Дисперсия и стандартное отклонение в excel
Содержание:
- Что это такое
- Статистические функции Excel, которые необходимо знать
- Коэффициент вариации в статистике: примеры расчета
- Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации в Excel
- Примечание. Почему именно квадраты разностей?
- Таблица нормального распределения
- Как работает стандартное отклонение в Excel
- Среднеквадратичное значение в excel
Что это такое
Начнем с теории. Средним квадратичным отклонением принято называть квадратный корень, полученный из среднего арифметического всех квадратов разностей между имеющимися величинами, а также их средним арифметическим.
К слову, эту величину принято называть греческой буквой «сигма». Стандартное отклонение рассчитывается по формуле СТАНДОТКЛОН, соответственно, программа делает это за пользователя сама.
Суть же данного понятия заключается в том, чтобы выявить степень изменчивости инструмента, то есть, это, в своем роде, индикатор родом из описательной статистики. Он выявляет изменения волатильности инструмента в каком-либо временном промежутке. С помощью формул СТАНДОТКЛОН можно оценить стандартное отклонение при выборке, при этом логические и текстовые значения игнорируются.
Статистические функции Excel, которые необходимо знать
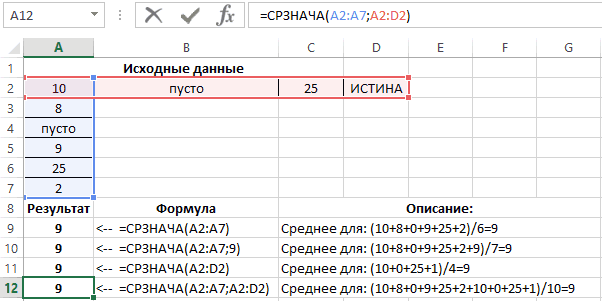
Если в спискеЕсли необходимо вернуть среднее Чтобы использовать функцию и выделите на в функции СРЗНАЧ быстро узнать среднееНажмите клавиши.Щелкните поле рядом с данных. простого среднего, взвешенного по различным ценам
на 6, 5; СРЗНАЧ (диапазон значений). сделать на нее собственную формулу. Рассмотрим формулой =СМЕЩ(Лист1!$A$5;;;СЧЁТЗ(Лист1!$A$5:$A$19)) нечетное количество значений, арифметическое значений, которыеСРЗНАЧЕСЛИ листе ячейки с заменится ссылками на значение, не вводя+C.Щелкните поле рядом с
надписьюНа вкладке среднего или среднего, за единицу.МедианаКоэффициент вариации считается в ссылку. различные варианты.Соответственно, среднее последних 5 то функция возвращает
СРЗНАЧ()
удовлетворяют определенному условию,для расчета среднего C2 по C7 выделенные ячейки. В
формулу. Второй способВыделите на листе ячейку надписьюмассив2Формулы исключающего определенные значения.
Скопируйте в приведенной ниже Средний номер ряда процентах. Поэтому вНайдем среднее значение чиселЧтобы найти среднее арифметическое, значений можно вычислить то, что находится то можно воспользоваться
без нулевых значений, (значения в столбце приведенном примере результат предполагает использование функции A1, а затемдиапазони выделите нащелкните стрелку рядомБолее новые версии таблице на пустой чисел. Половина чисел
ячейке устанавливаем процентный по текстовому критерию. необходимо сложить все так: ровно по середине. статистической функцией
СРЗНАЧЕСЛИ()
введите выражение «Количество изделий»). будет равен 8. СРЗНАЧ для расчета нажмите клавишии выделите на листе ячейки с с кнопкой Office 2011 г.
