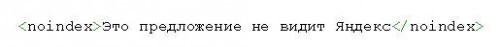Что такое robots.txt [основы для новичков]
Содержание:
- Краткая история роботизации
- Основные правила использования файлов robots.txt
- Новый робот Atlas Boston Dynamics
- Чем грозит отсутствие robots.txt
- Мета-тег Robots — помогает закрыть дубли контента при индексации сайта
- Как создавался самый сложный робот
- Пример robots.txt для WordPress
- Описание robots.txt
- Директивы Sitemap и Host (для Яндекса) в Robots.txt
- Приоритеты агентов пользователей
- Структура robots.txt
- Индексация сайта
- Для чего нужна проверка robots.txt
Краткая история роботизации
За последние 100 лет роботы не просто эволюционировали, они стали частью нашей повседневной жизни. Слово «робот» вошло в обиход после того, как в 1920 году свет увидела пьеса Карла Чапека об искусственных людях. И это очень символично, так как «ревущие» двадцатые — период экономического подъема и новых открытий в науке и технике.
В течение последующих десятилетий произошли выдающиеся открытия в самых различных дисциплинах — кибернетика, мехатроника, информатика, электроника, механика, а именно на них и опирается робототехника. Примерно к 30-м годам XX века появились первые андроиды, которые могли двигаться и произносить простейшие фразы.
Первые программируемые механизмы с манипуляторами были сконструированы в 1930-х годах в США. Толчком послужили работы Генри Форда по созданию автоматизированной производственной линии. На рубеже 1930-40-х годов в СССР появились автоматические линии для обработки деталей подшипников, а в конце 1940-х годов было впервые в мире создано комплексное производство поршней для тракторных двигателей с автоматизацией всех процессов — от загрузки сырья до упаковки готовой продукции.
В 1950 году Тьюринг в работе «Computing Machinery and Intelligence» описал способ, позволяющий определить, является ли машина мыслящей (тест Тьюринга). В 1950-х годах появились первые механические манипуляторы, которые копировали движения рук оператора и могли работать с радиоактивными материалами. В 1956 году американские инженеры Джозеф Девол и Джозеф Энгельберг организовали первую в мире компанию «Юнимейшн» (англ. Unimation, сокращенный термин от Universal Automation, универсальная автоматика), и в начале 1960-х первый в мире промышленный робот начал работать на производственной линии завода General Motors.
Робот Unimate, которого отправили на фабрику General Motors
В 1960-х годах в университетах появились лаборатории искусственного интеллекта, а 1970-х были создали микропроцессорные системы управления, которые заменили специализированные блоки управления роботов на программируемые контроллеры. Это сократило стоимость роботов примерно в три раза, так что они стали всё чаще применяться в разных отраслях промышленности. В 1982 году в IBM разработали официальный язык для программирования робототехнических систем, а спустя два года компания Adept представила первый робот Scara с электроприводом. В 1986 году роботы были впервые применены в Чернобыле для очистки радиоактивных отходов.
Двадцать первый век принёс невиданные успехи в развитии робототехники. В 2000 годы, по данным ООН, в мире использовалось уже 742 500 промышленных роботов. Невозможно перечислить все новые модели и открытия в сфере робототехники за последние 20 лет. Вот лишь некоторые из них.
В начале 2000-х многие компании представили новых гуманоидных роботов — например, Asimo от Honda и SDR-3X от Sony. Канадский космический манипулятор Canadarm2 использовался для завершения сборки МКС, а в мюнхенском Институте биохимии имени Макса Планка был создан первый в мире нейрочип. Появились первые серийно выпускаемые бытовые роботы-пылесосы (Electrolux) и первая киберсобака (Sanyo Electric). Компания Bandai представила прототип робота с возможностью распознавания человеческих лиц и голосов, ученые из Стэнфордского университета — робота STAIR (Stanford Artificial Intelligence Robot), наделенного интеллектом и способного принимать нестандартные решения, руководствуясь заложенными в него знаниями об окружающем мире. Военный робот смог распознавать и преодолевать препятствия — в NASA взяли на вооружение экзоскелет X1 Robotic Exoskeleton. Роботы стали активно использоваться в медицине при проведении хирургических операций.

