Документация по модулю python pandas
Содержание:
- Быстро: простые графики в Pandas
- Count unique values in a single column
- Count unique values in each column of the dataframe
- Get Unique values in a multiple columns
- Решение № 2: Сложенные бары
- Графики плотности
- Multiple Pandas Histograms from a DataFrame
- Коврики
- Выводы
- Matplotlib
- Важность статистических распределений
- Для просмотра групп
- Операции с текстовыми данными в Pandas
- Решение № 3 График плотности
- Single Histogram from a Pandas DataFrame
- Что такое функция groupby()?
- Introduction to Pandas Histograms
- Очень красиво: потрясающие интерактивные графики в Plotly
- Решение № 1: параллельные гистограммы
Быстро: простые графики в Pandas

Pandas имеет встроенные функции построения графиков, которые можно вызывать непосредственно из Series и DataFrame. За что я обожаю эти функции, это за их краткость, за разумные значения по умолчанию и за то, что с их помощью можно быстро понять, что происходит с данными.
Для создания графика просто вызовите метод следующим образом:
np.exp(data==2018]).plot(
kind='hist'
)
В результате выполнения этой команды получится следующий график:
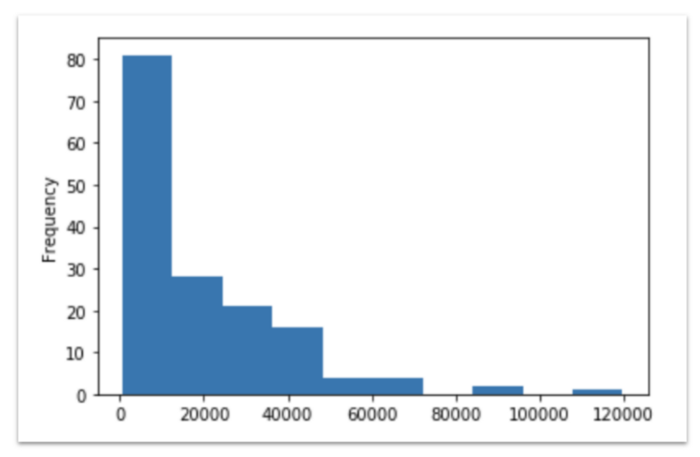
2018: Гистограмма количества стран в зависимости от ВВП на душу населения. Тут никаких сюрпризов: большинство стран бедны!
При построении графиков в Pandas я использую пять основных параметров:
- Pandas должна знать, какого типа график вы хотите строить. Возможны следующие варианты: .
- Позволяет переопределить значение размера, заданное по умолчанию (6 дюймов в ширину и 4 дюйма в высоту). Данный параметр принимает на вход кортеж, например , что я часто использую.
- Добавляет к графику заголовок. Как правило, я его использую, чтобы кратко описать, что происходит на графике, дабы потом это можно было быстро понять. Данный параметр принимает на вход строку.
- Позволяет переопределить ширину областей гистограммы. Данный параметр принимает на вход список или подобную ему последовательность, например .
- Позволяет переопределить максимальные и минимальные значения осей и . Оба параметра принимают на вход кортежи, например .
Давайте быстро пробежимся по некоторым типам таких графиков.
Вертикальная гистограмма
data == 2018
].set_index('Country name').nlargest(15).plot(
kind='bar',
figsize=(12,8)
)
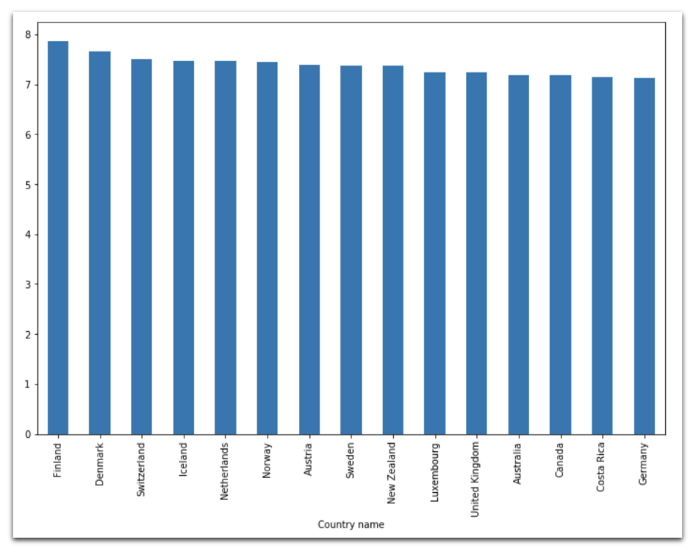
2018: Список 15 самых счастливых стран в мире. Лидирует Финляндия.
Горизонтальная гистограмма
np.exp(data == 2018
].groupby('Continent')\
.mean()).sort_values().plot(
kind='barh',
figsize=(12,8)
)
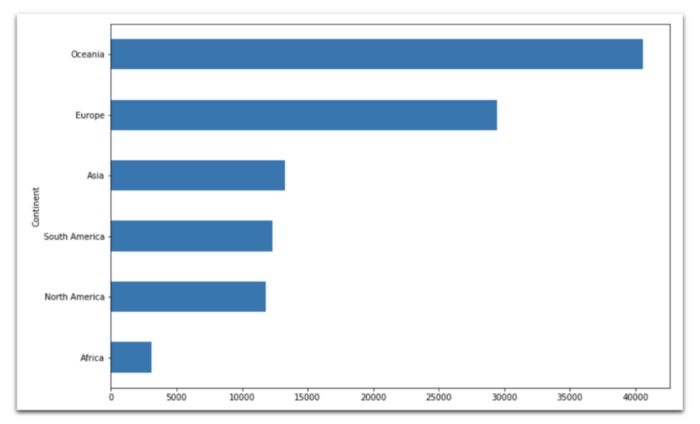
Средний ВВП на душу населения с разбивкой по континентам. Лидерство Австралии и Новой Зеландии неоспоримо.
