Иерархические базы данных
Содержание:
- Недостатки
- Операторы поиска данных с возможностью модификации
- Основные понятия
- 3.1.1.Структура данных.
- Особенности иерархической организации
- Основные понятия СУБД
- Виды моделей данных
- Примеры
- Управление сетевыми данными
- Операторы поиска данных с возможностью модификации
- Иерархия – это…
- Примеры типичных операторов поиска данных
- Структурная часть иерархической модели
- Язык описания данных иерархической модели
Недостатки
Однако те же особенности рассматриваемых СУБД, которые стали их основными достоинствами, определяют также и их недостатки. К примеру, громоздкость и сложность логических связей — опытному специалисту при работе с ранее неизвестной базой будет трудно разобраться, а простой пользователь и вовсе в ней «заблудится». Эта сложность понимания приводит к тому, что на самом деле не так много СУБД построены на иерархической модели. Примером иерархической базы данных является, кроме уже описанного продукта компании «АйБиЭм», «Ока» и МИРИС (производство России), а также Data Edge и Team-UP (от зарубежных корпораций).
Операторы поиска данных с возможностью модификации
- Найти и удержать единственный
экземпляр сегмента. Эта операция подобна первой операции поиска GET UNIQUE,
единственным отличием этой операции является то, что после выполнения этой
операции пал найденным экземпляром сегмента допустимы операции модификации
(изменения) данных.
Синтаксис:
GET HOLD UNIQUE
<имя сегмента> WHERE <список поиска>
- Найти и удержать следующий
с теми же условиями поиска. Аналогично операции 4 эта операция дублирует вторую
операции поиска GET NEXT с возможностью выполнения последующей модификации
данных.
Синтаксис:
GET HOLD NEXT
- Получить и удержать
следующий для того же родителя. Эта операция является аналогом операции поиска
3, но разрешает выполнение операций модификации данных после себя.
Синтаксис:
GET HOLD NEXT
WITHIN PARENT
Операторы
модификации данных
- Удалить : Это первая
из трех операций модификации.
Синтаксис:
DELETE
Эта команда
не имеет параметров. Почему? Потому что операции модификации действуют на экземпляр
сегмента, найденный командами поиска с удержанием. А он всегда единственный
текущий найденный и удерживаемый для модификации экземпляр конкретного сегмента.
Поэтому при выполнении команды удаления будет удален именно этот экземпляр сегмента.
- Обновить
Синтаксис:
UPDATE
Как же происходит
обновление, если мы и в этой команде не задаем никаких параметров. СУБД берет
данные из рабочей области пользователя, где в шаблонах записей соответствующих
внутренних переменных находятся значения полей каждого сегмента внешней модели,
с которой работает данный пользователь. Именно этими значениями и обновляется
текущий экземпляр сегмента. Значит, перед тем как выполнить операции модификации
UPDATE, необходимо присвоить соответствующим переменным новые значения.
Ввести новый
экземпляр сегмента.
INSERT <имя
сегмента>
Эта команда
позволяет ввести новый экземпляр сегмента, имя которого определено в параметре
команды. Если мы вводим данные в сегмент, который является подчиненным некоторому
родительскому экземпляру сегмента, то он будет внесен в БД и физически подключен
к тому экземпляру родительского сегмента, который в данный момент является текущим.
Как видим,
набор операций поиска и манипулирования данными в иерархической БД невелик,
но он вполне достаточен для получения доступа к любому экземпляру любого сегмента
БД. Однако следует отметить, что способ доступа, который применяется в данной
модели, связан с последовательным перемещением от одного экземпляра сегмента
к другому. Такой способ напоминает движение летательного аппарата или корабля
по заданным координатам и называется навигационным.
Основные понятия
К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь.
Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей.
К каждой записи базы данных существует только один (иерархический) путь от корневой записи.
Каждому узлу структуры соответствует один сегмент, представляющий собой поименованный линейный кортеж полей данных. Каждому сегменту (кроме S1-корневого) соответствует один входной и несколько выходных сегментов. Каждый сегмент структуры лежит на единственном иерархическом пути, начинающемся от корневого сегмента.
Следует отметить, что в настоящее время не разрабатываются СУБД, поддерживающие на концептуальном уровне только иерархические модели. Как правило, использующие иерархический подход системы, допускают связывание древовидных структур между собой и/или установление связей внутри них. Это приводит к сетевым даталогическим моделям СУБД.
