Семантика в яндекс.директе: этапы, инструменты, чек-лист по оптимизации
Содержание:
- Онлайн парсеры
- Оффлайн парсеры
- Вордстат: как с ним работать и какие операторы использовать
- 6 операторов для уточнения запросов
- Уточняющий синтаксис в Яндекс Вордстат
- Как работать с Вордстатом
- Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
- Зачем использовать программу Key Collector
- Статистика поисковых запросов Яндекса
- Yandex Wordstat Assistant
- Key Collector и СловоЕБ
- Yandex Wordstat Helper: что это, где скачать и как пользоваться
- Что такое семантическое ядро и почему оно так важно?
Онлайн парсеры
Подобные сервисы появились относительно недавно. Их преимущество – не нужно скачивать и устанавливать локально программные комплексы. Это экономит время, но сказывается на точности выборки КС. Причина – онлайн-парсеры не работают напрямую с базами данных Wordstat, а периодически скачивают их. Недостаток – не все запросы попадают в информационное поле сервиса.
Букварикс онлайн версия
Первым онлайн-сервисом с расширенными возможностями для SEO-оптимизаторов стал «Букварикс». До недавнего времени его использование было полностью бесплатным. Но с вводом нового функционала появилась платная подписка. Ее преимущества – фильтрация по частотности, количеству символов и слов. Есть ограничения для незарегистрированных пользователей. Но эта процедура бесплатная, возможна авторизация через социальные сети.
Особенности работы с «Букварикс»:
- максимальное количество поисковых фраз – 300 для платной версии;
- возможность скачивания отчета в формате .csv;
- группировка словоформ;
- дополнительные инструменты – анализ доменов, нормализатор, дубликатор и комбинатор слов.
Сервис значительно уступает по возможностям аналогичным программам, но прост в использовании. Рекомендован для начинающих оптимизаторов.
Оффлайн парсеры
Возможность парсинга Яндекс Вордстат без доступа к интернету или при его низкой скорости – одно из требований к современным инструментам СЕО анализа. Технически это реализовано просто – на компьютер или аналогичное устройство, скачивается базы Wordstat и затем с помощью программы происходит выборка ключевых слов.
Букварикс десктопная версия
Впервые полноценный десктопный вариант представили разработчики «Букварикс». Однако уже в октябре 2017 года этот проект был «заморожен», ПО и базы данных не обновляются. Компания предлагает все инструменты в онлайн-режиме. Скачать приложение можно на старой версии официального сайта, использование бесплатное.
Что нужно учитывать при использовании десктопной версии:
- скачиваемый объем – около 30 Гбайт;
- скачать можно только с Яндекс.Диска, состоит из 20 частей;
- последняя дата обновления БД – 1 октября 2017 г.
Информация в этой версии устарела, возможно использование как вспомогательного инструмента.
Вордстат: как с ним работать и какие операторы использовать
Для того, чтобы работать с Вордстатом и использовать все его операторы, необходимо помнить несколько важных правил. Первое и самое главное то, что это очень просто, и каждый сможет справиться с поставленной задачей.
Остальные пункты звучат так:
- Яндекс Вордстат абсолютно бесплатный;
- Для пользования нужно зарегистрироваться в Яндексе;
- С помощью Вордстата удобно подбирать ключевые слова для контента;
- Выдача зависит от сезонности;
- В Вордстате не обязательно пользоваться только разделом «По словам».
Удобно то, что в Вордстате можно сделать сортировку по регионам. В отличие от разработки сайта-визитки под ключ, это делается довольно просто.
Для этого нужно будет нажать кнопку «Все регионы» и в появившемся окошке проставить необходимые галочки. Кстати, здесь же справа, Вы найдете очень удобную опцию «Быстрый выбор». С её помощью можно в один клик обозначить для подбора слов наиболее распространенные географические варианты: Москва и область; Санкт-Петербург и область; Украина; Россия, СНГ и Грузия.
Как и в поисковых системах, в Вордстате можно использовать синтаксические знаки для уточнения запроса. Ниже мы рассмотрим, как использовать операторы в Вордстате и какую функцию выполняет каждый из них. В приведённой таблице наглядно продемонстрированы распространённые символы и их значения, где ххх и ууу — это любые слова.
| СИМВОЛ | ЗНАЧЕНИЕ |
| -ххх | Неиспользование слова |
| +ххх | Обязательное использование слова |
| «ххх ууу» | Вхождение только этих слов, но их порядок и окончания могут быть различными |
| !ххх | Точное вхождение слова (фиксация окончания) |

