Строки
Содержание:
- Объединение
- Точка – это любой символ
- offsetWidth/Height
- Точка с запятой
- JavaScript subString: Main Tips
- Строка как объект
- The slice() Method
- Точка и перенос строки
- str.replace(str|regexp, str|func)
- String Methods
- JS Учебник
- Сравнение строк в JavaScript
- Обратные символьные классы
- substring() Explained
- Поиск подстроки в строке средствами sql
- Метод slice ()
- Строковые функции
- Нюансы сравнения строк
- Backreferences в паттерне и при замене
- Методы строк
- Спецсимволы
Объединение

Рассмотрим основные аспекты, связанные с объединением строк и строковых переменных.
Стандартный способ:
let s1 = ‘Hello’;
let s2 = ‘world’;
let s3 = s1 + s2 + ‘!’;
console.log(s3); // Hello world!
Вместо одинарных кавычек можно использовать двойные. Кроме этого, кавычки внутри строки можно экранировать обратным слешем.
let s1 = «It’s string»;
let s2 = ‘It\’s string’;
Применяется в JavaScript и ещё один тип кавычек — обратные. Их применяют для использования переменных внутри строк.
let s1 = ‘Hello’;
let s2 = ‘world’;
let s3 = `${s1} ${s2}!`;
console.log(s3); // Hello world!
Ещё один способ объединения, использовать функцию «concat».
let s1 = ‘Hello’;
let s2 = ‘world’;
let s3 = s1.concat(‘ ‘, s2, ‘!’);
console.log(s3); // Hello world!
Здесь в переменную «s3», будет присваиваться значение переменной «s1», объедененное с пробелом, «s2» и восклицательным знаком
Важно, значение «s1» не изменится
Точка – это любой символ
Точка – это специальный символьный класс, который соответствует «любому символу, кроме новой строки».
Для примера:
Или в середине регулярного выражения:
Обратите внимание, что точка означает «любой символ», но не «отсутствие символа». Там должен быть какой-либо символ, чтобы соответствовать условию поиска:. Обычно точка не соответствует символу новой строки
Обычно точка не соответствует символу новой строки .
То есть, регулярное выражение будет искать символ и затем , с любым символом между ними, кроме перевода строки :
Но во многих ситуациях точкой мы хотим обозначить действительно «любой символ», включая перевод строки.
Как раз для этого нужен флаг . Если регулярное выражение имеет его, то точка соответствует буквально любому символу:
Внимание, пробелы!
Обычно мы уделяем мало внимания пробелам. Для нас строки и практически идентичны.
Но если регулярное выражение не учитывает пробелы, оно может не сработать.
Давайте попробуем найти цифры, разделённые дефисом:
Исправим это, добавив пробелы в регулярное выражение :
Пробел – это символ. Такой же важный, как любой другой.
Нельзя просто добавить или удалить пробелы из регулярного выражения, и ожидать, что оно будет также работать.
Другими словами, в регулярном выражении все символы имеют значение, даже пробелы.
offsetWidth/Height
Теперь переходим к самому элементу.
Эти два свойства – самые простые. Они содержат «внешнюю» ширину/высоту элемента, то есть его полный размер, включая рамки .
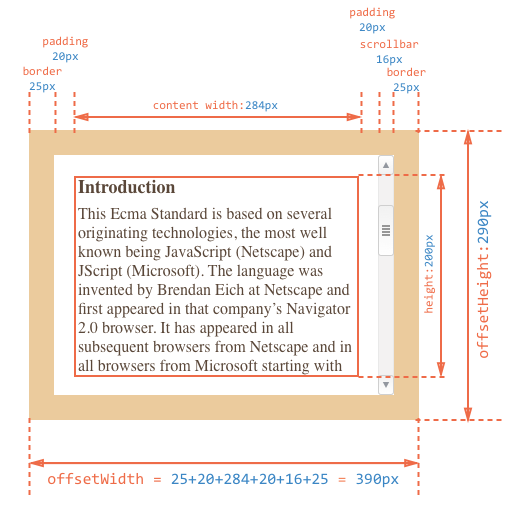
Для нашего элемента:
- – внешняя ширина блока, её можно получить сложением CSS-ширины (, но её часть на рисунке выше отнимает прокрутка, поэтому ), полей() и рамок ().
- – внешняя высота блока.
Метрики для невидимых элементов равны нулю.
Координаты и размеры в JavaScript устанавливаются только для видимых элементов.
