Модуль json в python
Содержание:
Command Line Interface¶
The module provides a simple command line interface to
validate and pretty-print JSON.
If the optional and arguments are not
specified, and will be used respectively:
$ echo '{"json": "obj"}' | python -m simplejson.tool
{
"json": "obj"
}
$ echo '{1.2:3.4}' | python -m simplejson.tool
Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
Command line options
-
The JSON file to be validated or pretty-printed:
$ python -m simplejson.tool mp_films.json { "title": "And Now for Something Completely Different", "year": 1971 }, { "title": "Monty Python and the Holy Grail", "year": 1975 }If infile is not specified, read from .
-
Write the output of the infile to the given outfile. Otherwise, write it
to .
Footnotes
| As noted in the errata for RFC 7159, JSON permits literal U+2028 (LINE SEPARATOR) and U+2029 (PARAGRAPH SEPARATOR) characters in strings, whereas JavaScript (as of ECMAScript Edition 5.1) does not. |
JSON-Encoder.
Синтаксис:
import json
json.JSONEncoder(*, skipkeys=False, ensure_ascii=True,
check_circular=True, allow_nan=True,
sort_keys=False, indent=None,
separators=None, default=None)
Параметры:
- — игнорирование не базовых типов ключей в словарях,
- — экранирование не-ASSCI символов,
- — проверка циклических ссылок,
- — представление значений , , в JSON,
- — сортировка словарей,
- — количество отступов при сериализации,
- — разделители используемые в JSON,
- — метод подкласса для объектов, которые не могут быть сериализованы,
Описание:
Функция модуля расширяет возможности преобразование структур данных Python в формат JSON.
Поддерживает следующие объекты и типы по умолчанию:
| Python | JSON |
Чтобы расширить возможности преобразование других объектов, создайте подкласс и реализуйте в нем метод , который возвращает сериализуемый объект для , если это возможно, в противном случае он должен вызвать реализацию суперкласса, которая будет вызвать исключение .
Если аргумент имеет значение (по умолчанию), то вызывается для попытки преобразования ключей, которые не являются , , или . Если имеет значение , такие элементы просто пропускаются.
Если аргумент имеет значение (по умолчанию), на выходе гарантированно все входящие не ASCII символы будут экранированы последовательностями \uXXXX. Если имеет значение , то не ASCII символы будут выводиться как есть.
Если аргумент (по умолчанию), тогда списки, словари и самостоятельно закодированные объекты будут проверяться на циклические ссылки во время кодировки, чтобы предотвратить бесконечную рекурсию, что может вызвать исключение . В другом случае, такая проверка не выполняется.
Если аргумент (по умолчанию: ), при каждой попытке сериализировать значение , выходящее за допустимые пределы (, , ), будет возникать исключение , в соответствии с сертификацией JSON. В случае если , будут использованы JavaScript аналоги (, , ).
Если аргумент (по умолчанию: False), выводимый словарь будет отсортирован по именам ключей, что полезно для регрессивного тестирования.
Если аргумент является неотрицательным целым числом или строкой, то вложенные объекты и массивы JSON будут выводиться с этим количеством отступов. Если уровень отступа равен 0, отрицательный или является пустой строкой , будут использоваться новые строки без отступов. Если (по умолчанию), то на выходе JSON будет наиболее компактным. Если будет строкой типа , то это значение будет использоваться в качестве отступа.
Если указан аргумент , то он должен быть кортежем типа . По умолчанию используется если . Для получения наиболее компактного представления JSON следует использовать , чтобы уменьшить количество пробелов.
Значение должно быть методом подкласса . Он вызывается для объектов, которые не могут быть сериализованы. Метод должен вернуть кодируемую версию объекта JSON или вызывать исключение . Если аргумент не указан и какой-то из объектов не может быть преобразован в JSON, то возникает ошибка .
Методы класса .
Реализует метод в подклассе так, чтобы он возвращал сериализуемый объект для или вызывал базовую реализацию.
