Удаленное логирование в journald или всё ещё «это вам не нужно»?
Содержание:
- Куда писать
- Нам обещали «конфигурируемый» способ логгирования
- Выбор точки остановки — set breakpoint
- Просмотр информации во время отладки приложения
- Клиент: пересылка логов с сохранением имени файла
- intel
- Logback
- Использование конфигурации логгера
- Стандартные логгеры
- Конфигурация rsyslog
- WP_DEBUG_LOG
- Шашки наголо!
- Всё вместе
- Берем полный контроль над форматированием сообщений
- Example #2 – Logging in a Module
- Что записывать в лог ?
Куда писать
Рассмотрим следующие варианты.
- Игнорировать 12-factor, docker-way и писать в файлы. Laravel (Monolog) позволяют даже настроить ротацию логов. Далее сообщения из файлов можно собрать с помощью Filebeat и отправить в Logstash для разбора.
- Отправлять логи из приложения напрямую дальше, например, по UDP для увеличения производительности.
- Комбинировать решения. Писать в файлы, которые с помощью Filebeat будут собраны и отправлены в Logstash. Писать в stderr контейнера, чтобы получить возможность использовать команды и быть готовым к удобному сбору логов из среды оркестрации контейнеров. При этом можно некоторые каналы писать только локально, некоторые отправлять по сети.
*
Варианты формата записи:
- Человекочитаемый (переносы строк, отступы и прочее)
- Машиночитаемый (обычно, json)
- Оба формата одновременно: машиночитаемый в stdout для дальнейшей маршрутизации, человекочитаемый на случай внезапных проблем с маршрутизацией и быстрого дебага
Любой из вариантов предполагает, что логи подвергаются маршрутизации — как минимум, отправке в единую систему обработки (хранения) логов по следующим причинам:
- Долгосрочное хранение и архивация
- Построение крупномасштабных графиков трендов
- Гибкая система оповещения о событиях
У докера есть возможность указать диспетчер логов. По умолчанию — , то есть, докер складывает вывод из контейнера в json-file на хосте. Если мы выбираем диспетчер логов, который будет отправлять записи куда-то по сети, то мы больше не сможем использовать команду . Если stdout/stderr контейнера был выбран единственным местом для записи логов приложения, то в случае сетевых проблем или проблем у единого хранилища, быстро извлечь записи для дебага может не получиться.
Какую комбинацию всех возможностей мест назначений и форматов записи выбрать вы можете решить для вашего проекта самостоятельно.
Нам обещали «конфигурируемый» способ логгирования
class-logger три уровня иерархии конфигурации:
- Глобальный
- Класс
- Метод
При вызове каждого метода, все три уровня мержатся вместе. Библиотека предоставляет разумный глобальный конфиг по умолчанию, так что ее можно использовать и без какой-либо предварительной настройки.
Что можно конфигурировать?
Мы рассмотрели как изменять конфиг, но все еще не разобрали, что именно в нем можно изменить.
Объект конфигурации имеет следующие свойства:
log
Это функция, которая занимается, собственно, логгированием. Ей на вход приходит отформатированное сообщения в виде строки. Используется для логгирования следующих событий:
- Перед созданием класса.
- Перед вызовом синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
- После вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
По умолчанию .
logError
Это функция, которая тоже занимается логгированием, но уже только сообщений об ошибке. Ей также на вход приходит отформатированное сообщения в виде строки. Используется для логгирования следующих событий:
По умолчанию .
formatter
Это объект с двумя методами: и . Эти методы создают то самое отформативанное сообщение.
создает сообщения для следующих событий:
- Перед созданием класса.
- Перед вызовом синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
создает сообщения для следующих событий:
- После вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
- Ошибки вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
По умолчанию .
args
Это может быть как булево значение, так и объект.
Если это , то он задает включать ли список аргументов (помните ?) во все сообщения ( и ).
Если это объект, то у него должно быть два булевых свойства: и . задает включать ли список аргументов для сообщений, — для сообщений.
По умолчанию .
Это , который контролирует логгировать ли создание класса или нет.
По умолчанию .
result
Это , который контролирует логгировать возвращаемое из метода значение. Стоит заметить, что возвращаемое значение — это не только то, что метод возвращает при успешном выполнении, но и ошибка, которую он бросает в случае неудачного выполнения. Помните ? Если этот флаг будет , то не будет никакого .