Для элементов с или находящихся вне документа дерево рендеринга не строится. Для них метрики равны нулю. Кстати, и для таких элементов тоже .
Это даёт нам замечательный способ для проверки, виден ли элемент:
- Работает, даже если родителю элемента установлено свойство .
- Работает для всех элементов, кроме , с которым возникают некоторые проблемы в разных браузерах. Обычно, проверяются не , поэтому всё ок.
- Считает элемент видимым, даже если позиционирован за пределами экрана или имеет свойство .
- «Схлопнутый» элемент, например пустой без высоты и ширины, будет считаться невидимым.
Точка с запятой
В большинстве случаев точку с запятой можно не ставить, если есть переход на новую строку.
Так тоже будет работать:
В этом случае JavaScript интерпретирует перенос строки как «неявную» точку с запятой. Это называется .
В большинстве случаев новая строка подразумевает точку с запятой. Но «в большинстве случаев» не значит «всегда»!
В некоторых ситуациях новая строка всё же не означает точку с запятой. Например:
Код выведет , потому что JavaScript не вставляет здесь точку с запятой. Интуитивно очевидно, что, если строка заканчивается знаком , значит, это «незавершённое выражение», поэтому точка с запятой не требуется. И в этом случае всё работает, как задумано.
Но есть ситуации, где JavaScript «забывает» вставить точку с запятой там, где она нужна.
Ошибки, которые при этом появляются, достаточно сложно обнаруживать и исправлять.
Пример ошибки
Если вы хотите увидеть конкретный пример такой ошибки, обратите внимание на этот код:
Пока нет необходимости знать значение скобок и . Мы изучим их позже. Пока что просто запомните результат выполнения этого кода: выводится , а затем .
А теперь добавим перед кодом и не поставим в конце точку с запятой:
Теперь, если запустить код, выведется только первый , а затем мы получим ошибку!
Всё исправится, если мы поставим точку с запятой после :
Теперь мы получим сообщение «Теперь всё в порядке», следом за которым будут и .
В первом примере без точки с запятой возникает ошибка, потому что JavaScript не вставляет точку с запятой перед квадратными скобками . И поэтому код в первом примере выполняется, как одна инструкция. Вот как движок видит его:
Но это должны быть две отдельные инструкции, а не одна. Такое слияние в данном случае неправильное, оттого и ошибка. Это может произойти и в некоторых других ситуациях.
Мы рекомендуем ставить точку с запятой между инструкциями, даже если они отделены переносами строк. Это правило широко используется в сообществе разработчиков. Стоит отметить ещё раз – в большинстве случаев можно не ставить точку с запятой. Но безопаснее, особенно для новичка, ставить её.
JavaScript subString: Main Tips
- The JavaScript method extracts the symbols between two indexes and returns a data string.
- This method extracts the symbols in a string between end and start, not including end itself.
- If the end index has a smaller value than start, the arguments will be switched.
- If either end or start is defined as negative number, the value is .
- The original string is left unchanged after using this method.
 Pros
Pros
- Simplistic design (no unnecessary information)
- High-quality courses (even the free ones)
- Variety of features
Main Features
- Nanodegree programs
- Suitable for enterprises
- Paid certificates of completion
100% FREE  Pros
Pros
- Professional service
- Flexible timetables
- A variety of features to choose from
Main Features
- Professional certificates of completion
- University-level courses
- Multiple Online degree programs
100% FREE  Pros
Pros
- Great user experience
- Offers quality content
- Very transparent with their pricing
Main Features
- Free certificates of completion
- Focused on data science skills
- Flexible learning timetable
100% FREE
Строка как объект
По умолчанию в JavaScript строка принимает фиксированные значения, однако с помощью ключевого слова и метода строку можно превратить в объект и определить для неё какие либо свойства.
var stringObject = new string(«This string is object»); //Определение строки как объектный тип данных
stringObject.name = «newString»; //Определение свойства name со значением newString
|
1 |
varstringObject=newstring(«This string is object»);//Определение строки как объектный тип данных stringObject.name=»newString»;//Определение свойства name со значением newString |
Приведение строки к типу объект в большинстве случаев не представляет ценности, более того, такое преобразование способствует замедлению выполнения кода и может привести к непредвиденным последствиям.
The slice() Method
extracts a part of a string and returns the
extracted part in a new string.
The method takes 2 parameters: the start position, and the end position (end
not included).