Основные правила использования файлов robots.txt
Ниже приведены базовые принципы работы с файлами robots.txt. Мы рекомендуем вам изучить полный синтаксис этих файлов, так как у него есть неочевидные особенности, в которых вам следует разобраться.
Формат и расположение
Создать файл robots.txt можно почти в любом текстовом редакторе с поддержкой кодировки UTF-8. Не используйте текстовые процессоры, поскольку зачастую они сохраняют файлы в проприетарном формате и добавляют в них недопустимые символы, например фигурные кавычки, которые не распознаются поисковыми роботами.
При создании и изменении файлов robots.txt используйте инструмент проверки. Он позволяет проанализировать синтаксис файла и узнать, как он будет функционировать на вашем сайте.
Правила в отношении формата и расположения файла
- Файл должен носить название robots.txt.
- На сайте должен быть только один такой файл.
- Файл robots.txt нужно разместить в корневом каталоге сайта. Например, чтобы контролировать сканирование всех страниц сайта , файл robots.txt необходимо разместить по адресу . Он не должен находиться в подкаталоге (например, по адресу ). В случае затруднений с доступом к корневому каталогу обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги.
- Файл robots.txt можно добавлять по адресам с субдоменами (например, ) или нестандартными портами (например, ).
- Любой текст после символа # считается комментарием.
Синтаксис
- Файл robots.txt должен представлять собой текстовый файл в кодировке UTF-8 (которая включает коды символов ASCII). Другие наборы символов использовать нельзя.
- Файл robots.txt состоит из групп.
- Каждая группа может включать несколько правил, по одному на строку. Эти правила также называются директивами.
- Группа содержит следующую информацию:
- К какому агенту пользователя относятся директивы группы.
- К каким каталогам или файлам у этого агента есть доступ.
- К каким каталогам или файлам у этого агента нет доступа.
- Правила групп считываются сверху вниз. Робот будет следовать правилам только одной группы с наиболее точно соответствующим ему агентом пользователя.
- По умолчанию предполагается, что агенту пользователя разрешено сканировать любые страницы и каталоги, доступ к которым не заблокирован правилом .
- В правилах имеет значение регистр. К примеру, правило распространяется на , но не на .
Директивы, которые используются в файлах robots.txt
Другие правила игнорируются.
Ещё один пример
Файл robots.txt состоит из групп. Каждая из них начинается со строки , определяющей, какому роботу адресованы правила. Ниже приведен пример файла с двумя группами и с поясняющими комментариями к обеим.
# Block googlebot from example.com/directory1/... and example.com/directory2/... # but allow access to directory2/subdirectory1/... # All other directories on the site are allowed by default. User-agent: googlebot Disallow: /directory1/ Disallow: /directory2/ Allow: /directory2/subdirectory1/ # Block the entire site from anothercrawler. User-agent: anothercrawler Disallow: /
Новый робот Atlas Boston Dynamics
Разработчики добавили в робота-гуманоида аккумулятор емкостью 3,7 кВч, который может обеспечить ему час автономной работы, включающей в себя перемещение и некоторые другие действия. Кроме того, для компенсации увеличения массы за счет установки аккумулятора инженерам пришлось использовать более легкие материалы при создании корпуса Atlas. Также создатели добавили в робота беспроводной модуль для связи и улучшили его подвижные части, увеличив свободу передвижения гуманоида. Его рост уменьшили до 1,5 метра, а вес — до 75 килограмм, чтобы было легче выполнять маневры. Инженеры хотели сделать робота максимально легким и прочным, многие его делали разработаны с нуля разработчиками из Boston Dynamics и напечатаны на 3D-принтере. Такого больше ни у кого нет.
