Python sets
Содержание:
- Как лучше выбирать элементы из списка?
- Поверхностное и глубокое копирование
- Вычитания множеств
- Множество
- Что такое генератор в Python?
- Python NumPy
- Особенности set
- OrderedDict objects¶
- UserString objects¶
- Создание множеств
- Использование setattr() с getattrr()
- Свойства методов и операторов
- Приоритет
- Обход множеств в цикле
- 5.4. Sets¶
- Назначение в Python
- defaultdict objects¶
- Значения нотации «О» большое
- Array.isArray
- 5.8. Comparing Sequences and Other Types¶
- Вывод
Как лучше выбирать элементы из списка?
Если вы хотите продуктивно работать со списками, то должны уметь получать доступ к данным, хранящимся в них.
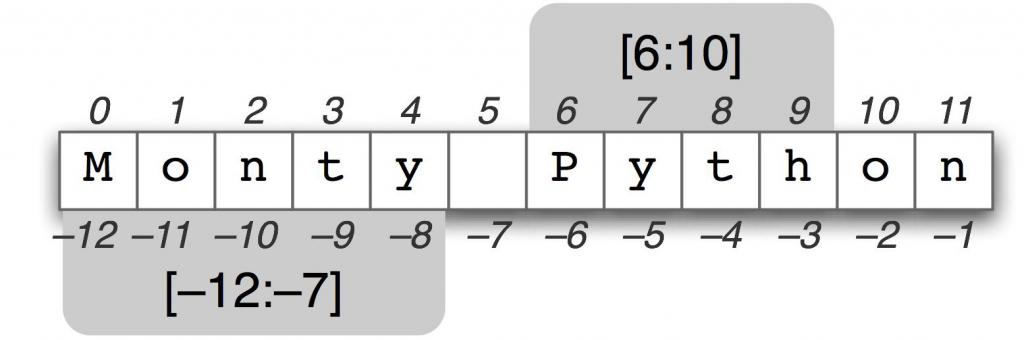
Обычно мы получаем доступ к элементам списков, чтобы изменять определенные значения, обновлять или удалять их, или выполнять какие-либо другие операции с ними. Мы получаем доступ к элементам списков и, собственно, ко всем другим типам последовательностей, при помощи оператора индекса . Внутри него мы помещаем целое число.
# Выбираем первый элемент списка oneZooAnimal = biggerZoo # Выводим на экран переменную `oneZooAnimal` print(oneZooAnimal)
Запустите данный код и убедитесь, что вы получите первый элемент списка, сохраненного в переменную . Это может быть поначалу несколько непривычно, но нумерация начинается с числа , а не .
Как получить последний элемент списка?
Ответ на этот вопрос является дополнением к объяснению в предыдущем разделе.
Попробуйте ввести отрицательное значение, например, или , в оператор индекса, чтобы получить последние элементы нашего списка !
# Вставляем -1 monkeys = biggerZoo print(monkeys) # А теперь -2 zebra = biggerZoo print(zebra)
Не правда ли, не слишком сложно?
Что означает ошибка «Index Out Of Range»?
Эта ошибка одна из тех, которые вы будете видеть достаточно часто, особенно если вы новичок в программировании.
Лучший способ понять эту ошибку — попробовать ее получить самостоятельно.
Возьмите ваш список и передайте в оператор индекса либо очень маленькое отрицательное число, либо очень большое положительное число.
Как видите, вы можете получить ошибку «Индекс вне диапазона» в случаях, когда вы передаете в оператор индекса целочисленное значение, не попадающее в диапазон значений индекса списка. Это означает, что вы присваиваете значение или ссылаетесь на (пока) несуществующий индекс.
Срезы в списках
Если вы новичок в программировании и в Python, этот вопрос может показаться одним из наиболее запутанных.
Обычно нотация срезов используется, когда мы хотим выбрать более одного элемента списка одновременно. Как и при выборе одного элемента из списка, мы используем двойные скобки. Отличие же состоит в том, что теперь мы еще используем внутри скобок двоеточие. Это выглядит следующим образом:
# Используем нотацию срезов someZooAnimals = biggerZoo # Выводим на экран то, что мы выбрали print(someZooAnimals) # Теперь поменяем местами 2 и двоеточие otherZooAnimals = biggerZoo # Выводим на экран полученный результат print(otherZooAnimals)
Вы можете видеть, что в первом случае мы выводим на экран список начиная с его элемента , который имеет индекс . Иными словами, мы начинаем с индекса и идем до конца списка, так как другой индекс не указан.