This example slices out a portion of a string from position 7 to position 12 (13-1):
var str = «Apple, Banana, Kiwi»;
var res = str.slice(7, 13);
The result of res will be:
Remember: JavaScript counts positions from zero. First position is 0.
If a parameter is negative, the position is counted from the
end of the string.
This example slices out a portion of a string from position -12 to position
-6:
var str = «Apple, Banana, Kiwi»;
var res = str.slice(-12, -6);
The result of res will be:
If you omit the second parameter, the method will slice out the rest of the string:
var res = str.slice(7);
or, counting from the end:
Точка и перенос строки
Для поиска в многострочном режиме почти все модификации перловых регэкспов используют специальный multiline-флаг.
И javascript здесь не исключение.
Попробуем же сделать поиск и замену многострочного вхождения. Скажем, будем заменять на тэг подчёркивания: :
Попробуйте запустить. Заменяет? Как бы не так!
Дело в том, что в javascript мультилайн режим (флаг ) влияет только на символы ^ и $, которые начинают матчиться с началом и концом строки, а не всего текста.
Точка по-прежнему – любой символ, кроме новой строки. В javascript нет флага, который устанавливает мультилайн-режим для точки. Для того, чтобы заматчить совсем что угодно – используйте .
Работающий вариант:
str.replace(str|regexp, str|func)
Это универсальный метод поиска-и-замены, один из самых полезных. Этакий швейцарский армейский нож для поиска и замены в строке.
Мы можем использовать его и без регулярных выражений, для поиска-и-замены подстроки:
Хотя есть подводный камень.
Когда первый аргумент является строкой, он заменяет только первое совпадение.
Вы можете видеть это в приведённом выше примере: только первый заменяется на .
Чтобы найти все дефисы, нам нужно использовать не строку , а регулярное выражение с обязательным флагом :
Второй аргумент – строка замены. Мы можем использовать специальные символы в нем:
| Спецсимволы | Действие в строке замены |
|---|---|
| вставляет | |
| вставляет всё найденное совпадение | |
| вставляет часть строки до совпадения | |
| вставляет часть строки после совпадения | |
| если это 1-2 значное число, то вставляет содержимое n-й скобки | |
| вставляет содержимое скобки с указанным именем |
Например:
Для ситуаций, которые требуют «умных» замен, вторым аргументом может быть функция.
Она будет вызываться для каждого совпадения, и её результат будет вставлен в качестве замены.
Функция вызывается с аргументами :
- – найденное совпадение,
- – содержимое скобок (см. главу Скобочные группы).
- – позиция, на которой найдено совпадение,
- – исходная строка,
- – объект с содержимым именованных скобок (см. главу Скобочные группы).
Если скобок в регулярном выражении нет, то будет только 3 аргумента: .
Например, переведём выбранные совпадения в верхний регистр:
Заменим каждое совпадение на его позицию в строке:
В примере ниже две скобки, поэтому функция замены вызывается с 5-ю аргументами: первый – всё совпадение, затем два аргумента содержимое скобок, затем (в примере не используются) индекс совпадения и исходная строка:
Если в регулярном выражении много скобочных групп, то бывает удобно использовать остаточные аргументы для обращения к ним:
Или, если мы используем именованные группы, то объект с ними всегда идёт последним, так что можно получить его так:
Использование функции даёт нам максимальные возможности по замене, потому что функция получает всю информацию о совпадении, имеет доступ к внешним переменным и может делать всё что угодно.
String Methods
| Method | Description |
|---|---|
| charAt() | Returns the character at the specified index (position) |
| charCodeAt() | Returns the Unicode of the character at the specified index |
| concat() | Joins two or more strings, and returns a new joined strings |
| endsWith() | Checks whether a string ends with specified string/characters |
| fromCharCode() | Converts Unicode values to characters |
| includes() | Checks whether a string contains the specified string/characters |
| indexOf() | Returns the position of the first found occurrence of a specified value in a string |
| lastIndexOf() | Returns the position of the last found occurrence of a specified value in a string |
| localeCompare() | Compares two strings in the current locale |
| match() | Searches a string for a match against a regular expression, and returns the matches |
| repeat() | Returns a new string with a specified number of copies of an existing string |
| replace() | Searches a string for a specified value, or a regular expression, and returns a new string where the specified values are replaced |
| search() | Searches a string for a specified value, or regular expression, and returns the position of the match |
| slice() | Extracts a part of a string and returns a new string |
| split() | Splits a string into an array of substrings |
| startsWith() | Checks whether a string begins with specified characters |
| substr() | Extracts the characters from a string, beginning at a specified start position, and through the specified number of character |
| substring() | Extracts the characters from a string, between two specified indices |
| toLocaleLowerCase() | Converts a string to lowercase letters, according to the host’s locale |
| toLocaleUpperCase() | Converts a string to uppercase letters, according to the host’s locale |
| toLowerCase() | Converts a string to lowercase letters |
| toString() | Returns the value of a String object |
| toUpperCase() | Converts a string to uppercase letters |
| trim() | Removes whitespace from both ends of a string |
| valueOf() | Returns the primitive value of a String object |
All string methods return a new value. They do not change the original
variable.
