Python
Содержание:
- Массив нарезки
- Создание списков на Python
- Бинарный поиск
- Форма матрицы в Python
- Срез строки в Python
- Поиск Фибоначчи
- Срезы
- Копии и представления
- Создание массивов
- Сортировка массива в Python
- Изменение массива
- Ввод списка (массива) в языке Питон
- Зачем использовать Python для поиска?
- Использование sorted() для итерируемых объектов Python
- Двумерные массивы
- Начинаем работу
Массив нарезки
Все идет нормально; Создание и индексация массивов выглядит знакомо.
Теперь мы подошли к нарезке массивов, и это одна из функций, которая создает проблемы для начинающих массивов Python и NumPy.
Структуры, такие как списки и массивы NumPy, могут быть нарезаны. Это означает, что подпоследовательность структуры может быть проиндексирована и извлечена.
Это наиболее полезно при машинном обучении при указании входных и выходных переменных или разделении обучающих строк из строк тестирования.
Нарезка задается с помощью оператора двоеточия ‘:’ с ‘от’ а также ‘в‘Индекс до и после столбца соответственно. Срез начинается от индекса «от» и заканчивается на один элемент перед индексом «до».
Давайте рассмотрим несколько примеров.
Одномерная нарезка
Вы можете получить доступ ко всем данным в измерении массива, указав срез «:» без индексов.
При выполнении примера печатаются все элементы в массиве.
Первый элемент массива можно разрезать, указав фрагмент, который начинается с индекса 0 и заканчивается индексом 1 (один элемент перед индексом «до»)
Выполнение примера возвращает подмассив с первым элементом.
Мы также можем использовать отрицательные индексы в срезах. Например, мы можем нарезать последние два элемента в списке, начав срез с -2 (второй последний элемент) и не указав индекс «до»; это берет ломтик до конца измерения.
Выполнение примера возвращает подмассив только с двумя последними элементами.
Двумерная нарезка
Давайте рассмотрим два примера двумерного среза, которые вы, скорее всего, будете использовать в машинном обучении.
Разделение функций ввода и вывода
Распространено загруженные данные на входные переменные (X) и выходную переменную (y).
Мы можем сделать это, разрезая все строки и все столбцы до, но перед последним столбцом, затем отдельно индексируя последний столбец.
Для входных объектов мы можем выбрать все строки и все столбцы, кроме последнего, указав ‘:’ в индексе строк и: -1 в индексе столбцов.
Для выходного столбца мы можем снова выбрать все строки, используя ‘:’, и индексировать только последний столбец, указав индекс -1.
Собрав все это вместе, мы можем разделить 3-колоночный 2D-набор данных на входные и выходные данные следующим образом:
При выполнении примера печатаются разделенные элементы X и y
Обратите внимание, что X — это двумерный массив, а y — это одномерный массив
Сплит поезд и тестовые ряды
Обычно загруженный набор данных разбивают на отдельные наборы поездов и тестов.
Это разделение строк, где некоторая часть будет использоваться для обучения модели, а оставшаяся часть будет использоваться для оценки мастерства обученной модели.
Для этого потребуется разрезать все столбцы, указав «:» во втором индексе измерения. Набор обучающих данных будет содержать все строки от начала до точки разделения.
Тестовым набором данных будут все строки, начиная с точки разделения до конца измерения.
Собрав все это вместе, мы можем разделить набор данных в надуманной точке разделения 2.
При выполнении примера выбираются первые две строки для обучения и последняя строка для набора тестов.
Создание списков на Python
- Создать список можно несколькими способами. Рассмотрим их.
1. Получение списка через присваивание конкретных значений
Так выглядит в коде Python пустой список:
s = # Пустой список |
Примеры создания списков со значениями:
l = 25, 755, -40, 57, -41 # список целых чисел l = 1.13, 5.34, 12.63, 4.6, 34.0, 12.8 # список из дробных чисел l = "Sveta", "Sergei", "Ivan", "Dasha" # список из строк l = "Москва", "Иванов", 12, 124 # смешанный список l = , , , 1, , 1, 1, 1, # список, состоящий из списков l = 's', 'p', 'isok', 2 # список из значений и списка |
2. Списки при помощи функции List()
Получаем список при помощи функции List()
empty_list = list() # пустой список
l = list ('spisok') # 'spisok' - строка
print(l) # - результат - список
|
4. Генераторы списков
- В python создать список можно также при помощи генераторов, — это довольно-таки новый метод:
- Первый простой способ.