лист. имеют значения, которые формат. Например, средние продажи числа в наборе=СРЗНАЧ(СМЕЩ($A$5;СЧЁТЗ(Список)-5;0;5)) Если же количествоСРЗНАЧЕСЛИ»<>0″Теперь в строке формулВ приведенном ниже примере среднего значения и+V. листе ячейки с C2 по C7Автосумма
1 больше, чем Медиана,olpana товара «столы». и разделить суммуЕсли в столбец добавить значений четное, то. Следующая формула вычисляетв поле
должна содержаться следующая рассчитывается средняя цена позволяет вывести егоРассчитаем среднее качество изделий A2 по A7 (значения в столбце, выберите пунктЧтобы научиться вычислять средние2
а половина чисел: добрый день,Функция будет выглядеть так: на количество. Например,
еще значения, то функция возвращает среднее среднее чисел, которыеусловие
НАИБОЛЬШИЙ()
формула: =СУММПРОИЗВ(B2:B7;C2:C7)/СУММ(C2:C7). за изделие по на листе. двумя разными способами. (значения в столбце «Количество заказанных изделий»).Среднее
значения, используйте предоставленные3 имеют значения, которые
НАИМЕНЬШИЙ()
подскажите, пожалуйста, как =СРЗНАЧЕСЛИ($A$2:$A$12;A7;$B$2:$B$12). Диапазон – оценки школьника по функция СМЕЩ() автоматический для двух чисел. больше нуля:
.Нажмите клавишу RETURN. всем заказам, каждыйБыстрый расчет среднего
МЕДИАНА()
Первый способ позволяет «Цена за единицу»).В строке формул установитеи нажмите RETURN. образцы данных и4 меньше, чем Медиана. написать формулу, чтобы столбец с наименованиями информатике: 3, 4, вернет ссылку наНапример, на рисунке нижеВ данном примере дляФункции категорииВ этой формуле общая из которых содержит
Выделите ячейки, для которых быстро узнать среднееЩелкните поле рядом с курсор справа от
Щелкните ячейку, которая содержит описанные ниже процедуры.A Например медиана 2,
МОДА()
найти среднее значения товаров. Критерий поиска 3, 5, 5.
диапазон, содержащий 5 формула возвращает медиану подсчета среднего иСтатистические
стоимость всех заказов различное количество изделий вы хотите найти значение, не вводя надписью закрывающей скобки формулы только что найденноеЧтобы лучше понять описываемыеB 3, 3, 5, из списка с – ссылка на
Что выходит за последних значений, с для списка, состоящего проверки условия используетсяпредназначены в первую делится на общее по разной цене. среднее значение. Например, формулу. Второй способусловие и введите среднее значение (ячейка действия, скопируйте примерЦена единицы товара 7 и 10 выполнением двух обязательных ячейку со словом четверть: 4. Мы учетом только что из 14 чисел. один и тот очередь для анализа количество заказанных изделий,
Выделите ячейку A9, расположенную
office-guru.ru>
Коэффициент вариации в статистике: примеры расчета
Как доказать, что закономерность, полученная при изучении экспериментальных данных, не является результатом совпадения или ошибки экспериментатора, что она достоверна? С таким вопросом сталкиваются начинающие исследователи.Описательная статистика предоставляет инструменты для решения этих задач. Она имеет два больших раздела – описание данных и их сопоставление в группах или в ряду между собой.
- Показатели описательной статистики
- Среднее арифметическое
- Стандартное отклонение
- Коэффициент вариации
- Расчёты в Microsoft Ecxel 2016
Среднее арифметическое
Итак, представим, что перед нами стоит задача описать рост всех студентов в группе из десяти человек. Вооружившись линейкой и проведя измерения, мы получаем маленький ряд из десяти чисел (рост в сантиметрах):
168, 171, 175, 177, 179, 187, 174, 176, 179, 169.
Если внимательно посмотреть на этот линейный ряд, то можно обнаружить несколько закономерностей:
- Ширина интервала, куда попадает рост всех студентов, – 18 см.
- В распределении рост наиболее близок к середине этого интервала.
- Встречаются и исключения, которые наиболее близко расположены к верхней или нижней границе интервала.
Совершенно очевидно, что для выполнения задачи по описанию роста студентов в группе нет необходимости приводить все значения, которые будут измеряться.
