Парсинг ключевых слов, бесплатные и платные варианты
Содержание:
- Получение содержимого сайта в командной строке
- Подготовка к парсингу сайтов в Excel (Google Таблице)
- Как работает парсинг, что это такое? Алгоритм работы парсера
- Очистка СЯ от «мусора»
- Зачем использовать программу Key Collector
- Типы специальных выражений для парсинга
- Способ 3. Подбор ключевых слов конкурентов с дальнейшим углублением
- Как получить нужные данные с помощью функции парсинга в Netpeak Spider
- Достоинства парсинга
- Основные понятия
- Видеоинструкция по оформлению заказа на парсер
- Как он работает?
- Как собирать ключевые слова
- Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
- Автоматически следовать редиректам с cURL
- Как пользоваться парсером Wordstat от Click.ru
- Постановка задачи
- Создание программы
- Виды парсеров по сферам применения
- Зачем нужен парсинг?
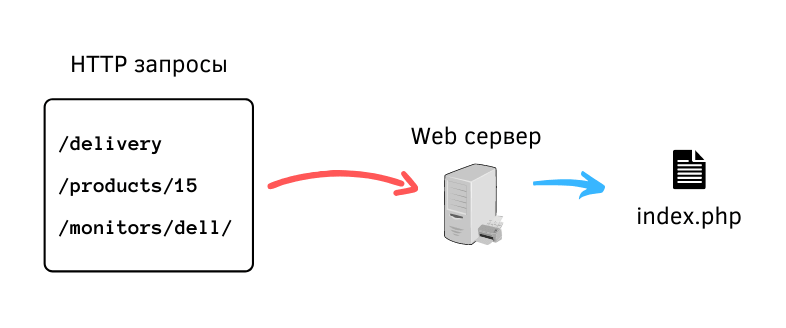
Получение содержимого сайта в командной строке
Самым простым способом получения содержимого веб-страницы, а точнее говоря, её HTML кода, является команда вида:
curl ХОСТ
В качестве ХОСТа может быть адрес сайта (URL) или IP. На самом деле, curl поддерживает много разных протоколов – но здесь мы говорим именно о сайтах.
Пример:
curl https://hackware.ru/
Хорошей практикой является заключать URL (ссылки на сайты и на страницы) в одинарные или двойные кавычки, поскольку эти адреса могут содержать специальные символы, имеющие особое значение для Bash. К таким символам относятся амперсант (&), решётка (#) и другие.
Чтобы в командной строке присвоить полученные данные переменной, можно использовать следующую конструкцию:
HTMLCode="$(curl https://hackware.ru/)" echo "$HTMLCode"
Здесь
HTMLCode – имя переменной (обратите внимание, что при присвоении (даже повторном) имя переменной пишется без знака доллара ($), а при использовании переменной, знак доллара всегда пишется.
=»$(КОМАНДА)» – конструкция выполнения КОМАНДЫ без вывода результата в консоль; результат выполнения команды присваивается переменной
Обратите внимание, что ни до, ни после знака равно (=) нет пробелов – это важно, иначе возникнет ошибка.. Также полученное содержимое веб-страницы зачастую передаётся по трубе для обработке в других командах:
Также полученное содержимое веб-страницы зачастую передаётся по трубе для обработке в других командах:
КОМАНДА1 | КОМАНДА2 | КОМАНДА3
Реальные примеры даны чуть ниже.
Подготовка к парсингу сайтов в Excel (Google Таблице)
Для того, чтобы начать парсить сайты потребуется в первую очередь перейти в Google Sheets, что можно сделать открыв страницу:
https://www.google.com/intl/ru_ru/sheets/about/

Потребуется войти в Google Аккаунт, после чего нажать на «Создать» (+).

Теперь можно переходить к парсингу, который можно выполнить через 2 основные функции:
- IMPORTXML. Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;
- IMPORTHTML. Позволяет получить данные из таблиц и списков.
Однако, все эти методы работают на основе ссылок на страницы, если таблицы с URL-адресами нет, то можно ускорить этот сбор через карту сайта (Sitemap). Для этого добавляем к домену сайта конструкцию «/robots.txt». Например, «seopulses.ru/robots.txt».
Здесь открываем URL с картой сайта:

Нас интересует список постов, поэтому открываем первую ссылку.
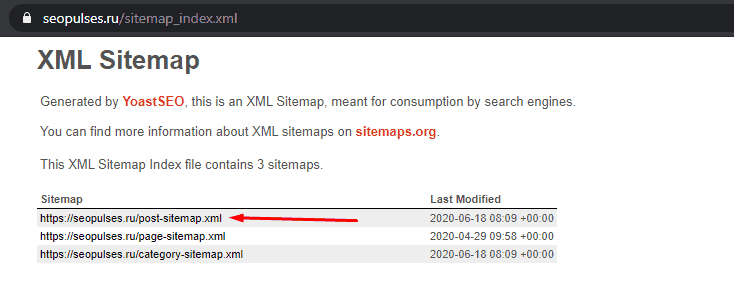
Получаем полный список из URL-адресов, который можно сохранить, кликнув правой кнопкой мыши и нажав на «Сохранить как» (в Google Chrome).

Теперь на компьютере сохранен файл XML, который можно открыть через текстовые редакторы, например, Sublime Text или NotePad++.