Знак минус («-») перед словом помогает убрать из полученного списка все словосочетания, где оно находится. Например, вбив в Вордстат «популярные запросы –слова», мы уберём из выдачи словосочетания вроде «популярные слова запроса», «популярные слова в запросах» и другие.
Знак плюс («+») даёт обратный эффект и подразумевает наличие слова, перед которым он стоит в выдаче. Это относится к предлогам и союзам, так как в обычном режиме Вордстат полностью игнорирует многие служебные части речи.
Если точнее, то сервис НЕ замечает короткие союзы и предлоги («и», «к»…), хотя более длинные удостаивает вниманиям («перед», «также»…). Например, мы вводим в поиск фразу «популярные запросы в яндексе», то в списке среди прочих запросов находим и «популярные поисковые запросы яндекс», и «топ популярных запросов яндекс», и другие словосочетания без предлога «в». А если мы вобьем «популярные запросы +в яндексе», то получим лишь то, что искали.
Знак кавычки («») позволяет уточнить выдачу, ведь в ней Вы увидите «закавыченные». Однако, их порядок и окончания могут отличаться.
Восклицательный знак («!») поможет получить точное «вхождение» в слова с нужным нам числом и падежом.
Яндекс Вордстат считается одним из полезнейших сервисов, который, несомненно, подкупает своей простотой. Благодаря этому, будь Вы новичком или же продвинутым пользователем, методы СЕО-продвижения сайта с использованием Вордстата станут понятны каждому.
6 операторов для уточнения запросов
Операторы WordStat — это символы, которые помогут вам точнее сформулировать ключевую фразу для получения статистики. Их на данный момент существует 6.
| Оператор | Что делает | Пример ключевой фразы | Отображение статистики |
! |
Жестко фиксирует слово (время, род, число, падеж) | купить замок в !москве |
купить замок москва |
" " |
Кавычки фиксируют количество слов в запросе | «купить замок» |
купить замок в москве |
+ |
Плюс фиксирует все частицы, предлоги и служебные слова в запросе. По-умолчанию они игнорируются | купить замок +на дверь |
купить замок для двери |
- |
Минус удаляет все лишние слова из запроса | купить замок -автомобиля |
купить замок для автомобиля |
| Квадратные скобки фиксируют порядок слов в запросе | купить |
купить дверной замок |
|
() и | |
Пайп (вертикальная черта) и круглые скобки помогают при группировке сложных запросов | купить замок (недорого|дверной) |
купить дверной замок недорого |
Вся прелесть операторов заключается в том, что их можно использовать друг с другом. Совместное использование операторов для детализации запросов дает хорошему вебмастеру мощный seo-инструмент, который поможет не только собрать качественное семантическое ядро, но и вычленить из всей массы запросов именно нужную объективную статистику без семантического мусора.
Уточняющий синтаксис в Яндекс Вордстат
Давайте снова взглянем на скришот, показывающий статистику по запросу «ключевое слово». На нем мы видим, что данная фраза упоминалась пользователями в поисковике более 62 тысяч раз в течение месяца.
И, кажется, что попадание в ТОП-1 поиска по ней принесет сайту минимум 15-20 тысяч ежемесячного трафика. Забегая вперед, скажу, что в реальной жизни сайт, занимающий первую позицию в поиске по данному запросу, получает по нему не более 200 посетителей – разница в 100 раз это не шутка.
Представьте, что вы вложили в продвижение своего проекта 100 тысяч, рассчитывая, что заработаете 200, а покупателей оказалось в 100 раз меньше и вы заработали 2 тысячи – это провал всего бизнес плана.
Может показаться, что статистика запросов от Яндекс врет и надо искать другой инструмент. Но не спешите, надо просто научиться правильно пользоваться вордстатом.
Есть такая штука – синтаксис поисковых запросов – это когда добавление специальных символов позволяет задавать поисковой системе более точные критерии поиска. Синтаксис запросов работает как в обычном поиске, так и в Yandex Wordstat – давайте учиться его использовать.
1. Исключаем всё лишнее (кавычки)
Первая причина завышенных результатов в статистике запросов – это учет не только той фразы, которую вы ввели в строке сервиса, но и всех фраз в которые она входит.
Обратите внимание, что в примере выше мы видим цифры не только запроса «ключевое слово», но и «ключевые слова яндекс», «статистика ключевых слов» и т.д. Весть этот список суммируется
Но, если мы возьмем наш запрос в кавычки, то все приставки и хвостики в учет не пойдут. Получится вот так:
Теперь мы видим, что цифра в 62 тысячи запросов уменьшилась до 1906 – это существенно ближе к истине, но еще не идеал.
2. Избавляемся от словоформ (восклицательный знак)
Запросы «ключевое слово», «ключевые слова», «ключевом слове» и т.д. мы считаем разными, но поисковая система, по-умолчанию, считает их одним и тем же, что опять размывает статистические данные.
Для того, чтобы исключить из месячных показов ненужные словоформы достаточно поставить перед каждым словом из запроса восклицательный знак, как в примере ниже:
Теперь мы видим всего 411 запросов, но это те самые случаи, когда пользователь ввел только выбранные слова в нужных падежах и склонениях.
3. Соблюдение порядка слов (квадратные скобки)
Еще одна не очевидная фишка поисковика – это безразличие к порядку слов во фразе. Для Яндекс Вордстат запрос «ключевое слово» и «слово ключевое» – одно и то же. В данной фразе этот момент не критичен, но есть запросы, где от порядка слов многое зависит.
За сохранение порядка слов отвечает оператор квадратные скобки ([]).
Такой формат можно считать эталонным.
4. Учет предлогов в статистике (плюс слова)
Следующая особенность поисковых систем – они не учитывают в статистике предлоги. Считается, что эти слова не несут смысловой нагрузки и ими можно пренебречь.
Для учета предлогов придется использовать дополнительный оператор – это знак плюс.
Используя «+» вы можете включать в учет нужные предлоги и отбрасывать фразы их не содержащие. Пишется вот так:
5. Исключение из учета отдельных слов (минус слова)
Нередко возникает необходимость получить общую статистику по фразе, не уточняя её кавычками, но без учета определенных добавок. Например, продавая какую-то услугу, нам необходимо вычислить спрос на нее. Естественно, существуют люди, желающие получить ее бесплатно – их в расчет брать не желательно.
Исключить слово «бесплатно» мы можем оператором «минус». Впрочем, минус удаляет из статистики любое слов стоящее за ним, не только «бесплатно».
Вот как используется данный синтаксис:
Одновременно можно использовать любое количество минус слов, разделяя их пробелами и ставя перед каждым знак “-“.
6. Объединение статистики по схожим запросам
Существует в Вордстате возможность не только уточнять запросы, но и наоборот – объединять данные по схожим фразам.
Как это работает: Допустим, у вас есть 4 ключа, по которым планируется продвижение страницы – это «яндекс вордстат», «yandex wordstat», «яндекс wordstat» и «yandex вордстат».
Мы можем взять общую статистику по всем 4 запросам. Для этого используем круглые скобки и вертикальную черту (прямой слэш). Внутри скобок слэшем разделяем варианты.
Пример: (слово1|слово2) одинаковая часть
Блоков с круглыми скобками может быть несколько, а общая часть может вовсе отсутствовать, как в на скриншоте ниже:
Как работать с Вордстатом
Сервис подбора слов помогает просматривать обобщенную статистику по запросам, а также оценивать частотность в зависимости от различных факторов. В Wordstat также есть набор операторов, с помощью которых можно узнать реальное число запросов для определенной формы слова или фразы.
Фильтры
Чтобы посмотреть статистику в срезе по устройствам, используйте фильтр. Он доступен в каждом разделе. Wordstat разделяет мобильные устройства на телефоны и планшеты.