Что же происходит во втором случае, когда мы поменяли местами индекс и двоеточие? Вы можете видеть, что мы получаем список из двух элементов, и . В данном случае мы стартуем с индекса и доходим до индекса (не включая его). Как вы можете видеть, результат не будет включать элемент .
В общем, подводя итоги:
# элементы берутся от start до end (но элемент под номером end не входит в диапазон!) a # элементы берутся начиная со start и до конца a # элементы берутся с начала до end (но элемент под номером end не входит в диапазон!) a
Совет: передавая в оператор индекса только двоеточие, мы создаем копию списка.
В дополнение к простой нотации срезов, мы еще можем задать значение шага, с которым будут выбираться значения. В обобщенном виде нотация будет иметь следующий вид:
# Начиная со start, не доходя до end, с шагом step a
Так что же по сути дает значение шага?
Ну, это позволяет вам буквально шагать по списку и выбирать только те элементы, которые включает в себя значение вашего шага. Вот пример:
Обратите внимание, что если вы не указали какое-либо значение шага, оно будет просто установлено в значение . При проходе по списку ни один элемент пропущен не будет
Также всегда помните, что ваш результат не включает индекс конечного значения, который вы указали в записи среза!
Как случайным образом выбрать элемент из списка?
Для этого мы используем пакет .
# Импортируем функцию `choice` из библиотеки `random` from random import choice # Создадим список из первых четырех букв алфавита list = # Выведем на экран случайный элемент списка print(choice(list))
Если мы хотим выбрать случайный элемент из списка по индексу, то можем использовать метод из той же библиотеки .
# Импортируем функцию `randrange` из библиотеки `random` from random import randrange # Создадим список из первых четырех букв алфавита randomLetters = # Выбираем случайный индекс нашего списка randomIndex = randrange(0,len(randomLetters)) # Выводим случайный элемент на экран print(randomLetters)
Совет: обратите внимание на библиотеку , она может вам пригодиться во многих случаях при программировании на Python
Поверхностное и глубокое копирование
Если несколько переменных ссылается на одно и то же множество, например вот так:
То изменение данных посредством одной из них, повлияет на все остальные переменные:
Что бы избежать подобного поведения необходимо создать поверхностную копию множества, передав его функции или вызвав метод :
Поскольку, множества могут хранить только хешируемые объекты (т.е. те которые точно не могут быть изменены), то проблем с глубоким копированием возникнуть не должно. Однако, чисто теоретически, кто-то может создать объекты, метод которых переопределен по другому (если честно, даже не могу представить кому и зачем это может понадобиться). То в этом случае, в множестве могут оказаться нехешируемые (!) и даже одинаковые элементы. В этом случае, придется прибегать к глубокому копированию множеств с помощью функции из модуля стандартной библиотеки.
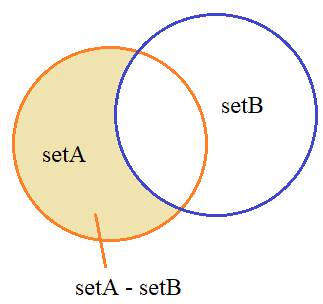
Вычитания множеств
Следующая
операция – это вычитание множеств. Например, для множеств:
setA = {1,2,3,4}
setB = {3,4,5,6,7}
операция
setA - setB
возвратит новое
множество, в котором из множества setA будут удалены
все значения, существующие в множестве setB:
{1, 2}
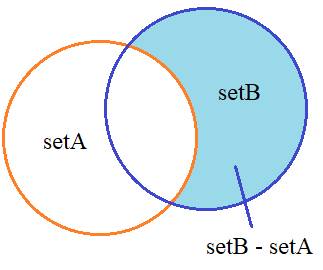
Или, наоборот,
из множества setB вычесть
множество setA:
setB – setA
получим значения
{5, 6, 7}
из которых
исключены величины, входящие в множество setA.