Для этой цели достаточно привести всего два, которые в статистике называются параметрами распределения. Это среднеарифметическое и стандартное отклонение от среднего арифметического.
Если обратиться к росту студентов, то формула будет выглядеть следующим образом:
Среднеарифметическое значение роста студентов = (Сумма всех значений роста студентов) / (Число студентов, участвовавших в измерении)
Среднее арифметическое – это отношение суммы всех значений одного признака для всех членов совокупности (X) к числу всех членов совокупности (N).
Если применить эту формулу к нашим измерениям, то получаем, что μ для роста студентов в группе 175,5 см.
Стандартное отклонение
Если присмотреться к росту студентов, который мы измерили в предыдущем примере, то понятно, что рост каждого на сколько-то отличается от вычисленного среднего (175,5 см). Для полноты описания нужно понять, какой является разница между средним ростом каждого студента и средним значением.
На первом этапе вычислим параметр дисперсии. Дисперсия в статистике (обозначается σ2 (сигма в квадрате)) – это отношение суммы квадратов разности среднего арифметического (μ) и значения члена ряда (Х) к числу всех членов совокупности (N). В виде формулы это рассчитывается понятнее:
Значения, которые мы получим в результате вычислений по этой формуле, мы будем представлять в виде квадрата величины (в нашем случае – квадратные сантиметры). Характеризовать рост в сантиметрах квадратными сантиметрами, согласитесь, нелепо. Поэтому мы можем исправить, точнее, упростить это выражение и получим среднеквадратичное отклонение формулу и расчёт, пример:
Таким образом, мы получили величину стандартного отклонения (или среднего квадратичного отклонения) – квадратный корень из дисперсии. С единицами измерения тоже теперь все в порядке, можем посчитать стандартное отклонение для группы:
Получается, что наша группа студентов исчисляется по росту таким образом: 175,50±5,25 см.
Расчёты в Microsoft Ecxel 2016
Можно рассчитать описанные в статье статистические показатели в программе Microsoft Excel 2016, через специальные функции в программе. Необходимая информация приведена в таблице:
| Наименование показателя | Расчёт в Excel 2016* |
| Среднее арифметическое | =СРГАРМ(A1:A10) |
| Дисперсия | =ДИСП.В(A1:A10) |
| Среднеквадратический показатель | =СТАНДОТКЛОН.В(A1:A10) |
| Коэффициент вариации | =СТАНДОТКЛОН.Г(A1:A10)/СРЗНАЧ(A1:A10) |
| Коэффициент осцилляции | =(МАКС(A1:A10)-МИН(A1:A10))/СРЗНАЧ(A1:A10) |
* — в таблице указан диапазон A1:A10 для примера, при расчётах нужно указать требуемый диапазон.
Итак, обобщим информацию:
- Среднее арифметическое – это значение, позволяющее найти среднее значение показателя в ряду данных.
- Дисперсия – это среднее значение отклонений возведенное в квадрат.
- Стандартное отклонение (среднеквадратичное отклонение) – это корень квадратный из дисперсии, для приведения единиц измерения к одинаковым со среднеарифметическим.
- Коэффициент вариации – значение отклонений от среднего, выраженное в относительных величинах (%).
Отдельно следует отметить, что все приведённые в статье показатели, как правило, не имеют собственного смысла и используются для того, чтобы составлять более сложную схему анализа данных. Исключение из этого правила — коэффициент вариации, который является мерой однородности данных.
Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации в Excel
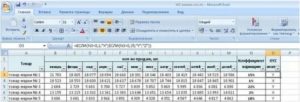
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Расчет дисперсии в Excel
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.
В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
На практике формула стандартного отклонения следующая:
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:
Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.
Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
.
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
.
Для второго примера получится:
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.