Чтобы обработать информацию корректно следует ознакомиться с инструкцией открытия XML-файлов в Excel (или создания), после чего данные будут поданы в формате таблицы.

Все готово, можно переходить к методам парсинга.
Как работает парсинг, что это такое? Алгоритм работы парсера
Независимо от того на каком формальном языке программирования написан парсер, алгоритм его действия остается одинаковым:
- выход в интернет, получение доступа к коду веб-ресурса и его скачивание;
- чтение, извлечение и обработка данных;
- представление извлеченных данных в удобоваримом виде – файлы .txt, .sql, .xml, .html и других форматах.
В интернете часто встречаются выражения, из которых следует, будто парсер (поисковый робот, бот) путешествует по Всемирной сети. Но зачастую эта программа никогда не покидает компьютера, на котором она инсталлирована.
Этим парсер коренным образом отличается от компьютерного вируса – автономной программы, способной к размножению, хотя по сути своей работы он похож на трояна. Ведь он получает данные, иногда конфиденциального характера, не спрашивая желания их владельца.
Очистка СЯ от «мусора»
Покажем, как это делать в Key Collector.
Ключевики, которые содержат ненужные слова
Нажимаем вкладку выбора условий фильтрации:
Задаем условие, как указано на скриншоте, и пишем слова:
Отмечаем фразы и добавляем в корзину:
Повторы слов
Аналогично вызываем настройки фильтрации фраз и выбираем такой вариант:
Стоп-слова (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.)
Нажимаем этот значок в верхнем меню:
В окне настроек добавляем фразы (1) и разбиваем по группам (2):
Далее — выделяем слова в таблице галочкой и добавляем в список стоп-слов.
Группы слов
Чтобы разбить запросы на группы, на вкладке «Данные» открываем «Анализ групп». В окне выбираем тип «По отдельным словам»:
Выбранные группы появятся в основном списке запросов, где можно отсеять все ненужные.
Запросы с нулевой частотностью
Выбираем следующее условие фильтрации:
Далее — требования по частоте:
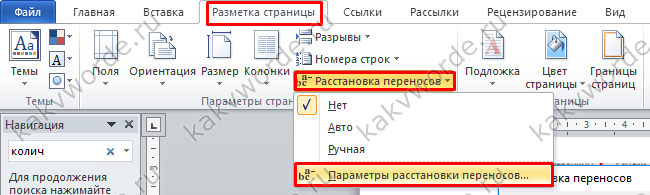
Можно удалить нецелевые запросы и вручную: копируем ключевики в Word. Заменяем пробел на знак абзаца, чтобы представить все слова из словосочетаний в виде колонки. Переносим обратно в Excel на отдельный лист, сортируем и определяем минус-слова. Затем находим с помощью фильтра фразы с ними и удаляем.
На какие вопросы машинный интеллект не дает ответы
Сбор семантики быстрее и проще с помощью различных сервисов, баз, приложений — благо, выбор есть. Однако нельзя слепо полагаться на автоматизацию. Есть два случая, когда без ручного труда не обойтись. Уже при подборе масок нужно «вытаскивать» синонимы и переформулировки из сайтов заказчика и конкурентов, правой колонки Wordstat, собственных идей и т.д. Мы увидели, что это всё предстоит делать специалисту по контекстной рекламе. Самый трудозатратный и не автоматизируемый процесс — очистка СЯ от «мусора». Готовых минус-списков и данных об отказах из Яндекс.Метрики недостаточно для 100% точности. Приходится смотреть предварительные списки и выявлять смысловое соответствие результатов бизнесу. Особенно это касается сложных продуктов. Например, подготовка сжатого воздуха, или осушка воздуха. Больше расширений можно насобирать по слову «осушка». Но среди результатов в Wordstat в мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Не всегда семантическое соответствие гарантирует смысловое соответствие. Это разные продукты, а значит, разный спрос. Чаще всего выявить и исключить его можно только вручную. Если вы не проверяете результаты парсинга, вы жертвуете полнотой СЯ и точностью будущих рекламных кампаний. Совет: выбирайте оптимальный баланс «трудозатраты — полнота» и делайте полный список минус-слов.
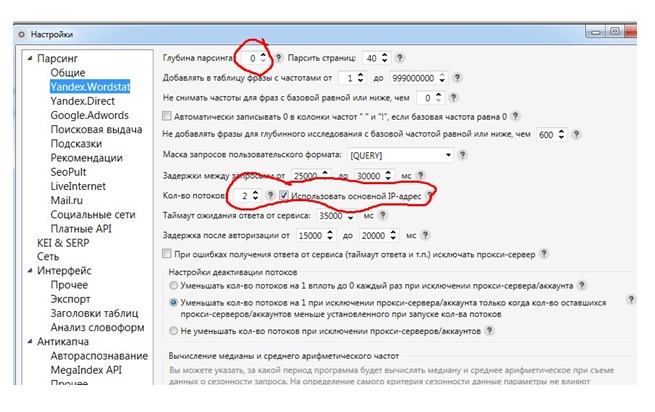
Зачем использовать программу Key Collector
Если вы хотите написать одну статью, то подобрать для нее ключи можно с помощью описанных выше онлайн сервисов.
Но если вы наполняете содержимым целый сайт или хотите оказывать услуги по составлению семантического ядра, то без Key Collector вам не обойтись, так как этот софт может собирать статистику, рассчитывать конкуренцию, работать с поисковыми подсказками, другими сервисами и т.д.
