Работа с регулярными выражениями на php. глава 3
Содержание:
- Обработка и замена при помощи «preg_replace_callback»
- Шаблон функции preg match php
- Формат функции
- Отличие «preg_match» от «preg_match_all»
- Описание preg match php
- Символ — элемент шаблона
- Поиск текста функцией «preg_match_all»
- Примеры preg_match PHP
- Примеры preg_replace PHP
- Описание
- Простая практика preg match php
- Использование нумирации в заменах и другие продвинутые возможности
- Поиск текста между тегами
Обработка и замена при помощи «preg_replace_callback»
Переходим к самому интересному. Если нужно над найденным фрагметом произвести какие-то действия и только потом осуществить замену, то следует использовать «preg_replace_callback». Рассмотрим как с помощью этой функции в именах сделать первую букву заглавной.
<html>
<head> <meta charset="utf-8"> </head>
<body>
<?php
$sContent = "<xx>наташа</xx> ... <xx>даша</xx> ... <xx>настя</xx>";
echo htmlspecialchars($sContent); echo "<br />";
$sContent = preg_replace_callback('|(<xx>)(.+)(</xx>)|iU', function($matches){
$matches = mb_substr(mb_strtoupper($matches, 'UTF-8'),0,1,'UTF-8').substr($matches, 2);
return $matches.$matches.$matches;
}
,$sContent);
echo htmlspecialchars($sContent);
?>
</body>
</html>
В качестве параметров передаём маску поиска, функцию с кодом обработки и строковую переменную в которой осуществляем поиск. Дополнительно могут ещё быть заданы два необязательных параметра. О них в следующем разделе статьи.
Переменная «$matches» это массив, содержащий элементы регулярного выражения. В нулевом элементе будет содержаться вся исходная строка, а в остальных — содержимое скобок.
Код обработки не описываю, но отмечу что для замены первой буквы на заглавную я использую PHP функции для работы со строками в UTF-8 кодировке. Если у Вас кодировка cp1251, то нужно отбросить префикс «mb_» и удалить последний параметр у функций.
ВНИМАНИЕ! Код в примере будет работать только при использовании PHP версии 5.3 и выше. Для более поздних версий требуется доработка
Шаблон функции preg match php
PHP preg match all использует стандартный синтаксис регулярных выражений. Квадратные скобки обозначают один из символов, который в них указан:
- только символы a, b, c.
- все, кроме символов A, B, C.
- \w и \W — текстовый или не текстовый символ.
- \s и \S — пробельный или не пробельный символ.
- \d и \D — цифра или не цифра.
Символы повторения обозначаются фигурными скобками — {n,m} и относятся к предыдущему символу.
- n обозначает повторение «не менее»;
- m — повторение «не более».
Синтаксис предусматривает множество вариантов для создания шаблонов, но лучше всего начинать с азов, то есть с простых, собственноручно написанных, в которых сложные элементы и комбинации отсутствуют.
Проще говоря, перечислив реальные символы, которые нужны, указав их нужные количества и учтя, что символ «^» соответствует началу, а «$» — концу строки, можно создавать простенькие шаблоны. Анализируя реальные отлаженные регулярные выражения от квалифицированных специалистов, можно обрести прочные знания для создания сложных применений preg match all. Арсенал PHP не ограничен только этими двумя функциями, но они чаще всего используются.
Формат функции
PHP предлагает две функции поиска: preg match и preg match all. Первая ищет первое вхождение шаблона в строке, вторая — все вхождения. Иногда используют термин «совпадение с шаблоном». В первом случае результат функции — «строка совпадает с шаблоном», во втором случае — «в строке найдены совпадения с шаблоном». Формально термин «совпадение» более точно отражает суть, но естественный контекст операции обычно — «поиск» информации. На практике востребовано и одно, и другое. Ниже рассмотрен формат функций.
