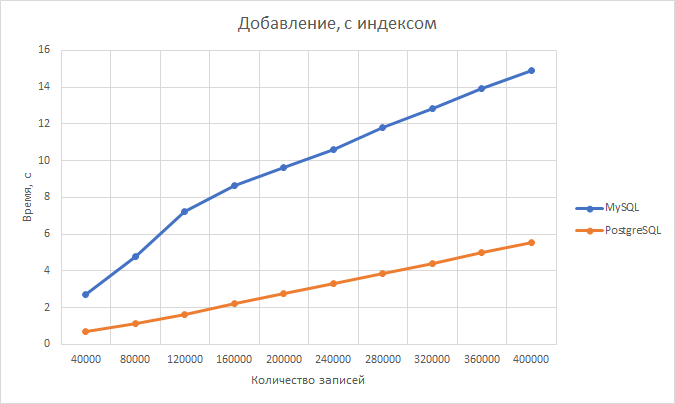
Data access layer как инструмент управления хранением данных
Содержание:
- 5 последних уроков рубрики «Разное»
- Основные недостатки
- Как осуществляется анализ клиентской базы
- Планы на будущее
- Хранение ссылок на объекты
- Работа с клиентской базой
- Системы Управления Базами Данных
- Вставка (INSERT)
- Разные базы — разные правила
- Структура Data Access Layer
- История
- Шаг 2. Избавляемся от дубликатов в столбцах
- Отличия RDBMS от обычной СУБД
- Доля рынка
- Django Admin
- Язык структурированных запросов (SQL)
- Недостатки RDBMS
5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.
Основные недостатки
Помимо невысокой эффективности, о которой было сказано ранее, к недостаткам традиционных реляционных СУБД можно отнести факт того, что в качестве основного и, часто, единственного механизма, обеспечивающего быстрый поиск и выборку отдельных строк таблице (или в связанных через внешние ключи таблицах), обычно используются различные модификации индексов, основанных на B-деревьях. Такое решение оказывается эффективным только при обработке небольших групп записей и высокой интенсивности модификации данных в базах данных.
Реляционные СУБД все еще доминируют в системах обработки финансовых транзакций, но сегодня компании все шире применяют СУБД новой архитектуры NoSQL — горизонтально масштабируемые, распределенные и разрабатываемые в открытых кодах. Примеры таких систем — Hadoop, MapReduce и VoltDB. По оценкам аналитиков Forrester, около 75% данных на предприятиях это либо полуструктурированная информация (XML, электронная почта и EDI), либо неструктурированная (текст, изображения, аудио и видео), и лишь 5% от этих данных хранится в реляционных СУБД, а остальное — в базах других типов или в виде файлов, и неподвластно обработке реляционными системами.
По мнению Блора, реляционные СУБД «могут умереть так, что этого никто не заметит» — например, если Oracle в своей СУБД попросту заменит SQL-механизм на NoSQL. Таким механизмом, считает аналитик, могла бы стать одна из существующих сегодня столбцовых СУБД.
Как осуществляется анализ клиентской базы
Распространено несколько способов анализа клиентской базы.
1. Recеncy Frequеncy Monеtary (RFM-анализ).
Данный подход основывается на том, что клиентская база формируется по принципу ранжирования, где каждый потребитель имеет определенные показатели:
- Recency — новизна (чего-либо);
- Frequency —как часто или в каком объеме происходит что-либо (например, покупка);
- Monetary — размер выручки.
Этот метод анализа клиентской базы строится на утверждении, что человек, который совершает определенные действия, сообщает ими о своей лояльности к вашей коммерческой организации. В числе таких действий: недавняя или крупная покупка, много приобретений и т. д.
2. ABC-анализ клиентов.
Данный метод основан на принципе Парето. Выделяются в клиентской базе три группы:
- А (75 %) — наиболее ценные клиенты;
- В (20 %) — клиенты средней ценности;
- С (5 %) — клиенты наименьшей ценности.
Соответственно, такой анализ клиентской базы показывает, на работу с какими потребителями стоит сделать основной упор.
3. Оценка клиентской базы.
Это более сложный способ анализа клиентской базы. Но и результаты его дают довольно объемные данные о лояльности заказчиков и эффективности работы сотрудников.

Вариантов такого анализа клиентской базы множество. Но можно считать, что вы выбрали довольно эффективный подход, если он включает следующие показатели:
- прибыль;
- объем заказов;
- количество заказов;
- рентабельность производства;
- наличие опозданий поставок;
- удовлетворенность клиентов.