Например, чтобы поддерживать произвольные итераторы, вы можете реализовать метод следующим образом:
def default(self, obj):
try
iterable = iter(obj)
except TypeError
pass
else
return list(iterable)
# базовый класс вызывает исключение TypeError
return json.JSONEncoder.default(self, obj)
Возвращает строковое представление JSON структуры данных Python.
json.JSONEncoder().encode({"foo" \"bar", "baz"\]})
'{"foo": \}'
Преобразовывает переданный объект o и выдаёт каждое строковое представление, как только оно становится доступным. Например:
for chunk in json.JSONEncoder().iterencode(bigobject):
mysocket.write(chunk)
Openers and Handlers¶
When you fetch a URL you use an opener (an instance of the perhaps
confusingly-named ). Normally we have been using
the default opener — via — but you can create custom
openers. Openers use handlers. All the “heavy lifting” is done by the
handlers. Each handler knows how to open URLs for a particular URL scheme (http,
ftp, etc.), or how to handle an aspect of URL opening, for example HTTP
redirections or HTTP cookies.
You will want to create openers if you want to fetch URLs with specific handlers
installed, for example to get an opener that handles cookies, or to get an
opener that does not handle redirections.
To create an opener, instantiate an , and then call
repeatedly.
Alternatively, you can use , which is a convenience function for
creating opener objects with a single function call. adds
several handlers by default, but provides a quick way to add more and/or
override the default handlers.
Other sorts of handlers you might want to can handle proxies, authentication,
and other common but slightly specialised situations.
can be used to make an object the (global) default
opener. This means that calls to will use the opener you have
installed.
Exceptions Related to JSON Library in Python:
- Class json.JSONDecoderError handles the exception related to decoding operation. and it’s a subclass of ValueError.
- Exception — json.JSONDecoderError(msg, doc)
- Parameters of Exception are,
- msg – Unformatted Error message
- doc – JSON docs parsed
- pos – start index of doc when it’s failed
- lineno – line no shows correspond to pos
- colon – column no correspond to pos
Example,
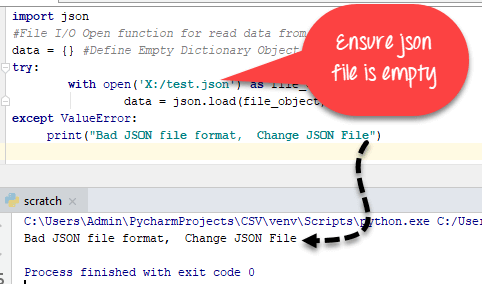
import json
#File I/O Open function for read data from JSON File
data = {} #Define Empty Dictionary Object
try:
with open('json_file_name.json') as file_object:
data = json.load(file_object)
except ValueError:
print("Bad JSON file format, Change JSON File")
Данные JSON
JSON (JavaScript Object Notation) стал одним из самых распространенных стандартных форматов для передачи данных в сети.
Одна из главных его особенностей — гибкость, хотя структура и не похожа на привычные таблицы.
В этом разделе вы узнаете, как использовать функции и для использования API. А в следующем — познакомитесь с другим примером взаимодействия со структурированными данными формата, который чаще встречается в реальной жизни.
http://jsonviewer.stack.hu/ — полезный онлайн-инструмент для проверки формата JSON. Нужно вставить данные в этом формате, и сайт покажет, представлены ли они в корректной форме, а также покажет дерево структуры.
Начнем с самого полезного примера, когда есть объект и его нужно конвертировать в файл JSON. Определим такой объект и используем его для вызова функции , указав название для итогового файла.
Он будет находится в рабочей папке и включать все данные в формате JSON.
Обратную операцию можно выполнить с помощью функции . Параметром здесь должен выступать файл с данными.
| down | left | right | up | |
|---|---|---|---|---|
| black | 5 | 7 | 6 | 4 |
| blue | 13 | 15 | 14 | 12 |
| red | 9 | 11 | 10 | 8 |
| white | 1 | 3 | 2 |
Это был простейший пример, где данные JSON представлены в табличной форме (поскольку источником файла служил именно такой объект — ). Но в большинстве случаев у JSON-файлов нет такой четкой структуры. Поэтому нужно конвертировать файл в табличную форму. Этот процесс называется нормализацией.
