Нормализация баз данных простыми словами
Содержание:
- Образец технического задания на организацию склада адресного хранения
- Пример приведения таблиц базы данных к четвертой нормальной форме
- Нормализация НСИ Контрагенты
- Классический пример приведения таблиц базы данных к четвертой нормальной форме
- Третья нормальная форма
- Первая нормальная форма
- MinMaxScaler: приведение к диапазону [0,1]
- Чек лист последовательности проектирования базы данных
- Пример приведения таблицы ко второй нормальной форме (первичный ключ составной)
- Что такое нормализация данных и чем она отличается от нормировки и нормирования
- Normalizer: применение нормализации к строкам
Образец технического задания на организацию склада адресного хранения
При составлении данного образа технического задания не преследовалась цель создать его по ГОСТу и в соответствии с авторитетными нормативными требованиями.
Этот образец технического задания составлен, по большей части, для руководства компании — людей, которым надо управлять компанией и не нужно глубоко погружаться в тонкости процессов разработки.
Преследовалась цель: ознакомить и согласовать с руководством основные принципы реализации проекта. И чтобы предложить руководителю компании доступным и понятным для него языком путь реализации проекта.
На мой взгляд,
данный образец может быть полезен тем, кто составляет описания и задания на разработку и внедрение, работая на стороне Заказчика.
Входящие требования для разработки технического задания:
— Учет номенклатуры на адресном складе в разрезе занимаемого в ячейке (объема) не ведется.
— Предполагается работа с оборудованием (терминалами сбора данных) под только в режиме «Off-Line» или без оборудования в неавтоматизированном режиме.
— Склад адресного хранения должен быть универсальным и доступным для применения в учете в других регионах.
1 стартмани
Пример приведения таблиц базы данных к четвертой нормальной форме
Представим, что мы работаем в каком-то учебном заведении, где есть курсы, которые изучают студенты, преподаватели, которые читают эти курсы, и аудитории, в которых преподаватели проводят занятия по курсам.
Курсы.
| Идентификатор курса | Название курса |
| 1 | SQL |
| 2 | Python |
| 3 | JavaScript |
Преподаватели.
| Идентификатор преподавателя | ФИО |
| 1 | Иванов И.И. |
| 2 | Сергеев С.С. |
| 3 | John Smith |
Аудитории.
| Идентификатор аудитории | Название аудитории |
| 1 | 101 |
| 2 | 203 |
| 3 | 305 |
| 4 | 407 |
| 5 | 502 |
При этом мы понимаем, что один и тот же курс могут преподавать разные преподаватели, и необязательно в какой-то одной аудитории, один раз курс может читаться в одной аудитории, а в другой раз совсем в другой аудитории, например, на курс записалось гораздо меньше студентов и чтобы не занимать аудиторию большого размера, под этот поток могут выделить аудиторию меньшего размера.
Также стоит отметить, что под каждый курс подходит только определенный набор аудиторий, например, те, которые оснащены необходимым оборудованием, или те, которые имеют соответствующую вместимость для конкретно этого курса.
В учебном заведении, конечно же, постоянно возникают вопросы с составлением расписания, однако для того чтобы его составлять, необходимо предварительно знать возможности этого учебного заведения. Иными словами, какие преподаватели могут преподавать тот или иной курс, а также в каких аудиториях тот или иной курс может читаться.
Для этого нам необходимо соединить эти три сущности в одной таблице. В итоге у нас получается следующая таблица (для наглядности здесь представлены текстовые значения, а не идентификаторы).
