Модели данных
Содержание:
- Введение
- Выбор первичного ключа
- Сетевая модель данных
- Бизнес и финансы
- Структура реляционной модели данных
- Подготовка эксперимента
- Иерархическая модель данных
- Описание
- Достоинства и недостатки реляционной модели данных
- Результат эксперимента
- Логические взаимосвязи
- 2.1 Иерархическая модель данных
- Сетевая модель данных
Введение
«Нужно бежать со всех ног, чтобы только оставаться на месте,
а чтобы куда-то попасть, надо бежать как минимум вдвое быстрее!»
(с) Алиса в стране чудес
Недавно, «от нечего делать», я задался вопросом (длинные майские выходные в режиме карантина к этому особенно располагают), насколько теоретические выкладки будут соответствовать практике? Собственно, так и родилась идея этой статьи. Разработчик, который не первый день работает с NoSQL, возможно и не почерпнет из нее что-то новое (и поэтому может сразу промотать полстатьи). Но для аналитиков, которые еще не работали плотно с NoSQL, полагаю, она будет полезна для получения базовых представлений об особенностях проектирования моделей данных для HBase.
Выбор первичного ключа
При создании сущности необходимо выделить группу атрибутов, которые потенциально могут стать первичным ключом (потенциальные ключи), затем произвести отбор атрибутов для включения в состав первичного ключа, следуя следующим рекомендациям:
Первичный ключ должен быть подобран таким образом, чтобы по значениям атрибутов, в него включенных, можно было точно идентифицировать экземпляр сущности. Никакой из атрибутов первичного ключа не должен иметь нулевое значение. Значения атрибутов первичного ключа не должны меняться. Если значение изменилось, значит, это уже другой экземпляр сущности.
При выборе первичного ключа можно внести в сущность дополнительный атрибут и сделать его ключом. Так, для определения первичного ключа часто используют уникальные номера, которые могут автоматически генерироваться системой при добавлении экземпляра сущности в БД. Применение уникальных номеров облегчает процесс индексации и поиска в БД.
Первичный ключ, выбранный при создании логической модели, может быть неудачным для осуществления эффективного доступа к БД и должен быть изменен при проектировании физической модели.
Потенциальный ключ, не ставший первичным, называется альтернативным ключом (Alternate Key). ERWin позволяет выделить атрибуты альтернативных ключей, и по умолчанию в дальнейшем при генерации схемы БД по этим атрибутам будет генерироваться уникальный индекс. При создании альтернативного ключа на диаграмме рядом с атрибутом появляются символы (АК).
Атрибуты, участвующие в неуникальных индексах, называются инверсионными входами (Inversion Entries). Инверсионные входы — это атрибут или группа атрибутов, которые не определяют экземпляр уникальным образом, но часто используются для обращения к экземплярам сущности. ERWin генерирует неуникальный индекс для каждого инверсионного входа.
При проведении связи между двумя сущностями в дочерней сущности автоматически образуются внешние ключи (foreign key). Связь образует ссылку на атрибуты первичного ключа в дочерней сущности, и эти атрибуты образуют внешний ключ в дочерней сущности. Атрибуты внешнего ключа обозначаются символами (FK) после своего имени.
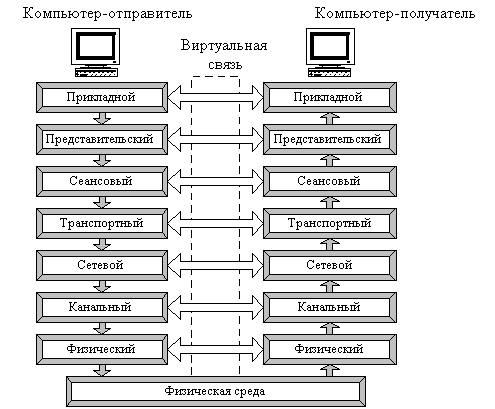
Сетевая модель данных
Определение 1
Базы данных являются моделью реального мира, потому в них находят свое представление объекты реального мира и связи между ними. Основой для сетевой модели данных является понятие ориентированного графа. В математике графом называется модель, состоящая из узлов и ребер.