Согласитесь, что намного проще открыть одну программу и работать только там, чем ходить по десяткам сайтов и где-то хранить полученные запросы.
А так я в Кей Коллекторе провожу парсинг и там же создаю группы, куда заношу полученные ключи для будущих статей.
Как найти ключи, определить частотность и уровень конкуренции
Работу в программе условно можно разделить на 2 способа:
- Парсинг ключей с помощью платных сервисов
- Парсинг ключей бесплатным Вордстатом
Первый способ. Так как программа универсальная, то в нее можно интегрировать такие сервисы для сбора ключей и статистики: SEMrush, SpyWords, Mutagen, Serpstat, MOAB.
Только предварительно не забудьте пройти регистрацию в том сервисе через который и будет происходить сбор данных. После чего в «Настройках» далее «Парсинг» далее «Платные API» указываем логи, пароль или токен.
После чего запускаем парсинг и указываем запрос, по которому надо собирать ядро.
В качестве примера был взят сервис Мутаген.
Как видим Мутаген все равно для парсинга будет использовать статистику от Яндекс Вордстат, поэтому не вижу смысла платить за это дополнительные деньги.
Ах да, так как сервисы платные, за каждую строчку будьте готовы потратить определенную сумму:
Цены на анализ запросов в Мутагене:
- Проверка конкуренции: 100 проверок — 30 руб.
- Парсер вордстат: 1 запрос — 0.02 руб.
Теперь представьте, если таких запросов будет 10 000, а если 100 000?
Второй способ.
Куда проще пользоваться бесплатным способом, это собирать ключевые слова и проверять конкуренцию через Yandex Wordstat.
Указали ключ и начинаем сбор. Все остальное сделает программа.
Единственное, что может принести неудобство, это когда при частом обращении к Яндексу, последний захочет убедиться, что вы не робот и покажет вам капчу.
Поэтому чтобы не отвлекаться на ее ввод, тем более если вы будите работаться с большим количеством слов, то лучше подключить к программе систему автоматического распознавания капчи.
Лично я для этого использую сервис ruCaptcha, где нам надо в настройках аккаунта получить API Key.
Кстати, если вы не хотите платить, то можете сначала заработать на разгадывании капчи. Лично я так и сделал, о чем рассказал в видео ниже.
Далее переходим в настройки Кей Коллектор и в меню «Антикапча» отмечаем пункт «Использовать ruCaptcha» и в поле настроек вводим полученный в личном кабинете API.
Теперь если в процессе парсинга будет встречаться капча, Key Collector не будет останавливаться, а сервис Рукапча все сделает за вас.
Как видно в ходе парсинга была разгадана 1 капча, а напротив отображается баланс, чтобы его было легче контролировать.
Если по ценам, то тут все очень даже лояльно:
Как видите, за очень малые деньги можно собирать СЯ с помощью стандартных функций программы, без подключения дорогих сервисов.
Типы специальных выражений для парсинга
Для парсинга данных применяются специальные выражения. Они позволяют программе искать тот или иной тип данных для извлечения. В зависимости от сложности задачи применяют такие паттерны:
- CSS-селекторы — паттерны, позволяющие выбрать нужные элементы разметки, как правило, для их последующей стилизации (но не в случае с парсингом).
- XPath — специальный язык запросов, с помощью которого можно извлечь содержимое какого-либо тега или атрибута по его адресу в исходном коде HTML-страницы.
- Regexp — язык, с помощью которого задаётся последовательность символов (паттерн), которая определяет, какой тип строки необходимо искать на странице.
Парсинг с помощью CSS-селекторов — самый простой и наиболее удобный метод парсинга. С их помощью можно решить примерно 95% всех задач, связанных с парсингом данных. Я вкратце расскажу о том, как их использовать.
Способ 3. Подбор ключевых слов конкурентов с дальнейшим углублением
Этот способ заключается в следующем: собираем ключевые слова, под которые оптимизированы сайты ваших конкурентов, а затем углубляем семантику. Таким образом мы можем собрать ключевые слова, которые упустили.
Собрать семантику конкурентов и углубить можно с помощью платформы PromoPult. Зарегистрируйте аккаунт (это бесплатно), создайте проект. На этапе выбора инструмента кликните по инструменту «Поисковое продвижение SEO».

