Как выполнить код python в microsoft sql server на t-sql
Содержание:
- Prevent SQL Injection
- Создание таблицы
- MySQLdb._mysql¶
- PyMySQL fetchAll
- Меняем MySQL на SQLite
- Python Tutorial
- Импортирование и использование
- Join Two or More Tables
- Вставка записи (INSERT)
- Способы выборки из таблиц
- Формирование запросов
- Version 2.1.1 — 2014-11-25 — Ramiro Morales
- Способы выборки из таблиц
- Транзакции в SQLite
- Создание бэкапа БД
- Подведем итоги
Prevent SQL Injection
It is considered a good practice to escape the values of any query, also in
update statements.
This is to prevent SQL injections, which is a common web hacking technique to
destroy or misuse your database.
The mysql.connector module uses the placeholder to escape values in the delete statement:
Example
Escape values by using the placholder
method:
import mysql.connectormydb = mysql.connector.connect( host=»localhost»,
user=»yourusername», password=»yourpassword», database=»mydatabase»)mycursor = mydb.cursor()sql = «UPDATE customers SET address = %s
WHERE address = %s»val = («Valley 345», «Canyon 123»)mycursor.execute(sql,
val)mydb.commit()print(mycursor.rowcount, «record(s)
affected»)
❮ Previous
Next ❯
Создание таблицы
Первое что вам нужно для базы данных – это таблица. Это место, где ваши данные будут организованы и храниться. Большую часть времени вам будут нужны несколько таблиц, в каждой из которых будут храниться поднастройки ваших данных. Создание таблицы в SQL это просто. Все что вам нужно сделать, это следующее:
MySQL
CREATE TABLE table_name (
id INTEGER,
name VARCHAR,
make VARCHAR
model VARCHAR,
year DATE,
PRIMARY KEY (id)
);
|
1 |
CREATETABLEtable_name( idINTEGER, nameVARCHAR, makeVARCHAR modelVARCHAR, yearDATE, PRIMARY KEY(id) |
Это довольно обобщенный код, но он работает в большей части случаев
Первое, на что стоит обратить внимание – куча слов прописанных заглавными буквами. Это команды SQL
Их не всегда нужно вписывать через капс, но мы сделали это, чтобы помочь вам увидеть их. Я также хочу обратить внимание на то, что каждая база данных поддерживает слегка отличающиеся команды. Большинство будет содержать CREATE TABLE, но типы столбцов баз данных могут быть разными. Обратите внимание на то, что в этом примере у нас есть базы данных INTEGER, VARCHAR и DATE.
DATE может вызывать много разных штук, как и VARCHAR. Проконсультируйтесь с документацией на тему того, что вам нужно делать. В любом случае, в этом примере мы создаем базу данных с пятью столбцами. Первый – это id, который мы настраиваем в качестве нашего основного ключа. Он не должен быть NULL, но мы и не указываем, что в нем, так как еще раз, каждый бекенд базы данных выполняет работу по-разному, или делает это автоматически для нас. Остальные столбцы говорят сами за себя
MySQLdb._mysql¶
If you want to write applications which are portable across databases,
use , and avoid using this module directly.
provides an interface which mostly implements the MySQL C API. For
more information, see the MySQL documentation. The documentation
for this module is intentionally weak because you probably should use
the higher-level MySQLdb module. If you really need it, use the
standard MySQL docs and transliterate as necessary.
The MySQL C API has been wrapped in an object-oriented way. The only
MySQL data structures which are implemented are the
(database connection handle) and (result handle)
types. In general, any function which takes as an
argument is now a method of the connection object, and any function
which takes as an argument is a method of the
result object. Functions requiring none of the MySQL data structures
are implemented as functions in the module. Functions requiring one of
the other MySQL data structures are generally not implemented.
Deprecated functions are not implemented. In all cases, the
prefix is dropped from the name. Most of the methods listed
are also available as MySQLdb Connection object methods. Their use is
non-portable.
| C API | |
|---|---|
| various options to | |
| option to | |
PyMySQL fetchAll
Метод позволяет извлечь все (оставшиеся) строки результата запроса, возвращая их в виде последовательности последовательностей.