Наиболее распространенный метод анализа — опрос.
Планы на будущее
Во фреймворке заложены основные возможности, которые я хотел в нем видеть. Он вполне работоспособен, но тем не менее ту стадию, на которой он находится в данный момент, я бы назвал только концептом.
Так, например, на данный момент существует backend, который позволяет фреймворку работать только с базой данных MySQL, из-за чего его можно запустить только на Electron. Также не реализован интерфейс для работы на мобильных устройствах и ряд других возможностей.
Ближайшие планы по развитию фреймворка:
- Реализовать механизмы объединения и группировок в запросах в классе Query.
- Добавить элементы управления для работы с объединениями и группировками.
- Разработать backend для преобразования объекта Query в json или xml, а также разработать серверную часть для работы с моделями Django.
- Реализовать механизм кеширования запросов к серверу данных.
- Воплотить в жизнь большое количество других идей.
Хранение ссылок на объекты
При манипулировании данными, хранящимися в базе данных «1С:Предприятия 8», зачастую используется объектный подход. Это значит, что обращение (чтение и запись) к некоторой совокупности данных, хранящихся в базе, происходит как к единому целому. Например, используя объектную технику, можно манипулировать данными справочников, документов, планов видов характеристик, планов счетов и т.д.
Характерной особенностью объектного манипулирования данными является то, что на каждый объект, как совокупность данных, существует уникальная ссылка, позволяющая однозначно идентифицировать этот объект в базе данных.
Эта ссылка также хранится в поле базы данных, вместе с остальными данными объекта. Кроме того, ссылка может быть использована как значение какого-либо поля другого объекта. Например, ссылка на объект справочника Контрагенты может быть использована как значение соответствующего реквизита документа Приходная накладная.
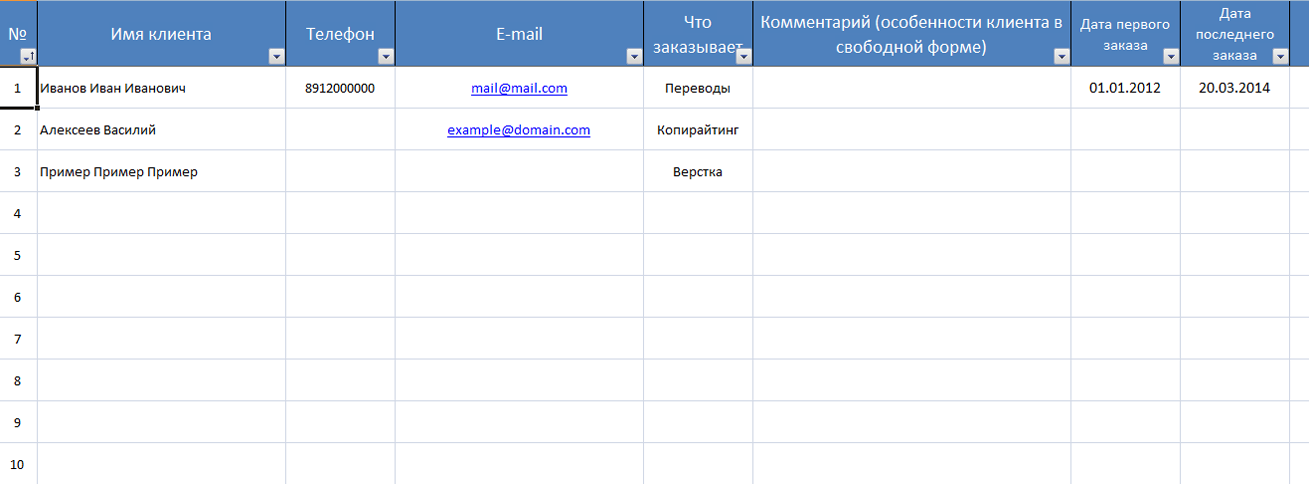
Работа с клиентской базой
Мало просто создать клиентскую базу. С ней необходимо работать, чтобы получать прибыль. Если этого не сделать, либо использовать неправильные методы, то результатом может стать уничтожение клиентской базы. То есть ваши потенциальные покупатели и заказчики уйдут к конкурентам. Грамотный подход, напротив, позволит расширить ряды ваших потребителей.
Первое, что необходимо, — это правильно вести клиентскую базу данных.

