Html кодировки
Содержание:
- Другие форматы данных
- UTF-8 Basic Latin
- BOM ломает парсеры JSON
- Макет кодовой страницы
- C0 Controls
- Самые распространенные кодировки
- BOM ломает скрипты
- Генерация файла для определения шрифта
- Range: Decimal 768-879. Hex 0300-036F.
- Что такое кодировка сайта и как она работает
- Проблемы с кодировкой не только в HTML-странице
- История создания
- Кодирование и декодирование
Другие форматы данных
Спецификация в JSON не нужна, является незаконной и нарушает работу программного обеспечения, которое работает в соответствии с RFC. Это должен быть нобрейнер, чтобы просто не использовать его тогда, и тем не менее, всегда есть люди, которые настаивают на нарушении JSON, используя спецификации, комментарии, разные правила цитирования или разные типы данных. Конечно, любой может свободно использовать такие вещи, как спецификации или что-то еще, если вам это нужно — просто не называйте это JSON.
Для других форматов данных, кроме JSON, посмотрите, как это действительно выглядит. Если единственными кодировками являются UTF- * и первый символ должен быть символом ASCII ниже 128, то у вас уже есть вся информация, необходимая для определения как кодировки, так и порядкового номера ваших данных. Добавление спецификаций даже в качестве дополнительной функции сделает ее более сложной и подверженной ошибкам.
UTF-8 Basic Latin
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| 32 | 0020 | SPACE | ||
| ! | 33 | 0021 | EXCLAMATION MARK | |
| « | 34 | 0022 | " | QUOTATION MARK |
| # | 35 | 0023 | NUMBER SIGN | |
| $ | 36 | 0024 | DOLLAR SIGN | |
| % | 37 | 0025 | PERCENT SIGN | |
| & | 38 | 0026 | & | AMPERSAND |
| ‘ | 39 | 0027 | APOSTROPHE | |
| ( | 40 | 0028 | LEFT PARENTHESIS | |
| ) | 41 | 0029 | RIGHT PARENTHESIS | |
| * | 42 | 002A | ASTERISK | |
| + | 43 | 002B | PLUS SIGN | |
| , | 44 | 002C | COMMA | |
| — | 45 | 002D | HYPHEN-MINUS | |
| . | 46 | 002E | FULL STOP | |
| 47 | 002F | SOLIDUS | ||
| 48 | 0030 | DIGIT ZERO | ||
| 1 | 49 | 0031 | DIGIT ONE | |
| 2 | 50 | 0032 | DIGIT TWO | |
| 3 | 51 | 0033 | DIGIT THREE | |
| 4 | 52 | 0034 | DIGIT FOUR | |
| 5 | 53 | 0035 | DIGIT FIVE | |
| 6 | 54 | 0036 | DIGIT SIX | |
| 7 | 55 | 0037 | DIGIT SEVEN | |
| 8 | 56 | 0038 | DIGIT EIGHT | |
| 9 | 57 | 0039 | DIGIT NINE | |
| 58 | 003A | COLON | ||
| ; | 59 | 003B | SEMICOLON | |
| < | 60 | 003C | < | LESS-THAN SIGN |
| = | 61 | 003D | EQUALS SIGN | |
| > | 62 | 003E | > | GREATER-THAN SIGN |
| ? | 63 | 003F | QUESTION MARK | |
| @ | 64 | 0040 | COMMERCIAL AT | |
| A | 65 | 0041 | LATIN CAPITAL LETTER A | |
| B | 66 | 0042 | LATIN CAPITAL LETTER B | |
| C | 67 | 0043 | LATIN CAPITAL LETTER C | |
| D | 68 | 0044 | LATIN CAPITAL LETTER D | |
| E | 69 | 0045 | LATIN CAPITAL LETTER E | |
| F | 70 | 0046 | LATIN CAPITAL LETTER F | |
| G | 71 | 0047 | LATIN CAPITAL LETTER G | |
| H | 72 | 0048 | LATIN CAPITAL LETTER H | |
| I | 73 | 0049 | LATIN CAPITAL LETTER I | |
| J | 74 | 004A | LATIN CAPITAL LETTER J | |
| K | 75 | 004B | LATIN CAPITAL LETTER K | |
| L | 76 | 004C | LATIN CAPITAL LETTER L | |
| M | 77 | 004D | LATIN CAPITAL LETTER M | |
| N | 78 | 004E | LATIN CAPITAL LETTER N | |
| O | 79 | 004F | LATIN CAPITAL LETTER O | |
| P | 80 | 0050 | LATIN CAPITAL LETTER P | |
| Q | 81 | 0051 | LATIN CAPITAL LETTER Q | |
| R | 82 | 0052 | LATIN CAPITAL LETTER R | |