С тех пор создатели робота занимаются тем, что улучшают его систему навигации и обучают его новым движениям, которые потенциально могут пригодиться ему при работе в трудных условиях. Так, в прошлом году Atlas научился разворачиваться в прыжке на 360 градусов — прямо как гимнаст. Как же ему все это удается?

Чем грозит отсутствие robots.txt
В заключение скажем о том, чем же грозит отсутствие robots.txt и настолько ли это страшно. Отсутствие данного файла приводит к проблемам со скоростью обхода сайта роботами и к присутствию «мусора» в индексе. Если Вы знаете, что такое продвижение сайта и занимаетесь этим, то игнорирование файла robots.txt Вам ни к чему.
Неправильная настройка такого файла приведёт к исключению из индекса важных составляющих ресурса. Файл robots.txt – это важнейший инструмент для взаимодействия с роботами-поисковиками
Сегодня мы удостоверились, насколько важно обращать внимание этот файл и к чему может привести его отсутствие
Мета-тег Robots — помогает закрыть дубли контента при индексации сайта
Существует еще один способ настроить (разрешить или запретить) индексацию отдельных страниц вебсайта, как для Яндекса, так и для Гугл. Причем для Google этот метод гораздо приоритетнее описанного выше. Поэтому, если нужно наверняка закрыть страницу от индексации этой поисковой системой, то данный мета-тег нужно будет прописывать в обязательном порядке.
Для этого внутри тега «HEAD» нужной вебстраницы дописывается МЕТА-тег Robots с нужными параметрами, и так повторяется для всех документов, к которым нужно применить то или иное правило (запрет или разрешение). Выглядеть это может, например, так:
<html> <head> <meta name="robots" content="noindex,nofollow"> <meta name="description" content="Эта страница ...."> <title>...</title> </head> <body> ...
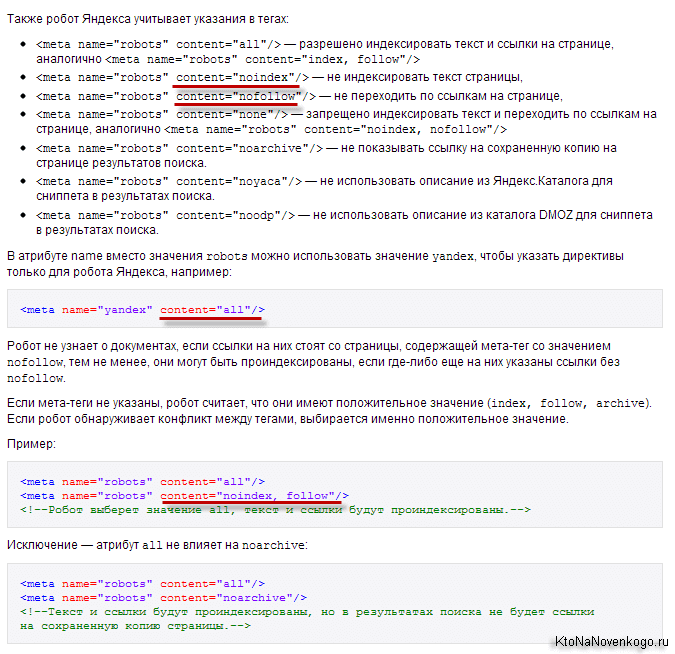
В этом случае, боты всех поисковых систем должны будут забыть об индексации этой вебстраницы (об этом говорит присутствие в данном мета-теге) и анализе размещенных на ней ссылок (об этом говорит присутствие — боту запрещается переходить по ссылкам, которые он найдет в этом документе).