Python
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import pymysql
con = pymysql.connect(‘localhost’, ‘user17’,
‘s$cret’, ‘testdb’)
with con:
cur = con.cursor()
cur.execute(«SELECT * FROM cities»)
rows = cur.fetchall()
for row in rows:
print(«{0} {1} {2}».format(row, row, row))
|
1 |
#!/usr/bin/python3 importpymysql con=pymysql.connect(‘localhost’,’user17′, ‘s$cret’,’testdb’) withcon cur=con.cursor() cur.execute(«SELECT * FROM cities») rows=cur.fetchall() forrow inrows print(«{0} {1} {2}».format(row,row1,row2)) |
В данном примере из таблицы базы данных выводятся все города (cities).
Python
cur.execute(«SELECT * FROM cities»)
| 1 | cur.execute(«SELECT * FROM cities») |
Python
rows = cur.fetchall()
| 1 | rows=cur.fetchall() |
Python
for row in rows:
print(«{0} {1} {2}».format(row, row, row))
|
1 |
forrow inrows print(«{0} {1} {2}».format(row,row1,row2)) |
Shell
$ ./retrieve_all.py
1 Bratislava 432000
2 Budapest 1759000
3 Prague 1280000
4 Warsaw 1748000
5 Los Angeles 3971000
6 New York 8550000
7 Edinburgh 464000
8 Berlin 3671000
|
1 |
$.retrieve_all.py 1Bratislava432000 2Budapest1759000 3Prague1280000 4Warsaw1748000 5Los Angeles3971000 6NewYork8550000 7Edinburgh464000 8Berlin3671000 |
Меняем MySQL на SQLite
Используя пример из кода выше, мы изменим базу данных из MySQL на SQLite не трогая код (кроме самого подключения). Нам нужно обновить немного наш файл. С самых первых строк было:
Python
import requests
from peewee import MySQLDatabase, Model
from peewee import IntegerField, FloatField, CharField, PrimaryKeyField, TimestampField, fn
from peewee import InternalError
db = MySQLDatabase(
‘peewee’, user=’root’, password=’mangos’,
host=’localhost’
)
|
1 |
importrequests frompeewee importMySQLDatabase,Model frompeewee importIntegerField,FloatField,CharField,PrimaryKeyField,TimestampField,fn frompeewee importInternalError db=MySQLDatabase( ‘peewee’,user=’root’,password=’mangos’, host=’localhost’ ) |
Теперь у нас:
Python
import requests
from peewee import SqliteDatabase, Model
from peewee import IntegerField, FloatField, CharField, PrimaryKeyField, TimestampField, fn
from peewee import InternalError
db = SqliteDatabase(‘binance-coins.db’)
|
1 |
importrequests frompeewee importSqliteDatabase,Model frompeewee importIntegerField,FloatField,CharField,PrimaryKeyField,TimestampField,fn frompeewee importInternalError db=SqliteDatabase(‘binance-coins.db’) |
После запуска отредактированного кода мы получим ошибку:
Shell
peewee.OperationalError: no such function: Rand
| 1 | peewee.OperationalErrorno such functionRand |
Ошибка в примере «Выбираем случайные 5 монет», в коде мы используем fn.Rand() и он работает для MySQL, но для SQLite и PostgreSQL он работать не будет, нужно использовать fn.Random(). Подробнее:
После запуска у нас появился файл базы данных binance-coins.db
Python Tutorial
Python HOMEPython IntroPython Get StartedPython SyntaxPython CommentsPython Variables
Python Variables
Variable Names
Assign Multiple Values
Output Variables
Global Variables
Variable Exercises
Python Data TypesPython NumbersPython CastingPython Strings
Python Strings