Таблица связей курсов, преподавателей и аудиторий.
| Курс | Преподаватель | Аудитория |
| SQL | Иванов И.И. | 101 |
| SQL | Иванов И.И. | 203 |
| SQL | Сергеев С.С. | 305 |
| SQL | Сергеев С.С. | 407 |
| Python | John Smith | 502 |
| Python | John Smith | 305 |
В данном случае первичный ключ здесь состоит из всех трех столбцов, поэтому эта таблица автоматически находится в третьей нормальной форме и нормальной форме Бойса-Кодда. Однако она не находится в четвертой нормальной форме, так как здесь есть многозначная зависимость
Курс ->-> Преподаватель
Курс ->-> Аудитория
Т.е. для каждого курса в этой таблице может быть несколько преподавателей, а также несколько аудиторий.
При этом, Вы понимаете, что преподавателю без разницы, в какой аудитории читать лекцию, ровно так же как и самой аудитории без разницы, какой преподаватель в ней будет работать))
Иными словами, эти два атрибута «Преподаватель» и «Аудитория» никак не зависят друг от друга, но они оба по отдельности зависят от курса.
Но что же плохого в этой таблице и в этой многозначной зависимости? Вы можете спросить.
Чтобы ответить на этот вопрос, мы можем задать себе несколько других вопросов.
Что будет если, например, преподаватель «Иванов И.И.» уволился? Нам нужно будет удалить две строки из этой таблицы, но удалив эти строки, мы удалим всю информацию и о аудиториях 101 и 203. Но они на самом-то деле есть и должны участвовать в планировании расписания. Это аномалия, и это плохо.
Или другая ситуация, что будет, если курсу назначен преподаватель, но аудитория еще не определена? Или наоборот, с аудиторией уже определились, а вот преподаватель еще не известен.
Мы должны создать записи либо с NULL либо со значениями по умолчанию, и это также является аномалией.
Многозначные зависимости плохи как раз тем, что их нельзя независимо друг от друга редактировать. Иными словами, чтобы внести изменения в одну зависимость, мы неизбежно должны затронуть другую зависимость.
Поэтому главное правило четвертой нормальной формы звучит следующим образом:
Решение в данном случае как всегда – декомпозиция.
Мы должны вынести каждую многозначную зависимость в отдельную таблицу, т.е. разнести независимые друг от друга атрибуты, в нашем случае «Преподаватель» и «Аудитория», по разным таблицам.
Связь курсов и преподавателей.
| Курс | Преподаватель |
| SQL | Иванов И.И. |
| SQL | Сергеев С.С. |
| Python | John Smith |
Связь курсов и аудиторий.
| Курс | Аудитория |
| SQL | 101 |
| SQL | 203 |
| SQL | 305 |
| SQL | 407 |
| Python | 502 |
| Python | 305 |
Нормализация НСИ Контрагенты
В результате проведения работ по нормализации данных Контрагенты (Клиенты, Сотрудники, Поставщики, Пациенты, Кредиторы, Дебиторы и пр.) наши клиенты получают данные, соответствующие следующим критериям:
1. Все карточки Контрагентов заполнены полно и без ошибок в реквизитах
При выполнении работ по нормализации данных наши специалисты проверяют все карточки контрагентов, вносят исправления при необходимости и заполняют недостающие данные. При этом они используют как экспертные знания и специализированные методики, так и различные автоматизированные сервисы по проверке и нормализации данных.
В результате этого блока работ клиент получает выверенные, полностью заполненные данные контрагентов, которые можно использовать во всех сферах деятельности компании. Например, при оформлении договоров и построении отчетов, использующих информацию о контрагентах.

Рис. 5. Карточка контрагента до и после проведения нормализации.
2. Проведена дедубликация в карточках контрагентов
При выполнении нормализации всей НСИ Контрагенты путем применения специализированных алгоритмов находятся все дубли. Это избавляет домен данных от проблем с ведением всей деятельности по контрагентам в несколько параллельных веток с невозможностью получить точный срез взаимодействия с контрагентами, по которым присутствуют дубли в записях.
В результатах проекта клиенту предоставляются все позиции НСИ, которые являются дублями.