Также можно
выполнять эквивалентные операции:
setA -= setB # setA = setA - setB setB -= setA # setB = setB - setA
В этом случае
переменные setA и setB будут ссылаться
на соответствующие результаты вычитаний.
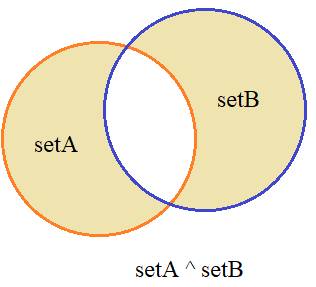
Следующая
операция симметричная разность на выходе дает такое множество:
setA = {1,2,3,4}; setB = {3,4,5,6,7}
setA ^ setB
то есть,
множество, составленное из значений, не входящих одновременно в оба множества. В
данном случае получим результат:
{1, 2, 5, 6, 7}
Множество
Множество – это математический объект, являющийся набором, совокупностью, собранием каких-либо объектов, которые называются элементами этого множества. Или другими словами:
Что значит неупорядоченная? Это значит, что два множества эквивалентны, если содержат одинаковые элементы.
Элементы множества должны быть уникальными, множество не может содержать одинаковых элементов. Добавление элементов, которые уже есть в множестве, не изменяет это множество.
Множества, состоящие из конечного числа элементов, называются конечными, а остальные множества – бесконечными. Конечное множество, как следует из названия, можно задать перечислением его элементов. Так как темой этой статьи является практическое использование множеств в Python, то я предлагаю сосредоточиться на конечных множествах.
Что такое генератор в Python?
Генератор это подвид итерируемых
объектов, как список или кортеж. Он
генерирует для нас последовательность
значений, которую мы можем перебрать.
Эту последовательность
можно использовать для итерации в цикле
for, но нельзя проиндексировать (т. е.,
перебрать ее можно только один раз).
Давайте посмотрим, как создается
такая последовательность значений при
помощи генератора.
а. Синтаксис генератора в
Python 3
Для создания генератора в Python внутри
функции вместо ключевого слова return
используется ключевое слово yield
Обратите
внимание на пример:
def counter():
i=1
while(i<=10):
yield i
i+=1
В этом примере мы определили генератор
с именем counter() и назначили значение 1
локальной переменной i. Цикл while будет
выполняться, пока i меньше или равно 10.
Внутри цикла мы возвращаем (yield) значение
i и увеличиваем его на единицу.
Затем мы используем этот генератор в
цикле for.
for i in counter():
print(i)
Вывод:
1 2 3 4 5 6 7 8 9 10
b. Как работает генератор в
Python
Чтобы разобраться в том, как работает
этот код, давайте начнем с цикла for. Этот
цикл выводит каждый элемент генератора
(т. е., каждый элемент, возвращаемый
генератором).
Мы начинаем с i=1. Таким образом, первый
элемент, возвращаемый генератором, это
1. Цикл for выводит этот элемент на экран
благодаря ключевому слову print. Затем i
инкрементируется до 2. Весь процесс
повторяется, пока i не инкрементируется
до 11 (т. е., пока условие в цикле while не
даст false).
Но если вы забудете добавить инкремент
i, вы получите бесконечный генератор.
Дело в том, что генератору в каждый
момент времени нужно удерживать в памяти
только одно значение. Таким образом,
нет никаких ограничений памяти.
def even(x):
while x%2==0:
yield 'Even'
for i in even(2):
print(i)
Вывод:
Even Even Even Even Even Even Even Even Even Even Even Even Even
EvenTraceback (самый недавний вызов идет последним):
File “”, line 2, in print(i) KeyboardInterrupt
Поскольку 2 это четное число, 2%2 это
всегда 0. Поэтому условие в цикле while
всегда будет соблюдаться (всегда true). В
результате генератор even() продолжает
возвращать значение Even, пока мы не
прервем выполнение цикла вручную
(сочетанием клавиш Ctrl+C).
