Что такое nofollow и для чего его используют
Содержание:
- Мета-тег
- Какое влияние оказывают rel nofollow и тег noindex
- Подробнее о теге noindex
- Как Яндекс учитывает rel nofollow и noindex
- Обработка значения nofollow атрибута rel поисковой системой Google
- Что это конкретно и как влияет?
- Как повысить эффективность закрытых ссылок
- Noindex
- Тэг nofollow
- Тег
- В чем разница rel=nofollow и
- How much time should you spend on reducing crawl budget?
- Nofollow
- Совместное использование тега и атрибута noindex nofollow
- Как работать с новыми атрибутами
- Использование Noindex в Яндексе
- 2.
Мета-тег
Начнем с базовых пониманий. Мета-тег — это служебная информация для страницы, которая указывается в документе в верхнем блоке <head></head> с HTML разметкой.
Что такое мета-тег robots?
В нашем случае, мета-тег с атрибутом name=“robots” дает указание роботам всех поисковых систем, без исключения. Так же, есть name=“googlebot”, виден только Google, и name=“yandex”, соответственно только для Yandex поисковика.
В коде это выглядит так:
<!DOCTYPE html> <html><head> <meta name="robots" content="noindex" /> (…) </head> <body>(…)</body> </html>
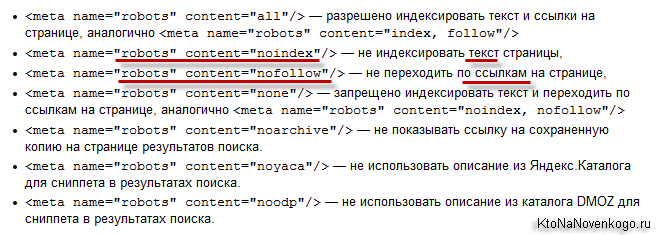
Атрибут content может принимать такие параметры как:
- “noindex” — ставит запрет на индексацию контента, но ссылки в документе все еще видны для поисковых роботов и открыты для просмотров и переходов на них
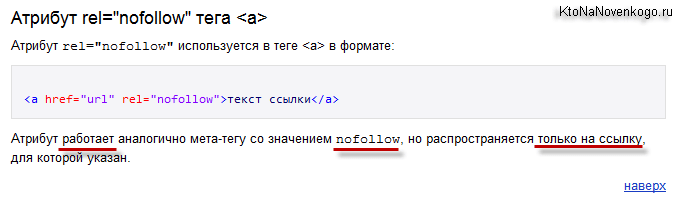
- “nofollow” — закрывает все ссылки на данной странице от индексации. Это касается как внешних, так и внутренних.
Варианты использования meta тега robots с noindex и nofollow
Возможны такие варианты использования:
<meta name="robots" content="index, follow"/> <!-- — включена индексация страницы и ссылок. Стоит по умолчанию для каждого сайта. --> <meta name="robots" content="noindex, follow"/> <!-- — запрет на индексацию контента страницы, но разрешен переход и просмотр ссылок. --> <meta name="robots" content="index, nofollow"/> <!-- — включена индексация, но запрещен переход и просмотр ссылок. --> <meta name="robots" content="noindex, nofollow"/> <!-- — запрет на индексацию и переход по ссылкам страницы. -->
Перечисленные варианты также можно использовать для скрытия от определенных поисковых систем, таких как Yandex и Google. Возможные варианты атрибута name видно выше, а в коде это может выглядеть так:
<meta name="googlebot" content="noindex, follow" />.
Стоит подбирать комбинацию атрибутов четко под свои цели и задачи. Давайте рассмотрим некоторые из них.
Когда нам нужен мета-тег “robots” со значением “noindex” или “nofollow”?
Мета-тег следует использовать на следующих страницах:
- со служебной информацией(админ. панель, логи сервера);
- дублирующийся контент(пагинация, архивы, теги).
А также в случаях:
- когда следует закрыть страницу от индексирования, но оставить возможность просматривать ссылки;
- когда хотите удалить документ из index и не допустить просмотра ссылок поисковыми роботами;
- когда нужно закрыть переход по ссылкам уже индексированного документа.