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.
- Атрибут (элемент данных) — наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем.
- Запись — именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи — конкретная запись с конкретным значением элементов
- Групповое отношение — иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) — подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
3.1.1.Структура данных.
Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая БД состоит из упорядоченного набора деревьев. Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных.
Особенности иерархической организации
Определение 1
Иерархическая организационная структура – структура управления, подразумевающая вертикальную форму контроля, представляет собой пирамидальную форму подчинения, каждый уровень которой подчиняется более высокому уровню.
К иерархическим системам относятся не только организационные структуры, но и другие системы, в которых существует контроль более высоких уровней над более низкими. Наиболее известным примером иерархической структуры является государство.
Пример 1
Глава государства через множество подчиненных ему структур контролирует общественные организации более низкого уровня.
Иерархическая организационная структура не может считаться лучше или хуже других видов организационной системы. В основе оценки качества организационной структуры лежит ее соответствие целям и задачам компании, способность эффективно организовать рабочие и бизнес-процессы. Иерархическая организационная структура позволяет обеспечить параллельное выполнение независимых процессов на одном уровне под общим контролем менеджеров высшего уровня.
Иерархическая структура распространена не только в менеджменте организаций. Такого вида системы принято использовать в информационных технологиях – на них основываются системы связи, обработки данных, файловые системы и т.п.
Иерархические организационные структуры считаются традиционными. Их концепция была впервые сформулирована Максом Вебером. Согласно его мнению, иерархические организационные структуры делятся на линейные и функциональные. К иерархическим организационным структурам в настоящее время относят также дивизиональные структуры.
Основные понятия СУБД
Определение 1
База данных является совокупностью сведений (о реальных объектах, процессах и событиях), которые относятся к некоторой теме или задаче. База организована с целью обеспечения удобного представления этой совокупности сведений.
Определение 2
Реляционная база данных – это множество таблиц, взаимосвязанных между собой, причем в каждой из них содержится информация об объектах определенного типа. В каждой строке таблицы содержатся данные об одном объекте (например, человеке, средстве передвижения), а в столбцах таблицы содержатся разные характеристики этих объектов, которые называются атрибутами (например, имена и адреса людей).
Строку таблицы называют записью. Все записи одинаковы по структуре — они состоят из полей, хранящих атрибуты определенного объекта. В каждом поле записи содержится одна характеристика объекта, имеющая строго определенный тип данных (например, текстовая строка или число). Все записи состоят из одних и тех же полей, различаются только значения атрибутов, хранящихся в них.
При работе с данными используют специальные системы, которые называются системами управления базами данных (СУБД).
Определение 3
Система управления базами данных (СУБД) является совокупностью программных и лингвистических средств общего или специального назначения, которые обеспечивают управление созданием и использованием баз данных
К основным функциям СУБД относятся определение данных (описание структуры БД), их обработка и управление.
Замечание 1
Перед тем, как занести данные в таблицу, необходимо определить ее структуру. Под этим подразумевается не только описания наименований и типов полей, но и ряд других характеристик (например, форматы, критерии проверки вводимых данных). Помимо описаний структур таблиц еще задают и связи между таблицами. Связи в реляционных БД определяют по совпадениям значений полей в разных таблицах. К примеру, клиенты и заказы, как правило, связаны отношением один-ко-многим, поскольку 1 записи таблицы со сведениями о клиентах могут соответствовать несколько записей таблицы заказов клиентов.
Рассмотрим отношение между преподавателями и их курсами лекций, отношение типа многие-ко-многим, поскольку 1 преподаватель может вести несколько курсов, в тоже время 1 курс могут вести несколько преподавателей.
И последний тип межтабличных связей — отношение один-к-одному. Этот тип отношений встречается намного реже. Может встречаться лишь в 2 случаях:
- когда в записи присутствует большое количество полей, в этом случае данные об одном типе объектов делятся на 2 связанные таблицы;
- когда необходимо установить дополнительные атрибуты для определенного количества записей в таблице, в этом случае создают отдельную таблицу для этих дополнительных атрибутов, связанную отношением один-к-одному с основной таблицей.
Любой СУБД могут выполняться 4 наиболее простые операции с данными:
- добавление в таблицу одну или несколько записей;
- удаление из таблицы одной или нескольких записей;
- обновление значений некоторых полей в одной или нескольких записях;
- нахождение одной или нескольких записей, соответствующих определенному условию.