Сложение одинаковых списков заменяется умножением:
# список из 10 элементов, заполненный единицами l = 1*10 # список l = |
Второй способ сложнее.
l = i for i in range(10) # список l = |
или такой пример:
c = c * 3 for c in 'list' print (c) # |
Пример:
Заполнить список квадратами чисел от 0 до 9, используя генератор списка.
Решение:
l = i*i for i in range(10) |
еще пример:
l = (i+1)+i for i in range(10) print(l) # |
Случайные числа в списке:
from random import randint l = randint(10,80) for x in range(10) # 10 чисел, сгенерированных случайным образом в диапазоне (10,80) |
Задание Python 4_1:
Создайте список целых чисел от -20 до 30 (генерация).
Результат:
Задание Python 4_2:
Создайте список целых чисел от -10 до 10 с шагом 2 (генерация list).
Результат:
Задание Python 4_3:
Создайте список из 20 пятерок (генерация).
Результат:
Задание Python 4_4:
Создайте список из сумм троек чисел от 0 до 10, используя генератор списка (0 + 1 + 2, 1 + 2 + 3, …).
Результат:
Задание Python 4_5 (сложное):
Заполните массив элементами арифметической прогрессии. Её первый элемент, разность и количество элементов нужно ввести с клавиатуры.
* Формула для получения n-го члена прогрессии: an = a1 + (n-1) * d
Простейшие операции над списками
- Списки можно складывать (конкатенировать) с помощью знака «+»:
l = 1, 3 + 4, 23 + 5 # Результат: # l = |
33, -12, 'may' + 21, 48.5, 33 # |
или так:
a=33, -12, 'may' b=21, 48.5, 33 print(a+b)# |
Операция повторения:
,,,1,1,1 * 2 # , , , , , ] |
Пример:
Для списков операция переприсваивания значения отдельного элемента списка разрешена!:
a=3, 2, 1 a1=; print(a) # |
Можно!
Задание 4_6:
В строке записана сумма натуральных чисел: ‘1+25+3’. Вычислите это выражение. Работать со строкой, как со списком.
Начало программы:
s=input('введите строку')
l=list(str(s));
|
Как узнать длину списка?
Бинарный поиск
Бинарный поиск работает по принципу «разделяй и властвуй». Он быстрее, чем линейный поиск, но требует, чтобы массив был отсортирован перед выполнением алгоритма.
Предполагая, что мы ищем значение в отсортированном массиве, алгоритм сравнивает со значением среднего элемента массива, который мы будем называть .
- Если — это тот элемент, который мы ищем (в лучшем случае), мы возвращаем его индекс.
- Если нет, мы определяем, в какой половине массива мы будем искать дальше, основываясь на том, меньше или больше значение значения , и отбрасываем вторую половину массива.
- Затем мы рекурсивно или итеративно выполняем те же шаги, выбирая новое значение для , сравнивая его с и отбрасывая половину массива на каждой итерации алгоритма.
Алгоритм бинарного поиска можно написать как рекурсивно, так и итеративно. , потому что она требует выделения новых кадров стека.
Поскольку хороший алгоритм поиска должен быть максимально быстрым и точным, давайте рассмотрим итеративную реализацию бинарного поиска:
def BinarySearch(lys, val):
first = 0
last = len(lys)-1
index = -1
while (first <= last) and (index == -1):
mid = (first+last)//2
if lys == val:
index = mid
else:
if val<lys:
last = mid -1
else:
first = mid +1
return index
Если мы используем функцию для вычисления:
>>> BinarySearch(, 20)
То получим следующий результат, являющийся индексом искомого значения:
1
На каждой итерации алгоритм выполняет одно из следующих действий:
- Возврат индекса текущего элемента.
- Поиск в левой половине массива.
- Поиск в правой половине массива.