Эффекты от нормализации домена данных Контрагенты
Наши клиенты отмечают следующие позитивные эффекты:
- возможность ведения централизованной истории взаимодействия по каждому контрагенту без потерь информации;
- безошибочное построение любых отчетов, использующих информацию о контрагентах;
- избежание негативных ситуаций и попадания в «черные списки», например, при работе (e-mail рассылка, обзвон) с существующей клиентской базой, в которой один и тот же клиент, ввиду ошибок, присутствует n-ое количество раз.
Классический пример приведения таблиц базы данных к четвертой нормальной форме
Чтобы стало еще понятней, давайте закрепим знания и рассмотрим классический пример, который обычно используется в литературе для пояснения четвертой нормальной формы.
Таблица связей студентов, курсов и хобби.
| Студент | Курс | Хобби |
| Иванов И.И. | SQL | Футбол |
| Иванов И.И. | Java | Хоккей |
| Сергеев С.С. | SQL | Волейбол |
| Сергеев С.С. | SQL | Теннис |
| John Smith | Python | Футбол |
| John Smith | Java | Теннис |
Данная таблица хранит информацию о студентах, в частности здесь хранятся курсы, которые посещает студент, и увлечения этого студента, т.е. хобби.
Отсюда следует, что каждый студент может посещать несколько курсов и иметь несколько увлечений.
Первичный ключ здесь также составной и состоит он из всех трех столбцов.
При этом мы можем заметить, что курс и хобби никак не связаны и не зависят друг от друга, но по отдельности зависят от студента.
Таким образом, мы можем наблюдать в этой таблице нетривиальную многозначную зависимость
Студент ->-> Курс
Студент ->-> Хобби
Поэтому эта таблица не находится в четвертой нормальной форме.
Кроме всех тех аномалий, связанных с редактированием данных, которые мы уже рассмотрели на предыдущем примере, в данном случае еще продемонстрирована проблема неоднозначной выборки данных.
Допустим, нам необходимо получить информацию о хобби студентов, которые посещают курс по SQL. Очевидным действием станет выборка с условием Курс = SQL, в результате мы получим 3 хобби: футбол, волейбол и теннис.
Результат выборки. Хобби студентов, которые посещают курс по SQL.
| Студент | Курс | Хобби |
| Иванов И.И. | SQL | Футбол |
| Сергеев С.С. | SQL | Волейбол |
| Сергеев С.С. | SQL | Теннис |
Однако, если мы заглянем в исходную таблицу, то мы четко увидим, что «Иванов И.И.» посещает курс по SQL и имеет хобби «Хоккей», но в нашей выборке этого хобби нет.
Чтобы нормализовать эту таблицу, мы должны точно так же, как и в предыдущем примере, разбить ее на две.
Связь студентов и курсов.
| Студент | Курс |
| Иванов И.И. | SQL |
| Иванов И.И. | Java |
| Сергеев С.С. | SQL |
| John Smith | Python |
| John Smith | Java |
Связь студентов и хобби.
| Студент | Хобби |
| Иванов И.И. | Футбол |
| Иванов И.И. | Хоккей |
| Сергеев С.С. | Волейбол |
| Сергеев С.С. | Теннис |
| John Smith | Футбол |
| John Smith | Теннис |
Однако в реальности такую ситуацию и такую таблицу вряд ли можно встретить, так как следуя здравому смыслу такие абсолютно не связанные друг с другом данные никто не будет хранить в одной таблице. Поэтому этот пример чисто теоретический и приводится для демонстрации принципов четвертой нормальной формы.
И если говорить о реальных данных, то нормализация до четвертой нормальной формы, как и до всех последующих, в современном мире практически не встречается. Если четвертую нормальную форму еще как-то можно представить и даже встретить данные, нормализованные до этой формы, то встретить данные, нормализованные до 5 или 6 нормальной формы, практически невозможно.
Вы можете спросить, а почему не нормализуют данные до 5 или 6 нормальной формы? Ведь каждая нормальная форма устраняет определенные аномалии, и если сделать полностью нормализованную базу данных, то по сути она будет идеальная, не содержащая ни одной аномалии, это же хорошо.