Обратите внимание, что генератор может
содержать больше одного ключевого слова
yield. Примерно так же, как функция может
иметь больше одного ключевого слова
return
def my_gen(x): while( x> 0): if x%2==0: yield 'Even' else: yield 'Odd' x-=1 for i in my_gen(7): print(i)
Вывод:
Odd Even Odd Even Odd Even Odd
2. Возврат значений в список
Здесь все просто. Если вы примените
функцию list() к вызову генератора, она
вернет список возвращенных генератором
значений, в том порядке, в котором они
возвращались. В следующем примере
генератор возвращает квадраты чисел,
если эти квадраты четные.
def even_squares(x):
for i in range(x):
if i**2%2==0:
yield i**2
Чтобы создать список из возвращаемых
генератором значений, мы просто применяем
функцию list() к вызову генератора. Мы не
перебираем эти значения при помощи
цикла for.
print(list(even_squares(10)))
Вывод:
Как видите, для чисел в диапазоне 0-9
(не 10, потому что диапазон (10) это числа
0-9), четные квадраты это 0, 4, 16, 36 и 64.
Остальные — 1, 9, 25, 49, 81 — нечетные. Поэтому
они не возвращаются генератором.
Python NumPy
NumPy IntroNumPy Getting StartedNumPy Creating ArraysNumPy Array IndexingNumPy Array SlicingNumPy Data TypesNumPy Copy vs ViewNumPy Array ShapeNumPy Array ReshapeNumPy Array IteratingNumPy Array JoinNumPy Array SplitNumPy Array SearchNumPy Array SortNumPy Array FilterNumPy Random
Random Intro
Data Distribution
Random Permutation
Seaborn Module
Normal Distribution
Binomial Distribution
Poisson Distribution
Uniform Distribution
Logistic Distribution
Multinomial Distribution
Exponential Distribution
Chi Square Distribution
Rayleigh Distribution
Pareto Distribution
Zipf Distribution
NumPy ufunc
ufunc Intro
ufunc Create Function
ufunc Simple Arithmetic
ufunc Rounding Decimals
ufunc Logs
ufunc Summations
ufunc Products
ufunc Differences
ufunc Finding LCM
ufunc Finding GCD
ufunc Trigonometric
ufunc Hyperbolic
ufunc Set Operations
Особенности set
Одно из основных свойств множеств заключается в уникальности каждого из их элементов. Посмотрим, что получится, если сформировать set из строчки с заведомо повторяющимися символами:
Из результата были удалены дублирующиеся в слове ‘TikTok’ символы. Так множества в очередной раз доказали, что содержат в себе только уникальные элементы.
Немаловажным является и тот факт, что при литеральном объявлении, итерируемые объекты сохраняют свою структуру.
Для сравнения:
Отдельное python множество может включать в себя объекты разных типов:
Здесь нет никакого противоречия с математической дефиницией, так как все составляющие имеют вполне конкретное общее свойство, являясь объектами языка Питон.
Но не стоит забывать и внутреннее определение set-ов
Важно помнить, что list-ы и dict-ы не подходят на роль элементов множества, из-за своей изменяемой природы
Функция , тем не менее, корректно обрабатывает случаи, когда ей на вход подаются списки или словари.
Однако в списках не должно быть вложенных изменяемых элементов.
OrderedDict objects¶
Ordered dictionaries are just like regular dictionaries but have some extra
capabilities relating to ordering operations. They have become less
important now that the built-in class gained the ability
to remember insertion order (this new behavior became guaranteed in
Python 3.7).
Some differences from still remain:
-
The regular was designed to be very good at mapping
operations. Tracking insertion order was secondary. -
The was designed to be good at reordering operations.
Space efficiency, iteration speed, and the performance of update
operations were secondary. -
Algorithmically, can handle frequent reordering
operations better than . This makes it suitable for tracking
recent accesses (for example in an LRU cache). -
The equality operation for checks for matching order.
-
The method of has a different
signature. It accepts an optional argument to specify which item is popped. -
has a method to
efficiently reposition an element to an endpoint. -
Until Python 3.8, lacked a method.
- class (items)
-
Return an instance of a subclass that has methods
specialized for rearranging dictionary order.New in version 3.1.
- (last=True)
-
The method for ordered dictionaries returns and removes a
(key, value) pair. The pairs are returned in
LIFO order if last is true
or FIFO order if false.
