Регрессия в excel: уравнение, примеры. линейная регрессия
Содержание:
- Разбор результатов анализа
- Строим диаграмму рассеяния (корреляционное поле) и график линии регрессии.
- Матрица парных коэффициентов корреляции в Excel
- Регрессия В Excel
- Пример 1
- Использование MS EXCEL для расчета корреляции
- Проверяем значимость коэффициента корреляции (проверяем гипотезу зависимости).
- Анализ результатов регрессии для R-квадрата
- Как рассчитать коэффициент корреляции в Excel
- Основные задачи и виды регрессии
- Изучение результатов и выводы
Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.
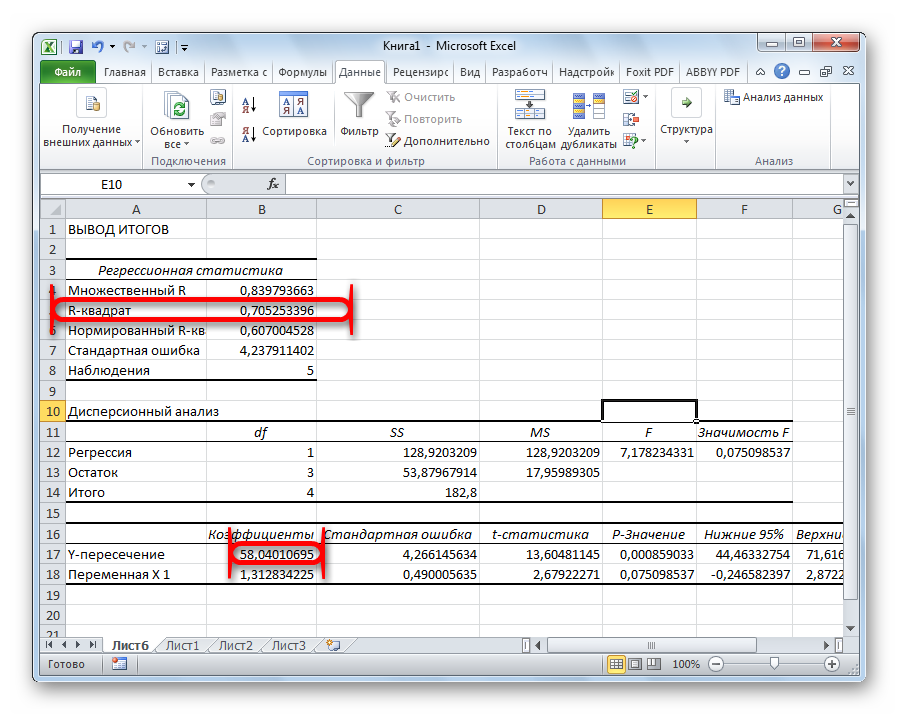
Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Строим диаграмму рассеяния (корреляционное поле) и график линии регрессии.
4.1.
Находим минимальный и максимальный элемент выборки X это 18-й и 15-й элементы соответственно, x min = 22.10000 и x max = 26.60000.
4.2.
Находим минимальный и максимальный элемент выборки Y это 2-й и 18-й элементы соответственно, y min = 29.40000 и y max = 31.60000.
4.3.
На оси абсцисс выбираем начальную точку чуть левее точки x 18
= 22.10000, и такой масштаб, чтобы на оси
поместилась точка x 15
= 26.60000 и отчетливо различались остальные точки.
4.4.
На оси ординат выбираем начальную точку чуть левее точки y 2
= 29.40000, и такой масштаб, чтобы на оси
поместилась точка y 18
= 31.60000 и отчетливо различались остальные точки.
4.5.
На оси абсцисс размещаем значения x k
, а на оси ординат значения y k
.
4.6.
Наносим точки (x 1
, y 1
),
(x 2
, y 2
),…,(x 26
, y 26
)
на координатную плоскость. Получаем диаграмму рассеяния (корреляционное поле), изображенное на рисунке ниже.
4.7.
Начертим линию регрессии.
Для этого найдем две различные точки с координатами (x r1 , y r1) и (x r2 , y r2)
удовлетворяющие уравнению (3.6), нанесем их на координатную плоскость и проведем через них прямую. В качестве абсциссы первой точки возьмем значение x min = 22.10000. Подставим значение x min в уравнение (3.6),
получим ординату первой точки. Таким образом имеем точку с координатами (22.10000, 31.96127). Аналогичным образом получим координаты второй точки, положив в качестве абсциссы значение x max = 26.60000.