Да, совершенно верно, база данных не будет содержать аномалий, но давайте вспомним, какие преимущества нам дает нормализация.
Обычно во всех источниках приводится два основных глобальных преимущества:
- Устранение аномалий
- Повышение производительности
Если с устранением аномалий все ясно, т.е. в полностью нормализованной базе данных их не будет и это хорошо, то с повышением производительности не все так однозначно.
Да, нормализация повышает производительность, но только где-то до 3 нормальной формы. Начиная с 4 нормальной формы, производительность увеличиваться не будет, более того, с каждой новой формой производительность будет значительно снижаться, не говоря уже о том, что с нормализованной базой данных до 5 или 6 нормальной формы будет крайне сложно и неудобно работать и сопровождать ее, ведь с каждой новой формой мы значительно увеличиваем количество таблиц в базе данных.
Поэтому процесс нормализации не является строго обязательным, т.е. не нужно нормализовать базу данных, только для того чтобы она была нормализована.
В процессе проектирования базы данных необходимо следовать здравому смыслу и найти баланс между отсутствием аномалий и приемлемой производительностью.
Полностью нормализованная база данных – это плохая база данных.
После того как мы привели таблицы базы данных к четвертой нормальной форме, мы можем переходить к приведению таблиц до пятой нормальной формы (5NF). Описание, требования и пример приведения таблиц до пятой нормальной формы мы рассмотрим в следующем материале.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Нравится7Не нравится
Третья нормальная форма
Значения в записи, не являющиеся частью ключа записи, не принадлежат таблице. В общем случае, когда содержимое группы полей может быть применено к более чем одной записи в таблице, рекомендуется размещать эти поля в отдельной таблице.
Например, в таблице сотрудников сотрудников можно включить название и адрес университета. Но вам нужен полный список университетов для групповых сообщений. Если сведения об университетах хранятся в таблице кандидатов, не существует способа перечисление университетов без текущих кандидатов. Создайте отдельную таблицу университетов и свяжите ее с таблицей кандидатов с помощью ключа кода университета.
ИСКЛЮЧЕНИЕ: следование третьей нормальной форме, хотя теоретически желательно, не всегда практично. Если у вас есть таблица Customers и вы хотите устранить все возможные зависимости между полями, необходимо создать отдельные таблицы для городов, почтовых индексов, торговых представителей, классов клиентов и других факторов, которые могут дублироваться в нескольких записях. Теоретически, нормализация стоит пурсинг. Тем не менее, многие небольшие таблицы могут понизить производительность или превышать количество файлов и емкости памяти.
Более часто можно применить третью обычную форму только к данным, которые часто изменяются. Если остались зависимые поля, разработайте приложение, чтобы требовать от пользователя проверки всех связанных полей при изменении любого из них.
Первая нормальная форма
- Исключите повторяющиеся группы в отдельных таблицах.
- Создайте отдельную таблицу для каждого набора связанных данных.
- Идентифицируйте каждый набор связанных данных с помощью первичного ключа.
Не используйте несколько полей в одной таблице для хранения похожих данных. Например, для отслеживания складской позиции, которая может поступать из двух возможных источников, в записи инвентаризации могут содержаться поля для кода поставщика 1 и поставщика с кодом 2.
Что происходит при добавлении третьего поставщика? Добавление поля не является ответом; для этого требуется изменение программ и таблиц, а также нестабильное динамическое количество поставщиков. Вместо этого разместите все сведения о поставщиках в отдельной таблице «поставщики», а затем свяжите запасы с поставщиками с ключом номера номенклатуры или поставщиками для запасов с ключом кода поставщика.