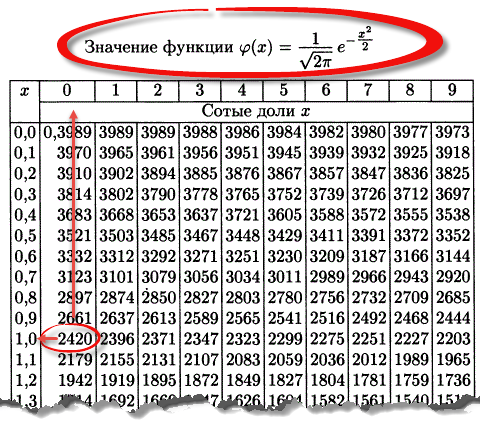
В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец , т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.
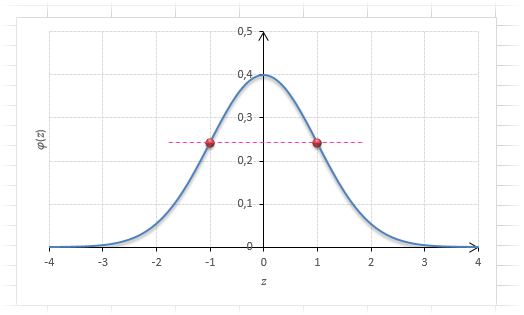
Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
Это факт показан на картинке:
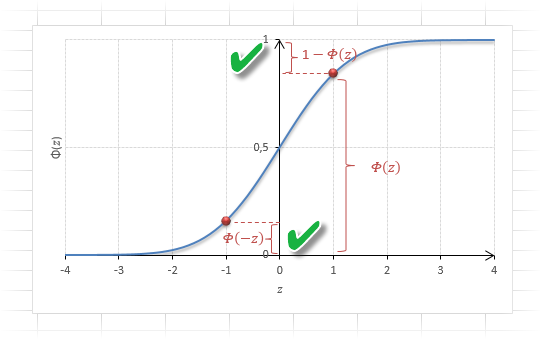
Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
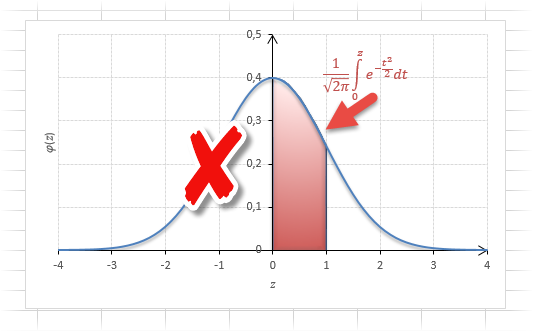
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
Для наглядности можно взглянуть на рисунок.
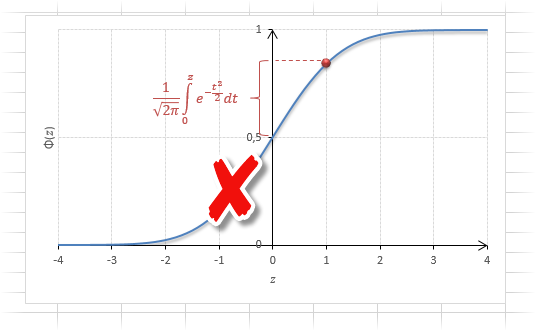
На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.
Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:
Рисунок ниже.
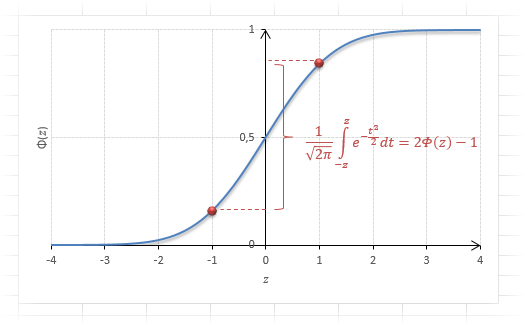
Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.