Slicing Strings
Modify Strings
Concatenate Strings
Format Strings
Escape Characters
String Methods
String Exercises
Python BooleansPython OperatorsPython Lists
Python Lists
Access List Items
Change List Items
Add List Items
Remove List Items
Loop Lists
List Comprehension
Sort Lists
Copy Lists
Join Lists
List Methods
List Exercises
Python Tuples
Python Tuples
Access Tuples
Update Tuples
Unpack Tuples
Loop Tuples
Join Tuples
Tuple Methods
Tuple Exercises
Python Sets
Python Sets
Access Set Items
Add Set Items
Remove Set Items
Loop Sets
Join Sets
Set Methods
Set Exercises
Python Dictionaries
Python Dictionaries
Access Items
Change Items
Add Items
Remove Items
Loop Dictionaries
Copy Dictionaries
Nested Dictionaries
Dictionary Methods
Dictionary Exercise
Python If…ElsePython While LoopsPython For LoopsPython FunctionsPython LambdaPython ArraysPython Classes/ObjectsPython InheritancePython IteratorsPython ScopePython ModulesPython DatesPython MathPython JSONPython RegExPython PIPPython Try…ExceptPython User InputPython String Formatting
Импортирование и использование

«Встроенность» предполагает, что вам не нужно запускать для получения библиотеки. Просто импортируйте ее с помощью:
Создание соединения с БД
Не беспокойтесь о драйверах, строках подключения и т.д. Вы можете создать базу данных SQLite и задать такой простой объект подключения, как:
После запуска этой строки кода происходит создание с БД и активируется подключение к ней. Дело в том, что базы данных, к которой мы просим подключиться Python, не существует, поэтому он автоматически создает пустую. Также мы можем ввести точно такой же код для подключения к уже существующей базе данных.

Создание таблицы
Теперь создадим таблицу:
Мы добавили три столбца в таблицу . Как видите, SQLite действительно легка и при этом поддерживает все основные функции обычной реляционной СУБД, такие как тип данных, обнуляемый тип, первичный ключ и автоинкремент.
После запуска этого кода создается таблица, но она ничего не выводит.
Включение записей
Вставим несколько записей в только что созданную таблицу , чтобы доказать, что она действительно создана.
Предположим, мы хотим вставить сразу несколько записей. Выполним:
Определяем оператор SQL с вопросительными знаками в качестве заполнителя. Теперь создадим образцы данных для вставки, а затем вставим их с помощью объекта подключения:
После запуска кода не появилось никаких предупреждений, значит все прошло успешно.
Запрос к таблице
Пришло время удостовериться, что все сделано правильно. Выполним запрос к таблице на возврат образцов строк.
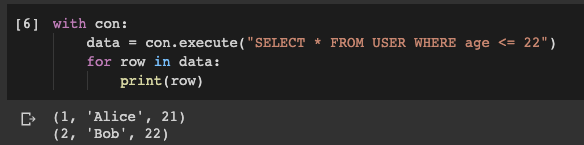
Как видите, все очень просто!
Более того, несмотря на свою легкость SQLite является широко используемой базой данных, и большинство программного обеспечения клиентов SQL ее поддерживает.
Чаще всего я использую инструмент DBeaver. Рассмотрим его на примере.
Подключение к базе данных SQLite из клиента SQL (DBeaver)
Поскольку я использую Google Colab, я буду загружать файл на свой компьютер. При запуске Python на локальном компьютере можно использовать клиент SQL для прямого подключения к файлу баз данных.
