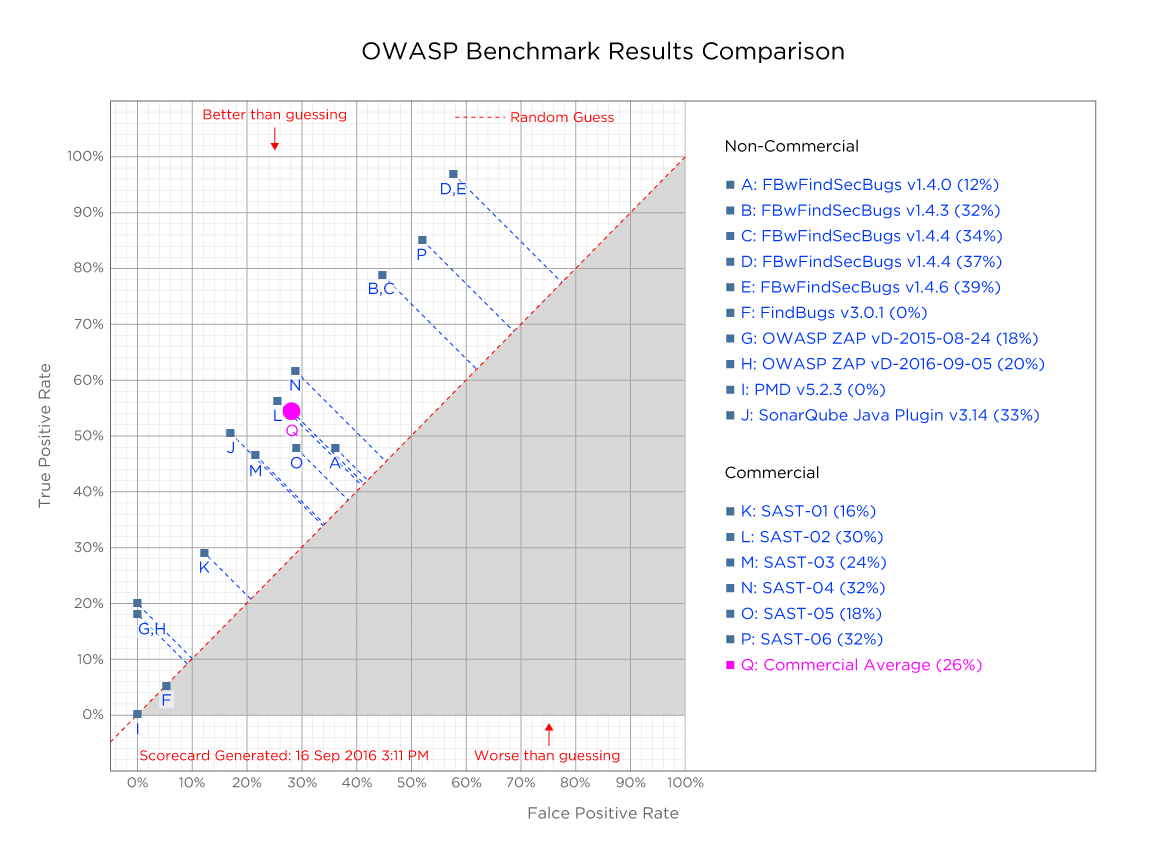 Пример сравнения анализаторов, проведенного в 2018 году
Пример сравнения анализаторов, проведенного в 2018 году
Наглядная проверка текста по закону Ципфа
Для предстоящей работы я решил взять несколько разных ключевых фраз и проверить тексты на соответствие закону Ципфа, расположенные в разных местах ТОПа нашей отечественной поисковой системы Yandex. Приступим.
Первый ключ – «Строительство домой из бруса».
Выбираю сайт, который расположен вверху поискового рейтинга, делаю анализ:

дом из бруса. Первые места в ТОПе
Что имеем: естественность – 80, тошнота – 5.9.
Перехожу на страницу ниже в поисковике, выбираю сайт из третьего десятка, провожу анализ:

Дом из бруса. Во втором десятке ТОПа
Результат: естественность – 82, тошнота – 6.16.
Опускаюсь на десяток позиций ниже и повторяю процедуру:

Дом из бруса. где-то далеко-далеко
Итог: Е – 86, Т – 8.6.