Ящик с усами (Box plot)
data.plot(
kind='box',
figsize=(12,8)
)
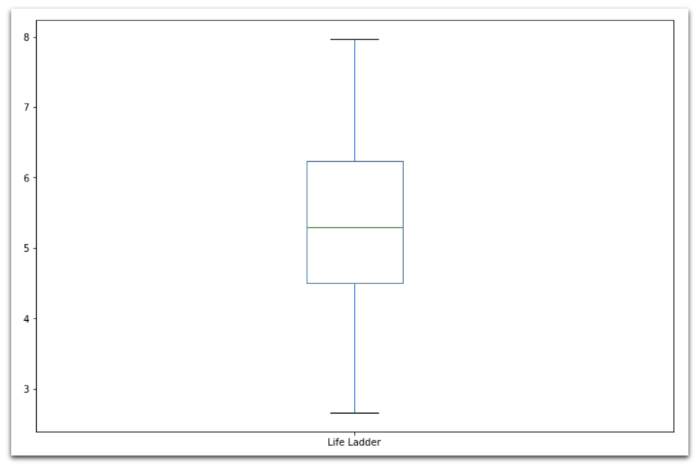
Распределение параметра Life Ladder («лестница жизни») показывает, что медианное значение «счастья» находится где-то в районе 5.5, и варьируется от 3 до 8.
Точечный график (диаграмма рассеяния)
data].plot(
kind='scatter',
x='Healthy life expectancy at birth',
y='Gapminder Life Expectancy',
figsize=(12,8)
)
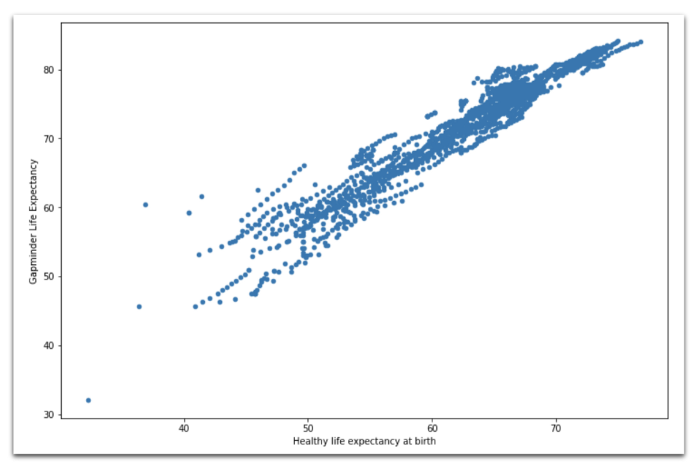
Диаграмма рассеяния ожидания продолжительности здоровой жизни из Всемирного доклада о счастье (ось х) и ожидания продолжительности жизни из Gapminder (ось у) демонстрирует сильную корреляцию между этими данными (что не удивительно).
Гексбиновая диаграмма
data == 2018].plot(
kind='hexbin',
x='Healthy life expectancy at birth',
y='Generosity',
C='Life Ladder',
gridsize=20,
figsize=(12,8),
cmap="Blues", # по умолчанию зеленый
sharex=False # необходимо, чтобы не допустить ошибок
)
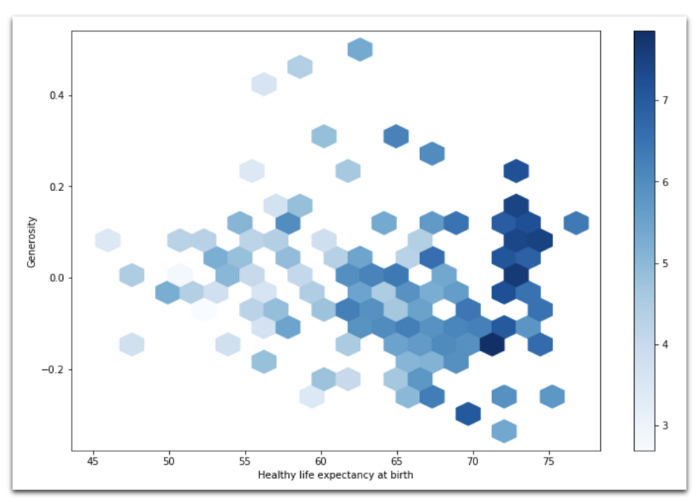
2018: Гексбиновая диаграмма показывает зависимость ожидаемой продолжительности жизни от щедрости.
Круговая диаграмма
data == 2018].groupby(
).sum().plot(
kind='pie',
figsize=(12,8),
cmap="Blues_r", # по умолчанию оранжевый
)
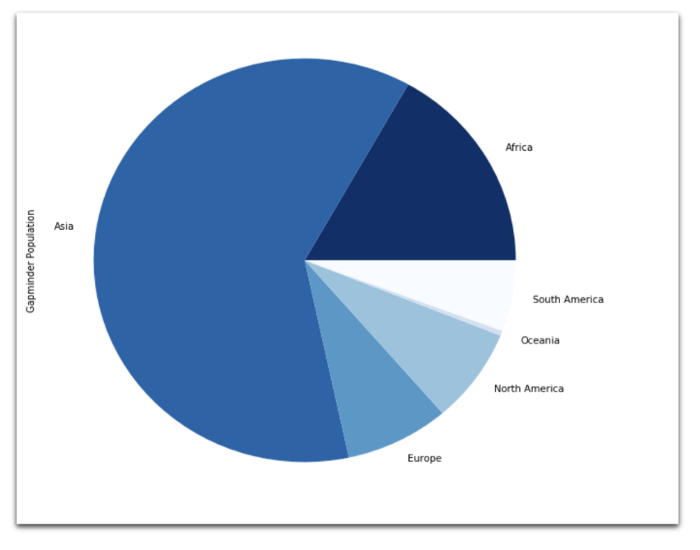
2018: Круговая диаграмма показывает количество жителей планеты с разбивкой по континентам.
Диаграмма с накоплением
data.groupby(
).sum().unstack().plot(
kind='area',
figsize=(12,8),
cmap="Blues", # по умолчанию оранжевый
)
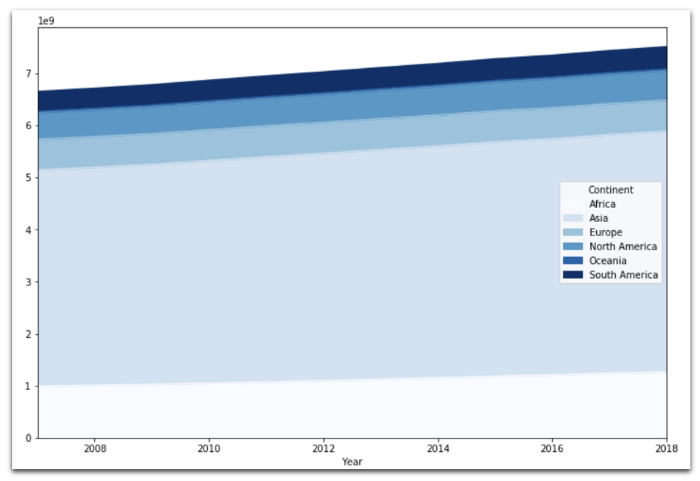
Количество жителей планеты растет.