Узлами являются объекты сетевой базы данных, а ребрами – связи между объектами. В реальном мире связи между объектами делятся на три типа:
- один-к-одному;
- один-ко-многим;
- много-ко-многим.
Сетевая модель поддерживает только два из этих типов: «один-к-одному» и «один-ко-многим». Ребра направленного графа показывают не только саму связь, то и тип связи.
Сетевая модель данных состоит из следующих структурных элементов:
- Атрибут – минимальная информационная единица данных, к которой пользователь может обратиться по имени. Аналогом атрибута является поле в реляционной модели данных.
- Агрегат данных – именованная совокупность данных, объединенная логикой содержимого и относящаяся к одному объекту. Например, если имеется атрибут «серия паспорта» и «номер паспорта», то их можно объединить в агрегат данных «паспортные данные». Это будет выглядеть как таблица с иерархическим заголовком.
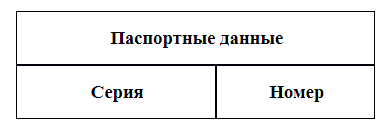
В реляционной модели данных аналогичное понятие отсутствует.
- Запись – совокупность атрибутов и/или агрегатов, соответствующая какому-либо объекту реального мира. Можно сказать, что запись – это агрегат, который не входит в другие агрегаты. В реляционной модели данных этому понятию соответствует таблица.
- Тип записи – совокупность записей с одинаковыми атрибутами.
-
Набор записей – структура, моделирующая связь между двумя типами записей. Если набор реализует отношение «один-ко-многим», то один тип записей в наборе называется «владельцем», другой – «подчиненным». Отношение «один-ко-многим» реализуется от владельца к подчиненным.
Например, между типами «Специальность» и «Студент» нужно установить связь типа «один-ко-многим», потому что на одной специальности учится много студентов. Тогда набор будет выглядеть, как показано на рисунке.
Тип записей «Специальность» является владельцем, тип записей «Студент» — подчиненным. Одной записи типа «Специальность» может соответствовать ноль или несколько записей типа «Студент». Связи устанавливаются за счет добавления в запись указателей на другие записи.
-
Сетевая база данных — это совокупность всех записей и наборов, которые достаточны для полного описания какой-либо предметной области.
Замечание 1
Сетевая база данных может состоять из любого количества записей и наборов разных типов. Две записи могут быть связаны любым количеством наборов, но в каждом наборе может быть только одна запись-владелец. Один и тот же тип записей может быть владельцем в одном наборе и подчиненным в другом наборе. Типа записи может вообще не входить ни в один набор.
Бизнес и финансы
БанкиБогатство и благосостояниеКоррупция(Преступность)МаркетингМенеджментИнвестицииЦенные бумагиУправлениеОткрытые акционерные обществаПроектыДокументыЦенные бумаги — контрольЦенные бумаги — оценкиОблигацииДолгиВалютаНедвижимость(Аренда)ПрофессииРаботаТорговляУслугиФинансыСтрахованиеБюджетФинансовые услугиКредитыКомпанииГосударственные предприятияЭкономикаМакроэкономикаМикроэкономикаНалогиАудитМеталлургияНефтьСельское хозяйствоЭнергетикаАрхитектураИнтерьерПолы и перекрытияПроцесс строительстваСтроительные материалыТеплоизоляцияЭкстерьерОрганизация и управление производством
Структура реляционной модели данных
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствованна соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формирую дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.