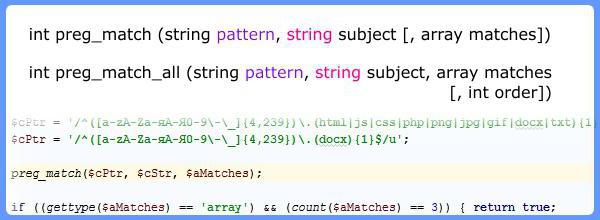
Результат функции — число, количество совпадений. Все найденные совпадения записываются в массив — matches. В случае функции preg match all можно указать порядок сортировки массива:
- PREG_PATTERN_ORDER;
- PREG_SET_ORDER.
Сортировка по первому варианту группирует результаты поиска по номеру регулярного выражения (значение по умолчанию). Во втором случае результаты группируются по месту их нахождения в строке.
Отличие «preg_match» от «preg_match_all»
Функция «preg_match» осуществляет поиск только до первого соответсвия с маской. Как только что-то найдено — поиск останавливается и возвращается одномерный массив.
if (preg_match('|<title>(.+)</title>|isU', $sContent, $arr))
return $arr; else return false;
Здесь нулевой элемент массива «$arr» содержит найденное совпадение вместе с тегами «title», а первый элемент — «$arr» только текст между этими тегами. Если в строке несколько тегов «title», это не значит что остальные значения будут записаны в «$arr» и так далее. Элемент «$arr» окажется не пуст если в маске указано несколько правил, но об этом в следующий раз.
Описание preg match php
mixed preg_replace (mixed pattern, mixed replacement, mixed subject )
Ищет в subject совпадения с pattern и замещает их replacement. Если
limit специфицирован, то замещаются только limit совпадений; если
limit опущен или равен -1, замещаются все совпадения.
Replacement может содержать ссылку в форме
\n или (начиная с PHP 4.0.4) $n, где последняя форма предпочтительнее. Каждая такая ссылка замещается текстом,
захваченным n‘ным патэрном в скобках. n может быть от 0 до 99, а
\0 или $0 ссылаются на текст, совпавший со всем патэрном. Открывающие скобки
подсчитываются слева направо (начиная с 1) для получения количества захватывающих субпатэрнов.
Если совпадения найдены, возвращается новый subject, иначе subject возвращается без изменений.
Каждый параметр preg_replace() может быть массивом.
Если subject это массив, то поиск и замена выполняются в каждом вхождении
subject, return-значение также будет массивом.
Если pattern и
replacement являются массивами, то preg_replace() принимает значение из каждого массива и использует их для выполнения поиска и
замены в subject. Если replacement имеет меньше значений, чем
pattern, то для оставшихся значений для замены используется пустая строка. Если
pattern это массив, а replacement это строка, то эта замещающая строка используется для каждого значения
pattern. Обратное не будет иметь смысла.
Модификатор /e делает так, что
preg_replace() рассматривает параметр replacement как PHP-код после выполнения соответствующей замены ссылок.Подсказка: убедитесь, что replacement образует строку правильного PHP-кода, иначе PHP сообщит об ошибке разбора в
строчке с preg_replace().
|
Этот пример даст:
$startDate = 5/27/1999 |
| Это переведёт в верхний регистр все тэги HTML в тексте ввода. |
Пример 3. Конвертация HTML в текст
|
См. также preg_match(),
preg_match_all() и
preg_split().
Символ — элемент шаблона
Важно помнить, что шаблон оперирует символами. Программирование уже давно забыло, что такое тип данных «символ»
Современные языки не опускаются ниже понятия «строка», но в отношении шаблона надо понимать: здесь манипулируют символами.
Построение шаблона — это, прежде всего, указание нужной последовательности символов. Если это четко усвоить, то ошибок в шаблоне не будет. Во всяком случае, будет гораздо меньше.
- а — это конкретный элемент шаблона — символ.
- a-z — это элемент шаблона, тоже один символ, но только со значением от a до z — вся латиница в нижнем регистре.
