Sql или nosql
Содержание:
- Отличия RDBMS от обычной СУБД
- Мультимодельные СУБД на основе реляционной модели
- Контроль за реляционной базой любого размера
- Основные характеристики полей реляционных БД
- Обзор самых популярных СУБД
- Модель сетевой базы данных
- Требования к проектированию БД
- Шаг 2. Избавляемся от дубликатов в столбцах
- Организация информации в реляционной базе данных
- Основное понятие реляционной базы данных
- Структурная таблица
- Структура реляционных баз данных
- Как узнать настоящую реляционную БД
- Фундаментальные модели
- Принципы создания
- SQL и NoSQL
Отличия RDBMS от обычной СУБД

СУБД хранит данные в виде файлов, тогда как RDBMS хранит данные в виде таблицы. СУБД позволяет нормализовать данные, а RDBMS поддерживает связь между данными, хранящимися в ее таблицах. Обычная СУБД не предоставляет ссылки. Она просто хранит данные своих файлов. Структурированный подход RDBMS поддерживает распределенную РБД в отличие от обычной системы управления базами данных. СУБД ориентирована на широкий спектр применений, ее особенности позволяют использовать ее во всем мире.

Особенности RDBMS:
- Общая реализация столбца, а также многопользовательский доступ включены в функции RDBMS.
- Потенциал этой модели реляционных СУБД был более чем оправдан современными возможностями применения.
- Лучшая безопасность обеспечивается созданием таблиц.
- Некоторые таблицы могут быть защищены системой.
- Пользователи могут устанавливать барьеры доступа к контенту. Это очень полезно в компаниях, где менеджер может решить, какие данные предоставляются сотрудникам и клиентам. Таким образом, можно настроить индивидуальный уровень защиты данных.
- Обеспечение будущих требований, поскольку новые данные могут быть легко добавлены к существующим таблицам и согласованы с ранее доступным содержимым. Это функция, которой нет ни в одной БД плоских файлов.
Мультимодельные СУБД на основе реляционной модели
Ведущими СУБД в настоящее время являются реляционные, прогноз Gartner нельзя было бы считать сбывшимся, если бы РСУБД не демонстрировали движения в направлении мультимодельности. И они демонстрируют. Теперь соображения о том, что мультимодельная СУБД подобна швейцарскому ножу, которым ничего нельзя сделать хорошо, можно направлять сразу Ларри Эллисону.
Автору, однако, больше нравится реализация мультимодельности в Microsoft SQL Server, на примере которого поддержка РСУБД документной и графовой моделей и будет описана.
Документная модель в MS SQL Server
О том, как в MS SQL Server реализована поддержка документной модели, на Хабре уже было две отличных статьи, ограничусь кратким пересказом и комментарием:
- Работаем с JSON в SQL Server 2016
- SQL Server 2017 JSON
Способ поддержки документной модели в MS SQL Server достаточно типичен для реляционных СУБД: JSON-документы предлагается хранить в обычных текстовых полях. Поддержка документной модели заключается в предоставлении специальных операторов для разбора этого JSON:
- для извлечения скалярных значений атрибутов,
- для извлечения поддокументов.
Вторым аргументом обоих операторов является выражение в JSONPath-подобном синтаксисе.
Абстрактно можно сказать, что хранимые таким образом документы не являются в реляционной СУБД «сущностями первого класса», в отличие от кортежей. Конкретно в MS SQL Server в настоящее время отсутствуют индексы по полям JSON-документов, что делает затруднительными операции соединения таблиц по значениям этих полей и даже выборку документов по этим значениям. Впрочем, возможно создать по такому полю вычислимый столбец и индекс по нему.
Дополнительно MS SQL Server предоставляет возможность удобно конструировать JSON-документ из содержимого таблиц с помощью оператора — возможность, в известном смысле противоположную предыдущей, обычному хранению. Понятно, что какой бы быстрой ни была РСУБД, такой подход противоречит идеологии документных СУБД, по сути хранящих готовые ответы на популярные запросы, и может решать лишь проблемы удобства разработки, но не быстродействия.
Наконец, MS SQL Server позволяет решать задачу, обратную конструированию документа: можно разложить JSON по таблицам с помощью . Если документ не совсем плоский, потребуется использовать .
