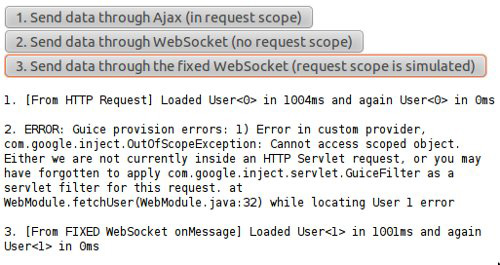
Путь к http/2
Содержание:
3.2 Content-Type: multipart/form-data
Как только интернет мир понял, что неплохо бы было через формы отсылать еще и файлы, так W3C консорциум взялся за доработку формата POST запроса. К тому времени уже достаточно широко применялся формат MIME (Multipurpose Internet Mail Extensions многоцелевые расширения протокола для формирования Mail сообщений), поэтому, чтобы не изобретать велосипед заново, решили использовать часть данного формата формирования сообщений для создания POST запросов в протоколе HTTP.
Каковы же основные отличия этого формата от типа application/x-www-form-urlencoded?
Главное отличие в том, что Entity-Body теперь можно поделить на разделы, которые разделяются границами (boundary). Что самое интересное каждый раздел может иметь свой собственный заголовок для описания данных, которые в нем хранятся, т.е. в одном запросе можно передавать данные различных типов (как в Mail письме Вы одновременно с текстом можете передавать файлы).
Итак, приступим. Рассмотрим опять все тот же пример с передачей логина и пароля, но теперь в новом формате.
POST http://www.site.ru/news.html HTTP/1.0Host: www.site.ruReferer: http://www.site.ru/index.htmlCookie: income=1Content-Type: multipart/form-data; boundary=1BEF0A57BE110FD467AContent-Length: 209
–1BEF0A57BE110FD467A Content-Disposition: form-data; name=»login» Petya Vasechkin –1BEF0A57BE110FD467A Content-Disposition: form-data; name=»password» qq –1BEF0A57BE110FD467A–
Теперь давайте разбираться в том что написано. Я специально выделил некоторые символы
жирным, чтобы они не сливались с данными. Присмотревшись внимательно можно заметить поле boundary после Content-Type. Это поле задает разделитель разделов границу. В качестве границы может быть использована строка, состоящая из латинских букв и цифр, а так же из еще некоторых символов (к сожалению, не помню каких еще). В теле запроса в начало границы добавляется ‘–‘, а заканчивается запрос границей, к которой символы ‘–‘ добавляются еще и в конец. В нашем запросе два раздела, первый описывает поле login, а второй поле password. Content-Disposition (тип данных в разделе) говорит, что это будут данные из формы, а в поле name задается имя поля. На этом заголовок раздела заканчивается и далее следует область данных раздела, в котором помещается значение поля (кодировать значение не требуется!).
Хочу обратить Ваше внимание та то, что в заголовках разделов не надо использовать Content-Length, а вот в заголовке запроса надо и его значение является размером всего Entity-Body, стоящего после второго
, следующего за Content-Length: 209. Т.е
Entity-Body отделяется от заголовка дополнительным переводом строки (что можно заметить и в разделах).
А теперь давайте напишем запрос для передачи файла.
POST http://www.site.ru/postnews.html HTTP/1.0Host: www.site.ruReferer: http://www.site.ru/news.htmlCookie: income=1Content-Type: multipart/form-data; boundary=1BEF0A57BE110FD467AContent-Length: 491
–1BEF0A57BE110FD467A Content-Disposition: form-data; name=»news_header» Пример новости –1BEF0A57BE110FD467A Content-Disposition: form-data; name=»news_file»; filename=»news.txt» Content-Type: application/octet-stream Content-Transfer-Encoding: binary А вот такая новость, которая лежит в файле news.txt –1BEF0A57BE110FD467A–
В данном примере в первом разделе пересылается заголовок новости, а во втором разделе пересылается файл news.txt. Внимательный да увидит поля filename и Content-Type во втором разделе. Поле filename задает имя пересылаемого файла, а поле Content-Type тип данного файла. Application/octet-stream говорит о том, что это стандартный поток данных, а Content-Transfer-Encoding: binary говорит на о том, что это бинарные данные, ничем не закодированные.
Очень важный момент. Большинство CGI скриптов написано умными людьми, поэтому они любят проверять тип пришедшего файла, который стоит в Content-Type. Зачем? Чаще всего закачка файлов на сайтах используется для получения картинок от посетителя. Так вот, браузер сам пытается определить что за файл посетитель хочет отправить и вставляет соответствующий Content-Type в запрос. Скрипт его проверяет при получении, и, например, если это не gif или не jpeg игнорирует данный файл. Поэтому при «ручном» формировании запроса позаботьтесь о значении Content-Type, чтобы оно было наиболее близким к формату передаваемого файла.
| image/gif | для gif |
| image/jpeg | для jpeg |
| image/png | для png |
| image/tiff | для tiff (что используется крайне редко, уж больно емкий формат) |
В нашем примере формируется запрос, в котором передается текстовый файл. Точно так же формируется запрос для передачи бинарного файла.