Библиотека pandas предоставляет функцию , которая умеет конвертировать объект или список в таблицу. Для начала ее нужно импортировать:
Создадим JSON-файл как в следующем примере с помощью любого текстового редактора и сохраним его в рабочей директории как .
Как видите, структура файла более сложная и не похожа на таблицу. В таком случае функция уже не сработает. Однако данные в нужной форме все еще можно получить. Во-первых, нужно загрузить содержимое файла и конвертировать его в строку.
После этого можно использовать функцию . Например, можно получить список книг. Для этого необходимо указать ключ в качестве второго параметра.
| price | title | |
|---|---|---|
| 23.56 | XML Cookbook | |
| 1 | 50.70 | Python Fundamentals |
| 2 | 12.30 | The NumPy library |
| 3 | 28.60 | Java Enterprise |
| 4 | 31.35 | HTML5 |
| 5 | 28.30 | Python for Dummies |
Функция считает содержимое всех элементов, у которых ключом является . Все свойства будут конвертированы в имена вложенных колонок, а соответствующие значения заполнят объект . В качестве индексов будет использоваться возрастающая последовательность чисел.
Однако в этом случае включает только внутреннюю информацию. Не лишним было бы добавить и значения остальных ключей на том же уровне. Для этого необходимо добавить другие колонки, вставив список ключей в качестве третьего элемента функции.
| price | title | writer | nationality | |
|---|---|---|---|---|
| 23.56 | XML Cookbook | Mark Ross | USA | |
| 1 | 50.70 | Python Fundamentals | Mark Ross | USA |
| 2 | 12.30 | The NumPy library | Mark Ross | USA |
| 3 | 28.60 | Java Enterprise | Barbara Bracket | UK |
| 4 | 31.35 | HTML5 | Barbara Bracket | UK |
| 5 | 28.30 | Python for Dummies | Barbara Bracket | UK |
Результатом будет с готовой структурой.
Standard Compliance and Interoperability¶
The JSON format is specified by RFC 7159 and by
ECMA-404.
This section details this module’s level of compliance with the RFC.
For simplicity, and subclasses, and
parameters other than those explicitly mentioned, are not considered.
This module does not comply with the RFC in a strict fashion, implementing some
extensions that are valid JavaScript but not valid JSON. In particular:
- Infinite and NaN number values are accepted and output;
- Repeated names within an object are accepted, and only the value of the last
name-value pair is used.
Since the RFC permits RFC-compliant parsers to accept input texts that are not
RFC-compliant, this module’s deserializer is technically RFC-compliant under
default settings.
Character Encodings
The RFC recommends that JSON be represented using either UTF-8, UTF-16, or
UTF-32, with UTF-8 being the recommended default for maximum interoperability.
As permitted, though not required, by the RFC, this module’s serializer sets
ensure_ascii=True by default, thus escaping the output so that the resulting
strings only contain ASCII characters.
Other than the ensure_ascii parameter, this module is defined strictly in
terms of conversion between Python objects and
, and thus does not otherwise directly address
the issue of character encodings.
The RFC prohibits adding a byte order mark (BOM) to the start of a JSON text,
and this module’s serializer does not add a BOM to its output.
The RFC permits, but does not require, JSON deserializers to ignore an initial
BOM in their input. This module’s deserializer will ignore an initial BOM, if
present.
Changed in version 3.6.0: Older versions would raise when an initial BOM is present
The RFC does not explicitly forbid JSON strings which contain byte sequences
that don’t correspond to valid Unicode characters (e.g. unpaired UTF-16
surrogates), but it does note that they may cause interoperability problems.
By default, this module accepts and outputs (when present in the original
) codepoints for such sequences.
Infinite and NaN Number Values
The RFC does not permit the representation of infinite or NaN number values.
