Парсинг и анализ семантики для seo: 5 бесплатных шаблонов google sheets
Содержание:
- Советы и рекомендации по использованию программ для парсинга
- Как собирать ключевые слова
- Перечень функций:
- Составление масок для парсинга
- Как работают парсеры поисковых запросов
- Парсеры Вордстат: какой выбрать?
- Маски для B2B-рынка
- SUBSTITUTE — меняем/удаляем пробелы и спецсимволы
- Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
- Программы парсеры
- Поисковые подсказки.
- Определение перспективных ключевых фраз
- Продвинутая семантика для статьи
- Определение «скрытых» данных на уровне ключевых слов
- P. S. Помните о сезонности
- Чек-лист по выбору парсера
- Плюсы и минусы работы с Кей Коллектором
- Десктопные и облачные парсеры
- Что умеет парсер Wordstat?
Советы и рекомендации по использованию программ для парсинга
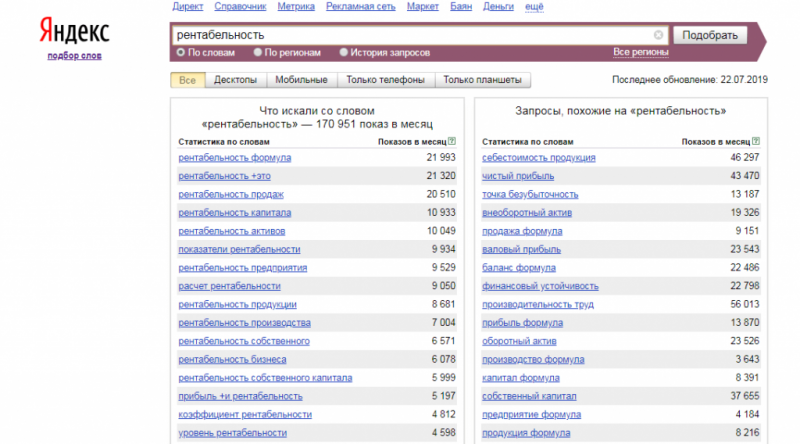
Специалисты советуют сочетать ручной и автоматический выбор запросов для составления семантического ядра, особенно для новичков. Пользуясь штатным инструментом Яндекс Вордстат Ассистент, вы нарабатываете навыки интуитивного подбора поисковых фраз, которые приводят на сайт целевых клиентов с помощью средне- и низкочастотных ключей. Высокочастотные фразы не всегда работают, особенно в конкурентной нише.
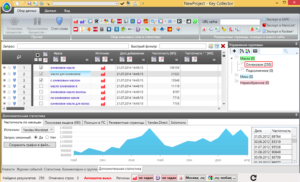
Если у вас нет времени на ручной парсинг в Яндекс Вордстат, используйте специальные инструменты. В интернете можно найти различное программное обеспечение, но большинство русскоязычных специалистов по SEO-оптимизации делают парсинг выдачи Яндекса с помощью Key Collector.
Это десктопный продукт, позволяющий создавать и хранить в локальной памяти компьютера проекты для каждого сайта, загружать и сохранять файлы и делать парсинг ключевых слов в соответствии с региональными настройками. Программа требует привязки к аккаунту. Для работы с ключевыми поисковыми запросами в Кей Коллекторе имеются пиктограммы основных поисковых систем в Рунете (в нашем случае это Yandex-парсер, хотя можно выбрать Google, Bing и другие).
Среди других полезных сервисов для SEO такие:
- Serpstat – многофункциональная платформа для профессионалов, имеющая триальную версию с ограниченным функционалом, а также платную подписку от 19 до 299$ в месяц;
- Ahrefs – веб-сервис с множеством полезных опций, включая мониторинг ниши, анализ конкурентов и улучшение индексации сайта. Для сбора семантического ядра предусмотрен инструмент Keywords Explorer. Протестировать его можно от 7$ в неделю;
- Semrush — аналог Ahrefs по части функционала, более дорогой по тарифам (от 99$ и выше).
Специалисты утверждают, что Кей Коллектор – это самая удобная и функциональная программа, позволяющая значительно облегчить жизнь оптимизатора. У нее есть множество полезных опций для точной настройки параметров парсера Yandex (например, глубины поиска, избирательного поиска запросов по базовой частотности и т.п.).
Но у программы есть нюанс – она платная. Стоимость лицензии составляет 1800-1900 рублей по электронному и безналичному расчету соответственно.
Совет! Если по какой-то причине вы не хотите пользоваться этим продуктом, можете попробовать его бесплатный аналог «Словоёб». Подойдет и более простой вариант — Букварикс – бесплатный сервис для сбора ключевых слов и формирования семантического ядра.