Принципы
«Protocol-Oriented Programming in Swift»
- «Don’t start with a class. Start with a protocol.». Это утверждение Dave Abrahams с вышеупомянутой сессии. Можно трактовать 2 способами:
- начинайте не с реализации, а с описания контракта (описание функциональности, которую объект будет обязан предоставить потребителям)
- описывайте переиспользуемую логику в протоколах, а не классах. Используйте протокол как единицу переиспользования кода, а класс — как место для уникальной логики. По другому можно описать этот принцип — encapsulate what varies.
Хорошим аналогом может стать паттерн «Шаблонный метод». Его идея — отделить общий алгоритм от деталей реализации. Базовый класс содержит общий алгоритм, а дочерние переопределяют определённые шаги алгоритма. В POP общий алгоритм будет содержаться в protocol extension, protocol будет определять шаги алгоритма и используемые типы, а реализация шагов — в классе.
- Композиция через расширения. Многие слышали фразу «предпочитайте композицию наследованию». В ООП, когда от объекта требуется разный набор функциональности (полиморфное поведение), эту функциональность можно либо разбить на части и организовать иерархию классов, где каждый класс наследует функциональность от предка и добавляет свою, либо разбить на несвязанные иерархией классы, экземпляры которых использовать в связующем классе. Используя возможность добавить соответствие протоколу через расширение мы можем использовать композицию не прибегая к созданию вспомогательных классов. Таким способом зачастую пользуются, когда добавляют viewController-у соответствие различным делегатам. Преимущество перед добавлением соответствия протоколам в самом классе — лучше организованный код:
- Вместо наследования используйте протоколы. Dave Abrahams сравнил протоколы с суперклассами, поскольку они позволяют достичь подобия множественного наследования.
Если ваш класс содержит много логики, стоит попытаться разбить его на отдельные наборы функциональности, которые вынести в протоколы.
Разумеется, в случае использования сторонних фреймворков, как Cocoa, наследования не избежать. - Используйте Retroactive modeling.
Интересный пример с всё той же сессии «Protocol-Oriented Programming in Swift». Вместо того, чтобы написать класс реализующий протокол Renderer для отрисовки с помощью CoreGraphics, классу CGContext через extension добавляется соответствие этому протоколу. Перед добавлением нового класса, реализующего протокол, стоит задуматься, есть ли тип (класс/структура/enum), который можно адаптировать к соответствию протокола? - Включайте в протоколы методы, которые можно переопределить (Requirements create customization points).
Если появилась необходимость переопределить общий метод, определённый в protocol extension, для конкретного класса, то перенесите сигнатуру этого метода в protocol requirements. Другие классы не придётся править, т.к. продолжат использовать метод из расширения. Различие будет в формулировке — теперь это «default implementation method» вместо «extension method».
HTTP 1.1 — что это за протокол?
HTTP (англ. «протокол передачи гипертекста») — сетевой протокол верхнего уровня для передачи гипертекстовых и произвольных данных в интернете.
При помощи HTTP браузер получает данные от веб-серверов и может отображать их в приемлемом и понятном для интернет-пользователей виде. Точно также происходит и обратный процесс — отправку пользовательских данных обратно, на сервер (например, при регистрации).
Контент отправляемый с сервера и на сервер может быть представлен в любом виде: рисунков, файлов, документов, ссылок и кода — в любом случае, именно благодаря HTTP люди могут пользоваться интернетом и загружать в браузере сотни веб-страниц.
Актуальная версия протокола — 1.1. Ее описание находится в спецификации RFC.
HTTP используется в клиент-серверной инфраструктуре передачи данных. Как это работает? Приложение на стороне «клиент» формирует запрос для обработки на стороне «сервер», после чего ответ отправляется обратно «клиенту». Затем «клиент» может инициировать дополнительные запросы, получать новые ответы. И так далее.
Наиболее распространенное «клиентское» приложение это веб-браузер через который осуществляется доступ к веб-ресурсам. С развитием мобильных технологий к браузерам добавились еще мобильные приложения на разнообразных смартфонах и планшетах. Причем серверная сторона современных многопрофильных приложений может одновременно обрабатывать данные и из браузера, и со смартфона. Все это через протокол HTTP.
Более того, HTTP часто выступает как протокол-транспорт для трансфера других прикладных протоколов и их API: WebDAV, XML-RPC, REST, SOAP. Ну а данные передаваемые по API могут иметь самый разный формат: XML, JSON и другие.