На следующем этапе укажите URL вашего сайта, регион, а также укажите название проекта.

Нажмите «Создать проект». Система переведет вас на следующий шаг и автоматически подберет запросы, по которым страницы вашего сайта ранжируются в топ-50 Яндекс и/или Google. С этой семантикой также можно поработать и подобрать фразы «с хвостами». Но мы будем собирать семантику конкурентов, поэтому переключаемся на вкладку «Слова ваших конкурентов».
Добавляем адреса сайтов, с которых хотим собрать семантику, затем жмем «Показать слова всех конкурентов».

Система проанализирует сайты, URL которых вы указали, и покажет список найденных ключевых слов.
Просмотрите список и выберите слова, которые будете использовать для углубления семантики. Проставьте на этих словах галочки и добавьте к опорному списку (на его основе мы будем расширять семантику).
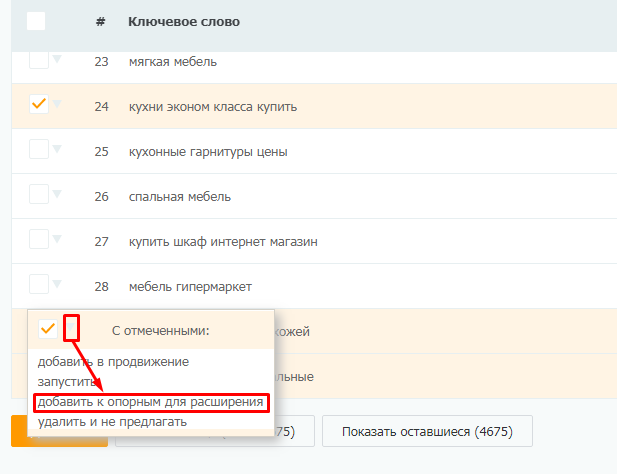

В профессиональном режиме можно по-разному работать с опорными словами – например, спарсить левую колонку Яндекс.Вордстата или подобрать фразы-ассоциации (с правой колонки Вордстата).
Мы добавили в опорный список 5 фраз и будем использовать для углубления семантики инструмент «СЧ+НЧ».

Результат: система подобрала 2186 ключевых фраз (обратите внимание, в опорном списке было всего пять фраз). Подобранные ключи можно добавить в опорный список и снова использовать инструмент «СЧ+НЧ», углубляя семантику уже по собранным запросам
После того как вы соберете достаточное количество ключей, выгрузите их с помощью функции экспорта.
Обратите внимание! Сбор семантики конкурентов и ее углубление в PromoPult бесплатны. Весь функционал доступен без ограничений – можно запускать любое количество проверок и собирать любое количество ключевых слов
Как получить нужные данные с помощью функции парсинга в Netpeak Spider
Итак, все выражения для парсинга подобраны. Теперь необходимо проделать следующие действия:
- Откройте Netpeak Spider.
-
Зайдите в настройки, откройте вкладку «Парсинг» и задайте подобранные условия.
Перед запуском сканирования хочу поделиться небольшим лайфхаком.
Программа по умолчанию анализирует много On-Page параметров, так как они необходимы для SEO-аудита. Для парсинга всё это не нужно. Разработчики позаботились о возможности включить только те параметры, которые вы считаете нужными для своей задачи. Перейдите на вкладку «Параметры», включите параметры парсинга и параметр «Код ответа сервера», а остальное отключите.
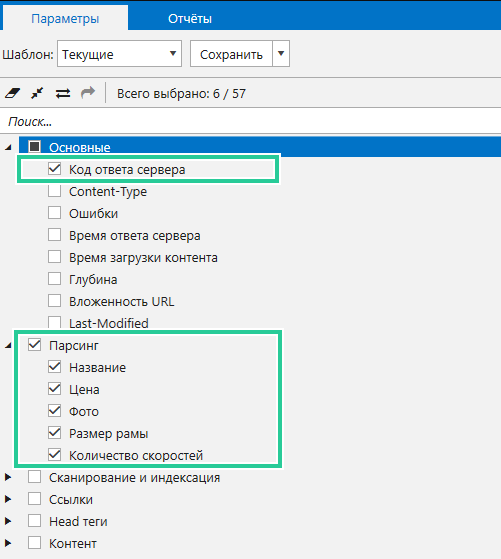
Как только сканирование будет завершено, в основной таблице вы найдёте значения найденных данных по заданным условиям.

При нажатии на число откроется окно с найденным значением. Полный отчёт по парсингу можно открыть несколькими способами:
- Через пункт меню «База данных» → «Сводка по парсингу».
- Через вкладку «Парсинг» на боковой панели → «Все результаты».
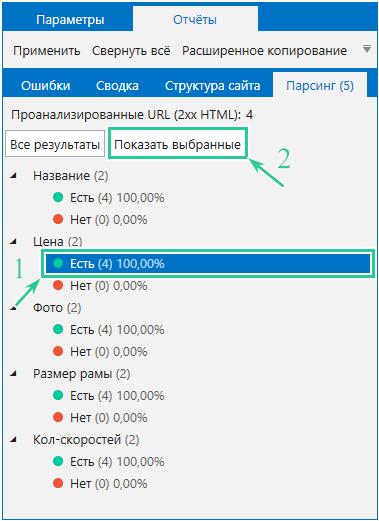
Дополнительно можно открыть отчёт по конкретному параметру на вкладке «Парсинг» боковой панели программы.
Кстати, в программе есть удобная функция, позволяющая буквально в два клика фильтровать данные, — сегментация.
Представим, что после парсинга цен из какого-либо раздела на сайте была найдена 291 страница с ценой и 197 страниц без цены. Получается, в отчёте по парсингу будет много пустых ячеек в колонке «Цена», которые будут мешать. Однако если выбрать группу страниц, содержащих цену, и применить её как сегмент, то программа исключит все страницы без цен и покажет отчёт только по выбранной группе.