Парсинг Яндекс Вордстат можно делать самостоятельно и с помощью специальных программ. Ручной сбор посредством инструмента Wordstat Assistant оправдывает себя в том случае, если ваша ниша имеет узкую направленность и мало конкурентов, а перечень поисковых запросов относительно невелик. При больших объемах работ рекомендуется пользоваться специальными программами для парсинга и аналитики.
Как собирать ключевые слова
Для Рунета основным источником ключевых слов является сервис Wordstat от ПС Яндекс.
Запросов от Google, как правило, получается гораздо меньше и поэтому они чаще используются на этапе сбора базовых запросов. Как результат, в подавляющем большинстве случаев парсят Вордстат и этого бывает вполне достаточно.
Если же у Вас какая-то узкая ниша и надо обеспечивать максимальную полноту, тогда можно подключать сервисы Google и/или базы запросов.
Процедура парсинга запросов в облачных сервисах проходит довольно просто. Например, для Rush-Analytics необходимо задавать следующие параметры:
- Настроить проект в сервисе.
- Установить региональность.
- Выбрать пункт «Собрать ключевые слова».
- Загрузить список Базовых Запросов.
- Загрузить список минус-слов, если они у Вас уже есть.
- Инициировать работу парсера по сбору ключевых фраз.
Более наглядно этот процесс можно увидеть в этом небольшом видеоролике.
У меня первый прогон обычно используется для формирования списка минус слов. Выгружаю полученный результат и методом пристального взора составляю список таких слов.
Второй прогон, с учетом собранных минусов, уже будет более результативным и список ключей будет содержать гораздо меньше мусорных запросов. Тем не менее мы опять просматриваем полученные ключи, чистим мусор, пополняем список минус-слов и у нас все готово для следующего шага — сбора подсказок.
Перечень функций:
| Light Edition | ||
|---|---|---|
| Автоматическое распознавание тела статьи на странице любого сайта, при условии, что на странице есть текстовый контент | ||
| Удобное редактирование и ручная проверка отпарсенного контента при помощи менеджера обработки контента | ||
| Возможность парсить контент без разметки (под генераторы дорвеев и т.п.) | ||
| Возможность парсить контент с сохранением исходной разметки (выделения, заголовки и т.п.), как с изображениями и возможностью их сохранения, так и без. | ||
| Возможность парсить статьи по списку ключевых слов | ||
| Возможность парсить статьи по списку ссылок | ||
| Возможность добавлять и парсить любые поисковые системы | ||
| Возможность парсить текст на любых языках, добавив поисковые систем с нужными языковыми настройками | ||
| Свободная настройка абсолютно любого формата вывода статей для дальнейшего экспорта контента с помощью любых приложений для постинга контента, например Zebroid, Textkit или напрямую в WordPress. | ||
| Парсер умеет автоматически определять капчи поисковых систем. Не зависимо от того какую ПС Вы добавите парсер самостоятельно определит ее и отправит ее на распознавание, например в сервис Rucaptcha или любой другой. | ||
| Возможность на стадии сбора контента фильтровать по собственным фильтрам как статьи так и отдельные абзыцы, а так же заменить или удалить любые включения как по точным условиям, так и с помощью регулярных выражений. | ||
Составление масок для парсинга
Начинаем подбор ключевых запросов с составления запросов для парсинга. Чаще всего это 2-словные, но иногда и 3-словные запросы, которые также называют «масками».
Эти запросы должны максимально коротко, но релевантно описывать ваши услуги или товары.
Предположим, вы предлагаете доставку еды. Подходящими для вас масками будут:
– доставка еды – еда на дом – еда в офис – заказать еду – доставка обедов и т. д.
В зависимости от ассортимента, вам также нужно охватить более точные запросы, например: доставка плова, заказать суши и т. д.
Вам интересны интернет-маркетинг и продвижение бизнеса в интернете? Подписывайтесь на наш Telegram-канал!
Как правильно составить маски запросов?
Не стоит пренебрегать данным этапом сбора семантического ядра (СЯ), так как от него зависит полнота СЯ, охват кампании, средняя цена за клик, количество и стоимость конверсий.
Неопытные специалисты часто используют только самые очевидные запросы. И хотя они охватывают большую часть целевой аудитории, по этим запросам самая высокая конкуренция и, как следствие, цена клика.
Чтобы собрать максимальное количество непересекающихся запросов, используйте:
- Брейншторминг. Просто подумайте, с помощью каких запросов ваша целевая аудитория может искать ваши товары или услуги.
- Правая колонка Yandex Wordstat. У Яндекса большой объем статистики, что и как ищут пользователи, и часто предлагает хорошие варианты ключевых фраз, до которых мы сами не додумались бы. Этот способ подходит и для сбора семантического ядра под Google;
- Блок «Вместе с этим ищут» на поиске Google и Яндекс. Работает по той же логике, что и правая колонка Wordstat — показывает, какие еще запросы вводят пользователи, которые ищут по определенному запросу.
