Парсинг html и скрепинг с помощью простой библиотеки html dom
Содержание:
- Основы PHP
- Шаг 3 – Реальный пример PHP парсинга HTML документа
- Единая точка входа
- SimpleXML
- Stream-based parsers
- Скрипт Human Emulator парсинга HTML-страницы с использованием XPath
- Потоковые парсеры
- Коды ошибок
- PHP XML Парсер функции
- Как парсить сайты
- 5 последних уроков рубрики «PHP»
- Константы синтаксического анализатора PHP XML
Основы PHP
Большинство читателей этой статьи уже работают с РНР, но, возможно, незнакомы с его историей и эволюцией.
О PHP
Hypertext Preprocessor (PHP) — это не зависящий от платформы язык сценариев, используемый для создания динамических Web-страниц и серверных приложений. Он начинался как Personal Home Page/Form Interpreter (PHP/FI) и обрел новую жизнь в руках Сураски (Suraski) и Гутманса (Gutmans), которые в июне 1998 года выпустили РНР3. Их компания Zend Technologies до сих пор управляет разработкой PHP.
В июле 2004 года вышел PHP5 с Zend Engine II и многими новыми функциями, такими как:
- Поддержка объектно-ориентированного программирования
- Улучшенная поддержка MySQL
- Улучшенная поддержка XML
PHP5 и XML
Поддержка XML присутствовала в РНР с самых ранних версий, но в РНР5 она существенно улучшена. Поддержка XML в РНР4 была ограниченной, в частности, предлагался только включенный по умолчанию парсер на базе SAX, а поддержка DOM не соответствовала стандарту W3C. В РНР5 разработчики PHP XML, можно сказать, изобрели колесо, обеспечив соответствие общепринятым стандартам.
Новое в поддержке XML в версии PHP5
PHP5 содержит полностью переписанные и новые расширения, включая парсер SAX, DOM, SimpleXML, XMLReader, XMLWriter и процессор XSLT. Теперь все эти расширения основаны на libxml2.
Наряду с улучшенной по сравнению с PHP4 поддержкой SAX, в РНР5 реализована поддержка DOM в соответствии со стандартом W3C, а также расширение SimpleXML. По умолчанию включены и SAX, и DOM, и SimpleXML. Тем, кто знаком с DOM по другим языкам, станет проще реализовать аналогичную функциональность в РНР
Шаг 3 – Реальный пример PHP парсинга HTML документа
Для примера парсинга, и приведения HTML DOM библиотеки
в действие, мы напишем грабер материалов на сайте sitear.ru. Далее мы выведем все статьи в виде
списка, в котором будут указаны названия статей. При написании граберов,
помните, кража контента преследуется законом! Но не в случае, когда на странице
стоит активная ссылка на исходный документ.
include('simple_html_dom.php');
$articles = array();
getArticles('http://sitear.ru/');
Начинаем с подключения библиотеки, и вызова функции getArticles, которая будет парсить HTML документы
соответственно адресу страницы, которая передается в качестве параметра
функции.
Также мы указываем глобальный массив, в котором будет,
хранится вся информация о статьях. Перед тем как начать парсинг HTML документа,
давайте посмотрим, как он выглядит.
<div class="title_material"> <div class="name_material"><a href="…">Название материала</a></div> <div class="views_material">Просмотров: <b>35</b></div> </div> <div class="description"> Описание статьи…</div>
Это базовый шаблон данной страницы. При написании парсера html, нужно тщательно исследовать
документ, так как и комментарии, типа <!—comment—>, это тоже потомки. Другими словами, в глазах
библиотеки simple HTML DOM,
это элементы, которые равноценны другим тегам страницы.
Единая точка входа
Принцип работы единой точки входа очень прост.
Веб-сервер настраивается так, чтобы все HTTP-запросы, вне зависимости от их URL, обрабатывались одним и тем же скриптом index.php.