Вторая точка будет: (26.60000, 30.15970).
Линия регрессии показана на рисунке ниже красным цветом
Обратите внимание, что линия регрессии всегда проходит через точку средних значений величин Х и Y, т.е. с координатами (M x , M y)
Утилита, которая широко используется во многих компаниях и на предприятиях. Реалии таковы, что практически любой работник должен в той или иной мере владеть Экселем, так как эта программа применяется для решения очень широкого спектра задач. Работая с таблицами, нередко приходится определять, связаны ли между собой определённые переменные. Для этого используется так называемая корреляция. В этой статье мы подробно рассмотрим, как рассчитать коэффициент корреляции в Excel. Давайте разбираться. Поехали!
Начнём с того, что такое коэффициент корреляции вообще. Он показывает степень взаимосвязи между двумя элементами и всегда находится в диапазоне от -1 (сильная обратная взаимосвязь) до 1 (сильная прямая взаимосвязь). Если коэффициент равен 0, это говорит о том, что взаимосвязь между значениями отсутствует.
Теперь, разобравшись с теорией, перейдём к практике. Чтобы найти взаимосвязь между переменными и у, воспользуйтесь встроенной функцией Microsoft Excel «КОРРЕЛ». Для этого нажмите на кнопку мастера функций (она расположена рядом с полем для формул). В открывшемся окне выберите из списка функций «КОРРЕЛ». После этого задайте диапазон в полях «Массив1» и «Массив2». Например, для «Массив1» выделите значения у, а для «Массив2» выделите значения х. В итоге вы получите рассчитанный программой коэффициент корреляции.

Следующий способ будет актуален для студентов, от которых требуют найти зависимость по заданной формуле. Прежде всего, нужно знать средние значения переменных x и y. Для этого выделите значения переменной и воспользуйтесь функцией «СРЗНАЧ». Далее необходимо вычислить разницу между каждым x и x ср, и y ср. В выбранных ячейках напишите формулы x-x, y-. Не забудьте закрепить ячейки со средними значениями. Затем растяните формулу вниз, чтобы она применилась и к остальным числам.
Теперь, когда есть все необходимые данные, можно посчитать корреляцию. Перемножьте полученные разности таким образом: (x-x ср) * (y-y ср). После того как вы получите результат для каждой из переменных, просуммируйте полученные числа при помощи функции автосуммы. Таким образом рассчитывается числитель.
Теперь перейдём к знаменателю. Посчитанные разности нужно возвести в квадрат. Для этого в отдельной колонке введите формулы: (x-x ср) 2 и (y-y ср) 2 . Затем растяните формулы на весь диапазон. После, при помощи кнопки «Автосумма», найдите сумму по всем колонкам (для x и для y). Осталось перемножить найденные суммы и извлечь из них квадратный корень. Последний шаг — поделите числитель на знаменатель. Полученный результат и будет искомым коэффициентом корреляции.
Матрица парных коэффициентов корреляции в Excel
Корреляционная матрица представляет собой таблицу, на пересечении строк и столбцов которой находятся коэффициенты корреляции между соответствующими значениями. Имеет смысл ее строить для нескольких переменных.
Матрица коэффициентов корреляции в Excel строится с помощью инструмента «Корреляция» из пакета «Анализ данных».
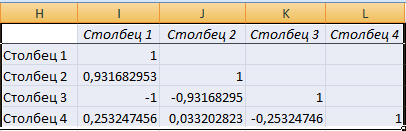
Между значениями y и х1 обнаружена сильная прямая взаимосвязь. Между х1 и х2 имеется сильная обратная связь. Связь со значениями в столбце х3 практически отсутствует.
Где x·y , x , y — средние значения выборок; σ(x), σ(y) — среднеквадратические отклонения.
Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b: , где σ(x)=S(x), σ(y)=S(y) — среднеквадратические отклонения, b — коэффициент перед x в уравнении регрессии y=a+bx .
Другие варианты формул:
или К xy — корреляционный момент (коэффициент ковариации)
Линейный коэффициент корреляции принимает значения от –1 до +1 (см. шкалу Чеддока). Например, при анализе тесноты линейной корреляционной связи между двумя переменными получен коэффициент парной линейной корреляции, равный –1 . Это означает, что между переменными существует точная обратная линейная зависимость.