Американский автор этого закона подошел бы, наверное, к автору последнего материала, и сказал бы ему – Вообще, красавчик!
Но в ТОПе то другое стоит! Мало? Повторяем проверку. Берем следующий ключ. Допустим – лечение геморроя.
Первое место в рейтинге:

Лечение геморроя. Первое место в ТОПе
Результат: Е – 70, Т – 11.23.
Ниже на два десятка позиций:

Лечение геморроя. Во втором десятке Топа.
Итог: Е – 91, Т – 4.90.
Еще на страницу ниже:

Лечение Геморроя. Примерно там, где находится сама болезнь.
Результат: Е – 91, Т – 4.12.
Что нужно чтобы стать копирайтером и как заработать?
С чего начать копирайтинг новичку, чтобы получить свой первый авторский опыт, поддерживающийся денежными поощрениями? Как заработать деньги в интернете без вложений прямо сейчас?
В первую очередь, зарегистрировать электронные кошельки, на которые будут поступать выплаты. Они могут быть как в национальной, так и в иностранной валюте. Поэтому рекомендовано заводить сразу 3 кошелька (рубль, доллар, евро) на каждом сервисе.
Самые распространённые:
Найти в интернете антиплагиат-программы, предназначенные для проверки уникальности текста. Они бесплатные. Их нужно только скачать и установить на компьютер:
- Advego Plagiatus;
- Etxt Antiplagiat.
Потренироваться в написании текстов можно на тематических ресурсах, предварительно зарегистрировавшись на них. Среди самых лояльных по условиям и модерации, отмечены сайты отзывов, за которые платят. Вот неполный список таковых:
Плюсы очевидны: труд оплачивается, а работа превращается в хобби, благодаря душевной атмосфере сайтов. Кроме того, заработок постепенно становится пассивным.
Но и минусы существенны. На большую прибыль рассчитывать не стоит, а времени они отнимают много.
Есть биржи копирайтинга: уровень которых более профессионален. Соответственно, и возможности заработка намного больше.
Точно сказать, сколько зарабатывает копирайтер с помощью таких контент-ресурсов, сложно. Всё зависит от умения, желания и времяпровождения за компьютером. Многим удаётся заработать десятки тысяч рублей в месяц, а некоторые ограничиваются 4000–5000 рублей.
Также можно завести свой блог, где шаг за шагом, будет совершенствоваться творческое мастерство. А заодно, расширяться возможности заработка. Как заработать на копирайтинге начинающему блогеру? Пройти регистрацию на интернет-площадках. Они созданы для блогеров-новичков:
Но на самом деле, эта специальность может приносить гораздо больше средств, чем на подобных ресурсах. Они нужны в начале профессионального пути, чтобы научиться писать уникально и качественно. Дальше, авторская позиция на них невыгодна, и нужно подумать, с чего начать копирайтинг, освоившись в «копирайтерской» среде.
Достаточно заманчивый вариант – трудоустройство в рекламной сфере. Но такую работу найти сложно, и она отнимает много времени. Требования к ней высоки, а вероятность всестороннего развития мала. Хотя, оплачивается эта должность достойно, и сулит большие перспективы работнику.
Многим очень удобно трудится удалённо, и самостоятельно корректировать график работы. Копирайтинг на дому работа, соответствующая этим критериям. При этом таким копирайтерам кто работает вне офиса, положены привилегии штатных сотрудников. Эта должность постоянна, и тоже хорошо оплачивается.
Есть категория лиц, которым официальное оформление, по каким-либо причинам, не требуется. В таком случае, можно стать фрилансером, и зарабатывать на копирайтинге в интернете. Заказчиков легко найти, опубликовав резюме на сайтах трудоустройства. Но стоит учесть, что риски быть обманутым при этом велики. Часто заказчики не оплачивают статью, распоряжаясь ею на своё усмотрение. А многие, даже просят небольшую оплату, для «резерва» заказа.
Кроме выполнения заказных работ, можно потрудиться над созданием собственного сайта. По мере наполнения ресурса качественным контентом, заработок становится пассивным и довольно высоким. А государство лояльно к копирайтерам, и на данный момент не требует уплаты налогов.