Подготовка эксперимента
Вышеизложенные теоретические рассуждения хотелось бы проверить на практике – это и было целью возникшей на долгих выходных задумки. Для этого необходимо оценить скорость работы нашего «условного приложения» во всех описанных сценариях использования базы, а также рост этого времени с ростом размера социальной сети (n). Целевым параметром, который нас интересует и который мы будем замерять в ходе эксперимента, является время, затраченное «условным приложением», на выполнение одной «бизнес-операции». Под «бизнес-операцией» мы понимаем одну из следующих:
- Добавление одного нового друга
- Проверка, является ли пользователь А другом пользователя Б
- Удаление одного друга
Таким образом, с учетом обозначенных в изначальной постановке требований, сценарий проверки вырисовывается следующий:
- Запись данных. Сгенерировать случайным образом исходную сеть размером n. Для большего приближения к «реальному миру» количество друзей у каждого пользователя – так же случайная величина. Замерить время, за которое наше «условное приложение» запишет в HBase все сгенерированные данные. Потом полученное время разделить на общее количество добавленных друзей – так мы получим среднее время на одну «бизнес-операцию»
- Чтение данных. Для каждого пользователя составить список «личностей», для которых надо получить ответ, подписан ли на них пользователь или нет. Длина списка = примерно кол-ву друзей пользователя, причем для половины проверяемых друзей ответ должен быть «Да», а для другой половины – «Нет». Проверка производится в таком порядке, чтобы ответы «Да» и «Нет» чередовались (то есть в каждом втором случае нам придется перебирать все колонки строки для вариантов 1 и 2). Общее время проверки затем разделить на количество проверяемых друзей для получения среднего времени на проверку одного субъекта.
- Удаление данных. Удалить у пользователя всех друзей. Причем порядок удаления – случайный (то есть «перемешиваем» изначальный список, использовавшийся для записи данных). Общее время проверки затем разделить на количество удаляемых друзей для получения среднего времени на одну проверку.
Сценарии необходимо прогнать для каждого из 5 вариантов моделей данных и для разных размеров социальной сети, чтобы посмотреть, как меняется время с ее ростом. В рамках одного n связи в сети и список пользователей для проверки должны быть, естественно, одинаковыми для всех 5 вариантов.
Для лучшего понимания ниже привожу пример сгенерированных данных для n= 5. Написанный «генератор» дает на выходе три словаря ID-шников:
- первый – для вставки
- второй – для проверки
- третий – для удаления
Как можно заметить, все ID, большие 10 000 в словаре для проверки – это как раз те, которые заведомо дадут ответ False. Вставка, проверка и удаление «друзей» производятся именно в указанной в словаре последовательности.
С учетом вычислительной мощности конкретного ноутбука экспериментально был выбран запуск для n = 10, 30, …. 170 – когда общее время работы полного цикла тестирования (все сценарии для всех вариантов для всех n) было еще более-менее разумным и умещалось во время одного чаепития (в среднем 15 минут).
Тут необходимо сделать ремарку, что в данном эксперименте мы в первую очередь оцениваем не абсолютные цифры производительности. Даже относительное сравнение разных двух вариантов может быть не совсем корректным. Сейчас нас интересует именно характер изменения времени в зависимости от n, так как с учетом указанной выше конфигурации «тестового стенда» получить временные оценки, «очищенные» от влияния случайных и прочих факторов, очень сложно (да и такой задачи не ставилось).
Иерархическая модель данных
Иерархическая
структура представляет совокупность
элементов, связанных между собой по
определенным правилам. Объекты, связанные
иерархическими отношениями, образуют
ориентированный граф (перевернутое
дерево), вид которого представлен на
рисунке. 21.
К основным понятиям
иерархической структуры относятся:
уровень, элемент (узел), связь. Узел
— это
совокупность атрибутов данных, описывающих
некоторый объект. На схеме иерархического
дерева узлы представляются вершинами
графа. Каждый узел на более низком уровне
связан только с одним узлом, находящимся
на более высоком уровне. Иерархическое
дерево имеет только одну вершину (корень
дерева), не подчиненную никакой другой
вершине и находящуюся на самом верхнем
(первом) уровне. Зависимые (подчиненные)
узлы находятся на втором, третьем и т.д.
уровнях. Количество деревьев в базе
данных определяется числом корневых
записей.
К каждой записи
базы данных существует только один
(иерархический) путь от корневой записи.
Например, как видно из рис. 21 для записи
С4 путь проходит через записи А и ВЗ.