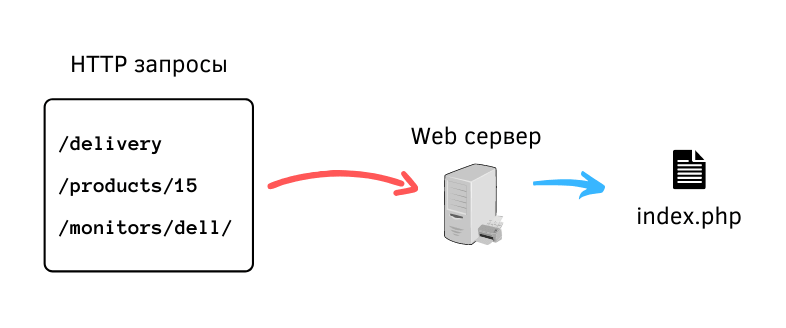 Перенаправление всех запросов на index.php
Перенаправление всех запросов на index.php
Текущий URL можно получить из переменной $_SERVER. Дальше останется только написать свои правила обработки URL-адресов. Упрощённый пример:
Однако в схеме выше есть одно упущение. Ведь если на сервер пришёл запрос к существующему файлу (style.css, script.js, logo.png и т.д) — сервер должен отдать этот файл, а не перенаправлять его.
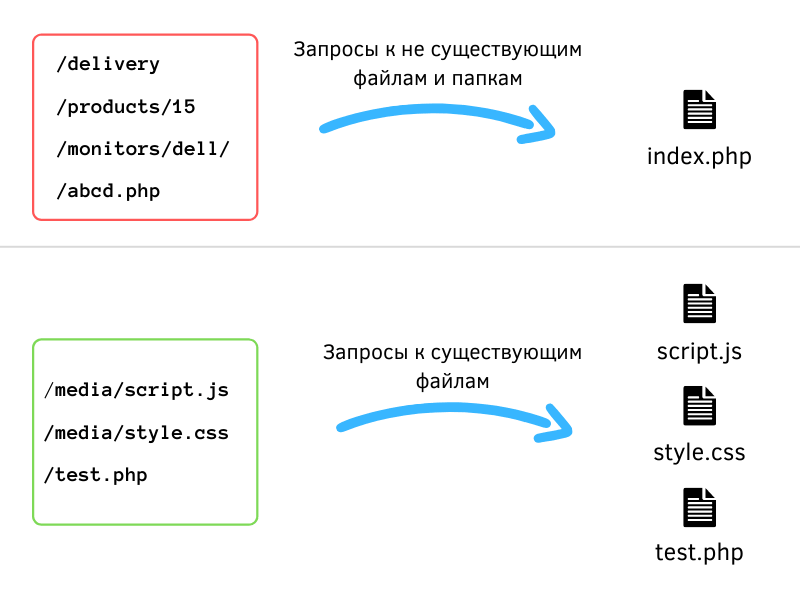 Принцип работы единой точки входа
Принцип работы единой точки входа
Вот и весь принцип единой точки входа. Именно так она работает в популярных CMS вроде WordPress и Opencart, в фреймворках Laravel, Symfony и т.д.
Единственный вопрос, который вам останется решить — что делать с запросами к существующим папкам.
Лично я предпочитаю также перенаправлять их на index.php.
На самом деле на сайтах часто используются 2 точки входа.
Первая — index.php, вторая — отдельный скрипт, предназначенный для работы с сайтом через консоль.
Плюсы единой точки входа
- Позволяет использовать ЧПУ
- Позволяет полностью управлять URL-адресами в PHP, в том числе хранить URL-адреса в базе данных
- Скрипты с конфигами, важными функциями и библиотеками подключаются только 1 раз и становятся доступны везде. Не нужно дублировать их подключение где-либо ещё.
Единая точка входа с Apache
Для настройки единой точки входа необходимо добавить несколько строк в конфиг веб-сервера. Проще всего это сделать с помощью файла .htaccess.