И, наконец, высший пилотаж копирайтинга – предпринимательская деятельность. Она основана на наборе штата сотрудников, в который входят копирайтеры и фрилансеры. Это одна из самых высокооплачиваемых профессий в России для девушек. Чтобы начать зарабатывать таким способом, потребуется освоить все виды копирайтинга.
История создания
Автором открытия закономерности является французский стенографист Жан-Батист Эсту (фр. Jean-Baptiste Estoup), который описал её в 1908 году в работе «Диапазон стенографии». Закон был впервые применён для описания распределения размеров городов немецким физиком Феликсом Ауэрбахом в работе «Закон концентрации населения» в 1913 году и носит имя американского лингвиста Джорджа Ципфа, который в 1949 году активно популяризировал данную закономерность, впервые предложив использовать её для описания распределения экономических сил и социального статуса.
Объяснение закона Ципфа, основанное на корреляционных свойствах аддитивных марковских цепей (со ступенчатой функцией памяти) было дано в 2005 году.
Закон Ципфа математически описывается распределением Парето. Является одним из базовых законов, используемых в инфометрии.
Анализатор по умолчаниюDefault analyzer
В запросах Когнитивный поиск Azure анализатор автоматически вызывается для всех строковых полей, помеченных как поддерживающие поиск.In Azure Cognitive Search queries, an analyzer is automatically invoked on all string fields marked as searchable.
По умолчанию Когнитивный поиск Azure использует анализатор Apache Lucene Standard (стандартный Lucene), который разбивает текст на элементы, следующие за правилами «сегментация текста Юникода» .By default, Azure Cognitive Search uses the Apache Lucene Standard analyzer (standard lucene), which breaks text into elements following the «Unicode Text Segmentation» rules. Кроме того, стандартный анализатор преобразует все знаки в нижний регистр.Additionally, the standard analyzer converts all characters to their lower case form. Анализу подвергаются как индексируемые документы, так и условия поиска во время индексирования и обработки запросов.Both indexed documents and search terms go through the analysis during indexing and query processing.
Можно переопределить значение по умолчанию для каждого поля.You can override the default on a field-by-field basis. Альтернативные анализаторы могут быть анализатором языка для лингвистической обработки, настраиваемого анализатораили стандартного анализатора из .Alternative analyzers can be a language analyzer for linguistic processing, a custom analyzer, or a predefined analyzer from the .
2.
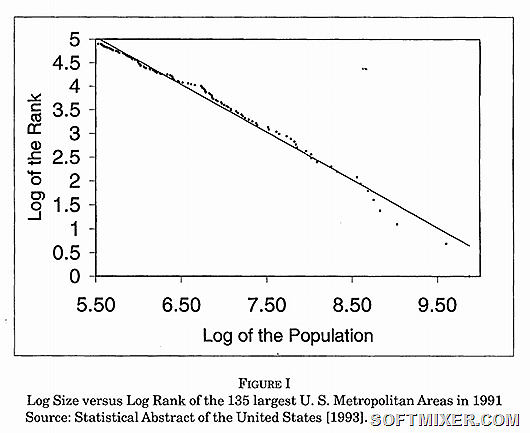
Можно задаться вопросом, что же имеется в виду под определением «город»? Ведь, например, Бостон и Кембридж считаются двумя разными городами, так же, как Сан-Франциско и Окленд, разделённые водой. У двух шведских географов тоже возник такой вопрос, и они стали рассматривать так называемые «естественные» города, объединённые населением и дорожными связками, а не политическими мотивами. И они обнаружили, что даже такие «естественные» города подчиняются закону Ципфа.
Почему закон Ципфа работает в городах?
Так что же заставляет города быть столь предсказуемыми в количестве населения? Никто точно не может это объяснить. Нам известно, что города расширяются за счёт иммиграции, иммигранты стекаются в большие мегаполисы, потому что там больше возможностей. Но иммиграции недостаточно, чтобы объяснить этот закон.
Есть также экономические мотивы, поскольку в больших городах делают большие деньги, а закон Ципфа работает и для распределения доходов. Однако, чёткого ответа на вопрос это по-прежнему не даёт.