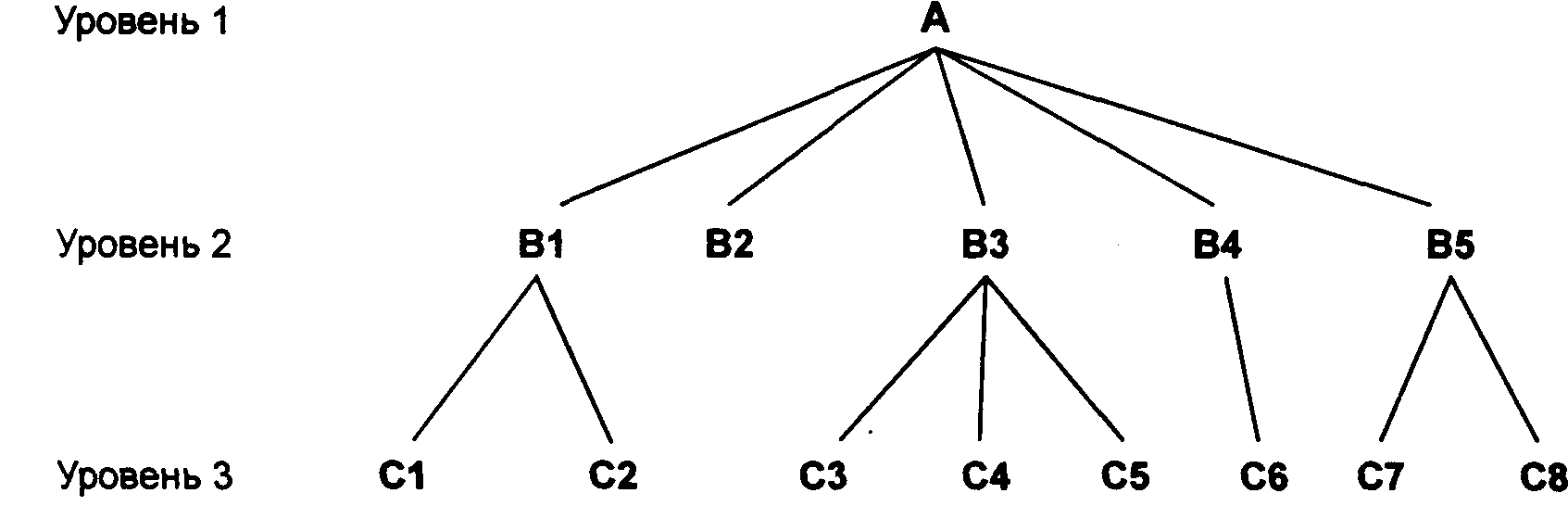
Рис.21 Графическое
изображение иерархической структуры
БД
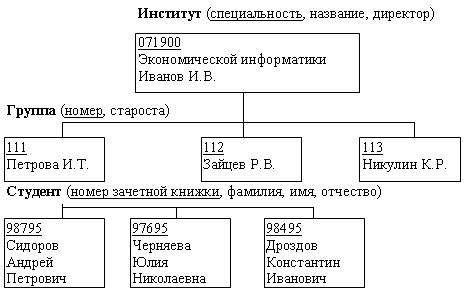
Пример.
Пример, представленный на рис. 15.9,
иллюстрирует использование иерархической
модели базы данных.Для рассматриваемого
примера иерархическая структура
правомерна, так как каждый студент
учится в определенной (только одной)
группе, которая относится к определенному
(только одному) институту

Рис. 22.
Пример иерархической структуры БД
Описание
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
- каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L.
Достоинства и недостатки реляционной модели данных
Достоинства
- Изложение информации в простой и понятной для пользователя форме (таблица).
- Реляционная модель данных основана на строгом математическом аппарате, что позволяет лаконично описывать необходимые операции над данными.
- Независимость данных от изменения в прикладной программе при изменении.
- Позволяет создавать языки манипулирования данными не процедурного типа.
- Для работы с моделью данных нет необходимости полностью знать организацию БД.
Недостатки
- Относительно медленный доступ к данным.
- Трудность в создании БД основанной на реляционной модели.
- Трудность в переводе в таблицу сложных отношений.
- Требуется относительно большой объем памяти.