Геометрический смысл коэффициента корреляции
Свойства коэффициента корреляции
- |r xy | ≤ 1;
- если X и Y независимы, то r xy =0, обратное не всегда верно;
- если |r xy |=1, то Y=aX+b, |r xy (X,aX+b)|=1, где a и b постоянные, а ≠ 0;
- |r xy (X,Y)|=|r xy (a 1 X+b 1 , a 2 X+b 2)|, где a 1 , a 2 , b 1 , b 2 – постоянные.
Инструкция
. Укажите количество исходных данных. Полученное решение сохраняется в файле Word
(см. Пример нахождения уравнения регрессии). Также автоматически создается шаблон решения в Excel
. .
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем считать взаимосвязь, или корреляцию, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность
в баллах
3 столбик — неуверенность в себе
в баллах
3.Затем необходимо выбрать пустую ячейку рядом с таблицей и нажать на значок f(x)
в панели Excel
4.Откроется меню функций, среди категорий необходимо выбрать Статистические
, а затем среди списка функций по алфавиту найти КОРРЕЛ
и нажать ОК
5.Затем откроется меню аргументов функции, которое позволит выбрать нужные нам столбики с данными. Для выбора первого столбика Агрессивность
нужно нажать на синюю кнопочку у строки Массив1
6.Выберем данные для Массива1
из столбика Агрессивность
и нажмем на синюю кнопочку в диалоговом окне
7. Затем аналогично Массиву 1 нажмём на синюю кнопочку у строки Массив2
8.Выберем данные для Массива2
— столбик Неуверенность в себе
и опять нажмем синюю кнопку, затем ОК
9.Вот, коэффициент корреляции r-Пирсона посчитан и записан в выбранной ячейке.В нашем случае он положительный и приблизительно равен 0,225
. Это говорит об умеренной положительной
связи между агрессивностью и неуверенностью в себе у детей-первоклассников
Таким образом, статистическим выводом
эксперимента будет: r = 0,225, выявлена умеренная положительная взаимосвязь между переменными агрессивность
и неуверенность в себе.
В некоторых исследованиях требуется указывать р-уровень значимости коэффициента корреляции, однако программа Excel, в отличие от SPSS, не предоставляет такой возможности. Ничего страшного, есть (А.Д. Наследов).
Также Вы можете и приложить её к результатам исследования.
Регрессия В Excel
Пакет анализаСервис/Надстройки Excel 2007Параметры ExcelПараметры Excel
Excel 2007Параметры ExcelПараметры Excel

 НадстройкиПакет анализаПерейти
НадстройкиПакет анализаПерейти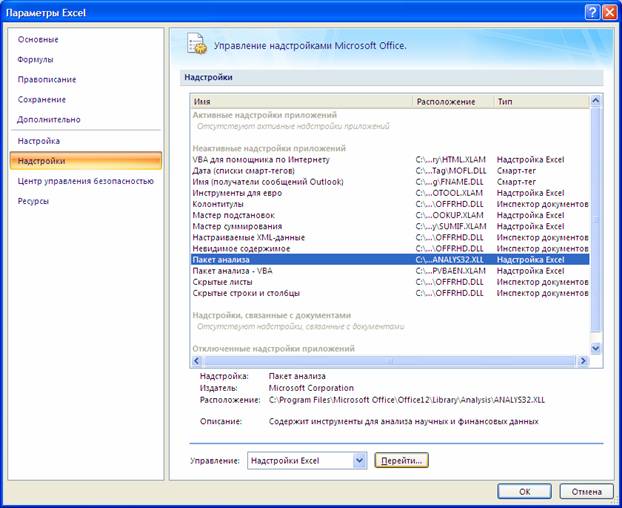
Для построения модели регрессии необходимо выбрать пункт . (В Excel 2007 этот режим находится в блоке ) Появится диалоговое окно, которое нужно заполнить:
 1) Входной интервалY ¾ содержит ссылку на ячейки, которые содержат значения результативного признака y. Значения должны быть расположены в столбце;
1) Входной интервалY ¾ содержит ссылку на ячейки, которые содержат значения результативного признака y. Значения должны быть расположены в столбце;
2) Входной интервалX ¾ содержит ссылку на ячейки, которые содержат значения факторов x1, x2, ..,xm(m≤16). Значения должны быть расположены в столбцах;
3) Признак Метки ставится, если первые ячейки содержат пояснительный текст (подписи данных);
4) Уровень надежности ¾ это доверительная вероятность, которая по умолчанию считается равной 95%. Если это значение не устраивает, то нужно включить этот признак и ввести требуемое значение;
5) Признак Константа-ноль включается, если необходимо построить уравнение, в котором свободная переменная a=0;
6) Параметры вывода определяют, куда должны быть помещены результаты. По умолчанию строит режим Новый рабочий лист;
7) Блок Остатки позволяет включать вывод остатков и построение их графиков.