| S | 83 | 0053 | LATIN CAPITAL LETTER S | |
| T | 84 | 0054 | LATIN CAPITAL LETTER T | |
| U | 85 | 0055 | LATIN CAPITAL LETTER U | |
| V | 86 | 0056 | LATIN CAPITAL LETTER V | |
| W | 87 | 0057 | LATIN CAPITAL LETTER W | |
| X | 88 | 0058 | LATIN CAPITAL LETTER X | |
| Y | 89 | 0059 | LATIN CAPITAL LETTER Y | |
| Z | 90 | 005A | LATIN CAPITAL LETTER Z | |
| 91 | 005B | LEFT SQUARE BRACKET | ||
| \ | 92 | 005C | REVERSE SOLIDUS | |
| 93 | 005D | RIGHT SQUARE BRACKET | ||
| ^ | 94 | 005E | CIRCUMFLEX ACCENT | |
| _ | 95 | 005F | LOW LINE | |
| ` | 96 | 0060 | GRAVE ACCENT | |
| a | 97 | 0061 | LATIN SMALL LETTER A | |
| b | 98 | 0062 | LATIN SMALL LETTER B | |
| c | 99 | 0063 | LATIN SMALL LETTER C | |
| d | 100 | 0064 | LATIN SMALL LETTER D | |
| e | 101 | 0065 | LATIN SMALL LETTER E | |
| f | 102 | 0066 | LATIN SMALL LETTER F | |
| g | 103 | 0067 | LATIN SMALL LETTER G | |
| h | 104 | 0068 | LATIN SMALL LETTER H | |
| i | 105 | 0069 | LATIN SMALL LETTER I | |
| j | 106 | 006A | LATIN SMALL LETTER J | |
| k | 107 | 006B | LATIN SMALL LETTER K | |
| l | 108 | 006C | LATIN SMALL LETTER L | |
| m | 109 | 006D | LATIN SMALL LETTER M | |
| n | 110 | 006E | LATIN SMALL LETTER N | |
| o | 111 | 006F | LATIN SMALL LETTER O | |
| p | 112 | 0070 | LATIN SMALL LETTER P | |
| q | 113 | 0071 | LATIN SMALL LETTER Q | |
| r | 114 | 0072 | LATIN SMALL LETTER R | |
| s | 115 | 0073 | LATIN SMALL LETTER S | |
| t | 116 | 0074 | LATIN SMALL LETTER T | |
| u | 117 | 0075 | LATIN SMALL LETTER U | |
| v | 118 | 0076 | LATIN SMALL LETTER V | |
| w | 119 | 0077 | LATIN SMALL LETTER W | |
| x | 120 | 0078 | LATIN SMALL LETTER X | |
| y | 121 | 0079 | LATIN SMALL LETTER Y | |
| z | 122 | 007A | LATIN SMALL LETTER Z | |
| { | 123 | 007B | LEFT CURLY BRACKET | |
| | | 124 | 007C | VERTICAL LINE | |
| } | 125 | 007D | RIGHT CURLY BRACKET | |
| ~ | 126 | 007E | TILDE |
BOM ломает парсеры JSON
Не только это нелегальный в JSON и не нужно, это на самом деле ломает все программное обеспечение которые определяют кодирование с использованием метода, представленного в RFC 4627:
Определяем кодировку и порядковый номер JSON, исследуя первые 4 байта для байта NUL:
Теперь, если файл начинается с спецификации, он будет выглядеть так:
Обратите внимание, что:
- UTF-32BE не запускается с тремя NUL, поэтому он не будет распознан
- UTF-32LE, за первым байтом не следуют 3 NUL, поэтому он не будет распознан
- UTF-16BE имеет только 1 NUL в первых 4 байтах, поэтому он не будет распознан
- UTF-16LE имеет только 1 NUL в первых 4 байтах, поэтому он не будет распознан
В зависимости от реализации все они могут быть неверно интерпретированы как UTF-8, а затем неверно истолкованы или отклонены как недействительные UTF-8, или не распознаны вообще.
Кроме того, если реализация проверяет действительный JSON, как я рекомендую, он отклонит даже ввод, который действительно закодирован как UTF-8, потому что он не начинается с символа ASCII < 128 как положено по RFC.
Макет кодовой страницы
В следующей таблице суммируется использование кодовых блоков UTF-8 (отдельных байтов или октетов) в формате кодовой страницы. Верхняя половина (от до ) предназначена для байтов, используемых только в однобайтных кодах, поэтому она выглядит как обычная кодовая страница; Нижняя половина — для байтов продолжения (от до ) и (возможно) ведущих байтов (от до ), и поясняется далее в легенде ниже.