Despite that, by default, this module accepts and outputs ,
, and as if they were valid JSON number literal values:
>>> # Neither of these calls raises an exception, but the results are not valid JSON
>>> json.dumps(float('-inf'))
'-Infinity'
>>> json.dumps(float('nan'))
'NaN'
>>> # Same when deserializing
>>> json.loads('-Infinity')
-inf
>>> json.loads('NaN')
nan
In the serializer, the allow_nan parameter can be used to alter this
behavior. In the deserializer, the parse_constant parameter can be used to
alter this behavior.
Repeated Names Within an Object
The RFC specifies that the names within a JSON object should be unique, but
does not mandate how repeated names in JSON objects should be handled. By
default, this module does not raise an exception; instead, it ignores all but
the last name-value pair for a given name:
>>> weird_json = '{"x": 1, "x": 2, "x": 3}'
>>> json.loads(weird_json) == {'x' 3}
True
The object_pairs_hook parameter can be used to alter this behavior.
Top-level Non-Object, Non-Array Values
The old version of JSON specified by the obsolete RFC 4627 required that
the top-level value of a JSON text must be either a JSON object or array
(Python or ), and could not be a JSON null,
boolean, number, or string value. RFC 7159 removed that restriction, and
this module does not and has never implemented that restriction in either its
serializer or its deserializer.
Regardless, for maximum interoperability, you may wish to voluntarily adhere
to the restriction yourself.
Fetching URLs¶
The simplest way to use urllib.request is as follows:
import urllib.request
with urllib.request.urlopen('http://python.org/') as response
html = response.read()
If you wish to retrieve a resource via URL and store it in a temporary location,
you can do so via the function:
import urllib.request
local_filename, headers = urllib.request.urlretrieve('http://python.org/')
html = open(local_filename)
Many uses of urllib will be that simple (note that instead of an ‘http:’ URL we
could have used a URL starting with ‘ftp:’, ‘file:’, etc.). However, it’s the
purpose of this tutorial to explain the more complicated cases, concentrating on
HTTP.
HTTP is based on requests and responses — the client makes requests and servers
send responses. urllib.request mirrors this with a object which represents
the HTTP request you are making. In its simplest form you create a Request
object that specifies the URL you want to fetch. Calling with this
Request object returns a response object for the URL requested. This response is
a file-like object, which means you can for example call on the
response:
import urllib.request
req = urllib.request.Request('http://www.voidspace.org.uk')
with urllib.request.urlopen(req) as response
the_page = response.read()
Note that urllib.request makes use of the same Request interface to handle all URL
schemes. For example, you can make an FTP request like so:
req = urllib.request.Request('ftp://example.com/')
In the case of HTTP, there are two extra things that Request objects allow you
to do: First, you can pass data to be sent to the server. Second, you can pass
extra information (“metadata”) about the data or the about request itself, to
the server — this information is sent as HTTP “headers”. Let’s look at each of
these in turn.
Data
Sometimes you want to send data to a URL (often the URL will refer to a CGI
(Common Gateway Interface) script or other web application). With HTTP,
this is often done using what’s known as a POST request. This is often what
your browser does when you submit a HTML form that you filled in on the web. Not
all POSTs have to come from forms: you can use a POST to transmit arbitrary data
to your own application. In the common case of HTML forms, the data needs to be
encoded in a standard way, and then passed to the Request object as the
argument. The encoding is done using a function from the
library.
import urllib.parse
import urllib.request
url = 'http://www.someserver.com/cgi-bin/register.cgi'
values = {'name' 'Michael Foord',
'location' 'Northampton',
'language' 'Python' }
data = urllib.parse.urlencode(values)
data = data.encode('ascii') # data should be bytes
req = urllib.request.Request(url, data)
with urllib.request.urlopen(req) as response
the_page = response.read()
Note that other encodings are sometimes required (e.g. for file upload from HTML
forms — see for more
details).
If you do not pass the argument, urllib uses a GET request. One
way in which GET and POST requests differ is that POST requests often have
“side-effects”: they change the state of the system in some way (for example by
placing an order with the website for a hundredweight of tinned spam to be
delivered to your door). Though the HTTP standard makes it clear that POSTs are
intended to always cause side-effects, and GET requests never to cause
side-effects, nothing prevents a GET request from having side-effects, nor a
POST requests from having no side-effects. Data can also be passed in an HTTP
GET request by encoding it in the URL itself.
