Строки в python
Содержание:
Сложность строковых операций
Нет необходимости заучивать сложность каждой операции. Достаточно помнить, что большинство операций со строками «под капотом» делают посимвольную обработку. Если каждый символ обрабатывается за константное время O(1), то итоговая временная сложность будет O(n).
Трюк в том, чтобы понять:
- Сколько итераций цикла нужно пройти для получения результата? Иначе говоря, что есть n?
- В каких случаях цикл не нужен, либо наоборот, недостаточен.
| Действие | Временная сложность |
| a == b | O(n), где n — размер меньшей строки |
| a.startswith(b) | O(b) |
| s = «».join(arr) | O(s) |
| s = a + b | O(s) |
| s.split(«, «) | O(s) |
| b = a | O(1) |
| b = a | O(k) |
| b = a | O(1), т.к. мы просто создаем второй указатель на ту же строку |
| b = a | O(a). Это пример с подвохом. Такой трюк часто используется для создания независимой копии списка. Создать так копии строк можно, но бессмысленно, т.к. строки неизменяемы. Помимо времени, мы также расходуем лишние O(n) памяти. |
| a.find(b) | Для поиска подстроки используется специальный алгоритм, эффективность которого зависит от данных. В среднем на случайных строках можно ожидать O(a). В худшем случае — O(a*b), как у тривиального поиска (в цикле по a делаем сравнение подстроки с b) |
| re.match(expression, a) | Регулярные выражения работают медленнее поиска, но зависимость от длины строки как правило линейна, т.е. O(a). |
Вводная информация о строках
Как и во многих других языках программирования, в Python есть большая коллекция функций, операторов и методов, позволяющих работать со строковым типом.
Литералы строк
Литерал – способ создания объектов, в случае строк Питон предлагает несколько основных вариантов:
Если внутри строки необходимо расположить двойные кавычки, и сама строка была создана с помощью двойных кавычек, можно сделать следующее:
Разницы между строками с одинарными и двойными кавычками нет – это одно и то же
Какие кавычки использовать – решать вам, соглашение PEP 8 не дает рекомендаций по использованию кавычек. Просто выберите один тип кавычек и придерживайтесь его. Однако если в стоке используются те же кавычки, что и в литерале строки, используйте разные типы кавычек – обратная косая черта в строке ухудшает читаемость кода.
Кодировка строк
В третьей версии языка программирования Python все строки представляют собой последовательность Unicode-символов.
В Python 3 кодировка по умолчанию исходного кода – UTF-8. Во второй версии по умолчанию использовалась ASCII. Если необходимо использовать другую кодировку, можно разместить специальное объявление на первой строке файла, к примеру:
Максимальная длина строки в Python
Максимальная длина строки зависит от платформы. Обычно это:
- 2**31 — 1 – для 32-битной платформы;
- 2**63 — 1 – для 64-битной платформы;
Константа , определенная в модуле
Конкатенация строк
Одна из самых распространенных операций со строками – их объединение (конкатенация). Для этого используется знак , в результате к концу первой строки будет дописана вторая:
При необходимости объединения строки с числом его предварительно нужно привести тоже к строке, используя функцию
Сравнение строк
При сравнении нескольких строк рассматриваются отдельные символы и их регистр:
- цифра условно меньше, чем любая буква из алфавита;
- алфавитная буква в верхнем регистре меньше, чем буква в нижнем регистре;
- чем раньше буква в алфавите, тем она меньше;
При этом сравниваются по очереди первые символы, затем – 2-е и так далее.
Далеко не всегда желательной является зависимость от регистра, в таком случае можно привести обе строки к одному и тому же регистру. Для этого используются функции – для приведения к нижнему и – к верхнему:
Как удалить строку в Python
Строки, как и некоторые другие типы данных в языке Python, являются неизменяемыми объектами. При задании нового значения строке просто создается новая, с заданным значением. Для удаления строки можно воспользоваться методом , заменив ее на пустую строку:
Или перезаписать переменную пустой строкой:
Обращение по индексу
Для выбора определенного символа из строки можно воспользоваться обращением по индексу, записав его в квадратных скобках:
Индекс начинается с 0
В Python предусмотрена возможность получить доступ и по отрицательному индексу. В таком случае отсчет будет вестись от конца строки:
Python F-Строки: Детали
На данный момент мы узнали почему f-строки так хороши, так что вам уже может быть интересно их попробовать в работе. Рассмотрим несколько деталей, которые нужно учитывать:
Кавычки
Вы можете использовать несколько типов кавычек внутри выражений. Убедитесь в том, что вы не используете один и тот же тип кавычек внутри и снаружи f-строки.
