Связный список
Содержание:
- Двусвязные (двунаправленные) списки
- Взаимообмен узлов списка
- Javascript создающий списки
- Недостатки
- Сортировка односвязного списка
- Линейный односвязный список
- Удаление повторяющихся значений
- Линейный односвязный список в языке Си
- 4 Вставка элемента в связный список
- Файл «List_Two.h»
- PHP код, реализующий работу сервера
- Подсписок списка
- HTML код
- Двусвязные списки
Двусвязные (двунаправленные) списки
В двусвязных списках (doubly linked list) к узлам добавляется ещё один указатель — на предыдущий узел. Это существенно повышает гибкость структуры данных по сравнению с односвязными списками.
Большинство функций реализующих двунаправленные списки аналогичны тем, что используются для реализации однонаправленных списков. Поэтому мы не будем их подробно рассматривать.
В узле двусвязного списка содержатся два указателя. Помимо указателя на следующий узел, есть указатель и на предыдущий. Это резко увеличивает функциональность двусвязного списка по сравнению с односвязным.
Во-первых следует заметить, что для создания методов двусвязного списка требуется немного больше усилий, та как теперь нужно менять два указателя в отличие от односвязных списков.
Как я уже написал выше, рассматривать методы двусвязных списков мы не будем. Классы необходимые для реализации двусвязных списков вы можете посмотреть здесь. Это заголовочный файл, поэтому достаточно добавить его к проекту и вы сможете пользоваться двусвязными списками.
Пожалуйста, внимательно изучите все классы представленные в файле. Именно на основе этой реализации списков в дальнейшем будут создаваться многие структуры данных. Я постарался как можно сильнее упростить код (в коде почти нет комментариев, и так всё понятно), надеюсь, получилось. Кроме того, обязательно выполните упражнения для двусвязных списков.
Единственное важное отличие данной реализации двусвязных списков, от реализации односвязных, которую мы рассматривали до сих пор — использование шаблонных классов. Если вы ещё не знаете что это такое, то перед рассмотрением кода двусвязных списков изучите шаблонные классы
Ещё один вид списков (частный случай двусвязного списка) — замкнутый или ещё встерачающееся название — кольцевой или закольцованный список. Это, кстати, наиболее полезный и часто встречающийся вариант связных списков. При этом у последнего элемента списка в поле next хранится head, а у первого элемента в поле previous — tail.
Заключение.
Ну, вот в общем-то, по спискам и всё. Несколько заключительных слов:
Сильная сторона списков заключается в том, что с их помощью можно без проблем добавлять и удалять элементы, что гораздо труднее делать с помощью массивов.
Также можно без проблем изменить размер списков, добавив/удавлив новые узлы.
У списков есть конечно же и слабые стороны. Получить доступ к какому-либо элементу не так просто. Необходимо пройти до этого элемента от начала списка, в то время как в массивах доступ к любому элементу можно получить с помощью индекса.
Кроме того, для хранения списков требуется больше памяти.
В списках удобно хранить объекты больших сложных классов. Если у вас множество мелких объектов, будет эффективнее сохнанить их в массиве. Кроме того, доступ к элементам списков происходит медленнее чем к элементам массива, так как узлы списков хранятся в разных участках памяти.
Мы ещё вернёмся к связным спискам когда будем рассматривать создание игрового ландшафта на основе клеток.
На сегодня всё.
Упражнения (односвязные списки):
1. Для односвязного списка реализуйте интерфейс взаимодействия с пользователем. Примерно как на картинке:
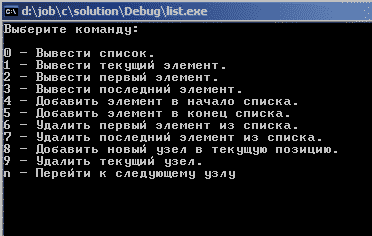
Пользователь вводит какую-нибудь команду, и программа должна корректно обработать эту команду.
Во время выполнения программы, загляните в отладчик и понаблюдайте значения переменных, хранящих список и итераторы.
Во время написания данной программы вы увидите все слабости данной реализации односвязных списков. Откровенно говоря, данная реализация написана довольно паршиво.
Упражнения (двусвязные списки):
1. Напишите два метода класса DListIterator: Start и End. Первый метод устанавливает итератор в начало списка, второй — в конец. Для реализации этих методов необходимо добавить в класс итераторов дополнительное поле — указатель на список.