Графовая модель в MS SQL Server
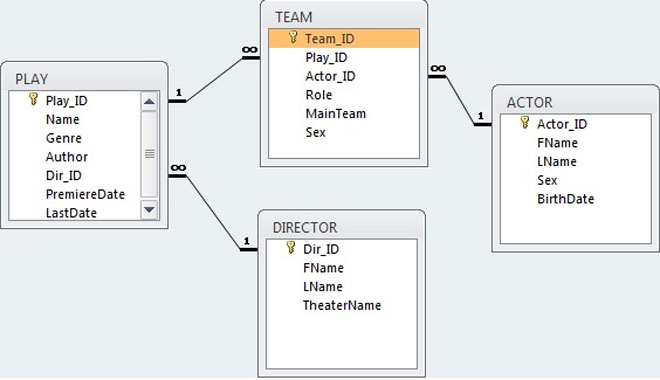
Поддержка графовой (LPG) модели реализована в Microsoft SQL Server тоже вполне предсказуемо: предлагается использовать специальные таблицы для хранения узлов и для хранения ребер графа. Такие таблицы создаются с использованием выражений и соответственно.
Таблицы первого вида сходны с обычными таблицами для хранения записей с тем лишь внешним отличием, что в таблице присутствует системное поле — уникальный в пределах базы данных идентификатор узла графа.
Аналогично, таблицы второго вида имеют системные поля и , записи в таких таблицах понятным образом задают связи между узлами. Для хранения связей каждого вида используется отдельная таблица.
Проиллюстрируем сказанное примером. Пусть графовые данные имеют схему как на приведенном рисунке. Тогда для создания соответствующей структуры в базе данных нужно выполнить следующие DDL-запросы:
Основная специфика таких таблиц заключается в том, что в запросах к ним возможно использовать графовые паттерны с Cypher-подобным синтаксисом (впрочем, «» и пр. пока не поддерживаются). Также на основе измерений производительности можно предположить, что способ хранения данных в этих таблицах отличен от механизма хранения данных в обычных таблицах и оптимизирован для выполнения подобных графовых запросов.
Более того, довольно трудно при работе с такими таблицами эти графовые паттерны не использовать, поскольку в обычных SQL-запросах для решения аналогичных задач потребуется предпринимать дополнительные усилия для получения системных «графовых» идентификаторов узлов (, , ; по этой же причине запросы на вставку данных не приведены здесь как слишком громоздкие).
Подводя итог описанию реализаций документной и графовой моделей в MS SQL Server, я бы отметил, что подобные реализации одной модели поверх другой не кажутся удачными в первую очередь с точки зрения языкового дизайна. Требуется расширять один язык другим, языки не вполне «ортогональны», правила сочетаемости могут быть довольно причудливы.
Контроль за реляционной базой любого размера
Для работы с базой данных используется специальный софт — системы управления базами данных — СУБД. Он облегчает работу с крупными базами и ускоряет процесс их настройки. Для СУБД был создан специальный язык структурированных запросов. Эти запросы содержат координаты расположения информации — названия строк и столбцов, их типы. Чем компактнее будет сформулирован запрос, тем быстрее отыщется информация.

Чтобы лучше представить себе БД реляционного типа, сравните её с чем-нибудь уже знакомым. Таблицы в excel — наглядный аналог таблицы в реляционной базе. Даже небольшой навык работы в этой программе позволит лучше представить принцип работы БД. Здесь ячейки заполняются вручную, зато визуально видна их структура.
Основные характеристики полей реляционных БД
Названия полей должны быть уникальными в рамках одной сущности. Типы атрибутов или полей реляционных баз данных описывают, данные какой категории хранятся в полях сущностей. Поле реляционной базы данных должно иметь фиксированный размер, исчисляемый в символах. Параметры и формат значений атрибутов определяют манеру исправления в них данных. Еще есть такое понятие, как «маска», или «шаблон ввода». Оно предназначено для определения конфигурации ввода данных в значение атрибута. Непременно при записи неправильного типа данных в поле должно выдаваться извещение об ошибке. Также на элементы полей накладываются некоторые ограничения – условия проверки точности и безошибочности ввода данных. Существует некоторое обязательное значение атрибута, которое однозначно должно быть заполнено данными. Некоторые строки атрибутов могут быть заполнены NULL-значениями. Разрешается ввод пустых данных в атрибуты полей. Как и извещение об ошибке, есть значения, которые заполняются системой автоматически – это данные по умолчанию. Для ускорения поиска любых данных предназначено индексированное поле.