Рекомендуем
Операторы поиска Google
Подробнее
Какое влияние оказывают rel nofollow и тег noindex
Да и Яндекс тоже не отстал от своего самого большого конкурента на рынке поиска рунета и изменил, начиная с 2010 года, свое отношение к nofollow (он стал его учитывать).
Тег же noindex, который Яндекс ввел в оборот единолично и который до некоторых пор являлся единственной альтернативой нофоллоу, сейчас никак не влияет на учет закрытой им ссылки.
Но с помощью него по-прежнему можно закрывать от индексации отдельные фрагменты вебстраницы. Этот тэг является парным и учитываться поиском не будет все, что попало между его открывающим и закрывающим элементом.
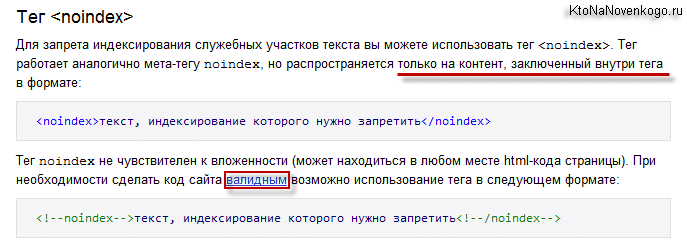
Т.к. ноиндекс был чисто нашим местечковым изобретением, то, естественно, что он не был включен в реестр разрешенных тегов текущей версии языка Html 4.01 и валидатор на него по-прежнему ругается.
<!--noindex-->текст, индексирование которого нужно запретить<!--/noindex-->
Яндекс пишет на своей странице хелпа, что noindex и nofollow следует интерпретировать точно так же, как и аналогичные значения, которые используются в мета теге robots.
Т.е. нофоллоу запрещает переход роботу поиска по данной ссылке, а ноиндекс запрещает добавлять заключенный в нем фрагмент текста в индекс.
так вообще никогда не учитывал noindex и, естественно, его с успехом игнорирует, равно как и любой другой поисковик кроме Яндекса. Изменилось отношение к подсчету статического веса на страницах, где находятся гиперссылки с добавленным в них атрибутом rel=»nofollow». Раньше их можно было вообще не учитывать, однако сейчас все стало немного сложнее и печальнее.
Итак, давайте сначала вернемся немного в прошлое и посмотрим, как можно было с помощью тегов nofollow и noindex закрыть от индексации гиперссылки для поисковых систем (чаще всего все же пытаются закрыть от индексации внешние бэклинки, ибо они способствуют утеканию статического веса, но об этом поговорим чуть позже).
Так вот, тексты ссылок, которые называют еще анкорами, позволяют Яндексу и Гуглу проводить так называемое ссылочное ранжирование, существенно влияющее на положение ресурса в поисковой выдаче. Именно по этой причине для продвижения сайта по какому-либо запросу (статистика поисковых запросов вам в помощь) оптимизаторы стараются закупить как можно больше бэклинков с текстами (анкорами), содержащими ключевые слова из того запроса, по которому продвигается данная страница.
В свое время ряд энтузиастов сделали так, что по запросу «жалкий неудачник» открывался ресурс тогдашнего президента Америки Буша младшего. Что примечательно, на самом ресурсе вообще не встречались данные ключевые слова, но зато на него была проставлена гигантская ссылочная масса с этим текстом (анкором), в результате чего вышел такой казус.
Сейчас уже такой фокус не пройдет, ибо ссылочное ранжирование не имеет такого колоссального влияния на ранжирование и нужно, чтобы и на самом портале Буша встречалась эта фраза, что маловероятно.
Но на этом роль ссылок в поисковом продвижении не заканчивается, ибо алгоритмы поиска в обязательном порядке для каждой страницы каждого отдельно взятого ресурса рассчитывают так называемый статический вес. Возможно, что разные системы рассчитывают его чуть по разному, но суть остается не измененной — статвес передается странице только по гиперссылке и при этом не учитывается ее анкор.
Правда, любая страница (документ, как их именуют поисковики) сразу после своего появления (индексации) имеет изначальный минимальный статический вес (что такое pr в Гугле), который может быть неограниченно увеличен за счет входящих внешних и внутренних ссылок на эту страницу. Тут ключевым моментом является то, что он передается не только внешними, но и внутренними ссылками.