Этот код будет работать:
Python
print(f»{‘Eric Idle’}»)
# Вывод: ‘Eric Idle’
|
1 |
print(f»{‘Eric Idle’}») # Вывод: ‘Eric Idle’ |
И этот тоже:
Python
print(f'{«Eric Idle»}’)
# Вывод: ‘Eric Idle’
|
1 |
print(f'{«Eric Idle»}’) # Вывод: ‘Eric Idle’ |
Вы также можете использовать тройные кавычки:
Python
print(f»»»Eric Idle»»»)
# Вывод: ‘Eric Idle’
|
1 |
print(f»»»Eric Idle»»») # Вывод: ‘Eric Idle’ |
Python
print(f»’Eric Idle»’)
# Вывод: ‘Eric Idle’
|
1 |
print(f»’Eric Idle»’) # Вывод: ‘Eric Idle’ |
Если вам понадобиться использовать один и тот же тип кавычек внутри и снаружи строки, вам может помочь :
Python
print(f»The \»comedian\» is {name}, aged {age}.»)
# Вывод: ‘The «comedian» is Eric Idle, aged 74.’
|
1 |
print(f»The \»comedian\» is {name}, aged {age}.») # Вывод: ‘The «comedian» is Eric Idle, aged 74.’ |
Словари
Говоря о кавычках, будьте внимательны при работе со . Вы можете вставить значение словаря по его ключу, но сам ключ нужно вставлять в одиночные кавычки внутри f-строки. Сама же f-строка должна иметь двойные кавычки.
Вот так:
Python
comedian = {‘name’: ‘Eric Idle’, ‘age’: 74}
print(f»The comedian is {comedian}, aged {comedian}.»)
# Вывод: The comedian is Eric Idle, aged 74.
|
1 |
comedian={‘name»Eric Idle’,’age’74} print(f»The comedian is {comedian}, aged {comedian}.») # Вывод: The comedian is Eric Idle, aged 74. |
Обратите внимание на количество возможных проблем, если допустить ошибку в синтаксисе SyntaxError:
Python
>>> comedian = {‘name’: ‘Eric Idle’, ‘age’: 74}
>>> f’The comedian is {comedian}, aged {comedian}.’
File «<stdin>», line 1
f’The comedian is {comedian}, aged {comedian}.’
^
SyntaxError: invalid syntax
|
1 |
>>>comedian={‘name»Eric Idle’,’age’74} >>>f’The comedian is {comedian}, aged {comedian}.’ File»<stdin>»,line1 f’The comedian is {comedian}, aged {comedian}.’ ^ SyntaxErrorinvalid syntax |
Если вы используете одиночные кавычки в ключах словаря и снаружи f-строк, тогда кавычка в начале ключа словаря будет интерпретирован как конец строки.
