Функции систем управления базами данных (субд)
Содержание:
- Создаем базу данных
- В чём преимущества
- Классификация баз данных
- Система управления базами данных Мicrosoft Ассеss
- Распространенные угрозы безопасности
- Виды моделей данных
- Требования к проектированию БД
- Индексы
- Результаты
- Основные характеристики баз данных
- Классификация СУБД
- Функции и классификация СУБД
- Состав СУБД
- Заключение
- Заключение
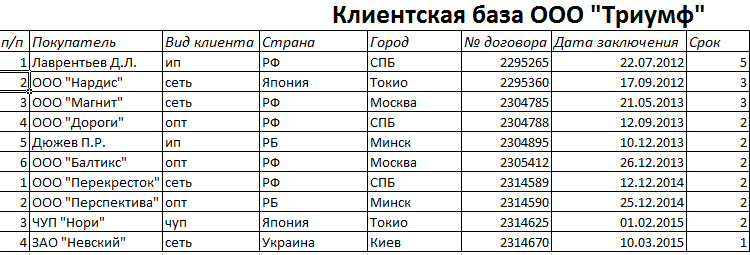
Создаем базу данных
Управление базами данных как объектами
Будем считать, что наша небольшая экскурсия по запросам и командам SQL со стороны «торгового зала» завершена. Заглянем теперь в его «служебные помещения» и познакомимся с тем, как создается сама база данных. Эта часть языка SQL не столь стандартизирована и сильно отличается в различных реализациях. Поэтому в дальнейших примерах я буду придерживаться синтаксиса, принятого в самой популярной на веб-серверах системе — MySQL.
MySQL — продукт шведской компании MySQL AB. Ее основатели — Дэвид Аксмарк, Аллан Ларсон и Майкл Видениус (последний больше известен по прозвищу — Монти). По одной из версий, первая часть названия продукта (My) — не что иное, как англизированная запись имени дочери М. Видениуса. Однако точно за происхождение названия сегодня не могут поручиться даже отцы-создатели. Существует версия, по которой «my» — это префикс, с которого начинались названия рабочих каталогов на их компьютерах.
Из всех команд чаще всего нам будут нужны три: CREATE (создать), ALTER (изменить) и DROP (уничтожить).
Чтобы создать новую базу данных с названием, ну скажем, OUR_SHOP, следует выполнить команду:
Еще лучше сразу при ее создании установить нужную кодировку (ведь по умолчанию в MySQL используется latin1). В итоге команда будет выглядеть так.
Если вы забыли сделать это сразу, не беда. Для того и существуют команды по изменению:
Когда, наигравшись вдоволь с пробной базой данных, вы захотите ее уничтожить, воспользуйтесь командой:
Управление таблицами
Чтобы создать таблицу GOODS, на которой мы отрабатывали манипуляции с данными, потребуется составить команду примерно такого вида:
Разберем эту команду подробнее. Тип INT устанавливается для столбцов с целочисленными данными, тип VARCHAR(100) обеспечивает хранение строк с длиной не более 100 символов, DECIMAL(10,2) соответствует действительным числам с не более чем десятью знаками и точностью в два знака после запятой.
Столбец ID объявлен первичным ключом (PRIMARY KEY).
Ключевое слово AUTO_INCREMENT означает, что при добавлении новых строк с неуказанным значением ID оно будет автоматически заполняться следующим значением. Это удобно, поскольку обычно нет нужды вручную указывать значения первичных ключей, а за тем, чтобы они были уникальными, пусть лучше следит база данных.
NOT NULL означает запрет на пустые значения в столбце, иными словами, гарантирует обязательность заполнения.
Команда DEFAULT задает значение по умолчанию — то, которое будет записываться в базу при добавлении новой строки, если не указано иное. В нашем случае она обеспечивает автоматическое объявление товара штучным (код = 1) в случае, если при добавлении новых строк не будет указан другой код.
Признак UNIQUE обеспечивает уникальность значений в колонке (в нашем случае — уникальность названий товаров).
Если в будущем вы захотите перенастроить объявленные командой CREATE столбцы таблицы, сделать это можно командой ALTER. Например, таблицу GOODS можно нарастить строчной колонкой REMARK (подкоманда ADD):
Поработав с ней немного и убедившись, что 50 символов для примечания явно недостаточно, увеличиваем максимальный размер строки до 250 (блок CHANGE):
Так как имя столбца мы не изменяли (новое совпадает со старым), то его просто повторяем в этой команде (как бы меняем само на себя).
И наконец, убедившись через какое-то время, что без примечания в товарном справочнике вполне можно обойтись, мы удаляем ставшую ненужной колонку (блок DROP):
Удалить таблицу целиком можно командой DROP:
Стоит ли говорить о том, что пользоваться командами с этим ключевым словом следует с особой осторожностью?
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Классификация баз данных
Информационные базы данных могут быть классифицированы по типу сохраняемой информации на:
- Фактографические базы данных. Это информационные базы, содержащие краткий набор сведений об изучаемых объектах, отображаемых в заданном формате.
- Документальные базы данных. Это базы, содержащие документацию самых разных типов, то есть это может быть текст, графика, звуковые файлы, мультимедиа и так далее.
По методу хранения информации базы данных классифицируются следующим образом:
- Централизованные базы данных, то есть хранимые в одном компьютерном устройстве.