Для просмотра данных по разным регионам, нажмите «Все регионы». Откроется окно, где можно уточнить регион показов.

Переключитесь на вкладку «По регионам», чтобы узнать число показов страниц по запросам из конкретного города, страны или региона, а также по все регионам вместе. Здесь можно посмотреть статистику на карте, если удобно. Также можно применить фильтры по устройствам, чтобы сузить поиск.

Здесь доступны два столбца с цифрами:
- «показов в месяц» — количество показов из региона за месяц;
- «региональная популярность» — доля, которую занимает регион в показах по данному слову, деленная на долю всех показов результатов поиска в этом регионе.
100% — это среднее значение. Если оно меньше 100%, то интерес пользователей к этому слову понижен, и наоборот.
Яндекс уточняет, что региональная популярность — это affinity index в отчетах Яндекс.Метрики.
Следующий раздел в интерфейсе — «История запросов». В первую очередь он помогает подобрать слова для бизнесов, где ярко выражена сезонность и не получается собрать семантику на основе статистики за месяц. В «Истории запросов» показывается динамика показов за два года.
Статистику можно смотреть в абсолютных или относительных значениях. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.

Операторы
Операторы в Wordstat помогают уточнить запросы и получить более детальную статистику по ним. Их можно применить только во вкладках «По словам» и «По регионам». Рассмотрим основные операторы, которые пригодятся специалисту на начальном этапе работе.
-
Кавычки фиксируют количество слов в запросе. Это помогает посмотреть, сколько раз пользователи вводили эту фразу. Система учитывает разный порядок слов и разные окончания. Повторяющиеся слова считаются за одно слово.
- Восклицательный знак нужен, чтобы посмотреть статистику по конкретной форме слова. Он ставится перед словом, которое не должно видоизменяться.
- С помощью оператора «Плюс» можно включать в запрос предлоги или другие служебные слова.
- «Минус» исключает слова из запроса.
- Если заключить ключевую фразу в квадратные скобки, система выдаст число запросов для фразы с сохранением порядка слов. При этом учитываются разные словоформы и предлоги.
Посмотрим на примеры использования. Если нужно узнать точное количество запросов исключительно по заданной фразе без дополнительных слов и без учета словоформ, нужно использовать два оператора: кавычки и восклицательный знак.