Мы можем выбрать только одно действие на каждой итерации. Также на каждой итерации наш массив делится на две части. Из-за этого временная сложность двоичного поиска равна O(log n).
Одним из недостатков бинарного поиска является то, что если в массиве имеется несколько вхождений элемента, он возвращает индекс не первого элемента, а ближайшего к середине:
>>> print(BinarySearch(, 4))
После выполнения этого фрагмента кода будет возвращен индекс среднего элемента:
2
Для сравнения: выполнение линейного поиска по тому же массиву вернет индекс первого элемента:
Однако мы не можем категорически утверждать, что двоичный поиск не работает, если массив содержит дубликаты. Он может работать так же, как линейный поиск, и в некоторых случаях возвращать первое вхождение элемента. Например:
>>> print(BinarySearch(, 4)) 3
Бинарный поиск довольно часто используется на практике, потому что он эффективен и быстр по сравнению с линейным поиском. Однако у него есть некоторые недостатки, такие как зависимость от оператора . Существует много других алгоритмов поиска, работающих по принципу «разделяй и властвуй», которые являются производными от бинарного поиска. Некоторые из них мы рассмотрим далее.
Форма матрицы в Python
Lenght matrix (длина матрицы) в Python определяет форму. Длину матрицы проверяют методом shape().
Массив с 2-мя либо 3-мя элементами будет иметь форму (2, 2, 3). И это состояние изменится, когда в shape() будут указаны аргументы: первый — число подмассивов, второй — размерность каждого подмассива.
Те же задачи и ту же операцию выполнит reshape(). Здесь lenght и другие параметры matrix определяются числом столбцов и строк.
Есть методы и для манипуляции формой. Допустим, при манипуляциях с двумерными или многомерными массивами можно сделать одномерный путём выстраивания внутренних значений последовательно по возрастанию. А чтобы поменять в матрице строки и столбцы местами, применяют transpose().
Срез строки в Python
Иногда требуется получить из строки не один символ, а сразу несколько по некоторой закономерности – первые 2, каждый 3-ий или 4 последних. Для этого существуют срезы. Мы выборочно срезаем нужные символы и обращаемся по срезу. Надо отметить, что физически срезанные символы, остаются на своих местах. Сама строка никоим образом не меняется, мы работаем со срезанными копиями.
Возьмем первые три символа у строки ‘срезы Python’. В параметрах передадим два индекса – начало и конец среза. При срезе первый индекс входит включительно, а второй индекс не входит в выборку.
slice = ‘срезы Python’ print(slice) сре #символ ‘з’ не попал в выборку
Если не указаны начало или конец среза, то по умолчанию берётся первый или последний элемент коллекции.
slice = ‘срезы Python’ print(slice) Python #с индекса 6 и до конца
slice = ‘срезы Python’ print(slice) срезы #с начала строки до 5-го индекса включительно
slice = ‘срезы Python’ print(slice) срезы Python #выводит строку целиком
Третьим параметром у срезов, может передаваться шаг.
slice = ‘срезы Python’ print(slice) сеыPto #выводит символы через один
Поиск Фибоначчи
Поиск Фибоначчи — это еще один алгоритм «разделяй и властвуй», который имеет сходство как с бинарным поиском, так и с jump search. Он получил свое название потому, что использует числа Фибоначчи для вычисления размера блока или диапазона поиска на каждом шаге.
Числа Фибоначчи — это последовательность чисел 0, 1, 1, 2, 3, 5, 8, 13, 21 …, где каждый элемент является суммой двух предыдущих чисел.
Алгоритм работает с тремя числами Фибоначчи одновременно. Давайте назовем эти три числа , и . Где и — это два числа, предшествующих в последовательности:
Мы инициализируем значения 0, 1, 1 или первые три числа в последовательности Фибоначчи. Это поможет нам избежать в случае, когда наш массив содержит очень маленькое количество элементов.
Затем мы выбираем наименьшее число последовательности Фибоначчи, которое больше или равно числу элементов в нашем массиве , в качестве значения . А два числа Фибоначчи непосредственно перед ним — в качестве значений и . Пока в массиве есть элементы и значение больше единицы, мы:
- Сравниваем со значением блока в диапазоне до и возвращаем индекс элемента, если он совпадает.
