Cемантическое ядро сайта
Содержание:
- Этап 2. Сбор и чистка семантического ядра в Key Collector
- Этап 1. Кластеризация
- Что такое семантическое ядро сайта
- Семантическое проектирование структуры нового сайта
- Очистка СЯ от «мусора»
- Автоматические сервисы поиска конкурентов
- Группы ключевых слов
- Онлайн-сервисы
- Виды поисковых запросов
- Автоматический сбор семантического ядра онлайн
Этап 2. Сбор и чистка семантического ядра в Key Collector
Перед началом сбора семантического ядра необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если ваш магазин находится в Москве, то и запросы с их частотностью нужно собирать по данному региону. Для этого в нижней части окна мы выбираем регион для сервисов Yandex.Wordstat и Яндекс Директ:

После выбора региона можно приступать к сбору семантики.
Методика
В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:

В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:

После нажатия на кнопку в правой колонке групп мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:

Запустив парсинг левой колонки Yandex.Wordstat, мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса Yandex.Wordstat, нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:

Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:

Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточненную» частотность, после чего нажимаем кнопку «Получить данные»:
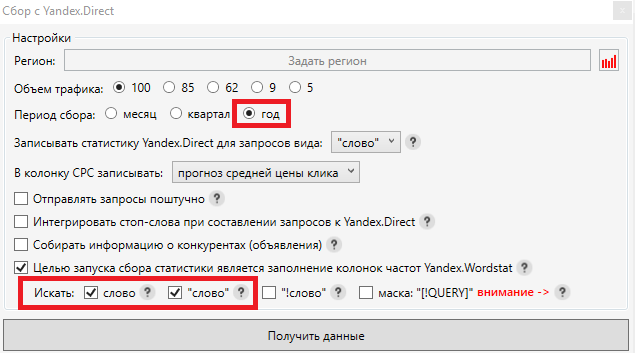
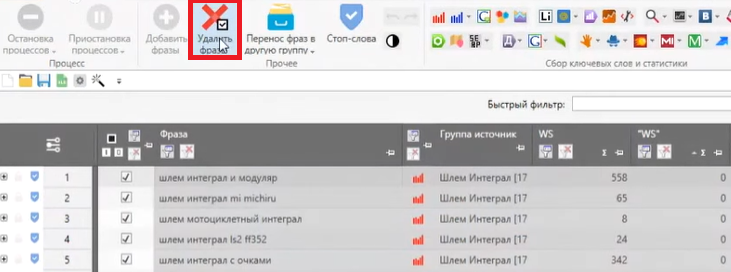
Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:
Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
1. Инструмент фильтрации позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
2. Инструмент «Стоп-слова» позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
3. Инструмент «Анализ групп» позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.
Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находится во вкладке «Данные»:

Во всплывающим окне можно увидеть несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице и не случится того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придется искать позже вручную в общем списке запросов.

Просматривая группы одну за другой, отмечаем их или фразы внутри них, которые явно нам не подходят. В процессе мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:

После того как отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».
После чего следует перейти к выгрузке запросов в Excel для последующей ручной чистки запросов и группировки семантики.
Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:
Этап 1. Кластеризация
Кластеризация — это группировка ключевых фраз на основе схожести результатов поисковой выдачи по ним.
В отличие от группировки на основе семантической близости, кластеризация позволяет избежать ошибок, связанных с размещением на одной странице запросов с разным интентом.
Например, фразы «картина для спальни купить» и «картины для спальни» при группировке на основе семантики наверняка бы попали в одну группу. Но если посмотреть на поисковую выдачу по ним, то она окажется разной.
Для кластеризации есть онлайн-сервисы (Just Magic, PixelPlus, PromoPult и др.) и десктопные программы (KeyAssort, KeyCollector). Работают они по похожему принципу (разве что в KeyCollector кластеризация требует специфической подготовки): загружаете список запросов, указываете регион, точность кластеризации и получаете сгруппированное ядро.
При кластеризации особенно важно задать правильную точность — количество совпадений результатов выдачи в ТОП-10, при котором фразы попадают в одну группу. Например, при точности 3 запросы попадут в один кластер, если в выдаче по ним будет три и более одинаковых результата
Если точность низкая, то кластеры получаются слишком обширными, а если высокая, то ядро может быть излишне раздроблено.
Чтобы не гадать и не переплачивать за лишние итерации, удобнее всего задать точность диапазоном. В этом случае вы получите несколько кластеризованных ядер, но заплатите только один раз. Такая функция есть в кластеризаторе PromoPult. Задаем точность от 3 до 7, устанавливаем приоритетную поисковую систему, регион и запускаем процесс:
Загружаем отчет и сравниваем результаты кластеризации при разной точности. Наша задача — выбрать «золотую середину», чтобы кластеры были и не слишком обширными, и не раздробленными. В нашем примере оптимальной видится точность 6.
Например, есть кластеры «деревянные подсвечники» и «купить свечи в интернет магазине». Мы не можем размещать эти кластеры на одной странице — у них разный интент. Но на сайте товарные группы с такими названиями расположены как раз на одной странице, что с точки зрения оптимизации неверно.
Логика подсказывает: почему бы просто не создать раздел «Свечи» и оптимизировать его под кластер «свечи купить», а раздел «Подсвечники, канделябры, свечи» переименовать в «Подсвечники» и оптимизировать под «деревянные подсвечники»?
Но все не так просто: а что делать с другими кластерами вроде «подсвечник в подарок»? Размещать в разделе «Подсвечники»? Или «Праздники»? Или еще каком-то? И таких кластеров около 200 — и каждый из них по-своему «проблемный».
Что такое семантическое ядро сайта
Начнем с определения:
Обратите внимание, что есть прямая взаимосвязь между ключами и страницами сайта: каждому слову/фразе должна быть сопоставлена одна конкретная страница (URL). Само собой, один URL может быть связан с несколькими ключами
Какое количество ключевых слов должно быть для одной страницы? Есть общая рекомендация, чтобы одной странице соответствовало не более 10 ключей. Но такой подход не всегда работает. Если у вас есть 20 или 30 ключей, которые по смыслу подходят строго к одной странице и разделение их на две страницы будет нелогичным, то не нужно «переоптимизировать» сайт и создавать две страницы с фактически одинаковым содержанием под похожие ключи.
Разрабатывая семантическое ядро и впоследствии структуру сайта, помните о следующих моментах:
- страница должна соответствовать ожиданиям посетителя;
- страница сайта = решение проблемы человека;
- сайт должен давать ответы на максимальное количество запросов по тематике;
- полная семантика сайта = структура сайта.

Семантическое проектирование структуры нового сайта
Делаются те же этапы, за исключением 0 и 5 шага.
Тут важен в первую очередь анализ конкурентов в выбранной нише.
Если вы только проектируете сайт, важно проанализировать структуру у конкурентов — вплоть до того по каким принципам идет построение URL страниц сайта.
Анализируя ТОП наиболее релевантных сайтов по большому спектру запросов можно понять какие потребности, они закрывают перед посетителями
Обратите внимание на такие вещи:
- Наличие отзывов и формы для их отправки;
- Наличие видео, аудио, фото и другого медиаконтента;
- Объем текста и его расположение вверху, снизу, в центре;
- Наличие структурированной информации: заголовки, подзаголовки, списки и другие юзабилити-элементы;
- Проверьте наличие блоков перелинковки на таких страницах — по каким принципам и алгоритмам строятся рекомендации;
- Есть ли интерактивный контент, который решает основные задачи (калькуляторы, специальные формы и другие удерживающие на странице элементы);
- Всмотритесь получше в конкурентов и выпишите все свои замечание по каждому типу страниц — это поможет при проектировании сайта.
Опыт в следующих тематиках
Имеется опыт работы с семантикой и наработки в тематиках:
- SEO и различные направления интернет-маркетинга;
- Разработка сайтов и веб-дизайн;
- Ремонт квартир и интерьер;
- Кухни и различная мебель;
- Животные (коммерческие и информационные);
- Инструменты;
- Образование;
- И многие другие…
Обновлено: 04.08.2020
6486
Очистка СЯ от «мусора»
Покажем, как это делать в Key Collector.
Ключевики, которые содержат ненужные слова
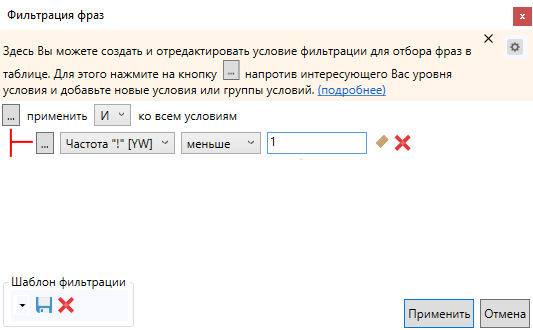
Нажимаем вкладку выбора условий фильтрации:

Задаем условие, как указано на скриншоте, и пишем слова:
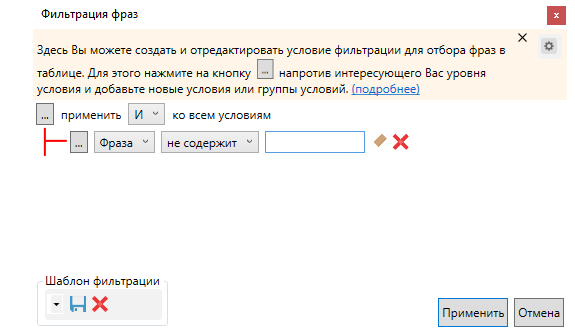
Отмечаем фразы и добавляем в корзину:
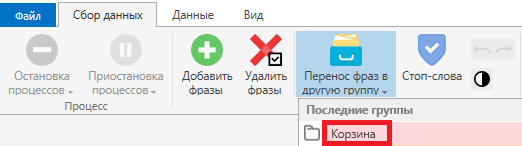
Повторы слов
Аналогично вызываем настройки фильтрации фраз и выбираем такой вариант:
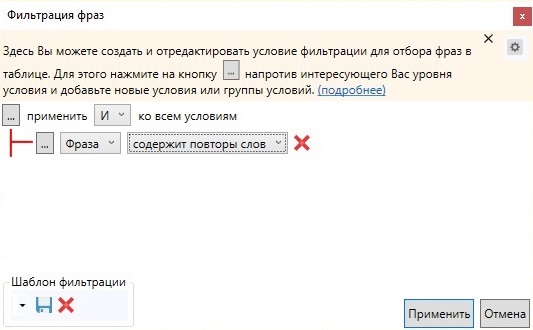
Стоп-слова (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.)
Нажимаем этот значок в верхнем меню:

В окне настроек добавляем фразы (1) и разбиваем по группам (2):
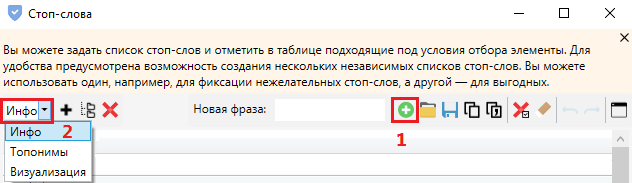
Далее — выделяем слова в таблице галочкой и добавляем в список стоп-слов.
Группы слов
Чтобы разбить запросы на группы, на вкладке «Данные» открываем «Анализ групп». В окне выбираем тип «По отдельным словам»:

Выбранные группы появятся в основном списке запросов, где можно отсеять все ненужные.
Запросы с нулевой частотностью
Выбираем следующее условие фильтрации:

Далее — требования по частоте:
Можно удалить нецелевые запросы и вручную: копируем ключевики в Word. Заменяем пробел на знак абзаца, чтобы представить все слова из словосочетаний в виде колонки. Переносим обратно в Excel на отдельный лист, сортируем и определяем минус-слова. Затем находим с помощью фильтра фразы с ними и удаляем.
На какие вопросы машинный интеллект не дает ответы
Сбор семантики быстрее и проще с помощью различных сервисов, баз, приложений — благо, выбор есть. Однако нельзя слепо полагаться на автоматизацию. Есть два случая, когда без ручного труда не обойтись. Уже при подборе масок нужно «вытаскивать» синонимы и переформулировки из сайтов заказчика и конкурентов, правой колонки Wordstat, собственных идей и т.д. Мы увидели, что это всё предстоит делать специалисту по контекстной рекламе. Самый трудозатратный и не автоматизируемый процесс — очистка СЯ от «мусора». Готовых минус-списков и данных об отказах из Яндекс.Метрики недостаточно для 100% точности. Приходится смотреть предварительные списки и выявлять смысловое соответствие результатов бизнесу. Особенно это касается сложных продуктов. Например, подготовка сжатого воздуха, или осушка воздуха. Больше расширений можно насобирать по слову «осушка». Но среди результатов в Wordstat в мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Не всегда семантическое соответствие гарантирует смысловое соответствие. Это разные продукты, а значит, разный спрос. Чаще всего выявить и исключить его можно только вручную. Если вы не проверяете результаты парсинга, вы жертвуете полнотой СЯ и точностью будущих рекламных кампаний. Совет: выбирайте оптимальный баланс «трудозатраты — полнота» и делайте полный список минус-слов.
Автоматические сервисы поиска конкурентов
При автоматическом подборе с помощью сервисов поиска конкурентов выбор сайтов строится на количестве общих ключевых слов, релевантности и видимости сайтов. Эти параметры рассчитываются на основе встроенных алгоритмов сервисов, их баз данных запросов и позиций сайтов.
Стоит уточнить, что если у сайта плохие позиции, плохо вписаны или вообще нет нужных запросов на страницах сайта, то и конкуренты будут не совсем релевантные. Такие способы больше подходят для сайтов с более-менее существенной видимостью и позициями.
И снова Топвизор
Внимательный читатель заметил, что в статье указано 11 способов, но перечислено всего 10 сервисов.
В январе этого года Топвизор запустили на альфа-тестирование новый инструмент для сравнительного анализа конкурентов https://topvisor.com/competitors/

Подключается только через техническую поддержку сервиса. Для подбора сайтов для последующего анализа подходит отлично. Сейчас запущен полноценный функционал, но иногда бывают баги.Стоит намного меньше, чем сбор позиций со снимками выдачи.