Читайте подробнее в посте → «Что такое сегментация в Netpeak Spider, и как её использовать».
Отчёт перед использованием сегментации:

И после:

Достоинства парсинга
Приложения с функцией парсинга оснащены положительными сторонами, которые делают ресурс более прибыльным:
- программы для парсинга могут осуществить молниеносный мониторинг десятков тысяч станиц на страницах Интернета;
- умная программа разложит по полочкам – разделит нужные данные и техническую информацию;
- программы используют метод выборки по настроенным параметрам – останется только нужная информация;
- осуществляется выгрузка информации в удобном формате и виде.

Разновидность форматов
Разумеется, после выгрузки данных необходимо проработать их и перепроверить. Это легче, чем заниматься сутками ручным поиском необходимой информации
Самое важное – экономия энергии и времени
Основные понятия
- входной символьный поток (далее входной поток или поток) — поток символов для разбора, подаваемый на вход парсера
- parser/парсер (разборщик, анализатор) — программа, принимающая входной поток и преобразующая его в AST и/или позволяющая привязать исполняемые функции к элементам грамматики
- AST(Abstract Syntax Tree)/АСД(Абстрактное синтаксическое дерево) (выходная структура данных) — Структура объектов, представляющая иерархию нетерминальных сущностей грамматики разбираемого потока и составляющих их терминалов. Например, алгебраический поток (1 + 2) + 3 можно представить в виде ВЫРАЖЕНИЕ(ВЫРАЖЕНИЕ(ЧИСЛО(1) ОПЕРАТОР(+) ЧИСЛО(2)) ОПЕРАТОР(+) ЧИСЛО(3)). Как правило, потом это дерево как-то обрабатывается клиентом парсера для получения результатов (например, подсчета ответа данного выражения)
- CFG(Context-free grammar)/КСГ(Контекстно-свободная грамматика) — вид наиболее распространенной грамматики, используемый для описания входящего потока символов для парсера (не только для этого, разумеется). Характеризуется тем, что использование её правил не зависит от контекста (что не исключает того, что она в некотором роде задает себе контекст сама, например правило для вызова функции не будет иметь значения, если находится внутри фрагмента потока, описываемого правилом комментария). Состоит из правил продукции, заданных для терминальных и не терминальных символов.
- Терминальные символы (терминалы) — для заданного языка разбора — набор всех (атомарных) символов, которые могут встречаться во входящем потоке
- Не терминальные символы (не терминалы) — для заданного языка разбора — набор всех символов, не встречающихся во входном потоке, но участвующих в правилах грамматики.
- язык разбора (в большинстве случаев будет КСЯ(контекстно-свободный язык)) — совокупность всех терминальных и не терминальных символов, а также КСГ для данного входного потока. Для примера, в естественных языках терминальными символами будут все буквы, цифры и знаки препинания, используемые языком, не терминалами будут слова и предложения (и другие конструкции, вроде подлежащего, сказуемого, глаголов, наречий и т.п.), а грамматикой собственно грамматика языка.
-
BNF(Backus-Naur Form, Backus normal form)/БНФ(Бэкуса-Наура форма) — форма, в которой одни синтаксические категории последовательно определяются через другие. Форма представления КСГ, часто используемая непосредственно для задания входа парсеру. Характеризуется тем, что определяемым является всегда ОДИН нетерминальный символ. Классической является форма записи вида:
Так же существует ряд разновидностей, таких как ABNF(AugmentedBNF), EBNF(ExtendedBNF) и др. В общем, эти формы несколько расширяют синтаксис обычной записи BNF. - LL(k), LR(k), SLR,… — виды алгоритмов парсеров. В этой статье мы не будем подробно на них останавливаться, если кого-то заинтересовало, внизу я дам несколько ссылок на материал, из которого можно о них узнать. Однако остановимся подробнее на другом аспекте, на грамматиках парсеров. Грамматика LL/LR групп парсеров является BNF, это верно. Но верно также, что не всякая грамматика BNF является также LL(k) или LR(k). Да и вообще, что значит буква k в записи LL/LR(k)? Она означает, что для разбора грамматики требуется заглянуть вперед максимум на k терминальных символов по потоку. То есть для разбора (0) грамматики требуется знать только текущий символ. Для (1) — требуется знать текущий и 1 следующий символ. Для (2) — текущий и 2 следующих и т.д. Немного подробнее о выборе/составлении BNF для конкретного парсера поговорим ниже.
- PEG(Parsing expression grammar)/РВ-грамматика — грамматика, созданная для распознавания строк в языке. Примером такой грамматики для алгебраических действий +, -, *, / для неотрицательных чисел является:
Видеоинструкция по оформлению заказа на парсер
(смотреть на YouTube)
Чтобы заказать парсер сайта, отправьте на почту order@excelvba.ru
письмо с темой «Заказ парсера сайта», и в этом письме:
1) прикрепите ПРИМЕР РЕЗУЛЬТАТА в виде файла Excel,
содержащий строку заголовка, и как минимум одну строку с данными
Посмотреть пример файла Excel