Как передаются эти данные? Чаще всего по TCP/IP-соединению: приложение-клиент по умолчанию использует TCP-порт 80, а сервер может использовать любой другой, но обычно это тоже 80 порт.
Объект манипуляций в HTTP это ресурс, указываемый в URI запроса клиентского приложения, чтобы корректно идентифицировать «что вообще нужно». Обычно это файлы, данные или логические объекты, которые хранятся на сервере. При этом в запросе можно указать, как именно представить одни и те же данные: какой выбрать формат, кодировку, язык. Такая «фича» позволяет обмениваться не только гипертекстом, но и двоичными данными.
Второй особенностью HTTP является отсутствие сохранения состояния между последовательными парами «запрос-ответ». Но это не проблема, потому что компоненты приложений на клиентской или серверной стороне само могут хранить информацию о состоянии последних запросов и ответов. На стороне клиента такая информация называется cookies («куки»), на стороне сервера — sessions («сессии»).
При этом для клиентского браузера не проблема следить за задержкой ответа сервера, а для сервера — хранить заголовки последних запросов и IP-адреса клиентов. Но, еще раз подчеркну, сам протокол об этом ничего не знает — он только передает данные.
Принимать участие в передаче данных могут и посредники (прокси-сервера), для того чтобы отличить прокси от конечных серверов (т.н. «исходный сервер»).
Самое волшебство начинается, когда одна и та же программа (клиентская или серверная) может выполнять функции посредник, клиента, сервера — в зависимости от задач.
Оптимизация
Оптимизация с помощью HTTP keep-alive
Протокол HTTP работает поверх протокола TCP («Transmission Control Protocol»). TCP — это надёжный протокол двусторонней передачи потока данных. TCP работает, пересылая пакеты данных от клиента к серверу и обратно. TCP-пакет состоит из заголовка и данных. В заголовке указаны, помимо прочего, IP-адреса клиента и сервера, номера TCP-портов, используемых на клиенте и сервере, и набор флагов. Для HTTP на сервере обычно используется стандартный TCP-порт номер 80.
TCP-соединение между клиентом и сервером устанавливается с помощью классического «TCP three-way handshake». Сначала клиент посылает серверу пакет с флагом SYN. В ответ сервер посылает пакет с флагами SYN+ACK. Наконец, клиент посылает ещё один пакет, с флагом ACK и с этой минуты соединение считается установленным, и клиент может посылать свои данные, в нашем случае — HTTP-запрос.
Понятно, что если десяток тысяч браузеров установит с сервером keep-alive соединение, то они достаточно быстро исчерпают его ресурсы. Поэтому во всех серверах есть конфигурируемый тайм-аут, по истечении которого keep-alive соединение разрывается, если на нём не было никакой активности.
Клиент может запросить разрыв соединения после ответа, передав в запросе заголовок Connection: close. Аналогично, сервер может сообщить в ответе, что не желает поддерживать keep-alive соединение, передав точно такой же заголовок: Connection: close. Вообще говоря, все эти расшаркивания с взаимным уведомлением, строго говоря, не налагают никаких обязанностей. И сервер, и клиент должны быть полностью готовы к тому, что соединение прервётся в любой момент времени по инициативе другой стороны без каких-либо уведомлений.
Для того, чтобы соблюсти целостность keep-alive соединения, сервер должен знать длину ответа. Самый простой способ — указать её в заголовке Content-Length. Если длина ответа не указана обработчиком, то сервер вынужден перед отправкой ответа установить заголовок Connection: close и закрыть соединение со своей стороны после отправки ответа.
Оптимизация с помощью компрессии
Прекрасным способом существенно снизить трафик и ускорить отклик сервера является компрессия отдаваемых файлов и страниц. Практически все современные веб-сервера так или иначе поддерживают эту функциональность. Коэффициент сжатия варьируется в зависимости от каждой конкретной страницы и может достигать значений порядка 10. Для разработчика веб-приложения сжатие полностью прозрачно и не требует никаких усилий.
Способность принимать компрессированное содержимое клиент анонсирует серверу с помощью заголовка Accept-Encoding: gzip. Если сервер настроен на сжатие соответствующего контента, то он может добавить заголовок ответа Content-Encoding: gzip (не путать с Transfer-Encoding) и отправить клиенту сжатое содержимое.
Оптимизация с помощью HTTP-pipelining
Когда мы делаем серию запросов и ответов в рамках одного keep-alive соединения, важную роль в производительности играет время задержки (latency) между запросом и ответом. Задержка может быть вызвана как высокой задержкой на канале, так и большим временем обработки запросов на сервере. Перед посылкой очередного запроса мы должны дождаться завершения обработки следующего. Чтобы справиться с этой проблемой, может использоваться технология HTTP-pipelining.
Смысл HTTP-pipelining состоит попросту в том, что клиент посылает подряд несколько запросов, а потом начинает постепенно разгребать приходящие ответы. Поддержка со стороны серверов в целом хорошая, но к сожалению, в настоящий момент клиенты, поддерживающие HTTP-pipelining, составляют очень небольшой процент рынка.