JS Учебник
JS СтартJS ВведениеJS УстановкаJS ВыводJS ОбъявленияJS СинтаксисJS КомментарииJS ПеременныеJS ОператорыJS АрифметическиеJS ПрисваиваниеJS Типы данныхJS ФункцииJS ОбъектыJS СобытияJS СтрокиJS Методы строкиJS ЧислаJS Методы числаJS МассивыJS Методы массиваJS Сортировка массиваJS Итерация массиваJS ДатыJS Форматы датJS Методы получения датJS Методы установки датJS МатематическиеJS РандомныеJS БулевыJS СравненияJS УсловияJS SwitchJS Цикл ForJS Цикл WhileJS ПрерываниеJS Преобразование типовJS ПобитовыеJS Регулярные выраженияJS ОшибкиJS Область действияJS ПодъёмJS Строгий режимJS Ключевое слово thisJS Ключевое слово LetJS Ключевое слово ConstJS Функции стрелокJS КлассыJS ОтладкаJS Гид по стилюJS Лучшие практикиJS ОшибкиJS ПроизводительностьJS Зарезервированные словаJS ВерсииJS Версия ES5JS Версия ES6JS JSON
Сравнение строк в JavaScript
Строки в JS сравниваются посимвольно в алфавитном порядке.
Особенности посимвольного сравнения строк в JS:
- Символы сравниваются по их кодам (больший код — больший символ, все строчные буквы идут после (правее) заглавных, так как их коды больше (‘a’ > ‘Z’ // 97>65 true) ;
- Буквы, имеющие диакритические знаки, идут «не по порядку» ( ‘Österreich’ > ‘Zealand’ );
Для получения символа по его коду (и наоборот) используется методы:
- codePointAt(pos), который возвращает код Unicode для символа, находящегося на позиции pos;
- charCodeAt(pos), который возвращает числовое значение Unicode UTF-16 для символа по указанному индексу (за исключением кодовых точек Unicode, больших 0x10000).
- String.fromCodePoint(code) — создаёт символ по его коду code
JavaScript
// одна и та же буква в нижнем и верхнем регистре будет иметь разные коды
alert( «z».codePointAt(0) ); // 122
alert( «Z».codePointAt(0) ); // 90
// Создание символа по его коду code
alert( String.fromCodePoint(90) ); // Z
// Добавление юникодного символа по коду, используя спецсимвол \u
alert( ‘\u005a’ ); // Z
|
1 |
// одна и та же буква в нижнем и верхнем регистре будет иметь разные коды alert(«z».codePointAt());// 122 alert(«Z».codePointAt());// 90 alert(String.fromCodePoint(90));// Z alert(‘\u005a’);// Z |
Выведем строку, содержащую символы с кодами от 65 до 90 — это латиница (символы заглавных букв):
JavaScript
let str_1 = «»;
for (let i = 65; i <= 90; i++) {
str_1 += String.fromCodePoint(i);
}
console.log(str_1); // ABCDEFGHIJKLMNOPQRSTUVWXYZ
|
1 |
let str_1 = «»; for (let i = 65; i <= 90; i++) { str_1 += String.fromCodePoint(i); } console.log(str_1);// ABCDEFGHIJKLMNOPQRSTUVWXYZ |
Правильное сравнение строк (метод str1.localeCompare(str2))
Вызов метода str1.localeCompare(str2) возвращает число, которое показывает, какая строка больше в соответствии с правилами языка:
- Отрицательное число, если str1 меньше str2.
- Положительное число, если str1 больше str2.
- 0, если строки равны.