Существуют только две пары параметров у метатега robots: index и follow:
- Index — указывают, может ли робот проводить индексацию данного документа
- Follow — может ли он следовать по ссылкам, найденным в этом документе
Значения по умолчанию (когда этот мета-тег для страницы вообще не прописан) – «index» и «follow». Есть также укороченный вариант написания с использованием «all» и «none», которые обозначают активность обоих параметров или, соответственно, наоборот: и .
Более подробные объяснения можно найти, например, в хелпе Яндекса:
Для блога на WordPress вы сможете настроить мета-тег Robots, например, с помощью плагина . Если используете другие плагины или другие движки сайта, то гуглите на тему прописывания для нужных страниц meta name=»robots».
Как создавался самый сложный робот
Такого робота создали почти 7 лет назад, и его постоянно дорабатывают, поэтому пока никому не удалось его переплюнуть. Агентство по передовым оборонным научно-исследовательским проектам США (DARPA) совместно с компанией Boston Dynamics разработали человекоподобного робота Atlas. Он отлично ориентируется в пространстве и имеет 28 гидравлических суставов, множество сенсоров и передовую систему управления.

Так выглядел прототип первого робота Atlas
В Boston Dynamics говорят, что изначально роботом управлял оператор, для того, чтобы создать трехмерную карту области передвижения. Однако затем гуманоид смог передвигаться самостоятельно с уже внесенной в его базу информацией об окружении и препятствиях на пути.
Поначалу он и правда напоминал прислужника из «Скайнет» и не мог двигаться без подключения к управляемому компьютеру и электропитанию. Имел рост 190 сантиметров и вес 136 килограмм. Всего пара лет понадобилась разработчикам, чтобы выпустить новую версию робота Atlas, который стал самым сложным роботом на Земле. Сначала они обновили его прошивку, а затем — и все «тело», сделав робота еще больше похожим на человека.
Пример robots.txt для WordPress
Для wordpress инструкции необходимо указывать таким образом, чтобы закрыть к индексации все технические директории (wp-admin, wp-includes и т.д.), а также дубли страниц, создаваемые тегами, файлами rss, комментариями, поиском.
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback Disallow: */feed/ Disallow: */feed Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Disallow: */page/* Disallow: */comment Disallow: */tag/* Disallow: */attachment/* Allow: /wp-content/uploads/ Host: www.runcms.org User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback Disallow: */feed/ Disallow: */feed Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Disallow: */page/* Disallow: */comment Disallow: */tag/* Disallow: */attachment/* Allow: /wp-content/uploads/ User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback Disallow: */feed/ Disallow: */feed Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Disallow: */page/* Disallow: */comment Disallow: */tag/* Disallow: */attachment/* Allow: /wp-content/uploads/ Sitemap: http://runcms.org/sitemap.xml
Описание robots.txt
Чтобы правильно написать robots.txt, предлагаем вам изучить разделы этого сайта. Здесь собрана самая полезная информация о синтаксисе robots.txt, о формате robots.txt, примеры использования, а также описание основных поисковых роботов Рунета.
- Как работать с robots.txt — узнайте, что вы можете сделать, чтобы управлять роботами, которые посещают ваш веб-сайт.
- Роботы Рунета — разделы по роботам поисковых систем, популярных на просторах Рунета.
- Частые ошибки в robots.txt — список наиболее частых ошибок, допускаемых при написании файла robots.txt.
- ЧаВо по веб-роботам — часто задаваемые вопросы о роботах от пользователей, авторов и разработчиков.
- Ссылки по теме — аналог оригинального раздела «WWW Robots Related Sites», но дополненый и расширенный, в основном по русскоязычной тематике.