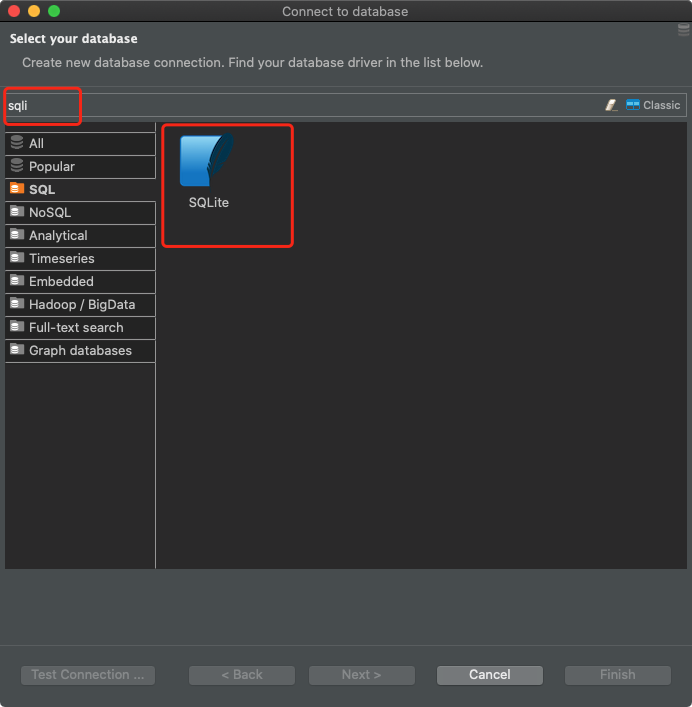
Создаем новое соединение в DBeaver и выбираем SQLite в качестве типа БД:
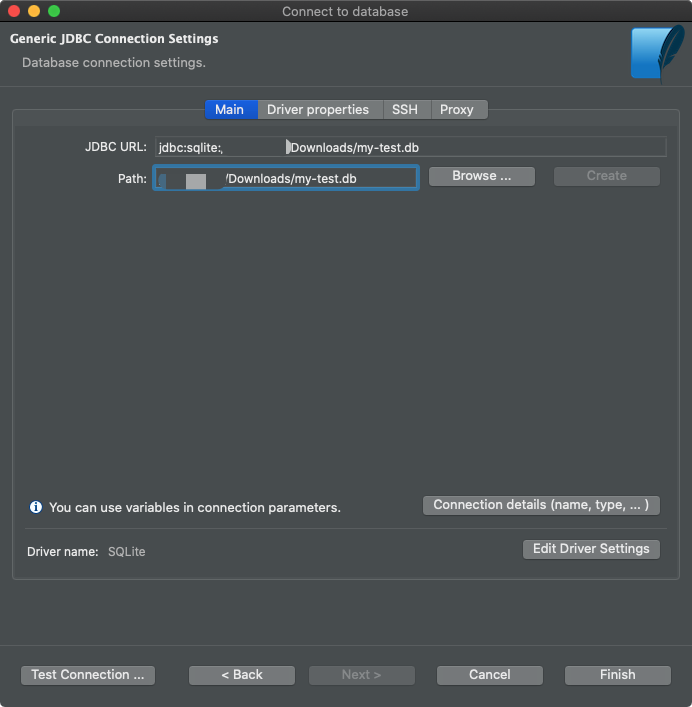
Затем переходим к файлу БД:
Теперь к базе данных можно выполнить любой SQL-запрос, как и в любых других реляционных БД:

Join Two or More Tables
You can combine rows from two or more tables, based on a related column
between them, by using a JOIN statement.
Consider you have a «users» table and a «products» table:
users
{ id: 1, name: ‘John’, fav: 154},{ id:
2, name: ‘Peter’, fav: 154},{ id: 3, name: ‘Amy’, fav: 155},{ id: 4, name: ‘Hannah’, fav:},{ id: 5, name: ‘Michael’, fav:}
products
{ id: 154, name:
‘Chocolate Heaven’ },{ id: 155, name: ‘Tasty Lemons’ },{
id: 156, name: ‘Vanilla Dreams’ }
These two tables can be combined by using users’ field and products’
field.
Example
Join users and products to see the name of the users favorite product:
import mysql.connectormydb = mysql.connector.connect( host=»localhost»,
user=»yourusername», password=»yourpassword», database=»mydatabase»)
mycursor = mydb.cursor()sql = «SELECT \ users.name AS user,
\ products.name AS favorite \ FROM users \ INNER JOIN
products ON users.fav = products.id»mycursor.execute(sql)
myresult = mycursor.fetchall()for x in myresult: print(x)
Note: You can use JOIN instead of INNER JOIN. They will
both give you the same result.
Вставка записи (INSERT)
Теперь мы можем перейти к добавлению данных сперва в category, а затем в таблицу products. Так как у нас есть рабочие модели, не так просто добавлять или обновлять записи.