Результат эксперимента
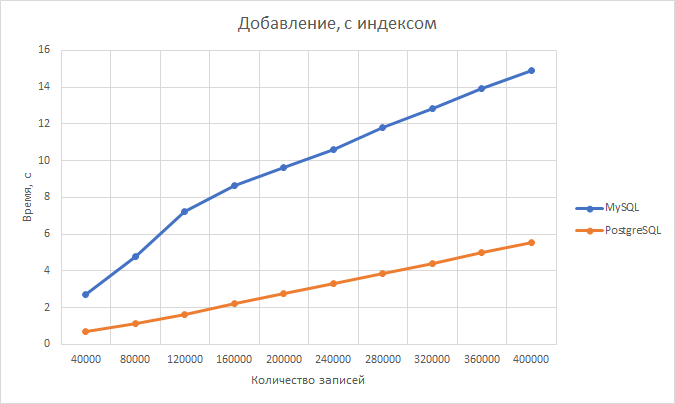
Первый тест – как меняется время, затрачиваемое на заполнение списка друзей. Результат – на графике ниже.
Варианты 3-5 ожидаемо показывают практически константное время «бизнес-операции», которое не зависит от роста размера сети и неотличимую разницу в производительности.
Вариант 2 показывает тоже константную, но чуть худшую производительность, причем практически ровно в 2 раза относительно вариантов 3-5. И это не может не радовать, так как соотноситься с теорией – в этом варианте количество операций ввода-вывода в/из HBase как раз в 2 раза больше. Это может служить косвенным свидетельством, что наш тестовый стенд в принципе дает неплохую точность.
Вариант 1 так же ожидаемо оказывается самым медленным и демонстрирует линейный от размера сети рост времени, затрачиваемого на добавление одно друга.
Посмотрим теперь результаты второго теста.
Варианты 3-5 опять же ведет себя ожидаемо – константное время, не зависящее от размера сети. Варианты 1 и 2 демонстрируют линейный рост времени при росте размера сети и схожую производительность. Причем вариант 2 оказывается чуть медленнее – по всей видимости из-за необходимости вычитки и обработки дополнительной колонки «count», что при росте n становится более заметным. Но я все же воздержусь от каких-либо выводов, так как точность данного сравнения относительно невысока. Кроме того, данные соотношения (какой вариант, 1 или 2, быстрее) менялись от запуска к запуску (при этом сохраняя характер зависимости и «идя ноздря в ноздрю»).
Ну и последний график – результат тестирования удаления.
Здесь опять же без сюрпризов. Варианты 3-5 осуществляют удаление за константное время.
Причем, что интересно, варианты 4 и 5, в отличии от предыдущих сценариев, показывают заметную чуть худшую производительность, чем вариант 3. По всей видимости, операция удаления строки – более затратная, нежели операция удаления колонки, что в целом логично.
Варианты 1 и 2, ожидаемо, демонстрируют линейный рост времени. При этом вариант 2 стабильно медленнее варианта 1 – из-за дополнительной операции ввода-вывода по «обслуживанию» колонки count.
Общие выводы эксперимента:
- Варианты 3-5 демонстрируют бОльшую эффективность, так как они использует преимущества HBase; при этом их производительность отличается друг относительно друга на константу и не зависит от размера сети.
- Разница между вариантами 4 и 5 не была зафиксирована. Но это не значит, что вариант 5 не следует использовать. Вполне вероятно, что используемый сценарий эксперимента с учетом ТТХ тестового стенда не позволил ее выявить.
- Характер роста времени, необходимого на выполнение «бизнес-операций» с данными, в целом подтвердил полученные ранее теоретические выкладки для всех вариантов.
Логические взаимосвязи
Логические взаимосвязи представляют собой связи между сущностями. Они определяются глаголами, показывающими, как одна сущность относится к другой.
Некоторые примеры взаимосвязей:
- команда включает много игроков,
- самолет перевозит много пассажиров,
- продавец продает много продуктов.
Во всех этих случаях взаимосвязи отражают взаимодействие между двумя сущностями, называемое «один-ко-многим». Это означает, что один экземпляр первой сущности взаимодействует с несколькими экземплярами другой сущности. Взаимосвязи отображаются линиями, соединяющими две сущности с точкой на одном конце и глаголом, располагаемым над линией.