В результате выводится информация, содержащая все необходимые сведения и сгруппированная в три блока: Регрессионная статистика, Дисперсионный анализ, Вывод остатка. Рассмотрим их подробнее.
1. Регрессионная статистика:
множественный R определяется формулой ;
R-квадрат вычисляется по формуле ;
Нормированный R-квадрат вычисляется по формуле ;
Стандартная ошибка S вычисляется по формуле ;
Наблюдения ¾ это количество данных n.
2. Дисперсионный анализ, строка Регрессия:
Параметр df равен m (количество наборов факторов x);
Параметр SS определяется формулой ;
Параметр MS определяется формулой ;
Статистика F определяется формулой ;
Значимость F. Если полученное число превышает α=1-p, то принимается гипотеза R2 = 0 (нет линейной зависимости), иначе принимается гипотеза R2≠0 (есть линейная зависимость).
3. Дисперсионный анализ, строка Остаток:
Параметр df равен n-m-1;
Параметр SS определяется формулой ;
Параметр MS определяется формулой .
4. Дисперсионный анализ, строка Итого содержит сумму первых двух столбцов.
5. Дисперсионный анализ, строка Y-пересечение содержит значение коэффициента a, стандартной ошибки Sb и t-статистики tb.
P-значение ¾ это значение уровней значимости, соответствующее вычисленным t-статистикам. Определяется функцией СТЬЮДРАСП(t-статистика; n—m-1). Если P-значение превышает α=1-p, то соответствующая переменная статистически незначима и ее можно исключить из модели.
Нижние 95% и Верхние 95% ¾ это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если в блоке ввода данных значение доверительной вероятности было оставлено по умолчанию, то последние два столбца будут дублировать предыдущие. Если пользователь ввел свое значение доверительной вероятности, то последние два столбца содержат значения нижней и верхней границы для указанной доверительной вероятности.
6. Дисперсионный анализ, строки x1, x2,..,xm содержат значения коэффициентов, стандартных ошибок, t-статистик, P-значений и доверительных интервалов для соответствующих xi.
Блок Вывод остатка содержит значения предсказанного y (в наших обозначениях это ) и остатки .
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а0 + а1×1 +…+аkxk, где хi — влияющие переменные, ai — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Использование MS EXCEL для расчета корреляции
В качестве примера возьмем 2 переменные Х и Y и, соответственно, выборку состоящую из нескольких пар значений (Хi; Yi). Для наглядности построим диаграмму рассеяния.

Примечание: Подробнее о построении диаграмм см. статью Основы построения диаграмм. В файле примера для построения диаграммы рассеяния использована диаграмма График, т.к. мы здесь отступили от требования случайности переменной Х (это упрощает генерацию различных типов взаимосвязей: построение трендов и заданный разброс). В случае реальных данных необходимо использовать диаграмму типа Точечная (см. ниже).
Расчеты корреляции проведем для различных случаев взаимосвязи между переменными: линейной, квадратичной и при отсутствии связи.
Примечание: В файле примера можно задать параметры линейного тренда (наклон, пересечение с осью Y) и степень разброса относительно этой линии тренда. Также можно настроить параметры квадратичной зависимости.
В файле примера для построения диаграммы рассеяния в случае отсутствия зависимости переменных использована диаграмма типа Точечная. В этом случае точки на диаграмме располагаются в виде облака.

Примечание: Обратите внимание, что изменяя масштаб диаграммы по вертикальной или горизонтальной оси, облаку точек можно придать вид вертикальной или горизонтальной линии. Понятно, что при этом переменные останутся независимыми
Как было сказано выше, для расчета коэффициента корреляции в MS EXCEL существует функций КОРРЕЛ() . Также можно воспользоваться аналогичной функцией PEARSON() , которая возвращает тот же результат.