Чтобы исключить запросы, не совпадающие с тематикой продвижения, используйте оператор минус вместе с восклицательным знаком. Как в известном примере, вы не будете показывать рекламу бильярдного кия пользователям, которые интересуются покупкой машины Kia и ошиблись в правописании.

Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
Создайте аккаунт в системе PromoPult (или авторизуйтесь, если у вас уже есть аккаунт). Откройте инструмент «Слова и объявления конкурентов». В блоке «Добавить задачу» укажите домены конкурентов или загрузите их с помощью XLSX-файла.

Блок профессиональных настроек пока не трогаем (мы еще разберем его).

В блоке «Поисковые системы» можно выбрать, в какой поисковой системе проверять домены. По умолчанию это Яндекс и Google. Также по умолчанию стоит галочка на пункте «Результаты на едином листе XLS» – в таблице с результатами данные по всем доменам будут сведены на одном листе.
Если вы проверяете небольшое количество доменов (до 5), можете ничего не менять здесь. Если же доменов больше, уберите галочку с этого пункта. В результатах парсинга под каждый домен будет создан отдельный лист – это удобнее для анализа большого количества данных.
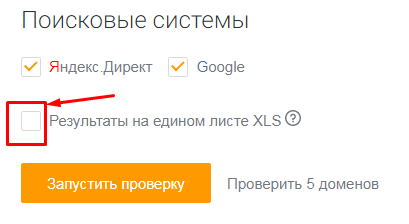
Жмем «Запустить проверку». Система начнет парсинг доменов (в нашем случае на это ушло 5 минут). Если у вас нет времени ждать, вы можете закрыть страницу с инструментом – все работы проводятся в фоновом режиме.
После окончания проверки вам на почту придет уведомление:

Раскройте блок «Список задач» и кликните по пиктограмме Excel-таблицы, чтобы скачать отчет. Также здесь можно удалить отчет или запустить повторный парсинг.

В настройках парсинга есть возможность выбрать отображение отчета: отдельный лист для каждого домена или все на одном листе.
В зависимости от этой настройки отчет будет выглядеть по-разному.
Отчет по каждому домену на разных листах
В нашем примере мы получили именно такой отчет. При скачивании загружается архив с файлами в формате CSV:
Что содержит архив:
Файл с уникальными ключевиками для всех конкурентов. Для пяти доменов, которые мы добавляли в проверку, парсер собрал почти 32 000 ключей.
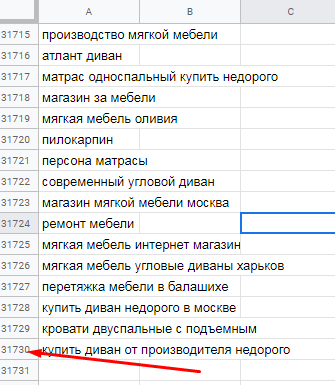
Общие результаты – данные по количеству объявлений на поиске Google и Яндекс. Для каждого домена данные указаны в разрезе регионов.
Технический файл, в котором указаны настройки парсинга.

Файлы с названиями доменов. Содержат ключевые слова конкурентов, заголовки и тексты объявлений. Данные указаны в разрезе поисковых систем и регионов. Например, вы можете посмотреть, какие объявления показывает конкурент в Яндексе в Санкт-Петербурге.
Обратите внимание! При парсинге объявления собираются из результатов поисковой выдачи в таком виде, в котором они отображаются. Кроме основного текста и заголовка могут собираться уточнения, быстрые ссылки и другие расширения (если они есть в объявлении)
Данные по доменам на одном листе
При таком способе отображения отчета загружается один XLSX-файл с четырьмя листами. Даже если вы парсите 50 доменов, листов в файле все равно будет четыре. Какие это листы:
«Результаты общие» – количество уникальных объявлений по всем доменам. Данные указаны в разрезе регионов и поисковых систем.
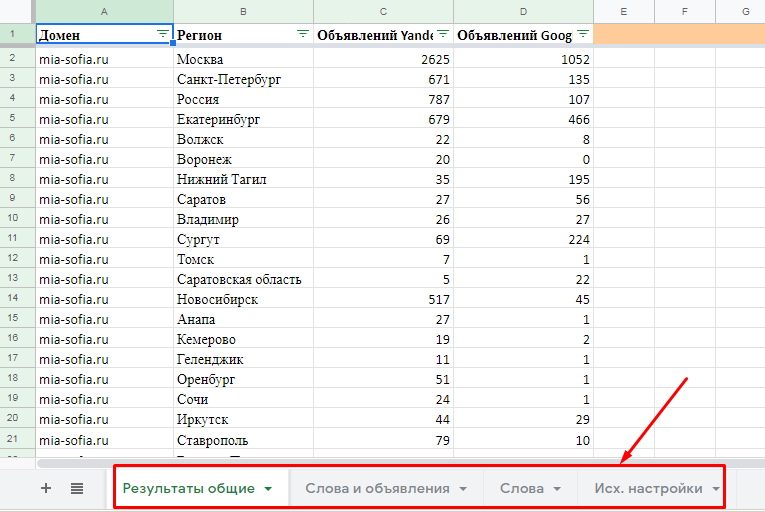
- «Слова и объявления». На этом листе собрана семантика по всем конкурентам и тексты объявлений. Данные указаны по каждому региону и поисковой системе. Если доменов много, работать с такой таблицей будет неудобно.
- «Слова». Собраны уникальные ключевики по всем доменам.
- «Исх. настройки». Указаны настройки парсинга.
Зачем использовать программу Key Collector
Если вы хотите написать одну статью, то подобрать для нее ключи можно с помощью описанных выше онлайн сервисов.
Но если вы наполняете содержимым целый сайт или хотите оказывать услуги по составлению семантического ядра, то без Key Collector вам не обойтись, так как этот софт может собирать статистику, рассчитывать конкуренцию, работать с поисковыми подсказками, другими сервисами и т.д.