Какими бывают протоколы Интернета
На сегодняшний день известно несколько разновидностей протоколов Интернета. Они имеют следующие обозначения:
- HTTP;
- DNS;
- ICMP;
- FTP;
- UDP;
- TCP/IP — название протокола, являющегося основным для интернет-сетей.
Обратите внимание! Различия между этими решениями кроются в уровнях назначения
И здесь можно разделить решения по нескольким веткам:
- физические уровни. Предполагают, что соединение создаётся при помощи витой пары, оптических волокон;
- ARP-уровень с драйверами устройств;
- сетевой уровень со стандартными ICMP, IP;
- транспортный уровень — UDP и TCP;
- прикладной. Сюда входят стандартные протоколы сети Интернет типа NFS, DNS, FTP, HTTP.
ISO/OSI — система стандартизации, которая используется абсолютно для всех решений. Благодаря этому не возникает сбоев у разнообразных платформ, даже если используются разные операционные системы, оборудование поставляют разные производители. Сейчас такие детали практически не имеют значения.
Обратите внимание! Для функционирования Интернета используется протокол каждого уровня
Что значит и где применяется HTTPS-протокол?
Ну, про обмен данными по протоколу HTTP вы уже все знаете: любая передача данных осуществляется через запросы по этому протоколу-транспорту. А зачем тогда нужен HTTPS и что он из себя представляет? Ведь жили же нормально и без него?
Проблема в том что данные по HTTP не защищаются и передаются в открытом виде. Интернет — глобальная распределенная сеть узлов. И если вы передаете открытые данные по незащищенному протоколу (Wi-Fi в ТРЦ сюда тоже относится), то один из этих узлов может перехватить их.
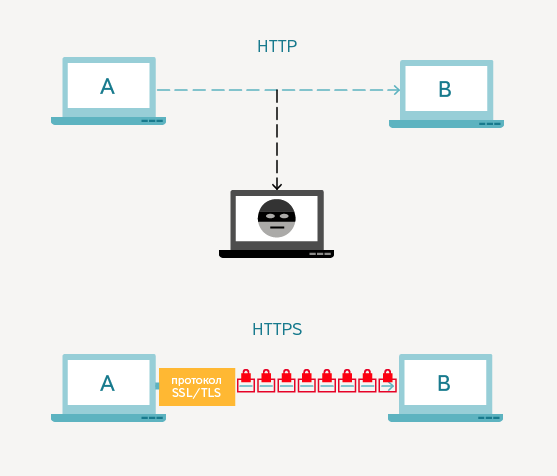
Не специально конечно, может быть просто взлом усилиями злоумышленников. HTTPS и создан для того чтобы соединение было безопасным, а данные передавались в зашифрованном виде по криптографическому протоколу SSL/TLS. Это специальная «обертка» поверх HTTP, она шифрует данные, делая их недоступными для злоумышленников и посторонних людей.
HTTPS — англ. «безопасный протокол передачи гипертекста».
Так что в отличие от 80 порта, используемого по умолчанию в HTTP, в HTTPS используется TCP-порт 443 и есть ключ для шифрования. Ключ может быть длиной 40, 56, 128 или 256 бит, достаточный уровень безопасности на данный момент начинается со 128-битных ключей.
Сейчас все браузеры поддерживают HTTPS — он включается автоматически, когда есть возможность и этого требует сервер.
Жизненно важно использовать HTTPS в следующих сервисах:
- Электронные платежные системы (банки, электронные деньги и прочее);
- Сервисы принимающие и отправляющие приватную информацию и персональные данные, например у Яндекса это: Паспорт, Такси, Директ, Метрика, Почта, Деньги, Вебмастер и другие;
- Социальные сети и личные кабинеты в интернет-сервисах;
- Поисковые системы.
Работает HTTPS просто. Объясню на примере.
Вы кладете важную информацию (логин, пароль, данные карты, персональные данные) в ячейку, «запираете ее на ключ»: ячейка шифрует ваши данные при помощи этого ключа.
Теперь отправляете ее почтой адресату. Адресат получает ячейку-посылку, но открыть ее не может — у него нет ключа. Тогда он запирает (шифрует) ячейку на второй замок и возвращает посылку вам обратно. Вы получаете посылку с двумя замками, при этом ключ к одному у вас есть. Теперь можно отпереть свой замок (расшифровать данные) и отправить посылку обратно еще раз — первоначальному адресату.
Данные при этом остаются защищенными — ведь они никем не просматривались и не менялись и до момента получения адресатом находятся под защитой зашифрованного им ключа. Адресат получает посылку, уже с одним замком, расшифровывает ее и обрабатывает ваши данные. Например, проводит вашу транзакцию.