Скобки
Чтобы скобки появились в вашей строке, вам нужно использовать двойные скобки:
Python
print(f»`74`»)
# Вывод: ‘{ 74 }’
|
1 |
print(f»`74`») |
Обратите внимание на то, что использование тройных скобок приведет к тому, что в строке будут только одинарные:
Python
print( f»{`74`}» )
# Вывод: ‘{ 74 }’
|
1 |
print(f»{`74`}») |
Однако, вы можете получить больше отображаемых скобок, если вы используете больше, чем три скобки:
Python
print(f»{{`74`}}»)
# Вывод: ‘`74`’
|
1 |
print(f»{{`74`}}») |
Бэкслеши
Как вы видели ранее, вы можете использовать бэкслеши в части строки f-string. Однако, вы не можете использовать бэкслеши в части выражения f-string:
Python
>>> f»{\»Eric Idle\»}»
File «<stdin>», line 1
f»{\»Eric Idle\»}»
^
SyntaxError: f-string expression part cannot include a backslash
|
1 |
>>>f»{\»Eric Idle\»}» File»<stdin>»,line1 f»{\»Eric Idle\»}» ^ SyntaxErrorf-stringexpression part cannot includeabackslash |
Вы можете проработать это, оценивая выражение заранее и используя результат в f-строк:
Python
name = «Eric Idle»
print(f»{name}»)
# Вывод: ‘Eric Idle’
|
1 |
name=»Eric Idle» print(f»{name}») |
Междустрочные комментарии
Выражения не должны включать комментарии с использованием символа #. В противном случае, у вас будет ошибка синтаксиса SyntaxError:
Python
>>> f»Eric is {2 * 37 #Oh my!}.»
File «<stdin>», line 1
f»Eric is {2 * 37 #Oh my!}.»
^
SyntaxError: f-string expression part cannot include ‘#’
|
1 |
>>>f»Eric is {2 * 37 #Oh my!}.» File»<stdin>»,line1 f»Eric is {2 * 37 #Oh my!}.» ^ SyntaxErrorf-stringexpression part cannot include’#’ |
Оценка сложности решения
Для начала убедитесь, что вы понимаете, что такое асимптотическая сложность O(n). В двух словах: это оценка сверху вашего алгоритма в сравнении с типичными функциями: 1, log n, n, n log n, n^2, n^3, 2^n, n!.
Например, получение элемента в массиве по индексу имеет сложность O(1), то есть занимает постоянное время, не зависящее от размера массива.
Поиск элемента массива по значению имеет сложность О(n), т. к. вам нужно пробежаться в цикле по n-элементам.
Интенсив «Чат-бот с искусственным интеллектом на Python»
21–23 декабря, Онлайн, Беcплатно
tproger.ru
События и курсы на tproger.ru
Сложность оценивается с точностью до константы, т.е. O(n/2) = O(n).
Старшие члены перебивают младшие: O(n^2 + n) = O(n^2).
Разделение строки с использованием разделителя
Python может разбивать строки по любому разделителю, указанному в качестве параметра метода . Таким разделителем может быть, например, запятая, точка или любой другой символ (или даже несколько символов).
Давайте рассмотрим пример, где в
качестве разделителя выступает запятая
и точка с запятой (это можно использовать
для работы с CSV-файлами).
print("Python2, Python3, Python, Numpy".split(','))
print("Python2; Python3; Python; Numpy".split(';'))
Результат:
Как видите, в результирующих списках
отсутствуют сами разделители.
Если вам нужно получить список, в
который войдут и разделители (в качестве
отдельных элементов), можно разбить
строку по шаблону, с использованием
регулярных выражений (см. ). Когда вы берете шаблон в
захватывающие круглые скобки, группа
в шаблоне также возвращается как часть
результирующего списка.
import re
sep = re.split(',', 'Python2, Python3, Python, Numpy')
print(sep)
sep = re.split('(,)', 'Python2, Python3, Python, Numpy')
print(sep)
Результат:
Если вы хотите, чтобы разделитель был частью каждой подстроки в списке, можно обойтись без регулярных выражений и использовать list comprehensions:
text = 'Python2, Python3, Python, Numpy' sep = ',' result = print(result)
Результат:
Примеры
1. Возводим в квадрат все числа от 1 до 9. Применяем функцию range.
Python
| 1 | x**2forxinrange(10) |
Результат:
Python
| 1 | ,1,4,9,16,25,36,49,64,81 |
2. Все цифры которые делятся на 5 без остатка, в диапазоне от 0 до 100.
Python
| 1 | xforxinrange(100)ifx%5== |
Результат:
Python
| 1 | ,5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85,90,95 |
3. Все цифры которые делятся на 3 и 6 без остатка, в диапазоне от 0 до 50.
Python
| 1 | xforxinrange(50)ifx%3==andx%6!= |
Результат:
Python
| 1 | 3,9,15,21,27,33,39,45 |
4. Первая буква из каждого слова предложения.