- 0-9 — это одна цифра, причем любая, а вот 1-3 — только 1, 2 или 3.
Регистр в шаблоне важен. Первый и последний символы шаблона имеют большое значение. Можно указать, с чего начинается шаблон и чем заканчивается.
Поиск текста функцией «preg_match_all»
Для поиска текста внутри тегов воспользуемся функцией «preg_match_all». Зададим маску поиска и посмотрим, что она возвращает в качестве результата.
$sContent = "... <xx>наташа</xx> ... <xx>даша</xx> ... <xx>настя</xx> ...";
if (preg_match_all('|<xx>(.+)</xx>|isU', $sContent, $arr)) {
echo $arr . " " . $arr . " " . $arr . "<br />";
echo $arr . " " . $arr . " " . $arr;
}
//на выходе получаем:
//<xx>наташа</xx> <xx>даша</xx> <xx>настя</xx>
//наташа даша настя
В нулевой разряд массива записались значения с тегами, а в первый — только текст между ними. Если требуется автоматизировать вывод всего найденного, то лучше использовать цикл foreach. Его рассмотрим ниже.
Функция preg_match_all возвращает «1» в случае нахождения в тексте соответствия с указанной маской или «0», если соответствий не найдено. В качестве параметров принимает маску, строку где ищем и переменную, в которую будут записаны найденные совпадения.
Маска поиска обрамляется символами «|». За ними идут директивы — «isU» обозначает регистронезависимый поиск в многострочном тексте с кодировкой «UTF-8»
|<xx>(.+)</xx>|isU
В самом правиле содержатся теги, между которыми требуется заменить текст — «(.+)». Точка символизирует любой символ, а плюс — что он может повторяться один или больше раз. Скобки говорят о том, что содержимое между ними нужно записать в переменную с результатом.
Примеры preg_match PHP
1.
if (!preg_match("/^*\@*\.{2,6}$/i", $email)) exit("Неправильный адрес");
2.
// \S означает "не пробел", а + -
// "любое число букв, цифр или точек". Модификатор 'i' после '/'
// заставляет PHP не учитывать регистр букв при поиске совпадений.
// Модификатор 's', стоящий рядом с 'i', говорит, что мы работаем
// в "однострочном режиме" (см. ниже в этой главе).
preg_match('/(\S+)@(+)/is', "Привет от somebody@mail.ru!", $p);
// Имя хоста будет в $p, а имя ящика (до @) - в $p.
echo "В тексте найдено: ящик - $p, хост - $p";
3.
if (!preg_match("|^{13,16}$|", $var)) ...
4.
if (preg_match("/(^+(*))$/" , $filename)==NULL) {
echo "invalid filename";
exit;
}
/\.(?:z(?:ip|{2})|r(?:ar|{2})|jar|bz2|gz|tar|rpm)$/i
/\.(?:mp3|wav|og(?:g|a)|flac|midi?|rm|aac|wma|mka|ape)$/i
/\.(?:exe|msi|dmg|bin|xpi|iso)$/i
/\.(?:jp(?:e?g|e|2)|gif|png|tiff?|bmp|ico)$/i
/\.(?:mpeg|ra?m|avi|mp(?:g|e|4)|mov|divx|asf|qt|wmv|m\dv|rv|vob|asx|ogm)$/i
5.
preg_match_all('/(8|7|\+7){0,1}{0,}({2}){0,}(({2}{0,}{2}{0,}{3})|({3}{0,}{2}{0,}{2})|({3}{0,}{1}{0,}{3})|({2}{0,}{3}{0,}{2}))/',
$text, $regs );
6.
if (preg_match("/^{8,20}$/",$string)) echo "yes"; else echo "no";
7.абвгДДДеёааббаабб
if (preg_match("/(.)\\1\\1/",$string)) echo "yes"; else echo "no";
8.
preg_match("/abc/", $string); // true если найдёт в любом месте
preg_match("/^abc/", $string); // true если найдёт в начале
preg_match("/abc$/", $string); // true если найдёт в конце
9.
preg_match("/(ozilla.|MSIE.3)/i", $_SERVER);
Примеры preg_replace PHP
1.
