Tech&biz insights
Содержание:
- Последние добавленные или измененные записи:
- Opening an Excel file with Pandas ExcelWriter
- Немного про пиксели и цветовые пространства
- Openpyxl Charts
- Formatting of the Dataframe output
- Набор на курс Python: почему мы думаем, что Python 2.7. — это серьезно, а Python 3 — модно
- Доступ к пикселям и манипулирование ими
- Accessing XlsxWriter from Pandas
- Модификаторы регулярных выражений: флаги опций
- Openpyxl iterate by columns
- Шаблон регулярного выражения
- В пользу Python (и других внешних языков программирования)
- Запуск проекта Otus.ru
- Handling multiple Pandas Dataframes
- Данные как ваша отправная точка
- Запись в файл Excel с python
- Чтение и запись файлов в Python
- Использование Python и Excel для обработки и анализа данных. Часть 1: импорт данных и настройка среды
Последние добавленные или измененные записи:
Метод list.extend() в Python, расширяет список другой последовательностью. Метод sequence.extend(iterable) позволяет расширить последовательность sequence содержимым итерации iterable. Альтернативный способ расширения sequence += iterable. Эта операция поддерживаются изменяемыми типами последовательностей.
Способы форматирования текстовых строк в Python. Форматирование строковыми литералами, форматирование методом str.format(), форматирование оператором ‘%’ в стиле языка C.
F-строки. Форматированные строки в Python. Форматированный строковый литерал или f-string — это строковый литерал с префиксом ‘f’ или’F’. Эти строки могут содержать поля замены, которые являются выражениями, разделенными фигурными скобками {}.
Исключения, определяемые модулем concurrent.futures в Python. В разделе рассмотрены все исключения, определяемые модулем concurrent.futures.
Функция as_completed() модуля concurrent.futures в Python. Функция as_completed() модуля concurrent.futures возвращает итератор по экземплярам Future (возможно, созданным разными экземплярами Executor), заданным fs, который возвращает объекты Future по мере их завершения (завершенные или отмененные).
Объект Future модуля concurrent.futures в Python. Экземпляры Future создаются методом Executor.submit()] объектов [ThreadPoolExecutor или ProcessPoolExecutor и не должны создаваться непосредственно, за исключением тестирования. Объект Future содержит в себе будущие результаты выполнения вызываемых объектов, запущенных в потоках/процессах и методы,
Opening an Excel file with Pandas ExcelWriter
To perform more complex DataFrame writes, we will need to create an object. The object included in the Pandas module behaves almost exactly like the vanilla Python object that we used in our tutorial on Python IO. The object opens the file, handles write operations, and can be used within a block.
We can open an object within a block and assign it to the variable as follows:
And continuing the similarity to the object, we can use the method similar to the object’s method. Instead of including the file pathname in the call, we will use the object instead:
which results in the same Excel file we produced in the previous section.
Can’t get enough Python?
The DataFrame we created was saved under a default Excel sheet entitled . If we want to change the name of the created sheet, we can use option of :
Now that we have created the object, we can save multiple DataFrames to multiple sheets in the Excel file:
Now our Excel file has two sheets with copies of the grades data from our Pandas dataframe.
Caution: When the object is executed, any existing file with the same name as the output file will be overwritten. Even if the function writes to an unused sheet name, the file will still be overwritten in its entirety. The class has a option that is intended to allow for appending to an existing Excel file, however this option has not been implemented on the native engine as of the writing of this tutorial.
Немного про пиксели и цветовые пространства
Перед тем как перейти к практике, нам нужно разобраться немного с теорией. Каждое изображение состоит из набора пикселей. Пиксель — это строительный блок изображения. Если представить изображение в виде сетки, то каждый квадрат в сетке содержит один пиксель, где точке с координатой ( 0, 0 ) соответствует верхний левый угол изображения. К примеру, представим, что у нас есть изображение с разрешением 400×300 пикселей. Это означает, что наша сетка состоит из 400 строк и 300 столбцов. В совокупности в нашем изображении есть 400*300 = 120000 пикселей.