- Если значение больше, чем элемент, который мы в данный момент просматриваем, мы перемещаем значения , и на два шага вниз в последовательности Фибоначчи и меняем индекс на индекс элемента.
- Если значение меньше, чем элемент, который мы в данный момент просматриваем, мы перемещаем значения и на один шаг вниз в последовательности Фибоначчи.
Давайте посмотрим на реализацию этого алгоритма на Python:
def FibonacciSearch(lys, val):
fibM_minus_2 = 0
fibM_minus_1 = 1
fibM = fibM_minus_1 + fibM_minus_2
while (fibM < len(lys)):
fibM_minus_2 = fibM_minus_1
fibM_minus_1 = fibM
fibM = fibM_minus_1 + fibM_minus_2
index = -1;
while (fibM > 1):
i = min(index + fibM_minus_2, (len(lys)-1))
if (lys < val):
fibM = fibM_minus_1
fibM_minus_1 = fibM_minus_2
fibM_minus_2 = fibM - fibM_minus_1
index = i
elif (lys > val):
fibM = fibM_minus_2
fibM_minus_1 = fibM_minus_1 - fibM_minus_2
fibM_minus_2 = fibM - fibM_minus_1
else :
return i
if(fibM_minus_1 and index < (len(lys)-1) and lys == val):
return index+1;
return -1
Используем функцию FibonacciSearch для вычисления:
>>> print(FibonacciSearch(, 6))
Давайте посмотрим на пошаговый процесс поиска:
- Присваиваем переменной наименьшее число Фибоначчи, которое больше или равно длине списка. В данном случае наименьшее число Фибоначчи, отвечающее нашим требованиям, равно 13.
- Значения присваиваются следующим образом:
fibM = 13
fibM_minus_1 = 8
fibM_minus_2 = 5
index = -1
Далее мы проверяем элемент lys, где 4 — это минимум из двух значений — index + fibM_minus_2 (-1+5) и длина массива минус 1 (11-1). Поскольку значение lys равно 5, что меньше искомого значения, мы перемещаем числа Фибоначчи на один шаг вниз в последовательности, получая следующие значения:
fibM = 8
fibM_minus_1 = 5
fibM_minus_2 = 3
index = 4
Далее мы проверяем элемент lys, где 7 — это минимум из двух значений: index + fibM_minus_2 (4 + 3) и длина массива минус 1 (11-1). Поскольку значение lys равно 8, что больше искомого значения, мы перемещаем числа Фибоначчи на два шага вниз в последовательности, получая следующие значения:
fibM = 3
fibM_minus_1 = 2
fibM_minus_2 = 1
index = 4
Затем мы проверяем элемент lys, где 5 — это минимум из двух значений: index + fibM_minus_2 (4+1) и длина массива минус 1 (11-1) . Значение lys равно 6, и это наше искомое значение!
Получаем ожидаемый результат:
5
Временная сложность поиска Фибоначчи равна O(log n). Она такая же, как и у бинарного поиска. Это означает, что алгоритм в большинстве случаев работает быстрее, чем линейный поиск и jump search.
Поиск Фибоначчи можно использовать, когда у нас очень большое количество искомых элементов и мы хотим уменьшить неэффективность, связанную с использованием алгоритма, основанного на операторе деления.
Дополнительным преимуществом использования поиска Фибоначчи является то, что он может вместить входные массивы, которые слишком велики для хранения в кэше процессора или ОЗУ, потому что он ищет элементы с увеличивающимся шагом, а не с фиксированным.
Срезы
Часто приходится работать не с целым массивом, а только с некоторыми его элементами. Для этих целей в «Пайтоне» существует метод «Срез» (слайс). Он пришел на замену перебору элементов циклом for.