Пожелания к оформлению файла-примера
- если файл содержит исходные данные (например, список ссылок или артикулов, по которым надо загружать данные) — в примере должно быть минимум 20-30 строк с исходными значениями (пример результата — в доп столбцах — может быть прописан для одной строки, но исходных значений, для тестирования парсера, должно быть несколько, — чем больше, тем лучше)
- расположите столбцы в нужном порядке, — именно в таком виде парсер будет выдавать результат
- если хотите, чтобы программа автоматически создавала / сохраняла файл результата, — укажите, в какой папке под каким именем сохранять
- пример нужен в виде файла Excel или CSV (а не скриншот). Если CSV нужен для импорта на сайт, — прикрепите пример файла CSV в нужной кодировке.
2) опишите, с какого сайта какие данные нужно брать
Интересует не только адрес сайта, — но и как найти на сайте нужные данные (например, получить полный список всех товаров)
Касательно возможных ограничений сайта (лимиты, капча, и пр.)
Такое встречается очень редко (только для порталов с огромной посещаемостью, — типа Google, Яндекс, Авито, Beru, Ozon, и т.п.), — но, тем не менее, я всегда об этом предупреждаю:
Парсер — не какая-то волшебная программа, которая сможет обойти ограничения, сделанные для людей.
Если сайт выдаёт капчу (требует ввести текст с картинки) — потребуется настраивать автораспознавание капчи, или же пользователю парсера придётся вводить этот текст во всплывающем окне (наличие капчи усложняет настройку, что сказывается на стоимости)
Если сайт позволяет загрузить не более 100 страниц в сутки, — парсер не сможет обойти это ограничение (в таких случаях, иногда настройка парсера становится бессмысленной)
Потому, если вы знаете о каких-то ограничениях сайта, — сразу укажите это при заказе (чтобы можно было оценить сложность и возможность получения необходимых данных с сайта)
После отправки заказа парсера на почту order@excelvba.ru,
с вами свяжется наш сотрудник, который займётся настройкой парсера для вас, — с ним уже обсудите нюансы (если из задания будет не всё понятно) и стоимость настройки.
Как он работает?
Для того, чтобы он начал работать — его нужно немного обучить. Для этого нужно воспользоваться селекторами.
У нас есть селекторы групп, товаров, всех вышеуказанных реквизитов товара и селекторы атрибутов.
Для того, чтобы указать селектор — достаточно открыть интересующий нас сайт в браузере Google Chrome, нажать F12 (инструменты разработчика), выбрать интересующий нас элемент и скопировать его селектор. Ниже будет видео как это сделать. При этом не обязательно, но совсем неплохо будет иметь базовые знания HTML.
При необходимости мы можем поменять обработчик узла, который был найден селектором. Это открывает для нас по-настоящему широкие возможности. Обработчик приходится менять не часто, но приходится и чтобы его правильно задать необходим базовый набор знаний в программировании 1С.
Если у Вас нет базовых знаний HTML и/или программирования 1С — советую обратить внимание на версию с начальными настройками. Вы просто скажите какой сайт Вам нужен, а я сделаю файл настроек
Вам останется только нажать несколько кнопок.
А как насчет нажатия всего одной кнопки «Записать в 1С»? Тоже возможно. Для этого будет версия обработки + настройки + заполненные таблицы. Это самый дорогой, но самый верный вариант получить результат. До 4000 товаров. Свыше 4000 — 1 р./товар
Как собирать ключевые слова
Для Рунета основным источником ключевых слов является сервис Wordstat от ПС Яндекс.
Запросов от Google, как правило, получается гораздо меньше и поэтому они чаще используются на этапе сбора базовых запросов. Как результат, в подавляющем большинстве случаев парсят Вордстат и этого бывает вполне достаточно.
Если же у Вас какая-то узкая ниша и надо обеспечивать максимальную полноту, тогда можно подключать сервисы Google и/или базы запросов.
Процедура парсинга запросов в облачных сервисах проходит довольно просто. Например, для Rush-Analytics необходимо задавать следующие параметры:
- Настроить проект в сервисе.
- Установить региональность.
- Выбрать пункт «Собрать ключевые слова».
- Загрузить список Базовых Запросов.
- Загрузить список минус-слов, если они у Вас уже есть.
- Инициировать работу парсера по сбору ключевых фраз.
Более наглядно этот процесс можно увидеть в этом небольшом видеоролике.
У меня первый прогон обычно используется для формирования списка минус слов. Выгружаю полученный результат и методом пристального взора составляю список таких слов.
Второй прогон, с учетом собранных минусов, уже будет более результативным и список ключей будет содержать гораздо меньше мусорных запросов. Тем не менее мы опять просматриваем полученные ключи, чистим мусор, пополняем список минус-слов и у нас все готово для следующего шага — сбора подсказок.
Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
Создайте аккаунт в системе PromoPult (или авторизуйтесь, если у вас уже есть аккаунт). Откройте инструмент «Слова и объявления конкурентов». В блоке «Добавить задачу» укажите домены конкурентов или загрузите их с помощью XLSX-файла.
Блок профессиональных настроек пока не трогаем (мы еще разберем его).
В блоке «Поисковые системы» можно выбрать, в какой поисковой системе проверять домены. По умолчанию это Яндекс и Google. Также по умолчанию стоит галочка на пункте «Результаты на едином листе XLS» – в таблице с результатами данные по всем доменам будут сведены на одном листе.
Если вы проверяете небольшое количество доменов (до 5), можете ничего не менять здесь. Если же доменов больше, уберите галочку с этого пункта. В результатах парсинга под каждый домен будет создан отдельный лист – это удобнее для анализа большого количества данных.
Жмем «Запустить проверку». Система начнет парсинг доменов (в нашем случае на это ушло 5 минут). Если у вас нет времени ждать, вы можете закрыть страницу с инструментом – все работы проводятся в фоновом режиме.
После окончания проверки вам на почту придет уведомление:
Раскройте блок «Список задач» и кликните по пиктограмме Excel-таблицы, чтобы скачать отчет. Также здесь можно удалить отчет или запустить повторный парсинг.
В настройках парсинга есть возможность выбрать отображение отчета: отдельный лист для каждого домена или все на одном листе.
В зависимости от этой настройки отчет будет выглядеть по-разному.
Отчет по каждому домену на разных листах
В нашем примере мы получили именно такой отчет. При скачивании загружается архив с файлами в формате CSV:
Что содержит архив:
Файл с уникальными ключевиками для всех конкурентов. Для пяти доменов, которые мы добавляли в проверку, парсер собрал почти 32 000 ключей.
Общие результаты – данные по количеству объявлений на поиске Google и Яндекс. Для каждого домена данные указаны в разрезе регионов.
Технический файл, в котором указаны настройки парсинга.
Файлы с названиями доменов. Содержат ключевые слова конкурентов, заголовки и тексты объявлений. Данные указаны в разрезе поисковых систем и регионов. Например, вы можете посмотреть, какие объявления показывает конкурент в Яндексе в Санкт-Петербурге.
Обратите внимание! При парсинге объявления собираются из результатов поисковой выдачи в таком виде, в котором они отображаются. Кроме основного текста и заголовка могут собираться уточнения, быстрые ссылки и другие расширения (если они есть в объявлении)
Данные по доменам на одном листе
При таком способе отображения отчета загружается один XLSX-файл с четырьмя листами. Даже если вы парсите 50 доменов, листов в файле все равно будет четыре. Какие это листы:
«Результаты общие» – количество уникальных объявлений по всем доменам. Данные указаны в разрезе регионов и поисковых систем.
- «Слова и объявления». На этом листе собрана семантика по всем конкурентам и тексты объявлений. Данные указаны по каждому региону и поисковой системе. Если доменов много, работать с такой таблицей будет неудобно.
- «Слова». Собраны уникальные ключевики по всем доменам.
- «Исх. настройки». Указаны настройки парсинга.
Автоматически следовать редиректам с cURL
Вы можете дать указание cURL следовать редиректам, т.е. открывать страницу, на которую делает редирект (перенаправление) та страница, которую мы в данный момент пытаемся открыть.
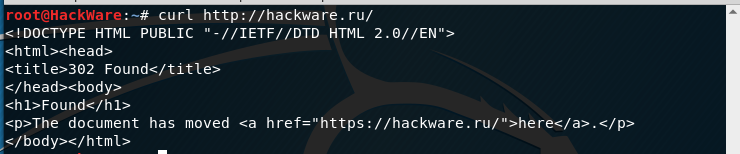
Например, если я попытаюсь открыть сайт следующим образом (обратите внимание на HTTP вместо HTTPS):
curl http://hackware.ru/
То я получу:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>302 Found</title> </head><body> <h1>Found</h1> <p>The document has moved <a href="https://hackware.ru/">here</a>.</p> </body></html>
Чтобы curl переходила по перенаправлением используется опция -L:
curl -L http://hackware.ru/
Как пользоваться парсером Wordstat от Click.ru
В числе инструментов Click.ru как раз есть функциональный и недорогой парсер Wordstat. Он быстро выдает частотность даже по большому списку запросов. При этом учитывает типы соответствия и региональность. Еще не требует капчу и прокси-серверы, а отчеты позволяет выгружать в Excel и хранить в «облаке».
Для начала работы зарегистрируйтесь в системе Click.ru. После входа в свой аккаунт на главной странице выберите раздел «Парсер частоты Wordstat» и приступайте к работе.
 Для начала парсинга перейдите в соответствующий раздел
Для начала парсинга перейдите в соответствующий раздел
Как работать с парсером Wordstat после регистрации в Click.ru:
Загрузите список запросов.
Есть два способа: скопировать и вставить ключи в специальное поле или же загрузить XLSX-файл с ними.
При копировании списка учитывайте, что каждый ключ должен идти с новой строки. А в эксель-файле смотрите, чтобы не было вспомогательной информации (названий столбцов, лишних цифр и т. д.). Система берет запросы из первого листа .XLSX по принципу «одна ячейка – один ключ».
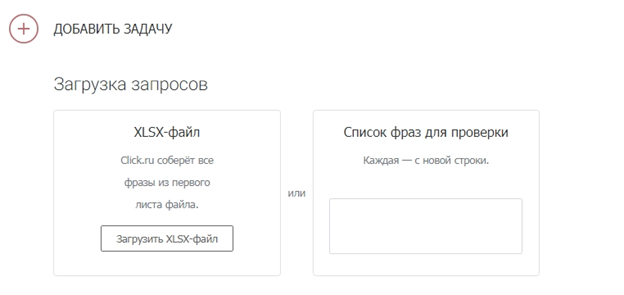 Этап загрузки запросов
Этап загрузки запросов
Выберите регионы.
В системе доступны все регионы Яндекса. Можно посчитать общую частотность по нескольким регионам или получить статистику отдельно по каждому.
Разделять регионы в отчете нужно, если вы планируете продвигать бизнес отдельными региональными поддоменами и посадочными страницами, привязанными к географии. В остальных случаях галочка не ставится.
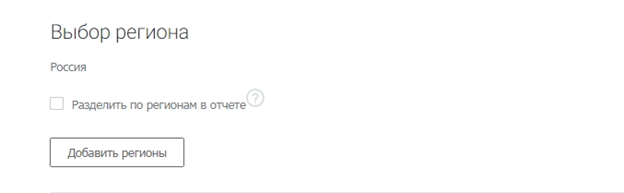 Выбираем регионы
Выбираем регионы
Укажите тип соответствия.
Широкое соответствие – когда фразы пробиваются как есть – часто показывает обманчивую частотность. Все из-за того, что учитываются все вложенные ключи, в том числе нерелевантные (как в примере с игрушками). То есть всегда лучше перепроверять частоту запроса с помощью специальных операторов.
Кавычки позволяют уточнять статистику по конкретной фразе, без учета вложенных ключей.
Пример
| скачать видео бесплатно – 1 111 285 показов | “скачать видео бесплатно” – 8 493 показа |
Кавычки с восклицательными знаками показывают частотность по заданным словоформам.
Пример
| “!купить !телефон” – 37 909 показов | “!купить !телефоны” – 2 798 показов |
Квадратные скобки – фиксируют порядок слов, что особенно важно в туристическом бизнесе
Пример
| – 4 213 показов | – 1 814 показов |
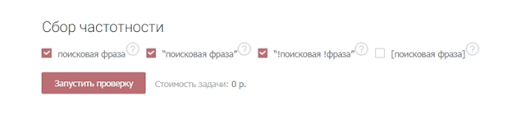 Все варианты типов соответствия
Все варианты типов соответствия
Запустите проверку.
Время сбора частотностей зависит от количества запросов, регионов и типов соответствия. Если запросов меньше 1 000, процесс займет 1–2 минуты.
Результат будет доступен в списке задач. Можно открыть отчет в браузере или скачать его в формате XLSX.
 Здесь будут появляться отчеты со статистикой
Здесь будут появляться отчеты со статистикой
Постановка задачи
По работе мне требуется распознать текст из печатного документа, сфотографированного камерой смартфона/планшета. Из-за соглашения о неразглашении информации я не могу привести пример фотографии, но суть в том, что в документе имеется таблица, в которой записаны некие показатели числом и прописью, и эти данные необходимо прочитать. Парсинг текста прописью необходим как дополнительный инструмент валидации, чтобы убедиться, что число распознано верно. Но, как известно, OCR не гарантирует точного распознавания текста. Например, число двадцать, записанное прописью, может быть распознано как «двадпать» или даже как «двапать». Нужно это учесть и извлечь максимальное количество информации, оценив величину возможной ошибки.
Примечание. Для распознавания текста я использую tesseract 4. Для .NET нет готового NuGet-пакета четвертой версии, поэтому я создал такой из ветки основного проекта, может кому пригодится: Genesis.Tesseract4.
Создание программы
Чтобы создать программу парсинга не нужно быть гуру программирования – достаточно усвоить моменты:
При создании алгоритма действий для программы важно внимательно изучить код web-страницы, которая числится донором. Да, здесь нужны хотя бы средние знания о том, что такое верстка и с чем ее едят
Знакомы слова CSS, HTML, JavaScript? Отлично, двигаемся дальше. Для тех, кому этого мало есть вариант глубокого изучения – DOM. Фишка технологии в возможности работы с иерархией web-страниц. Ну и конечно, само написание парсера. Здесь нужны владения навыком обработки текста.