This is done as follows:
>>> import urllib.request
>>> import urllib.parse
>>> data = {}
>>> data'name' = 'Somebody Here'
>>> data'location' = 'Northampton'
>>> data'language' = 'Python'
>>> url_values = urllib.parse.urlencode(data)
>>> print(url_values) # The order may differ from below.
name=Somebody+Here&language=Python&location=Northampton
>>> url = 'http://www.example.com/example.cgi'
>>> full_url = url + '?' + url_values
>>> data = urllib.request.urlopen(full_url)
Notice that the full URL is created by adding a to the URL, followed by
the encoded values.
Footnotes¶
This document was reviewed and revised by John Lee.
-
Google for example.
-
Browser sniffing is a very bad practice for website design — building
sites using web standards is much more sensible. Unfortunately a lot of
sites still send different versions to different browsers. -
The user agent for MSIE 6 is
‘Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)’ -
For details of more HTTP request headers, see
Quick Reference to HTTP Headers. -
In my case I have to use a proxy to access the internet at work. If you
attempt to fetch localhost URLs through this proxy it blocks them. IE
is set to use the proxy, which urllib picks up on. In order to test
scripts with a localhost server, I have to prevent urllib from using
the proxy. -
urllib opener for SSL proxy (CONNECT method): ASPN Cookbook Recipe.
Basic Authentication¶
To illustrate creating and installing a handler we will use the
. For a more detailed discussion of this subject –
including an explanation of how Basic Authentication works — see the Basic
Authentication Tutorial.
When authentication is required, the server sends a header (as well as the 401
error code) requesting authentication. This specifies the authentication scheme
and a ‘realm’. The header looks like: .
e.g.
WWW-Authenticate Basic realm="cPanel Users"
The client should then retry the request with the appropriate name and password
for the realm included as a header in the request. This is ‘basic
authentication’. In order to simplify this process we can create an instance of
and an opener to use this handler.
The uses an object called a password manager to handle
the mapping of URLs and realms to passwords and usernames. If you know what the
realm is (from the authentication header sent by the server), then you can use a
. Frequently one doesn’t care what the realm is. In that
case, it is convenient to use . This allows
you to specify a default username and password for a URL. This will be supplied
in the absence of you providing an alternative combination for a specific
realm. We indicate this by providing as the realm argument to the
method.
The top-level URL is the first URL that requires authentication. URLs “deeper”
than the URL you pass to .add_password() will also match.
# create a password manager password_mgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # Add the username and password. # If we knew the realm, we could use it instead of None. top_level_url = "http://example.com/foo/" password_mgr.add_password(None, top_level_url, username, password) handler = urllib.request.HTTPBasicAuthHandler(password_mgr) # create "opener" (OpenerDirector instance) opener = urllib.request.build_opener(handler) # use the opener to fetch a URL opener.open(a_url) # Install the opener. # Now all calls to urllib.request.urlopen use our opener. urllib.request.install_opener(opener)
Note
In the above example we only supplied our to
. By default openers have the handlers for normal situations
– (if a proxy setting such as an
environment variable is set), , ,
, , ,
, , .
urllib.request Restrictions¶
-
Currently, only the following protocols are supported: HTTP (versions 0.9 and
1.0), FTP, local files, and data URLs.Changed in version 3.4: Added support for data URLs.
-
The caching feature of has been disabled until someone
finds the time to hack proper processing of Expiration time headers. -
There should be a function to query whether a particular URL is in the cache.