Этот файл позволяет переопределять настройки Apache для определённых сайтов и папок.
Добавляем следующие настройки в .htaccess:
Чтобы перенаправление срабатывало для существующих директорий, удаляем строку с !-d в конце, вот так:
Готово. Получить URL адрес текущей страницы можно из переменной $_SERVER.
Также в интернете часто можно встретить другой вариант конфига, отличается он только последней строкой:
Главное отличие в том, что URL-адрес текущей страницы будет храниться как в $_SERVER, так и в отдельном GET-параметре, в нашем случае $_GET, причём этот URL будет очищен от GET-параметров.
Флаг QSA нужен, поскольку без него GET-параметры не будут работать, т.е. массив $_GET будет содержать только url_param и больше ничего.
Какой из двух вариантов выбрать — решать вам, лично мне больше нравится первый.
SimpleXML
Other articles in this series
- XML for
PHP developers, Part 1: The 15-minute PHP-with-XML starter - XML for
PHP developers, Part 3: Advanced techniques to read, manipulate, and write
XML
Part 1 provided essential information on XML and focused on quick-start Application
Programming Interfaces (APIs). It demonstrated how SimpleXML, combined with the Document
Object Model (DOM) as necessary, is the ideal choice if you work with straightforward,
predictable, and relatively basic XML documents.
XML and PHP5
Extensible Markup Language (XML) is described as both a markup language and a text-based
data storage format; it offers a text-based means to apply and describe a tree-based
structure to information.
In PHP5, there are totally new and rewritten extensions for parsing XML. Those that load
the entire XML document into memory include SimpleXML, the DOM, and the XSLT processor.
Those parsers that provide you with one piece of the XML document at a time include the
Simple API for XML (SAX) and XMLReader. SAX functions the same way it did in PHP4, but
it’s not based on the expat library anymore, but on the libxml2 library. If you are
familiar with the DOM from other languages, you will have an easier time coding with the
DOM in PHP5 than previous versions.
Stream-based parsers
Stream-based parsers are so named because they parse the XML in a stream with much the
same rationale as streaming audio, working with a particular node, and, when they are
finished with that node, entirely forgetting its existence. XMLReader is a pull parser
and you code for it in much the same way as for a database query result table in a
cursor. This makes it easier to work with unfamiliar or unpredictable XML files.
Parsing with XMLReader
The XMLReader extension is a stream-based parser of the type often referred to as a
cursor type or pull parser. XMLReader pulls information from the XML document on
request. It is based on the API derived from C# XmlTextReader. It is included and
enabled in PHP 5.1 by default and is based on libxml2. Before PHP 5.1, the XMLReader
extension was not enabled by default but was available at PECL (see for a link). XMLReader supports
namespaces and validation, including DTD and Relaxed NG.
XMLReader in action
XMLReader, as a stream parser, is well-suited to parsing large XML documents; it is a
lot easier to code than SAX and usually faster. This is your stream parser of
choice.
This example in Listing 10 parses a large XML document with XMLReader.
Listing 10.
XMLReader with a large XML
file
<?php
$reader = new XMLReader();
$reader->open("tooBig.xml");
while ($reader->read()) {
switch ($reader->nodeType) {
case (XMLREADER::ELEMENT):
if ($reader->localName == "entry") {
if ($reader->getAttribute("ID") == 5225) {
while ($reader->read()) {
if ($reader->nodeType == XMLREADER::ELEMENT) {
if ($reader->localName == "title") {
$reader->read();
echo $reader->value;
break;
}
if ($reader->localName == "entry") {
break;
}
}
}
}
}
}
}
?>
Parsing with SAX
The Simple API for XML (SAX) is a stream parser. Events are associated with the XML
document being read, so SAX is coded in callbacks. There are events for element opening
and closing tags, for the content of elements, for entities, and for parsing errors. The
primary reason to use the SAX parser rather than the XMLReader is that the SAX parser is
sometimes more efficient and usually more familiar. A major disadvantage is that SAX
parser code is complex and more difficult to write than XMLReader code.