$text = preg_replace("~<a href=\"http://www\.aaa\">+?</a>~",'',$text);
2.
$text = preg_replace('#<!--.*-->#sUi', '', $text);
3.
$text = preg_replace ("~(\\\|\*|\?|\|\(|\\\$|\))~", "",$text);
4.
$text = preg_replace('/(<(+)>)/U', '', $text);
5.
$text = preg_replace('#<script*>.*?</script>#is', '', $text);
6.
$text = str_replace('#39;', '', $text); // удаляем одинарные кавычки
$text = str_replace('"', '', $text); // удаляем двойные кавычки
$text = str_replace('&', '', $text); // удаляем амперсанд
$text = preg_replace('/(()_—«»#\/]+)/', '', $text); // удаляем недоспустимые символы
7.
$text = trim($text); // удаляем пробелы по бокам
$text = preg_replace('/ /', '', $text); // чистим обычные пробелы
$text = preg_replace("/ +/", " ", $text); // множественные пробелы заменяем на одинарные
8.
$text = preg_replace("/(\r\n){3,}/", "\r\n\r\n", $text); // убираем лишние переводы строк (больше 1 строки)
9.
$file = 'image.jpg';
$file = preg_replace("/.*?\./", '', $file); // выведет image
10.
function ProcessText($text)
{
$text = trim($text); // удаляем пробелы по бокам
$text = stripslashes($text); // удаляем слэши
$text = htmlspecialchars($text); // переводим HTML в текст
$text = preg_replace("/ +/", " ", $text); // множественные пробелы заменяем на одинарные
$text = preg_replace("/(\r\n){3,}/", "\r\n\r\n", $text); // убираем лишние переводы строк (больше 1 строки)
$test = nl2br ($text); // заменяем переводы строк на тег
$text = preg_replace("/^\"(+)\"/u", "$1«$2»", $text); // ставим людские кавычки
$text = preg_replace("/(«){2,}/","«",$text); // убираем лишние левые кавычки (больше 1 кавычки)
$text = preg_replace("/(»){2,}/","»",$text); // убираем лишние правые кавычки (больше 1 кавычки)
$text = preg_replace("/(\r\n){2,}/u", "</p><p />", $text); // ставим абзацы
return $text; //возвращаем переменную
}
11.
$string = preg_replace("!<title>(.*?)</title>!si","<НОВЫЙ_ТЕГ>\\1</НОВЫЙ_ТЕГ>",$string);
12.
$text = preg_replace('#(\.|\?|!|\(|\)){3,}#', '\1\1\1', $text);
13.
$string = preg_replace("/^/", "Начало: ", $string); // в начало
$string = preg_replace("/$/", " читать далее...", $string); // в конец
14.
$text = preg_replace('#(?<!\])\bhttp://+#i',
"<a href=\"$0\" target=_blank><u>Посмотреть на сайте</u></a>",
nl2br(stripslashes($text)));
15.
$str = preg_replace('/^(.+?)(\?.*?)?(#.*)?$/', '$1$3', $url);
16.
$string = preg_replace("/^/", "
", $string); // в начало всех строк
$string = preg_replace("/$/", "
", $string); // в конец всех строк
17.
// $document на выходе должен содержать HTML-документ.
// Необходимо удалить все HTML-теги, секции javascript,
// пробельные символы. Также необходимо заменить некоторые
// HTML-сущности на их эквивалент.