Для выполнения указанных операций используют механизм запросов. Результат выполнения запросов бывает представлен отобранным по определенным критериям множеством записей или изменениями в таблицах. Запрос к базе формируется на специально созданном для этих целей языке, называемом языком структурированных запросов (SQL — Structured Query Language).
Определение 4
И еще одна функция СУБД — это управление данными, под которым, как правило, понимается защита данных от несанкционированного доступа, поддержка многопользовательского режима работы с данными и обеспечение целостности и согласованности данных.
При действующей защите от несанкционированного доступа каждый пользователь может видеть и изменять лишь те данные, которые ему позволено видеть или менять. Средства, которые обеспечивают многопользовательскую работу, не разрешают нескольким пользователям в одно время проводить изменения над одними и теми же данными. Средства, обеспечивающие целостность и согласованность данных, не позволяют проводить изменения, которые могут привести к несогласованности данных. К примеру, когда 2 таблицы между собой связаны отношением один-ко-многим, невозможно внести запись в таблицу на стороне многих (подчиненная таблица), если при этом в таблице на стороне главной таблицы отсутствует соответствующая запись.
Виды моделей данных
Организация данных рассматривается с позиций той или иной модели данных. Модель данных является ядром любой базы данных. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных – совокупность структур данных, ограничений целостности и операций манипулирования данными. Модели используются для представления данных в информационных системах.
Различают три типа моделей данных, которые имеют множества допустимых информационных конструкций:
- иерархическая;
- сетевая;
- реляционная.
Иерархическая модель данных
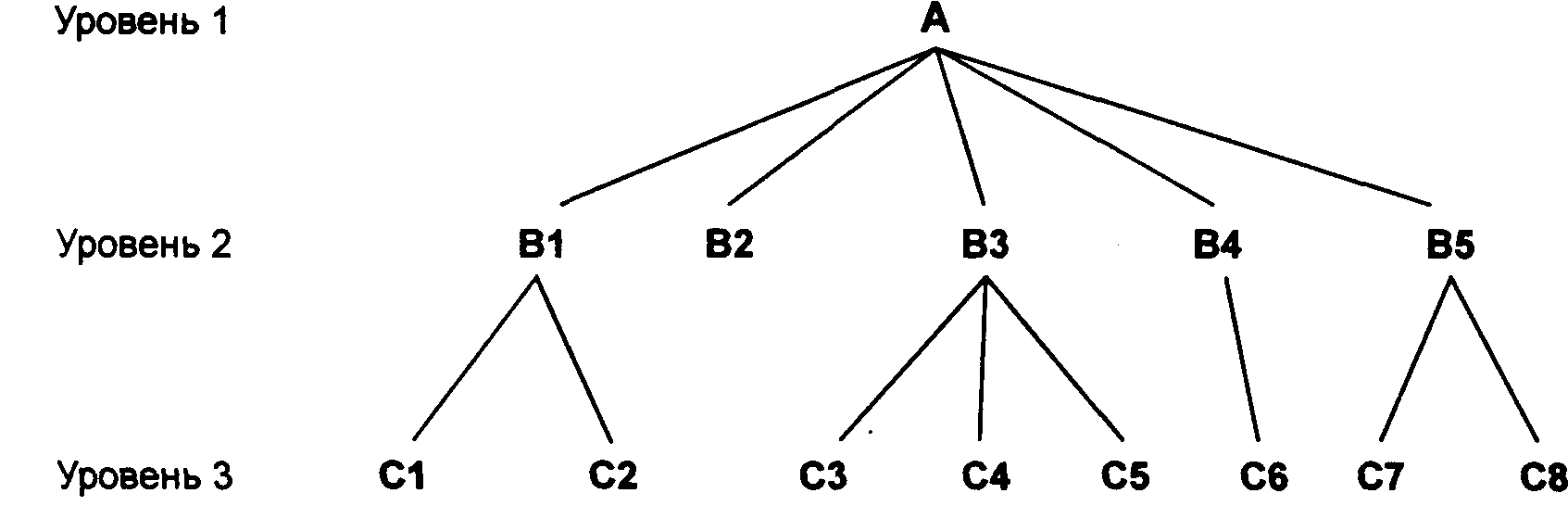
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен на рисунке:
Основные понятия иерархической структуры
Это – узел, уровень и связь.
Узел – это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне.
Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, как видно из рисунке, для записи С4 путь проходит через записи ВЗ к А.