Python
import peewee
from models import *
def add_category(name):
row = Category(
name=name.lower().strip(),
)
row.save()
add_category(‘Books’)
|
1 |
importpeewee frommodels import* defadd_category(name) row=Category( name=name.lower().strip(), ) row.save() add_category(‘Books’) |
Я добавил функцию под названием add_category() с параметром и именем внутри. Объект Category создан, как и поля таблицы, которые являются переданной собственностью данного объекта класса. В нашем случае, это поле name.
The row.save() сохраняет данные из объекта в базу данных.
Круто, не так ли? Больше не нужно прописывать уродливые INSERT-ы.
Теперь добавим product.
Python
import peewee
from models import *
def add_product(name, price, category_name):
cat_exist = True
try:
category = Category.select().where(Category.name == category_name.strip()).get()
except DoesNotExist as de:
cat_exist = False
if cat_exist:
row = Product(
name=name.lower().strip(),
price=price,
category=category
)
row.save()
|
1 |
importpeewee frommodels import* defadd_product(name,price,category_name) cat_exist=True try category=Category.select().where(Category.name==category_name.strip()).get() exceptDoesNotExist asde cat_exist=False ifcat_exist row=Product( name=name.lower().strip(), price=price, category=category ) row.save() |
add_product берет name, price и category_id в качестве вводных данных. Сначала, я проверю, существует ли категория, если да – значит её объекты хранятся в базе. В ORM вы имеете дело с объектом, по этому вы передаете информацию о категории в качестве объекта, так как мы уже определили эту взаимосвязь ранее.
Далее, я буду создавать разделы в main.py:
Python
add_category(‘Books’)
add_category(‘Electronic Appliances’)
|
1 |
add_category(‘Books’) add_category(‘Electronic Appliances’) |
Теперь добавим продукты:
Python
# Добавление продуктов.
add_product(‘C++ Premier’, 24.5, ‘books’)
add_product(‘Juicer’, 224.25, ‘Electronic Appliances’)
|
1 |
# Добавление продуктов. add_product(‘C++ Premier’,24.5,’books’) add_product(‘Juicer’,224.25,’Electronic Appliances’) |
Полный main.py можете видеть ниже:
main.py
Python
import peewee
from models import *
def add_category(name):
row = Category(
name=name.lower().strip(),
)
row.save()
def add_product(name, price, category_name):
cat_exist = True
try:
category = Category.select().where(Category.name == category_name.strip()).get()
except DoesNotExist as de:
cat_exist = False
if cat_exist:
row = Product(
name=name.lower().strip(),
price=price,
category=category
)
row.save()
if __name__ == ‘__main__’:
# Создаем разделы.
add_category(‘Books’)
add_category(‘Electronic Appliances’)
# Добавляем продукты в разделы.
add_product(‘C++ Premier’, 24.5, ‘books’)
add_product(‘Juicer’, 224.25, ‘Electronic Appliances’)
|
1 |
importpeewee frommodels import* defadd_category(name) row=Category( name=name.lower().strip(), ) row.save() defadd_product(name,price,category_name) cat_exist=True try category=Category.select().where(Category.name==category_name.strip()).get() exceptDoesNotExist asde cat_exist=False ifcat_exist row=Product( name=name.lower().strip(), price=price, category=category ) row.save() if__name__==’__main__’ # Создаем разделы. add_category(‘Books’) add_category(‘Electronic Appliances’) # Добавляем продукты в разделы. add_product(‘C++ Premier’,24.5,’books’) add_product(‘Juicer’,224.25,’Electronic Appliances’) |
Я передаю имя категории, как только её объект будет найден и передан объекту класса Product. Если вы хотите пойти по пути SQL, для начала вам нужно выполнить SELECT, чтобы получить существующий category_id, и затем назначить id добавляемому продукту.