MinMaxScaler: приведение к диапазону [0,1]
MinMaxScaler в PySpark применяется для шкалирования в диапазоне . Рассчитывается как
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0)) X_scaled = X_std * (max - min) + min # при min=0, max=1 => X_std = X_scaled
где min и max задаются как минимальное и максимальное допустимое значение, по умолчанию min=0, max=1. Вот так выглядит Python-код для такого вида нормализации:
from pyspark.ml.feature import MinMaxScaler
scaler = MinMaxScaler(inputCol="features", outputCol="scaledFeatures")
scalerModel = scaler.fit(dataFrame)
scaledData = scalerModel.transform(dataFrame)
print("Features scaled to range: " % (scaler.getMin(), scaler.getMax()))
scaledData.select("features", "scaledFeatures").show(truncate=False)
Результат нормализации данных в PySpark:
Features scaled to range: +--------------+-----------------------------------------------------------+ |features |scaledFeatures | +--------------+-----------------------------------------------------------+ || | | || || | +--------------+-----------------------------------------------------------+
Чек лист последовательности проектирования базы данных
Для тех, кто ещё только делает первые шаги в проектировании баз данных будет полезна типовая последовательность выполнения работ:
- Определить таблицы объектов
- Определить атомарные поля
- Определить типы полей
- Определить первичные ключи
- Определить внешние ключи
- Определить индексы полей
- Определить уникальность полей
- Определить признаки полей null/not null
- Определить дополнительные ограничений полей
- Выполнить нормализацию до 3-й нормальной формы
- Выполнить денормализацию с учетом ограничений по производительности
Методология IDEF1Х и программный продукт ERWin
|
На основании своего опыта могу сказать, что в моем конкретном случае использование AllFusion Data Model Validator (ERwin Examiner) приведет к сокращению трудозатрат приблизительно на 1000 человеко-часов при перепроектировании и настройке баз данных моей фирмы. Билл Кларк, администратор БД компании FunMail |
В свое время компания Computer Associates в рамках серии продуктов ERwin реализовала стандарт IDEF1X.
IDEF1X является методом для разработки реляционных баз данных и использует условный синтаксис, специально разработанный для построения концептуальной схемы структуры данных предприятия, независимой от конечной реализации базы данных и аппаратной платформы.
Сущность предметной области в IDEF1X описывает собой совокупность или набор экземпляров похожих по свойствам, но однозначно отличаемых друг от друга по одному или нескольким признакам. Каждый экземпляр является реализацией сущности. Таким образом, сущность в IDEF1X описывает конкретный набор экземпляров реального мира, в отличие от сущности в IDEF1, которая представляет собой абстрактный набор информационных отображений реального мира.
Поддержка нормализации в ERWin. ERWin не содержит полного алгоритма нормализации и не может проводить нормализацию автоматически, однако его возможности облегчают создание нормализованной модели данных. В первую очередь ERwin Examiner позволяет провести инспекцию структуры базы данных на предмет соответствия её общепринятым нормам проектирования в автоматическом режиме.
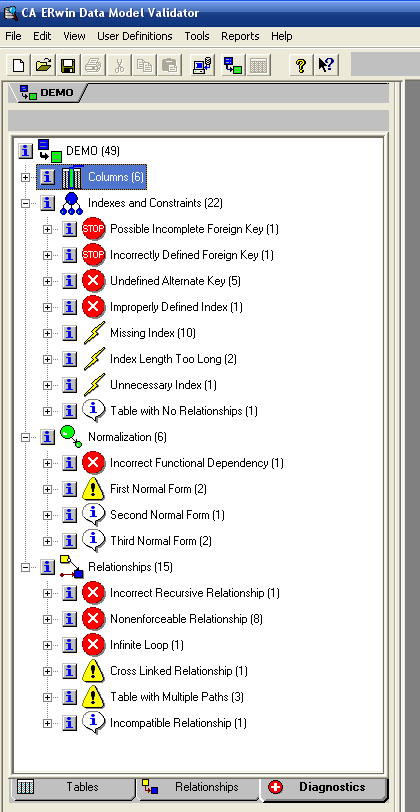
Обработка «СтруктураКонфигурацииIDEF1c.epf»
ERwin examiner позволяет провести анализ модели данных на основе экспертных данных заложенных в программу разработчиками. Не смотря на то, что средства ERwin не могут сказать как нужно делать, они могут сказать как делать не нужно. Использование средств валидации схем баз данных позволяет на собственном опыте решения практических задач впитать лучший опыт разработки.