Пример иерархической структуры:
Сетевая модель данных
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
На рисунке изображена сетевая структура базы данных в виде графа.
Пример сетевой структуры:
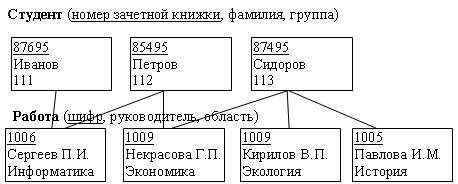
Примером сложной сетевой структуры может служить структура базы данных, содержащей сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС. Графическое изображение описанной в примере сетевой структуры состоит только из двух типов записей.
Реляционная модель данных
Понятие реляционный (англ. relation – отношение) связано с разработками известного американского специалиста в области систем баз данных Е.Кодда.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
- каждый элемент таблицы – один элемент данных;
- все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
- каждый столбец имеет уникальное имя (заголовки столбцов являются названиями полей в записях);
- одинаковые строки в таблице отсутствуют;
- порядок следования строк и столбцов может быть произвольным.
Отношение – это плоская таблица, содержащая N столбцов, среди которых нет одинаковых. N – это степень отношения, или арность отношения. Столбец отношения соответствует атрибуту сущности. Кортеж – строка отношения (соответствует записи в таблице).
Пример реляционной модели
| № личного дела | Фамилия | Имя | Отчество | Дата рождения | Группа |
| 16493 | Сергеев | Петр | Михайлович | 01.01.90 | 112 |
| 16593 | Петрова | Анна | Владимировна | 15.03.89 | 111 |
| 16693 | Антохин | Андрей | Борисович | 14.04.90 | 112 |
Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, а столбцы – атрибутам отношений, доменам, полям.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем).
Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ. В примере ключевым полем таблицы является «№ личного дела».
Примеры
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например, какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Управление сетевыми данными
Операции с сетевыми данными можно разделить на две группы: навигационные операции с данными и операции модификации данных.
Навигационные операции с данными
Навигационные операции сетевых баз данных осуществляют переход по связям, определенных в схеме баз данных, в результате таких переходов определяется запись, которую называют текущей.
- Найти конкретную запись в наборе однотипных записей и сделать ее текущей;
- Перейти от записи-владельца к записи-члену в некотором наборе;
- Перейти к следующей записи в некоторой связи;
- Перейти от записи-члена к владельцу по некоторой связи.
Операции модификации данных
Операций модификации сетевых баз данных осуществляют добавление новых записей данных, добавление новых наборов данных, удаление записей данных и наборов записей, модификация агрегатов и элементов данных.
- извлечь текущую запись в буфер прикладной программы для обработки;
- заменить в извлеченной записи значения указанных элементов данных на заданные новые их значения;
- запомнить запись из буфера в БД;
- создать новую запись;
- уничтожить запись;
- включить текущую запись в текущий экземпляр набора;
- исключить текущую запись из текущего экземпляра набора.
Операторы поиска данных с возможностью модификации
1. Найти и удержать единственный экземпляр сегмента. Эта операция подобна nepвой операции поиска GET UNIQUE, единственным отличием этой операции является то, что после выполнения этой операции над найденным экземпляром сегмента допустимы операции модификации (изменения) данных.
Синтаксис:
GET HOLD UNIQUE <имя сегнента> WHERE <список поиска>
2. Найти и удержать следующий с теми же условиями поиска. Аналогично операции 4 эта операция дублирует вторую операции поиска GET NEXT с возможностью выполнения последующей модификации данных.
Синтаксис:
GET HOLD NEXT
3. Получить и удержать следующий для того же родителя. Эта операция является аналогом операции поиска 3, но разрешает выполнение операций модификации данных после себя.
Синтаксис
GET HOLD NEXT WITHIN PARENT
Иерархия – это…
Помните, в далеком детстве вы собирали пирамидку и нужно было уложить кольца в строгой очередности: сначала самые большие, потом меньше, и так до конца в порядке уменьшения размера?
Эта последовательность, в которой каждый уровень находится в строгом соответствии с более высоким и более низким – называется иерархией.

«Иерархия» переводится с древнегреческого (hieros + arche) как «священное правление». Это выражение можно трактовать как «установленный порядок правления от более высших структур к более низшим».