Линейный график
data == 'Germany'
].set_index('Year').plot(
kind='line',
figsize=(12,8)
)
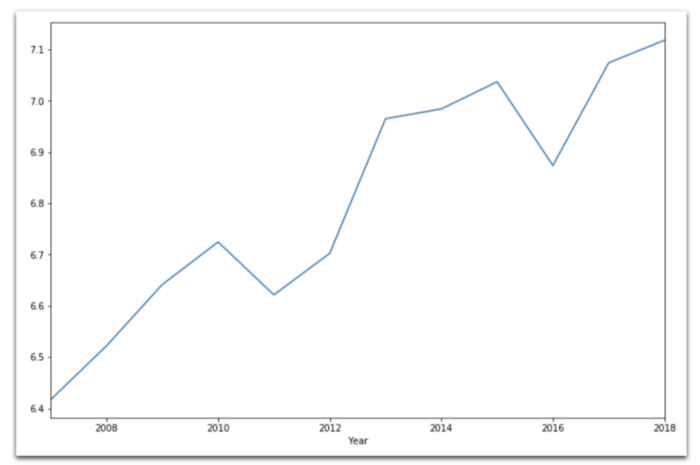
Динамика счастья в Германии.
Выводы
Строить графики в библиотеке pandas удобно, просто и быстро. Правда, они выходят слегка корявыми. Но это нормально, так как для создания более эстетичных графиков у нас есть другие инструменты. Переходим к библиотеке .
Count unique values in a single column
Suppose instead of getting the name of unique values in a column, if we are interested in count of unique elements in a column then we can use series.unique() function i.e.
# Count unique values in column 'Age' of the dataframe
uniqueValues = empDfObj.nunique()
print('Number of unique values in column "Age" of the dataframe : ')
print(uniqueValues)
Number of unique values in column "Age" of the dataframe : 4
Include NaN while counting the unique elements in a column
Using nunique() with default arguments doesn’t include NaN while counting the unique elements, if we want to include NaN too then we need to pass the dropna argument i.e.
# Count unique values in column 'Age' including NaN
uniqueValues = empDfObj.nunique(dropna=False)
print('Number of unique values in column "Age" including NaN')
print(uniqueValues)
Number of unique values in column "Age" including NaN 5
Count unique values in each column of the dataframe
In Dataframe.nunique() default value of axis is 0 i.e. it returns the count of unique elements in each column i.e.
# Get a series object containing the count of unique elements
# in each column of dataframe
uniqueValues = empDfObj.nunique()
print('Count of unique value sin each column :')
print(uniqueValues)
Count of unique value sin each column : Name 7 Age 4 City 4 Experience 4 dtype: int64
# Count unique elements in each column including NaN
uniqueValues = empDfObj.nunique(dropna=False)
print("Count Unique values in each column including NaN")
print(uniqueValues)
Count Unique values in each column including NaN Name 7 Age 5 City 5 Experience 4 dtype: int64
Get Unique values in a multiple columns
To get the unique values in multiple columns of a dataframe, we can merge the contents of those columns to create a single series object and then can call unique() function on that series object i.e.
# Get unique elements in multiple columns i.e. Name & Age
uniqueValues = (empDfObj.append(empDfObj)).unique()
print('Unique elements in column "Name" & "Age" :')
print(uniqueValues)
Unique elements in column "Name" & "Age" :
Complete example is as follows,
import pandas as pd
import numpy as np
def main():
# List of Tuples
empoyees =
# Create a DataFrame object
empDfObj = pd.DataFrame(empoyees, columns=, index=)
print("Contents of the Dataframe : ")
print(empDfObj)
print("*** Find unique values in a single column ***")
# Get a series of unique values in column 'Age' of the dataframe
uniqueValues = empDfObj.unique()
print('Unique elements in column "Age" ')
print(uniqueValues)
print("*** Count unique values in a single column ***")
# Count unique values in column 'Age' of the dataframe
uniqueValues = empDfObj.nunique()
print('Number of unique values in column "Age" of the dataframe : ')
print(uniqueValues)
print("*** Count Unique values in each column including NaN ***")
# Count unique values in column 'Age' including NaN
uniqueValues = empDfObj.nunique(dropna=False)
print('Number of unique values in column "Age" including NaN')
print(uniqueValues)
print("*** Count Unique values in each column ***")
# Get a series object containing the count of unique elements
# in each column of dataframe
uniqueValues = empDfObj.nunique()
print('Count of unique value sin each column :')
print(uniqueValues)
# Count unique elements in each column including NaN
uniqueValues = empDfObj.nunique(dropna=False)
print("Count Unique values in each column including NaN")
print(uniqueValues)
print("*** Get Unique values in a multiple columns ***")
# Get unique elements in multiple columns i.e. Name & Age
uniqueValues = (empDfObj.append(empDfObj)).unique()
print('Unique elements in column "Name" & "Age" :')
print(uniqueValues)
if __name__ == '__main__':
main()
Contents of the Dataframe :
Name Age City Experience
a jack 34.0 Sydney 5
b Riti 31.0 Delhi 7
c Aadi 16.0 NaN 11
d Mohit 31.0 Delhi 7
e Veena NaN Delhi 4
f Shaunak 35.0 Mumbai 5
g Shaun 35.0 Colombo 11
*** Find unique values in a single column ***
Unique elements in column "Age"
*** Count unique values in a single column ***
Number of unique values in column "Age" of the dataframe :
4
*** Count Unique values in each column including NaN ***
Number of unique values in column "Age" including NaN
5
*** Count Unique values in each column ***
Count of unique value sin each column :
Name 7
Age 4
City 4
Experience 4
dtype: int64
Count Unique values in each column including NaN
Name 7
Age 5
City 5
Experience 4
dtype: int64
*** Get Unique values in a multiple columns ***
Unique elements in column "Name" & "Age" :
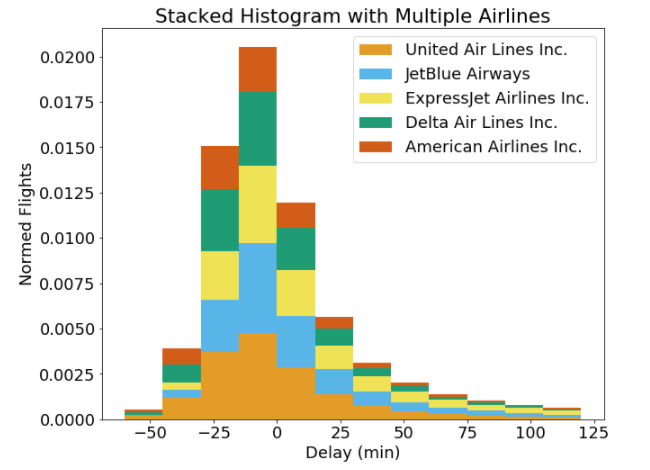
Решение № 2: Сложенные бары
Вместо того, чтобы строить столбцы для каждой авиакомпании бок о бок, мы можем сложить их, передав параметрна вызов гистограммы:
# Stacked histogram with multiple airlinesplt.hist(, bins = int(180/15), stacked=True, normed=True, color = colors, label=names)

Ну, это точно не лучше! Здесь каждая авиакомпания представлена как единое целое для каждой корзины, но сравнить ее практически невозможно. Например, с задержкой от -15 до 0 минут, имеет ли United Air Lines или JetBlue Airlines больший размер полосы? Я не могу сказать, и зрители не смогут либо. Я вообще не сторонник стековых баров, потому что их может быть сложно интерпретировать (хотя есть варианты использованиянапример, при визуализации пропорций). Оба решения, которые мы пытались использовать с помощью гистограмм, не увенчались успехом, и пришло время перейти к графику плотности.