SAX in action
SAX is likely familiar to those who worked with XML in PHP4, and the SAX extension in
PHP5 is compatible with the version they’re used to. Since it’s a stream parser, it’s a
good choice for large files, but not as good a choice as XMLReader.
This example in Listing 11 parses a large XML document with SAX.
Listing 11.
Using SAX to parse a large XML
file
<?php //This class contains all the callback methods that will actually //handle the XML data. class SaxClass { private $hit = false; private $titleHit = false; //callback for the start of each element function startElement($parser_object, $elementname, $attribute) { if ($elementname == "entry") { if ( $attribute == 5225) { $this->hit = true; } else { $this->hit = false; } } if ($this->hit && $elementname == "title") { $this->titleHit = true; } else { $this->titleHit =false; } } //callback for the end of each element function endElement($parser_object, $elementname) { } //callback for the content within an element function contentHandler($parser_object,$data) { if ($this->titleHit) { echo trim($data)."<br />"; } } } //Function to start the parsing once all values are set and //the file has been opened function doParse($parser_object) { if (!($fp = fopen("tooBig.xml", "r"))); //loop through data while ($data = fread($fp, 4096)) { //parse the fragment xml_parse($parser_object, $data, feof($fp)); } } $SaxObject = new SaxClass(); $parser_object = xml_parser_create(); xml_set_object ($parser_object, $SaxObject); //Don't alter the case of the data xml_parser_set_option($parser_object, XML_OPTION_CASE_FOLDING, false); xml_set_element_handler($parser_object,"startElement","endElement"); xml_set_character_data_handler($parser_object, "contentHandler"); doParse($parser_object); ?>
Скрипт Human Emulator парсинга HTML-страницы с использованием XPath
В этой статье мы рассмотрим один из примеров написания скрипта для парсингаHTML-страниц с использованием XPath на примере сайта bing.com.
Сперва определимся с тем, что такое XPath и зачем оно нужно, если есть регулярные выражения?
XPath (XML Path Language) — это язык запросов к элементам XML-подобного документа (далее для краткости просто XML). XPath призван реализовать навигацию по DOM в XML.
Regexp — формальный язык поиска и осуществления манипуляций с подстроками в тексте, основанный на использовании метасимволов. По сути это строка-образец (шаблон), состоящая из символов и метасимволов и задающая правило поиска.
Итак, главная разница в том, что XPath специализируется на XML, а Regexp — на любом виде текста.
В: Зачем использовать XPath, если есть regexp, в котором можно сделать тоже самое?О: Простота поддержки.
Синтаксис у regexp такой, что уже через неделю может быть проще всё переписать, чем вносить изменения, а с XPath можно спокойно работать. И синтаксис у xpath довольно компактный,xml’ё-фобы могут быть спокойны.
Простой пример для вдохновления — получим значение аттрибута «href» у, например, тега «a».
Yohoho! Regexp:
Быстро (несколько небольших страниц) пробежаться по основам XPath можно в туториале от .
Как использовать XPath в PHP можно почитать в документации на . И в небольшом тутораильчике от .
Теперь определимся с необходимым функционалом скрипта:
* Возможность указывать произвольный поисковый запрос
* Парсим только первую страницу поисковой выдачи
* Из поисковой выдачи нам нужно:
* заголовок
* ссылка
* номер в выдаче
Исходя из нашего ТЗ составляем примерный алгоритм работы скрипта:
1) Заходим на bing.com
2) Вводим поисковую фразу
3) Получаем со страницы необходимый результат
Приступим к написанию парсера поисковой выдачи http://bing.com. Для начала, создадим базовый каркас скрипта.