Посмотрите, как выглядела схема правления в Древней Греции с 800 до 500 годов до нашей эры:
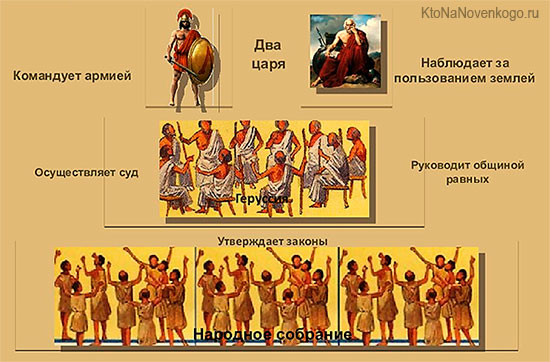 *при клике по картинке она откроется в полный размер в новом окне
*при клике по картинке она откроется в полный размер в новом окне
Это классический пример иерархической структуры управления государством. Но понятие иерархии относится не только к политической сфере, но и ко многим другим.
Вывод: иерархия – это порядок подчинения низших звеньев какой-либо структуры высшим.

Далее рассмотрим некоторые сферы, где применяются принципы иерархичности.
Примеры типичных операторов поиска данных
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Структурная часть иерархической модели
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных.
Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
Язык описания данных иерархической модели
В рамках
иерархической модели выделяют языковые средства описания данных (DDL, Data Definition
Language) и средства манипулирования данными (DML, Data Manipulation Language).
Каждая физическая
база описывается набором операторов, определяющих как ее логическую структуру,
так и структуру хранения БД. Описание начинается с оператора определения базы — DBD (Data Base
Definition):
DBD Name = <
имя БД>, ACCESS = < способ доступа>
Способ доступа
определяет способ организации взаимосвязи физических записей.
Определено 5 способов доступа:
HSAM
—
hierarchical sequential access method (иерархически
последовательный метод),
HISAM
—
hierarchical index sequential access method
(иерархически индексно-последовательный метод),
EDAM
—
hierarchical direct access method (иерархически прямой метод),
HID AM
—
hierarchical index direct access method (иерархически индексно-прямой метод),
INDEX
—
индексный метод.
Далее идет
описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = < имя оператора, определяющего хранимый набор данных>. DEVICE =< устройство хранения БД>,
Так как физические записи имеют разную длину, то при модификации данных запись может увеличиться
и превысит исходную длину записи до модификации. В этом случае при определенных
методах хранения может понадобиться дополнительное пространство хранения, где
и будут размещены дополнительные данные. Это пространство и называется областью
переполнения.
После описания
всей физической БД идет описание типов сегментов, ее составляющих, в соответстшш
с иерархией. Описание сегментов всегда начинается с описания корневого сегмента.
Общая схема описания типа сегмента такова:
SEGM NAME =
< имя сегмента>. BYTES =< размер в байтах>.
FREQ = <средняя
частота реализаций сегмента под одним исходным>
PARENT = <имя
родительского сегмента>
Параметр
FREQ определяет среднее количество экземпляров данного сегмента, связанных с
одним экземпляром родительского сегмента. Для корневого сегмента это число возможных
экземпляров корневого сегмента.
Для корневого
сегмента параметр PARENT равен 0 (нулю). Далее для каждого сегмента дается описание
полей:
FIELD NAME =
{(<имя поля> .{U M}) | <имя поля> }.
START = <
номер байта, с которого начинается значения поля >,
BYTES = <размер
поля в байтах>,
TYPE = {X |
Р | С}
Признак SEQ
— задается для ключевого поля, если экземпляры данного сегмента физически упорядочены
в соответствии со значениями данного поля.
Параметр
U задается, если значения ключевого поля уникальны для всех экземпляров данного
сегмента, М — в противном случае. Если поле является ключевым, то его описание
задается в круглых скобках, в противном случае имя поля задается без скобок.
Параметр TYPE определяет тип данных. Для ранних иерархических моделей были определены
только три типа данных: X — шестпадцатеричиый, Р —упакованный десятичный, С
— символьный.
Заканчивается
описание схемы вызовом процедуры генерации:
- DBDGEN — указывает
на конец последовательности управляющих операторов описания БД; - FINISH — устанавливает
ненулевой код завершения при обнаружении ошибки; - END — конец.
В системе
может быть несколько физических БД (ФБД), но каждая из них описывается отдельно
своим DBD и ей присваивается уникальное имя. Каждая ФБД содержит только один
корневой сегмент. Совокупность ФБД образует концептуальную модель данных.