В большинстве изображений пиксели представлены двумя способами: в оттенках серого и в цветовом пространстве RGB. В изображениях в оттенках серого каждый пиксель имеет значение между 0 и 255, где 0 соответствует чёрному, а 255 соответствует белому. А значения между 0 и 255 принимают различные оттенки серого, где значения ближе к 0 более тёмные, а значения ближе к 255 более светлые:
Цветные пиксели обычно представлены в цветовом пространстве RGB(red, green, blue — красный, зелёный, синий), где одно значение для красной компоненты, одно для зелёной и одно для синей. Каждая из трёх компонент представлена целым числом в диапазоне от 0 до 255 включительно, которое указывает как «много» цвета содержится. Исходя из того, что каждая компонента представлена в диапазоне , то для того, чтобы представить насыщенность каждого цвета, нам будет достаточно 8-битного целого беззнакового числа. Затем мы объединяем значения всех трёх компонент в кортеж вида (красный, зеленый, синий). К примеру, чтобы получить белый цвет, каждая из компонент должна равняться 255: (255, 255, 255). Тогда, чтобы получить чёрный цвет, каждая из компонент должна быть равной 0: (0, 0, 0). Ниже приведены распространённые цвета, представленные в виде RGB кортежей:
Openpyxl Charts
The library supports creation of various charts, including
bar charts, line charts, area charts, bubble charts, scatter charts, and pie charts.
According to the documentation, supports chart creation within
a worksheet only. Charts in existing workbooks will be lost.
create_bar_chart.py
#!/usr/bin/env python
from openpyxl import Workbook
from openpyxl.chart import (
Reference,
Series,
BarChart
)
book = Workbook()
sheet = book.active
rows =
for row in rows:
sheet.append(row)
data = Reference(sheet, min_col=2, min_row=1, max_col=2, max_row=6)
categs = Reference(sheet, min_col=1, min_row=1, max_row=6)
chart = BarChart()
chart.add_data(data=data)
chart.set_categories(categs)
chart.legend = None
chart.y_axis.majorGridlines = None
chart.varyColors = True
chart.title = "Olympic Gold medals in London"
sheet.add_chart(chart, "A8")
book.save("bar_chart.xlsx")
In the example, we create a bar chart to show the number of Olympic
gold medals per country in London 2012.
from openpyxl.chart import (
Reference,
Series,
BarChart
)
The module has tools to work with charts.
book = Workbook() sheet = book.active
A new workbook is created.
rows =
for row in rows:
sheet.append(row)
We create some data and add it to the cells of the active sheet.
data = Reference(sheet, min_col=2, min_row=1, max_col=2, max_row=6)
With the class, we refer to the rows in the sheet that
represent data. In our case, these are the numbers of olympic gold medals.
categs = Reference(sheet, min_col=1, min_row=1, max_row=6)
We create a category axis. A category axis is an axis with the data
treated as a sequence of non-numerical text labels. In our case, we have
text labels representing names of countries.
chart = BarChart() chart.add_data(data=data) chart.set_categories(categs)
We create a bar chart and set it data and categories.
chart.legend = None chart.y_axis.majorGridlines = None
Using and attributes, we
turn off the legends and major grid lines.
chart.varyColors = True
Setting to , each bar has a different
colour.
chart.title = "Olympic Gold medals in London"
A title is set for the chart.
sheet.add_chart(chart, "A8")
The created chart is added to the sheet with the method.
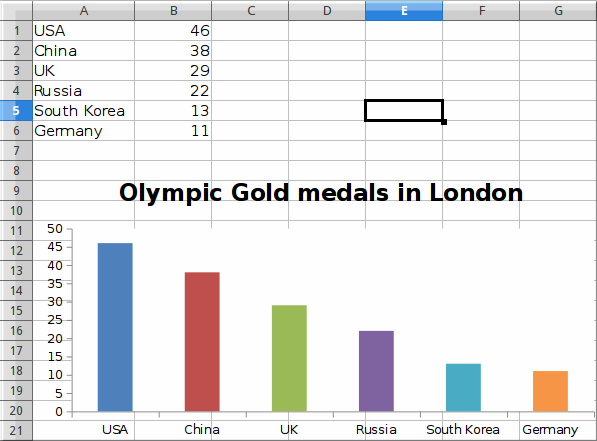 Figure: Bar chart
Figure: Bar chart
In this tutorial, we have worked with the openpyxl library. We have read data
from an Excel file, written data to an Excel file.