Графики плотности
Во-первых, что такое график плотности?график плотностиявляется сглаженной, непрерывной версией гистограммы, оцененной по данным. Наиболее распространенная форма оценки известна какоценка плотности ядра, В этом методе непрерывная кривая (ядро) рисуется в каждой отдельной точке данных, и все эти кривые затем складываются, чтобы сделать единую плавную оценку плотности. Ядро, наиболее часто используемое — это гауссово (которое создает гауссову кривую колокола в каждой точке данных). Если, как и я, вы находите это описание немного запутанным, взгляните на следующий сюжет:
Оценка плотности ядра (Источник)
Здесь каждая маленькая черная вертикальная линия на оси x представляет точку данных. Отдельные ядра (в данном примере гауссианы) показаны пунктирными красными линиями над каждой точкой. Сплошная синяя кривая создается путем суммирования отдельных гауссианов и образует график общей плотности.
Ось X — это значение переменной, как в гистограмме, ночто именно представляет ось Y? Ось Y на графике плотности является функцией плотности вероятности для оценки плотности ядра. Тем не менее, мы должны быть осторожны, чтобы указать, что это вероятностьплотностьа не вероятность. Разница заключается вПлотность вероятности — это вероятность на единицу по оси X, Чтобы преобразовать фактическую вероятность, нам нужно найти область под кривой для определенного интервала по оси X. Несколько запутанно, потому что это плотность вероятности, а не вероятность,Ось Y может принимать значения больше единицы.Единственным требованием графика плотности является то, что общая площадь под кривой интегрируется в единицу. Я обычно склонен думать об оси Y на графике плотности как о значении только для относительных сравнений между различными категориями.
Multiple Pandas Histograms from a DataFrame
The feature can take a list of column names to produce separate plots for each chosen column:
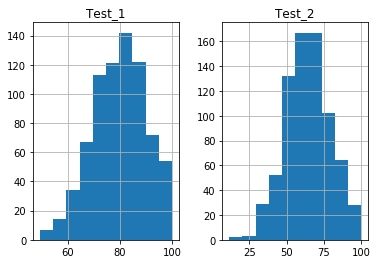
The histograms will be plotted side-by-side for you. Notice the axes are automatically adjusted by default, so the scales may be different for each Pandas DataFrame histogram.
Modifying Histogram Axes
Again, you may notice in the above plots, the x and y axes are not the same. Different scales can complicate side-by-side data comparisons, so we would prefer to set both of the axes to the same range and scale. We can do this with the and options. These options accept boolean values, which are False by default. If these options are set to True, then the respective axis range and scale is shared between plots:
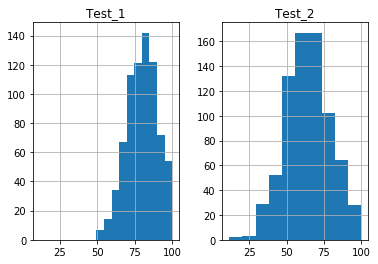
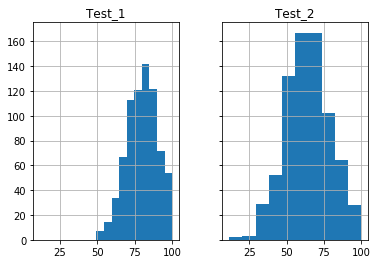
Note: Be careful when comparing histograms this way. The range over which bins are set in the Test_1 data are smaller than those in the Test_2 data, leading to larger boxes in Test_2 than Test_1. The result is that while both plots have the same number of data points,Test_2 appears “larger” because of the default bar widths.
Plotting Multiple Features in One Plot
Suppose we wanted to present the histograms on the same plot in different colors. To do this, we will have to slightly change our syntax and use the method. This method contains more specific options for plotting. It does not, however, contain a option, therefore we will have to slice the DataFrame prior to calling the method.
Recall our DataFrame had 3 columns of data. To only plot the Test_1 and Test_2 data, we’ll need to slice it like this:
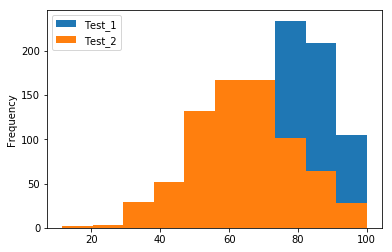
This code snippet plotted both histograms on the same plot, but the second plot “blocks” the view of the first. We can solve this problem by adjusting the transparency option, which takes a value in the range , where 0 is fully transparent and 1 is fully opaque.