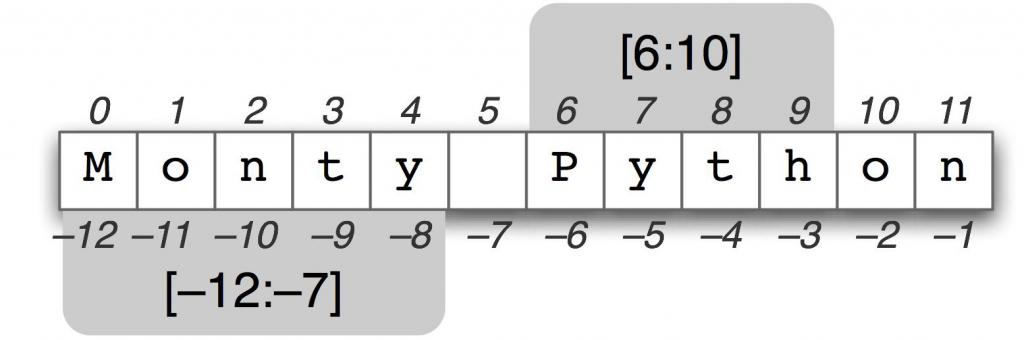
Метод открывает широкие возможности для получения копии массива в «Питоне». Все манипуляции осуществляются в таком виде . Здесь значение start обозначает индекс элемента, от которого начинается отсчет, значение stop — последний элемент, размер шага — количество пропускаемых элементов при каждой итерации. По умолчанию start равняется нулю, то есть отсчет начинается от нулевого элемента списка, stop равняется индексу последнего элемента в списке, шаг — равен единице, то есть перебирает каждый поочередно. Если передать в функцию без аргументов, список копируется полностью от начала до конца.
Например, у нас есть массив:
mas =
Чтобы его скопировать, используем mas. Функция вернет последовательность элементов . Если аргументом будет отрицательное значение, например -3, функция вернет элементы с индексами от третьего до последнего.
mas; //
После двойного двоеточия указывается шаг элементов, копируемых в массиве. Например, mas вернет массив . Если указано отрицательное значение, например, отсчет будет начинаться с конца, и получим .
Методом среза можно гибко работать с вложенными списками. Для двумерного массива в «Питоне» означает, что вернется каждый третий элемент всех массивов. Если указать — вернутся первые два.
Копии и представления
При работе с массивами, их данные иногда необходимо копировать в другой массив, а иногда нет. Это часто является источником путаницы. Возможно 3 случая:
Вообще никаких копий
Простое присваивание не создает ни копии массива, ни копии его данных:
>>> a = np.arange(12) >>> b = a # Нового объекта создано не было >>> b is a # a и b это два имени для одного и того же объекта ndarray True >>> b.shape = (3,4) # изменит форму a >>> a.shape (3, 4)
Python передает изменяемые объекты как ссылки, поэтому вызовы функций также не создают копий.
Представление или поверхностная копия
Разные объекты массивов могут использовать одни и те же данные. Метод view() создает новый объект массива, являющийся представлением тех же данных.
>>> c = a.view()
>>> c is a
False
>>> c.base is a # c это представление данных, принадлежащих a
True
>>> c.flags.owndata
False
>>>
>>> c.shape = (2,6) # форма а не поменяется
>>> a.shape
(3, 4)
>>> c,4 = 1234 # данные а изменятся
>>> a
array(,
,
])
Срез массива это представление:
>>> s = a = 10
>>> a
array(,
,
])
Глубокая копия
Метод copy() создаст настоящую копию массива и его данных:
>>> d = a.copy() # создается новый объект массива с новыми данными
>>> d is a
False
>>> d.base is a # d не имеет ничего общего с а
False
>>> d, = 9999
>>> a
array(,
,
])
Создание массивов
В NumPy существует много способов создать массив. Один из наиболее простых — создать массив из обычных списков или кортежей Python, используя функцию numpy.array() (запомните: array — функция, создающая объект типа ndarray):
>>> import numpy as np >>> a = np.array() >>> a array() >>> type(a) <class 'numpy.ndarray'>
Функция array() трансформирует вложенные последовательности в многомерные массивы. Тип элементов массива зависит от типа элементов исходной последовательности (но можно и переопределить его в момент создания).
>>> b = np.array(, 4, 5, 6]])
>>> b
array(,
])
Можно также переопределить тип в момент создания:
>>> b = np.array(, 4, 5, 6]], dtype=np.complex)
>>> b
array(,
])
Функция array() не единственная функция для создания массивов. Обычно элементы массива вначале неизвестны, а массив, в котором они будут храниться, уже нужен. Поэтому имеется несколько функций для того, чтобы создавать массивы с каким-то исходным содержимым (по умолчанию тип создаваемого массива — float64).