Причем документ, ссылаясь на другие внешние или внутренние страницы, вовсе не теряет свой статический вес (pr для Google или Виц для Яндекса), который целиком и полностью зависит только от количества и весомости входящих на нее гиперссылок. Под последним я подразумеваю собственный статвес страниц доноров (доноры — те, откуда проставлены беклинки на ваш документ, который в этом случае выступает акцептором).
Подробнее о теге noindex
Даже если судить только по названию, не сложно догадаться о его назначении. Данный тег запрещает индексировать всё, что им отмечено (но это не касается ссылок и картинок — только текста).
Следует заметить, что ряд HTML-редакторов принципиально не работают с тэгом noindex — например, в WordРress он удаляется автоматически. Но в определённом виде его всё-таки можно использовать: Этот тег работает только с поисковой системой Яндекс. Тег noindex Google, не смотря на все свои возможности, не воспринимает.
Можно применять noindex и в качестве простого тега и в качестве мета-тега. Соответственно, их функции в таком случае будут разными. Обычный тег скроет от индексации только тот участок кода, который будет находиться между его открывающим и закрывающим тэгами. 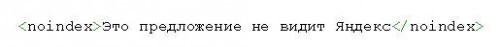
Применяемый в качестве мета-тега, noindex, прописанный в файле robots.txt, запретит индексировать всю страницу целиком.

Как правило, этот тег нормально функционирует и выполняет свои непосредственные обязанности. Тем не менее в ряде случаев, скрытая им от индексирования текстовая информация, все равно обрабатывается поисковыми ботами. Это связано с самим принципом работы поисковой системы. Тег noindex Yandex воспринимает, но все равно проиндексирует целиком весь код HTML, и только после этого отфильтрует значения, согласно тегам. Так что даже проиндексированный текст, спрятанный данным тегом, скоро исчезнет из поля зрения Яндекса.
К слову — для noindex вложенное размещение необязательно. В справке поисковой системы Яндекс указано, что тег будет работать и без вложения.
Как Яндекс учитывает rel nofollow и noindex
Это мы все говорили за Гугл, а как обстоит ситуация с использованием rel=»nofollow» для Яндекса, ведь это наш незабвенный лидер поиска в рунете. Тут все много туманнее, ибо однозначных суждений нет по этому вопросу.
Но похоже, что зеркало рунета, после того как стало учитывать rel nofollow в тегах гиперссылок, снял с noindex всякое влияние на запрет индексации ссылок.
Теперь noindex служит одной единственно цели — закрывать от индексации в Яндексе и Рамблере некоторые фрагменты текста. И если использовать его для ссылок, то он просто запретит этим поисковикам индексировать текст (анкор), а вот сама гиперссылка и передаваемый по ней статвес по-прежнему будут учитываться и браться в расчет.
Другой вопрос, как Яндекс учитывает rel nofollow? Копирует ли он схему работы у старого Google или же сразу взял на вооружение переделанный алгоритм расчета? Лично я затрудняюсь ответить на этот вопрос, но полагаю, что стоит рассчитывать именно на худший вариант.
Тогда получается, что у нас с вами уже не осталось инструментария, позволяющего полноценно закрыть от индексации ссылки, да так, чтобы не было утечки веса с сайта в пустоту.
По-прежнему мы можем закрыть от индексации целые страницы или гиперссылки на них с помощью мета тега Robots, назначение которого описано в статье приведенной в начале публикации, но вот с отдельно взятыми ссылками возникают сложности и rel nofollow перестал являться удачным решением для этой проблемы.
Можно, конечно же, проставлять внешние гиперссылки через редиректы или джаву, но Google их уже научился учитывать, а Яндекс, если еще и не научился, скоро обязательно научится. В связи с этим вообще не понятно как быть с бэклинками из комментариев и счетчиков посещений. Они по любому получается будут сосать статический вес с сайта в пустоту (при закрытии их в нофоллоу), либо на ресурсы комментаторов или счетчиков (в случае отказа от его использования).