// coding: windows-1251 // Настройка HumanEmulator // ———————————————— // Где запущен XHE $xhe_host = «127.0.0.1:7010»; // HumanEmulator lib require «../../Templates/xweb_human_emulator.php»; // Our tools require «tools/functions.php»; // Настройки скрипта // ———————————————— // Скрипт // ———————————————— // Quit $app->quit();
В настройки добавим переменную для хранения поискового запроса.
// Поисковый запрос $text = «ХуманЭмулятор»;
Заходим на сайт.
// Базовый URL $base_url = «https://www.bing.com/?setlang=en»; $browser->navigate($base_url);
Вводим поисковую фразу.
$input->set_value_by_attribute(«name», «q», true, $text); sleep(1); $element->click_by_attribute(«type», «submit»); sleep(5);
Сохраним в переменную содержимое страницы.
// Получаем содержимое страницы $content = $webpage->get_body();
Настроим xpath-объект:
$dom = new DOMDocument; @$dom->loadHTML($content); $xpath = new DOMXpath($dom);
Теперь у объекта $xpath есть метод «query» в который мы будемпередавать наше xpath-выражение. Давайте начнём создавать xpath-выражение.Открыв исходный код страницы с результатами поисковой выдачи увидим, что сами результаты находятся внутри тега «li».
Т.о. наше xpath-выражение выберет со страницы все поисковые результаты.
$results = $xpath->query(«//li»);
На одной странице у нас должно быть 1 или больше результатов, проверим себя:
if($results === false) { echo «С нашим xpath-выражением что-то не так.» . PHP_EOL; $app->quit(); } elseif($results->length === 0) { echo «Поисковый запрос ‘{$text}’ не принёс результатов.» . PHP_EOL: $app->quit(); } echo «Нашли {$results->length} совпадений.» . PHP_EOL;
Здесь стоит обратить внимание на ветку if, где мы сравниваем кол-во результатов xpath-поиска с нулём. Если наше xpath-выражение ничего не нашло, то это может означать две вещи:* Bing действительно ничего не нашёл
* Bing что-то нашёл, но поменял вёрстку на странице, и наше xpath-выражение необходимо исправлять.
2-й пункт достаточно коварный, в таких случаях, когда xpath-выражение ничего не находит необходимо дополнительно сверятся, чтобы удостоверится, что xpath-выражение не устарело (хотя и это не даст 100% гарантий). В нашем случае будем сверяться с тем, что Bing пишет кол-во найденных результатов.
14 results
А если результатов по поисковому запросу нет, то:
Потоковые парсеры
Потоковые парсеры называются так потому, что они анализируют XML в потоке, во многом напоминая работу потокового аудио. В каждый момент времени они работают с одним отдельным узлом, а закончив, совершенно забывают о его существовании. XMLReader — это pull-парсер, и программирование для него во многом напоминает извлечение результата запроса к таблице базы данных при помощи курсора. Это облегчает работу с незнакомыми или непредсказуемыми XML-файлами.
Парсинг при помощи XMLReader
XMLReader — это потоковый парсер того типа, который часто называют курсорным или pull-парсером. XMLReader вытягивает информацию из XML-документа по требованию. Он основан на API, полученном из C# XmlTextReader. В PHP 5.1 он включен и задействован по умолчанию и основан на библиотеке libxml2. До выхода PHP 5.1 расширение XMLReader не было включено по умолчанию, но было доступно в PECL (см. ). XMLReader поддерживает пространства имен и проверку, включая DTD и Relaxed NG.
XMLReader в действии
Как потоковый парсер, XMLReader хорошо подходит для работы с объемными XML-документами; программировать в нем намного легче и обычно быстрее, чем в SAX. Это лучший потоковый парсер.
В следующем примере (листинг 10) объемный XML-документ анализируется при помощи XMLReader.