В прошлом году группа исследователей обнаружила, что у закона Ципфа всё же есть исключения: закон работает, только если рассматриваемые города связаны экономически. Это объясняет, почему закон действует, например, для отдельной европейской страны, но не для всего ЕС.
Кстати, рекомендуем профессиональное бухгалтерское обслуживание, корректировку ндс и сопровождение бизнеса специально для тех, кто имеет дело с налоговыми документами. Подготовка документов для вашего бизнеса законными методами.
Как же растут города
Существует ещё одно странное правило, применимое к городам, оно имеет отношение к тому, каким способом города потребляют ресурсы, когда растут. Вырастая, города становятся более стабильными. Например, если город удваивается в размере, требуемое ему число бензоколонок не увеличивается вдвое.
Город будет вполне комфортно жить, если количество бензоколонок увеличится примерно на 77%. В то время, как закон Ципфа следует определённым социальным законам, этот закон более близок к природным, например, к тому, как животные потребляют энергию, становясь взрослее.
Извлечение именованных сущностей
| Название | Метод | Языки | Лицензия | Платформа |
|---|---|---|---|---|
| FreeLing | конечный автомат | русский, английский, итальянский, испанский, португальский, астурийский, валийский, галисийский, каталанский | GPL + Коммерческая | Linux |
| н/д | английский | Некоммерческая/Коммерческая | Веб-сервис | |
| н/д | английский | Коммерческая | Веб-сервис | |
| Eureka Engine | условные случайные поля | русский, английский | Коммерческая | Веб-сервис |
| машинное обучение | русский, английский | Бесплатная для исследовательских целей + коммерческая | Веб-сервис, Java, Python | |
| н/д | английский | Apache License | Java, Scala, Веб-сервис | |
| н/д | английский | Коммерческая | Веб-сервис | |
| н/д | английский, арабский, китайский и др. | Коммерческая | Linux, Windows, OS X, Solaris, Веб-сервис | |
| машинное обучение (Conditional Random Field sequence models) | английский, немецкий | GPL | Linux, Windows, OS X | |
| правила, машинное обучение | английский | Apache License | Java | |
| частотный анализ | русский, английский | н/д | Java | |
| правила | русский, украинский, английский | Non-Commercial Freeware | .NET, .NET Core, Java и Python | |
| машинное обучение | английский | Коммерческая | Java | |
| Томита-парсер | словари и контекстно-свободные грамматики | русский | Linux, Windows, OS X | |
| машинное обучение | русский | Коммерческая | Веб-сервис | |
| правила | русский | Коммерческая | Linux, Windows | |
| н/д | русский, английский, французский, немецкий | Коммерческая | Java | |
| н/д | русский, английский | Коммерческая | Веб-сервис | |
| н/д | русский, английский | Коммерческая | Windows, C++ | |
| н/д | русский | Коммерческая | .NET | |
| н/д | русский, английский, арабский, китайский, французский, немецкий, корейский, персидский, испанский | Коммерческая | Linux, Windows | |
| н/д | русский | Коммерческая | Java | |
| н/д | русский | Коммерческая | Windows | |
| н/д | русский | Коммерческая | FreeBSD, Windows | |
| н/д | русский | Коммерческая | н/д | |
| н/д | русский, английский | Коммерческая | н/д | |
| правила, машинное обучение | русский, английский (частично) | MIT | Python | |
| машинное обучение | русский | некоммерческая | .NET on Linux, Windows | |
| машинное обучение | английский | некоммерческая | .NET on Linux, Windows | |
| правила, шаблоны, словари, нечеткий поиск | русский | Коммерческая и некоммерческая | Windows, Linux, macOS |
Копирайтинг и его виды
Cразу первый вопрос назрел: что значит копирайтинг? Это профессиональная деятельность, которая направлена на написание рекламного и презентационного текста.
Копирайтинг делится на несколько видов. Чтобы стать профессионалом, то нужно освоить все техники для написания статей.
Написание статей может выступать в виде:
- рерайтинга;
- имиджевого копирайтинга;
- продающих текстов;
- SEO-копирайтинга.
Теперь давайте рассмотрим каждый вид по отдельности.