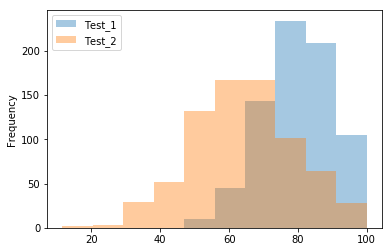
Now we can see the intersection of the plots. It’s worth noting that not all the plotting features are available in the Pandas plotting methods. Be aware that if the Pandas methods do not have the options you wish to apply to your plots, you’ll have to resort to using manual Matplotlib functions.
Grouping Pandas data with ‘by’ Option
We’re going to end this tutorial by talking about something a little more complicated. Suppose our data is grouped according to some feature of the data, or that our data exists in categories. In this case, we may want to determine the distributions of each type separately. In our example data, these categories are specified by the Type column, which is the third column in our DataFrame.
We can create multiple plots of data grouped by a feature using the option of the method. The option will take an object by which the data can be grouped. This can include a string of the column name you use to separate the data. This is exactly what we’re doing in our final example:

Histograms are just one way of plotting the distribution of data. For another helpful method, check out our tutorial on creating Pandas Density Plots, which plot the normalized frequency of occurrences in our dataframe.
On a related note, you can also plot a normalized histogram by setting the argument to True, like this:
Did you find this free tutorial helpful? You can find more great Python tips and tutorials by subscribing to our systematic Python training program below. Not ready to join? Share this article with your friends, classmates, and coworkers on and , instead! When you spread the word on social media, you’re helping us grow so we can continue to provide free tutorials like this one for people around the world.
Can’t get enough Python?
-
Notice that this fast method of histogram creation is the method , rather than (with the method explicitly included). The method contains default settings that are more applicable to fast, though simple, exploratory analysis. The will be used when we wish to specify more options for plotting. See the Manual Page for additional information.
Коврики
Если вы хотите показать каждое значение в распределении, а не только сглаженную плотность, вы можете добавить график коврика. Это показывает каждую отдельную точку данных на оси X, что позволяет нам визуализировать все фактические значения. Преимущество использования Seaborn’sявляется то, что мы можем добавить сюжет коврика с помощью одного вызова параметра(с некоторым форматированием также).
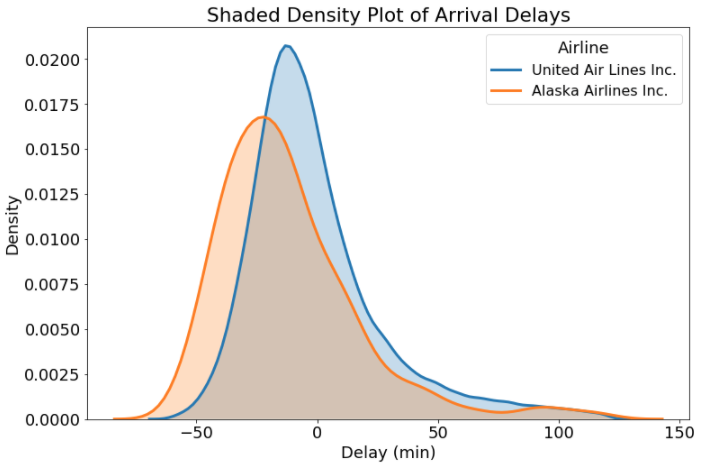
График плотности с ковриком для авиакомпании Аляска
Со многими точками данных график коврика может быть переполнен, но для некоторых наборов данных может быть полезно просмотреть каждую точку данных. График коврика также позволяет нам увидеть, как график плотности «создает» данные там, где их нет, потому что он выполняет распределение ядра в каждой точке данных. Эти распределения могут утекать во всем диапазоне исходных данных и создавать впечатление, что задержки в авиакомпании Alaska Airlines короче и длиннее, чем фактически зафиксированные. Мы должны быть осторожны с этим артефактом графиков плотности и указать его зрителям!
Выводы
Надеемся, что этот пост предоставил вам ряд возможностей для визуализации одной переменной из одной или нескольких категорий. Есть еще более одномерные (с одной переменной) графики, которые мы можем сделать, такие какграфики эмпирической совокупной плотности и квантиль-квантиль, но пока мы оставим это на гистограммах и графиках плотности (и на графиках ковров тоже!). Не беспокойтесь, если варианты кажутся ошеломляющими: с практикой сделать правильный выбор станет легче, и вы всегда можете обратиться за помощью в случае необходимости. Более того, зачастую не существует оптимального выбора, и «правильное» решение сводится к предпочтениям и целям визуализации. Хорошая вещь, независимо от того, какой сюжет вы хотите сделать, в Python найдется способ сделать это! Визуализации являются эффективным средством передачи результатов, и знание всех доступных параметров позволяет нам выбрать правильную фигуру для наших данных.
Я приветствую отзывы и конструктивную критику@koehrsen_will,
Matplotlib
Matplotlib имеет мощную и при этом еще и красивую визуализацию. Она представляет собой библиотеку построения графиков для Python с 26000 коммитами на GitHub и активным сообществом примерно из 700 участников. Благодаря графикам и чертежам, которые умеет выводить Matplotlib, она широко используется для визуализации данных. Matplotlib также предоставляет объектно-ориентированный API, который можно использовать для встраивания графиков в различные приложения.
Особенности:
- Может использоваться в качестве бесплатной альтернативы MATLAB, с открытым исходным кодом.
- Поддерживает десятки подчиненных приложений и типов данных для вывода, что означает, что вы можете пользоваться Matplotlib вне зависимости от того какая у вас операционная система и какой формат вы предпочитаете.
- Pandas может быть использована в качестве оболочки для Matplotlib API для управления Matplotlib, в качестве фильтра.
- Низкое потребление памяти и хорошая работа во время выполнения.
Области использования:
- Корреляционный анализ переменных.
- Визуализация интервалов 95-процентной вероятности для моделей.
- Обнаружение выделяющихся значений с использованием точечной диаграммы и т. п.
- Визуализация распределения данных для получения реальной картины
Видео Top 5 Python Libraries for Data Science демонстрирует простые примеры, которые помогут получить общее представление о возможностях Matplotlib.