Для того, чтобы удостовериться, что вычисления корреляции производятся функцией КОРРЕЛ() по вышеуказанным формулам, в файле примера приведено вычисление корреляции с помощью более подробных формул:
Примечание: Квадрат коэффициента корреляции r равен коэффициенту детерминации R2, который вычисляется при построении линии регрессии с помощью функции КВПИРСОН() . Значение R2 также можно вывести на диаграмме рассеяния, построив линейный тренд с помощью стандартного функционала MS EXCEL (выделите диаграмму, выберите вкладку Макет, затем в группе Анализ нажмите кнопку Линия тренда и выберите Линейное приближение). Подробнее о построении линии тренда см., например, в статье о методе наименьших квадратов.

Проверяем значимость коэффициента корреляции (проверяем гипотезу зависимости).
Поскольку оценка коэффициента корреляции вычислена на конечной выборке, и поэтому может отклоняться от своего генерального значения,
необходимо проверить значимость коэффициента корреляции. Проверка производится с помощью t
-критерия:
| t = |
|
(2.1) |
Случайная величина t
следует t
-распределению Стьюдента
и по таблице t
-распределения необходимо найти критическое значение критерия (t
кр.α) при заданном уровне
значимости α
. Если вычисленное по формуле (2.1) t
по модулю окажется меньше
чем t
кр.α , то зависимости между случайными величинами X и Y нет. В противном случае, экспериментальные
данные не противоречат гипотезе о зависимости случайных величин.
2.1.
| t = |
|
= -5.08680 |
2.2.
Искомое значение t
кр.α располагается на пересечении строки соответствующей числу степеней свободы
и столбца соответствующего заданному уровню значимости α
. В нашем случае число степеней свободы есть n — 2 = 26 — 2 = 24
и α
= 0.05
,
что соответствует критическому значению критерия t
кр.α = 2.064
(см. табл. 2)
Таблица 2 t
-распределение
|
Число степеней свободы(n — 2) |
α = 0.1 |
α = 0.05 |
α = 0.02 |
α = 0.01 |
α = 0.002 |
α = 0.001 |
| 1 | 6.314 | 12.706 | 31.821 | 63.657 | 318.31 | 636.62 |
| 2 | 2.920 | 4.303 | 6.965 | 9.925 | 22.327 | 31.598 |
| 3 | 2.353 | 3.182 | 4.541 | 5.841 | 10.214 | 12.924 |
| 4 | 2.132 | 2.776 | 3.747 | 4.604 | 7.173 | 8.610 |
| 5 | 2.015 | 2.571 | 3.365 | 4.032 | 5.893 | 6.869 |
| 6 | 1.943 | 2.447 | 3.143 | 3.707 | 5.208 | 5.959 |
| 7 | 1.895 | 2.365 | 2.998 | 3.499 | 4.785 | 5.408 |
| 8 | 1.860 | 2.306 | 2.896 | 3.355 | 4.501 | 5.041 |
| 9 | 1.833 | 2.262 | 2.821 | 3.250 | 4.297 | 4.781 |
| 10 | 1.812 | 2.228 | 2.764 | 3.169 | 4.144 | 4.587 |
| 11 | 1.796 | 2.201 | 2.718 | 3.106 | 4.025 | 4.437 |
| 12 | 1.782 | 2.179 | 2.681 | 3.055 | 3.930 | 4.318 |
| 13 | 1.771 | 2.160 | 2.650 | 3.012 | 3.852 | 4.221 |
| 14 | 1.761 | 2.145 | 2.624 | 2.977 | 3.787 | 4.140 |
| 15 | 1.753 | 2.131 | 2.602 | 2.947 | 3.733 | 4.073 |
| 16 | 1.746 | 2.120 | 2.583 | 2.921 | 3.686 | 4.015 |
| 17 | 1.740 | 2.110 | 2.567 | 2.898 | 3.646 | 3.965 |
| 18 | 1.734 | 2.101 | 2.552 | 2.878 | 3.610 | 3.922 |
| 19 | 1.729 | 2.093 | 2.539 | 2.861 | 3.579 | 3.883 |
| 20 | 1.725 | 2.086 | 2.528 | 2.845 | 3.552 | 3.850 |
| 21 | 1.721 | 2.080 | 2.518 | 2.831 | 3.527 | 3.819 |
| 22 | 1.717 | 2.074 | 2.508 | 2.819 | 3.505 | 3.792 |
| 23 | 1.714 | 2.069 | 2.500 | 2.807 | 3.485 | 3.767 |
|
24
|
1.711 |
2.064
|
2.492 | 2.797 | 3.467 | 3.745 |
| 25 | 1.708 | 2.060 | 2.485 | 2.787 | 3.450 | 3.725 |
| 26 | 1.706 | 2.056 | 2.479 | 2.779 | 3.435 | 3.707 |
| 27 | 1.703 | 2.052 | 2.473 | 2.771 | 3.421 | 3.690 |
| 28 | 1.701 | 2.048 | 2.467 | 2.763 | 3.408 | 3.674 |
| 29 | 1.699 | 2.045 | 2.462 | 2.756 | 3.396 | 3.659 |
| 30 | 1.697 | 2.042 | 2.457 | 2.750 | 3.385 | 3.646 |
| 40 | 1.684 | 2.021 | 2.423 | 2.704 | 3.307 | 3.551 |
| 60 | 1.671 | 2.000 | 2.390 | 2.660 | 3.232 | 3.460 |
| 120 | 1.658 | 1.980 | 2.358 | 2.617 | 3.160 | 3.373 |
| ∞ | 1.645 | 1.960 | 2.326 | 2.576 | 3.090 | 3.291 |
2.2.