Так как работать с ORM – значит иметь дело с объектами, мы храним объекты вместо скалярных значений. Кто-то может посчитать это слишком «инженерным» методом в нашем случае, но подумайте о случаях, когда вы понятия не имеете о том, какая база данных должна быть использована в будущем. Ваш код – это универсальный инструмент для работы с базами данных, так что если он работает с MySQL, или MSSQL, то он будет работать даже с MongoDb (гипотетически).
Способы выборки из таблиц
Объект cursor модуля MySQLdb поддерживает итерации. Это значит, что можно обойти все записи в наборе данных полученных из cur.execute без использования метода cur.fetchall, а просто используя инструкцию for row in cur:
Так же за место цикла for можно использовать цикл while
Обращение к данным по ключам может показаться неудобным, особенно если вы работает с большим набором данных из большого числа столбцов. Намного привычнее обращаться к данным по именам полей. Для этого напишем небольшую функцию-генератор. Вообще лучше сесть и написать хорошую обёртку во круг всего этого модуля. Например, можно динамически создавать курсор или даже делать коннект к базе.
Функцию-генератор по «именовыванию» последовательности записей.
Использовать её можно следующим образом:
Формирование запросов
Важным этапом в работе с базой данных является формирование запросов к этой базе данных. Отчасти проблема заключается в необходимости вставлять в строку запроса данные пользовательского ввода, что абсолютно не безопасно. Далее об этом.
Экранирование символов. В MySQLdb есть 4 метода экранирования:
- con.escape
- con.escape_string
- con.string_literal
- И автоматический механизм подстановки значений:cur.execute(«SELECT *FROM `city` WHERE id_city=’?’», (city,))
Тут символ подстановки (?) замещается значением из кортежа (city,) автоматически экранируя спец. символы.
Но не существует единого правила оформления подстановки значений в запрос. Поэтому есть переменная paramstyle которая может определить формат подстановки.
У меня MySQLdb.paramstyle равен ‘format’.
Варианты формата:
- qmark – параметры обозначаются знаков вопроса (?)
- numeric — параметры обозначаются числами
- named — параметры обозначаются именами
- format — параметры обозначаются в стиле printf.
- pyformat — параметры обозначаются в стиле расширенного набора кодов формата Python — %(name)s
Но есть небольшая проблема.
В Python 3.x такой подход работать не будет. Если заглянуть под капот модуля MySQLdb и найти функцию execute (\Lib\site-packages\MySQLdb\cursors.py), то можно видеть что в Python 3.x подстановка параметров осуществляется используя функцию format:
А в Python 2.x используется простое формирование строки:
По всей видимости, разработчики забыли изменить документацию к функции. И поэтому формирование в стиле Си функции printf работает не будет.
Следовательно, нужно использовать следующий подход:
Говоря об экранирование, используя функции escape_string и string_literal, они не работают с кодировками, что является серьёзной проблемой. Раньше была функция escape которая принимала один параметр, но теперь ей требуется 2 параметра, причём второй это словарь с ссылками на функции каждого из типов, и честно говоря для меня он остался загадкой. Поэтому лучше использовать вариант с автоматическим экранированием. Автоматическое экранирование спец. символов реализовано используя функцию escape.
Если вы разрабатываете Web приложение, то стоит позаботиться о преобразование символов & « в соответствующие сущности языка разметки, такие как & «. Для этого можно использовать функцию escape() модуля cgi:
Или написать что-то своё, с более расширенным функционалом.
Пример использования:
Обратите внимание на VALUES ({name}), метку {name} не нужно загонять в кавычки. Автоматическая подстановка сделает это за Вас, иначе будет выведено сообщение об ошибке
Вот наверно и всё, что я хотел рассказать. Думаю этого достаточно для нормального старта с базой данных MySQL. Удачных экспериментов!
Version 2.1.1 — 2014-11-25 — Ramiro Morales
Features
-
Custom message handlers (GH-139)
The DB-Library API includes a callback mechanism so applications can provide
functions known as message handlers that get passed informative messages
sent by the server which then can be logged, shown to the user, etc._mssql now allows you to install your own message handlers written in
Python. See the _msssql examples and reference sections of the
documentation for more details.Thanks Marc Abramowitz.