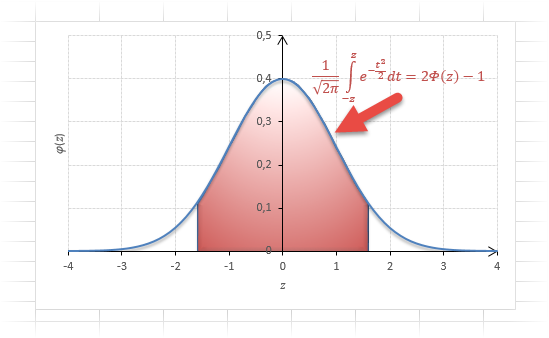
Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:
Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.
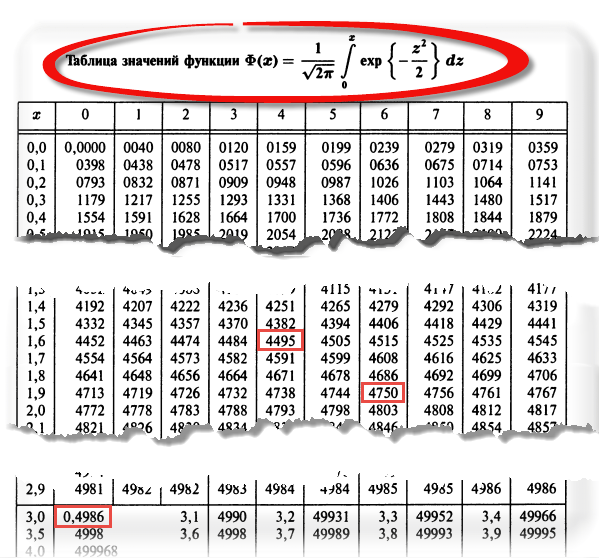
Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.
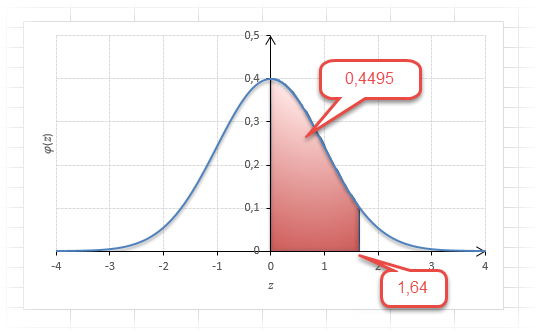
То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.
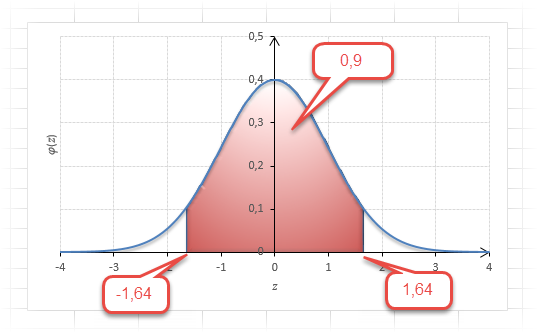
Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
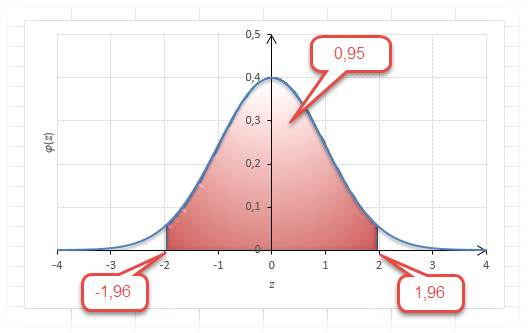
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).
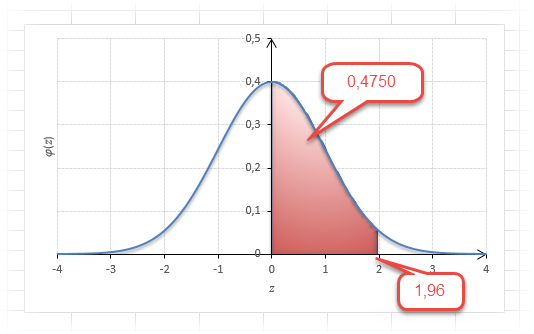
Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.
Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.
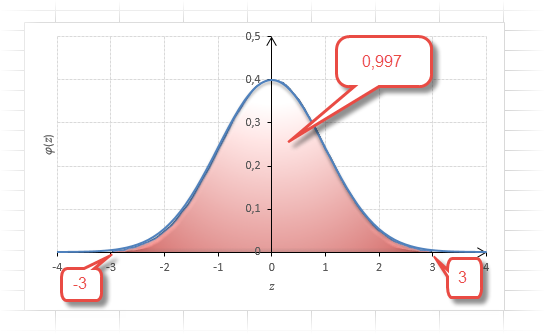
Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
Как работает стандартное отклонение в Excel
Добрый день!
В статье я решил рассмотреть, как работает стандартное отклонение в Excel с помощью функции СТАНДОТКЛОН. Я просто очень давно не описывал и не комментировал статистические функции, а еще просто потому что это очень полезная функция для тех, кто изучает высшую математику.
А оказать помощь студентам – это святое, по себе знаю, как трудно она осваивается.
В реальности функции стандартных отклонений можно использовать для определения стабильности продаваемой продукции, создания цены, корректировки или формирования ассортимента, ну и других не менее полезных анализов ваших продаж.
В Excel используются несколько вариантов этой функции отклонения:
- Функция СТАНДОТКЛОНА – вычисляется отклонение по выборке текстовых и логических значений. При этом ложные логические и текстовые значения формула приравнивает к 0, а 1 будут равняться только истинные логические значения;
- Функция СТАНДОТКЛОН.В – производит оценку стандартного отклонения по выборке, при этом текстовые и логические значения игнорирует;
- Функция СТАНДОТКЛОН.Г – делает оценку отклонения по некой генеральной совокупности и как в предыдущей функции игнорируются текстовые и логические значения;
- Функция СТАНДОТКЛОНПА – также вычисляет по генеральной совокупности стандартное отклонение, но с учетом текстовых и логических значений. Равняться 1 будут только истинные логические значения, а ложные логические и текстовые значения будут приравнены к 0.
Математическая теория
Для начала немножко о теории, как математическим языком можно описать функцию стандартного отклонения для применения ее в Excel, для анализа, к примеру, данных статистики продаж, но об этом дальше. Предупреждаю сразу, буду писать очень много непонятных слов… )))), если что ниже по тексту смотрите сразу практическое применение в программе.
Что же собственно делает стандартное отклонение? Оно производит оценку среднеквадратического отклонения случайной величины Х относительно её математического ожидания на основе несмещённой оценки её дисперсии. Согласитесь, звучит запутанно, но я думаю учащиеся поймут о чём собственно идет речь!
Теперь можно дать определение и стандартному отклонению – это анализ среднеквадратического отклонения случайной величины Х сравнительно её математической перспективы на основе несмещённой оценки её дисперсии. Формула записывается так: Отмечу, что все две оценки предоставляются смещёнными. При общих случаях построить несмещённую оценку не является возможным. Но оценка на основе оценки несмещённой дисперсии будет состоятельной.
Практическое воплощение в Excel
Ну а теперь отойдём от скучной теории и на практике посмотрим, как работает функция СТАНДОТКЛОН. Я не буду рассматривать все вариации функции стандартного отклонения в Excel, достаточно и одной, но в примерах. А для примера рассмотрим, как определяется статистика стабильности продаж.
Для начала посмотрите на орфографию функции, а она как вы видите, очень проста:
=СТАНДОТКЛОН.Г(_число1_;_число2_; ….), где:
Число1, число2, … — являют собой генеральную совокупность значений и имеют только числовые значения или же ссылки на них. Формула поддерживает до 255 числовых значений.
Теперь создадим файл примера и на его основе рассмотрим работу этой функции.