Абсолютное значение t
-критерия не меньше критического t
= 5.08680,
t
кр.α = 2.064,
следовательно экспериментальные данные, с вероятностью 0.95
(1 — α
),
не противоречат гипотезе
о зависимости случайных величин X и Y.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:

Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации
В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
Значение t-статистики (критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > tкр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Как рассчитать коэффициент корреляции в Excel
Если коэффициент равен 0, это говорит о том, что взаимосвязь между значениями отсутствует. Чтобы найти взаимосвязь между переменными и у, воспользуйтесь встроенной функцией Microsoft Excel «КОРРЕЛ». Например, для «Массив1» выделите значения у, а для «Массив2» выделите значения х. В итоге вы получите рассчитанный программой коэффициент корреляции. Далее необходимо вычислить разницу между каждым x и xср, и yср. В выбранных ячейках напишите формулы x-x, y-. Не забудьте закрепить ячейки со средними значениями. Полученный результат и будет искомым коэффициентом корреляции.
Приведенная выше формула расчета коэффициента Пирсона, показывает насколько трудоемок этот процесс если выполнять его вручную. Второе, порекомендуйте, пожалуйста, какой вид корреляционного анализа можно использовать для разных выборок с большим разбросом данных? Как мне статистически доказать достоверность отличий между группой старше 60 лет и всеми остальными?
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных. К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:

Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ В MS EXCEL
1. Создайте файл исходных данных в MS Excel (например, таблица 2)
2. Построение корреляционного поля
Для построения корреляционного поля в командной строке выбираем меню Вставка/ Диаграмма . В появившемся диалоговом окне выберите тип диаграммы: Точечная ; вид: Точечная диаграмма , позволяющая сравнить пары значений (Рис. 22).
Рисунок 22 – Выбор типа диаграммы
Рисунок 23– Вид окна при выборе диапазона и рядов Рисунок 25 – Вид окна, шаг 4
2. В контекстном меню выбираем команду Добавить линию тренда.
3. В появившемся диалоговом окне выбираем тип графика (в нашем примере линейная) и параметры уравнения, как показано на рисунке 26.
Нажимаем ОК. Результат представлен на рисунке 27.
Рисунок 27 – Корреляционное поле зависимости производительности труда от фондовооруженности
Аналогично строим корреляционное поле зависимости производительности труда от коэффициента сменности оборудования. (рисунок 28).

от коэффициента сменности оборудования
3. Построение корреляционной матрицы.
Для построения корреляционной матрицы в меню Сервис выбираем Анализ данных.
С помощью инструмента анализа данных Регрессия , помимо результатов регрессионной статистики, дисперсионного анализа и доверительных интервалов, можно получить остатки и графики подбора линии регрессии, остатков и нормальной вероятности. Для этого необходимо проверить доступ к пакету анализа. В главном меню последовательно выберите Сервис/ Надстройки . Установите флажок Пакет анализа (Рисунок 29)
Рисунок 30 – Диалоговое окно Анализ данных
После нажатия ОК в появившемся диалоговом окне указываем входной интервал (в нашем примере А2:D26), группирование (в нашем случае по столбцам) и параметры вывода, как показано на рисунке 31.

Результат расчетов представлен в таблице 4.
Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO – 0,031*VK +0,405*VD +0,691*VZP – 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 – 0,031*x3 +0,405*x4 +0,691*x5 – 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.


Теперь, когда мы перейдем во вкладку «Данные»
, на ленте в блоке инструментов «Анализ»
мы увидим новую кнопку – «Анализ данных»
.