JavaScript
let str_1 = ‘Alex’.localeCompare(‘NAV’);
console.log(str_1); // -1
let str_2 = ‘Alex’.localeCompare(‘Alex’);
console.log(str_2); // 0
|
1 |
let str_1=’Alex’.localeCompare(‘NAV’); console.log(str_1);// -1 let str_2=’Alex’.localeCompare(‘Alex’); console.log(str_2);// 0 |
Обратные символьные классы
Для каждого символьного класса существует «обратный класс», обозначаемый той же буквой, но в верхнем регистре.
«Обратный» означает, что он соответствует всем другим символам, например:
- Не цифра: любой символ, кроме , например буква.
- Не пробел: любой символ, кроме , например буква.
- Любой символ, кроме , то есть не буквы из латиницы, не знак подчёркивания и не цифра. В частности, русские буквы принадлежат этому классу.
Мы уже видели, как сделать чисто цифровой номер из строки вида : найти все цифры и соединить их.
Альтернативный, более короткий путь – найти нецифровые символы и удалить их из строки:
substring() Explained
The JavaScript method retrieves a specific portion of a string. During this extraction process, the original element is not modified. Instead, the JavaScript will return a brand new string, containing the characters taken from the original string.
The usage of JS can vary since it’s possible to indicate different indexes to start and end extraction.
In this example, extraction begins from the fourth symbol:
Example Copy
Here we can see how the values are swapped when the end value turns out to be smaller than start value:
Example Copy
In this example, the start value is less than 0 (negative). Therefore, the command will start from index number 0:
Example Copy
Let’s see how only the first symbol can be extracted:
Example Copy
In this example, only the last symbol is extracted:
Example Copy
You might notice that the JavaScript function is similar to the method. Read about their differences and the function in this tutorial.
The JavaScript function can start the extraction of a string from the first character. Then, the start index should be set to .
In the following example, the start index is set as 1 (the second character), while the end index is set to 4 (the fifth character).
Open the code editor by clicking the Try it Live button. You will see that the returned string is . The fifth character is not included as the end index is never extracted by the JavaScript function:
Example Copy
Поиск подстроки в строке средствами sql
Для вычисления позиции подстроки в строке в языке sql существует несколько функций. Первая, которую мы рассмотрим, функция POSITION:
integer POSITION(substr string IN str string)
Возвращает номер позиции первого вхождения подстроки substr в строке str и возвращает 0 если подстрока не найдена. Функция POSITION может работать с многобайтовыми символами.
Пример:
SELECT POSITION (‘cd’ IN ‘abcdcde’);
Результат: 3
SELECT POSITION (‘xy’ IN ‘abcdcde’);
Результат: 0
Следующая функция LOCATE позволяет начинать поиск подстроки с определенной позиции:
integer LOCATE(substr string, str string, pos integer)
Возвращает позицию первого вхождения подстроки substr в строке str, начиная с позиции pos. Если параметр pos не задан, то поиск осуществляется с начала строки. Если подстрока substr не найдена, то возвращает 0. Поддерживает многобайтовые символы.
Пример:
SELECT LOCATE (‘cd’, ‘abcdcdde’, 5);
Результат: 5
SELECT LOCATE (‘cd’, ‘abcdcdde’);
Результат: 3
Аналогом функций POSITION и LOCATE является функция INSTR:
integer INSTR(str string, substr string)
Также как и функции выше возвращает позицию первого вхождения подстроки substr в строке str. Единственное отличие от функций POSITION и LOCATE то, что аргументы поменяны местами.
Далее рассмотрим функции, которые помогают получить подстроку.
Первыми рассмотрим сразу две функции LEFT и RIGHT, которые похожи по своему действию:
string LEFT(str string, len integer)string RIGHT(str string, len integer)
Функция LEFT возвращает len первых символов из строки str, а функция RIGHT столько же последних. Поддерживают многобайтовые символы.
Пример:
SELECT LEFT (‘Москва’, 3);
Результат: Мос
SELECT RIGHT (‘Москва’, 3);
Результат: ква
Далее рассмотрим одинаковые по итоговому результату функции SUBSTRING и MID:
string SUBSTRING(str string, pos integer, len integer)string MID(str string, pos integer, len integer)
Функции позволяют получить подстроку строки str длиною len символов с позиции pos. В случае если параметр len не задан, то возвращается вся подстрока начиная с позиции pos.