Кроме взаимосвязи «один-ко-многим» существует еще один тип — это «многие-ко-многим». Этот тип связи описывает ситуацию, при которой экземпляры сущностей могут взаимодействовать с несколькими экземплярами других сущностей. Связь «многие-ко-многим» используют на первоначальных стадиях проектирования. Этот тип взаимосвязи отображается сплошной линией с точками на обоих концах.
Связь «многие-ко-многим» может не учитывать определенные ограничения системы, поэтому может быть заменена на «один-ко-многим» при последующем пересмотре проекта.
2.1 Иерархическая модель данных

В иерархической модели
связи между данными можно описать с
помощью упорядоченного графа (или
дерева). Упрощенно представление связей
между данными в иерархической модели
показано на рис. 2.1.
Рис. 2.1. Представление связей в
иерархической модели
Для описания структуры (схемы) иерархической
БД на некотором языке
программирования используется тип
данных «дерево».
Тип «дерево» схож
с типами данных «структура» языка
программирования С и «запись» языка
Паскаль. В них допускается вложенность
типов, каждый из которых находится на
некотором уровне.
Тип «дерево» является
составным. Он включает в себя подтипы
(«поддеревья»), каждый из которых, в
свою очередь, является типом «дерево».
Каждый из типов
«дерево» состоит из одного «корневого»
типа и упорядоченного
набора (возможно, пустого) подчиненных
типов. Каждый из элементарных
типов, включенных в тип «дерево», является
простым или составным типом «запись».
Простая «запись» состоит из одного
типа, например
числового, а составная «запись» объединяет
некоторую совокупность типов,
например целое, строку символов и
указатель (ссылку). Пример типа «дерево»
как совокупности типов показан на рис.
2.2.

Рис. 2.2. Пример типа «дерево»
Корневым называется
тип, который имеет подчиненные типы и
сам не является подтипом.Подчиненный
тип (подтип) являетсяпотомком по
отношению к типу,
который выступает для него в роли предка
(родителя). Потомки одного и того же
типа являютсяблизнецами по отношению
друг к другу.
В целом тип «дерево» представляет собой
иерархически организованный набор
типов «запись».
Иерархическая БД
представляет собой упорядоченную
совокупность экземпляров данных типа
«дерево» (деревьев), содержащих экземпляры
типа «запись»
(записи). Часто отношения родства между
типами переносят на отношения между
самими записями. Поля записей хранят
собственно числовые
или символьные значения, составляющие
основное содержание
БД. Обход всех элементов иерархической
БД обычно производится сверху
вниз и слева направо.
В иерархических СУБД может использоваться
терминология, отличающаяся от
приведенной выше (п.
1.1.3). Так, в СУБДIMSпонятию «запись» соответствует термин
«сегмент», а под «записью БД» понимается
вся совокупность записей,
относящаяся к одному экземпляру типа
«дерево».
Данные в базе с приведенной схемой (рис.
2.2) могут выглядеть, например,
как показано на рис. 2.3.
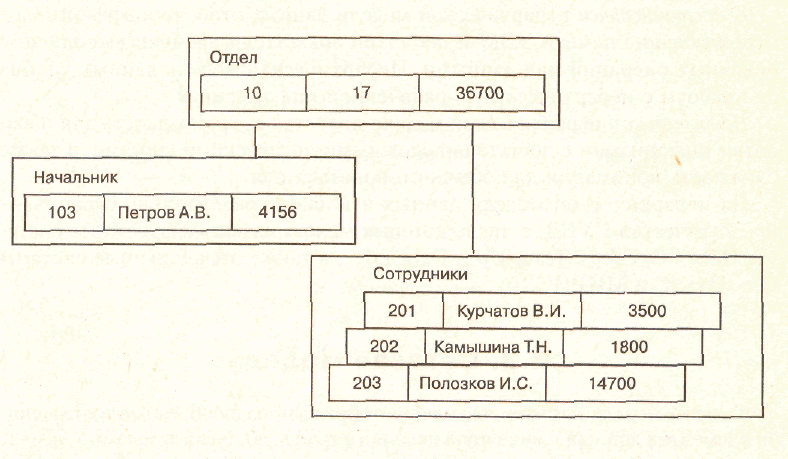
Рис. 2.3. Данные в иерархической базе
Для организации
физического
размещения
иерархических данных в памяти ЭВМ
могут использоваться следующие группы
методов:
• представление линейным списком с
последовательным распределением
памяти (адресная арифметика, левосписковые
структуры);
• представление
связными линейными списками (методы,
использующие
указатели и справочники).