- Распределённые базы данных, то есть используемые в локальной или глобальной компьютерной сети.
По структурной организации данных информационные базы могут классифицироваться на:
-
Табличные (реляционные) базы данных.
-
Не табличные (не реляционные) базы данных, которые в свою очередь подразделяются на:.
- иерархические,
- сетевые.
Понятие «реляционный» (от латинского relatio, что означает отношение) обозначает, что данный метод информационного хранения базируется на взаимном отношении составляющих базу элементов. Реляционная база данных, по существу, является двумерной таблицей, каждая строка которой именуется записью. А столбцы таблицы являются полями, причём все поля имеют свои имена и тип данных. То есть, поле базы данных представляет собой табличный столбец, который содержит величины, имеющие определённые свойства.
Базы данных, сформированные на основе реляционной модели, обладают следующими свойствами:
- Любой табличный компонент является одним компонентом данных.
- Все табличные поля обладают одним и тем же типом, то есть являются однородными.
- В таблице не может быть одинаковых записей.
- Допускается произвольный порядок табличных записей, и он может быть охарактеризован числом полей и типом данных.
Под «иерархической» понимается база данных, в которой информационные данные упорядочены по такому принципу, что один компонент назначается главным, а все другие являются подчинёнными. При иерархической модели базы данных упорядочивание записей выполняется в определённой последовательности, подобно ступеням лестницы, а информационный поиск может быть осуществлён путём последовательного «спуска» по ступеням. Такой тип модели может характеризоваться такими параметрами, как уровень, узел, связи. Принцип действия этой модели заключается в том, что определённый комплект узлов более низкого уровня объединяются с помощью связи с одним из узлов более высокого уровня.
Замечание 1
Узел является информационной моделью компонента, который расположен на данном иерархическом уровне.
Иерархическая модель данных обладает следующими свойствами:
- Ряд узлов низшего уровня соединяется лишь с одним из узлов высшего уровня.
- Дерево иерархии обладает только одной вершиной и не подчиняется никаким другим вершинам.
- Все узлы обладают своими идентификаторами (именами).
- Имеется лишь один путь по направлению от корневой записи к частным записям данных.
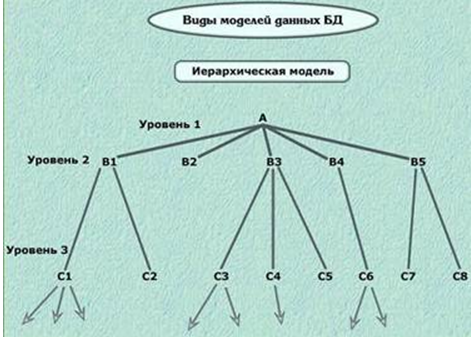 Рисунок 1. Виды моделей данных БД. Автор24 — интернет-биржа студенческих работ
Рисунок 1. Виды моделей данных БД. Автор24 — интернет-биржа студенческих работ
Каталог папок Windows считается иерархической базой, с которой возможно работать после запуска Проводника. Верхний уровень — это папка «Рабочий стол». Уровнем ниже, то есть на втором уровне, расположены папки «Мой компьютер», «Мои документы», «Сетевое окружение» и «Корзина», являющиеся потомками папки «Рабочий стол» и близнецами, по сути.
Сетевыми считаются базы данных, в которых к вертикальным связям иерархии прибавляются горизонтальные связи. Все объекты могут являться как главными, так и подчинёнными. Всемирная глобальная компьютерная сеть Интернет практически может считаться сетевой базой данных. При помощи гиперссылок огромное количество документов может быть связано между собой в единую распределённую сетевую информационную базу данных.
Система управления базами данных Мicrosoft Ассеss
Введение
Мicrosoft
Ассеss
обладает всеми чертами классической
системы управления
базами данных (СУБД). Ассеss
— это не только мощная,
гибкая и простая в использовании СУБД,
но и система для разработки приложений
баз данных. К числу наиболее мощных
средств
Ассеss
относятся средства разработки объектов
— мастера,
которые
можно использовать для создания таблиц,
запросов, различных типов форм и отчетов.
К областям применения
Мicrosoft
Ассеss
можно
отнести следующие:
* в
маломбизнесе
(бухгалтерский
учет, ввод заказов, ведение информации
о клиентах, ведение информации о деловых
контактах);
-
в
работе по контракту (разработка
внутриотраслевых приложений, разработка
межотраслевых приложений); -
в крупных
корпорациях (приложения
для рабочих групп, системы обработки
информации);
* в
качестве персональной СУБД (справочник
по адресам, ведение инвестиционного
портфеля, поваренная книга, каталоги
книг, пластинок, видеофильмов и т. п.).
Рассмотрим основные
определения, связанные с разработкой
баз данных.
База данных (БД,
database,
DВ)
— совокупность
взаимосвязанных данных, используемых
под управлением СУБД.
В самом общем
смысле база
данных —
это набор записей и файлов, организованных
специальным образом.
Система
управления базой данных (СУБД, DВМS)
—
программная
система, обеспечивающая определение
физической и логической
структуры базы данных, ввод информации
и доступ к ней.