-
Compatibility with Azure
Note
If you need to connect to Azure make sure you use FreeTDS 0.91 or
newer. -
Customizable per-connection initialization SQL clauses (both in pymssql
and _mssql) (GH-97)It is now possible to customize the SQL statements sent right after the
connection is established (e.g. 'SET ANSI_NULLS ON;'). Previously
it was a hard-coded list of queries. See the _mssql.MSSQLConnection
documentation for more details.Thanks Marc Abramowitz.
-
Added ability to handle instances of uuid.UUID passed as parameters for
SQL queries both in pymssql and _mssql. (GH-209)Thanks Marat Mavlyutov.
-
Thanks Marat Mavlyutov.
-
Documentation: Explicitly mention minimum versions supported of Python (2.6)
and SQL Server (2005). -
Incremental enhancements to the documentation.
Bug fixes
-
Handle errors when calling Stored Procedures via the .callproc() pymssql
cursor method. Now it will raise a DB-API DatabaseException; previously
it allowed a _mssql.MSSQLDatabaseException exception to surface. -
Fixes in tds_version _mssql connections property value
Made it work with TDS protocol version 7.2. (GH-211)
The value returned for TDS version 7.1 is still 8.0 for backward
compatibility (this is because such feature got added in times when
Microsoft documentation labeled the two protocol versions that followed 7.0
as 8.0 and 9.0; later it changed them to 7.1 and 7.2 respectively) and will
be corrected in a future release (2.2). -
PEP 249 compliance (GH-251)
Added type constructors to increase compatibility with other libraries.
Thanks Aymeric Augustin.
-
pymssql: Made handling of integer SP params more robust (GH-237)
-
Check lower bound value when convering integer values from to Python to SQL
(GH-238)
Способы выборки из таблиц
Объект cursor модуля MySQLdb поддерживает итерации. Это значит, что можно обойти все записи в наборе данных полученных из cur.execute без использования метода cur.fetchall, а просто используя инструкцию for row in cur:
Так же за место цикла for можно использовать цикл while
Обращение к данным по ключам может показаться неудобным, особенно если вы работает с большим набором данных из большого числа столбцов. Намного привычнее обращаться к данным по именам полей. Для этого напишем небольшую функцию-генератор. Вообще лучше сесть и написать хорошую обёртку во круг всего этого модуля. Например, можно динамически создавать курсор или даже делать коннект к базе.
Функцию-генератор по «именовыванию» последовательности записей.
Использовать её можно следующим образом:
Транзакции в SQLite
Управление транзакциями — одна из функций баз данных SQL, и SQLite также обрабатывает их. Транзакция — это последовательность изменений, в которой вы можете безопасно изменить базу данных, выполнив запрос и затем разместив .
Если по какой-то причине непосредственно перед фиксацией вы не хотите завершать транзакцию, вы можете вернуться в предыдущее состояние перед фиксацией, используя .
Точно так же мы также можем просматривать состояние базы данных через эти типы изменений.