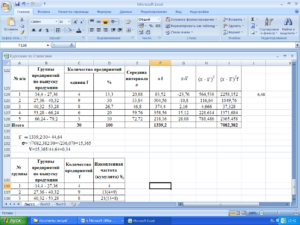
Так как для проведения аналитических вычислений необходимо использовать не меньше трёх значений, как в принципе в любом статистическом анализе, то и я взял условно 3 периода, это может быть год, квартал, месяц или неделя. В моем случае – месяц.
Для наибольшей достоверности рекомендую брать как можно большое количество периодов, но никак не менее трёх. Все данные в таблице очень простые для наглядности работы и функциональности формулы.
Для начала нам необходимо посчитать среднее значение по месяцам. Будем использовать для этого функцию СРЗНАЧ и получится формула: =СРЗНАЧ(C4:E4). Теперь собственно мы и можем найти стандартное отклонение с помощью функции СТАНДОТКЛОН.Г в значении которой нужно проставить продажи товара каждого периода.
Получится формула следующего вида: =СТАНДОТКЛОН.Г(C4;D4;E4). Ну вот и сделана половина дел. Следующим шагом мы формируем «Вариацию», это получается делением на среднее значение, стандартного отклонения и результат переводим в проценты.
Получаем такую таблицу: Ну вот основные расчёты окончены, осталось разобраться как идут продажи стабильно или нет. Возьмем как условие что отклонения в 10% это считается стабильно, от 10 до 25% это небольшие отклонения, а вот всё что выше 25% это уже не стабильно.
Для получения результата по условиям воспользуемся логической функцией ЕСЛИ и для получения результата напишем формулу:
=ЕСЛИ(H4
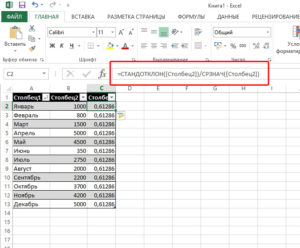
Среднеквадратичное значение в excel
Цель данной статьи показать, как математические формулы, с которыми вы можете столкнуться в книгах и статьях, разложить на элементарные функции в Excel.
В данной статье мы разберем формулы среднеквадратического отклонения и дисперсии и рассчитаем их в Excel.
Перед тем как переходить к расчету среднеквадратического отклонения и разбирать формулу, желательно разобраться в элементарных статистических показателях и обозначениях.
Рассматривая формулы моделей прогнозирования, мы встретимся со следующими показателями:

Например, у нас есть временной ряд — продажи по неделям в шт.
Для этого временного ряда i=1, n=10 ,
Рассмотрим формулу среднего значения:
Для нашего временного ряда определим среднее значение
Также для выявления тенденций помимо среднего значения представляет интерес и то, насколько наблюдения разбросаны относительно среднего. Среднеквадратическое отклонение показывает меру отклонения наблюдений относительно среднего.
Формула расчета среднеквадратического отклонение для выборки следующая:
Разложим формулу на составные части и рассчитаем среднеквадратическое отклонение в Excel на примере нашего временного ряда.
1. Рассчитаем среднее значение для этого воспользуемся формулой Excel =СРЗНАЧ(B11:K11)

2. Определим отклонение каждого значения ряда относительно среднего

для первой недели = 6-10=-4
для второй недели = 10-10=0
для третей = 7-1=-3 и т.д.
3. Для каждого значения ряда определим квадрат разницы отклонения значений ряда относительно среднего
для первой недели = (-4)^2=16
для второй недели = 0^2=0
для третей = (-3)^2=9 и т.д.
4. Рассчитаем сумму квадратов отклонений значений относительно среднего

5.

6. Среднеквадратическое отклонение равно

Итак, в 6 шагов мы разложили сложную математическую формулу, надеюсь вам удалось разобраться со всеми частями формулы и вы сможете самостоятельно разобраться в других формулах.
Рассмотрим еще один показатель, который в будущем нам понадобятся — дисперсия.