Возможности СУБД:
система управления базами данных
предоставляет возможность контролировать
задание структуры и описание данных,
работу с ними и организацию коллективного
пользования информацией. СУБД также
существенно увеличивает возможности
и облегчает каталогизацию и ведение
больших объемов хранящейся в многочисленных
таблицах информации. СУБД включает в
себя три основных типа функций: определение
(задание структуры и описание) данных,
обработки данных и управление данными.
Определение
данных. Определяется,
какая именно информация будет храниться
в базе данных, задается структура данных
и их тип (например, количество цифр или
символов), а также указывается то, как
данные будут связаны между собой.
Задаются форматы и критерии проверки
данных.
Обработка данных.
Данные можно
обрабатывать различны ми способами.
Можно выбирать любые поля, фильтровать
и сортировать данные. Можно объединять
данные с другой связанной информацией
и вычислять итоговые значения.
Управление
данными. Указываются
правила доступа к данным, их
корректировки и добавления новой
информации. Можно также определить
правила коллективного пользования
данными.
Распространенные угрозы безопасности
Примечательно, что именно количество патчей позволяет косвенно определить степень защиты информации в системах управления базами данных и выявить наиболее распространенные уязвимости. Так, исследование Trustwave показало, что в 2016 году пользователи СУБД чаще всего сталкивались с такими категориями киберугроз, как:
- Несанкционированное расширение привилегий. Эти уязвимости позволяли неуполномоченным лицам использовать права администратора, получая доступ к таблицам и конфигурациям БД.
- Переполнение буфера. Это приводило к поломке сервера, что подрывало аппаратную защиту базы данных, а также вызывало отказ в обслуживании и могло привести к запуску исполнения чужого вредоносного кода.
- Полномочия, настроенные по умолчанию. Учетные записи администратора, оставленные с паролем, заданным по умолчанию, могли дать дополнительный простор для мошеннических действий киберпреступников.
***
Таковыми оказались результаты недавних исследований. Очень надеемся, что в будущем системы управления базами данных станут более безопасными, а в топах популярности СУБД появятся новые названия. Обещаем следить за новостями и держать вас в курсе последних тенденций.

Виды моделей данных
Организация данных рассматривается с позиций той или иной модели данных. Модель данных является ядром любой базы данных. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных – совокупность структур данных, ограничений целостности и операций манипулирования данными. Модели используются для представления данных в информационных системах.
Различают три типа моделей данных, которые имеют множества допустимых информационных конструкций:
- иерархическая;
- сетевая;
- реляционная.
Иерархическая модель данных
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен на рисунке:
Основные понятия иерархической структуры
Это – узел, уровень и связь.
Узел – это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне.
Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, как видно из рисунке, для записи С4 путь проходит через записи ВЗ к А.
Пример иерархической структуры:
Сетевая модель данных
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
На рисунке изображена сетевая структура базы данных в виде графа.
Пример сетевой структуры:
Примером сложной сетевой структуры может служить структура базы данных, содержащей сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС. Графическое изображение описанной в примере сетевой структуры состоит только из двух типов записей.
Реляционная модель данных
Понятие реляционный (англ. relation – отношение) связано с разработками известного американского специалиста в области систем баз данных Е.Кодда.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
- каждый элемент таблицы – один элемент данных;
- все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
- каждый столбец имеет уникальное имя (заголовки столбцов являются названиями полей в записях);
- одинаковые строки в таблице отсутствуют;
- порядок следования строк и столбцов может быть произвольным.
Отношение – это плоская таблица, содержащая N столбцов, среди которых нет одинаковых. N – это степень отношения, или арность отношения. Столбец отношения соответствует атрибуту сущности. Кортеж – строка отношения (соответствует записи в таблице).
Пример реляционной модели
| № личного дела | Фамилия | Имя | Отчество | Дата рождения | Группа |
| 16493 | Сергеев | Петр | Михайлович | 01.01.90 | 112 |
| 16593 | Петрова | Анна | Владимировна | 15.03.89 | 111 |
| 16693 | Антохин | Андрей | Борисович | 14.04.90 | 112 |
Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, а столбцы – атрибутам отношений, доменам, полям.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем).
Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ. В примере ключевым полем таблицы является «№ личного дела».
Требования к проектированию БД
О видах и особенностях реляционных БД мы уже поговорили. Теперь давайте подробнее обсудим сложности их проектирования. В данном случае этот процесс начинается с постановки задач, исходя из нужных требований, особенностей использования, недостатков либо достоинств той либо иной системы управления. В случае с СУБД MySQL необходимо правильно составить общую структуру.
Требования обычно следующие:
1. База данных должна быть относительно простой в плане обработки информации.
2. Она должна быть максимально компактной и неизбыточной настолько, насколько это возможно без ущерба для функциональности.
Возможны и другие требования, причём нередко они противоречат друг другу
Именно поэтому важно найти оптимальный баланс с точки зрения архитектуры, учитывая назначение конечного продукта
Так как проектирование — важнейший процесс, им занимается проектировщик. Обычно к работе привлекают профессиональных администраторов серверов либо архитекторов БД, имеющих большой практический опыт. Нужно четко понимать, что проектируется и какие результаты должны получиться на выходе. Это бывает непросто, так как, если речь идёт о серьёзных проектах, готовая структура может включать в себя десятки и сотни таблиц, которые бывают связаны друг с другом как простыми, так и замысловатыми способами.