Собственно, я решил попробовать вообще убрать беклинки из комментариев и посмотреть как это повлияет на общее положение моего блога как в Гугле, так и в Яндексе. Если изменений в лучшую сторону не будет, то верну все как и было. Эксперимент получится, наверное, репрезентативным, ибо комментариев у меня около 6 000 и большинство из них имеют беклинк на ресурс комментатора.
Если кому-то интересно, то убрать ссылки из комментариев WordPress довольно просто. Вам нужно будет с помощью ftp клиента (менеджера) FileZilla подключиться по FTP и открыть на редактирование файл из папки с используемой вами темы Вордпресс. В нем вам нужно найти место, где прописан следующий кусочек кода:
<?php comment_author_link() ?>
и заменить его на чуть измененный вариант:
<?php comment_author() ?>
А так же для того, чтобы убрать из формы добавления нового комментария строчку для ввода URL, вам нужно будет удалить подобный участок кода:
<p>
<input type="text" name="url" id="url" value="<?php echo $comment_author_url; ?>" size="28" tabindex="3" class="textarea" />
<label for="url">
<?php _e('<acronym title="Uniform Resource Identifier">URI</acronym>'); ?>
</label>
</p>
Если приведенная мною теория насчет текущего положения с rel nofollow и noindex окажется правдивой, то должно произойти постепенное увеличение накопленного на блоге статического веса, что не преминет сказаться на позициях сайта в поисковой выдаче. В общем, поглядим.
P.S. Сейчас наиболее действенным способом закрытия ссылок и контента от индексации поисковиками является убирание их в Аякс. Об этом я писал в статье про Технический аудит и внутреннюю оптимизацию (пункт номер 6 под вторым подзаголовком).
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Обработка значения nofollow атрибута rel поисковой системой Google
Из официального справочного материала Google можно узнать, что поисковый робот по таким ссылкам не переходит. Если добавить к ссылке атрибут с указанным значением, то ссылка не попадает в сеть Google. Но закрытые таким образом от индексации страницы все равно появляются в индексе, если на них ведут открытые ссылки с других ресурсов или их адреса находятся в карте сайта. В тексте справки вы увидите словосочетание «как правило», которое использовали в предложении о переходе по закрытым от индексации ссылкам. Оно может означать, что поисковая система сама решает, переходить или не переходить, индексировать или не индексировать. Учитывая это и то, что другие поисковые системы не обращают внимания на nofollow, можно сказать, что закрытые таким образом ссылки способны приносить пользу наравне с открытыми.
Что это конкретно и как влияет?
Что это
Здесь может быть много всего:
- куски неуникального текста, взятые вами с чужого сайта и вставленные в вашу уникальную (изначально) статью,
- обилие кодов рекламы — тизеры, баннеры, контекстная реклама и другая,
- множество JavaScript-скриптов и кодов flash-приложений,
- разные блоки ссылок в сайдбаре вроде «наши друзья»,
- куча установленных счётчиков,
- и др.
Как влияет
Исходя из двух пунктов списка, указанных в начале статьи, влияет это так:
- портится уникальность текстов;
- происходит «разбавление» плотности ключевых слов страниц сайта.
Поэтому неплохо бы закрыть все лишние части материалов от индексации поисковыми роботами.
Как повысить эффективность закрытых ссылок
Чтобы пользователи сетевых ресурсов интересовались вашим контентом и переходили по ссылкам на продвигаемые страницы, нужно перед публикацией материалов и установкой ссылок тщательно проверять и тестировать важные элементы статьи и околоссылочного текста. Заголовки, лиды должны мотивировать посетителя перейти на ваш сайт, контент должен быть интересным, полезным и релевантным теме. Чтобы получить максимальную отдачу от ссылки:
- подбирайте не только площадку, но и место установки;
- определите цель для каждой ссылки;
- проверяйте релевантность контента;
- оптимизируйте посадочные страницы.
Ссылки, закрытые от индексации, могут быть полезнее, чем индексируемые. Все зависит от того, где установлена ссылка и куда приводит пользователя. Если для индексируемых ссылок это практически не имеет значения, то для nofollow-ссылок является основным фактором, определяющим ее полезность, так как цели для них преследуются разные. Наращивание массы индексируемых ссылок происходит преимущественно для поднятия показателей сайта, а неиндексируемых – исключительно для привлечения целевой аудитории. То есть открытые ссылки влияют на посещаемость продвигаемого сетевого ресурса косвенно, а закрытые напрямую.