- Сайты конкурентов. Просмотрите сайты ваших топ 5-10 конкурентов в Google и Яндекс. Подходящие нам ключевые запросы часто можно обнаружить в заголовках или в тексте на продвигаемых страницах.
- Названия конкурентов. В некоторых нишах, при правильном подходе, хорошие результаты показывает реклама на бренд конкурентов. Например, если вы занимаетесь доставкой пиццы, то в качестве ключевых фраз можете попробовать использовать « додо пицца» или «доминос».
- Ключевые слова конкурентов. Есть специальные сервисы конкурентного анализа, которые предлагают показать, какие запросы используют ваши конкуренты. Точность этих сервисов оставляет желать лучшего, но иногда помогают найти новые, релевантные запросы. Мы пользуемся keys.so, как недорогим и достаточно функциональным сервисом.
- Нестандартные формулировки, транслитерация, сленг. Иногда один и тот же бренд люди пишут по разному и, чтобы охватить их, нам нужно использовать все эти варианты в качестве ключевых слов. Например, вы продаете запчасти для автомобилей Hyundai. Чтобы охватить целевую аудиторию полностью, в вашем семантическом ядре должны использоваться слова: Хундай, Хендай, Хёндай, Хюндай, Хьюндай.

Блок «Вместе с этим ищут» в Яндексе

Правая колонка Яндекс Вордстат с рекомендациями ключевых слов
Как работают парсеры поисковых запросов
После того как вы собрали базу ключей и расширили ее с помощью Вордстат, можно воспользоваться платным сервисом, чтобы очистить значимые фразы и составить семантическое ядро. Рассмотрим, как это сделать, на примере Кей Коллектора
- Открываем «Файл» -> «Новый проект» и устанавливаем регион.
- Нажимаем «Пакетный сбор слов из левой колонки Yandex.Wordstat», копируем уже имеющийся список и нажимаем «Начать сбор».
Запросы с базовой частотностью (БЧ) ниже 5 являются мало запрашиваемыми и принесут мало трафика, поэтому их лучше удалить.
Чтобы автоматизировать этот процесс, перед началом сбора слов устанавливаем в настройках нижнюю границу БЧ, которая будет включена в конечный результат. 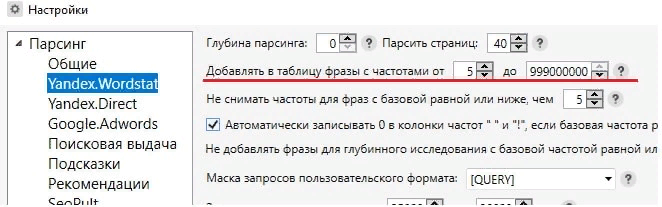
С помощью удобных программ и нехитрых действий вы сможете собрать базу ключей, даже если вы новичок.
Используете функцию парсинга ключевых запросов? Делитесь опытом в комментариях!
Парсеры Вордстат: какой выбрать?
Парсер — программа для автоматического сбора и обработка синтаксической информации во всемирной паутине. Самостоятельно анализировать ключевые слова запросы из Wordstat онлайн бывает сложно и неудобно. Первое правило любого специалиста — автоматизировать все, что можно и пользоваться готовым результатом. Для автоматического парсинга используются программы парсеры или сервис онлайн.
Главные выгоды автоматизации:
-
Снижение негативного влияния человеческого фактора. Выполнение рутинных действий сопряжено с ошибками, которые бывают даже у самых внимательных работников.
- Повышение эффективности. Хороший парсер обрабатывает огромное количество информации. Ни один человек не в состоянии самостоятельно выполнить подобную работу.
Автор статьи Дмитрий Интернет-маркетолог Полезная информация: в рунете встречаются разнообразные парсеры Wordstat онлайн. Пользоваться лучше проверенным программным обеспечением. Неизвестный софт с закрытым исходным кодом может работать некорректно, а то и вовсе собирать конфиденциальную информацию.
Ниже рассмотрены самые популярные парсеры Яндекс Вордстат. Рассмотрим известные программы и сервисы, а так же их плюсы и минусы.
Маски для B2B-рынка
Бизнесы более осознанно подходят к закупкам. Они ищут не просто бетон, а конкретную марку и условия для конкретной задачи.
При генерировании масок ключевых слов учитывайте 5 ключевых признаков продукта. Пример для производителя бетона:
- Свойства — ячеистый, тяжелый, мелкозернистый, монолитный, коррозионно-стойкий и т.д.;
- Марка — в10, в12, в15, в20, м100, м250 и т.д.;
- Применение — для фундамента, гаража, дорожек и т.д.;
- Условие — с доставкой, самовывоз, недорого, от производителя;
- Гео — в Перми, в Березниках и т.д.