Результат проектирования — диаграмма или схема. Это подробное схематическое описание, в котором указываются, какие данные будут храниться, сколько столбцов в таблице, тип столбцов в таблице, как связаны таблицы между собой и многое другое. При правильном и грамотном проектировании система будет работать стабильно и без сбоев. В обратном случае ожидайте проблем, так как нет ничего хуже, чем ошибиться на этапе построения архитектуры проекта.
Если вы хотите овладеть базами данных на высоком профессиональном уровне, записывайтесь на соответствующий курс в OTUS. Практикующие эксперты научат вас особенностям управления БД и тому, как эффективно взаимодействовать с любой реляционной СУБД, используя для этого язык структурированных запросов SQL.
Индексы
Индексы – основной способ ускорения работы баз данных. Чтобы найти нужную запись, необходимо сканировать всю таблицу, на что уходит большое количество времени.
Идея индексов состоит в том, чтобы создать для столбца копию, которая постоянно будет поддерживаться в отсортированном состоянии. Это позволяет очень быстро осуществлять поиск по такому столбцу, так, как заранее известно, где необходимо искать значение.
Добавление или удаление записи требует дополнительного времени на сортировку столбца, кроме того, создание копии увеличивает объем памяти, необходимый для размещения таблицы на жестком диске.
Существует несколько видов индексов:
- Первичный ключ – главный индекс таблицы. В таблице может быть только один первичный ключ, и все значения такого индекса должны отличаться друг от друга, являться уникальными в пределах одного столбца.
- Обычный индекс – таких индексов может быть несколько.
- Уникальный индекс – уникальных индексов также может быть несколько, на значения индекса не должны повторяться.
- Полнотекстовый индекс – специальный вид индекса для столбцов типа TEXT, позволяющий производить полнотекстовый поиск.
Результаты
С индексацией
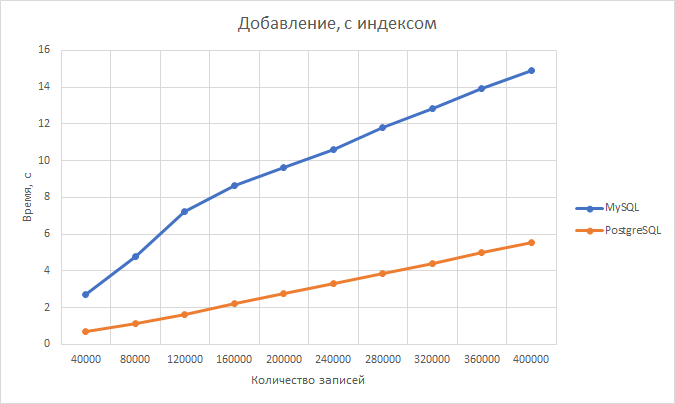
Добавление. postgresql оказался быстрее с большим отрывом в 3,46 раза.
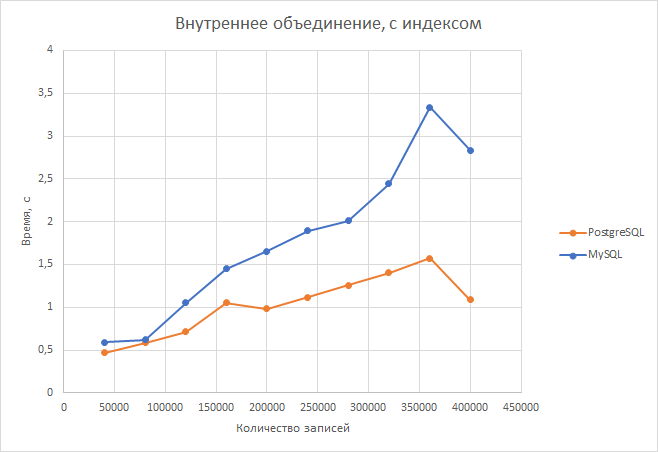
Внутреннее объединение. На небольшом количестве строк postgresql отрывается от mysql незначительно (в районе 25 процентов), но с увеличением размера второй таблицы преимущество postgresql становится более очевидным. При достижении второй таблицей максимального размера скорость объединения в postgresql уже в 2.8 раз выше. В среднем postgresql оказалась быстрее в 1,66 раза.
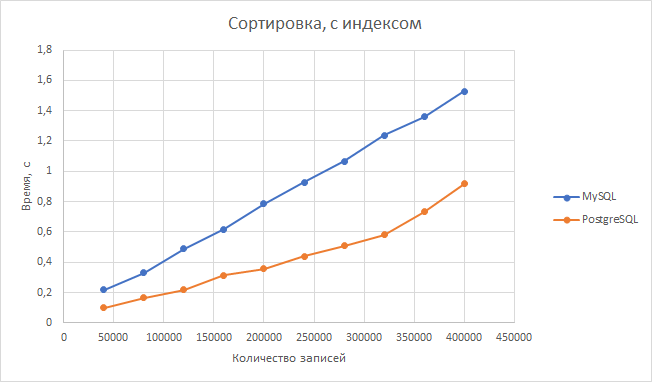
Сортировка. Postgresql быстрее на 60-100 процентов в зависимости от размера второй таблицы. В среднем postgresql быстрее в 2,04 раза.