Методология IDEF1X включает в себя графическое представление отношений между сущностями. Являясь проекцией стандарта IDEF1 на физический уровень баз данных, который позволяет вести как прямую разработку структуры базы данных в терминах конкретной СУБД так и обратный реинжениринг, методология IDEF1X позволяет переносить модели из одной СУБД в другую.
Для целей документирования структуры данных платформы 1С мной была разработана нотация IDEF1c. Простая и очевидная текстовая структура вот уже 5 лет помогает закрывать бреши в технологическом обеспечении платформы 1С. Данный инструмент не претендует на полноту — это скорее попытка начать диалог на эту тему заинтересованных разработчиков.
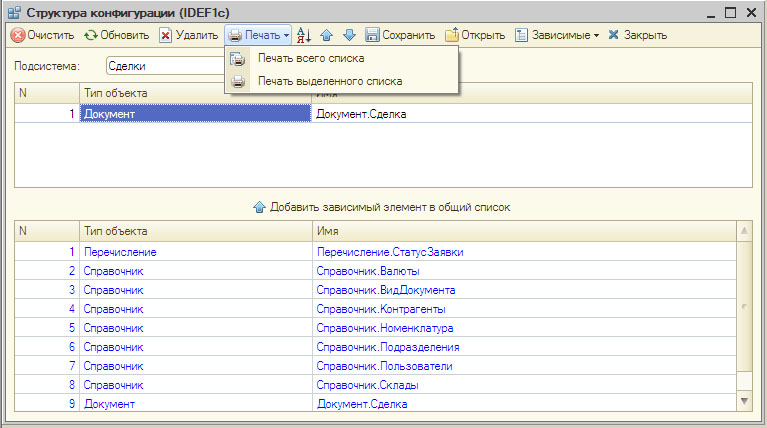
Операции:
- Подсистема — Выбор «подсистемы» для анализа объектов конфигурации. При смене подсистемы, объекты дописываются в конец списка.
- Очистить — Очистить список объектов для последующего добавления объектов конфигурации.
- Обновить — Добавить в конец списка объекты указанной подсистемы.
- Добавить зависимый элемент в общий список — Переместить из нижнего списка зависимых объектов в список объектов конфигурации для дальнейшей печати.
- Удалить — Удалить текущий объект из списка.
- Печать всего списка — Печать всего списка объектов конфигурации.
- Печать выделенного списка — Печать только выбранных элементов из списка объектов
- Сохранить — Сохранить список объектов конфигурации в xml-файле, для последующего использования
- Открыть — Загрузить спискок объектов конфигурации из xml-файла.
Обработка позволяет не только печать список объектов в формате IDEF1c, но и обмениваться списком в формате xml-файла для облегчения коммуникаций между разработчиками.
Пример, представления объектов конфигурации в формате IDEF1c:
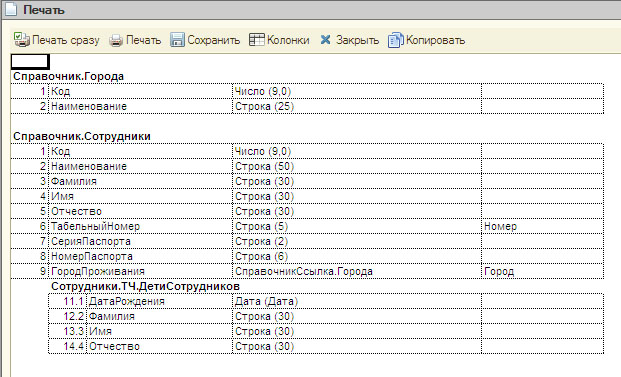
Данная обработка работает в обычной и управляемых формах, версия платформы 8.2.13.219 и выше. Может использоваться как внешняя обработка, что делает её удобным инструментом для исследовальских работ чужих конфигураций.