Показы рекламы по прямым запросам дорогие. Как снизить их стоимость и при этом не упустить целевых клиентов?
Поможет смежная семантика. Если пользователя интересуют товары / услуги, которые нужны вместе с тем, что предлагаете вы, как правило, это ваш потенциальный клиент. Ваша задача — узнать, что это за товары / услуги.
Допустим, вы продаете бетон. Ваша аудитория скорее всего также ищет в интернете технику для его использования, услуги по укладке бетона и т.д.
SUBSTITUTE — меняем/удаляем пробелы и спецсимволы
Универсальная функция замены/удаления символов в ячейках.
Синтаксис:
Номер соответствия — порядковый номер встреченного значения на замену, например, первое встреченное заменить, остальные оставить. Опциональный параметр.
Пример. У нас есть выгрузка ключевых фраз из Яндекс.Вордстат. Многие ключи содержат плюсики. Нам нужно их удалить.
Формула будет иметь вид:
Что мы сделали:
- где искать — указали ячейку с данными;
- «что искать» — указали плюсик, который нужно удалить;
- «на что менять» — поскольку символ нужно удалить, мы указали кавычки без символов внутри; если бы нам нужна была замена, здесь бы мы прописали текст, на который нужно заменить плюсик;
- номер соответствия — здесь мы ничего не указали, и функция удалит все плюсы в фразе; если бы мы указали 1, то функция удаляла бы только первый плюсик, если 2 — второй и т. д.
Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
Создайте аккаунт в системе PromoPult (или авторизуйтесь, если у вас уже есть аккаунт). Откройте инструмент «Слова и объявления конкурентов». В блоке «Добавить задачу» укажите домены конкурентов или загрузите их с помощью XLSX-файла.
Блок профессиональных настроек пока не трогаем (мы еще разберем его).
В блоке «Поисковые системы» можно выбрать, в какой поисковой системе проверять домены. По умолчанию это Яндекс и Google. Также по умолчанию стоит галочка на пункте «Результаты на едином листе XLS» – в таблице с результатами данные по всем доменам будут сведены на одном листе.
Если вы проверяете небольшое количество доменов (до 5), можете ничего не менять здесь. Если же доменов больше, уберите галочку с этого пункта. В результатах парсинга под каждый домен будет создан отдельный лист – это удобнее для анализа большого количества данных.
Жмем «Запустить проверку». Система начнет парсинг доменов (в нашем случае на это ушло 5 минут). Если у вас нет времени ждать, вы можете закрыть страницу с инструментом – все работы проводятся в фоновом режиме.
После окончания проверки вам на почту придет уведомление:
Раскройте блок «Список задач» и кликните по пиктограмме Excel-таблицы, чтобы скачать отчет. Также здесь можно удалить отчет или запустить повторный парсинг.
В настройках парсинга есть возможность выбрать отображение отчета: отдельный лист для каждого домена или все на одном листе.
В зависимости от этой настройки отчет будет выглядеть по-разному.
Отчет по каждому домену на разных листах
В нашем примере мы получили именно такой отчет. При скачивании загружается архив с файлами в формате CSV:
Что содержит архив:
Файл с уникальными ключевиками для всех конкурентов. Для пяти доменов, которые мы добавляли в проверку, парсер собрал почти 32 000 ключей.
Общие результаты – данные по количеству объявлений на поиске Google и Яндекс. Для каждого домена данные указаны в разрезе регионов.
Технический файл, в котором указаны настройки парсинга.
Файлы с названиями доменов. Содержат ключевые слова конкурентов, заголовки и тексты объявлений. Данные указаны в разрезе поисковых систем и регионов. Например, вы можете посмотреть, какие объявления показывает конкурент в Яндексе в Санкт-Петербурге.
Обратите внимание! При парсинге объявления собираются из результатов поисковой выдачи в таком виде, в котором они отображаются. Кроме основного текста и заголовка могут собираться уточнения, быстрые ссылки и другие расширения (если они есть в объявлении)
Данные по доменам на одном листе
При таком способе отображения отчета загружается один XLSX-файл с четырьмя листами. Даже если вы парсите 50 доменов, листов в файле все равно будет четыре. Какие это листы:
«Результаты общие» – количество уникальных объявлений по всем доменам. Данные указаны в разрезе регионов и поисковых систем.
- «Слова и объявления». На этом листе собрана семантика по всем конкурентам и тексты объявлений. Данные указаны по каждому региону и поисковой системе. Если доменов много, работать с такой таблицей будет неудобно.