Пример:
SELECT SUBSTRING (‘г. Москва — столица России’, 4, 6);
Результат: Москва
SELECT SUBSTRING (‘г. Москва — столица России’, 4);
Результат: Москва — столица России
Примеры с функцией MID не привожу, потому что результаты будут аналогичные.
Интересная функция SUBSTRING_INDEX:
string SUBSTRING_INDEX(str string, delim string, count integer)
Функция возвращает подстроку строки str, полученную путем удаления символов, идущих после разделителя delim, находящимся в позиции count. Параметр count может быть как положительным, так отрицательным. Если count положительный, то отсчет позиции разделителя будет вестись слева и удаляться будут символы находящиеся справа от разделителя. Если count отрицательный, то отсчет позиции разделителя ведется справа и удаляются символы находящиеся слева от разделителя. Возможно, описание получилось слишком запутанным, но на примерах станет понятней.
Пример:
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, 1);
Результат: www
В данном примере функция находит, первое вхождения символа точки в строке «www.mysql.ru» и удаляет все символы, идущие после нее, включая сам разделитель.
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, 2);
Результат: www.mysql
Здесь функция ищет второе вхождение точки, удаляет все символы справа от нее и возвращает получившуюся подстроку. И еще один пример с отрицательным значением параметра count:
SELECT SUBSTRING_INDEX (‘www.mysql.ru’, ‘.’, -2);
Результат: mysql.ru
В этом примере функция SUBSTRING_INDEX ищет вторую точку, отсчитывая позицию справа, удаляет символы слева от нее и выдает полученную подстроку.
Метод slice ()
slice () извлекает часть строки и возвращает извлеченную часть в новой строке.
Метод принимает 2 параметра: начальный индекс (положение) и Конечный индекс (позиция).
Этот пример нарезает часть строки из позиции 7 в положение 13:
var str = «Apple, Banana, Kiwi»;
var res = str.slice(7, 13);
The result of res will be:
Banana
Если параметр имеет отрицательное значение, позиция учитывается от конца строки.
Этот пример нарезает часть строки из позиции-12 в положение-6:
var str = «Apple, Banana, Kiwi»;
var res = str.slice(-12, -6);
The result of res will be:
Banana
Если опустить второй параметр, метод выполнит срез оставшейся части строки:
var res = str.slice(7);
или, считая с конца:
Строковые функции
Строковые функции (методы) упрощают работу со строками в JavaScript. Давайте посмотрим, как происходит изменение регистра с помощью строковых функций. К примеру с помощью функций toLowerCase() и toUpperCase() мы можем изменить регистр символов следующим образом:
alert( 'Interface'.toUpperCase() ); // INTERFACE alert( 'Interface'.toLowerCase() ); // interface
Также при необходимости мы можем выполнить перевод в нижний регистр и для какого-нибудь определённого символа:
alert( 'Interface'toLowerCase() ); // 'i'
Подробнее о строковых функциях поговорим в следующий раз. В частности, рассмотрим, как осуществляется поиск в строке и как работать с подстрокой. Следите за новостями!

При подготовке статьи использовались следующие материалы:
— «Строки»;
— «JavaScript. Строковые методы».
Нюансы сравнения строк
Если мы
проверяем строки на равенство, то никаких особых проблем в JavaScript это не
вызывает, например:
if("abc" == "abc") console.log( "строки равны" );
if("abc" != "ABC") console.log( "строки не равны" );
Но, когда мы
используем знаки больше/меньше, то строки сравниваются в лексикографическом
порядке. То есть:
1. Если код
текущего символа одной строки больше кода текущего символа другой строки, то
первая строка больше второй (остальные символы не имеют значения), например:
console.log( "z" > "Za" ); //true
2. Если код
текущего символа одной строки меньше кода текущего символа другой строки, то
первая строка меньше второй:
console.log( "B" < "a" ); //true
3. При равенстве
символов больше та строка, которая содержит больше символов:
console.log( "abc" < "abcd" ); //true
4. В остальных
случаях строки равны:
console.log( "abc" == "abc" ); //true
Но в этом
алгоритме есть один нюанс. Например, вот такое сравнение:
console.log( "Америка" > "Japan" ); //true
Дает значение true, так как
русская буква A имеет больший
код, чем латинская буква J. В этом легко убедиться,
воспользовавшись методом
str.codePointAt(pos)
который
возвращает код символа, стоящего в позиции pos:
console.log( "А".codePointAt(), "J".codePointAt() );
Сморите, у буквы
А код равен 1040, а у буквы J – 74. Напомню,
что строки в JavaScript хранятся в
кодировке UTF-16. К чему
может привести такой результат сравнения? Например, при сортировке мы получим
на первом месте страну «Japan», а потом «Америка». Возможно, это не
то, что нам бы хотелось? И здесь на помощь приходит специальный метод для
корректного сравнения таких строк:
str.localeCompare(compareStr)
он возвращает
отрицательное число, если str < compareStr, положительное
при str > compareStr и 0 если строки
равны. Например:
console.log( "Америка".localeCompare("Japan") ); // -1
возвращает -1
как и должно быть с учетом языкового сравнения. У этого метода есть два
дополнительных аргумента, которые указаны в документации JavaScript. Первый
позволяет указать язык (по умолчанию берётся из окружения) — от него зависит
порядок букв. Второй позволяет определять дополнительные правила, например, чувствительность
к регистру.