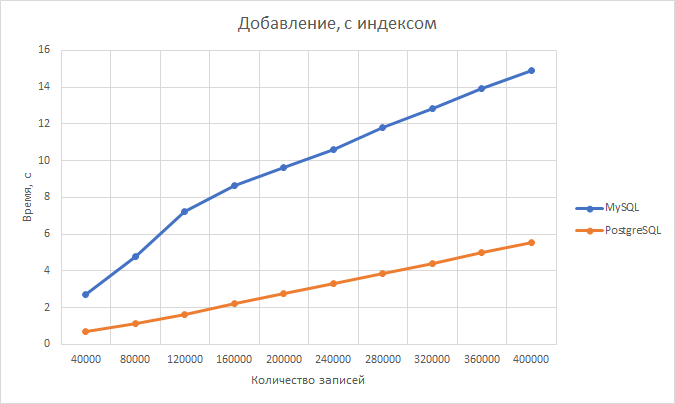
Обзор самых популярных СУБД
Самыми популярными при решении задач Data Mining являются СУБД:
-
MySQL — реляционная СУБД, имеющая открытый исходный код, позволяющая поддерживать табличные БД с простой структурой и сложными условиями запросов. Она отличается гибкостью и высокой скоростью обработки информации, простотой интерфейса и способностью синхронизации с другими БД и используется для построения прогностических моделей в e-commerce, IT и финтехе (то есть в сферах, где наиболее активно применяется Data Mining);
-
Microsoft SQL Server. Эта фирменная разработка Microsoft, подходящая к установке в ОС Windows и Linux. Ее характеризуют простой интерфейс, надежность сохранности данных и совместимость с с различными программными продуктами Windows. В интеллектуальном анализе данных эти СУБД используются главным образом для обработки данных из Microsoft Excel;
-
Oracle — объектно-реляционная СУБД с простой установкой и первоначальной настройкой, с возможностью расширения функционала. Ей присущи высокие надежность, практичность и быстродействие. В частности, в Data Mining для e-commerce эта СУБД позволяет решать задачи определения эффективности различных видов продаж и построения моделей потребностей клиентов в зависимости от ситуации на рынках;
-
PostgreSQL — объектно-реляционная СУБД, предназначенная для работы с базами данных различных сайтов и web-сервисов. Она подходит практически ко всем популярным платформам и используется в облачных сервисах.
Обучиться работе с перечисленными СУБД все желающие смогут, пройдя курс профессиональной переподготовки по программе «Инструментальные средства бизнес-аналитики», которую проводит ВШБИ НИУ ВШЭ. Записаться на обучение по данному курсу можно на нашем сайте.
Модель сетевой базы данных
Эта БД разрешает записи иметь множество родительских и дочерних форматов, способных визуализировать их в виде сетевой структуры. Напротив, в иерархической элемент реляционной СУБД имеет ряд дочерних и одну родительскую. На самом деле сетевая модель очень похожа на иерархическую, являясь ее подмножеством. Однако вместо использования одного родителя в сетевой модели используется теория множеств, обеспечивающая древовидную иерархию. Исключением является то, что дочерним таблицам можно иметь более одного родителя.
Преимущества сетевой БД:
- Концептуально проста и легка в разработке.
- Доступ к данным проще и гибче по отношению к иерархической модели и не позволяет члену существовать без родителя.
- Может обрабатывать сложные данные из-за своего отношения «многие ко многим». Это позволяет более естественное моделирование отношений между записями или объектами реляционной СУБД в отличие от иерархической.
- Благодаря своей гибкости легче перемещается и находит информацию в сетевой БД.
- Такая структура изолирует управляющие программы от сложных физических данных.
Требования к проектированию БД
О видах и особенностях реляционных БД мы уже поговорили. Теперь давайте подробнее обсудим сложности их проектирования. В данном случае этот процесс начинается с постановки задач, исходя из нужных требований, особенностей использования, недостатков либо достоинств той либо иной системы управления. В случае с СУБД MySQL необходимо правильно составить общую структуру.
Требования обычно следующие:
1. База данных должна быть относительно простой в плане обработки информации.
2. Она должна быть максимально компактной и неизбыточной настолько, насколько это возможно без ущерба для функциональности.
Возможны и другие требования, причём нередко они противоречат друг другу
Именно поэтому важно найти оптимальный баланс с точки зрения архитектуры, учитывая назначение конечного продукта
Так как проектирование — важнейший процесс, им занимается проектировщик. Обычно к работе привлекают профессиональных администраторов серверов либо архитекторов БД, имеющих большой практический опыт. Нужно четко понимать, что проектируется и какие результаты должны получиться на выходе. Это бывает непросто, так как, если речь идёт о серьёзных проектах, готовая структура может включать в себя десятки и сотни таблиц, которые бывают связаны друг с другом как простыми, так и замысловатыми способами.