Нужно выбрать поисковую систему и ввести адрес сайта.Стоимость отчёта обычно в пределах 50–100 рублей, можно выбрать глубину степени подбора конкурентов, но чем глубже — тем дороже.
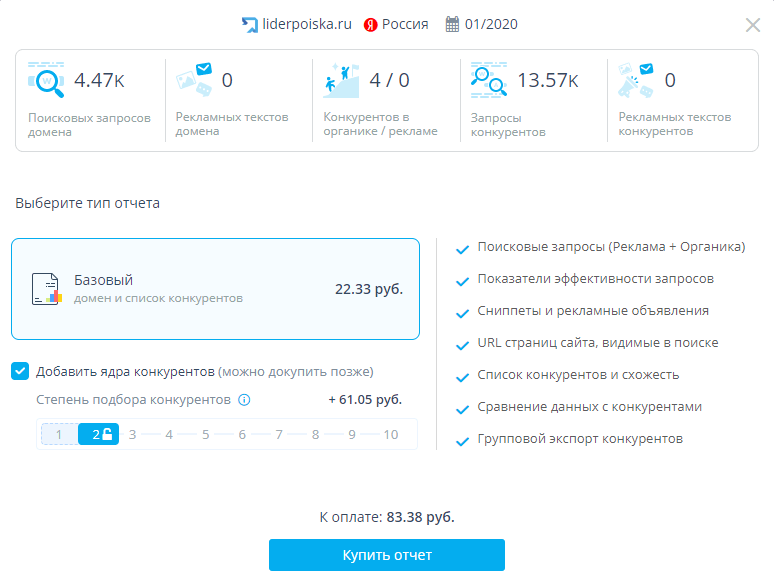
На вкладке «Конкуренты» мы можем увидеть список доменов пересекающихся по запросам из базы Топвизора. Можно отфильтровать результаты по степени конкурентности.

Нужные нам показатели:
- Конкурентность.
- Обратная конкурентность.
- Схожесть. Определяется количеством общих запросов. Чем их больше, тем больше схожесть.
Если сделать сортировку по обратной конкурентности, то сразу будет список близких конкурентов по сайту с учётом большего числа общих запросов, наиболее близкие по тематике. В прямой конкурентности могут быть компании, которые пересекаются с нами по поисковым фразам, но для них это лишь часть услуг или товаров и сам сайт намного больше.
Сервис также позволяет провести анализ пересекающихся и уникальных поисковых запросов. Но пока наша цель — подобрать список сайтов конкурентов для последующего анализа.
Serpstat
Даже без регистрации Серпстат позволяет получить анализ данных по конкурентам.Вбиваете интересующий домен, выбираете систему и регион. К сожалению, по регионам ограниченный выбор, поэтому если сайт региональный — этот способ может быть неточным, так как если нет вашего региона, придётся делать поиск по России.

В полученном окне нужно пролистать до блока «Конкуренты в поисковой выдаче».

Здесь же можно посмотреть ключевые фразы конкурентов, которые подобрала система.
Ahrefs
Для использования сервиса потребуется профиль с оплаченным тарифом.Здесь нужен инструмент Site Explorer.

Вбиваем домен, в блоке «Органическая выдача» находим «Competing domains» он же «Конкурирующие домены».
Аналогично можно проверять отдельные страницы, или просмотреть «Страницы-конкуренты», где будут показаны конкретные URL-адреса посадочных страниц.
Результат поиска можно отсортировать по количеству общих ключевых фраз.

Similarweb
Бесплатный, но не самый лёгкий способ — для проверки нужна регистрация, при которой нужно давать доступ к Google аналитике своего профиля, отвечать на вопросы в анкете, подтверждать данные.Но если пройти все этапы регистрации, можно получить базовый набор инструментов и получить примерные данные по многим сайтам.

Один из доступных без подписки инструментов «Competitive Landscape» — Конкурентная среда.
К сожалению, без оплаченного доступа позволяет посмотреть только первые 5 сайтов, но в некоторых случаях и этого достаточно.

Pr-cy.ru
Один из базовых сервисов для сбора аналитики.Без регистрации можно проверить сайт и в блоке «Похожие сайты» найти своих конкурентов.