В процессе ранжирования поисковые системы учитывают множество разнообразных факторов, причем делают это по-разному
«Яндекс», Google и другие поисковики принимают во внимание все ссылки, которые находят на страницах сетевых ресурсов, независимо от того, какие дополнительные атрибуты они имеют. Они лишь учитывают желание веб-мастера не допустить индексацию
Окончательное решение всегда остается за поисковой системой.
Noindex
Тег noindex используется, чтобы запретить индексацию какой-то определенной части текста. Следует помнить, что ссылки и изображения этот тег от поисковиков не закрывает. Если все-таки попытаться закрыть этим тегом анкор со ссылкой, то под индексацию не попадет только анкор (словосочетание), а сама ссылка однозначно попадает в индекс.
Noindex запрещает индексацию части кода, находящуюся между открывающим и закрывающим тегами. Вот пример:
Естественно, его не стоит путать с мета-тегом ноиндекс, который прописывается вначале страницы, они имеют различные задачи. Если взять мета-тег <meta name=»robots» content=»noindex,nofollow»> , то он запрещает индексирование всей страницы и переход по ссылкам. Этот запрет можно также прописать в файле robots.txt и такие страницы поисковыми роботами не будут учтены.
Валидный noindex
Некоторые HTML-редакторы noindex не воспринимают, поскольку он не является валидным. К примеру, в WordPress визуальный редактор его попросту удаляет. Но валидность тегу все же придать можно:
Если в HTML-редакторе прописать тег в такой форме, то он будет абсолютно валиден и можно не бояться, что он исчезнет. Тег noindex воспринимает только поисковый бот Яндекса, робот Гугла на него абсолютно не реагирует.
Некоторые оптимизаторы допускают ошибку, когда советуют закрыть все ссылки такими тегами noindex и nofollow, но об этом будет рассказано ниже. Что касается работы тега ноиндекс, то она безотказна. Абсолютно вся заключенная в этих тегах информация в индекс не попадает. Но некоторые вебмастера утверждают, что иногда все же текст внутри этих тегов индексируется ботами – да, действительно такое случается.
А это все потому, что Yandex изначально индексирует полностью весь html-код страницы, даже находящийся внутри noindex, но затем происходит фильтрация. Поэтому вначале действительно проиндексирована вся страница, но через некоторое время html-код срабатывает и тест, заключенный в этот тег «вылетает» из индексации.
Можно даже не соблюдать вложенность тега noindex – он все равно сработает (об этом рассказывается в справочной Яндекса). Не забывайте, используя, открывающий <noindex> в конце исключаемого текста поставить закрывающий </noindex>, а то весь текст, идущий после тега не проиндексируется.
Тэг nofollow
Атрибут nofollow предназначен для закрытия от индексации ссылок как для Гугла, так и для Яндекса. Он используется для того, чтобы не передавать вес со ссылающегося сайта на ссылаемый. То, что Яндекс не знает о нофоллоу — миф, убедитесь сами — . Кстати, тег nofollow не сохраняет вес на странице — если какая-та ссылка «нофоллоу», то вес по ней не перетекает, а сгорает, либо, если есть другие не закрытые данным тегом ссылки на странице, перераспределяется между ними. Кстати, отсюда следует, что если у вас на странице есть хотя бы одна активная внешняя гиперссылка, то вес со страницы уходит — поэтому не стоит закрывать все внешние ссылки тегом nofollow. Вес вы все равно не сохраните (он сгорит, если все внешние ссылки закрыть нофоллоу).
<a href="http://example.ru" rel="nofollow">анкор</a>
Бессмысленно ставить атрибут нофоллоу в ссылках, ведущих на внутренние страницы сайта — но бывает исключение из этого. Если вес со страницы необходимо передать только по определенным внутренним ссылкам, нужно лишь закрыть лишние «нофоллоу».
Тег
Noindex – тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш. Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
<noindex>Здесь находится закрытый для индексации контент</noindex>
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt. Недостаток данного способа очевиден: запрет на индексацию возможен только по отношению ко всей странице, но не отдельному текстовому фрагменту.