По умолчанию .
classInstance
Это может быть как булево значение, так и объект. Концепция та же, что и .
Добавляет сериализованное представление инстанса вашего класса в сообщения. Другими словами, если у вашего класса есть какие-то свойства, то они будут сериализованны в JSON и добавлены в логи.
Не все свойства подлежат сериализации. class-logger использует следующую логику:
- Берем все собственные (те, которые не в прототипе) свойства интсанса.
- Выкидываем из них все типа .
- Выкидываем из них все объекты, которые не являются простыми объектами.
- Что за простые объекты? считает объект простым, если его прототип — это .
- Почему? Часто в качестве свойств выступают инстансы других классов-сервисов. Наши логи распухли бы самым безобразным образом, если бы мы из стали сериализовать.
- Сериализовать в JSON строку все, что осталось.
По умолчанию .
Выбор точки остановки — set breakpoint
Практически все современные Android приложения используют Kotlin и RxJava. И при типичном использовании этой связки языка и библиотеки при добавлении точки остановки иногда появляется такой выбор:

Android Studio предлагает нам выбрать где именно мы хотим добавить точку остановки — момент выполнения метода subscribe в Rx-цепочке или выполнение кода внутри лямбды, которую мы передаем в subscribe. А можно поставить точку остановки сразу для двух действий (All).
Примечание для новичков: Если вы хотите отладить действие, которое вы планируете выполнить внутри метода subscribe, и не поняли в примере выше где именно вам поставить точку остановки — вам нужно поставить ее внутри лямбда выражения.
Просмотр информации во время отладки приложения

Остановка выполнения приложения при достижении breakpoint-a. Синим цветом Android Studio подсвечивает на какой именно точке выполнение программы было остановлено.
Клиент: пересылка логов с сохранением имени файла
Сохранять имена файлов мы будем в поле . В имена хочется включить каталоги, чтобы не наблюдать одноуровневую россыпь файлов: . Если лог читается не из файла, а из переданных в syslog сообщений от программы, то она может не согласиться записывать в TAG символ , потому что это не соответствует стандарту. Поэтому мы закодируем их двойными подчеркиваниями, а на лог-сервере распарсим обратно.
Создадим шаблон для передачи логов по сети. Мы хотим передавать сообщения с тегами длиннее 32 символов (у нас длинные названия логов), и передавать более точную, чем стандартную, метку времени с указанием временной зоны. Кроме того, к названию лог-файла будет добавлена локальная переменная , позже станет понятно, зачем. Локальные переменные в RainerScript начинаются с точки. Если переменная не определена, она раскроется в пустую строку.
Теперь создадим RuleSet, который будут использоваться для передачи логов по сети. Его можно будет присоединять к Input, читающим файлы, или вызывать как функцию. Да, rsyslog позволяет вызвать один RuleSet из другого. Для использования RELP надо сначала загрузить соответствующий модуль.
Теперь создадим Input, читающий лог-файл, и присоединим к нему этот RuleSet.
Стоит обратить внимание, что для каждого считываемого файла rsyslog создаёт state-файлы в своём рабочем каталоге (задаётся директивой ). Если rsyslog не может создавать там файлы, то весь лог-файл будет заново передаваться после перезапуска rsyslog
В случае, если какое-то приложение пишет в общий syslog с определённым тегом, и мы хотим как сохранять это в файл, так и пересылать по сети:
Чтение лог-файлов, заданных через wildcard
Интерлюдия
Программист: Не могу найти на лог-сервере логи somevendor.log за начало прошлого месяца, посмотри плиз.
Девопс: Эээ… а мы разве пишем такие логи? Предупреждать же надо. Ну в любом случае всё старше недели логротейт потёр, если мы его не сохраняли — значит уже нету.
Программист: бурно возмущается
Вайлдкарды поддерживаются только в режиме работы imfile (это режим по-умолчанию). Начиная с верcии 8.25.0, вайлдкарды поддерживаются как в имени файла, так и пути: /var/log/.log.