- «Слова». Собраны уникальные ключевики по всем доменам.
- «Исх. настройки». Указаны настройки парсинга.
Программы парсеры
Для точной обработки ключевых слов рекомендуется использовать программные комплексы. Преимущество – они работают напрямую с базами данных Ворстат. Полная версия платная, некоторые разработчики предоставляют демо-режим с ограниченным функционалом.
Кей Коллектор
Программа «Кей Коллектор» популярна среди разработчиков и СЕО-оптимизаторов. Причины – работа с популярными поисковыми системами, сегментация выборок по параметрам пользователя. Предоставляется только на платной основе, стоимость зависит от количества приобретаемых лицензий.
Особенности «Кей Коллектор»:
- Анализируется только актуальная статистика, сбор информации ведется напрямую из баз данных (БД) Яндекса.
- Ключевые слова подбираются по региону, частоте, сезонности.
- Учитываются стоп-слова.
Возможен многопоточный режим работы. Но есть вероятность получения бана или многократного ввода капчи при формировании нескольких потоков запроса информации с одного IP. Возможен сбор информации через Яндекс.Директ, что уменьшает скорость обработки.
Словоёб
Бесплатная альтернатива Кей Коллектор, но с меньшими функциональными возможностями. Отличие – «Словоёб» работает только с Вордстат. При анализе некоторых ключевых фраз могут не учитываться низкочастотные запросы, которые есть в статистике Яндекс.Директ. Глубина эффективного парсинга ограничена 40 страницами.
Особенности программы «Словоёб»:
- меньшие возможности работы с таблицами;
- нет «поисковых подсказок»;
- отсутствует сбор главных страниц выдачи;
- нет позиций по запросам.
Программа подходит для формирования СЯ небольшого проекта. Причина – скорость обработки полученных данных, нет углубленного анализа запросов.
Магадан
Технические ограничения в бесплатном варианте программы:
- нельзя выбрать региональность для запросов;
- отключены фильтры по количеству символов, слов;
- нет импорта файлов со стоп-словами;
- нельзя задавать правила к генерируемым ключевым фразам;
- отключен экспорт КС.
Несмотря на такие ограничения «Магадан» можно использовать для формирования СЯ 1-3 проектов. Но по отзывам пользователей по сравнению с ручной обработкой Вордстата теряются низкочастотные запросы.
Поисковые подсказки.
Что же такое, поисковые подсказки Яндекс и при чем здесь управление выдачей? Поисковые подсказки — это выпадающий список ключевых фраз, во время ввода запроса пользователем. Вообщем, я хотел сказать, что это список слов, которые предлагает Яндекс, когда вы вводите запрос в поиск. Вы же наверняка их видели.
Но как это связано с управлением выдачей? На самом деле, косвенно. Но все же связано. Да, и учтите, что я не имею ввиду общую выдачу Яндекс, я имею ввиду выдачу вашего сайта. То есть, если вы используете поиск по сайту от лидера Рунета, то когда пользователь находится на вашем сайте и начинает вводить свой запрос, появляются поисковые подсказки, которые смогут помочь юзеру найти то, что он хочет, потому что теперь мы можем их настроить, а значит и повлиять на выдачу результатов поиска по сайту. Что можно назвать управлением выдачей Яндекс.
Управление выдачей или поисковыми подсказками Яндекс.
Итак, давайте разберемся, как это работает и какая выгода нам от этого. Для начала установите поиск по сайту от Яндекс, если он еще не установлен. Если установлен, то вам необходимо совершить минимум действий, а именно: перейти в управление поиском, выбрать который хотите отредактировать и в меню, слева выбрать «поисковые подсказки».
Здесь мы можем выбрать показывать подсказки или нет. Выбрать язык. И конечно же добавить, удалить или переместить поисковые подсказки Яндекс. Для этого, необходимо начать вводить запрос, тем самым представить себя на месте пользователя. Например, хочет посетитель найти информацию по установке dle, но не все же станут полностью вводить запрос, ведь «лень» не позволит этого сделать. Вот для них и созданы подсказки, чтоб они могли выбрать, а не вводить запрос полностью. Итак, например, вводим просто dle и что мы видим? Поиск предлагает нам довольно странные варианты, ну если честно полную фигню, которая никак не связана с мои сайтом и тем более с установкой или настройкой dle.
Но теперь мы можем исправить это положение и просто удалить не нужное и добавить необходимое, а также менять местами запросы — какие-то ставить выше, какие-то ниже. И это удобно и действительно поисковые подсказки яндекс можeт повлиять на выдачу. Ведь если посетитель не станет вводить запрос дальше и не найдет подходящий вариант в выпавшем списке, он может просто уйти. А с помощью возможности управления, мы можем исправить положение и пользователь выберет из списка нужное ему словосочетание и останется на сайте, для прочтения статьи, что в свою очередь может повлиять на поведенческие факторы и соответственно на основную выдачу Яндекс.