Листинг 10. XMLReader с объемным XML-файлом
<?php
$reader = new XMLReader();
$reader->open("tooBig.xml");
while ($reader->read()) {
switch ($reader->nodeType) {
case (XMLREADER::ELEMENT):
if ($reader->localName == "entry") {
if ($reader->getAttribute("ID") == 5225) {
while ($reader->read()) {
if ($reader->nodeType == XMLREADER::ELEMENT) {
if ($reader->localName == "title") {
$reader->read();
echo $reader->value;
break;
}
if ($reader->localName == "entry") {
break;
}
}
}
}
}
}
}
?>
Парсинг при помощи SAX
Simple API for XML (SAX) представляет собой потоковый парсер. События связаны с читаемым XML-документом, поэтому SAX программируется в стиле обратных вызовов. Существуют события для открывающих и закрывающих тегов элемента, сущностей и ошибок парсинга. Главная причина использования парсера SAX вместо XMLReader заключается в том, что парсер SAX иногда более эффективен и обычно лучше знаком. Важный недостаток — код для парсера SAX получается сложнее, и его труднее писать, чем для XMLReader.
SAX в действии
SAX должен быть знаком тем, кто работал с XML в PHP4, а расширение SAX
в PHP5 совместимо с версией, к которой они привыкли. Так как это потоковый парсер, он хорошо справляется с объемными файлами, но это не лучший выбор, чем XMLReader.
В листинге 11 приведен пример обработки объемного XML-документа парсером SAX.
Листинг 11. Использование SAX для анализа объемного XML-файла
<?php
//Этот класс содержит все методы обратного вызова,
//которые автоматически управляют данными XML.
class SaxClass {
private $hit = false;
private $titleHit = false;
//обратный вызов для начала каждого элемента
function startElement($parser_object, $elementname, $attribute) {
if ($elementname == "entry") {
if ( $attribute == 5225) {
$this->hit = true;
} else {
$this->hit = false;
}
}
if ($this->hit && $elementname == "title") {
$this->titleHit = true;
} else {
$this->titleHit =false;
}
}
//обратный вызов для конца каждого элемента
function endElement($parser_object, $elementname) {
}
//обратный вызов для содержимого каждого элемента
function contentHandler($parser_object,$data)
{
if ($this->titleHit) {
echo trim($data)."<br />";
}
}
}
//Функция запуска парсинга, когда все значения установлены
//и файл открыт
function doParse($parser_object) {
if (!($fp = fopen("tooBig.xml", "r")));
//прокрутка данных
while ($data = fread($fp, 4096)) {
//анализ фрагмента
xml_parse($parser_object, $data, feof($fp));
}
}
$SaxObject = new SaxClass();
$parser_object = xml_parser_create();
xml_set_object ($parser_object, $SaxObject);
//Не меняйте регистр данных
xml_parser_set_option($parser_object, XML_OPTION_CASE_FOLDING, false);
xml_set_element_handler($parser_object,"startElement","endElement");
xml_set_character_data_handler($parser_object, "contentHandler");
doParse($parser_object);
?>
Коды ошибок
Следующие константы определены для кодов ошибок XML (как возвращаемые
xml_parse()):
| XML_ERROR_NONE |
| XML_ERROR_NO_MEMORY |
| XML_ERROR_SYNTAX |
| XML_ERROR_NO_ELEMENTS |
| XML_ERROR_INVALID_TOKEN |
| XML_ERROR_UNCLOSED_TOKEN |
| XML_ERROR_PARTIAL_CHAR |
| XML_ERROR_TAG_MISMATCH |
| XML_ERROR_DUPLICATE_ATTRIBUTE |
| XML_ERROR_JUNK_AFTER_DOC_ELEMENT |
| XML_ERROR_PARAM_ENTITY_REF |
| XML_ERROR_UNDEFINED_ENTITY |
| XML_ERROR_RECURSIVE_ENTITY_REF |
| XML_ERROR_ASYNC_ENTITY |
| XML_ERROR_BAD_CHAR_REF |
| XML_ERROR_BINARY_ENTITY_REF |
| XML_ERROR_ATTRIBUTE_EXTERNAL_ENTITY_REF |
| XML_ERROR_MISPLACED_XML_PI |
| XML_ERROR_UNKNOWN_ENCODING |
| XML_ERROR_INCORRECT_ENCODING |
| XML_ERROR_UNCLOSED_CDATA_SECTION |
| XML_ERROR_EXTERNAL_ENTITY_HANDLING |
PHP XML Парсер функции
PHP: указывает самую раннюю версию PHP, которая поддерживает эту функцию.