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ | NUL0000 | SOH00011 | STX00022 | ETX00033 | EOT00044 | ENQ00055 | ACK00066 | BEL00077 | BS00088 | HT00099 | LF000A10 | VT000B11 | FF000C12 | CR000D13 | SO000E14 | SI000F15 |
| 1_ | DLE001016 | DC1001117 | DC2001218 | DC3001319 | DC4001420 | NAK001521 | SYN001622 | ETB001723 | CAN001824 | EM001925 | SUB001A26 | ESC001B27 | FS001C28 | GS001D29 | RS001E30 | US001F31 |
| 2_ | SP002032 | !002133 | «002234 | #002335 | $002436 | %002537 | &002638 | ‘002739 | (002840 | )002941 | *002A42 | +002B43 | ,002C44 | —002D45 | .002E46 | 002F47 |
| 3_ | 003048 | 003149 | 003250 | 003351 | 003452 | 003553 | 003654 | 003755 | 003856 | 003957 | 003A58 | ;003B59 | <003C60 | =003D61 | >003E62 | ?003F63 |
| 4_ | @004064 | A004165 | B004266 | C004367 | D004468 | E004569 | F004670 | G004771 | H004872 | I004973 | J004A74 | K004B75 | L004C76 | M004D77 | N004E78 | O004F79 |
| 5_ | P005080 | Q005181 | R005282 | S005383 | T005484 | U005585 | V005686 | W005787 | X005888 | Y005989 | Z005A90 | 005B91 | \005C92 | 005D93 | ^005E94 | _005F95 |
| 6_ | `006096 | a006197 | b006298 | c006399 | d0064100 | e0065101 | f0066102 | g0067103 | h0068104 | i0069105 | j006A106 | k006B107 | l006C108 | m006D109 | n006E110 | o006F111 |
| 7_ | p0070112 | q0071113 | r0072114 | s0073115 | t0074116 | u0075117 | v0076118 | w0077119 | x0078120 | y0079121 | z007A122 | {007B123 | |007C124 | }007D125 | ~007E126 | DEL007F127 |
| 8_ | •+00128 | •+01129 | •+02130 | •+03131 | •+04132 | •+05133 | •+06134 | •+07135 | •+08136 | •+09137 | •+0A138 | •+0B139 | •+0C140 | •+0D141 | •+0E142 | •+0F143 |
| 9_ | •+10144 | •+11145 | •+12146 | •+13147 | •+14148 | •+15149 | •+16150 | •+17151 | •+18152 | •+19153 | •+1A154 | •+1B155 | •+1C156 | •+1D157 | •+1E158 | •+1F159 |
| A_ | •+20160 | •+21161 | •+22162 | •+23163 | •+24164 | •+25165 | •+26166 | •+27167 | •+28168 | •+29169 | •+2A170 | •+2B171 | •+2C172 | •+2D173 | •+2E174 | •+2F175 |
| B_ | •+30176 | •+31177 | •+32178 | •+33179 | •+34180 | •+35181 | •+36182 | •+37183 | •+38184 | •+39185 | •+3A186 | •+3B187 | •+3C188 | •+3D189 | •+3E190 | •+3F191 |
| 2-byteC_ | 0000192 | 0040193 | Latin0080194 | Latin00C0195 | Latin0100196 | Latin0140197 | Latin0180198 | Latin01C0199 | Latin0200200 | IPA0240201 | IPA0280202 | IPA02C0203 | accents0300204 | accents0340205 | Greek0380206 | Greek03C0207 |
| 2-byteD_ | Cyril0400208 | Cyril0440209 | Cyril0480210 | Cyril04C0211 | Cyril0500212 | Armeni0540213 | Hebrew0580214 | Hebrew05C0215 | Arabic0600216 | Arabic0640217 | Arabic0680218 | Arabic06C0219 | Syriac0700220 | Arabic0740221 | Thaana0780222 | N’Ko07C0223 |
| 3-byteE_ | Indic0800*224 | Misc.1000225 | Symbol2000226 | Kana, CJK3000227 | CJK4000228 | CJK5000229 | CJK6000230 | CJK7000231 | CJK8000232 | CJK9000233 | AsianA000234 | HangulB000235 | HangulC000236 | HangulD000237 | PUAE000238 | FormsF000239 |
| 4‑byteF_ | SMP, SIP10000*240 | 40000241 | 80000242 | SSP, SPUAC0000243 | SPUA-B100000244 | 140000245 | 180000246 | 1C0000247 | 5-byte200000*248 | 5-byte1000000249 | 5-byte2000000250 | 5-byte3000000251 | 6-byte4000000*252 | 6-byte40000000253 | 254 | 255 |
Оранжевые ячейки с большой точкой являются байтами продолжения. Шестнадцатеричное число, указанное после знака «+», представляет собой значение шести бит, которые они добавляют.
Белые ячейки — это ведущие байты для последовательности из нескольких байтов, длина показана слева от строки. Текст показывает блоки Unicode, закодированные последовательностями, начинающимися с этого байта, а шестнадцатеричная кодовая точка, показанная в ячейке, является самым младшим символьным значением, закодированным с использованием этого старшего байта.