Наряду с этими библиотеками специалисты Data Science также используют возможности некоторых других полезных библиотек:
Подобно TensorFlow, Keras — является еще одной популярной библиотекой, которая широко используется для модулей глубокого обучения и нейронных сетей. Keras поддерживает в качестве подчиненного приложения как TensorFlow, так и Theano, поэтому представляет собой хороший вариант, если вы не хотите погружаться в детали TensorFlow.
Scikit-learn — это библиотека машинного обучения, которая предоставляет практически все необходимые алгоритмы машинного обучения. Scikit-learn предназначен для совместной работы с NumPy и SciPy.
Seabourn — еще одна библиотека для визуализации данных. Это расширение matplotlib, предоставляющее дополнительные типы графиков.
Вот видео Simplilearn, в котором рассматриваются 5 лучших библиотек Python для Data Science, созданное экспертами в этой области.
В дополнение к пяти наиболее популярным библиотекам Python и трем другим полезным библиотекам, которые здесь обсуждались, есть много других не менее ценных библиотек для Data Science, заслуживающих вашего внимания. О них вы сможете прочитать в наших следующих статьях.
Важность статистических распределений
Я начал изучать статистику (курс Stats 119), учась в Сан-Диего. Этот курс является вводным и включает в себя самые основы статистики, как например, агрегацию данных (визуальную и количественную), концепцию шансов и вероятностей, регрессию, выборки и, самое главное, статистические распределения. В это время мое понимание тех или иных количественных феноменов практически полностью сдвинулось в сторону представления их в виде статистических распределений (как правило, гауссовых).
И по сей день я нахожу потрясающим, как всего две величины, математическое ожидание и дисперсия, могут помочь вам постичь суть явления. Просто зная эти два числа, легко сделать вывод, насколько вероятен тот или иной результат. Мы сразу знаем, в какой области будут основные результаты. Это дает нам возможность быстро выделять статистически значимые явления, не производя при этом сложных вычислений.
В общем, теперь при работе с любыми новыми данными моим первым шагом всегда является попытка визуализировать их статистическое распределение.
Для просмотра групп
Помимо разделения данных в соответствии с определенным значением столбца, мы можем даже просмотреть детали каждой группы, сформированной из категорий столбца, используя функцию .
Вот снимок образца набора данных, используемого в этом примере:

Синтаксис:
dataframe.groupby('column').groups
Пример:
import pandas
data = pandas.read_csv("C:/marketing_tr.csv")
data_grp = data.groupby('marital').groups
data_grp
Как видно выше, мы разделили данные и сформировали новый фрейм данных значений из столбца — «семейный».
Кроме того, мы использовали функцию groupby(). Groups для отображения всех категорий значений, присутствующих в этом конкретном столбце.
Кроме того, он также представляет положение этих категорий в исходном наборе данных вместе с типом данных и количеством имеющихся значений.
Выход:
{'divorced': Int64Index(,
dtype='int64', length=843),
'married': Int64Index(,
dtype='int64', length=4445),
'single': Int64Index(,
dtype='int64', length=2118),
'unknown': Int64Index(, dtype='int64')}
Операции с текстовыми данными в Pandas
Строковые функции Python можно применять к DataFrame.
Ниже приводится список наиболее часто используемых строковых функций в DataFrame:
| Функция |
| lower(): преобразует строку в DataFrame в нижний регистр. |
| upper(): преобразует строку в DataFrame в верхний регистр. |
| len(): возвращает длину строки. |
| strip(): обрезает пробелы с обеих сторон ввода в DataFrame. |
| split (»): разбивает строку с шаблоном ввода. |
| contains (pattern): возвращает истину, если переданная подстрока присутствует во входном элементе DataFrame. |
| replace (x, y): меняет значения x и y. |
| startwith (шаблон): возвращает истину, если входной элемент начинается с предоставленного аргумента. |
| endwith (pattern): возвращает истину, если входной элемент заканчивается предоставленным аргументом. |
| swapcase: меняет верхний регистр на нижний и наоборот. |
| islower(): возвращает логическое значение и проверяет, все ли символы ввода в нижнем регистре или нет. |
| isupper(): возвращает логическое значение и проверяет, все ли символы ввода находятся в верхнем регистре или нет. |
Пример:
import pandas
import numpy
input = pandas.Series()
print("Converting the DataFrame to lower case....\n")
print(input.str.lower())
print("Converting the DataFrame to Upper Case.....\n")
print(input.str.upper())
print("Displaying the length of data element in each row.....\n")
print(input.str.len())
print("Replacing 'a' with '@'.....\n")
print(input.str.replace('a','@'))
Выход:
Converting the DataFrame to lower case.... 0 john 1 bran 2 caret 3 joha 4 sam dtype: object Converting the DataFrame to Upper Case..... 0 JOHN 1 BRAN 2 CARET 3 JOHA 4 SAM dtype: object Displaying the length of data element in each row..... 0 4 1 4 2 5 3 4 4 3 dtype: int64 Replacing 'a' with '@'..... 0 John 1 Br@n 2 C@ret 3 Joh@ 4 S@m dtype: object
Решение № 3 График плотности
Теперь, когда мы понимаем, как строится график плотности и что он представляет, давайте посмотрим, как он может решить нашу проблему визуализации задержек прибытия нескольких авиакомпаний. Чтобы показать распределения на одном и том же участке, мы можем перебирать авиакомпании, каждый раз звоняс оценкой плотности ядра, установленной на True, и гистограммой, установленной на False. Код для построения графика плотности с несколькими авиакомпаниями ниже:
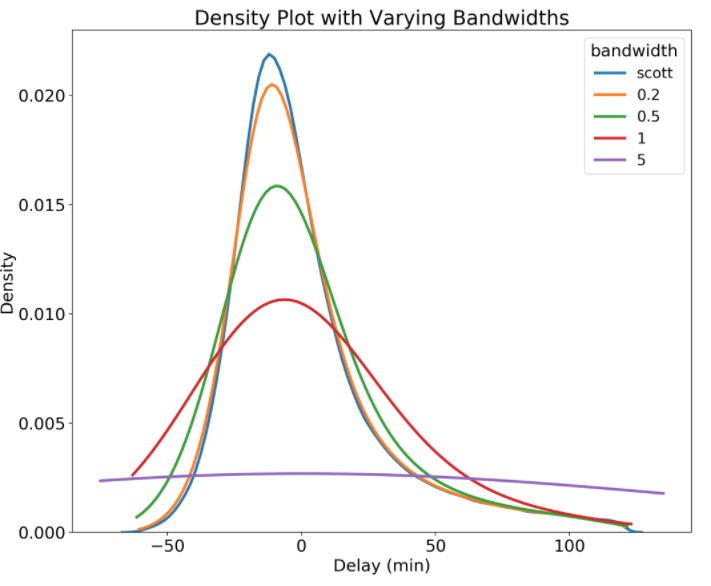
График плотности с несколькими авиакомпаниями
Наконец-то мы пришли к эффективному решению! С графиком плотности, мы можем легко сделать сравнение между авиакомпаниями, потому что график менее загроможден. Теперь, когда у нас наконец есть сюжет, который мы хотим, мы приходим к выводу, что у всех этих авиакомпаний есть почти идентичные распределения задержек прилета! Однако в наборе данных есть другие авиакомпании, и мы можем нанести на график одну из них, которая будет немного отличаться, чтобы проиллюстрировать еще один необязательный параметр для графиков плотности, заштриховывая график.