Visit Python tutorial or
list .
Formatting of the Dataframe output
XlsxWriter and Pandas provide very little support for formatting the output
data from a dataframe apart from default formatting such as the header and
index cells and any cells that contain dates or datetimes. In addition it
isn’t possible to format any cells that already have a default format applied.
If you require very controlled formatting of the dataframe output then you
would probably be better off using Xlsxwriter directly with raw data taken
from Pandas. However, some formatting options are available.
For example it is possible to set the default date and datetime formats via
the Pandas interface:
writer = pd.ExcelWriter("pandas_datetime.xlsx",
engine='xlsxwriter',
datetime_format='mmm d yyyy hh:mm:ss',
date_format='mmmm dd yyyy')
Which would give:
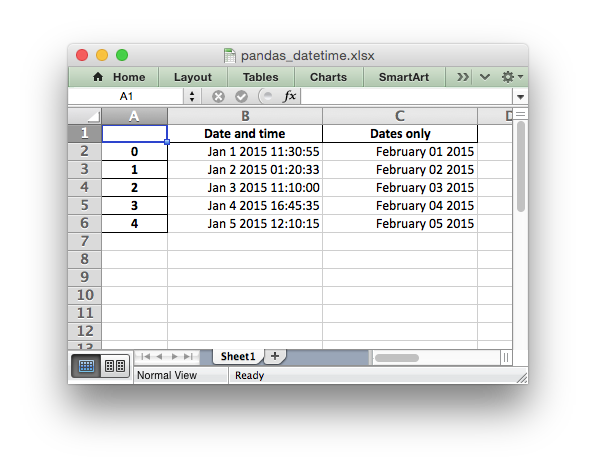
See the full example at .
It is possible to format any other, non date/datetime column data using
:
# Add some cell formats.
format1 = workbook.add_format({'num_format' '#,##0.00'})
format2 = workbook.add_format({'num_format' '0%'})
# Set the column width and format.
worksheet.set_column('B:B', 18, format1)
# Set the format but not the column width.
worksheet.set_column('C:C', None, format2)
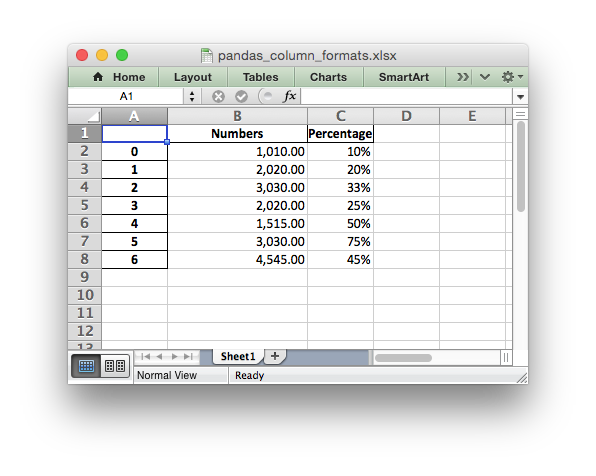
Note: This feature requires Pandas >= 0.16.
Набор на курс Python: почему мы думаем, что Python 2.7. — это серьезно, а Python 3 — модно
Пару дней назад мы открыли набор на один из самых долгожданных курсов — курс серьезного изучения Python. Сегодня мы хотели рассказать вам о направленности и программе курса. Курс предназначен для тех, кто уже знает всякое про Python, но хочет повысить свой навык до уровня middle разработчика и найти уже работу, которая будет приносить не только удовольствие, но и хороший доход (ведь лучшим по результатам обучения студентам наши партнеры — крупнейшие IT компании предложат пройти собеседования). Мы не ждем на курсе новичков: поэтому наличие некоего beginner уровня проверяется вступительным тестом — там всего пара десятков вопросов. Если большинство из вопросов теста вызывают длительный ступор — лучше задуматься над тем, чтобы немного подтянуть свои знания по Python самостоятельно, ведь во время курса может не быть возможности останавливаться на basic вещах.