| Функция | Описание | PHP |
|---|---|---|
| utf8_decode() | Декодирует строку UTF-8 в ISO-8859-1 | 3 |
| utf8_encode() | Кодирует строку ISO-8859-1 в UTF-8 | 3 |
| xml_error_string() | Возвращает строку ошибки из синтаксического анализатора XML | 3 |
| xml_get_current_byte_index() | Возвращает текущий байтовый индекс из синтаксического анализатора XML | 3 |
| xml_get_current_column_number() | Возвращает текущий номер столбца из синтаксического анализатора XML | 3 |
| xml_get_current_line_number() | Возвращает текущий номер строки из синтаксического анализатора XML | 3 |
| xml_get_error_code() | Возвращает код ошибки из синтаксического анализатора XML | 3 |
| xml_parse() | Синтаксический анализ XML документа | 3 |
| xml_parse_into_struct() | Анализ XML данных в массиве | 3 |
| xml_parser_create_ns() | Создание синтаксического анализатора XML с поддержкой пространства имен | 4 |
| xml_parser_create() | Создание синтаксического анализатора XML | 3 |
| xml_parser_free() | Свободный синтаксический анализатор XML | 3 |
| xml_parser_get_option() | Получение параметров из синтаксического анализатора XML | 3 |
| xml_parser_set_option() | Задает параметры в XML парсер | 3 |
| xml_set_character_data_handler() | Устанавливает функцию обработчика для символьных данных | 3 |
| xml_set_default_handler() | Устанавливает функцию обработчика индекса | 3 |
| xml_set_element_handler() | Устанавливает функцию обработчика для начального и конечного элемента элементов | 3 |
| xml_set_end_namespace_decl_handler() | Устанавливает функцию обработчика для конца объявлений пространства имен | 4 |
| xml_set_external_entity_ref_handler() | Устанавливает функцию обработчика для внешних объектов | 3 |
| xml_set_notation_decl_handler() | Устанавливает функцию обработчика для объявлений нотации | 3 |
| xml_set_object() | Использование синтаксического анализатора XML внутри объекта | 4 |
| xml_set_processing_instruction_handler() | Устанавливает функцию обработчика для обработки инструкции | 3 |
| xml_set_start_namespace_decl_handler() | Устанавливает функцию обработчика для запуска объявлений пространства имен | 4 |
| xml_set_unparsed_entity_decl_handler() | Устанавливает функцию обработчика для нерасшифрованных объявлений сущностей | 3 |
Как парсить сайты
Я долго не хотел писать эту статью, поскольку конкретного смысла в ней нет. Чтобы сделать парсер на PHP, нужно знать этот язык. А те, кто его знает, такой вопрос просто не зададут. Но в этой статье я расскажу, как вообще создаются парсеры, а также, что конкретно нужно изучать.
Итак, вот список пунктов, которые необходимо пройти, чтобы создать парсер контента на PHP:
- Получить содержимое страницы и записать его в строковую переменную. Наиболее простой вариант — это функция file_get_contents(). Если контент доступен только авторизованным пользователям, то тут всё несколько сложнее. Здесь уже надо посмотреть, каков механизм авторизации. Далее, используя cURL, отправить правильный запрос на форму авторизации, получить ответ и затем отправить правильные заголовки (например, полученный идентификатор сессии), а также в этом же запросе обратиться к той странице, которая нужна. Тогда уже в этом ответе Вы получите конечную страницу.