Преимущества тега noindex
- Сокрытие второстепенной информации позволяет повысить релевантность индексируемой страницы за счет возрастания относительной плотности ключевых фраз.
- С помощью noindex можно спрятать содержимое сквозных блоков, информация в которых будет дублироваться на нескольких страницах, что отразится на пессимизации сайта в поисковой выдаче Yandex.
- В некоторых случаях в сниппет может попасть нежелательная или служебная информация, которую проще всего скрыть тегом noindex.
Принцип действия noindex
Noindex может находиться в любом месте HTML-кода вне зависимости от уровня вложенности.
Несмотря на тот факт, что noindex был изначально предложен разработчиками Yandex, использование данного инструмента может быть расценено в качестве серого метода оптимизации. Это связано с тем, что некоторые веб-мастера применяют его не по прямому назначению. В частности, от робота прячется неуникальный контент или качественный текст, не содержащий ключевых слов, рассчитанный на прочтение посетителем сайта. Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Для борьбы с подобными методами оптимизации Yandex анализирует текст, закрытый тегом noindex, проводя его индексацию, но впоследствии отфильтровывая скрытое содержимое. В результате изучения контента страницы поисковик может принять решение о наложении санкций на сайт, если сочтет, что его владелец использует неправомерные способы влияния на результаты поисковой выдачи.
В чем разница rel=nofollow и
Так в чем же проблема?
Зачем Яндексу понадобилось вводить поддержку rel=»nofollow»?
тег <noindex> это личная инициатива Yandex
Атрибут со статусом rel=»nofollow» стандартизирован и используется во всем мире для указания поисковикам, что ссылка не одобрена автором и по ней не нужно следовать.
Например, если закрыть служебную страницу от индексации в robots.txt, а ссылку оставить открытой, робот проследует на данную страницу, но не проиндексирует ее. Зачем тогда тратить ресурсы робота на переходы по ненужным страницам? Еще есть один нюанс, если на вашу служебную страницу ведут открытые ссылки с других внешних источников, то ваша, как бы закрытая страница, попадет в поиск, даже если она закрыта в robots.txt. Об этом также расскажу в следующих статьях.
Исходя из всего этого, по многочисленным просьбам и жалобам веб-мастеров, Яндекс ввел поддержку стандартизированного W3C атрибута со статусом rel=»nofollow». Атрибут закрывает ссылки от переходов роботом и не передает вес. Теперь многое стало проще. Но есть один нюанс. Анкоры ссылок будут проиндексированы как текст.
How much time should you spend on reducing crawl budget?
You might hear a lot of talk on SEO forums about how important crawl efficiency and crawl budget is for SEO and, while it’s common practice to disallow and noindex large groups of pages that have no benefit to search engines or readers (for example, back-end code that is only used for the running of the site, or some types of duplicate content), deciding whether to hide lots of individual pages is probably not the best use of time and effort.
Google likes to index as many URLs as possible, so, unless there is a specific reason to hide a page from search engines, it’s usually ok to leave the decision up to Google. In any case, even if you hide pages from search engines, Google will still keep checking to see if those URLs have changed. This is especially pertinent if there are links pointing to that page; even if Google has forgotten about the URL, it might re-discover it the next time a link is found to it anyway.
Nofollow
Атрибут rel=»nofollow» имеет задачу закрывать от поисковиков ссылки, расположенные в тексте. Он используется оптимизаторами для исключения передачи веса со ссылающегося ресурса на ссылаемый. Яндексу об этом атрибуте прекрасно известно.
Необходимо знать, что nofollow вес на странице не сохраняет – если ссылка заключена в этот тег. Вес ресурса по ней не переходит, а наоборот «сгорает» или при присутствии на странице других не закрытых атрибутом ссылок, вес будет распределяться между ними. И если на странице сайта присутствует хотя бы одна внешняя активная ссылка, то вес страницы будет уходить.
Даже если вы закроете все внешние ссылки атрибутом nofollow – то вес все равно сохранен не будет – он «сгорит». Поэтому все внешние ссылки закрывать не имеет смысла.