- (key, last=True)
-
Move an existing key to either end of an ordered dictionary. The item
is moved to the right end if last is true (the default) or to the
beginning if last is false. Raises if the key does
not exist:>>> d = OrderedDict.fromkeys('abcde') >>> d.move_to_end('b') >>> ''.join(d.keys()) 'acdeb' >>> d.move_to_end('b', last=False) >>> ''.join(d.keys()) 'bacde'New in version 3.2.
In addition to the usual mapping methods, ordered dictionaries also support
reverse iteration using .
Equality tests between objects are order-sensitive
and are implemented as .
Equality tests between objects and other
objects are order-insensitive like regular
dictionaries. This allows objects to be substituted
anywhere a regular dictionary is used.
Changed in version 3.5: The items, keys, and values
of now support reverse iteration using .
Changed in version 3.6: With the acceptance of PEP 468, order is retained for keyword arguments
passed to the constructor and its
method.
Changed in version 3.9: Added merge () and update () operators, specified in PEP 584.
UserString objects¶
The class, acts as a wrapper around string objects.
The need for this class has been partially supplanted by the ability to
subclass directly from ; however, this class can be easier
to work with because the underlying string is accessible as an
attribute.
- class (seq)
-
Class that simulates a string object. The instance’s
content is kept in a regular string object, which is accessible via the
attribute of instances. The instance’s
contents are initially set to a copy of seq. The seq argument can
be any object which can be converted into a string using the built-in
function.In addition to supporting the methods and operations of strings,
instances provide the following attribute:-
A real object used to store the contents of the
class.
Changed in version 3.5: New methods , , ,
, , and . -
Создание множеств
Множество может быть создано путем перечисления его элементов через запятую и заключением их в фигурные скобки:
А вот создать пустое множество с помощью уже не получится, так как пустые фигурные скобки являются литералом словарей:
Создать пустое множество можно только с помощью функции :
Если передать функции некоторый объект, то она попытается преобразовать его в множество:
Если передать функции другое множество, то он будет возвращено как бы без изменений, но на самом деле будет возвращена его поверхностная копия:
Множества типа set являются изменяемыми и в них могут добавляться элементы. Это может привести к тому, что если две переменные ссылаются на одно и тоже, множество то изменение одной приведет к изменению другой:
Поверхностное копирование множеств позволяет избежать таких проблем:
Множества могут быть созданы с помощью генераторов множеств:
Использование setattr() с getattrr()
Обычно он используется в тандеме с для получения и установки атрибутов объектов.
Вот пример, демонстрирующий некоторые варианты использования сочетании с .
В этом примере создаются объекты и устанавливаются атрибуты каждого предмета в соответствии с их оценками для одного ученика.
После создания объекта Student с помощью мы используем и сортируем оценки учащихся по предметам.
class Student():
def __init__(self, name, results):
self.name = name
for key, value in results.items():
# Sets the attribute of the 'subject' to
# the corresponding subject mark.
# For example: a.'Chemistry' = 75
setattr(self, key, value)
def update_mark(self, subject, mark):
self.subject = mark
subjects =
a = Student('Amit', {key: value for (key, value) in zip(subjects, )})
b = Student('Rahul', {key: value for (key, value) in zip(subjects, )})
c = Student('Sunil', {key: value for (key, value) in zip(subjects, )})
student_list =
stud_names =
print('Sorted Physics Marks:')
print(sorted())
print('\nSorted Marks for all subjects:')
print(sorted())
print('\nSorted Marks for every Student:')
print(dict(zip(stud_names, ) for s in student_list])))
Хотя некоторые однострочники Python могут показаться очень сложными, это не так. Первый эквивалентен:
ls = []
for s in student_list:
ls.append(getattr(s, 'Physics'))
# Sort the list
ls.sort()
print(ls)
Второй тоже очень похож, но использует два вложенных цикла вместо одного.
ls = []
for s in student_list:
for subject in subjects:
ls.append(getattr(s, subject))
ls.sort()
print(ls)
Последний Словарь для каждого студента.