А вот, что можно получить в результате, с помощью редактирования подсказок. И небольшая инструкция, по редактированию.
А чтобы менять запросы местами, достаточно зажать левую кнопку мыши и перетащить в нужное место. И не забудьте сохранить результаты.
Вот такие дела. Я надеюсь никто не расстроился, что не получиться управлять выдачей яндекс и передвинуть свой сайт в топ. Тогда, какой будет интерес? Вообщем всем удачи, у меня на этом все. Поисковые подсказки Яндекс, вам в помощь.
Определение перспективных ключевых фраз
Когда денег на SEO мало (в случае с МСБ это почти всегда так), продвигаться по ядру из тысяч запросов не получится. Придется выбирать самые «жирные» из них, а остальные откладывать до лучших времен.
Один из способов — выбрать фразы, по которым страницы сайта находятся с 5 по 20 позицию в Google. По ним можно быстрее и с меньшими затратами выйти в ТОП-5. Ну и скачок позиций, скажем, с двенадцатой на третью даст намного больше трафика, чем с 100-й на 12-ю (узнать точный прирост трафика вы можете с помощью сценарного прогноза в Data Studio).
Позиции по ключевым фразам в Google доступны в Search Console. Для их выгрузки есть шаблон, описанный в Codingisforlosers.
Для выгрузки ключей из ТОП-20 необходимо:
- создать копию шаблона Quick Wins Keyword Finder (все шаблоны в статье закрыты от редактирования, просьба не запрашивать права доступа — просто создайте копию и используйте ее);
- установить дополнение для Google Sheets Search Analytics for Sheets (для настройки экспорта отчетов из Search Console в Google Sheets);
- иметь доступ к аккаунту в Search Console и накопленную статистику по запросам (хотя бы за пару месяцев).
Открываем шаблон и настраиваем выгрузку данных из Search Console (меню «Дополнения» / «Search Analytics for Sheets» / «Open Sidebar»).
Для автоматической выгрузки на вкладке «Requests»:
- в поле «Verified Site» выбираем сайт (после подтверждения доступа к аккаунту в появится список сайтов);
- в поле «Group By» выбираем «Query» и «Page» (то есть мы будем извлекать данные по запросам и страницам);
- в поле «Results Sheet» обязательно задаем «RAW Data», иначе шаблон работать не будет.
Нажимаем кнопку «Request Data». После экспорт данных на листе «Quick Wins» указаны запросы, страницы, количество кликов, показов, средний CTR и позиция за период. Эти ключи подходят для приоритетного продвижения.
Помимо автоматической выгрузки в шаблоне есть ручной режим. Перейдите на вкладку «MANUAL» и введите данные (ключи, URL и позиции). На вкладке «Quick Wins » будет выборка перспективных запросов.
Продвинутая семантика для статьи
Нам понадобится SEO-программа «Key Collector». Это очень известная программа в кругах SEO-специалистов, и если вы планируете продвигаться в этой области, то однозначно стоит её приобрести. Также есть её урезанная бесплатная версия с неприличным названием «Словоёб», возможностей которой может хватить.
Key Collector умеет парсить ключевые слова со всех популярных источников ключей. Функционал программы поистине обширен, лучше изучить официальную справку на русском языке. Для написания информационной статьи нам понадобятся три функции: парсинг левой колонки Wordstat, парсинг похожих ключевых фраз и поиск конкурентов.
Итак, кликаем на значок «Пакетный сбор слов из левой колонки Yandex.Wordstat» и записываем одну или сразу несколько ключевых фраз, нажимаем «Начать сбор»:
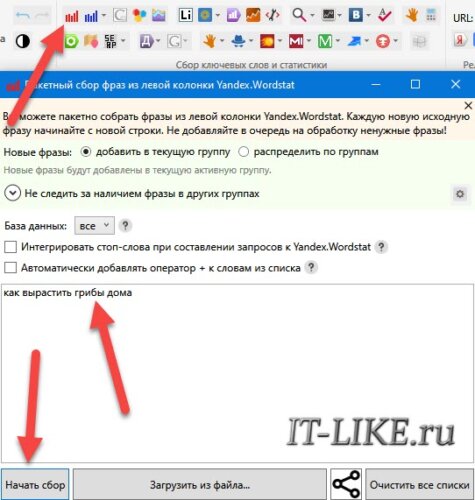
Программа вытащит из вордстата то же самое, что мы видели на сайте сервиса, но может сделать это сразу для нескольких фраз. Такое мы уже видели, более интересная функция заключается в парсинге подсказок поисковых систем. Это те варианты, которые предлагают поисковики, когда мы начинаем вводить запрос. В подсказках есть неочевидные ключи, это то что надо!