Естественно, в ссылках, которые ведут на внутренние странички блога атрибут nofollow ставить бессмысленно, хотя бывают исключения. В тех случаях, когда вес со страницы нужно передать по выбранным внутренним ссылкам, все остальные можно закрыть.
Пример совместного использования nofollow и noindex
Прекрасно себя чувствуют оба тега nofollow и noindex, когда они находятся в непосредственной близости. Вот пример их использования:
Оформление ссылки, таким образом, поможет вам удержать вес страницы и к тому же поисковый бот Яндекса анкор не увидит. В заключении нужно сказать, что не нужно закрывать тегом ноиндекс ссылки, таким образом, вы запрещаете индексацию только анкора, но не самой ссылки. Для нее будет достаточно одного атрибута нофоллоу.
Совместное использование тега и атрибута noindex nofollow
Оба тега, и ноиндекс, и нофоллоу отлично чувствуют себя, когда их ставят рядом друг с другом. Пример их совместного использования:
<noindex><a href="http://example.ru" rel="nofollow">анкор</a></noindex>
Такая ссылка не передает вес по мнению поисковых систем, кроме того, Яндекс еще и не видит анкор.
Но как и было сказано выше, совсем необязательно закрывать ссылки тегом noindex, это бессмысленно. Вы так сможете запретить индексировать анкор, но не саму ссылку. Самой ссылке хватает тега nofollow. Но несмотря на это, многие оптимизаторы (в большей степени — новички), страхуясь, закрывают ссылку обеими тегами — nofollow noindex. Они лишь делают лишнюю работу — толка от нее никакого, задачи этих тегов разные. Просмотрите любую мою статью (к примеру эту — Работа копирайтинг, рерайтинг и свободная продажа статей), ни одна ссылка там не закрыта тегом ноиндекс. Не доверяете мне, загляните на блог опытного оптимизатора. И школа Старт Ап, учащая своих студентов закрывать все ссылки ноиндексом, ошибается.
Как работать с новыми атрибутами
Разберем, в каких случаях какой атрибут применять и что будет, если игнорировать новые правила.
Какой атрибут для исходящей ссылки выбрать
Если вы хотите специфицировать ссылку, рекомендации Google ясны:
- rel=»nofollow» – базовая запретительная директива. Ссылки с ней не используются для сканирования, индексирования и ранжирования контента;
- rel=»sponsored» – атрибут для обозначения рекламных (спонсорских, партнерских, покупных и т.п.) ссылок;
- rel=»ugc» – директива для ссылок в пользовательском контенте сайта. Применение атрибута не обязательно, если авторитет пользователя не вызывает сомнения.
| rel Value (Значение) | Описание |
| Без значения | С обычными ссылками атрибут rel не нужен. В таком случае вы разрешаете Google беспрепятственный переход по исходящей ссылке. Делаете это на свой страх и риск. |
| rel=»nofollow» | Используйте nofollow, когда все остальные значения не подходят. Применяется, когда вы не хотите, чтобы Google ассоциировал ваш сайт с ресурсом, на который указывает ссылка. Для внутренних ссылок запрет лучше прописывать в robots.txt. |
| rel=»sponsored» | Применяйте эту директиву для описания рекламных (спонсорских, платных) и похожих ссылок. |
| rel=»ugc» | Атрибут необходим для обозначения ссылок в контенте, созданном пользователями – комментарии на форумах, посты в блогах и т.д. Если вы хотите подчеркнуть особый авторитет пользователя на страницах вашего сайта (вы ему безоговорочно доверяете), снабжать его ссылку такой директивой не нужно. |
Google допускает комбинационное использование названных атрибутов для одной ссылки, например, rel=»nofollow sponsored».
Накажет ли Google за отсутствие nofollow-директив с покупными ссылками
Такая вероятность остается. Поисковик рекомендует обозначать рекламные линки с помощью rel=»sponsored» или rel=»nofollow». Директива rel=»ugc» в этом случае неприемлема.
Такой подход вызывает определенное непонимание в SEO-кругах. Что если посетитель вашего сайта разместил в своем комментарии или посте спонсорскую ссылку? Пока Google не разъяснил, как в такой ситуации поступать веб-мастеру.