Пример приведения таблицы ко второй нормальной форме (первичный ключ составной)
А теперь давайте рассмотрим другую ситуацию, в которой первичный ключ у нас будет составным.
Представим, что наша организация выполняет несколько проектов, в которых может быть задействовано несколько участников, и нам необходимо хранить информацию об этих проектах. В частности мы хотим знать, кто участвует в каждом из проектов, продолжительность этого проекта, ну и возможно какие-то другие сведения. При этом мы понимаем, что отдельно взятый сотрудник может участвовать в нескольких проектах.
Для хранения таких данных мы создали следующую таблицу.
Таблица проектов организации в первой нормальной форме.
| Название проекта | Участник | Должность | Срок проекта (мес.) |
| Внедрение приложения | Иванов И.И. | Программист | 8 |
| Внедрение приложения | Сергеев С.С. | Бухгалтер | 8 |
| Внедрение приложения | John Smith | Менеджер | 8 |
| Открытие нового магазина | Сергеев С.С. | Бухгалтер | 12 |
| Открытие нового магазина | John Smith | Менеджер | 12 |
Как видим, она в первой нормальной форме, значит, мы можем пытаться приводить ее ко второй нормальной форме.
Как Вы помните, чтобы привести таблицу ко второй нормальной форме, необходимо определить для нее первичный ключ.
Посмотрев на эту таблицу, мы понимаем, что четко идентифицировать каждую строку мы можем только с помощью комбинации столбцов, например, «Название проекта» + «Участник», иными словами, зная «Название проекта» и «Участника», мы можем четко определить конкретную запись в таблице, т.е. каждое сочетание значений этих столбцов является уникальным.
Таким образом, мы определили первичный ключ и он у нас составной, т.е. состоящий их двух столбцов.
Таблица проектов организации. Внедрен составной первичный ключ.
| Название проекта | Участник | Должность | Срок проекта (мес.) |
| Внедрение приложения | Иванов И.И. | Программист | 8 |
| Внедрение приложения | Сергеев С.С. | Бухгалтер | 8 |
| Внедрение приложения | John Smith | Менеджер | 8 |
| Открытие нового магазина | Сергеев С.С. | Бухгалтер | 12 |
| Открытие нового магазина | John Smith | Менеджер | 12 |
Так как первичный ключ составной, нам необходимо проверить еще и второе требование, которое гласит, что «Все неключевые столбцы таблицы должны зависеть от полного ключа».
Другими словами, остальные столбцы, которые не входят в первичный ключ, должны зависеть от всего первичного ключа, т.е. от всех столбцов, а не от какого-то одного.
Чтобы это проверить, мы можем задать себе несколько вопросов.
Можем ли мы определить «Должность», зная только название проекта? Нет. Для этого нам необходимо знать и участника. Значит, пока все хорошо, по этой части ключа мы не можем четко определить значение неключевого столбца. Идем дальше и проверяем другую часть ключа.
Можем ли мы определить «Должность» зная только участника? Да, можем. Значит наш первичный ключ плохой, и требование второй нормальной формы не выполняется.
Что делать в этом случае?
В этом случае мы будем выполнять действие, которое выполняется, наверное, в 99% случаев на протяжении всего процесса нормализации базы данных – это декомпозиция.
Чтобы декомпозировать нашу таблицу и привести базу данных к нормализованной форме, мы должны создать следующие таблицы.