$search = array ("'<script*?>.*?</script>'si", // Вырезает javaScript
"'<[\/\!]*?*?>'si", // Вырезает HTML-теги
"'()+'", // Вырезает пробельные символы
"'&(quot|#34);'i", // Заменяет HTML-сущности
"'&(amp|#38);'i",
"'&(lt|#60);'i",
"'&(gt|#62);'i",
"'&(nbsp|#160);'i",
"'&(iexcl|#161);'i",
"'&(cent|#162);'i",
"'&(pound|#163);'i",
"'&(copy|#169);'i",
"'&#(\d+);'e"); // интерпретировать как php-код
$replace = array ("",
"",
"\\1",
"\"",
"&",
"<",
">",
" ",
chr(161),
chr(162),
chr(163),
chr(169),
"chr(\\1)");
$text = preg_replace($search, $replace, $document);
18.
$html = preg_replace( '/(\S+)@(+)/is', '<a href="mailto:$0">$0</a>', $text);
Описание
int preg_match_all (string pattern, string subject, array matches )
Ищет в subject все совпадения с регулярным выражением pattern и помещает их в
matches в порядке, специфицированном в
order.
После нахождения первого совпадения последующий поиск продолжается до
нахождения последнего совпадения.
flags может быть комбинацией следующих флагов
(обратите внимание, что нет смысла использовать
PREG_PATTERN_ORDER вместе с
PREG_SET_ORDER):
- PREG_PATTERN_ORDER
- Упорядочивает результаты таким образом, что $matches это массив
полных совпадений с патэрном, $matches это массив строк, совпавших с
первым субпатэрном в скобках, и так далее.preg_match_all ("|<+>(.*)</+>|U", "<b>example: </b><div align=left>this is a test</div>", $out, PREG_PATTERN_ORDER); print $out.", ".$out."\n"; print $out.", ".$out."\n";Этот пример выдаст:
<b>example: </b>, <div align=left>this is a test</div> example: , this is a test
Итак, $out содержит массив строк, совпавших со всем патэрном,
а $out содержит массив строк, заключённых в тэги. - PREG_SET_ORDER
- Упорядочивает результаты таким образом, что $matches это массив
первого набора совпадений, $matches это массив второго набора совпадений,
и так далее.preg_match_all ("|<+>(.*)</+>|U", "<b>example: </b><div align=left>this is a test</div>", $out, PREG_SET_ORDER); print $out.", ".$out."\n"; print $out.", ".$out."\n";Этот пример выдаст:
<b>example: </b>, example: <div align=left>this is a test</div>, this is a test
В данном случае $matches это первый набор совпадений, а
$matches содержит текст, совпавший с полным патэрном, $matches
содержит текст, совпавший с первым субратэрном, и так далее.
Аналогично $matches это второй набор совпадений, etc. - PREG_OFFSET_CAPTURE
- Если этот флаг установлен, для каждого возникшего совпадения будет
возвращено дополнительное строковое смещение. Заметьте, что это изменяет return-значение
в массиве, где каждый элемент является массивом, состоящим из совпавшей
строки в смещении 0 и её строкового смещения в subject — в смещении 1.
Этот флаг доступен, начиная с PHP 4.3.0.
Если никакой флаг упорядочивания не задан, принимается PREG_PATTERN_ORDER.
Возвращает количество полных совпадений с патэрном (это может быть нуль),
или FALSE при ошибке.
Пример 1. Получение всех телефонных номеров из текста.
|
Пример 2. Поиск совпадений с HTML-тэгами (greedy/жадный)
|
Этот пример выдаст:
matched: <b>bold text</b> part 1: <b> part 2: bold text part 3: </b> matched: <a href=howdy.html>click me</a> part 1: <a href=howdy.html> part 2: click me part 3: </a> |
См. также preg_match(),
preg_replace() и preg_split().
Простая практика preg match php
Шаблон для целого числа:
«/*/»
Тоже шаблон целого числа, но спереди может быть знак («+», «-«), и спереди/сзади могут быть лишние пробелы:
/^{0,1}*/
Аналогично:
- /^{0,1}*(\.)*/ — число с точкой.
- /+@+\.{2,3}/ — вариант для распознавания e-mail.
Применение собственных шаблонов для preg match all, примеры их в интернете, анализ кода страниц сайтов и другие источники позволяют сформировать собственную библиотеку шаблонов.