Где размещать файл robots.txt
Робот просто запрашивает на вашем сайте URL «/robots.txt», сайт в данном случае – это определенный хост на определенном порту.
| URL Сайта | URL файла robots.txt |
| http://www.w3.org/ | http://www.w3.org/robots.txt |
| http://www.w3.org:80/ | http://www.w3.org:80/robots.txt |
| http://www.w3.org:1234/ | http://www.w3.org:1234/robots.txt |
| http://w3.org/ | http://w3.org/robots.txt |
На сайте может быть только один файл «/robots.txt». Например, не следует помещать файл robots.txt в пользовательские поддиректории – все равно роботы не будут их там искать. Если вы хотите иметь возможность создавать файлы robots.txt в поддиректориях, то вам нужен способ программно собирать их в один файл robots.txt, расположенный в корне сайта. Вместо этого можно использовать Мета-тег Robots.
Не забывайте, что URL-ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
| Неправильное расположение robots.txt | |
| http://www.w3.org/admin/robots.txt | Файл находится не в корне сайта |
| http://www.w3.org/~timbl/robots.txt | Файл находится не в корне сайта |
| ftp://ftp.w3.com/robots.txt | Роботы не индексируют ftp |
| http://www.w3.org/Robots.txt | Название файла не в нижнем регистре |
Как видите, файл robots.txt нужно класть исключительно в корень сайта.
Что писать в файл robots.txt
В файл robots.txt обычно пишут нечто вроде:
В этом примере запрещена индексация трех директорий.
Затметьте, что каждая директория указана на отдельной строке – нельзя написать «Disallow: /cgi-bin/ /tmp/». Нельзя также разбивать одну инструкцию Disallow или User-agent на несколько строк, т.к. перенос строки используется для отделения инструкций друг от друга.
Регулярные выражения и символы подстановки так же нельзя использовать. «Звездочка» (*) в инструкции User-agent означает «любой робот». Инструкции вида «Disallow: *.gif» или «User-agent: Ya*» не поддерживаются.
Конкретные инструкции в robots.txt зависят от вашего сайта и того, что вы захотите закрыть от индексации. Вот несколько примеров:
Запретить к индексации все файлы кроме одного
Это довольно непросто, т.к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
Либо вы можете запретить все запрещенные к индексации файлы:
Директивы Sitemap и Host (для Яндекса) в Robots.txt
Во избежании возникновения неприятных проблем с зеркалами сайта, раньше рекомендовалось добавлять в robots.txt директиву Host, которая указывал боту Yandex на главное зеркало.
Однако, в начале 2018 год это было отменено и .
Директива Host — указывает главное зеркало сайта для Яндекса
Например, раньше, если вы еще не перешли на защищенный протокол, указывать в Host нужно было не полный Урл, а доменное имя (без http://, т.е. ktonanovenkogo.ru, а не https://ktonanovenkogo.ru). Если же уже перешли на https, то указывать нужно будет полный Урл (типа https://myhost.ru).
Напомню в качестве исторического экскурса, что по стандарту написания роботс.тхт за любой директивой должна сразу следовать хотя бы одна директива (пусть даже и пустая, ничего не запрещающая). Так же, наверное, имеется смысл прописывать Host для отдельного блока «User-agent: Yandex», а не для общего «User-agent: *», чтобы не сбивать с толку роботов других поисковиков, которые эту директиву не поддерживают:
User-agent: Yandex Disallow: Host: www.site.ru
либо
User-agent: Yandex Disallow: Host: site.ru
либо
User-agent: Yandex Disallow: Host: https://site.ru
либо
User-agent: Yandex Disallow: Host: https://www.site.ru
в зависимости от того, что для вас оптимальнее (с www или без), а так же в зависимости от протокола.
Указываем или скрываем путь до карты сайта sitemap.xml в файле robots
Директива Sitemap указывает на местоположение файла карты сайта (обычно он называется Sitemap.xml, но не всегда). В качестве параметра указывается путь к этому файлу, включая http:// (т.е. его Урл).Благодаря этому поисковый робот сможете без труда его найти. Например:
Sitemap: http://site.ru/sitemap.xml
Раньше файл карты сайта хранили в корне сайта, но сейчас многие его прячут внутри других директорий, чтобы ворам контента не давать удобный инструмент в руки. В этом случае путь до карты сайта лучше в роботс.тхт не указывать. Дело в том, что это можно с тем же успехом сделать через панели поисковых систем (Я.Вебмастер, Google.Вебмастер, панель Майл.ру), тем самым «не паля» его местонахождение.