- Изучить структуру страницы. Вам нужно найти контент, который Вам необходим и посмотреть, в каком блоке он находится. Если блок, в котором он находится не уникален, то найти другие общие признаки, по которым Вы однозначно сможете сказать, что если строка удовлетворяет им, то это то, что Вам и нужно.
- Используя строковые функции, достать из исходной строки нужный Вам контент по признакам, найденным во 2-ом пункте.
Отмечу так же, что всё это поймёт и сможет применить на практике только тот, кто знает PHP. Поэтому те, кто его только начинает изучать, Вам потребуются следующие знания:
- Строковые функции.
- Библиотека cURL, либо её аналог.
- Отличное знание HTML.
Те же, кто ещё вообще не знает PHP, то до парсеров в этом случае ещё далеко, и нужно изучать всю базу. В этом Вам поможет мой курс, либо какие-нибудь книги по PHP.
Безусловно, Америки я в этой статье не открыл, но слишком много вопросов по теме парсеров, поэтому этой статьёй я постарался лишь дать развёрнутый ответ.
5 последних уроков рубрики «PHP»
Когда речь идёт о безопасности веб-сайта, то фраза «фильтруйте всё, экранируйте всё» всегда будет актуальна. Сегодня поговорим о фильтрации данных.
Обеспечение безопасности веб-сайта — это не только защита от SQL инъекций, но и протекция от межсайтового скриптинга (XSS), межсайтовой подделки запросов (CSRF) и от других видов атак
В частности, вам нужно очень осторожно подходить к формированию HTML, CSS и JavaScript кода.
Expressive 2 поддерживает возможность подключения других ZF компонент по специальной схеме. Не всем нравится данное решение
В этой статье мы расскажем как улучшили процесс подключение нескольких модулей.
Предположим, что вам необходимо отправить какую-то информацию в Google Analytics из серверного скрипта. Как это сделать. Ответ в этой заметке.
Подборка PHP песочниц
Подборка из нескольких видов PHP песочниц. На некоторых вы в режиме online сможете потестить свой код, но есть так же решения, которые можно внедрить на свой сайт.
Константы синтаксического анализатора PHP XML
| Constant |
|---|
| XML_ERROR_NONE (integer) |
| XML_ERROR_NO_MEMORY (integer) |
| XML_ERROR_SYNTAX (integer) |
| XML_ERROR_NO_ELEMENTS (integer) |
| XML_ERROR_INVALID_TOKEN (integer) |
| XML_ERROR_UNCLOSED_TOKEN (integer) |
| XML_ERROR_PARTIAL_CHAR (integer) |
| XML_ERROR_TAG_MISMATCH (integer) |
| XML_ERROR_DUPLICATE_ATTRIBUTE (integer) |
| XML_ERROR_JUNK_AFTER_DOC_ELEMENT (integer) |
| XML_ERROR_PARAM_ENTITY_REF (integer) |
| XML_ERROR_UNDEFINED_ENTITY (integer) |
| XML_ERROR_RECURSIVE_ENTITY_REF (integer) |
| XML_ERROR_ASYNC_ENTITY (integer) |
| XML_ERROR_BAD_CHAR_REF (integer) |
| XML_ERROR_BINARY_ENTITY_REF (integer) |
| XML_ERROR_ATTRIBUTE_EXTERNAL_ENTITY_REF (integer) |
| XML_ERROR_MISPLACED_XML_PI (integer) |
| XML_ERROR_UNKNOWN_ENCODING (integer) |
| XML_ERROR_INCORRECT_ENCODING (integer) |
| XML_ERROR_UNCLOSED_CDATA_SECTION (integer) |
| XML_ERROR_EXTERNAL_ENTITY_HANDLING (integer) |
| XML_OPTION_CASE_FOLDING (integer) |
| XML_OPTION_TARGET_ENCODING (integer) |
| XML_OPTION_SKIP_TAGSTART (integer) |
| XML_OPTION_SKIP_WHITE (integer) |
❮ Назад
Дальше ❯