Backreferences в паттерне и при замене
Иногда нужно в самом паттерне поиска обратиться к предыдущей его части.
Например, при поиске BB-тагов, то есть строк вида , и . Или при поиске атрибутов, которые могут быть в одинарных кавычках или двойных.
Обращение к предыдущей части паттерна в javascript осуществляется как \1, \2 и т.п., бэкслеш + номер скобочной группы:
Обращение к скобочной группе в строке замены идёт уже через доллар: . Не знаю, почему, наверное так удобнее…
P.S. Понятно, что при таком способе поиска bb-тагов придётся пропустить текст через замену несколько раз – пока результат не перестанет отличаться от оригинала.
Методы строк
| Метод | Описание | Chrome | Firefox | Opera | Safari | IExplorer | Edge |
|---|---|---|---|---|---|---|---|
| charAt() | Возвращает символ по заданному индексу внутри строки. | Да | Да | Да | Да | Да | Да |
| charCodeAt() | Возвращает числовое значение символа по указанному индексу в стандарте кодирования символов Unicode (Юникод). | Да | Да | Да | Да | Да | Да |
| codePointAt() | Возвращает неотрицательное целое число, являющееся значением кодовой точки в стандарте кодирования символов Unicode (Юникод). | 41.0 | 29.0 | 28.0 | 10.0 | Нет | Да |
| concat() | Используется для объединения двух, или более строк в одну, при этом метод не изменяет существующие строки, а возвращает новую строку. | Да | Да | Да | Да | Да | Да |
| endsWith() | Определяет, совпадает ли конец данной строки с указанной строкой, или символом, возвращая при этом логическое значение. | 41.0 | 17.0 | 28.0 | 9.0 | Нет | Да |
| fromCharCode() | Преобразует значение или значения кодовых точек в стандарте кодирования символов UTF-16 (Юникод) в символы и возвращает строковое значение. | Да | Да | Да | Да | Да | Да |
| fromCodePoint() | Преобразует значение или значения кодовых точек в стандарте кодирования символов Юникод в символы и возвращает строковое значение. Позволяет работать со значениями выше 65535. | 41.0 | 29.0 | 28.0 | 10.0 | Нет | Да |
| includes() | Определяет, содержится ли одна строка внутри другой строки, возвращая при этом логическое значение. | 41.0 | 40.0* | 28.0 | 9.0 | Нет | Да |
| indexOf() | Возвращает позицию первого найденного вхождения указанного значения в строке. | Да | Да | Да | Да | Да | Да |
| lastIndexOf() | Возвращает позицию последнего найденного вхождения указанного значения в строке. | Да | Да | Да | Да | Да | Да |
| localeCompare() | Сравнивает две строки и определяет являются ли они эквивалентными в текущем языковом стандарте. | Да | Да | Да | Да | Да* | Да |
| match() | Производит поиск по заданной строке с использованием регулярного выражения (глобальный объект RegExp) и возвращает массив, содержащий результаты этого поиска. | Да | Да | Да | Да | Да | Да |
| normalize() | Возвращает форму нормализации в стандарте кодирования символов Unicode (Юникод) для указанной строки. | 34.0 | 31.0 | Да | 10.0 | Нет | Да |
| padEnd() | Позволяет дополнить текущую строку, начиная с её конца (справа) с помощью пробельного символа (по умолчанию), или заданной строкой, таким образом чтобы результирующая строка достигла заданной длины. | 57.0 | 48.0 | 44.0 | 10.0 | Нет | 15.0 |
| padStart() | Позволяет дополнить текущую строку, начиная с её начала (слева) с помощью пробельного символа (по умолчанию), или заданной строкой, таким образом чтобы результирующая строка достигла заданной длины. | 57.0 | 48.0 | 44.0 | 10.0 | Нет | 15.0 |
| raw() | Возвращает необработанную строковую форму строки шаблона. | 41.0 | 34.0 | 28.0 | 10.0 | Нет | Да |