Сначала мы перебираем каждое имя и получаем атрибут из списка объектов ученика, а затем сортируем промежуточный список перед добавлением в наш Словарь.
dct = {}
for name, s in zip(subjects, student_list):
ls = []
for subject in subjects:
ls.append(getattr(s, subject))
ls.sort()
dct = ls
print(dct)
Вывод полного фрагмента кода:
Sorted Physics Marks:
Sorted Marks for all subjects:
Sorted Marks for every Student:
{'Amit': , 'Rahul': , 'Sunil': }
Свойства методов и операторов
Как показано выше, данные операции, за некоторым исключением, выполнятся двумя способами: при помощи метода или соответствующего ему оператора (например и оператор ). Главным и основным их различием является то, что метод может принимать в качестве аргумента не только , но и любой итерируемый объект, в то время, как оператор требует в качестве операндов наличие фактических множеств.
Но есть и сходства. Например, важным является то, что некоторые операторы и методы позволяют совершать операции над несколькими сетами сразу:
Тем интереснее, что оператор симметрической разности позволяет использовать несколько наборов, а метод – нет.
Приоритет
Иногда выражение содержит несколько операторов. В этом случае приоритет оператора используется для определения порядка выполнения.
- Мы можем создать группу выражений, используя круглые скобки. Выражение в скобках сначала вычисляется, прежде чем они смогут участвовать в дальнейших вычислениях.
- Некоторые операторы имеют одинаковый уровень приоритета. В этом случае выражение оценивается слева направо.
В таблице ниже перечислены приоритеты операторов в порядке убывания.
| Приоритет |
|---|
| ** (экспонента) |
| ~ (Дополнение к единицам) |
| *, /, //, % (Умножение, Деление, Операторы Модуля) |
| +, – (Сложение, Вычитание) |
| <<, >> (операторы сдвига вправо и влево) |
| & (побитовый AND) |
| |, ^ (побитовый OR, XOR) |
| ==, !=, >, <, >=, <= (сравнения) |
| =, +=, -=, *=, /=, //=, %= (присваивания) |
| is, is not (идентификации) |
| in, not in (принадлежности) |
| not, and, or (логические) |
Обход множеств в цикле
Множества так же как последовательности (строки, списки и т.д) и отображения (словари) являются коллекциями, т.е. могут хранить сложные структуры данных (например, кортежи). Но так как элементы множеств не снабжены никакими идентификаторами (ни индексами, ни ключами), то множества не поддерживают операторы извлечения среза и извлечения элемента по ключу . Тем не менее множества поддерживают оператор проверки на вхождение (а так же ) и функцию определения размера :
Множества поддерживают механизм итерирования и их элементы могут быть получены перебором в цикле :
Чаще всего множества используются для итерирования уникальных элементов последовательностей. И тут возможны два случая. Давайте рассмотрим следующий список:
В первом случае, может быть неважно в каком порядке обрабатываются элементы, главное обрабатывать только уникальные:
Во втором случае, по прежнему нужно обрабатывать только уникальные элементы, но порядок следования элементов в списке может оказаться важен. В этом случае используют пустые множества:
Так же множества могут выступать в роли итерируемого объекта в любых генераторах:
5.4. Sets¶
Python also includes a data type for sets. A set is an unordered collection
with no duplicate elements. Basic uses include membership testing and
eliminating duplicate entries. Set objects also support mathematical operations
like union, intersection, difference, and symmetric difference.
Curly braces or the function can be used to create sets. Note: to
create an empty set you have to use , not ; the latter creates an
empty dictionary, a data structure that we discuss in the next section.
Here is a brief demonstration:
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # show that duplicates have been removed
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # fast membership testing
True
>>> 'crabgrass' in basket
False
>>> # Demonstrate set operations on unique letters from two words
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # unique letters in a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # letters in a but not in b
{'r', 'd', 'b'}
>>> a | b # letters in a or b or both
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # letters in both a and b
{'a', 'c'}
>>> a ^ b # letters in a or b but not both
{'r', 'd', 'b', 'm', 'z', 'l'}
Similarly to , set comprehensions
are also supported:
Назначение в Python
Множества (set) в питоне появились не сразу, и здесь они представлены как неупорядоченные коллекции уникальных и неизменяемых объектов. Коллекции, которые не являются ни последовательностями (как списки), ни отображениями (как словари). Хотя с последними у множеств много общего.