Исходя из этого, можно предположить, что сеошники будут обозначать сомнительные ссылки пользователей при помощи rel=»nofollow» или rel=»nofollow ugc».
Помогут ли nofollow-атрибуты контролировать сканирование и индексирование
Директива nofollow всегда была слабым помощником в плане запрета индексации. Ничего не изменится и в будущем. Если хотите запретить Google индексировать страницы, тогда используйте другие более действенные методы, в основе которых команда noindex.
Что касается сканирования, то тут все несколько иначе. В прошлом многие владельцы крупных порталов использовали nofollow для экономии краулингового бюджета, а также в целях ограничения сканирования Гуглботом не самых важных внутренних страниц сайта.
Недавние заявления Google допускают такие действия и в будущем, однако с 1 марта следующего года nofollow-директивы могут игнорироваться – в некоторых случаях бот будет сканировать, несмотря на прописанный атрибутом запрет. SEO-экспертам нужно будет искать другие эффективные способы, чтобы закрыть от сканирования отдельные рубрики сайта.
Использование Noindex в Яндексе
Пользоваться им не сложнее, чем любым другим HTML-тегом. Обычно выглядит всё так:

Возможен и альтернативный вариант — тег ноиндекс в виде стандартного HTML-комментария. Вот, к примеру, как можно скрыть контекст от AdSense:
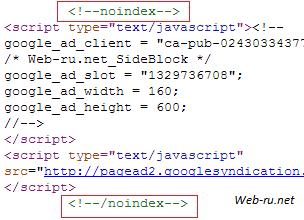
AdSense «завёрнут» в noindex tag
— т.е. всё то же самое, но добавляем указание на то, что это комментарий. На мой взгляд, такой вариант предпочтительней.
Кстати, чтобы узнать, где на веб-странице расставлены блоки тегов ноуиндекс, можно поставить:
- дополнение RDS bar в Chrome.
- дополнение Page Promoter bar в Firefox.
Они будут буквально «подсвечивать» участки кода, «завёрнутые» в этот тег. Правда, RDS bar иногда не подсвечивает вариант в формате комментария — noindex.
2.
Этот мета-тег устанавливается в секцию <head> на той странице, которая не должна индексироваться и в исходном коде выглядит так:
<head> ... <meta name ”robots” content=”noindex” /> ... </head>
В примере выше метатег запрещает индексацию на уровне страницы (весь контент, который на ней есть), но не запрещает поисковым роботам посещать ее и переходить по ссылкам, которые используются в контенте.
Но обычно используется комбинация с nofollow, чтобы запретить поисковому роботу переходить по ссылкам на данной странице (и по внешним, и по внутренним). В этом случае метатег выглядит так:
<head> ... <meta name ”robots” content=”noindex, nofollow” /> ... </head>
Возможные комбинации noindex + nofollow:
- <meta name=”robots” content=”noindex, follow” /> — используется в случае, если не нужно, чтобы страница была проиндексирована поисковиками, но роботам были доступны ссылки с этой страницы на другие внутренние или внешние ссылки с нее.
- <meta name=”robots” content=”noindex” /> выполняет то же самое. В данном случае вы запретите поисковой системе индексировать страницу, но индексация ссылок на ней возможна.
- <meta name=”robots” content=”noindex, nofollow” /> – запрещает индексировать контент на соответствующей странице + запрещает роботам переходить по ссылкам. Т.е. полный запрет индексирования страницы.
- <meta name=”robots” content=”index, follow” /> – разрешает роботам индексировать страницу и ходить по ссылкам. Использовать данный вариант смысла нет, так как по умолчанию, и без него поисковикам разрешено выполнять те же действия.
- <meta name=”robots” content=”index, nofollow” /> — разрешает индексировать страницу, но запрещает переходить по ссылкам и индексировать их.
- <meta name=”robots” content=”nofollow” /> — делает то же самое, т.е. разрешает индексировать контент на странице, но запрещает индексацию ссылок.
Отдельное использование Noindex для Google и Yandex
- <meta name=”googlebot” content=”noindex” /> — закрывает страницу от индексации для робота Google
- <meta name=”yandex” content=”noindex” /> — закрывает страницу от индексации для робота Yandex