-
For backward compatibility, if a URL appears to point to a local file but the
file can’t be opened, the URL is re-interpreted using the FTP protocol. This
can sometimes cause confusing error messages. -
The and functions can cause arbitrarily
long delays while waiting for a network connection to be set up. This means
that it is difficult to build an interactive Web client using these functions
without using threads. -
The data returned by or is the raw data
returned by the server. This may be binary data (such as an image), plain text
or (for example) HTML. The HTTP protocol provides type information in the reply
header, which can be inspected by looking at the Content-Type
header. If the returned data is HTML, you can use the module
to parse it. -
The code handling the FTP protocol cannot differentiate between a file and a
directory. This can lead to unexpected behavior when attempting to read a URL
that points to a file that is not accessible. If the URL ends in a , it is
assumed to refer to a directory and will be handled accordingly. But if an
attempt to read a file leads to a 550 error (meaning the URL cannot be found or
is not accessible, often for permission reasons), then the path is treated as a
directory in order to handle the case when a directory is specified by a URL but
the trailing has been left off. This can cause misleading results when
you try to fetch a file whose read permissions make it inaccessible; the FTP
code will try to read it, fail with a 550 error, and then perform a directory
listing for the unreadable file. If fine-grained control is needed, consider
using the module, subclassing , or changing
_urlopener to meet your needs.
Convert from Python to JSON
If you have a Python object, you can convert it into a JSON string by
using the method.
Example
Convert from Python to JSON:
import json# a Python object (dict):x = { «name»:
«John», «age»: 30, «city»: «New York»}#
convert into JSON:y = json.dumps(x)# the result is a JSON string:
print(y)
You can convert Python objects of the following types, into JSON strings:
- dict
- list
- tuple
- string
- int
- float
- True
- False
- None
Example
Convert Python objects into JSON strings, and print the values:
import jsonprint(json.dumps({«name»: «John», «age»: 30}))print(json.dumps())print(json.dumps((«apple», «bananas»)))
print(json.dumps(«hello»))print(json.dumps(42))print(json.dumps(31.76))print(json.dumps(True))print(json.dumps(False))print(json.dumps(None))
When you convert from Python to JSON, Python objects are converted into the JSON (JavaScript) equivalent:
| Python | JSON |
|---|---|
| dict | Object |
| list | Array |
| tuple | Array |
| str | String |
| int | Number |
| float | Number |
| True | true |
| False | false |
| None | null |
Example
Convert a Python object containing all the legal data types:
import jsonx = { «name»:
«John», «age»: 30, «married»: True,
«divorced»: False, «children»: («Ann»,»Billy»), «pets»:
None, «cars»:
}print(json.dumps(x))
Performance
Serialization and deserialization performance of orjson is better than
ultrajson, rapidjson, simplejson, or json. The benchmarks are done on
fixtures of real data:
-
twitter.json, 631.5KiB, results of a search on Twitter for «一», containing
CJK strings, dictionaries of strings and arrays of dictionaries, indented. -
github.json, 55.8KiB, a GitHub activity feed, containing dictionaries of
strings and arrays of dictionaries, not indented. -
citm_catalog.json, 1.7MiB, concert data, containing nested dictionaries of
strings and arrays of integers, indented. -
canada.json, 2.2MiB, coordinates of the Canadian border in GeoJSON
format, containing floats and arrays, indented.