Можно сказать, что set напоминает словарь, в котором ключи не имеют соответствующих им значений
Множества:
- Дают возможность быстро удалять дубликаты, поскольку, по определению, могут содержать только уникальные элементы;
- Позволяют, в отличие от других коллекций, выполнять над собой ряд математических операций, таких как объединение, пересечение и разность множеств;
Пример set-ов в Python:
defaultdict objects¶
- class (default_factory, …)
-
Returns a new dictionary-like object. is a subclass of the
built-in class. It overrides one method and adds one writable
instance variable. The remaining functionality is the same as for the
class and is not documented here.The first argument provides the initial value for the
attribute; it defaults to . All remaining arguments are treated the same
as if they were passed to the constructor, including keyword
arguments.objects support the following method in addition to the
standard operations:- (key)
-
If the attribute is , this raises a
exception with the key as argument.If is not , it is called without arguments
to provide a default value for the given key, this value is inserted in
the dictionary for the key, and returned.If calling raises an exception this exception is
propagated unchanged.This method is called by the method of the
class when the requested key is not found; whatever it
returns or raises is then returned or raised by .Note that is not called for any operations besides
. This means that will, like normal
dictionaries, return as a default rather than using
.
objects support the following instance variable:
-
This attribute is used by the method; it is
initialized from the first argument to the constructor, if present, or to
, if absent.
Changed in version 3.9: Added merge () and update () operators, specified in
PEP 584.
Значения нотации «О» большое
На письме временная сложность алгоритма обозначается как O(n), где n — размер входной коллекции.
O(1)
Обозначение константной временной сложности. Независимо от размера коллекции, время, необходимое для выполнения операции, константно. Это обозначение константной временной сложности. Эти операции выполняются настолько быстро, насколько возможно. Например, операции, которые проверяют, есть ли внутри коллекции элементы, имеют сложность O(1).
O(log n)
Обозначение логарифмической временной сложности. В этом случае когда размер коллекции увеличивается, время, необходимое для выполнения операции, логарифмически увеличивается. Эту сложность имеют потенциально оптимизированные алгоритмы поиска.
O(n)
Обозначение линейной временной сложности. Время, необходимое для выполнения операции, прямо и линейно пропорционально количеству элементов в коллекции. Это обозначение линейной временной сложности. Это что-то среднее с точки зрения производительности. Например, если мы хотим суммировать все элементы в коллекции, нужно будет выполнить итерацию по коллекции. Следовательно, итерация коллекции является операцией O(n).
O(n log n)
Обозначение квазилинейной временной сложности. Скорость выполнения операции является квазилинейной функцией числа элементов в коллекции. Временная сложность оптимизированного алгоритма сортировки обычно равна O(n log n).
O(n^2)
Обозначение квадратичной временной сложности. Время, необходимое для выполнения операции, пропорционально квадрату элементов в коллекции.
O(n!)
Обозначение факториальной временной сложности. Каждая операция требует вычисления всех перестановок коллекции, следовательно требуемое время выполнения операции является факториалом размера входной коллекции. Это очень медленно.
Нотация «O» большое относительна. Она не зависит от машины, игнорирует константы и понятна широкой аудитории, включая математиков, технологов, специалистов по данным и т. д.
Array.isArray
Массивы не
образуют отдельный тип языка. Они основаны на объектах. Поэтому typeof не может
отличить простой объект от массива:
console.log(typeof {}); // object
console.log (typeof ); // тоже object
Но массивы
используются настолько часто, что для этого придумали специальный метод: Array.isArray(value). Он возвращает
true, если value массив, и false, если нет.