Single Histogram from a Pandas DataFrame
The simple method above plotted histograms of every feature in the DataFrame. If we wish to only examine a subset of the features, or even look at only one, then we can specify what we want to plot using the parameter of the method. The feature takes either a string or list of strings of columns names:
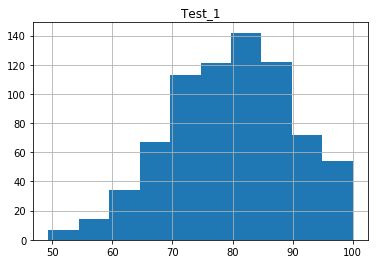
We’ll demonstrating with a list of strings shortly.
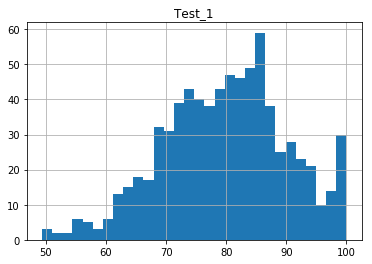
Modifying Histogram Bin Sizes
The bins, or bars of the histogram plot, can be adjusted using the option. This option can be tuned depending on the data, to see either subtle distribution trends, or broader phenomena. Which bin size to use heavily depends on the data set you use, therefore it is important to know how to change this parameter. The default number of bars is 10.
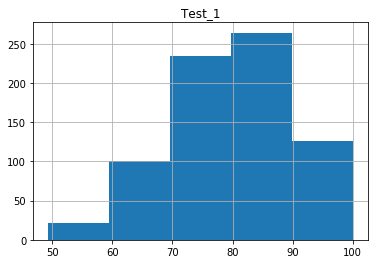
Что такое функция groupby()?
Модуль Python Pandas широко используется для улучшения предварительной обработки данных и используется для визуализации данных.
Модуль Pandas имеет различные встроенные функции для более эффективной работы с данными. Функция используется для разделения и выделения некоторой части данных из всего набора данных на основе определенных предопределенных условий или параметров.
Синтаксис:
dataframe.groupby('column-name')
Используя приведенный выше синтаксис, мы можем разделить набор данных и выбрать все данные, принадлежащие переданному столбцу, в качестве аргумента функции.
Входной набор данных:

Пример:
import pandas
data = pandas.read_csv("C:/marketing_tr.csv")
data_grp = data.groupby('marital')
data_grp.first()
В приведенном выше примере мы использовали функцию groupby() для разделения и отдельного создания нового фрейма данных со всеми данными, принадлежащими столбцу marital, соответственно.
Выход:

Introduction to Pandas Histograms
Histograms are a powerful tool for analyzing the distribution of data. Plots like histograms that characterize the distribution of individual variables or features are vital for data analysis because they help reveal patterns in the input data. Pandas DataFrames that contain our data come pre-equipped with methods for creating histograms, making preparation and presentation easy.
We can create histograms from Pandas DataFrames using the DataFrame method, which is a sub-method of . Pandas uses the Python module Matplotlib to create and render all plots, and each plotting method from takes optional arguments that are passed to the Matplotlib functions. In this tutorial, we will cover the essential tools and options for plotting histograms from Pandas DataFrames, but you should be aware that many more options (e.g. plot color, orientation, size, etc.) are available to be passed to the Matplotlib via .
If you’re trying to find out how to plot your Pandas DataFrame data in a histogram, we’re going to assume you’ve already built your Pandas DataFrame. We’ve already built ours, too! To illustrate creating histograms, we’re going assume we have the following DataFrame df containing test grades already available within our Python environment:
Can’t get enough Python?
Here we have two features, Test_1 and Test_2, along with a group number for each test given by the feature Type. A “feature” is just a what we call a piece of measurable information about a topic.
If we would like to create a fast and simple histogram for exploratory analysis, we can use the simple method, like this:
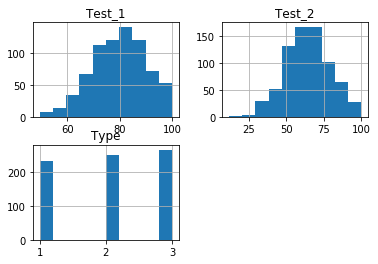
This command produced histograms for each of the 3 features we specified. However, if we want to perform additional analysis by altering the plots, we will have to specify additional options when calling our histograms.
Очень красиво: потрясающие интерактивные графики в Plotly

И наконец-то, больше никакой Matplotlib! У библиотеки Plotly есть три важных свойства:
- «Зависание»: когда курсор «зависает» над графиком, всплывает окно с аннотацией.
- Интерактивность: графики легко могут быть сделаны интерактивными (то есть меняющимися во времени в зависимости от ваших действий) без каких-либо дополнительных настроек.
- Прекрасные геопространственные карты: в Plotly есть свои базовые инструменты для построения карт, однако для совершенного результата всегда можно воспользоваться интеграцией с Mapbox.
Точечный график (диаграмма рассеяния)
С помощью библиотеки Plotly графики строятся следующим образом. Создаем переменную , а затем запускаем функцию .

Логарифм подушевого ВВП
Точечный график (диаграмма рассеяния) — путешествие во времени
fig = px.scatter(
data_frame=data,
x="Log GDP per capita",
y="Life Ladder",
animation_frame="Year",
animation_group="Country name",
size="Gapminder Population",
color="Continent",
hover_name="Country name",
facet_col="Continent",
size_max=45,
category_orders={'Year':list(range(2007,2019))}
)
fig.show()

Визуализация того, как данные меняются со временем.