1. Рерайт (рерайтинг)
Он относится к простому виду проработки материала для статьи. Его цель – переработать один текст в другой. Напрашивается вопрос: зачем это нужно и кому? Каждый текст по-разному ранжируется (то есть сортируется) поисковыми системами. Когда роботы поисковых систем обработают статью, она начинает свое продвижение по ТОПу с выдачей конкретных запросов.
Текст неуникальный или контент низкого уровня уникальности не сможет получить высокий рейтинг (иногда встречаются исключения) и поисковая система не продвинет их на первые места. Пользователи не дойдут до сайтов с копипастом, а их рейтинг понизится, трастовость сайта упадет.
Исключения: сайты агрегаторы, которые копируют быстро чужой контент и это дает им продвижение и возможность занимать первые строки поисковиков. Но копирайтер к ним отношения не имеет, а на обычные сайты — контент качественный необходим постоянно.
2. Имиджевый копирайтинг
Сложным видом копирайтинга выступает имиджевый. Чтобы написать статью автор изучает психологию продаж и маркетинг
Тут важно пройти обучение у коучей, получить их опыт, отработать его на каком-нибудь проекте и презентовать свои услуги, как специалиста с высоким уровнем знаний и владения маркетинговыми технологиями
Мало знать основы уникальности, нужно понимать какие триггеры работают, как их грамотно использовать и что будет «дорогим» приемом, а что «дешевым».
Владельцы компаний среднего и малого бизнеса пользуются услугами агентств, которые смогут создать имидж.
3. Продающие тексты
У этих текстов коммерческая задача. Они увеличивают продажи товара/услуги, служат вспомогательным инструментом, но не могут заменить продукт. Если текст обалденный, но товар плохой, то продажи расти не будут. Текст помогает сделать выбор, он не должен обманывать покупателя и описывать те свойства товара или услуги, которыми не обладает.
4. SEO-копирайтинг
Что такое SEO-копирайтинг? Это не просто написание информационной статьи, это использование в них специальных ключевых слов. Если копирайтер может органично и грамотно вставить ключевые слова в текст – он ценится на этом рынке.
В сложные темы контента ключевые слова вписываются с трудом. Логично использовать структуру текста с вопросами к содержанию, ответы дадут пользователю нужную информацию.
SEO-копирайтинг направлен на продвижение статьи в ТОПе поисковой системы. Но из-за новых фильтров Яндекса (Баден-Баден), с ключами стараются не баловаться и не спамить тексты. Алгоритмы становятся умнее и распознать нелогично вставленные слова им легче.
Обратим внимание на биржу копирайтинга — Content Monster. Ее хвалят и говорят, что она тщательно отбирает авторов
Да, это так. Но есть среди авторов и друзья между собой, поэтому взяв тексты, он может передать их кому-либо еще. С этим нужно бороться и жаловаться администраторам об обмане.
А если повезло найти хороших, ответственных исполнителей, их нужно ценить и поощрять, чтобы они писали качественные статьи, которые потом принесут максимум пользы и трафика.
Биржа копирайтинга ContentMonster
Зачем нужны частоты
Частотный словарь может быть полезен на практике для изучающих иностранный язык: конечно, не стоит заставлять человека, когда он узнает новое слово, выяснять точно, какое именно место в частотном списке оно занимает, но можно дать ему представление о том, стоит ли вообще это слово запоминать. Например, в словарях издательства Macmillan есть два типа слов: красные и чёрные, причём у красных слов стоят еще звездочки — одна, две или три. Вот несколько примеров:

Красные слова с тремя звездочками занимают в частотном словаре места с 1-го по 2500-е, слова с двумя звездочками — с 2501-го по 5000-е, а слова с одной звездочкой — с 5001-го по 7500-е. Черные слова располагаются ниже 7500-го места. Для пользователя это имеет очень простые следствия. Если ты ищешь в словаре слово и видишь при нем три звездочки, выучи его обязательно: оно наверняка попадется еще много раз. Если при слове только одна звездочка, это достаточно полезное слово, но часто не пригодится. И, наконец, черные слова — совсем редкие; их стоит заучивать, только если стремишься выучить язык на продвинутом уровне, но если не получится, то ничего страшного. Можно прекрасно говорить по-английски, не зная, что thatch значит «соломенная крыша», а crescent — «полумесяц»; без слов restriction «ограничение» и allegedly «якобы» тоже можно прожить, а вот слова animal «животное» и play «играть» точно надо знать.