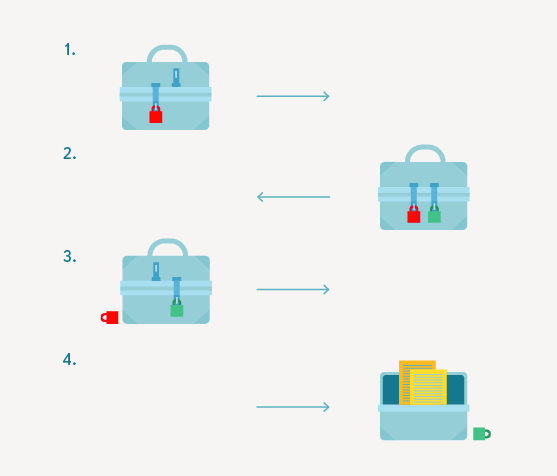
Все — вот так просто работает HTTPS.
Фишка тут в том, что при первом таком обмене происходит обмен ключом шифрования, чтобы он был известен обоим конечным адресатам, но не известен ни одному из узлов по маршруту следования данных. После обмена шифром можно свободно обмениваться сообщениями (зашифрованными) без опасений о перехвате этих данных, ведь без ключа-шифра открыть и прочитать их не удастся.
Единственный нюанс здесь — надо знать, что вы отправляете данные именно туда, куда нужно. И что конечный пункт и является пунктом назначения. Но нужно подтвердить и точно знать, что конечный адресат существует и управляется тем самым сервером, куда отправляются данные.
Для этого серверы получают в центрах сертификации специальные HTTPS-сертификаты безопасности, которые подтверждают «конечность» пункта назначения (что сайт не является узлом передающим данные дальше) и работоспособность технологии шифрования SSL/TLS, т.е. безопасность соединения.
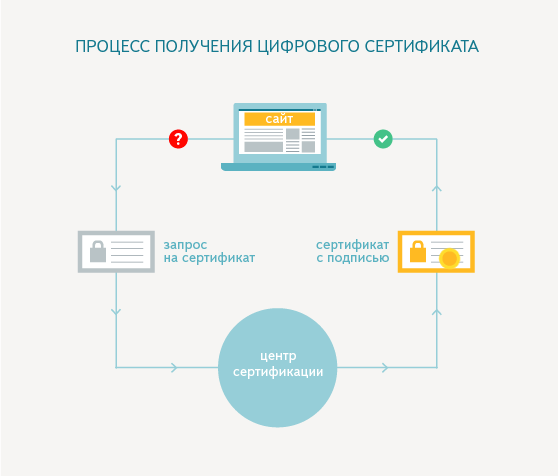
А вот как выглядит сам сертификат:
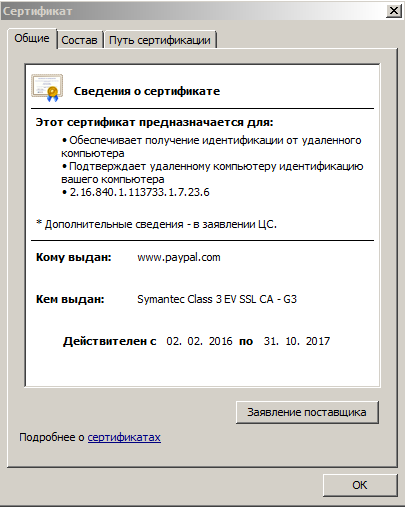
На текущий момент HTTPS встроен во все современные браузеры и все что требуется от пользователя для поддержания безопасности отправки данных по HTTPS — регулярно обновлять программное обеспечение для серфинга, приема и отправки важных данных в интернете.
Осуществляя взаимодействие «клиент-сервер» по протоколу HTTPS можно не беспокоиться за сохранность данных — вы надежно защищены от прослушивания сетевого соединения: атак снифферов и man-in-the-middle.
Что означает перечеркнутый значок HTTPS и зеленый значок HTTPS, в чем разница? В безопасности. Зеленый — безопасный, красный и перечеркнутый — небезопасный.
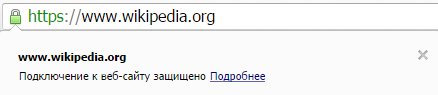
И очень удобно, что перечеркнутый значок HTTPS означает, что несмотря на использование этого протокола, соединение не безопасное. Так происходит когда элементы сайта подгружаются не по HTTPS или истек срок действия сертификата. Пользователю сразу видно — ага, небезопасно. И он может уйти с сайта, либо рисковать своими данными.
Протокол HTTP
Протокол HTTP или HyperText Transfer Protocol это главный прокол сервиса Интернет WWW (всемирной паутины). Основная задача протокола, обеспечить передачу гипертекста в сети. В протоколе точно описывается формат сообщений, для обмена клиентов и серверов.