2. Напишите программу аналогичную программе для связных списков. Набор команд выберите самостоятельно.
Взаимообмен узлов списка
Здесь тоже необходимо рассмотреть две ситуации:
- меняются соседние узлы
При этом узлы могут быть переданы в любом порядке относительно корня списка. Для упрощения реализации функции поменяем узлы так, чтобы node1 стоял перед node2 - меняются отстоящие узлы
1234567891011121314151617181920212223242526272829303132333435
void List::Swap(Node* node1, Node* node2){ if (node1 == NULL || node2 == NULL) return; // не допускаем обмен с несуществующим узлом if (node1 == node2) return; // если один узел указан дважды, менять ничего не надо if (node2->ptr == node1) // если node2 находится перед node1, меняем их местами { Node *p = node1; node1 = node2; node2 = p; } Node *prev1 = Prev(node1); Node *prev2 = Prev(node2); Node *next1 = Next(node1); Node *next2 = Next(node2); if (next1 == node2) // обмен соседних узлов { if (prev1 != NULL) prev1->ptr = node2; else head = node2; node2->ptr = node1; node1->ptr = next2; return; } if (prev1 != NULL) // обмен отстоящих узлов prev1->ptr = node2; else head = node2; if (prev2 != NULL) prev2->ptr = node1; else head = node1; node2->ptr = next1; node1->ptr = next2;}
Javascript создающий списки
Файл tsel.js, подключаемый в секции head содержит класс-функцию объекта, который запрашивает данные на сервере и создаёт в нашем документе связанные выпадающие списки.
Давайте рассмотрим его, не вникая в подробности реализации.
function TSEL(params) {
//счетчик ID контейнеров
this.SC = 0;
//инициализация
this.IDSobj = $(‘#’ + params.selectorID).get(0);
this.IDRobj = $(‘#’ + params.resultID).get(0);
this.url = params.ajaxUrl;
this.buildSelect = function(data) {
//эта функция создаёт HTML select tag
//и вставляет его в конец контейнера
//DIV#selector
//на входе — массив элементов списка
..
}
this.getBrunch = function(parentID) {
//тут мы асинхронно получаем массив опций
//по ID родительской ветки
//при получении данных — вызывается buildSelect
//так появляется очередной связанный список
..
}
this.buildResult = function(data) {
//формируем HTML код карточки вооружения
//в контейнере DIV#result
//выводим все поля объекта data
..
}
this.getResult = function(id) {
//получаем по ajax данные из таблицы items
//для описания единицы вооружения
//при получении данных вызываем buildResult
..
}
this.doChild = function (selectObj) {
//эта функция вызывается каждый раз при выборе
//элемента в списке
//здесь решается что делать :
//1. загрузить следующий уровень иерархии (getBrunch)
//2. или загрузить карточку вооружений (getResult)
..
}
//при инициализации мы грузим корень дерева
this.getBrunch(0);
}
|
1 |
functionTSEL(params){ //счетчик ID контейнеров this.SC=; //инициализация this.IDSobj=$(‘#’+params.selectorID).get(); this.IDRobj=$(‘#’+params.resultID).get(); this.url=params.ajaxUrl; this.buildSelect=function(data){ //эта функция создаёт HTML select tag //и вставляет его в конец контейнера //DIV#selector //на входе — массив элементов списка .. } this.getBrunch=function(parentID){ //тут мы асинхронно получаем массив опций //по ID родительской ветки //при получении данных — вызывается buildSelect //так появляется очередной связанный список .. } this.buildResult=function(data){ //формируем HTML код карточки вооружения //в контейнере DIV#result //выводим все поля объекта data .. } this.getResult=function(id){ //получаем по ajax данные из таблицы items //для описания единицы вооружения //при получении данных вызываем buildResult .. } this.doChild=function(selectObj){ //эта функция вызывается каждый раз при выборе //элемента в списке //здесь решается что делать : //1. загрузить следующий уровень иерархии (getBrunch) //2. или загрузить карточку вооружений (getResult) .. } //при инициализации мы грузим корень дерева this.getBrunch(); } |
Я не стал полностью приводить код, постарался описать его логику. Файлы примера, а также скрипт базы данных вы найдете в архиве в конце статьи.
Мы имеем дело всего с пятью функциями. Две из них грузят и показывают очередной уровень select-а, ещё две — делают тоже самое для карточки вооружений. А оставшаяся функция реализует логику : какую пару задействовать при выборе пункта списка.