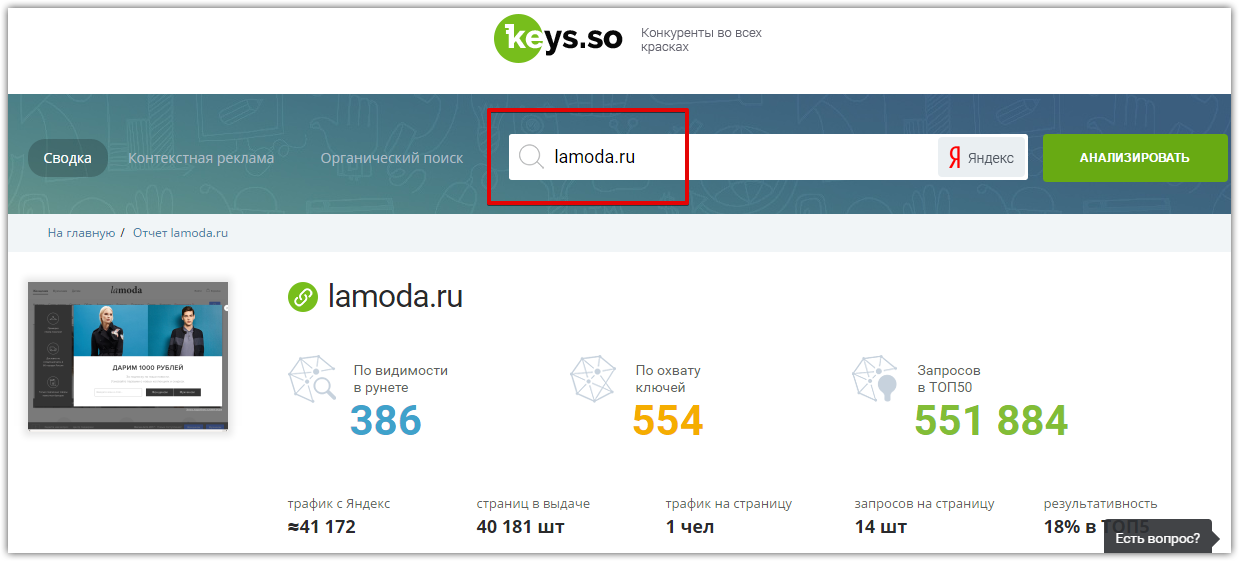
Keys.so
Базовый аудит доступен без регистрации. Как и другие сервисы, собирает основные данные по сайту.

Блок «Конкуренты» один из первых, перейдя в него, получаем расширенную информацию по похожести, тематичности и количеству общих запросов.