К основным операциям
манипулирования иерархически
организованными
данными относятся следующие:
поиск указанного
экземпляра БД (например, дерева со
значением 10 в поле
Отд_номер);
переход от одного дерева к другому;
переход от одной записи к другой внутри
дерева (например, к следующей
записи типа Сотрудники);
вставка новой записи в указанную позицию;
удаление текущей записи и т. д.
В соответствии с
определением типа «дерево», можно
заключить, что между предками и
потомками автоматически поддерживается
контрольцелостности
связей. Основное правило контроля
целостности формулируется следующим
образом: потомок не может существовать
без родителя, а у некоторых родителей
может не быть потомков. Механизмыподдержания
целостности связей между записями
различных деревьев
отсутствуют.
К достоинствам
ИМД относятся
эффективное использование
памяти ЭВМ и неплохие показатели времени
выполнения основных
операций над данными. ИМД удобна для
работы с иерархически упорядоченной
информацией.
Недостатком ИМД
является ее громоздкость для обработки
информации с достаточно сложными
логическими связями, а такжесложность
понимания для обычного пользователя.
На ИМД основано
сравнительно ограниченное количество
СУБД, в числе которых можно назвать
зарубежные системы
IMS,
PC/Focus,
Tearn-Up
и Data
Edge,
а также российские системы Ока,
ИНЭС и МИРИС.
Сетевая модель данных
В сетевой структуре
при тех же основных понятиях (уровень,
узел, связь) каждый элемент может быть
связан с любым другим элементом. На рис.
23 изображена сетевая структура базы
данных в виде графа.
Пример.
Примером сложной сетевой структуры
может служить структура базы данных,
содержащей сведения о студентах,
участвующих в научно-исследовательских
работах (НИРС). Возможно участие одного
студента в нескольких НИРС, а также
участие нескольких студентов в разработке
одной НИРС. Графическое изображение
описанной в примере сетевой структуры,
состоящей только из двух типов записей,
показано на рис. 24. Единственное отношение
представляет собой сложную связь между
записями в обоих направлениях.
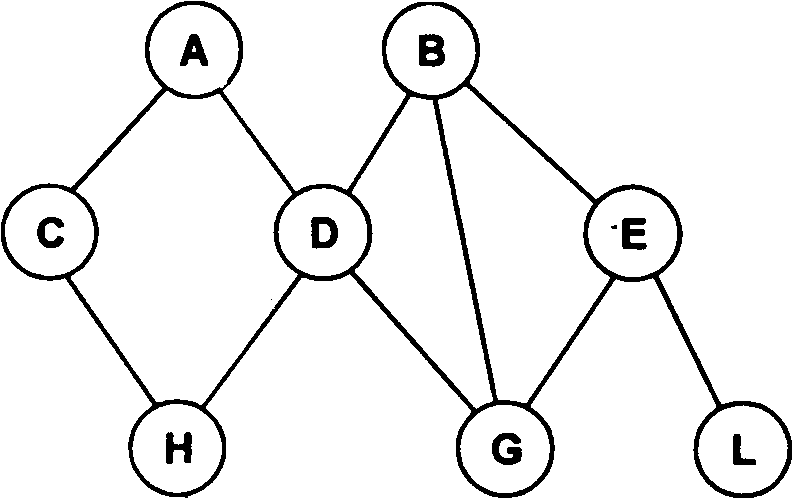
Рис. 23.
Графическое изображение сетевой
структуры
Студент
(номер зачетной
книжки,
фамилия, группа)
|
87695 |
85495 |
||
|
Иванов |
Петров |
||
|
111 |
112 |
||
Работа
(шифр, руководитель, область)’
|
1006 |
1009 |
1008 |
1005 |
||||
Рис. 24.
Пример сетевой структуры БД