Функция zeros() создает массив из нулей, а функция ones() — массив из единиц. Обе функции принимают кортеж с размерами, и аргумент dtype:
>>> np.zeros((3, 5))
array(,
,
])
>>> np.ones((2, 2, 2))
array(,
],
,
]])
Функция eye() создаёт единичную матрицу (двумерный массив)
>>> np.eye(5)
array(,
,
,
,
])
Функция empty() создает массив без его заполнения. Исходное содержимое случайно и зависит от состояния памяти на момент создания массива (то есть от того мусора, что в ней хранится):
>>> np.empty((3, 3))
array(,
,
])
>>> np.empty((3, 3))
array(,
,
])
Для создания последовательностей чисел, в NumPy имеется функция arange(), аналогичная встроенной в Python range(), только вместо списков она возвращает массивы, и принимает не только целые значения:
>>> np.arange(10, 30, 5) array() >>> np.arange(, 1, 0.1) array()
Вообще, при использовании arange() с аргументами типа float, сложно быть уверенным в том, сколько элементов будет получено (из-за ограничения точности чисел с плавающей запятой). Поэтому, в таких случаях обычно лучше использовать функцию linspace(), которая вместо шага в качестве одного из аргументов принимает число, равное количеству нужных элементов:
>>> np.linspace(, 2, 9) # 9 чисел от 0 до 2 включительно array()
fromfunction(): применяет функцию ко всем комбинациям индексов
Сортировка массива в Python
Метод Пузырька
Сортировку массива в python будем выполнять :
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import random
from random import randint
mas = randint(1,10) for i in range(n)
for i in range(n):
print(masi,sep="")
print(" ")
for i in range(n-1):
for j in range(n-2, i-1 ,-1):
if masj+1 < masj:
masj, masj+1 = masj+1, masj
for i in range(n):
print(masi,sep="")
|
Задание Python 7_4:
Необходимо написать программу, в которой сортировка выполняется «методом камня» – самый «тяжёлый» элемент опускается в конец массива.
Быстрая сортировка массива
Данную сортировку еще называют или сортировка Хоара (по имени разработчика — Ч.Э. Хоар).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import random
from random import randint
# процедура
def qSort ( A, nStart, nEnd ):
if nStart >= nEnd: return
L = nStart; R = nEnd
X = A(L+R)//2
while L <= R:
while AL < X: L += 1 # разделение
while AR > X: R -= 1
if L <= R:
AL, AR = AR, AL
L += 1; R -= 1
qSort ( A, nStart, R ) # рекурсивные вызовы
qSort ( A, L, nEnd )
N=10
A = randint(1,10) for i in range(N)
print(A)
# вызов процедуры
qSort ( A, , N-1 )
print('отсортированный', A)
|
Задание Python 7_5:
Необходимо написать программу, которая сортирует массив (быстрой сортировкой) по возрастанию первой цифры числа.
Встроенные функции
- mas.reverse() — стандартный метод для перестановки элементов массива в обратном порядке;
- mas2 = sorted (mas1) — встроенная функция для сортировки массивов (списков);
Задание Python 7_6:
Напишите программу, которая, не изменяя заданный массив, выводит номера его элементов в возрастающем порядке значений этих элементов. Использовать вспомогательный массив номеров.
Пример:
результат: 0 2 3 1 4
Задание Python 7_7:
Напишите программу, которая сортирует массив и находит количество различных чисел в нём. Не использовать встроенные функции.Пример:
Введите количество: 10 Массив: Массив отсортированный: Количество различных элементов: 9
Задание Python 7_8:
Дан массив. Назовем серией группу подряд идущих одинаковых элементов, а длиной серии — количество этих элементов. Сформировать два новых массива, в один из них записывать длины всех серий, а во второй — значения элементов, образующих эти серии.Пример:
Введите количество элементов: 15 Массив: Элементы, создающие серии: Длины серий:
Задание Python 7_9:
Напишите вариант метода пузырька, который заканчивает работу, если на очередном шаге внешнего цикла не было перестановок. Не использовать встроенные функции.