Многострочные сообщения
Для работы с лог-файлами, содержащими многострочные сообщения, модуль imfile предлагает три варианта:
- — сообщения разделены пустой строкой
- — новые сообщения начинаются с начала строки, продолжение сообщения идёт с отступом. Часто так выглядят стектрейсы
- — определять начало нового сообщения по regexp (POSIX Extended)
Первые два варианта имеют проблемы в режиме работы , и при необходимости третий легко их заменяет с соответствующим regexp. Считывание многострочных логов имеет одну тонкость. Обычно признак нового сообщения находится в его начале, и мы не можем быть уверены, что программа закончила писать прошлое сообщение, пока не началось следующее. Из-за этого последнее сообщение может никогда не передаваться. Чтобы этого избежать, мы задаём , по истечении которого сообщение считается законченным и будет передано.
intel
- Как уже сказал, у нее очень удобная конфигурация, настроить можно все в одном месте. У логгеров есть обработчики, у обработчиков есть форматтеры сообщений, фильтры по сообщениям и уровням. Почти сказка.
- Иерархии логгеров, кто пришел н-р с slf4j считает это само собой разумеющимся, однако же только в этой либе это было нормально реализовано. Что такое иерархия логгов:
у каждого логгера есть родитель (полное имя логгера задается перечеслением через точку всех родителей), задавая конфигурацию родителя можно выставить опцию, чтобы все дети автоматически получали ее же (log propagation). То есть я могу например создать несколько родительских логеров, задать им обработчики (н-р на уровни ERROR и WARN слать email) и все дети будут использовать их же, но более того если мне нужно заглушить какое то дерево логгов, я просто специализирую конфигурацию для его полного пути. И все это в одном месте и один раз. - Очень разумная подмена стандартной console. Разрешаются пути относительно текущей рабочей директории, что позволяет без проблем конфигурировать вывод console.log и получить плюшки логгера.
- Выкинул все такие оптимизации для бенчмарка — писать такое себя не уважать.
- Формат сообщений в intel: нужно у полей объекта-записи указывать их тип (н-р ‘ %(name)s:: %(message)s’), но ведь типы этих полей известны — так зачем нужно их указывать. Вместо этого я взял формат сообщений из logback.
- Для форматирования аргументов при логгировании используется свой собственный аналог util.format причем со своими ключами и он же используется при подмене консоли, то есть если сторонняя либа напишет, что то в консоль мы получим не то что ожидаем. Естественно это было заменено на util.format
- После некоторого профайлинга стало очевидно, что все время уходит на форматирование сообщений. Так как формат обычно задается один раз разумно его оптимизировать, что и было сделано, с помощью new Function формат собирается один раз, а не при каждом вызове.
код бенчмарка
форк
Logback
Для реализации выбрана добротная библиотека логгирования «logback», предоставляющая интересные возможности для кастомизации:
Настраивается как из XML-конфига, так и напрямую из Джавы, подходы можно комбинировать:
Вкратце о логгировании:
- Программист дергает логгер,
- Логгер дергает назначенные ему аппендеры,
- Аппендер думает и вызывает энкодер,
- Энкодер форматирует ровно одну строку лога,
- Для этого он дёргает цепочку конвертеров, каждый из которых раскрывает свою ,
- Успех.
Для простоты была выбрана чистая джавиная конфигурация. Тут всё довольно очевидно если держать перед глазами XML-конфиг. Основная задача — создать свои собственные appender/encoder и зарегистрировать их — они будут вызываться логбэком из своих недр. Почти каждый создаваемый объект нужно не забыть запустить методом . Абстрактный пример:
Использование конфигурации логгера
Далее, позвольте мне объяснить, что происходит, когда вы пытаетесь залогировать какое-нибудь сообщение. Как вы могли догадаться, логгер берет цепочку приемников для уровня логирования этого сообщения. Затем он начинает обрабатывать звенья этой цепи одно за другим. Для каждого звена логгер решает, нужно ли записывать сообщение в приемник, указанный в звене, и следует ли после этого продолжать обработку цепочки. Эти решения принимаются с помощью фильтров. Разрешите мне показать, как фильтры работают в NLog.
Вот как фильтры задаются в конфигурации:
Как вы могли догадаться, если фильтр возвращает или , сообщение не будет записано в приемник. Если результат работы фильтра — или , сообщение будет записано. Но в чем разница между и и между или ? Это просто. В случае и NLog прекращает обработку цепочки приемников и не пишет ничего в приемники, содержащиеся в последующих звеньях.