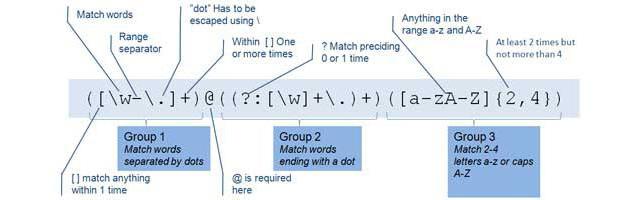
Вариантов для поиска информации может быть множество. В частности, приведенные последние две конструкции можно смоделировать иначе. Во многих случаях предпочтение будет иметь тот шаблон, который быстрее и точнее обеспечит нужное совпадение. Применение на PHP preg match all, как и аналогичных функций на других языках, требует практики, внимания и предварительной проверки правильности шаблонов.
Использование нумирации в заменах и другие продвинутые возможности
Теперь немного о продвинутых возможностях функции «preg_replace_callback». Ранее я упоминал что у неё есть два необязательных параметра. Первый (по умолчанию равен «-1») содержит максимальное количество замен, которое должна произвести функция. Второй — переменная, в которую будет записано количество произведенных замен.
$sContent = preg_replace_callback('|(<xx>)(.+)(</xx>)|iU',
function($matches){ //тут код }
,$sContent,2,$count);
Задав эти два параметра в предыдущем примере, замена главной буквы будет произведена только у первых двух имён. Соответственно, переменная «$count» будет содержать — 2. Если установить первый дополнительный параметр в «-1», то «$count» будет — 3.
И в конце о том, как узнать какая по счету замена происходит в данный момент. Это может потребоваться если появилась необходимость произвести замену между пятым и десятым найденным элементом строки или требуется для каких-то тегов прописать уникальные идентификаторы.
Для реализации может быть использована глобальная или статическая переменная. Использование глобальных переменных может быть отключено в PHP, поэтому рассмотрим пример со статической переменной. Присвоим всем тегам h2 уникальный идентификатор.
<?php
$str = '<h2>Марина</h2> <b>Алёша</b> <h2>Наташа</h2> <h2>Катя</h2>';
$str = preg_replace_callback('|<h2>(.+)</h2>|iU', function($matches){
static $id = 0;
$id++;
return '<h2 id="uniq-'.$id.'">'.$matches.'</h2>';
}, $str,-1,$count);
echo $str.' Количество замен: '.$count;
?>
Объявляя статическую переменную нужно помнить что она сохраняет своё значение между вызовами функции, поэтому идеально подходит для решения нашей задачи.
Поиск текста между тегами
Допустим, у нас есть следующий текст:
И из него нужно достать текст, который находится между тегами <span> и </span>.
Проще всего это сделать с помощью регулярных выражений:
Функция preg_match_all() принимает 3 параметра: шаблон поиска, сам текст и переменную, в которую эта функция сохранит результаты поиска.
Поскольку функция возвращает количество найденных строк (или false в случае ошибки), мы можем сразу подставить её в оператор if.
Массив с результатами поиска (в нашем случае $result) состоит из двух частей: в $result будут найденные строки вместе с открывающим и закрывающим тегами span, а в $result будут те же строки без тега span, т.е. тот текст, что находится в круглых скобках.
Маска регулярного выражения находится между вертикальными чертами |. В шаблоне (.*) точка означает любой символ, звёздочка — любое количество символов (т.е. суммарно получаем «любое количество любых символов»).
Скобки говорят, что найденный текст нам нужно получить отдельно. Без скобок мы получим только $result, а $result не будет существовать.
Чтобы найти только не пустые теги, можно заменить .* на .+. Плюсик означает любое количество символов, но не меньше одного.
Uis — модификаторы. U означает работу с UTF-8, i — регистронезависимый поиск, s — что символ точка включает в себя переносы строк, т.е. поиск будет по всем строкам, а не по одной.