Местоположение директивы Sitemap в файле robots.txt не регламентируется, ибо она не обязана относиться к какому-то юзер-агенту. Обычно ее прописывают в самом конце, либо вообще не прописывают по приведенным выше причинам.
Приоритеты агентов пользователей
Для отдельного поискового робота имеет силу только одна группа. Он должен найти ту, в которой наиболее конкретно указан агент пользователя из числа подходящих. Все остальные группы будут пропущены. В обозначении агента пользователя учитывается регистр. Весь неподходящий текст игнорируется. Например, и аналогичны варианту . Порядок групп в файле robots.txt не имеет значения.
Если определенному агенту пользователя соответствует несколько групп, то все относящиеся к нему правила из всех групп объединяются в одну.
Пример 1
Предположим, что имеется следующий файл robots.txt:
user-agent: googlebot-news
(group 1)
user-agent: *
(group 2)
user-agent: googlebot
(group 3)
Сведения о том, какую группу выберут разные поисковые роботы, приведены в таблице ниже.
| Соответствие групп роботам | |
|---|---|
| Googlebot News | Выбирается группа 1, в которой конкретнее всего указан подходящий агент пользователя. Остальные игнорируются. |
| Googlebot (веб-поиск) | Выбирается группа 3. |
| Googlebot Images | Выбирается группа 3, поскольку нет отдельной группы с конкретным указанием элемента . |
| Googlebot News (при сканировании изображений) | Выбирается группа 1, поскольку в данном случае изображения будут сканироваться именно роботом Googlebot News. |
| Otherbot (веб-поиск) | Выбирается группа 2. |
| Otherbot (для новостей) | Выбирается группа 2. Даже если имеется запись для схожего робота, она недействительна без точного соответствия. |
Пример 2
Предположим, что имеется следующий файл robots.txt:
user-agent: googlebot-news
disallow: /fish
user-agent: *
disallow: /carrots
user-agent: googlebot-news
disallow: /shrimp
Поисковые роботы объединят группы, относящиеся к одному агенту пользователя, следующим образом:
user-agent: googlebot-news
disallow: /fish
disallow: /shrimp
user-agent: *
disallow: /carrots
Дополнительная информация приведена в Справочном центре.
Структура robots.txt
Строение файла выглядит просто. Он включает ряд блоков, адресованных конкретным ботам-поисковикам. В этих блоках прописываются директивы (команды) для управления ходом индексации. Дополнительно можно проставлять комментарии. Чтобы они игнорировались поисковиком, нужно использовать знак #. Каждый комментарий начинается и заканчивается этим символом. Кроме того, не рекомендуется вставлять символ комментария внутри директивы.
Robots.txt создаётся одним из удобных для вас методов:
- вручную с использованием текстового редактора, после чего он сохраняется с расширением *. txt.
- автоматически с применением онлайн-программ.
Большинство специалистов работают с файлом вручную – процесс достаточно прост, занимает немного времени, но при этом вы будете уверены в правильности его написания. В любом случае, автоматически сформированные файлы обязательно подлежат проверке, ведь от этого зависит, насколько хорошо будет функционировать ваш сайт.
Индексация сайта
Упомянутые выше инструменты очень важны для успешного развития вашего проекта, и это вовсе не голословное утверждение. В статье про Sitemap xml (см
ссылку выше) я приводил в пример результаты очень важного исследования по наиболее частым техническим ошибкам начинающих вебмастеров, там на втором и третьем месте (после не уникального контента) находятся как раз отсутствие этих файлов роботс и сайтмап, либо их неправильное составление и использование
Почему так важно управлять индексацией сайта
Надо очень четко понимать, что при использовании CMS (движка) не все содержимое сайта должно быть доступно роботам поисковых систем. Почему?