Стандартные логгеры
В среде веб-сервера у нас часто есть рутинная информация, которую мы должны регистрировать. Django предоставляет несколько стандартных логгеров (loggers) для ведения логов.
django
Это универсальный логгер принимающий все сообщения. Сообщения не записываются непосредственно в этот логгер поэтому нужно использовать один из следующих логгеров.
django.request
Этот логгер обрабатывает все сообщения вызванные HTTP-запросами и вызывает исключения для определенных кодов состояния. Все коды ошибок HTTP 5xx будут вызывать сообщения об ERROR. Аналогичным образом, коды HTTP 4xx будут отображаться в виде WARNING.
django.server
Когда сервер запускается с помощью команды runserver (что мы и делали), он будет регистрировать сообщения, связанные с обработкой этих запросов, точно так же, как логгер django.request, за исключением того, что все другие сообщения регистрируются на уровне INFO.
django.template
Независимо от того, как часто я работал с шаблонами Django, я никогда не собирал их без ошибок с первого раза. Логгер django.template обрабатывает ошибки, связанные с отображением шаблонов.
django.db.backends
Этот логгер обрабатывает любые сообщения связанные с взаимодействием кода с базой данных. Все операторы SQL уровня приложения будут отображаться на уровне DEBUG. Поскольку это может быть довольно шумно, необходимо включить ведение журнала отладки, изменив settings.DEBUG на True.
django.security.*
Django предоставляет обработчики ошибок, связанных с безопасностью. В частности, этот логгер будет получать любые сообщения, возникающие в результате ошибки SuspiciousOperation. Django определяет подклассы для каждого типа ошибок безопасности, таких как DisallowedHost или InvalidSessionKey. Остальные подклассы SuspiciousOperation можно найти .
Примечание. Если сообщение будет обрабатываться django.security то оно не будет отправлено через логгер django.request. Так что не игнорируйте сообщения от логгера django.security. *!
django.security.csrf
Этот логгер не наследуется от SuspiciousOperation. Он обрабатывает любые исключения, которые происходят из-за атак Cross-Site Request Forgery (CSRF).
И так в качестве следующего примера давайте запишем сообщения с помощью логгера django.request. Это делается путем добавления логгера в раздел регистрации конфигурации следующим образом:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'console': {
'format': '%(name)-12s %(levelname)-8s %(message)s'
},
'file': {
'format': '%(asctime)s %(name)-12s %(levelname)-8s %(message)s'
}
},
'handlers': {
'console': {
'class': 'logging.StreamHandler',
'formatter': 'console'
},
'file': {
'level': 'DEBUG',
'class': 'logging.FileHandler',
'formatter': 'file',
'filename': 'debug.log'
}
},
'loggers': {
'': {
'level': 'DEBUG',
'handlers': ,
'propagate': True
},
'django.request': {
'level': 'DEBUG',
'handlers':
}
}
})
Это будет регистрировать сообщения-запросы, подобные следующим:
Обратите внимание на использование параметра propagate. Этим параметром регулируется возможность передачи сообщения другим логгерам
Если оно установлено в False то дальше сообщение не пойдет.
Так же для каждого модуля в вашем приложение вы можете описать свой логгер (например для ведение отдельных файлов). Это делается следующим образом:
...
'loggers': {
...
'loggers.hello': {
'level': 'DEBUG',
'handlers': ,
'propagate': True
},
},
Конфигурация rsyslog
В отличии от второй распространённой альтернативы, syslog-ng, rsyslog совместим с конфигами исторического syslogd:
Т. к. возможности rsyslog гораздо больше, чем у его предшественника, формат конфигов был расширен дополнительными директивами, начинающимися со знака :
Начиная с шестой версии, появился си-подобный формат RainerScript, позволяющий задавать сложные правила обработки сообщений.