Согласитесь, что намного проще открыть одну программу и работать только там, чем ходить по десяткам сайтов и где-то хранить полученные запросы.
А так я в Кей Коллекторе провожу парсинг и там же создаю группы, куда заношу полученные ключи для будущих статей.
Как найти ключи, определить частотность и уровень конкуренции
Работу в программе условно можно разделить на 2 способа:
- Парсинг ключей с помощью платных сервисов
- Парсинг ключей бесплатным Вордстатом
Первый способ. Так как программа универсальная, то в нее можно интегрировать такие сервисы для сбора ключей и статистики: SEMrush, SpyWords, Mutagen, Serpstat, MOAB.

Только предварительно не забудьте пройти регистрацию в том сервисе через который и будет происходить сбор данных. После чего в «Настройках» далее «Парсинг» далее «Платные API» указываем логи, пароль или токен.

После чего запускаем парсинг и указываем запрос, по которому надо собирать ядро.

В качестве примера был взят сервис Мутаген.

Как видим Мутаген все равно для парсинга будет использовать статистику от Яндекс Вордстат, поэтому не вижу смысла платить за это дополнительные деньги.
Ах да, так как сервисы платные, за каждую строчку будьте готовы потратить определенную сумму:
Цены на анализ запросов в Мутагене:
- Проверка конкуренции: 100 проверок — 30 руб.
- Парсер вордстат: 1 запрос — 0.02 руб.
Теперь представьте, если таких запросов будет 10 000, а если 100 000?
Второй способ.
Куда проще пользоваться бесплатным способом, это собирать ключевые слова и проверять конкуренцию через Yandex Wordstat.

Указали ключ и начинаем сбор. Все остальное сделает программа.
Единственное, что может принести неудобство, это когда при частом обращении к Яндексу, последний захочет убедиться, что вы не робот и покажет вам капчу.
Поэтому чтобы не отвлекаться на ее ввод, тем более если вы будите работаться с большим количеством слов, то лучше подключить к программе систему автоматического распознавания капчи.
Лично я для этого использую сервис ruCaptcha, где нам надо в настройках аккаунта получить API Key.

Кстати, если вы не хотите платить, то можете сначала заработать на разгадывании капчи. Лично я так и сделал, о чем рассказал в видео ниже.
Далее переходим в настройки Кей Коллектор и в меню «Антикапча» отмечаем пункт «Использовать ruCaptcha» и в поле настроек вводим полученный в личном кабинете API.

Теперь если в процессе парсинга будет встречаться капча, Key Collector не будет останавливаться, а сервис Рукапча все сделает за вас.