Доступ к пикселям и манипулирование ими
Для того, чтобы узнать высоту, ширину и количество каналов у изображения можно использовать атрибут shape:
Важно помнить, что у изображений в оттенках серого img.shape будет недоступно, так как данные изображения представлены в виде 2D массива. Чтобы получить доступ к значению пикселя, нам просто нужно указать координаты x и y пикселя, который нас интересует
Также важно помнить, что библиотека OpenCV хранит каналы формата RGB в обратном порядке, в то время как мы думаем в терминах красного, зеленого и синего, то OpenCV хранит их в порядке синего, зеленого и красного цветов:
Чтобы получить доступ к значению пикселя, нам просто нужно указать координаты x и y пикселя, который нас интересует
Также важно помнить, что библиотека OpenCV хранит каналы формата RGB в обратном порядке, в то время как мы думаем в терминах красного, зеленого и синего, то OpenCV хранит их в порядке синего, зеленого и красного цветов:. Cначала мы берём пиксель, который расположен в точке (0,0)
Данный пиксель, да и любой другой пиксель, представлены в виде кортежа. Заметьте, что название переменных расположены в порядке b, g и r. В следующей строке выводим значение каждого канала на экран. Как можно увидеть, доступ к значениям пикселей довольно прост, также просто можно и манипулировать значениями пикселей:
Cначала мы берём пиксель, который расположен в точке (0,0). Данный пиксель, да и любой другой пиксель, представлены в виде кортежа. Заметьте, что название переменных расположены в порядке b, g и r. В следующей строке выводим значение каждого канала на экран. Как можно увидеть, доступ к значениям пикселей довольно прост, также просто можно и манипулировать значениями пикселей:
В первой строке мы устанавливаем значение пикселя (0, 0) равным (255, 0, 0), затем мы снова берём значение данного пикселя и выводим его на экран, в результате мне на консоль вывелось следующее:
Accessing XlsxWriter from Pandas
In order to apply XlsxWriter features such as Charts, Conditional Formatting
and Column Formatting to the Pandas output we need to access the underlying
and objects. After
that we can treat them as normal XlsxWriter objects.
Continuing on from the above example we do that as follows:
import pandas as pd # Create a Pandas dataframe from the data. df = pd.DataFrame({'Data' 10, 20, 30, 20, 15, 30, 45]}) # Create a Pandas Excel writer using XlsxWriter as the engine. writer = pd.ExcelWriter('pandas_simple.xlsx', engine='xlsxwriter') # Convert the dataframe to an XlsxWriter Excel object. df.to_excel(writer, sheet_name='Sheet1') # Get the xlsxwriter objects from the dataframe writer object. workbook = writer.book worksheet = writer.sheets'Sheet1'
This is equivalent to the following code when using XlsxWriter on its own:
workbook = xlsxwriter.Workbook('filename.xlsx')
worksheet = workbook.add_worksheet()
Модификаторы регулярных выражений: флаги опций
Литералы регулярных выражений могут включать необязательный модификатор для управления различными аспектами сопоставления. Модификаторы указываются в качестве необязательного флага. Вы можете предоставить несколько модификаторов, используя исключающее ИЛИ (|), как показано ранее, и может быть представлено одним из них —
| Sr.No. | Модификатор и описание |
|---|---|
| 1 |
re.I Выполняет сопоставление без учета регистра. |
| 2 |
re.L Интерпретирует слова в соответствии с текущей локалью. Эта интерпретация влияет на буквенную группу (\ w и \ W), а также на поведение границ слов (\ b и \ B). |
| 3 |
re.M Делает $ совпадает с концом строки (а не только с концом строки) и заставляет ^ соответствовать началу любой строки (а не только началу строки). |
| 4 |
re.S Делает точку (точку) совпадением с любым символом, включая символ новой строки. |
| 5 |
re.U Интерпретирует буквы в соответствии с набором символов Unicode. Этот флаг влияет на поведение \ w, \ W, \ b, \ B. |
| 6 |
re.X Разрешает «симпатичный» синтаксис регулярного выражения. Он игнорирует пробелы (за исключением внутри set [] или когда экранируется обратной косой чертой) и обрабатывает неэкранированный # как маркер комментария. |
Openpyxl iterate by columns
The method return cells from the
worksheet as columns.
iterating_by_columns.py
#!/usr/bin/env python
from openpyxl import Workbook
book = Workbook()
sheet = book.active
rows = (
(88, 46, 57),
(89, 38, 12),
(23, 59, 78),
(56, 21, 98),
(24, 18, 43),
(34, 15, 67)
)
for row in rows:
sheet.append(row)
for row in sheet.iter_cols(min_row=1, min_col=1, max_row=6, max_col=3):
for cell in row:
print(cell.value, end=" ")
print()
book.save('iterbycols.xlsx')
The example iterates over data column by column.