Т. к. всё это делалось постепенно и с учётом совместимости со старыми конфигами, то в итоге получилась пара неприятных моментов:
- некоторые плагины (я пока с такими не сталкивался) могут не поддерживать новый RainerScript стиль настроек, им по-прежнему нужны старые директивы
- настройка через старые директивы не всегда работает как ожидается для нового формата:
- если модуль вызывается с помощью старого формата:, то владелец и разрешения получившегося файла регулируются старыми директивами , , . А вот если он вызывается с помощью , то эти директивы игнорируются, и надо настраивать параметы action или задавать при загрузке модуля
- Директивы вида настраивают только ту очередь, которая будет использована в первом action после них, потом значения сбрасываются.
- точки с запятой где-то запрещены, а где-то наоборот обязательны (второе реже)
Чтобы не спотыкаться об эти тонкости (да, в документации они описаны, но кто же её целиком читает?), стоит следовать простым правилам:
- для маленьких простых конфигов использовать старый формат:
- для сложной обработки сообщений и для тонкой настройки Actions всегда использовать RainerScript, не трогая legacy директивы вида
WP_DEBUG_LOG
По умолчанию: false
Еще один компонент дебага. Включает запись ошибок в файл . Зависит от WP_DEBUG — работает только если WP_DEBUG равен true.
Запись ошибок в файл может пригодится, когда нужно проверить наличие ошибок в коде, который ничего не выводит на экран. Например, при AJAX запросе или при тестировании CRON или REST.
define( 'WP_DEBUG_LOG', true ); // true - запись ошибок в файл /wp-content/debug.log
Через WP
C WordPress 5.1, в WP_DEBUG_LOG можно указать путь к файлу лога:
define( 'WP_DEBUG_LOG', '/srv/path/to/custom/log/location/errors.log' );
Через PHP
Чтобы изменить название файла, добавьте следующую строку как можно раньше, например в MU плагины:
ini_set( 'error_log', WP_CONTENT_DIR . '/hidden-debug.log' );
Но эту строку нельзя добавлять в wp-config.php — это слишком рано…
Имейте ввиду:
- Конечная папка в указанном пути должна существовать и быть доступна для записи.
- Файла внутри может не быть, он будет создан, как только произойдет первая ошибка.
Шашки наголо!
Не бродя вокруг да около, перейдем сразу к коду.
Этот сервис создаст три записи в логе:
- Перед его созданием со списком аргументов, переданных в конструктор.
- Перед вызовом со списком аргументов.
- После вызова со списком аргументов и результатом выполнения.
In words of code:
Полный список событий, которые можно залоггировать:
- Перед созданием класса.
- Перед вызовом синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
- После вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
- Ошибки вызова синхронных и асинхронных методов и функциональных свойств, как статических, так и не статических.
Всё вместе
Всё описанное можно запускать в docker-контейнерах. Причём всё конфигурируется таким образом, что всем стеком можно пользоваться как локально при разработке, так и в staging- и production-окружениях, где переменными остаются только переменные окружения.
Все описанные сервисы, за исключением Elastalert, позволяют использовать переменные окружения в конфигурациях. Проблему Elastalert удалось разрешить, используя команду вида в entrypoint-скрипте и доустановкой зависимостей, чтобы это работало.
Конфигурации каких сервисов стека оставлять в репозитории проекта, а какие выносить в отдельный репозиторий мониторинга, зависит от наличия других проектов и того, как они будут переиспользовать стек.
Такой вариант стека имеет следующие преимущества:
- Снаружи доступен только 80 порт nginx, который проксирует запросы по basic auth к Kibana
- Порт Logstash тоже закрыт. Доступ к нему производится с помощью ssh-туннеля
- Одной командой поднимается весь стек кроме nginx
- Отдельными командами можно пересобирать, перезапускать docker-образы
- Отдельными командами можно произвести переразвертывание новой версии одного из образов
- Сервисы автоматически запускаются при перезагрузке сервера или внутреннем сбое
- Разворачивается одинаково в локальном и боевом окружении, отличаясь .env-файлом алертинга и файлом nginx-паролем
- Параметры *_JAVA_OPTS подобраны таким образом, чтобы весь стек стабильно работал на одном инстансе с 4GB RAM (зависит от потока событий и длительности хранения в ES).
Стоит заметить, что в данном подходе не используется ни один из xpack-плагинов.
Допустим вариант использования docker-compose. Главное, что основная конфигурация, состоящая из Dockerfile-ов, конфига Filebeat, конфигов Logstash, правил оповещения, правил автоудаления индексов, находится под системой контроля версий, получая возможность быстрого переразвертывания, хранения истории изменений и всех других преимуществ VCS.