| repeat() | Возвращает новый строковый объект, который содержит указанное количество соединённых вместе копий строки на которой был вызван метод. | 41.0 | 24.0 | 28.0 | 9.0 | Нет | Да |
| replace() | Выполняет внутри строки поиск с использованием регулярного выражения (объект RegExp), или строкового значения и возвращает новую строку, в которой будут заменены найденные значения. | Да | Да | Да | Да | Да | Да |
| search() | Выполняет поиск первого соответствия (сопоставления) регулярному выражению (объект RegExp) внутри строки. | Да | Да | Да | Да | Да | Да |
| slice() | Позволяет возвратить новую строку, которая содержит копии символов, вырезанных из исходной строки. | Да | Да | Да | Да | Да | Да |
| split() | Позволяет разбить строки на массив подстрок, используя заданную строку разделитель для определения места разбиения. | Да | Да | Да | Да | Да | Да |
| startsWith() | Определяет, совпадает ли начало данной строки с указанной строкой, или символом, возвращая при этом логическое значение. | 41.0 | 17.0 | 28.0 | 9.0 | Нет | Да |
| substr() | Позволяет извлечь из строки определенное количество символов, начиная с заданного индекса. | Да | Да | Да | Да | Да | Да |
| substring() | Позволяет извлечь символы из строки (подстроку) между двумя заданными индексами, или от определенного индекса до конца строки. | Да | Да | Да | Да | Да | Да |
| toLocaleLowerCase() | Преобразует строку в строчные буквы (нижний регистр) с учетом текущего языкового стандарта. | Да | Да | Да | Да | Да | Да |
| toLocaleUpperCase() | Преобразует строку в заглавные буквы (верхний регистр) с учетом текущего языкового стандарта. | Да | Да | Да | Да | Да | Да |
| toLowerCase() | Преобразует строку в строчные буквы (нижний регистр). | Да | Да | Да | Да | Да | Да |
| toString() | Возвращает значение строкового объекта. | Да | Да | Да | Да | Да | Да |
| toUpperCase() | Преобразует строку в заглавные буквы (верхний регистр). | Да | Да | Да | Да | Да | Да |
| trim() | Позволяет удалить пробелы с обоих концов строки. | Да | Да | Да | Да | 9.0 | Да |
| valueOf() | Возвращает примитивное значение строкового объекта в виде строкового типа данных. | Да | Да | Да | Да | Да | Да |
Спецсимволы
Если мы применяем одинарные либо двойные кавычки, мы тоже можем создавать многострочные строки. Для этого понадобится символ перевода строки \n:
let guestList = "Guests:\n * Bob\n * Petr\n * Maria"; alert(guestList); // список гостей из нескольких строк
Две строки ниже являются эквивалентными. Разница в том, что они по-разному записаны:
// используем спецсимвол перевода строки let str1 = "Hello\nWorld"; // используем обратные кавычки let str2 = `Hello World`; alert(str1 == str2); // true
Существует и масса других спецсимволов:
Рассмотрим парочку примеров с Юникодом:
//
alert( "\u00A9" );
// Длинные коды
// 佫, редкий китайский иероглиф
alert( "\u{20331}" );
// , улыбающийся смайлик с глазами-сердечками
alert( "\u{1F60D}" );
Как правило, спецсимволы начинаются с символа экранирования, представляющего собой обратный слеш \. Его можно использовать и для того, чтобы вставлять в строки кавычки:
alert( 'I\'m the God!' ); // I'm the God!
Но экранировать нужно только тогда, когда внутри строки мы используем такие же кавычки, в которые эта самая строка заключена. Таким образом, можно поступать проще:
alert( `I'm the Walrus!` ); // I'm the Walrus!
Как видите, мы поместили строку в косые кавычки, а раздели I’m одинарной кавычкой. Просто и элегантно.
Кстати, если вдруг потребуется добавить в нашу строку сам обратный слеш, то мы экранируем его вторым обратным слешем:
alert( `The backslash: \\` ); // The backslash: \