Результат проектирования — диаграмма или схема. Это подробное схематическое описание, в котором указываются, какие данные будут храниться, сколько столбцов в таблице, тип столбцов в таблице, как связаны таблицы между собой и многое другое. При правильном и грамотном проектировании система будет работать стабильно и без сбоев. В обратном случае ожидайте проблем, так как нет ничего хуже, чем ошибиться на этапе построения архитектуры проекта.
Если вы хотите овладеть базами данных на высоком профессиональном уровне, записывайтесь на соответствующий курс в OTUS. Практикующие эксперты научат вас особенностям управления БД и тому, как эффективно взаимодействовать с любой реляционной СУБД, используя для этого язык структурированных запросов SQL.
Шаг 2. Избавляемся от дубликатов в столбцах
Как было оговорено выше, столбцы “username” и “following_username” содержат дубликаты данных. Они возникли в результате того, что я хотел отобразить отношения между твиттами и пользователями. Давайте улучшим нашу структуру БД, разделив существующую таблицу на две: в одной будем хранить информацию, а в другой — отношения между записями.
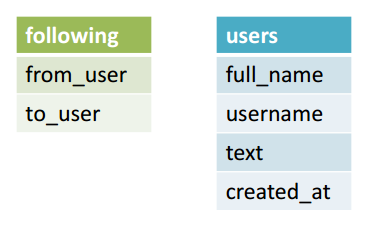
Поскольку @Brett_Englebert подписан на @RealSkipBayless, то в таблице “following” отобразим это следующим образом: имя @Brett_Englebert поместим в колонку “from_user”, а @RealSkipBayless в “to_user.” Давайте посмотрим, как будет выглядеть таблица “following” после разделения Таблицы 1:
Таблица 2. following
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | klout |
| GunnarSvalander | zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | CindyCrawford |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3. users
| full_name | username | text | created_at |
|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Уже лучше. Теперь в таблице “users” (Таблица 3) у нас хранится только информация о твиттах, а в таблице following (Таблица 2) — зависимость пользователей.
Основатель теории реляционных баз данных, Эдгар Кодд, назвал бы этот процесс (удаления повторений из столбцов таблиц) приведением БД к первой нормальной форме.
Организация информации в реляционной базе данных
Информация в реляционной базе данных организуется по следующему принципу: пары таблиц объединяются между собой при помощи совпадающих ключей (одинаковых столбцов), которые называются информационными связями. Выделяют информационные связи трех типов:
- «один к одному». Связи данного типа предполагают наличие в двух связанных таблицах только одного одинакового атрибута;
- «один ко многим». Это означает, что при данном типе связи один атрибут первой таблицы совпадает с несколькими атрибутами во второй;
- «многие ко многим». В данном случае связи между двумя таблицами устанавливаются через несколько соответствующих друг другу атрибутов.
Чтобы информация в таблицах не дублировалась и не возникало затруднений ее обновления из-за необходимости редактирования каждой записи, реляционные базы данных, базу данных требуется нормализовать. Под нормализацией понимается организация данных в БД — создание таблиц и построение связей между ними.
Чаще всего при работе с БД выполняются три основных правила нормализации, что относит базу данных к:
- первой нормальной форме. В таких БД исключаются повторяющиеся группы в отдельных таблицах, для каждого набора связанных данных создаются отдельные таблицы, каждый набор связанных данных идентифицируется при помощи первичного ключа;
- второй нормальной форме. БД, соответствующая второму правилу нормализации, имеет отдельные таблицы, связанные при помощи внешнего ключа и содержащие наборы значений, которые применяются к нескольким записям;
- третьей нормальной форме. Третье правило нормализации исключает из БД не связанные с ключами поля.
Благодаря такой организации сокращается объем избыточных данных в БД, уменьшаются затраты на ее ведение, устраняется противоречивость хранимой в базе информации и обеспечивается ее безопасность.
Узнать более подробно об организации информации в реляционных базах данных все желающие смогут в рамках профессиональной подготовки по курсу «Инструментальные средства бизнес-аналитики», которую проводит ВШБИ НИУ ВШЭ. Записаться на обучение по данному курсу можно на нашем сайте.