Опрос заказчика
Не стоит забывать про владельца сайта или бизнеса — он знает процессы изнутри, знает ближайших конкурентов в оффлайне, и процентов на 75 это компании, которые мы увидим в ТОПе. Спросить — не лишнее, тем более это быстро, просто и бесплатно.
Если это собственный сайт и вы разбираетесь в нише в которой работаете, то у вас уже есть понимание, кто ваши ближайшие соперники. В таком случае, все перечисленные способы помогут понять, на кого стоит ориентироваться, ведь если компания успешна в оффлайне, это не обязательно говорит о том, что она успешна в сети, и наоборот.
Группы ключевых слов
Все ключевые слова семантического ядра можно разделить на группы. Классифицировать можно по частотности, геозависимости и коммерческим показателям. Давайте рассмотрим каждый вариант.
Частота ключевых слов
Частотностью ключевых слов называют количество поисковых запросов, связанных с каким-то конкретным ключом. Этот фактор определяет как много людей (и как часто) ищут что-то, используя те или иные словосочетания. Различают следующие кластеры:
- Высокочастотные запросы (ВЧ) – наиболее популярные ключевые слова в поисковых системах.
- Среднечастотные (СЧ) – менее популярные ключевики. Что-то вроде золотой середины.
- Низкочастотные (НЧ) – ключевые слова, с которыми обращаются в поисковик не так уж часто.
- Микронизкочастотные (МНЧ) – когда запросов почти нет, раз-два и обчелся.
Продвижение по каждому из кластеров может сильно отличаться. Причем не только по сложности. Если вы хотите узнать, как отличить ВЧ запрос от СЧ, или наоборот, то я предлагаю вам присмотреться к одному из самых распространенных вариантов в Рунете:
- ВЧ – от 10 000 запросов в месяц;
- СЧ – от 1 000 до 10 000;
- НЧ – от 100 до 1 000;
- МНЧ – менее 100.
Не могу утверждать, что это абсолютная истина. Многие SEO-специалисты устанавливают свои собственные референсы, исходя из личного опыта. Какому варианту верить – решайте сами. Однако должен уточнить, что эти цифры могут значительно меняться как в большую, так и в меньшую сторону. Особенно если мы говорим о продвижении по региональным запросам.
Коммерция
Помимо частотности ключевых слов, их можно разделить еще и на коммерческие и некоммерческие. Первые, понятное дело, представляют собой запросы, которые используются пользователями для поиска товаров или услуг с целью их дальнейшего приобретения. Вторые же, как правило, используются для поиска информации.
В свою очередь, запрос “Как установить Windows на ПК” можно отнести к некоммерческому запросу, т. к. человек просто ищет информацию по установке или эксплуатации своей машины.
Благодаря этому повышается конверсия (количество пользователей, выполнивших целевое действие, т. е. купивших товар или услугу), что в свою очередь повышает доходность проекта.
Геолокация
Местоположение человека, который осуществляет поиск в Яндексе или Гугле, тоже может быть очень важным фактором. К примеру, по запросу “Лучшие клубы города” жителям Москвы и Иваново будут показаны совершенно разные результаты. Это называется геозависимость запросов, когда таргетинг идет именно на расположение хоста (пользователя).
Если региональность вам действительно важна, то составлять СЯ стоит с учетом расположения, т. е. геолокации.
Как вы могли догадаться, по геолокации запросы могут делиться на зависимые и независимые.
Но вот по геонезависимым запросам можно действительно неплохо повысить конверсию. Например, если в дополнение к вашему магазину на проекте есть еще и информационный блог, где находятся полезные материалы по покупке тех или иных видов товаров, то пользователи, переходящие к вам с общих, независимых от геолокации ключевиков, смогут улучшить поведенческие факторы вашего сайта. Что в конечном итоге продвинет его выше, как по нужному региону, так и в целом.
Я думаю, что принцип работы региональности в поисковых системах не должен вызывать затруднений. Подытожив, можно сказать, что геолокация хоста может очень сильно влиять на выдачу
И если ваш сайт заточен под какой-то конкретный регион или группу регионов, то вам определенно стоит обратить внимание на этот фактор при составлении семантического ядра
Онлайн-сервисы
В остальном все работает просто: оплачиваете работу, вам выдают файлик с семантикой, который вы можете скачать и использовать.
Список онлайн-сервисов, которые занимаются сбором семантического ядра на заказ:
Семантика.Онлайн – одна из топовых контор, которая может сделать вам семантическое ядро. Многие известные компании работают с этим сервисом. Семантика.Онлайн давно зарекомендовала себя как профессионал своего дела. Тарифы, кстати говоря, там весьма доступные. Любой простой пользователь сможет позволить себе заказ семантического ядра у этой конторы.

На данный момент цена за одно ключевое слово составляет 2,5 рубля. Здесь же есть возможность заказать более тщательную ручную обработку и кластеризацию. В отличие от стандартной автоматической, ручная будет составляться опытными SEO-специалистами с полным погружением в тематику. В таком случае цена за ключ будет около 4,5 рублей. Дороже, но качественнее.
Сервис имеет большое количество положительных отзывов от разных вебмастеров. В основном это люди, для которых информационные сайты – бизнес, на котором они зарабатывают сотни тысяч рублей. Это не безликие комментарии, составленные самими администраторами сервиса. Все отзывы реальные, вы легко сможете проверить их авторов по социальным сетям.
Semantix.pro – еще один известный сервис, который занимается составлением семантического ядра на заказ. Можно рассматривать в качестве прямого конкурента или альтернативы Семантики.Онлайн. В среднем цены на услуги здесь выше. За один ключевой запрос вы должны будете заплатить 5 рублей по базовому тарифу и 10 – по более продвинутому.
Семантикс также имеет большое количество отзывов и рекомендаций. На сайте есть разделы с кейсами, где вы сможете видеть примерный процесс работы и результата.
В обоих случаях вы получите файл со сгруппированными ключевыми словами и заголовками статей (title).
Таких сервисов гораздо больше, но я решил вам показать самые популярные. Если они вам не нравятся, вы можете попробовать поискать другие. Но, должен предупредить, что при заказе услуг у непроверенных сервисов, вы рискуете нарваться на мошенников или дилетантов.
Виды поисковых запросов
Рассмотрим 3 типа параметров оценки ключей.
Первый – частность. В этой категории выделяют:
- Высокочастотные ключи – фразы, определяющие тему. Включают в себя 1–2 слова. Средний показатель количества поисковых запросов стартует от 1–3 тыс. в месяц и может достигать сотен тысяч показов в зависимости от тематики. Как правило, под них адаптируют главные страницы сайтов.
- Среднечастотные – самостоятельные направления в теме. Состоят обычно из 2–3 слов. Точная частотность – от 500 до 1000. Как правило, это категории коммерческого сайта или темы для крупных инфостатей.
- Низкочастотные – запросы, связанные с поиском конкретного ответа на вопрос. Чаще всего включают в себя 3–4 слова. Это может быть карточка товара или тема статьи. В среднем их ищут 50–500 человек ежемесячно.
- Анализируя метрику или данные счетчиков статистики, вы можете встретить еще и микро-НЧ ключи. Это фразы, которые вбивают в строку поиска единожды. Адаптировать под них страницу нерационально. Достаточно быть в топе по НЧ, включающим их в себя.
Второй параметр – конкурентность.
В данном случае ключи бывают:
- высококонкурентными;
- среднеконкурентными;
- низкоконкурентными.
И, наконец, третий – потребность. Выделяют ключи следующих видов:
- Навигационные. Отражают стремление человека найти определенный сайт или сведения на нем.
- Информационные. Выражают желание пользователя получить ответ на запрос.
- Транзакционные. Напрямую связаны с намерением купить товар.
- Нечеткие или общие. Те, по которым трудно определить интенцию.
- Геозависимые и геонезависимые. Выражают желание пользователя найти информацию или совершить транзакцию в своем городе или без привязки к региону.