$ ./iterating_by_columns.py 88 89 23 56 24 34 46 38 59 21 18 15 57 12 78 98 43 67
This is the output of the example.
Шаблон регулярного выражения
Строка шаблона, используя специальный синтаксис для обозначения регулярное выражение:
Буквы и цифры сами. Регулярное выражение при букв и цифр совпадают ту же строку.
Большинство из букв и цифр будет иметь различное значение, когда ему предшествует обратный слэш.
Пунктуация спасшемся только тогда, когда сам матч, или они представляют собой особый смысл.
Сам Backslash должен использовать побег символ обратной косой.
Поскольку регулярные выражения обычно содержат символы, так что вам лучше использовать исходную строку, чтобы представлять их. Элементы схемы (например, г ‘/ т’, что эквивалентно ‘// Т’) совпадает с соответствующим специальные символы.
В следующей таблице перечислены синтаксис регулярных выражений шаблон конкретных элементов. Если ваши модели использования, обеспечивая при этом необязательные флаги аргумент, значение некоторых элементов рисунка будет меняться.
| режим | описание |
|---|---|
| ^ | Соответствует началу строки |
| $ | Соответствует концу строки. |
| , | Соответствует любому символу, кроме символа новой строки, если указан флаг re.DOTALL, вы можете соответствовать любому символу, включая символ новой строки. |
| Он используется для представления группы символов, перечисленных отдельно: матч ‘а’, ‘т’ или ‘K’ | |
| Не [] символов: соответствует в дополнение к а, Ь, с символами. | |
| Re * | 0 или более выражениям. |
| Re + | Один или более совпадающих выражений. |
| повторно? | Матч 0 или 1 по предшествующих регулярных выражений для определения сегментов, не жадный путь |
| Re {п} | |
| повторно {п,} | Точное соответствие п предыдущего выражения. |
| Re {п, т} | Матч п в т раз по предшествующих регулярных выражений для определения сегментов, жадный путь |
| а | б | Совпадение или б |
| (Re) | Выражение матч G в скобках, также представляет собой группу |
| (? Imx) | Регулярное выражение состоит из трех дополнительных флагов: я, м, или х. Она влияет только на область в скобках. |
| (? -imx) | Регулярные выражения Закрыть я, м, или х необязательный флаг. Она влияет только на область в скобках. |
| (?: Re) | Аналогично (…), но не представляет собой группу, |
| (Imx 😕 Re) | Я использую в круглые скобки, м или х необязательный флаг |
| (-imx 😕 Re) | Не используйте I, M в круглых скобках, или х дополнительный флаг |
| (? # …) | Примечание. |
| (? = Re) | Форвард уверен разделитель. Если содержится регулярное выражение, представленное здесь …, успешно матчи в текущем местоположении, и не иначе. Тем не менее, как только содержала выражение была опробована, согласующий двигатель не продвигается, остальная часть узора даже попробовать разделителем правильно. |
| (?! Re) | Нападающий отрицанием разделителем. И, конечно, противоречит разделителем, успешным, когда содержащийся выражение не совпадает с текущей позиции в строке |
| (?> Re) | Независимый поиск по шаблону, устраняя откаты. |
| \ W | матч буквенно-цифровой |
| \ W | Матч не алфавитно-цифровой |
| \ S | Соответствует любой символ пробела, что эквивалентно . |
| \ S | Соответствует любой непустой символ |
| \ D | Соответствует любому количеству, которое эквивалентно . |
| \ D | Соответствует любому нечисловая |
| \ A | Соответствует началу строки |
| \ Z | Матч конец строки, если она существует символ новой строки, только до конца строки, чтобы соответствовать новой строки. с |
| \ Z | конец строки Match |
| \ G | Матч Матч завершен последнюю позицию. |
| \ B | Матчи границы слова, то есть, оно относится к месту и пробелы между словами. Например, ‘эр \ Ъ’ не может сравниться с «никогда» в «эр», но не может сравниться с «глаголом» в «эр». |
| \ B | Матч граница слова. ‘Er \ B’ может соответствовать «глагол» в «эр», но не может сравниться с «никогда» в «эр». |
| \ N, \ т, и тому подобное. | Соответствует новой строки. Соответствует символу табуляции. подождите |
| \ 1 … \ 9 | Соответствующие подвыражения п-го пакета. |
| \ 10 | Матч первые п пакетов подвыражению, если он после матча. В противном случае, выражение относится к восьмеричный код. |
В пользу Python (и других внешних языков программирования)
- Приятный синтаксис и синтаксический сахар. Если коротко, то VBA не отличается выразительностью и удобством. Это вопрос личного вкуса, но для меня Python намного удобнее.