Python
phrase = «Тестовое сообщение из мира Python для сообщества.»
print( for w in phrase.split()])
|
1 |
phrase=»Тестовое сообщение из мира Python для сообщества.» print(wforwinphrase.split()) |
Результат:
Python
| 1 | ‘Т’,’с’,’и’,’м’,’P’,’д’,’с’ |
5. Заменяем букву в каждом слове на .
Python
phrase = «АБАЖУР, АБАЗИНСКИЙ, АБАЗИНЫ, АББАТ, АББАТИСА, АББАТСТВО»
print(».join())
|
1 |
phrase=»АБАЖУР, АБАЗИНСКИЙ, АБАЗИНЫ, АББАТ, АББАТИСА, АББАТСТВО» print(».join(letter ifletter!=’А’else’#’forletter inphrase)) |
Результат:
Python
#Б#ЖУР, #Б#ЗИНСКИЙ, #Б#ЗИНЫ, #ББ#Т, #ББ#ТИС#, #ББ#ТСТВО
| 1 | #Б#ЖУР, #Б#ЗИНСКИЙ, #Б#ЗИНЫ, #ББ#Т, #ББ#ТИС#, #ББ#ТСТВО |
Итоги
Надеюсь это руководство помогло вам понять простой способ экономии кода , который вам нужно написать для получения конкретной готовой работы с вашими списками.
Старайтесь сохранять ваши списковые включения короткими, а условия if – простыми. Несложно разглядеть решение многих ваших проблем в списковых включениях и превратить их в огромный беспорядок.
Если это только распалило ваш аппетит, посмотрим, сможете ли вы разобраться со словарными включениями самостоятельно. Они используют конструкторы dict, {:} , но они довольно похожи. Вы также можете проработать установочные включения. Также ознакомьтесь с функциональным программированием в Python, если считаете себя готовым.
Преобразование типов данных
Мы можем преобразовывать значения из одного типа в другой с помощью таких функций, как , , и т.д.
При преобразовании числа с плавающей запятой в целое будет утеряна часть после запятой:
Для преобразования из/в строку должны использоваться совместимые значения:
Можно даже преобразовывать одну последовательность в другую:
Прим. перев. Для преобразования списка из символов обратно в строку нельзя вызвать , так как в результате мы получим строковое представление списка (наподобие того, что мы видим, когда выводим список на экран). Вместо этого нужно сделать следующее:
Для преобразования в словарь каждый элемент последовательности должен быть парой:
Методы подсчета
Методы подсчета позволяют ограничить количество символов в формах пользовательского ввода и сравнивать строки. Как и для других последовательных типов данных, для работы со строками существует несколько методов.
Метод len() выводит длину любого последовательного типа данных (включая строки, списки, кортежи и словари).
Запросите длину строки ss:
Строка «8host Blog!» содержит 11 символов.
Кроме переменных, метод len() может подсчитать длину любой заданной строки, например:
Метод len() подсчитывает общее количество символов в строке.
Метод str.count()может подсчитать, сколько раз в строке повторяется тот или иной символ. Запросите количество символов о в строке «8host Blog!».
Запросите другой символ:
Несмотря на то, что символ b присутствует в запрашиваемой строке, метод возвращает 0, поскольку он чувствителен к регистру. Чтобы вывести символы по нижнему регистру, используйте метод str.lower().
Используйте метод str.count() на последовательность символов:
Подстрока likes встречается в вышеприведённой строке дважды.
Чтобы определить индекс символа в строке, используйте метод str.find().
Для примера запросите индекс символа o в строке ss:
Первый символ о в строке «8host Blog!» находится под индексом 2.
Попробуйте узнать индекс первого символа подстроки «likes» внутри строки likes:
Но в данной строке последовательность likes встречается дважды. Как узнать индекс первого символа второй последовательности likes? Методу str.find() можно задать второй параметр – индекс, с которого нужно начинать поиск.