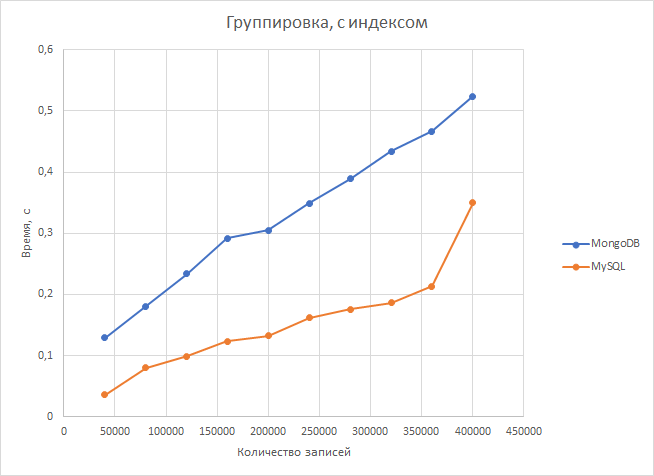
Группировка. Сначала postgresql была быстрее в 4 раза, но с ростом второй таблицы преимущество сократилось до 1.6 раз. В среднем postgresql оказалась быстрее в 2,32 раза
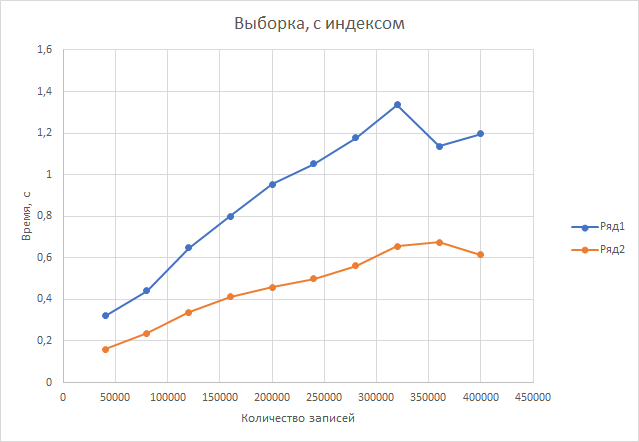
Выборка. Postgresql справляется в среднем в 1,97 раза лучше.
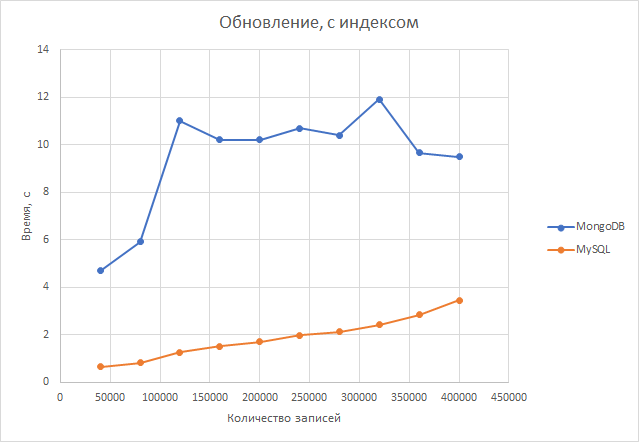
Обновление. В postgresql время обновления данных растет более-менее линейно, чего совсем не скажешь о mysql, что говорит о разной реализации двух СУБД. При обновлении максимального числа строк postgresql справилась примерно в 2.5 раза лучше, при обновлении меньше числа строк отрыв становится гораздо существеннее. Postgresql справляется в среднем в 5,72 раза лучше.
Без индексации
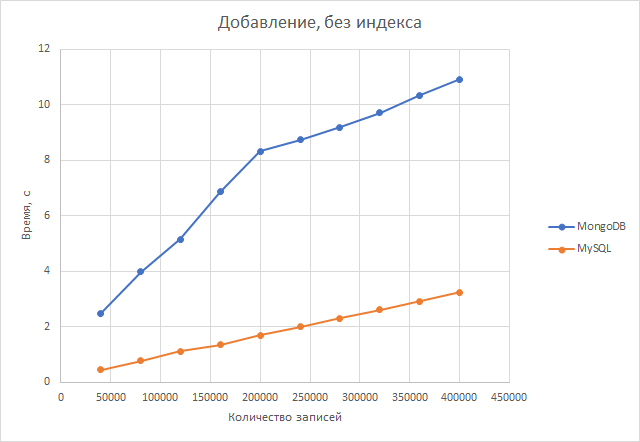
И у postgresql, и у mysql скорость добавления выросла. Оно и понятно, ведь теперь не нужно строить дополнительные индексы. Тем не менее преимущество сохраняется у postgresql (в среднем в 4,44 раза).
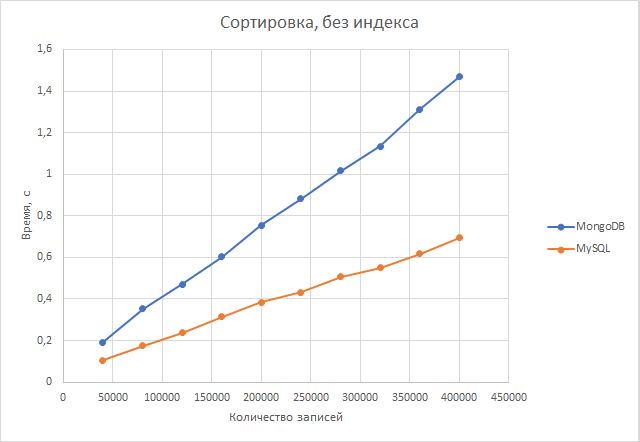
Сортировка. Postgresql быстрее в среднем в 2 раза.