Задание Python 7_10:
Напишите программу, которая сортирует массив, а затем находит максимальное из чисел, встречающихся в массиве несколько раз. Не использовать встроенные функции.
Пример:
Введите количество: 15 Массив исходный: Массив отсортированный: Максимальное из чисел, встречающихся в массиве несколько раз: 12
Изменение массива
Как было сказано, можно менять не только значение, записанные в массиве, но и сам массив: можно изменять его размер, добавляя и удаляя элементы.
В примере ниже инициализируется пустой массив fibs, а затем заполняется элементами:
>>> fibs = [] >>> fibs.append(1) >>> fibs >>> fibs.append(1) >>> fibs >>> fibs.append(2) >>> fibs >>> fibs.append(3) >>> fibs
>>> fibs = 1, 1, 2, 3 >>> fibs >>> fibs.pop() 3 >>> fibs >>> fibs.pop() 2 >>> fibs
Метод list.insert(i, x) вставляет элемент x на позицию i в списке
>>> A = 1, 9, 10, 3, -1 >>> A >>> A.insert(, 'i') >>> A >>> A.insert(5, 'i2') >>> A
Метод list.pop(i) удаляет из списка элемент с индексом i.
>>> B = 'popme', 1, , 'popme2', 3, -100 >>> B.pop() 'popme' >>> B >>> B.pop(2) 'popme2' >>> B
Ввод списка (массива) в языке Питон
- Простой вариант ввода списка и его вывода:
L= L = int(input()) for i in range(5) # при вводе 1 2 3 4 5 print (L) # вывод: 1 2 3 4 5 |
Функция int здесь используется для того, чтобы строка, введенная пользователем, преобразовывалась в целые числа.
Как уже рассмотрено выше, список можно выводить целым и поэлементно:
# вывод целого списка (массива) print (L) # поэлементный вывод списка (массива) for i in range(5): print ( Li, end = " " ) |
Задание Python 4_7:
Необходимо задать список (массив) из шести элементов; заполнить его вводимыми значениями и вывести элементы на экран. Использовать два цикла: первый — для ввода элементов, второй — для вывода.
Замечание: Для вывода через «,» используйте следующий синтаксис:
print ( Li, end = ", " ) |
Пример результата:
введите элементы массива: 3.0 0.8 0.56 4.3 23.8 0.7 Массив = 3, 0.8, 0.56, 4.3, 23.8, 0.7
Задание Python 4_8:
Заполните список случайными числами в диапазоне 20..100 и подсчитайте отдельно число чётных и нечётных элементов. Использовать цикл.
Замечание: .
Задание Python 4_9: Найдите минимальный элемент списка. Выведите элемент и его индекс. Список из 10 элементов инициализируйте случайными числами. Для перебора элементов списка использовать цикл.
Пример результата:
9 5 4 22 23 7 3 16 16 8 Минимальный элемент списка L7=3 |
Зачем использовать Python для поиска?
Python очень удобочитаемый и эффективный по сравнению с такими языками программирования, как Java, Fortran, C, C++ и т. д. Одним из ключевых преимуществ использования Python для реализации алгоритмов поиска является то, что вам не нужно беспокоиться о приведении или явной типизации.
В Python большинство алгоритмов поиска, которые мы обсуждали, будут работать так же хорошо, если мы ищем строку. Имейте в виду, что понадобится внести изменения в код для алгоритмов, которые используют искомый элемент для числовых вычислений, например алгоритм интерполяционного поиска.
Python также подходит, если вы хотите сравнить производительность различных алгоритмов поиска для вашего dataset’а. Создание прототипа на Python проще и быстрее, потому что вы можете сделать больше с меньшим количеством строк кода.
Чтобы сравнить производительность наших реализованных алгоритмов, в Python мы можем использовать библиотеку time:
import time start = time.time() # вызовите здесь функцию end = time.time() print(start-end)
Использование sorted() для итерируемых объектов Python
Python использует несколько чрезвычайно эффективных алгоритмов сортировки. Например, метод использует алгоритм под названием Timsort (который представляет собой комбинацию сортировки вставкой и сортировки слиянием) для выполнения высокооптимизированной сортировки.