Описан протокол HTTP в RFC 2616(HTTP1.1).
Основа протокола обеспечить взаимодействие клиента и сервера по средством одного ASCII-запроса, и следующего на него ответа в стандарте RFC 822 MIME.
На практике протокол HTTP работает на основе TCP/IP порт 80, но можно настроить и по-другому. И хоть TCP/IP не является обязательным, он остается предпочтительным, так как берет на себя разбиение и сборку сообщений на себя и не «напрягает» ни браузер, ни сервер.
Следует отметить, что протокол HTTP может использоваться не только в веб-технологиях, но и других ООП приложениях (объективно-ориентированных).
HTTP/1.1 – 1999
Прошло 3 года со времён HTTP/1.0, и в 1999 вышла новая версия протокола — HTTP/1.1, включающая множество улучшений:
- Новые HTTP-методы — PUT, PATCH, HEAD, OPTIONS, DELETE.
- Идентификация хостов. В HTTP/1.0 заголовок Host не был обязательным, а HTTP/1.1 сделал его таковым.
- Постоянные соединения. Как говорилось выше, в HTTP/1.0 одно соединение обрабатывало лишь один запрос и после этого сразу закрывалось, что вызывало серьёзные проблемы с производительностью и проблемы с задержками. В HTTP/1.1 появились постоянные соединения, т.е. соединения, которые по умолчанию не закрывались, оставаясь открытыми для нескольких последовательных запросов. Чтобы закрыть соединение, нужно было при запросе добавить заголовок Connection: close. Клиенты обычно посылали этот заголовок в последнем запросе к серверу, чтобы безопасно закрыть соединение.
- Потоковая передача данных, при которой клиент может в рамках соединения посылать множественные запросы к серверу, не ожидая ответов, а сервер посылает ответы в той же последовательности, в которой получены запросы. Но, вы можете спросить, как же клиент узнает, когда закончится один ответ и начнётся другой? Для разрешения этой задачи устанавливается заголовок Content-Length, с помощью которого клиент определяет, где заканчивается один ответ и можно ожидать следующий.
Замечу, что для того, чтобы ощутить пользу постоянных соединений или потоковой передачи данных, заголовок Content-Length должен быть доступен в ответе. Это позволит клиенту понять, когда завершится передача и можно будет отправить следующий запрос (в случае обычных последовательных запросов) или начинать ожидание следующего ответа (в случае потоковой передачи).
Но в таком подходе по-прежнему оставались проблемы. Что, если данные динамичны, и сервер не может перед отправкой узнать длину контента? Получается, в этом случае мы не можем пользоваться постоянными соединениями? Чтобы разрешить эту задачу, HTTP/1.1 ввёл сhunked encoding — механизм разбиения информации на небольшие части (chunks) и их передачу.
- Chunked Transfers если контент строится динамически и сервер в начале передачи не может определить Content-Length, он начинает отсылать контент частями, друг за другом, и добавлять Content-Length к каждой передаваемой части. Когда все части отправлены, посылается пустой пакет с заголовком Content-Length, установленным в 0, сигнализируя клиенту, что передача завершена. Чтобы сказать клиенту, что передача будет вестись по частям, сервер добавляет заголовок Transfer-Encoding: chunked.
- В отличие от базовой аутентификации в HTTP/1.0, в HTTP/1.1 добавились дайджест-аутентификация и прокси-аутентификация.
- Кэширование.
- Диапазоны байт (byte ranges).
- Кодировки
- Согласование содержимого (content negotiation).
- Клиентские куки.
- Улучшенная поддержка сжатия.
- И другие…
Особенности HTTP/1.1 — отдельная тема для разговора, и в этой статье я не буду задерживаться на ней надолго. Вы можете найти огромное количество материалов по этой теме. Рекомендую к прочтению Key differences between HTTP/1.0 and HTTP/1.1 и, для супергероев, ссылку на RFC.
HTTP/1.1 появился в 1999 и пробыл стандартом долгие годы. И, хотя он и был намного лучше своего предшественника, со временем начал устаревать. Веб постоянно растёт и меняется, и с каждым днём загрузка веб-страниц требует всё больших ресурсов. Сегодня стандартной веб-странице приходится открывать более 30 соединений. Вы скажете: «Но… ведь… в HTTP/1.1 существуют постоянные соединения…». Однако, дело в том, что HTTP/1.1 поддерживает лишь одно внешнее соединение в любой момент времени. HTTP/1.1 пытался исправить это потоковой передачей данных, однако это не решало задачу полностью. Возникала проблема блокировки начала очереди (head-of-line blocking) — когда медленный или большой запрос блокировал все последующие (ведь они выполнялись в порядке очереди). Чтобы преодолеть эти недостатки HTTP/1.1, разработчики изобретали обходные пути. Примером тому служат спрайты, закодированные в CSS изображения, конкатенация CSS и JS файлов, доменное шардирование и другие.