Еще одна важная область, в которой применяется частотный анализ, — это автоматическая обработка текста (natural language processing)
Например, для проверки орфографии и исправления опечаток очень важно понимать, какие слова редкие, а какие — частотные. Предположим, что пользователь напечатал такую английскую фразу:
Мы прекрасно понимаем, что в ней содержится опечатка: вместо teh должно быть написано the. Но ведь teh могло легко получиться и из чего-нибудь другого: что если пользователь хотел ввести ten, но случайно попал в букву h вместо n? Или, может быть, он хотел напечатать tech, но пропустил букву c? Почему же мы всё-таки полагаем, что имелось в виду слово the, в котором переставились две буквы? Можно, конечно, долго рассуждать о том, что с ten и с tech получится неправильное предложение (например, ten black dog — плохое сочетание слов, а должно быть ten black dogs), но это знание трудно формализовать и вложить в компьютер. Но можно поступить проще: заглянем в частотный словарь, и он сообщит нам, что the — самое популярное английское слово, так что вероятность того, что пользователь хотел напечатать именно его, особенно велика. Эта стратегия — всегда исправляй опечатку на самое частотное из похожих слов — может показаться примитивной, но она неплохо работает.
Just Magic
Следующий сервис Just Magic:
- дает больше всего данных по длинным запросам (более 2х слов);
- позволяет анализировать, в том числе, разбавленные вхождения;
- анализирует большее количество вхождения зон ключа. Здесь уже, по крайней мере, появились анкоры исходящих ссылок, но почему-то исчез H1. Зато появилась разбивка на текстовые фрагменты и plain-текст;
- можно на входе фильтровать те документы, по которым проводить анализ.
И вот появляется рекомендация добавить слово «анализ» 40 раз и «операция» 10 раз. Самое интересное, поскольку ранее вручную уже проанализировали те документы, которые находятся в ТОПе, известно, что нигде такого количества вхождений нет. И числа эти 40 и 10 не являются ни средними значениями, ни медианами. Откуда они взяты, непонятно.

Морфологический анализ
| Название | Метод | Языки | Лицензия | Платформа |
|---|---|---|---|---|
| словарный | русский, английский, немецкий | LGPL | Linux, Windows | |
| Snowball | алгоритм Портера | русский, английский | BSD | Linux, Windows |
| Stemka | словарный | русский | Собственная | Linux, Windows |
| pymorphy | словарный | русский, английский, немецкий | MIT | Python |
| Myaso | алгоритм Витерби | русский, английский | MIT | Ruby |
| Eureka Engine | машинное обучение | русский | Коммерческая | Веб-сервис |
| машинное обучение | русский, английский | Бесплатная для исследовательских целей + коммерческая | Веб-сервис, Java, Python | |
| русский, английский | LGPLv3 + некоммерческая | Python, C++ | ||
| словарный | русский, английский, немецкий | LGPL | PHP | |
| словарный | русский, английский, украинский | Non-Commercial Freeware | .NET, .NET Core, Java и Python | |
| FreeLing | словарный | русский, англиский, итальянский, испанский, португальский, астурийский, валийский, галисийский, каталанский | GPL + Коммерческая | Linux |
| машинное обучение | английский | Apache License | Python | |
| машинное обучение | английский | MIT | Python | |
| машинное обучение | английский | GPL | Python | |
| правила, регулярные выражения | английский, испанский, немецкий, французский, итальянский, нидерландский | BSD | Python | |
| правила | английский, французский, японский | MIT | Node.js | |
| словарный | русский, английский | MIT | Linux | |
| алгоритм Витерби | английский, корейский | BSD | Linux, Windows | |
| метод опорных векторов | русский, английский | LGPL | Perl | |
| машинное обучение | английский | GPL | Java | |
| машинное обучение | английский, немецкий, арабский, китайский | GPL | Java | |
| словарный | русский | Apache License | Java | |
| словарный | русский | GPL | Java | |
| mystem | словарный | русский | Некоммерческая | Linux, Windows |
| TreeTagger | деревья принятия решений | русский, английский, немецкий, французский, итальянский, нидерландский, испанский, болгарский, греческий, португальский, китайский, суахили, латинский, эстонский | Некоммерческая | Linux, Windows |