Latency
twitter.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.59 | 1698.8 | 1 |
| ujson | 2.14 | 464.3 | 3.64 |
| rapidjson | 2.39 | 418.5 | 4.06 |
| simplejson | 3.15 | 316.9 | 5.36 |
| json | 3.56 | 281.2 | 6.06 |
twitter.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 2.28 | 439.3 | 1 |
| ujson | 2.89 | 345.9 | 1.27 |
| rapidjson | 3.85 | 259.6 | 1.69 |
| simplejson | 3.66 | 272.1 | 1.61 |
| json | 4.05 | 246.7 | 1.78 |
github.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.07 | 15265.2 | 1 |
| ujson | 0.22 | 4556.7 | 3.35 |
| rapidjson | 0.26 | 3808.9 | 4.02 |
| simplejson | 0.37 | 2690.4 | 5.68 |
| json | 0.35 | 2847.8 | 5.36 |
github.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.18 | 5610.1 | 1 |
| ujson | 0.28 | 3540.7 | 1.58 |
| rapidjson | 0.33 | 3031.5 | 1.85 |
| simplejson | 0.29 | 3385.6 | 1.65 |
| json | 0.29 | 3402.1 | 1.65 |
citm_catalog.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.99 | 1008.5 | 1 |
| ujson | 3.69 | 270.7 | 3.72 |
| rapidjson | 3.55 | 281.4 | 3.58 |
| simplejson | 11.76 | 85.1 | 11.85 |
| json | 6.89 | 145.1 | 6.95 |
citm_catalog.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 4.53 | 220.5 | 1 |
| ujson | 5.67 | 176.5 | 1.25 |
| rapidjson | 7.51 | 133.3 | 1.66 |
| simplejson | 7.54 | 132.7 | 1.66 |
| json | 7.8 | 128.2 | 1.72 |
canada.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 4.72 | 198.9 | 1 |
| ujson | 17.76 | 56.3 | 3.77 |
| rapidjson | 61.83 | 16.2 | 13.11 |
| simplejson | 80.6 | 12.4 | 17.09 |
| json | 52.38 | 18.8 | 11.11 |
canada.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 10.28 | 97.4 | 1 |
| ujson | 16.49 | 60.5 | 1.6 |
| rapidjson | 37.92 | 26.4 | 3.69 |
| simplejson | 37.7 | 26.5 | 3.67 |
| json | 37.87 | 27.6 | 3.68 |
Memory
orjson’s memory usage when deserializing is similar to or lower than
the standard library and other third-party libraries.
This measures, in the first column, RSS after importing a library and reading
the fixture, and in the second column, increases in RSS after repeatedly
calling on the fixture.
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 13.5 | 2.5 |
| ujson | 14 | 4.1 |
| rapidjson | 14.7 | 6.5 |
| simplejson | 13.2 | 2.5 |
| json | 12.9 | 2.3 |
github.json
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 13.1 | 0.3 |
| ujson | 13.5 | 0.3 |
| rapidjson | 14 | 0.7 |
| simplejson | 12.6 | 0.3 |
| json | 12.3 | 0.1 |
citm_catalog.json
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 14.6 | 7.9 |
| ujson | 15.1 | 11.1 |
| rapidjson | 15.8 | 36 |
| simplejson | 14.3 | 27.4 |
| json | 14 | 27.2 |
canada.json
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 17.1 | 15.7 |
| ujson | 17.6 | 17.4 |
| rapidjson | 18.3 | 17.9 |
| simplejson | 16.9 | 19.6 |
| json | 16.5 | 19.4 |
Reproducing
The above was measured using Python 3.8.3 on Linux (x86_64) with
orjson 3.3.0, ujson 3.0.0, python-rapidson 0.9.1, and simplejson 3.17.2.
The latency results can be reproduced using the and
scripts. The memory results can be reproduced using the script.
Command Line Interface¶
Source code: Lib/json/tool.py
The module provides a simple command line interface to validate
and pretty-print JSON objects.
If the optional and arguments are not
specified, and will be used respectively:
$ echo '{"json": "obj"}' | python -m json.tool
{
"json": "obj"
}
$ echo '{1.2:3.4}' | python -m json.tool
Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
Changed in version 3.5: The output is now in the same order as the input. Use the
option to sort the output of dictionaries
alphabetically by key.
Command line options
-
The JSON file to be validated or pretty-printed:
$ python -m json.tool mp_films.json { "title": "And Now for Something Completely Different", "year": 1971 }, { "title": "Monty Python and the Holy Grail", "year": 1975 }If infile is not specified, read from .
-
Write the output of the infile to the given outfile. Otherwise, write it
to .
-
Sort the output of dictionaries alphabetically by key.
New in version 3.5.
-
Disable escaping of non-ascii characters, see for more information.
New in version 3.9.
-
Parse every input line as separate JSON object.
New in version 3.8.
-
Mutually exclusive options for whitespace control.
New in version 3.9.
-
Show the help message.
Footnotes
-
As noted in the errata for RFC 7159,
JSON permits literal U+2028 (LINE SEPARATOR) and
U+2029 (PARAGRAPH SEPARATOR) characters in strings, whereas JavaScript
(as of ECMAScript Edition 5.1) does not.