HTML Ссылки
HTML по АлфавитуHTML по КатегориямHTML Атрибуты ТеговHTML Атрибуты ГлобалHTML Атрибуты СобытийHTML ЦветаHTML ХолстыHTML Аудио / ВидеоHTML Наборы символовHTML DOCTYPEsHTML Кодирование URLHTML Языковые кодыHTML Коды странHTTP Ответы сервераHTTP МетодыPX в EM конвертерГорячие клавиши
HTML Теги
<!—>
<!DOCTYPE>
<a>
<abbr>
<acronym>
<address>
<applet>
<area>
<article>
<aside>
<audio>
<b>
<base>
<basefont>
<bdi>
<bdo>
<big>
<blockquote>
<body>
<br>
<button>
<canvas>
<caption>
<center>
<cite>
<code>
<col>
<colgroup>
<data>
<datalist>
<dd>
<del>
<details>
<dfn>
<dialog>
<dir>
<div>
<dl>
<dt>
<em>
<embed>
<fieldset>
<figcaption>
<figure>
<font>
<footer>
<form>
<frame>
<frameset>
<h1> — <h6>
<head>
<header>
<hr>
<html>
<i>
<iframe>
<img>
<input>
<ins>
<kbd>
<label>
<legend>
<li>
<link>
<main>
<map>
<mark>
<menu>
<menuitem>
<meta>
<meter>
<nav>
<noframes>
<noscript>
<object>
<ol>
<optgroup>
<option>
<output>
<p>
<param>
<picture>
<pre>
<progress>
<q>
<rp>
<rt>
<ruby>
<s>
<samp>
<script>
<section>
<select>
<small>
<source>
<span>
<strike>
<strong>
<style>
<sub>
<summary>
<sup>
<svg>
<table>
<tbody>
<td>
<template>
<textarea>
<tfoot>
<th>
<thead>
<time>
<title>
<tr>
<track>
<tt>
<u>
<ul>
<var>
<video>
<wbr>
Преимущества и недостатки протокола
Достоинства
- Интернет протокол HTTP дает возможность достаточно просто создавать нужные клиентские приложения.
- Первоначальные возможности протокола возможно расширить, внедрив свои персональные заголовки.
- Протокол поддерживается как клиент большим числом программ и есть возможность выбирать среди множества хостинговых компаний с серверами HTTP.
Недостатки
- Протокол HTTP не содержит в явном виде возможность навигации внутри ресурсов сервера.
- Отсутствует поддержка распределенности. Промышленное применение интернет протокола HTTP с использованием распределённых вычислений при больших нагрузках на сервер оказывается непригодным.
Коды состояния
В ответ на запрос от клиента, сервер отправляет ответ, который содержит, в том числе, и код состояния. Данный код несёт в себе особый смысл для того, чтобы клиент мог отчётливей понять, как интерпретировать ответ:
1xx: Информационные сообщения
Набор этих кодов был введён в HTTP/1.1. Сервер может отправить запрос вида: Expect: 100-continue, что означает, что клиент ещё отправляет оставшуюся часть запроса. Клиенты, работающие с HTTP/1.0 игнорируют данные заголовки.
2xx: Сообщения об успехе
Если клиент получил код из серии 2xx, то запрос ушёл успешно. Самый распространённый вариант – это 200 OK. При GET запросе, сервер отправляет ответ в теле сообщения. Также существуют и другие возможные ответы:
- 202 Accepted: запрос принят, но может не содержать ресурс в ответе. Это полезно для асинхронных запросов на стороне сервера. Сервер определяет, отправить ресурс или нет.
- 204 No Content: в теле ответа нет сообщения.
- 205 Reset Content: указание серверу о сбросе представления документа.
- 206 Partial Content: ответ содержит только часть контента. В дополнительных заголовках определяется общая длина контента и другая инфа.
3xx: Перенаправление
Своеобразное сообщение клиенту о необходимости совершить ещё одно действие. Самый распространённый вариант применения: перенаправить клиент на другой адрес.
- 301 Moved Permanently: ресурс теперь можно найти по другому URL адресу.
- 303 See Other: ресурс временно можно найти по другому URL адресу. Заголовок Location содержит временный URL.
- 304 Not Modified: сервер определяет, что ресурс не был изменён и клиенту нужно задействовать закэшированную версию ответа. Для проверки идентичности информации используется ETag (хэш Сущности – Enttity Tag);
4xx: Клиентские ошибки
Данный класс сообщений используется сервером, если он решил, что запрос был отправлен с ошибкой. Наиболее распространённый код: 404 Not Found. Это означает, что ресурс не найден на сервере. Другие возможные коды:
- 400 Bad Request: вопрос был сформирован неверно.
- 401 Unauthorized: для совершения запроса нужна аутентификация. Информация передаётся через заголовок Authorization.