Проекты.
| Идентификатор проекта | Название проекта | Срок проекта (мес.) |
| 1 | Внедрение приложения | 8 |
| 2 | Открытие нового магазина | 12 |
Участники.
| Идентификатор участника | Участник | Должность |
| 1 | Иванов И.И. | Программист |
| 2 | Сергеев С.С. | Бухгалтер |
| 3 | John Smith | Менеджер |
Связь проектов и участников этих проектов.
| Идентификатор проекта | Идентификатор участника |
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 2 | 2 |
| 2 | 3 |
Мы создали 3 таблицы:
- Проекты, в нее мы добавили искусственный первичный ключ
- Участники, в нее мы также добавили искусственный первичный ключ
- Связь между проектами и участниками, она нужна для реализации связи «Многие ко многим», так как между этими таблицами связь именно такая
После того как мы привели таблицы базы данных ко второй нормальной форме, мы можем переходить к приведению таблиц до третьей нормальной формы (3NF). Описание, требования и пример приведения таблиц до третьей нормальной формы мы рассмотрим в следующем материале.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Нравится13Не нравится
Что такое нормализация данных и чем она отличается от нормировки и нормирования
В случае машинного обучения (Machine Learning), нормализация – это процедура предобработки входной информации (обучающих, тестовых и валидационных выборок, а также реальных данных), при которой значения признаков во входном векторе приводятся к некоторому заданному диапазону, например, или .
Следует отличать понятия нормализации, нормировки и нормирования.
Нормировка – это корректировка значений в соответствии с некоторыми функциями преобразования, с целью сделать их более удобными для сравнения. Например, разделив набор измерений о росте людей в дюймах на 2.54, мы получим значение роста в метрической системе.
Нормировка данных требуется, когда несовместимость единиц измерений переменных может отразиться на результатах и рекомендуется, когда итоговые отчеты могут быть улучшены, если выразить результаты в определенных понятных/совместимых единицах. Например, время реакции, записанное в миллисекундах, легче интерпретировать, чем число тактов процессора, в которых были получены данные эксперимента .
Нормирование – это процесс установления предельно допустимых или оптимальных нормативных значений в прикладных сферах деятельности, например, нормирование труда. Как правило, нормы разрабатываются по результатам исследовательских, проектных или научных работ, а также на основе экспертных оценок .
 Нормализация, нормировка и нормирование — это разные понятия
Нормализация, нормировка и нормирование — это разные понятия
Normalizer: применение нормализации к строкам
Normalizer в PySpark необходим для нормализации не атрибутов (столбцов), а записей (строк) путем деления на p-норму . Общая формула выглядит так:
p_norm = sum(X**p) ** (1/p) X = X / p_norm
Единственным параметром в этом виде нормализации является , причём
-
если p=1, то p-норма равна сумме значений каждой строки;
-
если p=∞, то p-норма равна максимальному значению в каждой строке.
Следующий код на Python демонстрирует результат при p=1:
from pyspark.ml.feature import Normalizer
from pyspark.ml.linalg import Vectors
dataFrame = spark.createDataFrame(),),
(1, Vectors.dense(),),
(2, Vectors.dense(),)
], )
normalizer = Normalizer(inputCol="features", outputCol="normFeatures", p=1.0)
l1NormData = normalizer.transform(dataFrame)
print("Normalized using L^1 norm")
l1NormData.show()
#
Normalized using L^1 norm
+---+--------------+------------------+
| id| features| normFeatures|
+---+--------------+------------------+
| 0|| |
| 1| | |
| 2|||
+---+--------------+------------------+
В случае же p=∞ нормализация в PySpark приводит к другим результатам:
lInfNormData = normalizer.transform(dataFrame, {normalizer.p: float("inf")})
print("Normalized using L^inf norm")
lInfNormData.show()
#
Normalized using L^inf norm
+---+--------------+--------------+
| id| features| normFeatures|
+---+--------------+--------------+
| 0|||
| 1| | |
| 2|| |
+---+--------------+--------------+
Normalizer можно применять после атрибутивного шкалирования, о которых пойдёт речь дальше.