console.log(Array.isArray({})); // false
console.log(Array.isArray()); // true
Подведем итоги
по рассмотренным методам массивов. У нас получился следующий список:
|
Для |
|
|
push(…items) |
добавляет элементы в конец |
|
pop() |
извлекает элемент с конца |
|
shift() |
извлекает элемент с начала |
|
unshift(…items) |
добавляет элементы в начало |
|
splice(pos, deleteCount, …items) |
начиная с индекса pos, удаляет |
|
slice(start, end) |
создаёт новый массив, копируя в него |
|
concat(…items) |
возвращает новый массив: копирует все |
|
Для поиска |
|
|
indexOf/lastIndexOf(item, pos) |
ищет item, начиная с позиции pos, и |
|
includes(value) |
возвращает true, если в массиве |
|
find/filter(func) |
фильтрует элементы через функцию и |
|
findIndex(func) |
похож на find, но возвращает индекс |
|
Для перебора |
|
|
forEach(func) |
вызывает func для каждого элемента. |
|
Для |
|
|
map(func) |
создаёт новый массив из результатов |
|
sort(func) |
сортирует массив «на месте», а потом |
|
reverse() |
«на месте» меняет порядок следования |
|
split/join |
преобразует строку в массив и обратно |
|
reduce(func, initial) |
вычисляет одно значение на основе |
Видео по теме
JavaScipt #1: что это такое, с чего начать, как внедрять и запускать
JavaScipt #2: способы объявления переменных и констант в стандарте ES6+
JavaScript #3: примитивные типы number, string, Infinity, NaN, boolean, null, undefined, Symbol
JavaScript #4: приведение типов, оператор присваивания, функции alert, prompt, confirm
JavaScript #5: арифметические операции: +, -, *, /, **, %, ++, —
JavaScript #6: условные операторы if и switch, сравнение строк, строгое сравнение
JavaScript #7: операторы циклов for, while, do while, операторы break и continue
JavaScript #8: объявление функций по Function Declaration, аргументы по умолчанию
JavaScript #9: функции по Function Expression, анонимные функции, callback-функции
JavaScript #10: анонимные и стрелочные функции, функциональное выражение
JavaScript #11: объекты, цикл for in
JavaScript #12: методы объектов, ключевое слово this
JavaScript #13: клонирование объектов, функции конструкторы
JavaScript #14: массивы (array), методы push, pop, shift, unshift, многомерные массивы
JavaScript #15: методы массивов: splice, slice, indexOf, find, filter, forEach, sort, split, join
JavaScript #16: числовые методы toString, floor, ceil, round, random, parseInt и другие
JavaScript #17: методы строк — length, toLowerCase, indexOf, includes, startsWith, slice, substring
JavaScript #18: коллекции Map и Set
JavaScript #19: деструктурирующее присваивание
JavaScript #20: рекурсивные функции, остаточные аргументы, оператор расширения
JavaScript #21: замыкания, лексическое окружение, вложенные функции
JavaScript #22: свойства name, length и методы call, apply, bind функций
JavaScript #23: создание функций (new Function), функции setTimeout, setInterval и clearInterval
5.8. Comparing Sequences and Other Types¶
Sequence objects typically may be compared to other objects with the same sequence
type. The comparison uses lexicographical ordering: first the first two
items are compared, and if they differ this determines the outcome of the
comparison; if they are equal, the next two items are compared, and so on, until
either sequence is exhausted. If two items to be compared are themselves
sequences of the same type, the lexicographical comparison is carried out
recursively. If all items of two sequences compare equal, the sequences are
considered equal. If one sequence is an initial sub-sequence of the other, the
shorter sequence is the smaller (lesser) one. Lexicographical ordering for
strings uses the Unicode code point number to order individual characters.
Some examples of comparisons between sequences of the same type:
(1, 2, 3) < (1, 2, 4)
1, 2, 3 < 1, 2, 4
'ABC' < 'C' < 'Pascal' < 'Python'
(1, 2, 3, 4) < (1, 2, 4)
(1, 2) < (1, 2, -1)
(1, 2, 3) == (1.0, 2.0, 3.0)
(1, 2, ('aa', 'ab')) < (1, 2, ('abc', 'a'), 4)
Note that comparing objects of different types with or is legal
provided that the objects have appropriate comparison methods. For example,
mixed numeric types are compared according to their numeric value, so 0 equals
0.0, etc. Otherwise, rather than providing an arbitrary ordering, the
interpreter will raise a exception.
Footnotes
-
Other languages may return the mutated object, which allows method
chaining, such as .
Вывод
Данная статья предоставляет подробное введение во множества языка программирования Python. Математическое определение множеств аналогично определению множеств в Python.
Множество — это набор элементов в произвольном порядке. Само по себе, множество является изменяемым, однако его элементы являются неизменяемыми.
Однако, мы можем добавлять и убирать элементы из множества без каких-либо проблем. В большей структур данных элементы являются индексированными. Однако, элементы множеств не являются индексированными. Это делает невозможным для нас выполнять операции, которые направлены на определенные элементы множества.