Как вести клиентскую базу
- Соблюдайте цикличность. Не утомляйте клиента регулярными звонками. Звоните лишь тогда, когда необходимо, со значительными интервалами.
- Следите за тем, чтобы к одному клиенту ни в коем случае не было прикреплено двое или более сотрудников.
- Введите лимит времени на работу с одним клиентом. Если в выделенный срок не удалось добиться положительного ответа, то не стоит дальше продолжать давить. Несговорчивые персоны должны быть удалены из клиентской базы.
- Формируйте клиентскую базу данных, содержащую все необходимые сведения о потребителе. Сюда можно включить график работы, контакты, историю заказов и т. д.
- Ведите историю взаимодействия с клиентом. Прошлый опыт позволит в будущем выбирать более эффективные стратегии и избежать старых ошибок.
- Узнавайте подробности о преимуществах конкурентов, если заказчик отдал им предпочтение.
В идеале клиентская база должна регулярно наполняться подобной информацией. Если данным советом пренебречь, то работать будет гораздо сложнее.
Кстати, имейте в виду, что информация о проблемах с клиентами должна быть закрыта от продавцов. Дело в том, что, обращаясь к тем, кому прежде не удалось что-то продать, ваш сотрудник будет чувствовать неуверенность.
Управление клиентской базой
Есть два инструмента, которые позволяют эффективно взаимодействовать с клиентской базой.
Первый инструмент — это паспорт региона. Важная информация о той местности, в которой зарегистрирован клиент. Это экономическая характеристика, политическая ситуация, анализ социальной сферы и т. д. — словом, всё, что может нам пригодиться для более глубокого понимания полной картины.
Второй инструмент — это карточка клиента: история сотрудничества, аналитика, контакты и информация, связанная с бизнесом.
В случае, когда мы говорим об организациях, важно включать в карточку информацию о том, как выстраивалось общение с лицом, принимающим решение. Данный термин также известен как DMU (Decision Making Unit)
Собственно, от того, насколько удалось заинтересовать данное лицо или группу лиц, зависит успех работы с клиентом.
Системы Управления Базами Данных
Теперь, когда у нас есть реляционная БД, каким образом мы можем её имплементировать? Для этого мы можем воспользоваться системами управления базами данных (СУБД). Существует целый набор подобных программ, как платных, так и бесплатных. Среди платных можно выделить Oracle Database, IBM DB2 и Microsoft SQL Server. Бесплатные: MySQL, SQLite и PostgreSQL.
Чаще всего различные компании используют MySQL. Twitter в этом смысле — не исключение.
SQLite чаще используется при разработке приложений для iOS и Android, где хранится различного рода конфиденциальная информация. Браузер Google Chrome использует SQLite для хранения истории просмотров, кукисов, изображений…
PostgreSQL используется реже. Для неё существует полезное расширение PostGIS, которое делает данную СУБД удобной для хранения геолокационных данных. К примеру сервис OpenStreetMap исользует PostgreSQL.
Вставка (INSERT)
Синтаксис 1:
> INSERT INTO <table> (<fields>) VALUES (<values>)
Синтаксис 2:
> INSERT INTO <table> VALUES (<values>)
* где table — имя таблицы, в которую заносим данные; fields — перечисление полей через запятую; values — перечисление значений через запятую.
* первый вариант позволит сделать вставку только по перечисленным полям — остальные получат значения по умолчанию. Второй вариант потребует вставки для всех полей.
1. Вставка нескольких строк одним запросом:
> INSERT INTO cities (`name`, `country`) VALUES (‘Москва’, ‘Россия’), (‘Париж’, ‘Франция’), (‘Фунафути’ ,’Тувалу’);
* в данном примере мы одним SQL-запросом добавим 3 записи.
2. Вставка из другой таблицы (копирование строк, INSERT + SELECT):
Синтаксис при копировании строк из одной таблицы в другую выглядит так:
> INSERT INTO <table1> SELECT * FROM <table2> WHERE <условие для select>;
* где table1 — куда копируем; table2 — откуда копируем.
а) скопировать все без разбора:
> INSERT INTO cities-new SELECT * FROM cities;
* в данном примере мы скопируем все строки из таблицы cities в таблицу cities-new.
б) скопировать определенные столбцы строк с условием:
> INSERT INTO cities-new (`name`, `country`) SELECT `name`, `country` FROM cities WHERE name LIKE ‘М%’;
* извлекаем все записи из таблицы cities, названия которых начинаются на «М» и заносим в таблицу cities-new.