Красные клетки никогда не должны появляться в действительной последовательности UTF-8. Первые два (C0 и C1) могли использоваться только для недопустимого «чрезмерного кодирования» символов ASCII (то есть, пытаясь закодировать 7-битное значение ASCII между 0 и 127, используя два байта вместо одного, см. Ниже). Оставшиеся красные ячейки указывают ведущие байты последовательностей, которые могут только кодировать числа, превышающие предел 0x10FFFF в Юникоде, или которые также никогда не использовались в исходном проекте для 31 бита (FE и FF).
Розовые ячейки являются ведущими байтами для последовательности из нескольких байтов, из которых допустимы некоторые, но не все возможные последовательности продолжения. E0 и F0 могут начинать сглаженные кодировки, в этом случае отображается самая низкая незашифрованная кодовая точка, помеченная звездочкой «*». F4 может запускать кодовые точки более 0x10FFFF, которые являются недопустимыми. ED может начать кодирование суррогатной половины, которая не может быть закодирована в UTF-16 и также недействительна.
C0 Controls
The control characters were originally designed to control
hardware devices.
Control characters (except horizontal tab, carriage return, and line feed)
have nothing to do inside an HTML document.
| Char | Dec | Hex | Description |
|---|---|---|---|
| NUL | 0000 | null character | |
| SOH | 1 | 0001 | start of header |
| STX | 2 | 0002 | start of text |
| ETX | 3 | 0003 | end of text |
| EOT | 4 | 0004 | end of transmission |
| ENQ | 5 | 0005 | enquiry |
| ACK | 6 | 0006 | acknowledge |
| BEL | 7 | 0007 | bell (ring) |
| BS | 8 | 0008 | backspace |
| HT | 9 | 0009 | horizontal tab |
| LF | 10 | 000A | line feed |
| VT | 11 | 000B | vertical tab |
| FF | 12 | 000C | form feed |
| CR | 13 | 000D | carriage return |
| SO | 14 | 000E | shift out |
| SI | 15 | 000F | shift in |
| DLE | 16 | 0010 | data link escape |
| DC1 | 17 | 0011 | device control 1 |
| DC2 | 18 | 0012 | device control 2 |
| DC3 | 19 | 0013 | device control 3 |
| DC4 | 20 | 0014 | device control 4 |
| NAK | 21 | 0015 | negative acknowledge |
| SYN | 22 | 0016 | synchronize |
| ETB | 23 | 0017 | end transmission block |
| CAN | 24 | 0018 | cancel |
| EM | 25 | 0019 | end of medium |
| SUB | 26 | 001A | substitute |
| ESC | 27 | 001B | escape |
| FS | 28 | 001C | file separator |
| GS | 29 | 001D | group separator |
| RS | 30 | 001E | record separator |
| US | 31 | 001F | unit separator |
| DEL | 127 | 007F | delete (rubout) |
❮ Previous
Next ❯
Самые распространенные кодировки
Из предыдущего пункта вы уже знаете что такое кодировка и почему настолько важно правильно прописать ее в коде страниц сайта. Давайте теперь выясним какую из множества кодировок лучше выбрать для будущего сайта
Поскольку самой распространенной и наиболее понятной в освоении всегда была операционная система Windows, то большинство веб-разработчиков создавали HTML-страницы в кодировке windows-1251 (ANSI), которая использовалась по-умолчанию. Но windows-1251 поддерживает не очень большое количество букв и символов, а разработчики хотят использовать в своих текстах различные стрелочки, сердечки, квадратики и другие символы, в том числе есть необходимость совмещать слова из разных языков в одном документе, поэтому на смену ей уже давно пришла более расширенная UTF-8 и большинство разработчиков используют именно эту кодировку.
BOM ломает скрипты
Сценарии оболочки, сценарии Perl, сценарии Python, сценарии Ruby, сценарии Node.js или любой другой исполняемый файл, который должен запускаться интерпретатором — все начинается с линия Шебанга который выглядит как один из тех:
Он сообщает системе, какой интерпретатор должен быть запущен при вызове такого скрипта. Если сценарий закодирован в UTF-8, может возникнуть соблазн включить вначале спецификацию. Но на самом деле «#!» персонажи не просто персонажи. Они на самом деле магическое число это происходит из двух символов ASCII. Если вы поместите что-то (например, спецификацию) перед этими символами, то файл будет выглядеть так, как будто он имеет другое магическое число, и это может привести к проблемам.
Смотрите Википедию, :
Генерация файла для определения шрифта
Вторым шагом является создание PHP файла, который содержит всю необходимую информацию для FPDF. Для того чтобы чтобы это сделать, в каталоге font/makefont Вы сможете найти дополнительный скрипт в фале makefont.php, который содержит следующие функции:MakeFont( string fontfile, string afmfile ]])
Значения которые принимает метод, в качестве параметров:
- fontfile — Путь к файлу с расширением .ttf или .pfb.
- afmfile — Путь к файлу с расширением .afm.
- enc — Название используемой кодировки. По умолчанию cp1252.
- patch — Дополнительные изменения касающиеся кодировки. По умолчанию пуст.