Как видно в ходе парсинга была разгадана 1 капча, а напротив отображается баланс, чтобы его было легче контролировать.
Если по ценам, то тут все очень даже лояльно:
Как видите, за очень малые деньги можно собирать СЯ с помощью стандартных функций программы, без подключения дорогих сервисов.
Статистика поисковых запросов Яндекса
На сегодняшний день поисковая система Яндекс занимает лидирующие позиции в российском сегменте интернета. Для вебмастеров и оптимизаторов данная поисковая система создала специальный сервис – Яндекс Wordstat. Научившись правильно пользоваться данным сервисом, вы с легкостью сможете составить семантическое ядро вашего сайта, а также подобрать ключевые слова индивидуально для каждой новой статьи, публикуемой на вашем интернет-проекте.
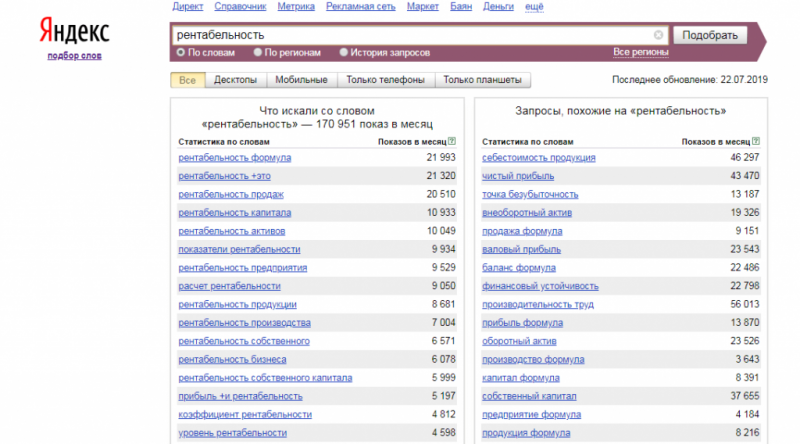
К примеру, возьмем следующий запрос – «продвижение сайт».
Система выдала нам две колонки. Первая (левая) – это словарные наборы, в состав которых входит часть исходного ключевого слова, ну а вторая (правая) – это ассоциативные запросы. Во вторую колонку входят те слова, которые чаще всего вводили пользователи Яндекса до или после исходного запроса во время одной сессии. Используя эту информацию, можно значительно расширить свое семантическое ядро.
Для чего же нужен Яндекс Wordstat?
- Подбор ключевых слов для создания семантического ядра и продвижения сайта в целом.
- Анализ и аудит конкурентоспособности той или иной тематики потенциального интернет-проекта.
- Подбор и анализ релевантных ключевых слов.
Читатели часто путают два совершенно разных термина: ключевые слова и запросы. Проясним, в чем же различия.
- Запрос – это слово или словосочетание, которое пользователь поисковой системы вписывает в строку поиска. Различаются по типам и видам.
- Ключевое слово – это определенное слово или словосочетание, которое используется владельцами интернет-ресурсов или оптимизаторами для продвижения той или иной страницы и/или сайта. Ключевые слова имеют строгие правила вхождения, а если их не придерживаться, то поисковые системы могут применить к вам санкции (понижение позиций в поисковой выдаче или вовсе его вылет).
Чтобы узнать самые частые поисковые запросы по заданной тематике нужно выполнить следующий алгоритм:
- В специально отведенном поле ввести тематическое словосочетание и кликнуть кнопку «Подобрать».
Обратите внимание, что все полученные данные предоставляются вам за последний месяц (30 дней) и являются сезонными. Во время подбора наиболее популярных запросов вы также можете пользоваться специальными «операторами», которые поддерживаются Яндексом
Во время подбора наиболее популярных запросов вы также можете пользоваться специальными «операторами», которые поддерживаются Яндексом.
- Оператор кавычки («») – отвечает за частотность по определенному запросу.
- Оператор восклицательный знак (!) – предотвращает использование словоформ и выдает четкое ключевое слово.
- Оператор минус-слово (-) – позволяет убрать определенное слово из запроса. К примеру, указав запрос «книга по психологии -скачать» вы можете убрать слово «скачать».
- Оператор плюс-слово (+) – обратное действие предыдущего оператора, т.е. вы добавляете слово.
Чтобы работать с Вордстатом было удобнее, настоятельно рекомендуем установить плагин Yandex Wordstat Assistant.
Еще один способ значительно упростить работу со статистикой Яндекса – это использование бесплатной программы Словоёб и платной программы Key Colleсtor.
Yandex Wordstat Assistant
Расширение устанавливается в 3 простых шага:
1) Скачайте актуальную версию расширения для браузера, в котором работаете с Яндекс Wordstat: Google Chrome, Mozilla Firefox, Opera или Яндекс Браузер.
Для всех браузеров алгоритм одинаковый. Мы покажем, как устанавливать и пользоваться возможностями Wordstat Assistant, на примере Google Chrome.
2) Нажмите кнопку для установки:
3) Подтвердите, что собираетесь установить расширение:
На этом всё готово, остается проверить, установилось ли расширение.
Если всё корректно, вы увидите:
Значок с таким уведомлением – теперь он всегда будет отображаться в вашем браузере.
Если такого значка нет, попробуйте перезапустить браузер.
Панель управления Wordstat Assistant в левой области страницы Яндекс Wordstat – в неё будут попадать все ключевые фразы, которые вы добавите.
На случай, если панель не появится, обновите страницу или также перезапустите браузер.
Знак «+» напротив каждого результата и в левой, и в правой колонке – нужен, чтобы добавлять фразы в список.
Чтобы его увидеть, введите нужную фразу, как обычно в Вордстате, например:
Рассмотрим все функции по порядку.
1) Добавление и удаление фраз из списка
Можно добавить в список отдельную ключевую фразу, нажав на плюс, или все фразы из таблицы (именно с той страницы, на которой вы находитесь, а не из всей выдачи), нажав ссылку «Добавить все»:
Например, мы хотим добавить все похожие фразы из левой колонки с первой страницы. Жмем «Добавить все», в окне подтверждения – «Добавить»:
Выглядит это так, в скобках указана частотность для каждого запроса:
Над списком отображается общее количество фраз, которые вы добавили, и суммарная частотность по ним:
В результатах поиска Yandex Wordstat фразы, которые вы выбрали, становятся серого цвета, со знаком минус вместо плюса.
Эти опции при необходимости можно отключить здесь:
По знаку «–» фразу можно в любой момент удалить из результатов поиска Яндекс Wordstat (1). Либо можно удалить прямо её из панели управления: для этого наведите на фразу курсор и кликните по минусу рядом с ней (2). Чтобы очистить весь список, нажмите крестик вверху панели управления (3).
При попытке добавить такой же ключ, какой уже есть в списке, Wordstat Assistant выдает сообщение:
2) Добавление собственных ключей
Для этого нажмите плюс на панели управления, введите запрос или список запросов, как на скриншоте:
Для добавленных вручную фраз вместо частотности показывается знак вопроса:
Если ваша фраза совпадает с фразой из результатов поиска Wordstat, последняя выделяется серым цветом. Но частотность при этом остается неизвестной (?), а не перетягивается из данных Wordstat.
3) Сортировка списка ключевых фраз
Её можно выполнять с помощью этой кнопки:
Она меняет свой вид в зависимости от того, по какому признаку вы сортируете фразы:
По возрастанию и убыванию частотности:
По алфавиту:
По порядку добавления (вновь добавленные в конец / в начало списка):
4) Копирование данных из Вордстата
Можно скопировать просто список фраз (1), либо список фраз вместе с фразами значения частотности (2), чтобы работать с ними дальше в любом формате – например, txt или Excel:
Чтобы автоматически удалить знак «+» из всех фраз, задайте эту настройку:
Если вы закроете вкладку с Wordstat или браузер, ничего не потеряется. Список сохранится под тем аккаунтом, в котором вы его сформировали.
Key Collector и СловоЕБ
Это комплексная десктопная программа, в которой есть буквально всё для работы с контекстной рекламой, в том числе сбор семантического ядра.
Чтобы сделать парсинг в Key Collector, добавляем фразы:

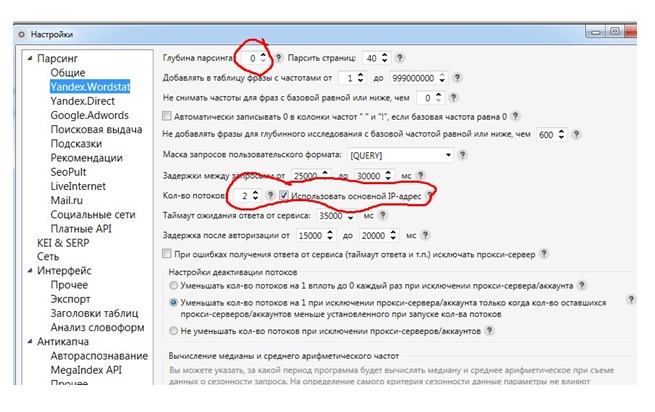
Запускаем парсинг. Рекомендация: выбирайте глубину 2. Так вы сразу получаете не только результаты парсинга, но и дополнительную выдачу по каждому из них.
Подробнее настройки описаны здесь.
Также Key Collector позволяет очистить семантическое ядро от «мусора», а именно:
- Ключевиков, которые содержат ненужные слова;
- Повторов слов;
- Стоп-слов (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.);
- Запросов с нулевой частотностью.
Есть бесплатный аналог Key Collector – СловоЕБ. Основное его ограничение – в источниках. Он работает только с левой и правой колонкой в Wordstat, Rambler.Adstat и поисковыми подсказками Яндекс и Google.
Для сравнения: Key Collector поддерживает всё вышеперечисленное, плюс Google Ads, подсказки Mail, Wordstat полностью и системы аналитики, установленные на сайте (Google Analytics, Яндекс.Метрика, LiveInternet).
Другие ограничения программы СловоЕБ:
- Проверяет частоту запросов только по Wordstat, а КК также по Yandex.Direct, Google.Ads, LiveInternet, Rambler.Adstat, APIShop.com;
- Оценивает конкурентность запросов для Яндекс и Google, в то время как в КК 4 формулы оценки KEI, которые можно менять вручную.
Однако этого функционала будет вполне достаточно, если у вас небольшой проект.
Yandex Wordstat Helper: что это, где скачать и как пользоваться
Для успешного продвижения сайта важно грамотно собирать и группировать запросы, называемые «семантическим ядром». Для этого seo-специалисты пользуются специальными сервисами статистики поисковых систем
У Яндекса таким сервисом является Wordstat.
Однако вручную вычленять оттуда информацию и не совсем удобно, поскольку надо копировать каждый ключевик в таблицу Excel или Google Docs, многократно переключаться между окнами. На все это уходит немало времени. Облегчить процесс подбора запросов позволяют специальные плагины. Один из наиболее популярных – Yandex Wordstat Helper, разработанный специалистами компании «Арктическая лаборатория».
Что такое семантическое ядро и почему оно так важно?
Перечень ключевых слов и фраз, которые характеризуют направление и тематику сайта, называют семантическим ядром. Оно позволяет понять, пользуется ли спросом информация, товар, услуга, и выстроить грамотную структуру ресурса.
Термин «семантическое ядро» встречается часто. Что это такое? Поговорим о механизме работы поисковой системы. Мы вводим запрос (ключевое слово) и получаем перечень страниц, максимально релевантных нашему запросу и оптимизированных под него. Семантическим ядром считается список всех ключей, используемых для продвижения сайта.
Вам обязательно нужно знать и понимать, какие сведения и по каким запросам человек может найти на веб-ресурсе. Если вы не знаете этого, востребованным сайт никогда не станет. То есть SEO-продвижение невозможно без формирования семантического ядра.
Веб-сайт должен привлекать всю целевую аудиторию (ЦА). Для этого требуется:
- сбор полного семантического ядра. Помните, что на один запрос не делают одну страницу;
- кластеризация запросов. После сбора всех ключевых слов их нужно объединить в группы. В них может быть как 5, так и 25 ключей. Каждая группа предназначена для решения одной задачи;
- определение посадочной страницы. Одна страница — на одну группу. На сайте не должно быть двух страниц, решающих одну задачу.
Если вы заинтересованы в нормальном SEO-продвижении своего ресурса, соберите все возможные ключи. Возьмем сайт строительной компании. При выборе запросов мы понимаем, что жилье можно разбить по типам: дом, таунхаус, квартира и т. д. Соответственно подбираются следующие ключевые запросы: купить дом, купить квартиру, купить таунхаус, купить дом с ремонтом и пр.
Итак, мы разбили запросы на все способы и типы. Сейчас наша задача — разместить информацию. Необязательно помещать всё в меню веб-сайта. Лучше распределите данные по страницам разделов и подразделов, создайте блок фильтров. Так вы раскидаете все запросы по сайту и получите дополнительный трафик.
Поэтапное формирование семантического ядра выглядит так:
- Сбор ключевых запросов из многочисленных источников.
- Очистка ядра от неподходящих запросов.
- Объединение и группировка запросов.
- Формирование структуры сайта под данное ядро.
Залог качественного SEO-продвижения сайта заключается в грамотном формировании семантического ядра. Оно несет смысловую нагрузку вашего ресурса. Если человек по запросу не может получить полные (релевантные) сведения о вашем сайте, придется с ним (с сайтом) поработать.
Формирование качественного семантического ядра — долгий процесс. Кто-то предпочитает сбор семантики вручную, но большинство веб-студий делают это автоматизировано, используя специальные сервисы. Как подобрать запросы, что брать за основу? Поговорим об основных источниках ключевых слов.
В первую очередь нужно проанализировать информацию, товары или услуги, которые уже размещены или скоро появятся на сайте. Это — самое главное при работе с семантическим ядром. Ваша задача — максимально глубоко проанализировать проект и понять специфику ниши. У многих веб-специалистов нет возможности полностью изучить чужой бизнес, а потому в этом вопросе непременно нужно взаимодействовать с клиентом. Так, например, вы можете согласовать весь перечень поисковых фраз.
Яндекс-статистика запросов в поисковиках — прекрасное решение для оптимизаторов, позволяющее узнать, что пользователи ищут в Интернете. Всё, что вам нужно сделать — зайти на сервис wordstat.yandex.ru. Подобный инструмент есть и у Google: частота запросов www.google.ru/adwords/. Сервисы предназначены для использования контекстной рекламы, однако и для SEO-оптимизации тоже подходят.
Статистика сайта — отличный источник ключевых слов. Её также необходимо тщательно анализировать, особенно если у сайта уже есть хороший трафик. Накопленные данные позволяют оценить запросы и трафик поведения пользователей на странице (число просмотров, проведенное время, количество отказов).
Чтобы легко и быстро создать качественную структуру сайта, нужно проанализировать веб-ресурсы конкурентов. Необходимо лишь найти нескольких лидеров в вашем сегменте, у которых SEO-структура сформирована грамотно.
Далее есть несколько вариантов:
- анализ видимости конкурентов в поисковиках и получение списка их ключевых слов. Формирование семантического ядра на основе данных запросов или дополнение своего отсутствующими;
- сбор лучших решений из структуры нескольких сайтов конкурентов и создание своей идеальной.