Важно уделять внимание автоматической проверки работоспособности стека. Я предлагаю организовать проверку следующим образом. В самом приложении создается задача, исполняемая по расписанию (в Laravel для этого есть scheduler), скажем, раз в неделю за 5 минут до дейлимитинга
Сама задача вызывает логгер и записывает сообщение с уровнем ALERT. Если весь стек функционирует нормально, то вы получите оповещение. Если такого оповещения нет, а вы к нему привыкли, то это станет сигналом для разбирательств
В самом приложении создается задача, исполняемая по расписанию (в Laravel для этого есть scheduler), скажем, раз в неделю за 5 минут до дейлимитинга. Сама задача вызывает логгер и записывает сообщение с уровнем ALERT. Если весь стек функционирует нормально, то вы получите оповещение. Если такого оповещения нет, а вы к нему привыкли, то это станет сигналом для разбирательств.
Берем полный контроль над форматированием сообщений
Что же делать, если вам нравится идея, но ваши представление о прекрасном настаивает на другом формате строки сообщений? Вы можете взять полный контроль над форматированием сообщений, передав свой собственный форматтер.
Вы можете написать свой собственный форматтер с нуля. Безусловно. Но этот вариант не будет освещен в рамках этой (если вам интересна именно эта опцию, загляните в раздел в README).
Самый быстрый и простой способ переопределить форматирование — это унаследовать свой форматтер от форматтера по умолчанию — .
имеет следующие методы, которые создают небольшие блоки финальных сообщений:
-
- Возвращает сериализованный результат выполнения или сериализованную ошибку. Использует fast-safe-stringify для объектов под капотом. Сериализованная ошибка включает в себя следующие свойства:
- Имя класса (функции), которая была использована для создания ошибки ().
- Код ().
- Сообщение ().
- Имя ().
- Стек трейс ().
Сообщение состоит из:
Сообщение состоит:
Вы можете переопределить только необходимые вам базовые методы.
Давайте рассмотрим, как можно добавить timestamp ко всем сообщениям.
Example #2 – Logging in a Module
tag: v0.2 – https://gitlab.com/patkennedy79/python_logging/tree/v0.2
The second example is slightly more complex, as it updates the structure of the program to include a package with a single module:
python_logging python_logging __init__.py first_class.py run.py
The first_class.py file basically contains the FirstClass class that was created in the first example:
import logging
class FirstClass(object):
def __init__(self):
self.current_number = 0
self.logger = logging.getLogger(__name__)
# Create the Logger
self.logger = logging.getLogger(__name__)
self.logger.setLevel(logging.DEBUG)
# Create the Handler for logging data to a file
logger_handler = logging.FileHandler('python_logging.log')
logger_handler.setLevel(logging.DEBUG)
# Create a Formatter for formatting the log messages
logger_formatter = logging.Formatter('%(name)s - %(levelname)s - %(message)s')
# Add the Formatter to the Handler
logger_handler.setFormatter(logger_formatter)
# Add the Handler to the Logger
self.logger.addHandler(logger_handler)
self.logger.info('Completed configuring logger()!')
def increment_number(self):
self.current_number += 1
self.logger.warning('Incrementing number!')
self.logger.info('Still incrementing number!!')
def decrement_number(self):
self.current_number -= 1
def clear_number(self):
self.current_number = 0
self.logger.warning('Clearing number!')
self.logger.info('Still clearing number!!')
In order to utilize this module, update the run.py file in the top-level directory to import the FirstClass class to utilize it:
from python_logging.first_class import FirstClass number = FirstClass() number.increment_number() number.increment_number() print "Current number: %s" % str(number.current_number) number.clear_number() print "Current number: %s" % str(number.current_number)
Check that the log file is unchanged.
Что записывать в лог ?
Понимая суть процесса отладки, мы с легкостью ответим на этот вопрос:
Логи должны содержать информацию, необходимую для реконструкции переходов состояний.