- type — Тип шрифта ( TrueType или Type1 ). По умолчанию TrueType.
Первым параметром должно быть имя и путь к шрифту. Расширение должно быть .ttf или .pfb. Если у вас есть шрифт Type1 в ASCII формате с расширением .pfa, Вы можете преобразовать его в двоичном формате с помощью утилиты .
Ранее сгенерированный файл AFM
Кодировка определяет связь между кодом (от 0 до 255) и характер. Первые 128 являются фиксированными и соответствуют ASCII, а следующие являются переменными. Кодировки хранятся в .map файлах. Кодировки бывают следующие:
- cp1250 (Central Europe)
- cp1251 (Cyrillic)
- cp1252 (Western Europe)
- cp1253 (Greek)
- cp1254 (Turkish)
- cp1255 (Hebrew)
- cp1257 (Baltic)
- cp1258 (Vietnamese)
- cp874 (Thai)
- ISO-8859-1 (Western Europe)
- ISO-8859-2 (Central Europe)
- ISO-8859-4 (Baltic)
- ISO-8859-5 (Cyrillic)
- ISO-8859-7 (Greek)
- ISO-8859-9 (Turkish)
- ISO-8859-11 (Thai)
- ISO-8859-15 (Western Europe)
- ISO-8859-16 (Central Europe)
- KOI8-R (Russian)
- KOI8-U (Ukrainian)
Шрифт который Вы выберете должен содержать символы, соответствующие выбранной кодировке.
В особенных случаях когда символы шрифта не содержат литеры, такие, как Symbol или ZapfDingbats, нужно передать пустую строку.
Кодировки, которые начинаются с СР, используются в ОС Windows. Linux системы обычно используют ISO.Примечание: стандартные шрифты используют кодировку cp1252.
Четвертый параметр дает возможность изменять кодировку. Иногда Вы можете добавить несколько символов. Так, например, ISO-8859-1 не содержит символ евро. Чтобы добавить его на позицию 164, нужно передать — array(164=>’Euro’).
Последний параметр используется для передачи типа шрифта, в случае, если он не встроены (то есть если первый параметр пуст).
После того как Вы заполнили все параметры функции, Вы можете создать новый файл подключив при этом makefont.php, или просто добавить вызов функции непосредственно внутрь основного файла. После исполнения функции будет создано несколько файлов:.php и .afm. При желании Вы можете переименовать файл. Помимо этого скрипт создает файл с расширением .z, который является сжатым (за исключением случаев, когда функция сжатия недоступна, она требует Zlib). Вы можете переименовать и его тоже, но в этом случае Вы должны изменить переменную $file в .php файле, с соответствующим именем.
Пример:
MakeFont('c:\\windows\\fonts\\comic.ttf','comic.afm','cp1252');
|
Выше приведенный пример создаст два файла: comic.php и comic.z.
Когда Вы получите эти файлы, их нужно скопировать в каталог с шрифтами. Если файл шрифта не получился сжатым то скопируйте файлы с расширением .ttf или .pfb, вместо .z.
Примечание: для шрифтов TTF, Вы можете не делать этого в ручную а скачать эти файлы с помощью утилиты по этому адресу: http://fpdf.fruit-lab.de/. Я думаю что использование данного скрипта не составит у Вас больших трудностей, но все таки: Нужно выбрать файл TTF с компьютера, и потом при нажатии на единственную кнопку получите нужные файлы для FPDF.
Range: Decimal 768-879. Hex 0300-036F.
If you want any of these characters displayed in HTML, you can use the HTML entity found in the table below.
If the character does not have an HTML entity, you can use the decimal (dec) or hexadecimal (hex) reference.
Will display as:
I will display a
I will display ̃
I will display ã
Older browsers may not support all the HTML5 entities in the table below.
Chrome and Opera have good support, and IE 11+ and Firefox 35+ support all the entities.