| алгоритм Витерби | русский, английский | Некоммерческая | Linux | |
| словарный | русский, украинский | Коммерческая | Windows, Веб-сервис | |
| словарный | русский | Коммерческая | Windows | |
| словарный, правила | русский, английский | Коммерческая | Windows | |
| словарный | русский, английский | Коммерческая | Linux, Windows | |
| словарный | русский, украинский, английский, французский, немецкий, испанский, итальянский, португальский | Коммерческая | Windows | |
| словарный | русский | н/д | Windows | |
| словарный | русский | MIT + некоммерческая | Java on Linux, Windows | |
| машинное обучение, словарный | русский | некоммерческая | .NET on Linux, Windows | |
| машинное обучение, словарный | английский | некоммерческая | .NET on Linux, Windows |
Профессия копирайтер: плюсы и минусы
Профессия копирайтера имеет свои плюсы и минусы. Самый большой плюс заработка на написании текстов – это хорошая перспективность. Конечно, никто не говорит, что через месяц копирайтер будет заниматься SEO продвижением компании, но по крайней мере работать с дорогостоящими темами для статей уже сможет. Так же, с обретением навыков можно будет задуматься о самостоятельном творчестве, например открытие своих курсов по копирайтингу.
Свободная работа станет ещё одним преимуществом этой профессии. Ведь копирайтер может работать в любом удобном для себя месте. Главное, заказ выполнить в срок и иметь доступ в интернет, чтобы его выслать заказчику.
При этом копирайтеры неплохо зарабатывают. Если найти заказчика, который поставит хорошие расценки, то можно сказать, что при желании копирайтеры могут заработать 2-3 раза больше, чем обычные офисные работники. Так как зарплата у таких специалистов обычно сдельная.
Так же копирайтеры, в познании своей профессии, расширяют кругозор знаний. Ведь чтобы написать текст на какую-то определённую тему, нужно эту тему знать, хотя бы на базовом уровне. Например, если заказчик даёт тему статьи: «органическое продвижение сайта в Яндексе» соответственно в такой теме мало будет общих слов. Поэтому копирайтер начинает искать ресурсы для написания статьи, читает их и на основании этой информации пишет свой уникальный текст.
Но не смотря на все, вышеперечисленные плюсы работы копирайтером, это профессия подходит далеко не всем. Это связано и с требованиями к копирайтеру, которые мы уже перечислили и с умением формировать свои мысли чётко и понять. Человек должен уметь логически мыслить, строить предложения, писать качественно, чтобы завлечь пользователя.
Ещё, работа в сфере копирайтинга – очень конкурентная деятельность. Так как эта профессия является одним из способов заработка фрилансеров которые уже более опытны в своём деле – вести конкуренцию, при этом «держать» клиентов очень трудно, по началу.
Vaal
Данная программа анализирует, насколько чувственно и эмоционально написан твой текст. Только на русском и украинском языке. Это не онлайн-сервис, а скачиваемая программа. После проверки через нее твой тест получит штампы «медлительного», «эмоционального» и даже «тихого». Довольно забавно. Кстати, программа может автоматически оценивать текст прямо во время его написания в Word. Однако и она не совершенна. Не указывается, какие именно слова или обороты влияют на эмоциональную окраску текста, поэтому непонятно, что делать с полученной информацией. Переписывать бесконечно тоже не выход.
Параметры SEO анализа текстов
Обычно SEO анализ текстов сайта проводится по следующим параметрам:
- Плотность ключевых слов и фраз: процентный объем ключевых слов и/или фраз в тексте по отношению к полному объему текста в символах без пробелов;
- Тошнота текста (заспамленность): этот показатель определяет, как часто в тексте используются ключевые слова;
- Тошнота классическая: рассчитывается извлечением квадратного корня из количества повторений самого употребляемого слова.
- Водность: это количество в тексте стоп-слов, связок слов и не смысловых фразеологических оборотов. Водность до 15% считается отличной, от 15 до 30 % водность текста близка к критической, более 30% означает, что текст требует переписки.
- К SEO показателям так же относятся: размер текста в символах с пробелами и без пробелов и главное, уникальность текста.