в) копирование с обновлением повторяющихся ключей.
Если копировать таблицы несколько раз, то может возникнуть проблема повторения первичного ключа. В базах данных значения таких ключей должны быть уникальными и при попытке вставить повтор мы получим ошибку «Duplicate entry ‘xxx’ for key ‘PRIMARY’». Чтобы новые строки вставить, а повторяющиеся обновить (если есть изменения), используем «ON DUPLICATE KEY UPDATE»:
> INSERT INTO cities-new SELECT * FROM cities ON DUPLICATE KEY UPDATE `name`=VALUES(`name`), `country`=VALUES(`country`);
* в данном примере, как и в предыдущих, мы копируем данные из таблицы cities в таблицу cities-new. Но при совпадении значений первичного ключа мы будем обновлять поля name и country.
Разные базы — разные правила
Внутри каждой базы данных и её управляющей системы свои строгие правила:
- какие данные могут храниться: текст, цифры, фото, видео или всё вместе;
- какие свойства есть у этих данных: дата записи, кто записал, кто может прочитать;
- что делать, если с базой хотят работать одновременно несколько человек: разрешать только одному или пусть все вместе работают.
Рабочая ситуация: допустим, вы работаете в банке и открыли карточку клиента, чтобы поменять ему кредитный лимит. В этот же момент другой сотрудник из соседнего офиса тоже хочет поменять лимит этому же клиенту, но уже на другую сумму. Как база отреагирует на такое? Должна ли она разрешать второму сотруднику открывать карточку или её нужно заблокировать, пока первый не закончит? А если она разрешит открыть карточку, то что будет, если двое сотрудников напишут там разный лимит — какой из них сохранять в итоге? СУБД задаёт эти правила и следит за их выполнением.
Структура Data Access Layer
Данный раздел описывает принципиальное устройство программного обеспечения DAL, реализующего концепцию унифицированного доступа к данным. В описании структуры DAL рассматриваются в том числе и вопросы выбора и применения конкретных технологий и программных продуктов.
Принципы, применяющиеся при проектировании DAL
- Не ставится задача автоматического, безостановочного, не требующего затрат или мгновенного переключения работающей АС с одного средства хранения на другое. Проектировочные решения должны не полностью исключать (что долго и сложно), а существенно снижать зависимость логики приложения от средства хранения таким образом, чтобы значительно облегчить возможный переход. Нужно рассчитывать на разумный подход проектировщиков АС и понимание ими архитектурных принципов и целей, а потому не пытаться выстроить суперзащищенную техническую систему.
- При проектировании должны максимально использоваться готовые, уже существующие на рынке и стандартизованные средства и компоненты. Если предприятие хочет обеспечить максимальную независимость от вендоров, то предпочтительно использование Open Source продуктов и технологий, но только достаточно зрелых, с подобающим размером сообщества и примерами внедрений на ответственных предприятиях.
- Следует стремиться к простоте перевода существующих АС на DAL.
- Лучше наращивать возможности реализуемого DAL постепенно, итерационно. Первый шаг должен быть простым, дешевым и быстрым, направленным на решение наиболее актуальных задач (в частности, переносимость реляционных СУБД).
- Новый подход к управлению хранением может не ограничиваться техническими средствами, а включать, например, изменения в организационных механизмах предприятия в части управления инфраструктурой, а также в процессах проектирования и технического аудита АС.
Варианты размещения компонентов структуры DAL
Рис. 6. Варианты размещения компонентов структуры DAL
- В виде библиотеки, включаемой в состав приложения. В этом варианте необходима разработка разных видов модулей доступа для разных технологий разработки АС.
- В виде сетевого сервиса. Этот вариант предназначен для тех случаев, когда по каким-то причинам невозможна или нежелательна работа сервиса доступа к данным в виде библиотеки (например, ИС разработана на платформе, у которой нет библиотеки для работы с DAL). В таком варианте DAL доступен для любого приложения, способного работать с сетевыми сервисами по протоколу HTTP. Для этого способа размещения набор предоставляемых интерфейсов доступа к данным может быть ограничен.
История
В 1974 году компания IBM начала исследовательский проект по разработке прототипа РСУБД IBM System R. Её первым коммерческим продуктом был IBM SQL/DS, выпущенный в 1982 году.