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| ò | 768 | 0300 | GRAVE ACCENT | |
| ó | 769 | 0301 | ACUTE ACCENT | |
| ô | 770 | 0302 | CIRCUMFLEX ACCENT | |
| õ | 771 | 0303 | TILDE | |
| ō | 772 | 0304 | MACRON | |
| o̅ | 773 | 0305 | OVERLINE | |
| ŏ | 774 | 0306 | BREVE | |
| ȯ | 775 | 0307 | DOT ABOVE | |
| ö | 776 | 0308 | DIAERESIS | |
| ỏ | 777 | 0309 | HOOK ABOVE | |
| o̊ | 778 | 030A | RING ABOVE | |
| ő | 779 | 030B | DOUBLE ACUTE ACCENT | |
| ǒ | 780 | 030C | CARON | |
| o̍ | 781 | 030D | VERTICAL LINE ABOVE | |
| o̎ | 782 | 030E | DOUBLE VERTICAL LINE ABOVE | |
| ȍ | 783 | 030F | DOUBLE GRAVE ACCENT | |
| o̐ | 784 | 0310 | CANDRABINDU | |
| ȏ | 785 | 0311 | INVERTED BREVE | |
| o̒ | 786 | 0312 | TURNED COMMA ABOVE | |
| o̓ | 787 | 0313 | COMMA ABOVE | |
| o̔ | 788 | 0314 | REVERSED COMMA ABOVE | |
| o̕ | 789 | 0315 | COMMA ABOVE RIGHT | |
| o̖ | 790 | 0316 | GRAVE ACCENT BELOW | |
| o̗ | 791 | 0317 | ACUTE ACCENT BELOW | |
| o̘ | 792 | 0318 | LEFT TACK BELOW | |
| o̙ | 793 | 0319 | RIGHT TACK BELOW | |
| o̚ | 794 | 031A | LEFT ANGLE ABOVE | |
| ơ | 795 | 031B | HORN | |
| o̜ | 796 | 031C | LEFT HALF RING BELOW | |
| o̝ | 797 | 031D | UP TACK BELOW | |
| o̞ | 798 | 031E | DOWN TACK BELOW | |
| o̟ | 799 | 031F | PLUS SIGN BELOW | |
| o̠ | 800 | 0320 | MINUS SIGN BELOW | |
| o̡ | 801 | 0321 | PALATALIZED HOOK BELOW | |
| o̢ | 802 | 0322 | RETROFLEX HOOK BELOW | |
| ọ | 803 | 0323 | DOT BELOW | |
| o̤ | 804 | 0324 | DIAERESIS BELOW | |
| o̥ | 805 | 0325 | RING BELOW | |
| o̦ | 806 | 0326 | COMMA BELOW | |
| o̧ | 807 | 0327 | CEDILLA | |
| ǫ | 808 | 0328 | OGONEK | |
| o̩ | 809 | 0329 | VERTICAL LINE BELOW | |
| o̪ | 810 | 032A | BRIDGE BELOW | |
| o̫ | 811 | 032B | INVERTED DOUBLE ARCH BELOW | |
| o̬ | 812 | 032C | CARON BELOW | |
| o̭ | 813 | 032D | CIRCUMFLEX ACCENT BELOW | |
| o̮ | 814 | 032E | BREVE BELOW | |
| o̯ | 815 | 032F | INVERTED BREVE BELOW | |
| o̰ | 816 | 0330 | TILDE BELOW | |
| o̱ | 817 | 0331 | MACRON BELOW | |
| o̲ | 818 | 0332 | LOW LINE | |
| o̳ | 819 | 0333 | DOUBLE LOW LINE | |
| o̴ | 820 | 0334 | TILDE OVERLAY | |
| o̵ | 821 | 0335 | SHORT STROKE OVERLAY | |
| o̶ | 822 | 0336 | LONG STROKE OVERLAY | |
| o̷ | 823 | 0337 | SHORT SOLIDUS OVERLAY | |
| o̸ | 824 | 0338 | LONG SOLIDUS OVERLAY | |
| o̹ | 825 | 0339 | RIGHT HALF RING BELOW | |
| o̺ | 826 | 033A | INVERTED BRIDGE BELOW | |
| o̻ | 827 | 033B | SQUARE BELOW | |
| o̼ | 828 | 033C | SEAGULL BELOW | |
| o̽ | 829 | 033D | X ABOVE | |
| o̾ | 830 | 033E | VERTICAL TILDE | |
| o̿ | 831 | 033F | DOUBLE OVERLINE | |
| ò | 832 | 0340 | GRAVE TONE MARK | |
| ó | 833 | 0341 | ACUTE TONE MARK | |
| o͂ | 834 | 0342 | GREEK PERISPOMENI (combined with theta) | |
| o̓ | 835 | 0343 | GREEK KORONIS (combined with theta) | |
| ö́ | 836 | 0344 | GREEK DIALYTIKA TONOS (combined with theta) | |
| oͅ | 837 | 0345 | GREEK YPOGEGRAMMENI (combined with theta) | |
| o͆ | 838 | 0346 | BRIDGE ABOVE | |
| o͇ | 839 | 0347 | EQUALS SIGN BELOW | |
| o͈ | 840 | 0348 | DOUBLE VERTICAL LINE BELOW | |
| o͉ | 841 | 0349 | LEFT ANGLE BELOW | |
| o͊ | 842 | 034A | NOT TILDE ABOVE | |
| o͋ | 843 | 034B | HOMOTHETIC ABOVE | |
| o͌ | 844 | 034C | ALMOST EQUAL TO ABOVE | |
| o͍ | 845 | 034D | LEFT RIGHT ARROW BELOW | |
| o͎ | 846 | 034E | UPWARDS ARROW BELOW | |
| o͏ | 847 | 034F | GRAPHEME JOINER | |
| o͐ | 848 | 0350 | RIGHT ARROWHEAD ABOVE | |
| o͑ | 849 | 0351 | LEFT HALF RING ABOVE | |
| o͒ | 850 | 0352 | FERMATA | |
| o͓ | 851 | 0353 | X BELOW | |
| o͔ | 852 | 0354 | LEFT ARROWHEAD BELOW | |
| o͕ | 853 | 0355 | RIGHT ARROWHEAD BELOW | |
| o͖ | 854 | 0356 | RIGHT ARROWHEAD AND UP ARROWHEAD BELOW | |
| o͗ | 855 | 0357 | RIGHT HALF RING ABOVE | |
| o͘ | 856 | 0358 | DOT ABOVE RIGHT | |