Операции со строками
Последнее обновление: 23.04.2017
Строка представляет последовательность символов в кодировке Unicode, заключенных в кавычки. Причем в Python мы можем использовать как одинарные, так и двойные кавычки:
name = "Tom" surname = 'Smith' print(name, surname) # Tom Smith
Одной из самых распространенных операций со строками является их объединение или конкатенация. Для объединения строк применяется знак плюса:
name = "Tom" surname = 'Smith' fullname = name + " " + surname print(fullname) # Tom Smith
С объединением двух строк все просто, но что, если нам надо сложить строку и число? В этом случае необходимо привести число к строке с помощью функции
str():
name = "Tom" age = 33 info = "Name: " + name + " Age: " + str(age) print(info) # Name: Tom Age: 33
Эскейп-последовательности
Кроме стандартных символов строки могут включать управляющие эскейп-последовательности, которые интерпретируются особым образом.
Например, последовательность \n представляет перевод строки. Поэтому следующее выражение:
print("Время пришло в гости отправится\nждет меня старинный друг")
На консоль выведет две строки:
Время пришло в гости отправится ждет меня старинный друг
Тоже самое касается и последовательности \t, которая добавляет табляцию.
Кроме того, существуют символы, которые вроде бы сложно использовать в строке. Например, кавычки. И чтобы отобразить кавычки (как двойные, так и одинарные)
внутри строки, перед ними ставится слеш:
print("Кафе \"Central Perk\"")
Сравнение строк
Особо следует сказать о сравнении строк
При сравнении строк принимается во внимание символы и их регистр. Так, цифровой символ условно меньше, чем любой алфавитный символ
Алфавитный символ в верхнем регистре условно меньше, чем алфавитные символы в нижнем регистре. Например:
str1 = "1a" str2 = "aa" str3 = "Aa" print(str1 > str2) # False, так как первый символ в str1 - цифра print(str2 > str3) # True, так как первый символ в str2 - в нижнем регистре
Поэтому строка «1a» условно меньше, чем строка «aa». Вначале сравнение идет по первому символу. Если начальные символы обоих строк представляют цифры, то
меньшей считается меньшая цифра, например, «1a» меньше, чем «2a».
Если начальные символы представляют алфавитные символы в одном и том же регистре, то смотрят по алфавиту. Так, «aa» меньше, чем «ba», а «ba» меньше, чем «ca».
Если первые символы одинаковые, в расчет берутся вторые символы при их наличии.
Зависимость от регистра не всегда желательна, так как по сути мы имеем дело с одинаковыми строками. В этом случае перед сравнением мы можем
привести обе строки к одному из регистров.
Функция lower() приводит строку к нижнему регистру, а функция upper() — к верхнему.
str1 = "Tom" str2 = "tom" print(str1 == str2) # False - строки не равны print(str1.lower() == str2.lower()) # True
НазадВперед
Методы списков
Давайте теперь
предположим, что у нас имеется список из чисел:
a = 1, -54, 3, 23, 43, -45,
и мы хотим в
конец этого списка добавить значение. Это можно сделать с помощью метода:
a.append(100)
И обратите
внимание: метод append ничего не возвращает, то есть, он меняет
сам список благодаря тому, что он относится к изменяемому типу данных. Поэтому
писать здесь конструкцию типа
a = a.append(100)
категорически не
следует, так мы только потеряем весь наш список! И этим методы списков
отличаются от методов строк, когда мы записывали:
string="Hello" string = string.upper()
Здесь метод upper возвращает
измененную строку, поэтому все работает как и ожидается. А метод append ничего не
возвращает, и присваивать значение None переменной a не имеет
смысла, тем более, что все работает и так:
a = 1, -54, 3, 23, 43, -45, a.append(100)
Причем, мы в методе
append можем записать
не только число, но и другой тип данных, например, строку:
a.append("hello")
тогда в конец
списка будет добавлен этот элемент. Или, булевое значение:
a.append(True)
Или еще один
список:
a.append(1,2,3)
И так далее. Главное,
чтобы было указано одно конкретное значение. Вот так работать не будет:
a.append(1,2)
Если нам нужно
вставить элемент в произвольную позицию, то используется метод
a.insert(3, -1000)
Здесь мы
указываем индекс вставляемого элемента и далее значение самого элемента.