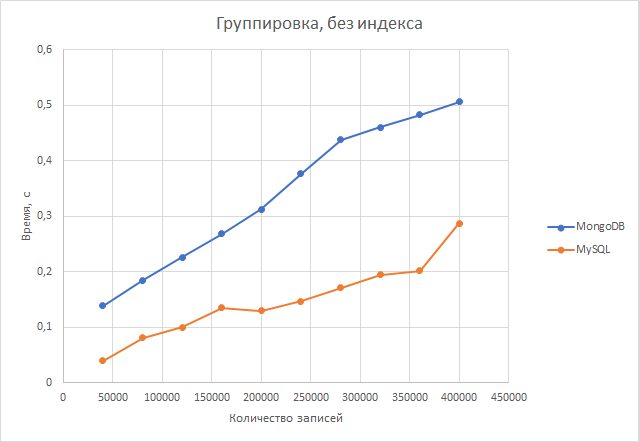
Группировка. Postgresql быстрее в среднем в 2,41 раза.
Отмена индексирования практически никак не повлияла на скорость выполнения запросов с группировкой и сортировкой как у postgresql, так и у mysql. Это говорит о том, что алгоритмы сортировки и группировки в обеих СУБД от индексов не зависят.
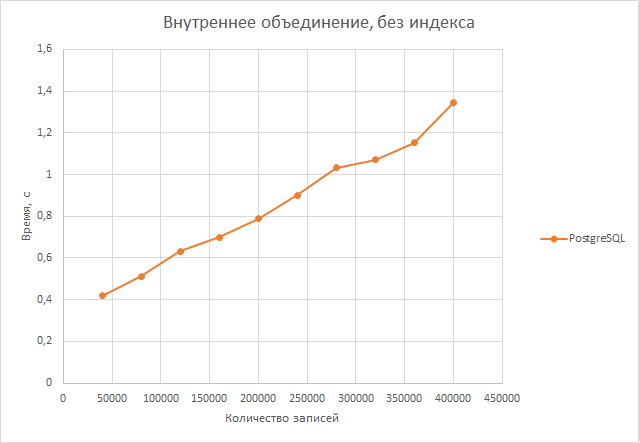
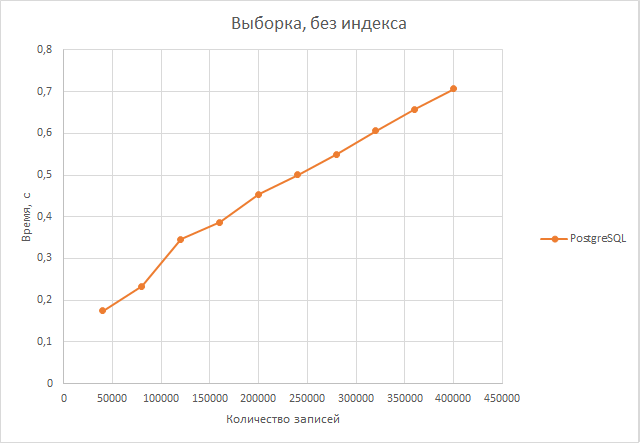
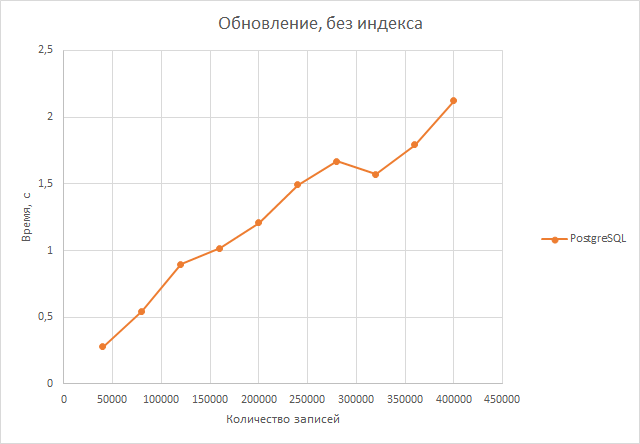
Самым же неожиданным оказался тот факт, что отмена индексов в postgresql практически не сказалась даже на скорости выполнения объединения таблиц, а также выборки из первой таблицы и ее обновления. Хотя, казалось бы, в этих тестах нам важна скорость поиска по атрибуту rand_num, а индексирование как раз и должно было ускорить этот поиск.
Для mysql же результаты тестирования объединения, выборки и обновления мы даже приводить не будем, так как уже при заполнении второй таблицы на 40000 строк на каждый запрос уходило более 400 секунд. Чего, собственно, изначально мы могли ожидать от обеих СУБД, а не только от MySQL.
Основные характеристики баз данных
MySQL — свободная реляционная система управления базами данных. Разработку и поддержку MySQL осуществляет корпорация Oracle, получившая права на торговую марку вместе с поглощённой Sun Microsystems.