- Богатая экосистема библиотек. Огромный выбор готовых библиотек для работы с внешним миром. Пытаться сделать на VBA программу, взаимодействующую с каким-нибудь внешним API, та еще боль. Занимательно, что как раз для работы с файлами Office библиотеки того же Python — откровенно «на троечку».
- Хорошие средства разработки. Можно выбрать из огромного выбор программ, которые облегчают процесс разработки. Стандартный редактор VBA из Office предлагает очень бедный функционал и, в сравнении с альтернативами из мира Python, откровенно неудобен. Писать код VBA в внешнем редакторе, а потом копировать внутрь офиса для отладки — тоже неудобно.
- Скорость работы. Не проверял скорость однопоточной работы, но, предположу, что в случае однопоточной работы преимущество будет за Python. В любом случае, достаточно тривиально организуется многопоточная обработка данных/файлов, что позволяет говорить в большей достижимой скорости.
Запуск проекта Otus.ru
Друзья!
Сервис Otus.ru — это инструмент для трудоустройства. Мы используем образовательные методики для отбора лучших специалистов для задач бизнеса. Мы собрали и типизировали вакансии крупных игроков ИТ-бизнеса, создали на базе полученных требований курсы. Мы заключили соглашения с этими компаниями о том, что лучшие наши студенты пройдут собеседование на релевантные позиции. Мы соединяем, как мы надеемся, лучших работодателей с самыми замотивированными специалистами.
Сейчас мы делаем пилот, запускаем первый курс по Java. На подходе еще четыре курса, в планах — около 40
Но на этом этапе нам важно протестировать нашу образовательную технологию, сделать так, чтобы наш продукт был качественным
Handling multiple Pandas Dataframes
It is possible to write more than one dataframe to a worksheet or to several
worksheets. For example to write multiple dataframes to multiple worksheets:
# Write each dataframe to a different worksheet. df1.to_excel(writer, sheet_name='Sheet1') df2.to_excel(writer, sheet_name='Sheet2') df3.to_excel(writer, sheet_name='Sheet3')
See the full example at .
It is also possible to position multiple dataframes within the same
worksheet:
# Position the dataframes in the worksheet.
df1.to_excel(writer, sheet_name='Sheet1') # Default position, cell A1.
df2.to_excel(writer, sheet_name='Sheet1', startcol=3)
df3.to_excel(writer, sheet_name='Sheet1', startrow=6)