| o͙ | 857 | 0359 | ASTERISK BELOW | |
| o͚ | 858 | 035A | DOUBLE RING BELOW | |
| o͛ | 859 | 035B | ZIGZAG ABOVE | |
| ͜o | 860 | 035C | DOUBLE BREVE BELOW | |
| ͝o | 861 | 035D | DOUBLE BREVE | |
| ͞o | 862 | 035E | DOUBLE MACRON | |
| ͟o | 863 | 035F | DOUBLE MACRON BELOW | |
| ͠o | 864 | 0360 | DOUBLE TILDE | |
| ͡o | 865 | 0361 | DOUBLE INVERTED BREVE | |
| ͢o | 866 | 0362 | DOUBLE RIGHTWARDS ARROW BELOW | |
| oͣ | 867 | 0363 | LATIN SMALL LETTER A | |
| oͤ | 868 | 0364 | LATIN SMALL LETTER E | |
| oͥ | 869 | 0365 | LATIN SMALL LETTER I | |
| oͦ | 870 | 0366 | LATIN SMALL LETTER O | |
| oͧ | 871 | 0367 | LATIN SMALL LETTER U | |
| oͨ | 872 | 0368 | LATIN SMALL LETTER C | |
| oͩ | 873 | 0369 | LATIN SMALL LETTER D | |
| oͪ | 874 | 036A | LATIN SMALL LETTER H | |
| oͫ | 875 | 036B | LATIN SMALL LETTER M | |
| oͬ | 876 | 036C | LATIN SMALL LETTER R | |
| oͭ | 877 | 036D | LATIN SMALL LETTER T | |
| oͮ | 878 | 036E | LATIN SMALL LETTER V | |
| oͯ | 879 | 036F | LATIN SMALL LETTER X |
❮ Previous
Next ❯
Что такое кодировка сайта и как она работает
Кодировку можно представить в виде таблицы, состоящей из разных букв, цифр и других символов понятных человеку, которые закодированы определенным образом. Когда вы открываете текстовый файл, к которым относятся в том числе HTML-страницы, то компьютер считывает из заголовка файла в какой кодировке он был сохранен и выводит текст в соответствующей кодировке преобразовывая компьютерные данные в вид понятный человеку сопоставляя эти данные с таблицей кодировки. Если информация о кодировке из заголовка файла совпадает с кодировкой в которой сохранены данные в HTML-странице, то пользователь видит привычные ему буквы, цифры и другие символы. Если же есть несовпадение, то в результате пользователю выводится непонятный набор символов, особенно часто это происходит в старых почтовых программах. Если пользователь получил письмо с непонятными крякозябрами, то просто перебирая разные кодировки, обычно получается угадать и выбрать ту, в которой написано письмо, и в результате непонятный набор символов превращается в понятный человеку текст.
То же самое происходит и с HTML-страницами сайта. Если документ был сохранен, например, в кодировке UTF-8, а в самом документе прописан META-тег указывающий что это кодировка windows-1251, то браузер опять же будет сопоставлять сохраненные в файле данные с таблицей указанной ему кодировки и так как символы закодированы по-разному, то браузер выведет вместо привычного текста непонятный набор символов или же часть букв может быть в нормальном виде, а другие буквы или символы могут выводиться, например, в виде знаков вопроса. Все выше сказанное относится в том числе и к отображению имен файлов.
Создавая новый документ в текстовом редакторе лучше сразу убедиться что выбрана нужная кодировка. Современные редакторы позволяют преобразовать текст открытого документа из одной кодировки в другую, а стандартный Блокнот позволяет выбрать кодировку только при сохранении файла.
Проблемы с кодировкой не только в HTML-странице
Сайт, независимо от того является ли он просто набором статических HTML-документов или сложных динамических скриптов генерирующих страницы на лету, размещается на веб-сервере, который также работает с определенной кодировкой. И если сервер выдает информацию в одной кодировке, а ваши страницы или скрипты сохранены в другой кодировке, то опять же могут быть проблемы с отображением страниц в браузере пользователя. Многие хостинги позволяют менять настройки и выбрать кодировку в соответствии с той, которая используется в файлах сайта, через панель управления или же прописать ее в файле .htaccess, если на хостинге используется популярный веб-сервер Apache.