PostgreSQL (произносится «Пост-Грэс-Кью-Эл») — свободная объектно-реляционная система управления базами данных (ORDBMS) (по-русски ОРСУБД или просто СУБД) основанная на POSTGRES, версии 4.2, которая была разработана в Научном Компьютерном Департаменте Беркли Калифорнийского Университета.
| Параметры | MySQL | PostgreSQL |
|---|---|---|
| Краткое описание | Широко используемая свободная реляционная система управления базами данных | Широко используемая свободная реляционная система управления базами данных |
| Основная модель хранения данных | Реляционная база данных | Реляционная база данных |
| Дополнительная модель хранения данных | База данных типа Key/Value, документно-ориентированная база данных | База данных типа Key/Value, документно-ориентированная база данных |
| Вебсайт | ||
| Документация | ||
| Разработчик | Oracle | PostgreSQL Global Development Group |
| Дата релиза | 1995 | 1996 |
| Текущая версия | 8.0.12, Июль 2018 | 10.5, Август 2018 |
| Лицензия | Открытое программное обеспечение | Открытое программное обеспечение |
| Облачное | Нет | Нет |
| Язык реализации | С++, C | C |
| Поддерживаемые операционные системы сервера | FreeBSD, Linux, Solaris, OS X, Windows | FreeBSD, Linux, Solaris, OS X, Windows, NetBSD, OpenBSD, HP-UX, Unix |
| Схема данных | Да | Да |
| Типизация | Да | Да |
| Поддержка XML | Да | Да |
| Поддержка вторичных индексов | Да | Да |
| SQL | Да | Да |
| API и другие методы доступа | Проприентарное нативное API, ADO.NET, JDBC, ODBC | Нативная С библиотека, потоковое API для больших объектов, ADO.NET, JDBC, ODBC |
| Поддерживаемые языки программирования | Ada, C, C#, С++, D, Delphi, Eiffel, Erlang, Haskell, Java, JavaScript (Node.js), Objective-C, OCaml, Perl, PHP, Python, Ruby, Scheme, Tcl | .Net, C, С++, Delphi, Java, Perl, PHP, Python, Tcl |
| Язык написания скриптов на стороне сервера | Да | Функции определенные пользователем |
| Триггеры | Да | Да |
| Методы разбиения | Горизонтальное разбиение, шардинг с MySQL Cluster или MySQL Fabric | декларативное разбиение (по диапазону или списку) начиная с PostgerSQL 10.0 |
| Методы репликаций | Master-Master, Master-Slave | Master-Slave |
| MapReduce | Нет | Нет |
| Концепции согласования | Немедленное согласование | Немедленное согласованиее |
| Параллелизм | Да | Да |
| Возможность хранения только в памяти | Да | Нет |
| Контроль доступа пользователей | Концепт пользователей с детальной авторизацией | Детальные права доступа в соответствии с SQL стандартом |
Классификация СУБД
Самым важным признаком, по которому классифицируются СУБД, является модель данных.
Как и модели данных СУБД бывают следующих видов:
- Иерархические. Самыми известными иерархическими СУБД является IMS и Cache . Модель удобна для хранения структур, которые являются иерархическими по своей природе. Иерархической является, например, структура предприятия с подчиненными подразделениями. Однако, большинство предметных областей не соответствуют иерархической структуре. Потому иерерхические СУБД не популярны и используются в основном в устаревших ИС.
- Сетевые. Известными представителями этого класса являются IDMS и CronosPRO. Данная модель является усовершенствованием иерархической. Высокая сложность и жесткость структуры базы данных также снижают популярность этого класса СУБД;
- Реляционные. На сегодняшний день реляционные базы данных и СУБД являются стандартом де-факто. Чаще всего, когда речь идет о базе данных, то подразумевается именно реляционная. На рынке ПО существует много представителей этого класса СУБД: MS SQL SERVER,IBM DB2, MySQL, PostgreSQL и т.д. ;
- Постреляционные. Постреляционная модель основана на тех же принципах, что и реляционная, но без учета требования неделимости данных. Их достоинством является более высокая скорость работы, а недостатком – сложности в обеспечении целостности данных. Типичным представителем являются СУБД uniVerse и UniData;
- No sql (нереляционные). Модель no sql отличается простотой и гибкостью. Она позволяет добавлять элементы данных в таблицы без предварительного объявления об изменении структуры. Наиболее известные представители MongoDB и CouchDB.
- Объектные. Этот класс СУБД хранит данные в виде объектов. Такой подход очень удобен для предметных областей со сложной структурой. Недостатком является необходимость использовать процедурные языки для доступа к данным. К современным объектным СУБД относятся POET, Jasmine, Versant, O2, ODB-Jupiter.
- Объектно-реляционные. Некоторые производители СУБД совмещают в своих продуктах реляционную и объектную модели. К таким «гибридам» относятся Informix Universal Server и Oracle8 Universal Data Server
- Многомерные. Если реляционная модель хранит данные в двумерных таблицах, то многомерная позволяет добавлять дополнительные измерения. В результате данных хранятся не в таблицах, а в гиперкубах. Многомерные СУБД используются в задачах анализа данных. На многомерной технологии основаны СУБД jBASE, EssBase.
Функции и классификация СУБД
СУБД выполняют следующие функции:
-
управляют данными, размещенными на дисковых носителях;
-
управляют данными в оперативной памяти с задействованием дискового кэша;
-
сохраняют историю изменений (проводят журнализацию), создают резервные копии и восстанавливают содержимое БД, поврежденное в результате некорректного завершения работы;
-
поддерживают используемые в БД языки, определяющие типы данных и манипулирующие ими.