# Write the dataframe without the header and index.
df4.to_excel(writer, sheet_name='Sheet1',
startrow=7, startcol=4, header=False, index=False)
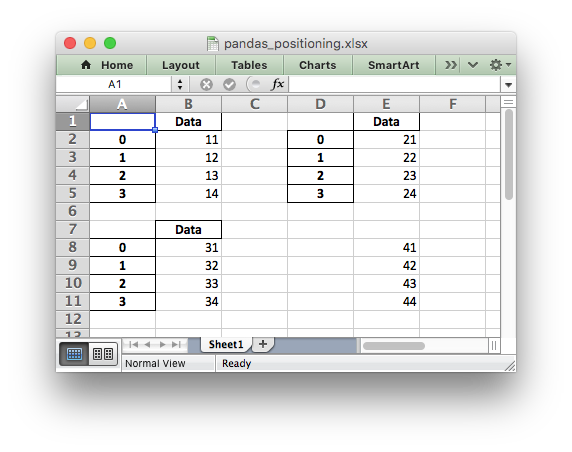
Данные как ваша отправная точка
Когда вы начинаете проект по data science, вам придется работать с данными, которые вы собрали по всему интернету, и с наборами данных, которые вы загрузили из других мест — Kaggle, Quandl и тд
Но чаще всего вы также найдете данные в Google или в репозиториях, которые используются другими пользователями. Эти данные могут быть в файле Excel или сохранены в файл с расширением .csv … Возможности могут иногда казаться бесконечными, но когда у вас есть данные, в первую очередь вы должны убедиться, что они качественные.
В случае с электронной таблицей вы можете не только проверить, могут ли эти данные ответить на вопрос исследования, который вы имеете в виду, но также и можете ли вы доверять данным, которые хранятся в электронной таблице.
Проверяем качество таблицы
- Представляет ли электронная таблица статические данные?
- Смешивает ли она данные, расчеты и отчетность?
- Являются ли данные в вашей электронной таблице полными и последовательными?
- Имеет ли ваша таблица систематизированную структуру рабочего листа?
- Проверяли ли вы действительные формулы в электронной таблице?
Этот список вопросов поможет убедиться, что ваша таблица не грешит против лучших практик, принятых в отрасли. Конечно, этот список не исчерпывающий, но позволит провести базовую проверку таблицы.
Лучшие практики для данных электронных таблиц
Прежде чем приступить к чтению вашей электронной таблицы на Python, вы также должны подумать о том, чтобы настроить свой файл в соответствии с некоторыми основными принципами, такими как:
- Первая строка таблицы обычно зарезервирована для заголовка, а первый столбец используется для идентификации единицы выборки;
- Избегайте имен, значений или полей с пробелами. В противном случае каждое слово будет интерпретироваться как отдельная переменная, что приведет к ошибкам, связанным с количеством элементов на строку в вашем наборе данных. По возможности, используйте:
- подчеркивания,
- тире,
- горбатый регистр, где первая буква каждого слова пишется с большой буквы
- объединяющие слова
- Короткие имена предпочтительнее длинных имен;
- старайтесь не использовать имена, которые содержат символы ?, $,%, ^, &, *, (,), -, #,? ,,, <,>, /, |, \, , {, и };
- Удалите все комментарии, которые вы сделали в вашем файле, чтобы избежать добавления в ваш файл лишних столбцов или NA;
- Убедитесь, что все пропущенные значения в вашем наборе данных обозначены как NA.
Затем, после того, как вы внесли необходимые изменения или тщательно изучили свои данные, убедитесь, что вы сохранили внесенные изменения. Сделав это, вы можете вернуться к данным позже, чтобы отредактировать их, добавить дополнительные данные или изменить их, сохранив формулы, которые вы, возможно, использовали для расчета данных и т.д.
Если вы работаете с Microsoft Excel, вы можете сохранить файл в разных форматах: помимо расширения по умолчанию .xls или .xlsx, вы можете перейти на вкладку «Файл», нажать «Сохранить как» и выбрать одно из расширений, которые указаны в качестве параметров «Сохранить как тип». Наиболее часто используемые расширения для сохранения наборов данных в data science — это .csv и .txt (в виде текстового файла с разделителями табуляции). В зависимости от выбранного варианта сохранения поля вашего набора данных разделяются вкладками или запятыми, которые образуют символы-разделители полей вашего набора данных.
Теперь, когда вы проверили и сохранили ваши данные, вы можете начать с подготовки вашего рабочего окружения.
Запись в файл Excel с python
Будем хранить информацию, которую нужно записать в файл Excel, в . А с помощью встроенной функции ее можно будет записать в Excel.
Сначала импортируем модуль . Потом используем словарь для заполнения :
Копировать
Ключи в словаре — это названия колонок. А значения станут строками с информацией.