- Удаляем лишние и мусорные ключевики из напарсенной таблицы
- Выделяем и копируем несколько самых интересных фраз в буфер обмена
- Открываем инструмент «Пакетный сбор поисковых подсказок»
- Вставляем слова из буфера
- Убираем галочку «С подбором окончаний», оставляем системы Яндекс, Google, Mail, Yandex.Direct в режиме «SAFE»
- Жмём «Начать сбор»
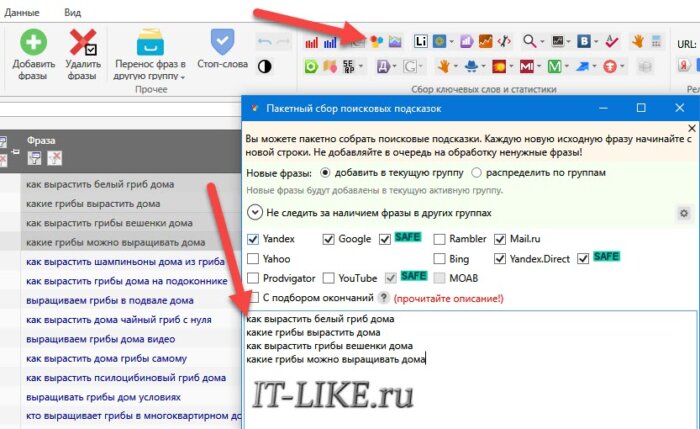
Процесс может занять довольно продолжительное время, поэтому, если долго ничего не происходит посмотрите, что пишет в «Журнале событий» (кнопка внизу окна Key Collector). В итоге, получится список из десятков, а скорее всего сотен ключевых слов, но их частотность нужно собирать отдельно. В примере с «грибами» засветились новые слова ‘зимой’, ‘в горшке’, ‘из спор’, ‘грибница’, ‘для бизнеса’ и другие. Будет много мусора, который придётся почистить руками.
При каждодневной работе у вас появится список СТОП-слов, строчки с которыми будут автоматически удалятся. Например, в СТОП-слова попадают все возможные названия городов страны. Также, большой преградой для СЕОшников становятся блокировки, баны и капчи Яндекса. Проблема решается подключением нескольких, или намного большего количества, прокси-серверов с разными IP-адресами в настройках Кей-коллектора.
Существуют бесплатные и платные прокси. Бесплатные нам не подходят, т.к. они банятся очень быстро, при этом работают медленно и нестабильно. Сайтов по продаже проксей очень много, поэтому лучше сразу открыть рейтинг прокси серверов https://top5proxy.com/ и выбрать кого-то из ТОПа. Вам нужны прокси типа IPv4, они дороже, но Wordstat не работает с IPv6.
Определение «скрытых» данных на уровне ключевых слов
В Google Analytics есть возможность подгрузить данные из Search Console. Но вы не увидите ничего нового — все те же страницы, CTR, позиции и показы. А было бы интересно посмотреть, какой процент отказов при переходе по тем или иным ключевым словам и, что еще интересней, сколько достигнуто целей по ним.
Тут поможет шаблон от Sarah Lively, который описан в статье для MOZ.
Для начала работы установите дополнения для Google Sheets:
- Google Analytics Spreadsheet Add-on;
- Search Analytics for Sheets (если вы использовали первые два шаблона, то это дополнение у вас уже есть).
Шаг 1. Настраиваем выгрузку данных из Google Analytics
Создайте новую таблицу, откройте меню «Дополнения» / «Google Analytics» и выберите пункт «Create new report».
Заполняем параметры отчета:
- Name — «Organic Landing Pages Last Year»;
- Account — выбираем аккаунт;
- Property — выбираем ресурс;
- View — выбираем представление.
Нажимаем «Create report». Появляется лист «Report Configuration». Вначале он выглядит так:
Но нам нужно, чтобы он выглядел так (параметры выгрузки вводим вручную):
Просто скопируйте и вставьте параметры отчетов (и удалите в поле Limit значение 1000):
| Report Name | Organic Landing Pages Last Year | Organic Landing Pages This Year |
| View ID | //здесь будет ваш ID в GA!!! | //здесь будет ваш ID в GA!!! |
| Start Date | 395daysAgo | 30daysAgo |
| End Date | 365daysAgo | yesterday |
| Metrics | ga:sessions, ga:bounces, ga:goalCompletionsAll | ga:sessions, ga:bounces, ga:goalCompletionsAll |
| Dimensions | ga:landingPagePath | ga:landingPagePath |
| Order | -ga:sessions | -ga:sessions |
| Filters | ||
| Segments | sessions::condition::ga:medium==organic | sessions::condition::ga:medium==organic |
После этого в меню «Дополнения» / «Google Analytics» нажмите «Run reports». Если все хорошо, вы увидите такое сообщение:
Также появится два новых листа с названиями отчетов.