В зависимости от того, какие способы представления и обработки данных выбирают основой для СУБД, эти системы могут относиться к:
-
иерархическим системам управления. Для этой модели характерно построение древовидной структуры данных, разделенной на различные уровни;
-
сетевым СУБД. Эта модель представляет собой расширенную версию иерархической модели не с одной записью — «предком» строго для каждого «потомка», а с несколькими, размещенными в одной сети;
-
реляционным СУБД. Эти системы управления используются в БД, представленных в виде двумерных таблиц с размещенными в них атрибутированными записями;
-
объектно-ориентированным СУБД. Эти системы управления работают с БД, в которых все данные сложно структурированы по классам и типам;
-
объектно-реляционными СУБД. Данные СУБД представляют собой комплексы, способные дополнительно выполнять объектно-ориентированные операции.
Наибольшее распространение среди существующих типов СУБД получили СУБД, работающие с реляционными базами данных. Они применяются преимущественно при создании различных web-продуктов.

Состав СУБД
Обычно современная СУБД содержит следующие компоненты:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию,
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
- сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы
Заключение
Базы данных должны обязательно быть оптимизированы для окружения, в котором они будут использоваться. Исторически так сложилось, что MySQL ориентировалась на максимальную производительность, а Postgresql разрабатывалась как база данных с большим количеством настроек и максимально соответствующую стандарту. Но со временем Postgresql получила много улучшений и оптимизаций.
В большинстве случаев для организации работы с базой данных в MySQL используется таблица InnoDB, эта таблица представляет из себя B-дерево с индексами. Индексы позволяют очень быстро получить данные из диска, и для этого будет нужно меньше дисковых операций. Но сканирование дерева требует нахождения двух индексов, а это уже медленно. Все это значит, что MySQL будет быстрее Postgresql только при использовании первичного ключа.
Вся заголовочная информация таблиц Postgresql находится в оперативной памяти. Вы не можете создать таблицу, которая будет не в памяти. Записи таблицы сортируются по индексу, а поэтому их можно очень быстро извлечь. Для большего удобства можно применять несколько индексов к одной таблице.
В целом PostgreSQL работает быстрее MySQL, как показали тесты, примерно в 2 раза.
Заключение
Для работы организаций, которым необходимо работать с грифом «секретно», возможно использовать исключительно СУБД ЛИНТЕР. Также могут использовать крупные предприятия и компании, которые стремятся надежно защитить свои данные, что на сегодняшний день очень актуально.
В то же время для обработки огромных объемов данных, где требуется высокая производительность, нет другой альтернативы, как СУБД PostgreSQL, которая является одной из ведущих на мировом рынке СУБД и по своим техническим характеристикам имеет высокий уровень.
Окончательный вывод можно сделать, что популярным зарубежным системам есть что противопоставить и чем заместить импортные СУБД.
Любую из рассматриваемых СУБД можно использовать исходя из индивидуальных требований предприятия. Выбор стоит между надежностью, безопасностью данных для работы конфиденциальной информации и высокой производительностью при обработке данных.
- cronos.ru /. – Электрон. текстовые дан. – Режим доступа: http://www.cronos.ru/, свободный.
- DB-Engines Ranking /. – Электрон. текстовые дан. – Режим доступа: https://db-engines.com/en/ranking, свободный.
- IT NEWS, 2018, № 12.
- Государственный реестр средств сертифицированных защиты информации /. – Электрон. текстовые дан. – Режим доступа: https://fstec.ru/tekhnicheskaya-zashchita-informatsii/dokumenty-po-sertifikatsii/153-sistema-sertifikatsii/591-gosudarstvennyj-reestr-sertifitsirovannykh-sredstv-zashchity-informatsii-n-ross-ru-0001-01bi00/, свободный.
- Postgresql.org /. – Электрон. текстовые дан. – Режим доступа: https://www.postgresql.org/about/licence/, свободный.
- red-soft.ru /. – Электрон. текстовые дан. – Режим доступа: http://www.red-soft.ru/, свободный.
- Единый реестр Российских программ для электронных вычислительных машин и баз данных /. – Электрон. текстовые дан. – Режим доступа: https://reestr.minsvyaz.ru/, свободный.
- СУБД ЛИНТЕР. Комплект документации. Описание применения. 2010 год.
Ключевые слова: система управления базами данных, автоматизированное рабочее место, информационная система, программное обеспечение, операционная система.
Analysis of database management systems in modern conditions
Ogorodnikova O.V., Federal State Institution “Pre-trial Detention Center No. 2” of the Office of the Federal Penitentiary Service of Russia for the city of Moscow. St. Petersburg and Leningrad region. 187500, Leningrad Region, Moscow Tikhvin, ul. Krasnoarmeyskaya, 13, senior engineer of the automation group, olga-ogorodnikova@yandex.ru
Abstract: The purpose of the article is to examine the current conditions for the possibility of using database management systems by government agencies. What kind of DBMS can you choose for today. This raises the issue of compatibility of software and operating systems. Possible variants of database management systems are also considered: PostgreSQL, CronosPro, Red Database, Linter. As a result, the choice remains for the not very popular DBMS Linter, but the only possible applicable option for a number of government agencies.
Keywords: Database management system, workstation, Information system, software, operating system.