Практически ни один современный сайт не обходится без использования базы данных MySQL и она также может стать источником проблем с кодировкой. Если файлы сайта сохранены в одной кодировке, а информация в базе данных в другой, то на странице та часть информации, которая выводится из базы данных может отображаться в виде все тех же знаков вопросов или других непонятных символов. Чтобы избежать проблем с кодировкой она должна быть одинаковой для веб-сервера, базы данных MySQL, в скриптах, в HTML-страницах сайта и в META-теге, который прописывается в HTML-коде. Если есть проблемы с отображением текста, то проверяйте на наличие проблемы все выше перечисленное.
История создания
До появления Unicode UTF-8 широко использовались другие кодировки (ASCII, ISO/IEC 646, ISO/IEC 8859, KOI8, Windows-125x).
Впервые кодировка UTF-8 была официально представлена на конференции USENIX в Сан Диего в январе 1993. От других мультибайтных кодировок ее отличала полная совместимость с ASCII: все символы ASCII в UTF-8 кодируются 7 битами. Каждый символ кодировки, отличный от ASCII, состоит из ведущего байта, указывающего длину последовательности, и одного или нескольких продолжающих байт. Такой принцип позволяет определить длину последовательности только по первому байту. Коды символов ASCII, ведущих и продолжающих байт не пересекаются, что позволяет легко найти начало последовательности простым откатом назад максимум на пять байт.
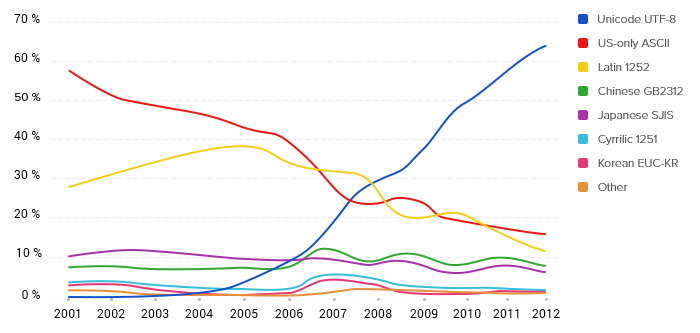 График изменения популярности кодировок в интернете
График изменения популярности кодировок в интернете
В ноябре 2003 года стандартом RFC-3629 максимальная длина последовательности UTF-8 была ограничена четырьмя байтами, однако потенциально UTF-8 позволяет использовать последовательности вплоть до шести байт.
На сегодняшний день самой распространенной кодировкой является UTF-8. Она включает в себя более двух миллионов символов: все возможные современные алфавиты, цифры, знаки препинания, математические и специальные символы, музыкальные знаки и символы вымерших форм письменности. А резерва UTF-8 хватит для размещения более двух миллиардов символов. Так что о смене кодировки в ближайшее время задумываться не придётся.
Однако торжество современных технологий — явление относительно новое. Согласно Google, самой распространенной в интернете кодировкой UTF-8 стала только в 2008 году — тогда ее использовали чуть более чем 25% проиндексированных веб-страниц. А еще в 2006 UTF-8 использовали менее чем 10% веб-страниц.
Стремительный рост популярности кодировки UTF-8 связан с целым рядом ее преимуществ перед предшественницами.
Кодирование и декодирование
Кодирование— это процесс формирования определенного представления информации,переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.То есть любой символ, который мы видим или вводим, для компьютера в реальности — всего лишь набор битов (набор нулей и единиц). Именно эти биты и перегоняются от устройства к устройству. А чтобы показать результат этих перегонок человеку, компьютер преобразует с помощью таблицы (той самой кодировки) код символа в соответствующий внешний вид.
UTF-32LE в UTF-8
Схемой можете воспользоваться при кодировании и раскодировании.
Эта схема сделана так, чтобы вы видели какие биты куда попадают как при кодировании, так и раскодировании.
По ней видно что при этих обоих процессах просто нужные биты выставляются на нужные позиции при нужных значениях контрольных бит.
Можно заметить что компоновка в больших байтовых последовательностях осуществляется по 6 бит (в так называемых лидирующих байтах).
При этом старшие биты предусматриваемого кода будут в первых байтах (схоже с порядком Big-Endian).

Кодирование
Порядок действий такой:
- Каждый символ превращаем в Unicode.
- Проверяем из какого диапазона символ.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h40
b2 = (c - b1) &h40
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h40
b2 = ((c - b1) &h40) Mod &h40
b3 = (c - b1 - (&h40 * b2)) &h1000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < Then
ToLong = CLng(intVal) + &H10000
Else
ToLong = CLng(intVal)
End If
End Function
Декодирование
Декодирование — преобразование зашифрованной информации в понятный, пригодный для непосредственного использования вид.
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Unicode.
Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h3F
b2 = c and &h1F
c = b1 + b2 * &h40
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h3F
b2 = asc(mid(s,i+1,1)) and &h3F
b3 = c and &h0F
c = b3 * &H1000 + b2 * &H40 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function