Следующий метод remove удаляет элемент
по значению:
a.remove(True)
a.remove('hello')
Он находит
первый подходящий элемент и удаляет его, остальные не трогает. Если же
указывается несуществующий элемент:
a.remove('hello2')
то возникает
ошибка. Еще один метод для удаления
a.pop()
выполняет
удаление последнего элемента и при этом, возвращает его значение. В самом
списке последний элемент пропадает. То есть, с помощью этого метода можно
сохранять удаленный элемент в какой-либо переменной:
end = a.pop()
Также в этом
методе можно указывать индекс удаляемого элемента, например:
a.pop(3)
Если нам нужно
очистить весь список – удалить все элементы, то можно воспользоваться методом:
a.clear()
Получим пустой
список. Следующий метод
a = 1, -54, 3, 23, 43, -45, c = a.copy()
возвращает копию
списка. Это эквивалентно конструкции:
c = list(a)
В этом можно
убедиться так:
c1 = 1
и список c будет отличаться
от списка a.
Следующий метод count позволяет найти
число элементов с указанным значением:
c.count(1) c.count(-45)
Если же нам
нужен индекс определенного значения, то для этого используется метод index:
c.index(-45) c.index(1)
возвратит 0,
т.к. берется индекс только первого найденного элемента. Но, мы здесь можем
указать стартовое значение для поиска:
c.index(1, 1)
Здесь поиск
будет начинаться с индекса 1, то есть, со второго элемента. Или, так:
c.index(23, 1, 5)
Ищем число 23 с
1-го индекса и по 5-й не включая его. Если элемент не находится
c.index(23, 1, 3)
то метод
приводит к ошибке. Чтобы этого избежать в своих программах, можно вначале
проверить: существует ли такой элемент в нашем срезе:
23 in c1:3
и при значении True далее уже
определять индекс этого элемента.
Следующий метод
c.reverse()
меняет порядок
следования элементов на обратный.
Последний метод,
который мы рассмотрим, это
c.sort()
выполняет
сортировку элементов списка по возрастанию. Для сортировки по убыванию, следует
этот метод записать так:
c.sort(reverse=True)
Причем, этот
метод работает и со строками:
lst = "Москва", "Санкт-Петербург", "Тверь", "Казань" lst.sort()
Здесь
используется лексикографическое сравнение, о котором мы говорили, когда
рассматривали строки.
Это все основные
методы списков и чтобы вам было проще ориентироваться, приведу следующую
таблицу:
|
Метод |
Описание |
|
append() |
Добавляет |
|
insert() |
Вставляет |
|
remove() |
Удаляет |
|
pop() |
Удаляет |
|
clear() |
Очищает |
|
copy() |
Возвращает |
|
count() |
Возвращает |
|
index() |
Возвращает |
|
reverse() |
Меняет |
|
sort() |
Сортирует |
Best Practices
Последние абзацы статьи будут посвящены лучшим решениям практических задач, с которыми так или иначе сталкивается Python-разработчик.
Как перевести список в другой формат?
Иногда требуется перевести список в строку, в словарь или в JSON. Для этого нужно будет вывести список без скобок.
Перевод списка в строку осуществляется с помощью функции join(). На примере это выглядит так:
В данном случае в качестве разделителя используется запятая.
Словарь в Python – это такая же встроенная структура данных, наряду со списком. Преобразование списка в словарь — задача тоже несложная. Для этого потребуется воспользоваться функцией . Вот пример преобразования:
JSON – это JavaScript Object Notation. В Python находится встроенный модуль для кодирования и декодирования данных JSON. С применением метода можно запросто преобразовать список в строку JSON.
Как узнать индекс элемента в списке?
Узнать позицию элемента в последовательности списка бывает необходимым, когда элементов много, вручную их не сосчитать, и нужно обращение по индексу. Для того, чтобы узнать индекс элемента, используют функцию .
В качестве аргумента передаем значение, а на выходе получаем его индекс.
Как посчитать количество уникальных элементов в списке?