Параллельные категории — прикольный способ визуализировать категоральные переменные
def q_bin_in_3(col):
return pd.qcut(
col,
q=3,
labels=
)
_ = data.copy()
_ = _.groupby('Year').transform(q_bin_in_3)
_ = _.groupby('Year').transform(q_bin_in_3)
_ = _.groupby('Year').transform(q_bin_in_3)
_ = _.groupby('Year').transform(q_bin_in_3)
_ = _.groupby().mean().reset_index()
fig = px.parallel_categories(_, color="Life Ladder", color_continuous_scale=px.colors.sequential.Inferno)
fig.show()
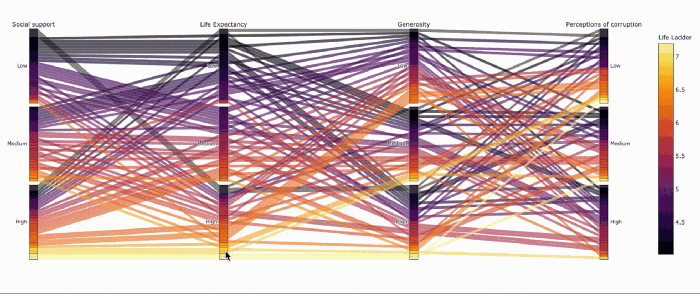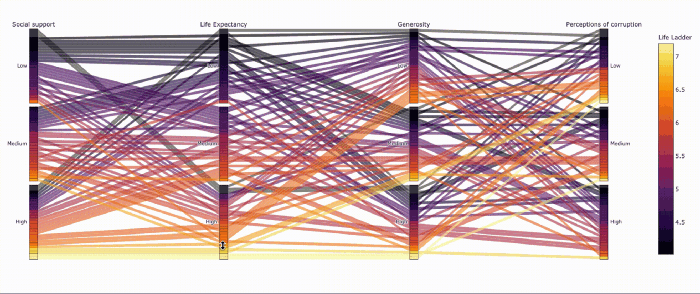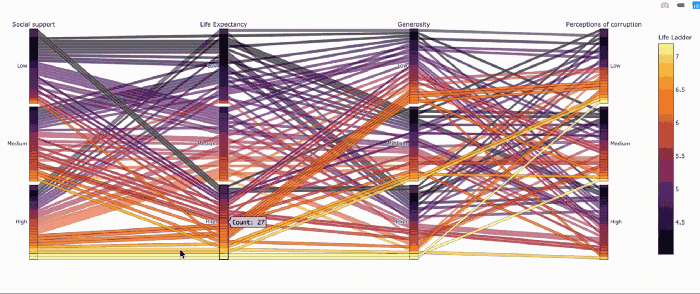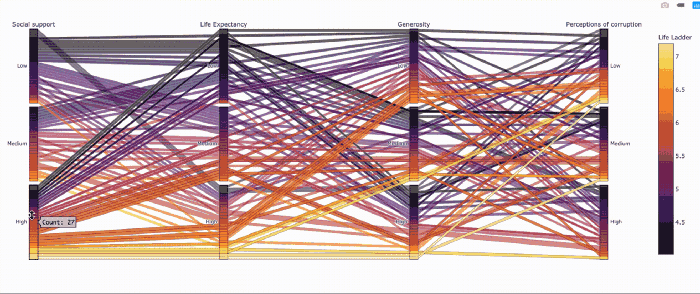
Похоже, не все страны с высокой продолжительностью жизни одинаково счастливы.
Столбчатые диаграммы — пример интерактивных фильтров
fig = px.bar(
data,
x="Continent",
y="Gapminder Population",
color="Mean Log GDP per capita",
barmode="stack",
facet_col="Year",
category_orders={"Year": range(2007,2019)},
hover_name='Country name',
hover_data=
)
fig.show()

Сюжетный график — как уровень счастья меняется со временем
fig = px.choropleth(
data,
locations="ISO3",
color="Life Ladder",
hover_name="Country name",
animation_frame="Year")
fig.show()

Карта, визиолизирующая, как уровень счастья менялся со временем. Сирия и Афганистан в самом низу «лестницы счастья», что совсем не удивительно.
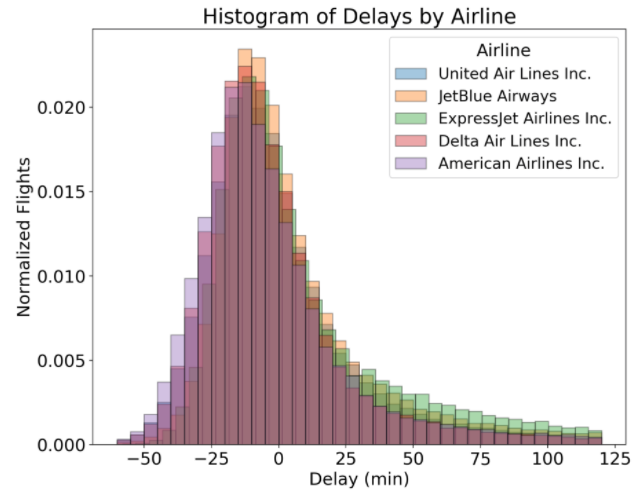
Решение № 1: параллельные гистограммы
Вместо того, чтобы перекрывать гистограммы авиакомпании, мы можем разместить их рядом. Для этого мы создаем список задержек прилета для каждой авиакомпании, а затем передаем это ввызов функции в виде списка списков. Мы должны указать разные цвета для каждой авиакомпании и ярлык, чтобы мы могли различать их. Код, включая создание списков для каждой авиакомпании, приведен ниже:
По умолчанию, если мы передадим список списков, matplotlib разместит столбцы рядом. Здесь я изменил ширину бина на 15 минут, потому что в противном случае сюжет слишком загроможден, но даже с этой модификацией это не эффективный показатель. Слишком много информации для обработки сразу, столбцы не совпадают с метками, и все еще сложно сравнивать распределение между авиакомпаниями. Когда мы строим сюжет, мы хотим, чтобы зрителю было как можно проще его понять, и эта цифра не соответствует этим критериям! Давайте посмотрим на второе потенциальное решение.