Теперь можно использовать функцию для записи содержимого в файл. Единственный аргумент — это путь к файлу:
Копировать
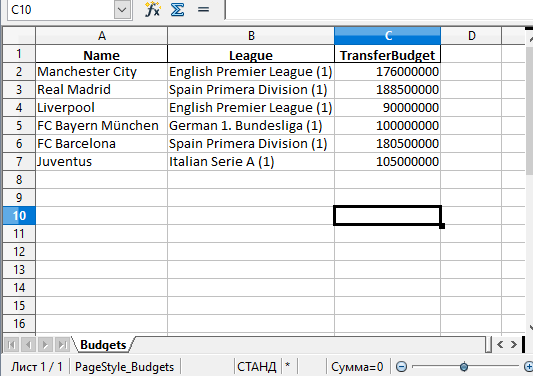
А вот и созданный файл Excel:
Стоит обратить внимание на то, что в этом примере не использовались параметры. Таким образом название листа в файле останется по умолчанию — «Sheet1»
В файле может быть и дополнительная колонка с числами. Эти числа представляют собой индексы, которые взяты напрямую из DataFrame.
Поменять название листа можно, добавив параметр в вызов :
Копировать
Также можно добавили параметр со значением , чтобы избавиться от колонки с индексами. Теперь файл Excel будет выглядеть следующим образом:
Чтение и запись файлов в Python
В Python файлы можно читать или записывать информацию в них с помощью соответствующих режимов.
Функция read()
Функция используется для чтения содержимого файла после открытия его в режиме чтения ().
Синтаксис
Где,
- = объект файла
- = количество символов, которые нужно прочитать. Если не указать, то файл прочитается целиком.
Пример
Интерпретатор прочитал 7 символов файла и если снова использовать функцию , то чтение начнется с 8-го символа.
Функция readline()
Функция используется для построчного чтения содержимого файла. Она используется для крупных файлов. С ее помощью можно получать доступ к любой строке в любой момент.
Пример
Создадим файл с нескольким строками:
Посмотрим, как функция работает в .
Обратите внимание, как в последнем случае строки отделены друг от друга
Функция write()
Функция используется для записи в файлы Python, открытые в режиме записи.
Если пытаться открыть файл, которого не существует, в этом режиме, тогда будет создан новый.
Синтаксис
Пример
Предположим, файла не существует. Он будет создан при попытке открыть его в режиме чтения.
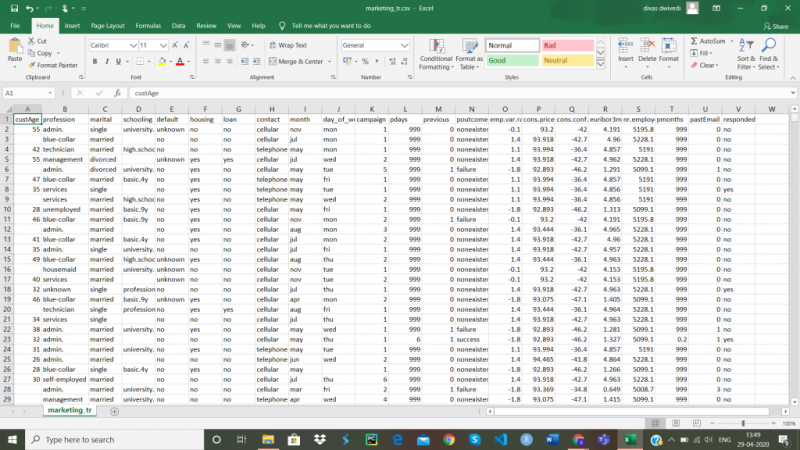
Использование Python и Excel для обработки и анализа данных. Часть 1: импорт данных и настройка среды
Если Вы только начинаете свой путь знакомства с возможностями Python, ваши познания еще имеют начальный уровень — этот материал для Вас. В статье мы опишем, как можно извлекать информацию из данных, представленных в Excel файлах, работать с ними используя базовый функционал библиотек. В первой части статьи мы расскажем про установку необходимых библиотек и настройку среды. Во второй части — предоставим обзор библиотек, которые могут быть использованы для загрузки и записи таблиц в файлы с помощью Python и расскажем как работать с такими библиотеками как pandas, openpyxl, xlrd, xlutils, pyexcel.