Однако первой коммерчески доступной RDBMS была Oracle, выпущенная в 1979 году компанией Relational Software (в настоящее время Oracle Corporation).
Другие примеры СУБД включают IBM DB2, SAP Sybase ASE и IBM Informix. В 1984 году появилась первая RDBMS для Apple Macintosh под кодовым названием Silver Surfer, позже она была выпущена в 1987 году под названием 4th Dimension и известна сегодня как 4D.
В 1970-е годы, когда уже были получены почти все основные теоретические результаты и даже существовали первые прототипы реляционных СУБД, многие авторитетные специалисты отрицали возможность добиться эффективной реализации таких систем. Однако преимущества реляционного подхода и развитие методов и алгоритмов организации и управления реляционными базами данных привели к тому, что к концу 1980-х годов реляционные системы заняли на мировом рынке СУБД доминирующее положение.
В связи с резким ростом популярности РСУБД в 1980-х годах многие компании стали позиционировать свои СУБД как «реляционные» в рекламных целях, иногда не имея для этого достаточных оснований, вследствие чего автор реляционной модели данных Эдгар Кодд в 1985 году опубликовал свои знаменитые «12 правил Кодда», которым должна удовлетворять каждая РСУБД.
Шаг 2. Избавляемся от дубликатов в столбцах
Как было оговорено выше, столбцы “username” и “following_username” содержат дубликаты данных. Они возникли в результате того, что я хотел отобразить отношения между твиттами и пользователями. Давайте улучшим нашу структуру БД, разделив существующую таблицу на две: в одной будем хранить информацию, а в другой — отношения между записями.
Поскольку @Brett_Englebert подписан на @RealSkipBayless, то в таблице “following” отобразим это следующим образом: имя @Brett_Englebert поместим в колонку “from_user”, а @RealSkipBayless в “to_user.” Давайте посмотрим, как будет выглядеть таблица “following” после разделения Таблицы 1:
Таблица 2. following
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | klout |
| GunnarSvalander | zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | CindyCrawford |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3. users
| full_name | username | text | created_at |
|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Уже лучше. Теперь в таблице “users” (Таблица 3) у нас хранится только информация о твиттах, а в таблице following (Таблица 2) — зависимость пользователей.
Основатель теории реляционных баз данных, Эдгар Кодд, назвал бы этот процесс (удаления повторений из столбцов таблиц) приведением БД к первой нормальной форме.
Отличия RDBMS от обычной СУБД
СУБД хранит данные в виде файлов, тогда как RDBMS хранит данные в виде таблицы. СУБД позволяет нормализовать данные, а RDBMS поддерживает связь между данными, хранящимися в ее таблицах. Обычная СУБД не предоставляет ссылки. Она просто хранит данные своих файлов. Структурированный подход RDBMS поддерживает распределенную РБД в отличие от обычной системы управления базами данных. СУБД ориентирована на широкий спектр применений, ее особенности позволяют использовать ее во всем мире.
Особенности RDBMS:
- Общая реализация столбца, а также многопользовательский доступ включены в функции RDBMS.
- Потенциал этой модели реляционных СУБД был более чем оправдан современными возможностями применения.
- Лучшая безопасность обеспечивается созданием таблиц.
- Некоторые таблицы могут быть защищены системой.
- Пользователи могут устанавливать барьеры доступа к контенту. Это очень полезно в компаниях, где менеджер может решить, какие данные предоставляются сотрудникам и клиентам. Таким образом, можно настроить индивидуальный уровень защиты данных.
- Обеспечение будущих требований, поскольку новые данные могут быть легко добавлены к существующим таблицам и согласованы с ранее доступным содержимым. Это функция, которой нет ни в одной БД плоских файлов.
Доля рынка
По данным DB-Engines, в мае 2017 года наиболее популярными системами являются Oracle, MySQL (с открытым исходным кодом), Microsoft SQL Server, PostgreSQL (с открытым исходным кодом), IBM DB2, Microsoft Access и SQLite (с открытым исходным кодом).
По данным исследовательской компании Gartner, в 2011 году доходы пяти ведущих коммерческих поставщиков реляционных баз данных составили: Oracle (48,8%), IBM (20,2%), Microsoft (17,0%), SAP, включая Sybase (4,6%) и Teradata (3,7% ).
По данным Gartner, в 2008 году доля сайтов баз данных, использующих любую технологию, была:.