- 403 Forbidden: сервер не открыл доступ к ресурсу.
- 405 Method Not Allowed: неверный HTTP метод был задействован для того, чтобы получить доступ к ресурсу.
- 409 Conflict: сервер не может до конца обработать запрос, т.к. пытается изменить более новую версию ресурса. Это часто происходит при PUT запросах.
5xx: Ошибки сервера
Ряд кодов, которые используются для определения ошибки сервера при обработке запроса. Самый распространённый: 500 Internal Server Error. Другие варианты:
- 501 Not Implemented: сервер не поддерживает запрашиваемую функциональность.
- 503 Service Unavailable: это может случиться, если на сервере произошла ошибка или он перегружен. Обычно в этом случае, сервер не отвечает, а время, данное на ответ, истекает.
HTTP/1.0 — 1996
В отличие от HTTP/0.9, спроектированного только для HTML-ответов, HTTP/1.0 справляется и с другими форматами: изображения, видео, текст и другие типы контента. В него добавлены новые методы (такие, как POST и HEAD). Изменился формат запросов/ответов. К запросам и ответам добавились HTTP-заголовки. Добавлены коды состояний, чтобы различать разные ответы сервера. Введена поддержка кодировок. Добавлены составные типы данных (multi-part types), авторизация, кэширование, различные кодировки контента и ещё многое другое.
Вот так выглядели простые запрос и ответ по протоколу HTTP/1.0:
Помимо запроса клиент посылал персональную информацию, требуемый тип ответа и т.д. В HTTP/0.9 клиент не послал бы такую информацию, поскольку заголовков попросту не существовало.
Пример ответа на подобный запрос:
В начале ответа стоит HTTP/1.0 (HTTP и номер версии), затем код состояния — 200, затем — описание кода состояния.
В новой версии заголовки запросов и ответов были закодированы в ASCII (HTTP/0.9 весь был закодирован в ASCII), а вот тело ответа могло быть любого контентного типа — изображением, видео, HTML, обычным текстом и т. п. Теперь сервер мог послать любой тип контента клиенту, поэтому словосочетание «Hyper Text» в аббревиатуре HTTP стало искажением. HMTP, или Hypermedia Transfer Protocol, пожалуй, стало бы более уместным названием, но все к тому времени уже привыкли к HTTP.
Один из главных недостатков HTTP/1.0 — то, что вы не можете послать несколько запросов во время одного соединения. Если клиенту надо что-либо получить от сервера, ему нужно открыть новое TCP-соединение, и, как только запрос будет выполнен, это соединение закроется. Для каждого следующего запроса нужно создавать новое соединение.
Почему это плохо? Давайте предположим, что вы открываете страницу, содержащую 10 изображений, 5 файлов стилей и 5 JavaScript файлов. В общей сложности при запросе к этой странице вам нужно получить 20 ресурсов — а это значит, что серверу придётся создать 20 отдельных соединений. Такое число соединений значительно сказывается на производительности, поскольку каждое новое TCP-соединение требует «тройного рукопожатия», за которым следует медленный старт.
Тройное рукопожатие
«Тройное рукопожатие» — это обмен последовательностью пакетов между клиентом и сервером, позволяющий установить TCP-соединение для начала передачи данных.
- SYN — Клиент генерирует случайное число, например, x, и отправляет его на сервер.
- SYN ACK — Сервер подтверждает этот запрос, посылая обратно пакет ACK, состоящий из случайного числа, выбранного сервером (допустим, y), и числа x + 1, где x — число, пришедшее от клиента.
- ACK — клиент увеличивает число y, полученное от сервера и посылает y + 1 на сервер.
Примечание переводчика: SYN — синхронизация номеров последовательности, (англ. Synchronize sequence numbers). ACK — поле «Номер подтверждения» задействовано (англ. Acknowledgement field is significant).
Только после завершения тройного рукопожатия начинается передача данных между клиентом и сервером. Стоит заметить, что клиент может посылать данные сразу же после отправки последнего ACK-пакета, однако сервер всё равно ожидает ACK-пакет, чтобы выполнить запрос.
Тем не менее, некоторые реализации HTTP/1.0 старались преодолеть эту проблему, добавив новый заголовок Connection: keep-alive, который говорил бы серверу «Эй, дружище, не закрывай это соединение, оно нам ещё пригодится». Однако эта возможность не была широко распространена, поэтому проблема оставалась актуальна.
Помимо того, что HTTP — протокол без установления соединения, в нём также не предусмотрена поддержка состояний. Иными словами, сервер не хранит информации о клиенте, поэтому каждому запросу приходится включать в себя всю необходимую серверу информацию, без учёта прошлых запросов. И это только подливает масла в огонь: помимо огромного числа соединений, которые открывает клиент, он также посылает повторяющиеся данные, излишне перегружая сеть.