CSS, HTML, JavaScript
Предположим, что программа уже есть и самое время начать работу.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Зачем нужен парсинг?
Сбор информации в интернете – трудоемкая, рутинная, отнимающая много времени работа. Парсеры, способные в течение суток перебрать большую часть веб-ресурсов в поисках нужной информации, автоматизируют ее.
Наиболее активно «парсят» всемирную сеть роботы поисковых систем. Но информация собирается парсерами и в частных интересах. На ее основе, например, можно написать диссертацию. Парсинг используют программы автоматической проверки уникальности текстовой информации, быстро сравнивая содержимое сотен веб-страниц с предложенным текстом.
Возможностью «спарсить» чужой контент для наполнения своего сайта пользуются многие веб-мастера и администраторы сайтов. Это оправдано, если требуется часто изменять контент для представления текущих новостей или другой, быстро меняющейся информации.
Парсинг – «палочка-выручалочка» для организаторов спам-рассылок по электронной почте или каналам мобильной связи. Для этого им надо запустить «бота» путешествовать по социальным сетям и собирать «телефоны, адреса, явки».
Ну и хозяева некоторых, особенно недавно организованных веб-ресурсов, любят наполнить свой сайт чужим контентом. Правда, они рискуют, поскольку поисковые системы быстро находят и банят любителей копипаста.