import sqlite3
db_filename = 'database.db'
def display_table(conn):
cursor = conn.cursor()
cursor.execute('select name, size, date from images;')
for name, size, date in cursor.fetchall():
print(name, size, date)
with sqlite3.connect(db_filename) as conn1:
print('Before changes:')
display_table(conn1)
cursor1 = conn1.cursor()
cursor1.execute("""
insert into images (name, size, date)
values ('JournalDev.png', 2000, '2020-02-20');
""")
print('\nAfter changes in conn1:')
display_table(conn1)
print('\nBefore commit:')
with sqlite3.connect(db_filename) as conn2:
display_table(conn2)
# Commit from the first connection
conn1.commit()
print('\nAfter commit:')
with sqlite3.connect(db_filename) as conn3:
display_table(conn3)
cursor1.execute("""
insert into images (name, size, date)
values ('Hello.png', 200, '2020-01-18');
""")
print('\nBefore commit:')
with sqlite3.connect(db_filename) as conn2:
display_table(conn2)
# Revert to changes before conn1's commit
conn1.rollback()
print('\nAfter connection 1 rollback:')
with sqlite3.connect(db_filename) as conn4:
display_table(conn4)
Выход
Before changes: sample.png 100 2019-10-10 ask_python.png 450 2019-05-02 class_room.jpeg 1200 2018-04-07 After changes in conn1: sample.png 100 2019-10-10 ask_python.png 450 2019-05-02 class_room.jpeg 1200 2018-04-07 JournalDev.png 2000 2020-02-20 Before commit: sample.png 100 2019-10-10 ask_python.png 450 2019-05-02 class_room.jpeg 1200 2018-04-07 After commit: sample.png 100 2019-10-10 ask_python.png 450 2019-05-02 class_room.jpeg 1200 2018-04-07 JournalDev.png 2000 2020-02-20 Before commit: sample.png 100 2019-10-10 ask_python.png 450 2019-05-02 class_room.jpeg 1200 2018-04-07 JournalDev.png 2000 2020-02-20 After connection 1 rollback: sample.png 100 2019-10-10 ask_python.png 450 2019-05-02 class_room.jpeg 1200 2018-04-07 JournalDev.png 2000 2020-02-20
Здесь, как видите, таблица изменяется только после того, как мы явно завершим транзакцию. Любые изменения до этого фактически не изменяют таблицу. Наконец, мы откатываем запись , чтобы она не вставлялась в таблицу.
Создание бэкапа БД
Класс Cursor содержит один
весьма полезный метод
iterdump()
возвращающий
итератор для SQL-запросов, на
основе которых можно воссоздать текущую БД. Если просто вывести в консоль
возвращаемых строк:
with sq.connect("cars.db") as con:
cur = con.cursor()
for sql in con.iterdump():
print(sql)
То получим
список следующих SQL-команд:
BEGIN TRANSACTION;
CREATE TABLE cars (
car_id INTEGER PRIMARY KEY AUTOINCREMENT,
model TEXT,
price INTEGER);
INSERT INTO "cars" VALUES(1,'Audi',);
INSERT INTO "cars" VALUES(2,'Mercedes',57127);
INSERT INTO "cars" VALUES(3,'Skoda',9000);
INSERT INTO "cars" VALUES(4,'Volvo',29000);
INSERT INTO "cars" VALUES(5,'Bentley',350000);
DELETE FROM "sqlite_sequence";
INSERT INTO "sqlite_sequence" VALUES('cars',5);
CREATE TABLE users (
name TEXT,
ava BLOB,
score INTEGER);
INSERT INTO "users" VALUES('Николай', …,1000);
COMMIT;
С помощью этих
запросов можно точно воссоздать таблицы БД, то есть, их можно рассматривать как
некий дамп БД.
Чтобы наша
программа выглядела более функциональной, сохраним все эти строчки в отдельном
файле:
with open("sql_damp.sql", "w") as f:
for sql in con.iterdump():
f.write(sql)
После запуска в
рабочем каталоге программы появится файл sql_damp.sql с набором
соответствующих команд.
Теперь, чтобы
восстановить БД с помощью этого файла можно воспользоваться методом executescript,
о котором мы уже говорили:
with open("sql_damp.sql", "r") as f:
sql = f.read()
cur.executescript(sql)
Перед
выполнением этой программы удалим файл cars.db и после запуска
снова увидим этот файл с прежним содержимым.
Подведем итоги
В данной статье мы рассмотрели ряд различных тем. Вы освоили основы использования SQL. Также вы узнали кое-что о различных способах подключения к базам данных, используя Python. Это был не исчерпывающий список способов, и тем не менее. Существует ряд других пакетов, которые вы можете использовать для подключения к различным базам данных.
К примеру, мы даже не затронули вопрос использования MongoDb, как и других баз данных NoSQL, несмотря на то, что они так же поддерживаются Python. Если база данных не так популярна, по сравнению с остальными, скорее всего, есть способ подключиться к ней с помощью Python. Вам определенно следует потратить время на то, чтобы проверить эти пакеты лично и найти тот самый!