- База данных Oracle — 70%
- Microsoft SQL Server — 68%
- MySQL (Oracle Corporation) — 50%
- IBM DB2 — 39%
- IBM Informix — 18%
- SAP Sybase Adaptive Server Enterprise — 15%
- SAP Sybase IQ — 14%
- Teradata — 11%
Django Admin
После анализа и изучения отзывов я выбрал фреймворк Django с его генератором admin-интерфейсов. При этом пришлось перенести некоторые идеи, заложенные в 1С, на код Python. В итоге получались примерно такие интерфейсы:
Однако, при больших объемах данных стали проявляться недостатки такого подхода.
Во-первых, интерфейсы Django Admin обладают очень ограниченным функционалом и удобство их создания сходит на нет, если нужен функционал, не предусмотренный Django. В таком случае приходится ковыряться в коде Django и искать место, куда можно было бы внедрить свой код, наследуя классы или переделывая шаблоны. Такие модификации носят несистемный характер и через некоторое время к ним трудно возвращаться и вспоминать, как они работают (что приходилось делать, в частности, после обновления очередной версии Django).
Во-вторых, работать с создаваемыми Django Admin интерфейсами было не достаточно удобно, ввод данных был затруднителен и не оперативен. Хотелось интерактивности хотя бы на уровне 1С, чтобы интерфейс не перегружал страницу каждый раз, когда отправляются данные, а использовал такие технологии, как Ajax или WebSocket.
Язык структурированных запросов (SQL)
После того, как вы выбрали подходящую для вас СУБД и установили её, следующим шагом было бы создание таблиц и управление данными. Для этого мы можем воспользоваться специальным языком SQL.
Создание БД development:
CREATE DATABASE development;
Создание таблицы Users:
CREATE TABLE users ( full_name VARCHAR(100), username VARCHAR(100) );
При создании полей нам необходимо указать тип хранимой информации и её размер. Колонки “full_name” и “username” будут типа VARCHAR, который предназначен для хранения строк символов. Размер 100 символов. Список всех типов вы можете найти .
Добавление записи:
INSERT INTO users (full_name, username)
VALUES ("Boris Hadjur", "_DreamLead");
Извлечение всех записей пользователя _DreamLead:
SELECT text, created_at FROM tweets WHERE username="_DreamLead";
Обновление записи:
UPDATE users SET full_name="Boris H" WHERE username="_DreamLead";
Удаление записи:
DELETE FROM users WHERE username="_DreamLead";
SQL очень похож на человеческий язык (английский). В каждом СУБД SQL обладает рядом собственных особенностей и различий, но в целом, все разновидности SQL похожи друг на друга.
Недостатки RDBMS
Стоимость
Одним из недостатков RDBMS является дорогостоящая настройка и поддержка системы баз данных. Чтобы создать реляционную базу данных, необходимо приобрести специальное программное обеспечение. Требуется время для ввода всей информации и настройки программы. Если компания большая, необходимо нанять программиста для создания реляционной базы данных с использованием Structured Query Language (SQL) и администратора базы данных для поддержки базы данных после ее создания. Независимо от того, какие данные используются, придется либо импортировать их из других данных, таких как текстовые файлы или электронные таблицы Excel, либо ввести данные на клавиатуре. Независимо от размера вашей компании придется защищать свои данные от несанкционированного доступа, чтобы соответствовать нормативным стандартам.
Изобилие информации
Успехи в сложности информации вызывают еще один недостаток RDBMS. Реляционные базы данных предназначены для организации данных по общим характеристикам. Сложные изображения, цифры, рисунки и мультимедийные продукты не поддаются простой классификации, что ведет к созданию нового типа базы данных, называемого объектно-реляционными системами управления базами данных ORDBMS. Эти системы предназначены для работы с более сложными приложениями и могут быть масштабируемыми.
Ограниченные пределы
Некоторые реляционные базы данных имеют ограничения на длину поля. При создании базы данных, необходимо указать количество данных, которое можно поместить в поле. Некоторые имена или поисковые запросы короче фактических, и это может привести к потере данных.
Изолированные базы данных
Сложные системы реляционных баз данных могут привести к тому, что эти базы данных станут «островами информации», где информация не может быть легко передана из одной большой системы в другую. Часто, в крупных фирмах или учреждениях, реляционные базы данных растут в разных подразделениях по-разному. Приведение этих баз данных к единой структуре может быть сложной и дорогостоящей процедурой.