Самый простой способ – приведение списка к (множеству). После этого останутся только уникальные элементы, которые мы посчитаем функцией
Как создать список числовых элементов с шагом
Создание списка числовых элементов с шагом может понадобиться не так и часто, но мы рассмотрим пример построения такого списка.
Шагом называется переход от одного элемента к другому. Если шаг отрицательный, произойдёт реверс массива, то есть отсчёт пойдёт справа налево. Вот так выглядит список с шагом.
Еще один вариант – воспользоваться генератором списков:
При разработке на языке Python, списки встречаются довольно часто. Знание основ работы со списками поможет быстро и качественно писать программный код .
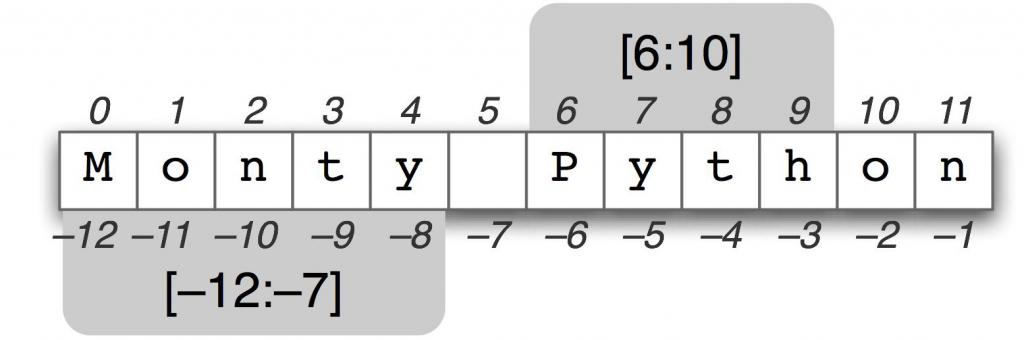
Индексация строк
Каждому символу в строке соответствует индексный номер, начиная с 0. К примеру, строка 8host Blog! индексируется следующим образом:
| 8 | h | o | s | t | B | l | o | g | ! | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
Как видите, индексом первого символа является 0, последний индекс, 10, принадлежит символу «!».Любой другой символ или знак препинания (*#$&.;?,) также будет иметь свой собственный номер индекса.
Следует обратить внимание на то, что пробел также является частью строки, потому тоже имеет свой индекс (в данном случае 5). Принимая во внимание тот факт, что каждый символ в строке Python имеет соответствующий индекс, вы можете управлять строками так же, как и любыми другими последовательными типами данных
Принимая во внимание тот факт, что каждый символ в строке Python имеет соответствующий индекс, вы можете управлять строками так же, как и любыми другими последовательными типами данных
Поиск символа по положительному индексу
Ссылаясь на индекс, вы можете извлечь один символ из строки. Для этого индекс помещается в квадратные скобки. Объявите строку и попробуйте извлечь один из её символов.
Когда вы ссылаетесь на конкретный индекс, Python возвращает символ, которому этот индекс принадлежит. Символ t в строке 8host Blog! имеет индекс 4.
Выбор символа по отрицательному индексу
К примеру, у вас есть очень длинная строка. Чтобы точно определить её конец, можно начать счёт в обратном порядке, начиная с конца строки и индекса -1.
К примеру, строка 8host Blog!будет иметь следующий негативный индекс:
| 8 | h | o | s | t | B | l | o | g | ! | |
| -11 | -10 | -9 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
Запросите символ с отрицательным индексом -9:
Отрицательный индекс позволяет выбрать символ в длинной строке.
Повторение строк
Однажды у вас могут возникнуть обстоятельства, при которых вы захотите использовать Python для автоматизации некоторых задач. И одной из таких задач может стать многократное повторение строки в тексте. Для того чтобы это осуществить, потребуется воспользоваться оператором , который, как и оператор , отличается от . При использовании с одной строкой и одним числом становится оператором повторения, а не умножения. Он лишь повторяет заданный текст указанное число раз.
Давайте выведем на экран 9 раз с помощью оператора .
print("Sammy" * 9)
SammySammySammySammySammySammySammySammySammy
Таким образом, с помощью оператора повторения мы можем сколь угодно клонировать нужный нам текст.