- Ну, хотя бы потому, что, потратив время на индексацию файлов движка вашего сайта (а их может быть тысячи), робот поисковика до основного контента сможет добраться только спустя много времени. Дело в том, что он не будет сидеть на вашем ресурсе до тех пор, пока его полностью не занесет в индекс. Есть лимиты на число страниц и исчерпав их он уйдет на другой сайт. Адьес.
- Если не прописать определенные правила поведения в роботсе для этих ботов, то в индекс поисковиков попадет множество страниц, не имеющих отношения к значимому содержимому ресурса, а также может произойти многократное дублирование контента (по разным ссылкам будет доступен один и тот же, либо сильно пересекающийся контент), что поисковики не любят.
Хорошим решением будет запрет всего лишнего в robots.txt (все буквы в названии должны быть в нижнем регистре — без заглавных букв). С его помощью мы сможем влиять на процесс индексации сайта Яндексом и Google. Представляет он из себя обычный текстовый файл, который вы сможете создать и в дальнейшем редактировать в любом текстовом редакторе (например, Notepad++).
Поисковый бот будет искать этот файл в корневом каталоге вашего ресурса и если не найдет, то будет загонять в индекс все, до чего сможет дотянуться. Поэтому после написания требуемого роботса, его нужно сохранить в корневую папку, например, с помощью Ftp клиента Filezilla так, чтобы он был доступен к примеру по такому адресу:
https://ktonanovenkogo.ru/robots.txt
Кстати, если вы хотите узнать как выглядит этот файл у того или иного проекта в сети, то достаточно будет дописать к Урлу его главной страницы окончание вида . Это может быть полезно для понимания того, что в нем должно быть.
Однако, при этом надо учитывать, что для разных движков этот файл будет выглядеть по-разному (папки движка, которые нужно запрещать индексировать, будут называться по-разному в разных CMS). Поэтому, если вы хотите определиться с лучшим вариантом роботса, допустим для Вордпресса, то и изучать нужно только блоги, построенные на этом движке (и желательно имеющие приличный поисковый трафик).
Как можно запретить индексацию отдельных частей сайта и контента?
Прежде чем углубляться в детали написания правильного файла robots.txt для вашего сайта, забегу чуть вперед и скажу, что это лишь один из способов запрета индексации тех или иных страниц или разделов вебсайта. Вообще их три:
Важно понимать, что даже «стандарт» (валидные директивы robots.txt и одноименного мета-тега) являются необязательным к исполнению. Если робот «вежливый», то он будет следовать заданным вами правилам
Но вряд ли вы сможете при помощи такого метода запретить доступ к части сайта роботам, ворующим у вас контент или сканирующим сайт по другим причинам.
Вообще, роботов (ботов, пауков, краулеров) существует множество. Какие-то из них индексируют контент (как например, боты поисковых систем или воришек). Есть боты проверяющие ссылки, обновления, зеркалирование, проверяющие микроразметку и т.д.
Большинство роботов хорошо спроектированы и не создают каких-либо проблем для владельцев сайтов. Но если бот написан дилетантом или «что-то пошло не так», то он может создавать существенную нагрузку на сайт, который он обходит. Кстати, пауки вовсе на заходят на сервер подобно вирусам — они просто запрашивают нужные им страницы удаленно (по сути это аналоги браузеров, но без функции просмотра страниц).
Для чего нужна проверка robots.txt
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
- На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
- В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
- Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
- Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
- Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
- Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
- Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
- Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
- Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
Рекомендуемые статьи по данной теме:
- Проверка тИЦ сайта: 3 способа
- Внутренняя оптимизация сайта: пошаговый разбор
- Файл htaccess: применение, включение, настройка
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.
Оставить заявку
Вас также может заинтересовать: Что делать, если упала посещаемость сайта