Шаг 2. Выгрузка данных из Search Console
Работаем в том же файле. Переходим на новый лист и запускаем дополнение Search Analytics for Sheets.
Параметры выгрузки:
- Verified Site — указываем сайт;
- Date Range — задаем тот же период, что и в отчете «Organic Landing Pages This Year» (в нашем случае — последний месяц);
- Group By — «Query», «Page»;
- Aggregation Type — «By Page»;
- Results Sheet — выбираем текущий «Лист 1».
Выгружаем данные и переименовываем «Лист 1» на «Search Console Data». Получаем такую таблицу:
Для приведения данных в сопоставимый с Google Analytics вид меняем URL на относительные — удаляем название домена (через функцию замены меняем домен на пустой символ).
После изменения URL должны иметь такой вид:
Шаг 3. Сводим данные из Google Analytics и Search Console
Копируем шаблон Keyword Level Data. Открываем его и копируем лист «Keyword Data» в наш рабочий файл. В столбцы «Page URL #1» и «Page URL #2» вставляем относительные URL страниц, по которым хотим сравнить статистику.
По каждой странице подтягивается статистика из Google Analytics, а также 6 самых популярных ключей, по которым были переходы. Конечно, это не детальная статистика по каждому ключу, но все же это лучше, чем ничего.
При необходимости вы можете доработать шаблон — изменить показатели, количество выгружаемых ключей и т. п. Как это сделать, детально описано в оригинальной статье.
Как видите, для работы с ключами не обязательно сразу доставать кошелек. Есть немало простых решений. Следите за нашими публикациями — мы еще не раз поделимся полезностями.
P. S. Помните о сезонности
Вордстат – и, следовательно, парсер тоже – показывает статистику за последние 30 дней. Если запрос сезонный, можно сделать неправильные выводы, если смотреть только один месяц. Сезонные ключи нужно дополнительно проверять на wordstat.yandex.ru в разделе «История запросов»:
Зарегистрируйтесь в Click.ru сейчас и получите доступ к парсеру Wordstat, а также бесплатным инструментам по созданию и управлению контекстной рекламой – умному подборщику слов, генератору объявлений, медиапланеру, автобиддеру. По промокоду key вы в течение месяца сможете апробировать все возможности сервиса и получать максимальное вознаграждение 8 % вне зависимости от суммы расходов на контекстную рекламу.
Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
- Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
- Определите, какой объем данных и в каком виде нужно получать.
- Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
- Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
- Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
Плюсы и минусы работы с Кей Коллектором
Еще один вариант – сбор парсером KeyCollector (КК). Эта программа покупается один раз, причем по вполне сходной и доступной цене, а затем используем бесплатно.

При больших объемах КК очень сильно подгружает Ваш ПК, да и скорость сбора данных у него низкая. Поэтому мощность компьютера, на котором Вы хотите парсить большие объемы должна быть соответствующей.
Для настройки многих операций сбора КК может потребовать определенных умственных усилий и хлопот при подключение разных аккаунтов, прокси-серверов, работе с капчей и т.п.
Но без этого получить данные без ощутимых материальных затрат не получится.
Я использую KeyCollector при работе над СЯ в основном на этапе чистки собранных ключей от мусора, дублей и т.п..
Десктопные и облачные парсеры
Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
Например, вот англоязычные облачные парсеры:
- Import.io,
- Mozenda (доступна также десктопная версия парсера),
- Octoparce,
- ParseHub.
Из русскоязычных облачных парсеров можно привести такие:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
Популярные десктопные парсеры:
- ParserOK,
- Datacol,
- Screaming Frog, ComparseR, Netpeak Spider — об этих инструментах чуть позже поговорим подробнее.
Что умеет парсер Wordstat?
Возможности парсера:
- пакетная проверка частотностей;
- сбор частотностей по регионам;
- хранение отчетов в «облаке».
Также сервис позволяет учитывать тип соответствия запроса при парсинге (с применением операторов расширенного поиска).
Особенности и преимущества сервиса:
- нет ограничений по количеству фраз — за одну проверку можно спарсить частотности для нескольких тысяч или даже десятков тысяч запросов;
- сервис работает онлайн «в облаке» — не нужно скачивать и устанавливать программное обеспечение;
- быстрый и безопасный парсинг — не нужно обходить капчу или использовать прокси;
- отчет выгружается в формате XLSX.
- стоимость сервиса — в два-три раза ниже аналогов;
- первые 50 проверок — бесплатные.