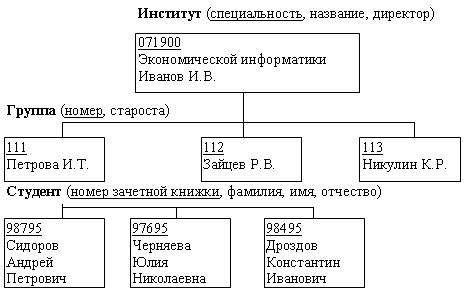
Основное понятие реляционной базы данных
Такая модель была разработана в 1970-х годах доктором науки Эдгаром Коддом. Она представляет собой логически структурированную таблицу с полями, описывающую данные, их отношения между собой, операции, произведенные над ними, а главное — правила, которые гарантируют их целостность. Почему модель называется реляционной? В ее основе лежат отношения (от лат. relatio) между данными. Существует множество определений этого типа базы данных. Реляционные таблицы с информацией гораздо проще систематизировать и придать обработке, нежели в сетевой или иерархической модели. Как же это сделать? Достаточно знать особенности, структуру модели и свойства реляционных таблиц.

Структурная таблица
Таблица — это логическая структура, состоящая из строк и столбцов. Строки не имеют фиксированного порядка, поэтому, если извлекаются данные, может понадобиться отсортировать их. Порядок столбцов указывается при создании таблицы администратором БД. На пересечении каждого столбца и строки находится определенный элемент данных, называемый значением, или, точнее, атомарным значением. Таблица именуется высокоуровневым классификатором идентификатора пользователя владельца, за которым следует имя таблицы, например TEST.DEPT или PROD.DEPT.
Существует нескольких типов таблиц:
- Базовая, которая создается и содержит постоянные данные.
- Временная, в которой хранятся промежуточные результаты запроса.
Элементы таблиц:
- Столбцы имеют упорядоченный набор: DEPTNO, DEPTNAME, MGR и ADMK DEPT. Все они должны быть однотипными данными.
- Строки — каждая содержит данные для одного отдела.
- Значения на пересечении столбца и строки. Например, PLANNING — это значение столбца DEPT NAME в строке для отдела B01.
Индекс — это упорядоченный набор указателей на строки таблицы. В отличие от строк таблицы, которые не находятся в определенном порядке, индекс DB2 должен всегда поддерживать порядок.
Индекс используется для двух целей:
- Для повышения быстродействия получения значений данных.
- Для уникальности.
Создав индекс по имени сотрудника, можно получить данные для этого сотрудника быстрее, чем сканируя всю таблицу. Кроме того, создавая его, DB2 обеспечит уникальность каждого значения. Создание индекса автоматически создает индексное пространство, набор данных, который его содержит.
Структура реляционных баз данных
Основные термины и понятия реляционных баз данных представлены:
- отношениями — двумерными таблицами, содержащими информацию о различных объектах;
- полями таблицы — столбцами таблиц, содержащими значения, характеризуемые определенными свойствами (размер, формат данных, обязательность заполнения);
- типами данных — типами значений конкретных столбцов;
- атрибутами — заголовками столбцов таблиц, характеризующими поименованное свойство объекта;
- доменами — множеством всех допустимых значений атрибута;
- кортежами — строками таблиц, записями, состоящими из логически связанных значений атрибутов;
- ячейками — структурными элементами таблиц, задающими определенные значения соответствующих полей;
- первичными ключами — полем (или набором полей) таблицы, однозначно идентифицирующим каждую из ее записей. Набор полей называется составным ключом;
- альтернативными ключами — не совпадающими с первичным ключом полями таблицы, дающими каждой записи уникальное определение;
- внешними ключами — полем или набором полей таблицы, значения в которых совпадают со значениями первичных ключей других таблиц.
Файлы реляционной базы данных имеют свои особенности:
- каждую таблицу именуют уникальным названием;
- число полей в таблицах фиксируется;
- пересечение столбца и строки представлено только одним значением;
- записи отличаются друг от друга хотя бы одним значением элемента;
- полям присваиваются индивидуальные имена;
- в каждом столбце должны содержаться однородные данные.

Как узнать настоящую реляционную БД
Таблицы реляционной базы имеют ряд отличительных особенностей. В первую очередь это особая структура. Каждая строка таблицы уникальна, не может быть двух одинаковых. Столбцы имеют строгую упорядоченность.
Наличие хотя бы одного столбца обязательное условие, даже если в таблице совсем нет строк. Каждый столбец так же должен быть с уникальным обозначением и содержать только один тип данных — дату, текст или число.