Какова структура ключей? Они состоят:
- из тела;
- спецификатора;
- хвоста.
Телом называют ключевое слово, которое показывает продукт. Например, «тренажер». Это высокочастотный запрос. Но если мы постараемся написать под него статью, то получим огромный поток нецелевого трафика и, соответственно, снизим качество поведенческих факторов пользователей. В результате сайт упадет в поисковой выдаче.
Спецификатор отражает намерение пользователя – «купить тренажер», «настроить тренажер» и т. д. Эта часть ключа дает нам немного больше конкретной информации. И уже с учетом нее мы понимаем, чего именно хочет человек, когда делает этот запрос, и какой материал ему нужен.
Хвост уточняет намерение пользователя, например «починить тренажер недорого». Хвост – «недорого», поскольку человек конкретизировал намерение.
Всю эту теорию необходимо знать, если вы хотите работать с семантическим ядром.
Автоматический сбор семантического ядра онлайн
А теперь поговорим о самых востребованных сервисах по сбору семантического ядра.
Wordstat
Эту программу https://wordstat.yandex.ru/ можно считать первоисточником, поскольку другие инструменты так или иначе взаимодействуют с данными поисковой системы. В первую очередь выберите несколько запросов, максимально точно отражающих суть вашего бизнеса. Допустим, вы продаете цифровые фотоаппараты. Представьте, что лично ищете любой аналогичный магазин в Интернете. В качестве примера приведем запрос «купить фотоаппарат».
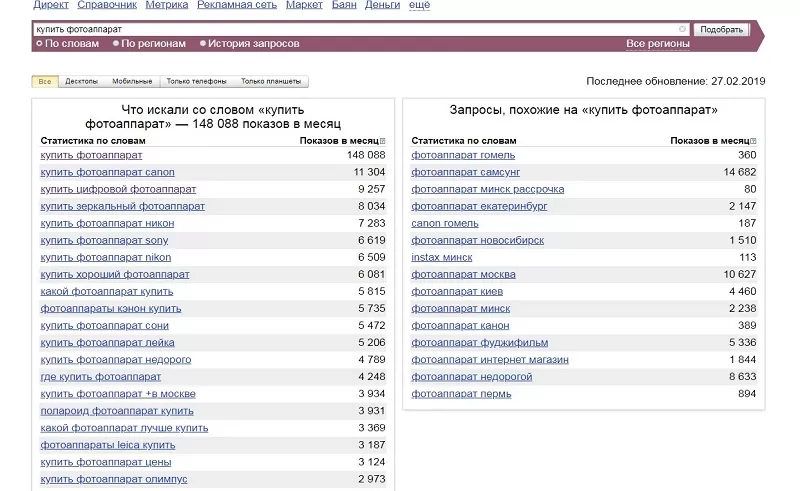
Слева в колонке – фразы, которые аудитория искала вместе с фразой «купить фотоаппарат». Не забывайте, что из перечня полученных фраз надо отсеять все лишние запросы. Вы ведь не продаете фотоаппараты на Avito?
Если вы не уверены, к какой категории относится запрос (коммерческий он или нет), просто впишите его в строку поиска и проанализируйте результаты выдачи. Если в ней больше блогов и журналов, то запрос, по всей вероятности, информационный. Например, в ключи может попасть фраза «какой фотоаппарат купить в 2019 году».
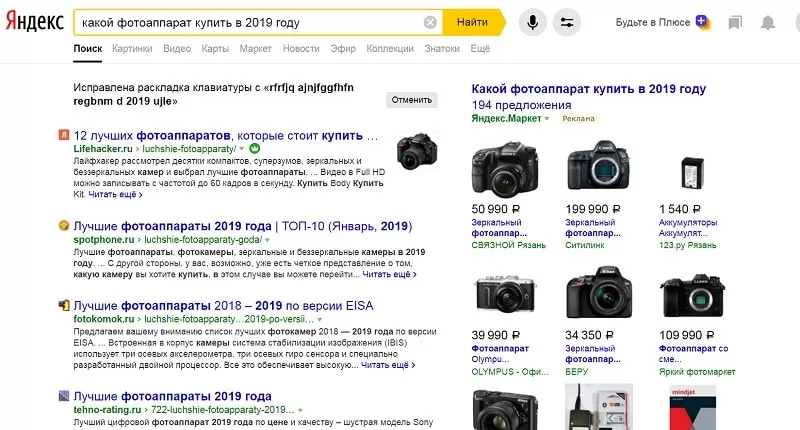
По запросу «какой цифровой фотоаппарат купить в 2019 году» поисковая система выдает только инфосайты.
Давайте подробнее поговорим о Wordstat как о программе для сбора семантического ядра. В колонке справа указаны фразы, схожие с начальным запросом. Но лишнего здесь, конечно, больше. Ваша задача – пользоваться только теми фразами, которые реально отражают специфику бизнеса, и, безусловно, исключать инфозапросы типа «качественный фотоаппарат». Правой колонкой можете пользоваться, чтобы искать синонимы. К примеру, мало кто может с первого раза правильно написать название японской марки fujifilm. Встречаются запросы «фиджифильм», «фудзифилм» и т. п. Все эти вариации также нужно включить в состав семантического ядра.