Невозможно, да и не нужно, фиксировать все состояния во все отрезки времени. Например, полиции достаточно лишь нескольких точных набросков, а не видеоклона, для поимки преступника. Тоже самое относится и к логам: разработчикам нужно только внести в них информацию о том, когда происходит переход в критическое состояние. Кроме того, логи должны содержать ключевые характеристики текущего состояния и причину перехода.
Переход в критическое состояние
Не все переходы состояний стоит записывать в лог
Важно рассмотреть программу как серию изменяемых состояний, разделить их на фазы и затем сосредоточиться на времени, когда выполнение переходит от одной фазы к другой. . Предположим, что существуют 3 фазы запуска приложения:
Предположим, что существуют 3 фазы запуска приложения:
- загрузка настроек программы;
- подключение к зависимостям;
- запуск сервера.
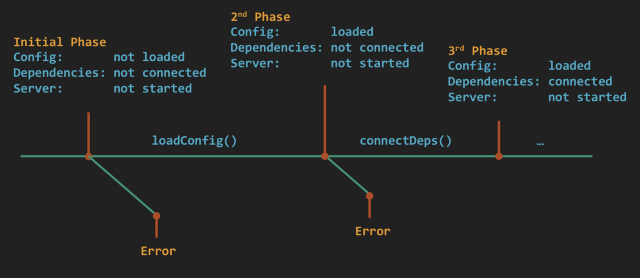
Запуск приложения с точки зрения переходов состояний
Было бы очень разумно вести логи в начале и конце каждой фазы. Если бы произошла ошибка на этапе подключения к зависимостям и приложение бы зависло, то логи отчетливо показали бы, что после загрузки настроек оно вошло во вторую фазу процесса, не завершив его. Располагая этой информацией, разработчики смогли бы быстро определить проблему.
Ключевые характеристики
Логирование состояний напоминает создание эскизов программы только с учетом ключевых характеристик основ бизнес-логики. Если есть информация закрытого характера, например персональные данные, то ее также нужно записать в лог, но в завуалированном виде.
Например, когда HTTP-сервер переходит из состояния ожидания запроса в состояние получения запроса, он должен зафиксировать в логе HTTP-метод и URL, так как они описывают основы HTTP-запроса. Остальные его элементы (заголовки или часть тела сообщения) записываются в том случае, если их значения влияют на бизнес-логику. Например, если поведение сервера сильно отличается между состояниями Content-Type:application/json и Content-Type:multipart/form-data, заголовок следует записать.
Причина перехода состояния
Логирование причины перехода состояния чрезвычайно полезно для отладки. Логи должны кратко охватывать содержание предыдущих и следующих состояний, а также объяснять их причины. Они помогают разработчикам получить общую картину и ориентироваться в процессе реконструкции (отладки) выполнения программы.
Пример
Рассмотрим простой пример для обобщения всего сказанного. Предположим, что сервер получает некорректный номер социального страхования, и разработчик намерен внести в лог информацию об этом событии.
Вот несколько анти-шаблонов логов, в которых отсутствуют ключевые характеристики состояния и причины:
- server.go: Error processing request (Запрос на обработку ошибок)
- server.go: SSN rejected (Номер социального страхования отклонен)
- server.go: SSN rejected for user UUID “123e4567-e89b-12d3-a456–426655440000” (Номер социального страхования отклонен для пользователя UUID “123e4567-e89b-12d3-a456–426655440000”)
Все они содержат определенную информацию, но ее недостаточно для ответов на вопросы, которые могут возникнуть у разработчиков в процессе поиска ошибки. Какой запрос не смог обработать сервер? Почему номер социального страхования был отклонен? Какой пользователь столкнулся с этой ситуацией? Грамотный и полезный для отладки лог будет выглядеть так:
server.go: Received a SSN request(track id: “e4a49a27–1063–4ab3–9075-cf5faec22a16”) from user uuid “123e4567-e89b-12d3-a456–426655440000”(previous state), rejecting it(next state) because the server is expecting SSN format AAA-GG-SSSS but got **-***(why)
( server.go: Получен запрос номера социального страхования (трек id: “e4a49a27–1063–4ab3–9075-cf5faec22a16”) от пользователя user uuid “123e4567-e89b-12d3-a456–426655440000” (предыдущее состояние), запрос отклонен (следующее состояние), так как сервер требует номер социального страхования в формате AAA-GG-SSSS, а получил **-*** (причина)