Каждая ячейка таблицы содержит только единое значение, без каких либо подгрупп
Также важной отличительной чертой реляционной базы является универсальность. Правильно организованная БД не зависит от аппаратного обеспечения компьютеров и от способов хранения информации
К тому же не должно иметь значение, хранится ли база на одном компьютере или на нескольких.
Фундаментальные модели
Возвращаясь к возникновению баз данных, стоит сказать, что этот процесс был достаточно сложным, он берет свое начало вместе с развитием программируемого оборудования обработки информации. Поэтому неудивительно, что количество их моделей на данный момент достигает более 50, но основными из них считаются иерархическая, реляционная и сетевая, которые и до сих пор широко применяются на практике. Что же они собой представляют?
Иерархическая база данных имеет древовидную структуру и составляется из данных разных уровней, между которыми существуют связи. Сетевая модель БД представляет собой более сложный шаблон. Ее структура напоминает иерархическую, а схема расширенная и усовершенствованная. Разница между ними в том, что потомственные данные иерархической модели могут иметь связь только с одним предком, а у сетевой их может быть несколько. Структура реляционной базы данных гораздо сложнее. Поэтому ее следует разобрать более подробно.
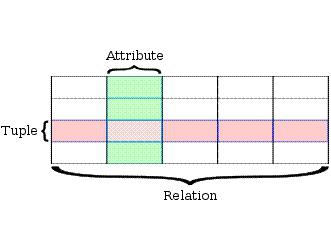
Принципы создания
Каждая таблица, которую еще называют отношением в реляционной базе СУБД, содержит один или ряд категорий данных в столбцах атрибутах. Каждая строка называется записью, или кортежем, содержит уникальный экземпляр данных или ключ для категорий, установленных столбцами. Таблица имеет уникальный первичный ключ, идентифицирующий информацию в ней. Табличная связь устанавливается с помощью внешних ключей, ссылающихся на первичные ключи иной таблицы.
Например, типичная реляционная база СУБД бизнес-заказов имеет таблицу, в которой описывается клиент, со столбцами для имени, адреса, номера телефона и другой информации. Следующая имеет заказ: продукт, клиент, дата, цена продажи и так далее. Пользователь РБД получает представление о базе данных в соответствии со своими потребностями. Например, менеджеру филиала может понравиться просмотр или отчет обо всех клиентах, которые купили товары после определенной даты. Специалист по финансовым услугам в той же компании из тех же таблиц получает отчет о счетах, которые необходимо оплатить.
SQL и NoSQL
abДва варианта представления данных
уплотнения
Масштабируемость
Тип хранилища данных
Сценарий использования
Пример
Рекомендации
Хранилище типа ключ-значение
Подходит для простых приложений, с одним типом объектов, в ситуациях, когда поиск объектов выполняют лишь по одному атрибуту.
Интерактивное обновление домашней страницы пользователя в Facebook.
Рекомендовано знакомство с технологией memcached.
Если приходится искать объекты по нескольким атрибутам, рассмотрите вариант перехода к хранилищу, ориентированному на документы.
Хранилище, ориентированное на документы
Подходит для хранения объектов различных типов.
Транспортное приложение, оперирующее данными о водителях и автомобилях, работая с которым надо искать объекты по разным полям, например — имя или дата рождения водителя, номер прав, транспортное средство, которым он владеет.
Подходит для приложений, в ходе работы с которыми допускается реализация принципа «согласованность в конечном счёте» с ограниченными атомарностью и изоляцией. Рекомендуется применять механизм кворумного чтения для обеспечения своевременной атомарной непротиворечивости.
Система хранения данных с расширяемыми записями
Более высокая пропускная способность и лучшие возможности параллельной обработки данных ценой слегка более высокой сложности, нежели у хранилищ, ориентированных на документы.
Приложения, похожие на eBay
Вертикальное и горизонтальное разделение данных для хранения информации клиентов.
Для упрощения разделения данных используются HBase или Hypertable.
Масштабируемая RDBMS
Использование семантики ACID освобождает программистов от необходимости работать на достаточно низком уровне, а именно, отвечать за блокировки и непротиворечивость данных, обрабатывать устаревшие данные, коллизии.
Приложения, которым не требуются обновления или слияния данных, охватывающие множество узлов.
Стоит обратить внимание на такие системы, как MySQL Cluster, VoltDB, Clustrix, ориентированные на улучшенное масштабирование.
этом