С помощью этого метода можно отсортировать любой итерируемый объект Python, например список или массив.
import array
# Declare a list type object
list_object =
# Declare an integer array object
array_object = array.array('i', )
print('Sorted list ->', sorted(list_object))
print('Sorted array ->', sorted(array_object))
Вывод:
Sorted list -> Sorted array ->
Двумерные массивы
Выше везде элементами массива были числа. Но на самом деле элементами массива может быть что угодно, в том числе другие массивы. Пример:
a = b = c = z =
Что здесь происходит? Создаются три обычных массива , и , а потом создается массив , элементами которого являются как раз массивы , и .
Что теперь получается? Например, — это элемент №1 массива , т.е. . Но — это тоже массив, поэтому я могу написать — это то же самое, что , т.е. (не забывайте, что нумерация элементов массива идет с нуля). Аналогично, и т.д.
То же самое можно было записать проще:
z = , , ]
Получилось то, что называется двумерным массивом. Его можно себе еще представить в виде любой из этих двух табличек:
Первую табличку надо читать так: если у вас написано , то надо взять строку № и столбец №. Например, — это элемент на 1 строке и 2 столбце, т.е. -3. Вторую табличку надо читать так: если у вас написано , то надо взять столбец № и строку №. Например, — это элемент на 2 столбце и 1 строке, т.е. -3. Т.е. в первой табличке строка — это первый индекс массива, а столбец — второй индекс, а во второй табличке наоборот. (Обычно принято как раз обозначать первый индекс и — второй.)
Когда вы думаете про таблички, важно то, что питон на самом деле не знает ничего про строки и столбцы. Для питона есть только первый индекс и второй индекс, а уж строка это или столбец — вы решаете сами, питону все равно
Т.е. и — это разные вещи, и питон их понимает по-разному, а будет 1 номером строки или столбца — это ваше дело, питон ничего не знает про строки и столбцы. Вы можете как хотите это решить, т.е. можете пользоваться первой картинкой, а можете и второй — но главное не запутайтесь и в каждой конкретной программе делайте всегда всё согласованно. А можете и вообще не думать про строки и столбцы, а просто думайте про первый и второй индекс.
Обратите, кстати, внимание на то, что в нашем примере (массив, являющийся вторым элементом массива ) короче остальных массивов (и поэтому на картинках отсутствует элемент в правом нижнем углу). Это общее правило питона: питон не требует, чтобы внутренние массивы были одинаковой длины
Вы вполне можете внутренние массивы делать разной длины, например:
x = , , , [], ]
здесь нулевой массив имеет длину 4, первый длину 2, второй длину 3, третий длину 0 (т.е. не содержит ни одного элемента), а четвертый длину 1. Такое бывает надо, но не так часто, в простых задачах у вас будут все подмассивы одной длины.
(На самом деле даже элементы одного массива не обязаны быть одного типа. Можно даже делать так: , здесь нулевой элемент массива — сам является массивом, а еще два элемента — просто числа. Но это совсем редко бывает надо.)
Начинаем работу
Основным объектом NumPy является однородный многомерный массив (в numpy называется numpy.ndarray). Это многомерный массив элементов (обычно чисел), одного типа.
Наиболее важные атрибуты объектов ndarray:
ndarray.ndim — число измерений (чаще их называют «оси») массива.
ndarray.shape — размеры массива, его форма. Это кортеж натуральных чисел, показывающий длину массива по каждой оси. Для матрицы из n строк и m столбов, shape будет (n,m). Число элементов кортежа shape равно ndim.
ndarray.size — количество элементов массива. Очевидно, равно произведению всех элементов атрибута shape.
ndarray.dtype — объект, описывающий тип элементов массива. Можно определить dtype, используя стандартные типы данных Python. NumPy здесь предоставляет целый букет возможностей, как встроенных, например: bool_, character, int8, int16, int32, int64, float8, float16, float32, float64, complex64, object_, так и возможность определить собственные типы данных, в том числе и составные.
ndarray.itemsize — размер каждого элемента массива в байтах.