Анализируя запросы, вы обязательно увидите, что пользователи ищут фототехнику по ряду определенных критериев:
- стоимость (купить недорого);
- марка (купить фотоаппарат самсунг, кэнон, сони);
- модель (купить фотоаппарат canon powershot);
- характеристики (купить цифровой фотоаппарат, купить зеркальный фотоаппарат);
- регион (купить фотоаппарат в казани, купить фотоаппарат в краснодаре).
Эти данные позволяют вам сформировать так называемые маски запросов, в частности:
- фотоаппарат + действие (купить, заказать, с доставкой по РФ);
- фотоаппарат + стоимость (недорого, дешево, по акции, до 10 тыс., до 50 тыс.);
- фотоаппарат + марка;
- фотоаппарат + марка + модель;
- фотоаппарат + характеристика (64 гб, с nfc, 12 дюймов, с двумя симками);
- фотоаппарат + еще какой-то запрос (легкий, в качестве подарка).
Определив маски запросов, вы:
- Грамотно распределите посадочные страницы на сайте по категориям и характеристикам товаров.
- Разработаете страницы под популярные поисковые запросы (например, недорогой фотоаппарат).
- Растиражируете выбранные маски запросов на все остальные группы товаров.
- Сделаете шаблон для сбора семантического ядра.
На этой ступени мы не советуем сильно акцентировать внимание на частотности запроса. В список можете включать любые непустые фразы (с частотой от 1), связанные с вашим бизнес-проектом
При помощи каких фраз вы продвигаете и рекламируете свой товар, дело второе. На данном этапе главная задача – сбор полноценного семантического ядра.
RushAnalytics
Программа Rush Analytics помогает сделать сбор запросов из левой колонки Wordstat более автоматизированным с последующей загрузкой данных в таблицу Excel.
В нашем примере нужно лишь запустить сбор ключей по запросам «фотоаппарат». Но есть одна важная деталь. Wordstat по умолчанию отдает всего 41 страницу с результатами. Как вы понимаете, все запросы по такой схеме получить не удастся. Для обхода ограничения необходимо воспользоваться методом сбора частотности для запросов заданной длины (до 7 слов).
Для этого следует добавить запросы в Wordstat таким образом (обязательно нужны кавычки):
- «фотоаппарат фотоаппарат»;
- «фотоаппарат фотоаппарат фотоаппарат»;
- «фотоаппарат фотоаппарат фотоаппарат, фотоаппарат»;
- и так далее – до 7 слов.
Этот метод поможет в сборе максимального количества запросов по вашей теме.
Spywords.ru
Программа spywords.ru дает возможность несколько облегчить себе задачу и собрать семантическое ядро не с нуля, а с помощью сайтов-конкурентов.

Принцип работы предельно прост: нужно выбрать 3–4 лидера в вашей отрасли и собрать все фразы, по которым их ранжируют поисковики в пределах Топ-100.
Конечно, так вы, скорее всего, не соберете полноценную семантику. Но с большой долей вероятности охватите процентов 60, и для начала этого достаточно.