Недостатки
Недостатки связных списков вытекают из их главного свойства — последовательного доступа к данным:
- сложность прямого доступа к элементу, а именно определения физического адреса по его индексу (порядковому номеру) в списке
- на поля-указатели (указатели на следующий и предыдущий элемент) расходуется дополнительная память (в массивах, например, указатели не нужны)
- некоторые операции со списками медленнее, чем с массивами, так как к произвольному элементу списка можно обратиться, только пройдя все предшествующие ему элементы
- соседние элементы списка могут быть распределены в памяти нелокально, что снизит эффективность кэширования данных в процессоре
- над связными списками, по сравнению с массивами, гораздо труднее (хоть и возможно) производить параллельные векторные операции, такие, как вычисление суммы: накладные расходы на перебор элементов снижают эффективность распараллеливания
Сортировка односвязного списка
Сортировать список будем слиянием. Этот метод очень похож на сортировку слиянием для массива. Для его реализации нам
понадобятся две функции: одна буде делить список пополам, а другая будет объединять два упорядоченных односвязных списка, не создавая при этом новых узлов.
Наша реализация не будет оптимальной, однако, некоторые решения, которые мы применим, могут быть использованы и в других алгоритмах.
Вспомогательная функция – слияние двух отсортированных списков. Функция не должна создавать новых узлов, так что будем использовать только имеющиеся. Для начала проверим, если хоть один из списков пуст, то вернём другой.
Node tmp;
*c = NULL;
if (a == NULL) {
*c = b;
return;
}
if (b == NULL) {
*c = a;
return;
}
После этого нужно, чтобы наша локальная переменная стала хранить адрес большего из узлов двух списков, от него и будем танцевать дальше
if (a->value < b->value) {
*c = a;
a = a->next;
} else {
*c = b;
b = b->next;
}
Теперь сохраним указатель c, так как в дальнейшем он будет использоваться для прохода по списку
tmp.next = *c;
После этого проходим по спискам, сравниваем значения и перекидываем их
while (a && b) {
if (a->value < b->value) {
(*c)->next = a;
a = a->next;
} else {
(*c)->next = b;
b = b->next;
}
(*c) = (*c)->next;
}
В конце, может остаться один список, который пройден не до конца. Добавим его узлы
if (a) {
while (a) {
(*c)->next = a;
(*c) = (*c)->next;
a = a->next;
}
}
if (b) {
while (b) {
(*c)->next = b;
(*c) = (*c)->next;
b = b->next;
}
}
Теперь указатель c хранит адрес последнего узла, а нам нужна ссылка на голову. Она как раз хранится во второй переменной tmp
*c = tmp.next;
Весь алгоритм
void merge(Node *a, Node *b, Node **c) {
Node tmp;
*c = NULL;
if (a == NULL) {
*c = b;
return;
}
if (b == NULL) {
*c = a;
return;
}
if (a->value < b->value) {
*c = a;
a = a->next;
} else {
*c = b;
b = b->next;
}
tmp.next = *c;
while (a && b) {
if (a->value < b->value) {
(*c)->next = a;
a = a->next;
} else {
(*c)->next = b;
b = b->next;
}
(*c) = (*c)->next;
}
if (a) {
while (a) {
(*c)->next = a;
(*c) = (*c)->next;
a = a->next;
}
}
if (b) {
while (b) {
(*c)->next = b;
(*c) = (*c)->next;
b = b->next;
}
}
*c = tmp.next;
}
Ещё одна важная функция – нахождение середины списка. Для этих целей будем использовать два указателя. Один из них — fast – за одну итерацию будет два раза изменять значение и продвигаться по списку вперёд. Второй – slow, всего один раз. Таким образом, если список чётный, то slow окажется ровно посредине списка, а если список нечётный, то второй подсписок будет на один элемент длиннее.
void split(Node *src, Node **low, Node **high) {
Node *fast = NULL;
Node *slow = NULL;
if (src == NULL || src->next == NULL) {
(*low) = src;
(*high) = NULL;
return;
}
slow = src;
fast = src->next;
while (fast != NULL) {
fast = fast->next;
if (fast != NULL) {
fast = fast->next;
slow = slow->next;
}
}
(*low) = src;
(*high) = slow->next;
slow->next = NULL;
}
Очевидно, что можно было один раз узнать длину списка, а потом передавать размер в каждую функцию. Это было бы проще и быстрее. Но мы не ищем лёгких путей)))
Теперь у нас есть функция, которая позволяет разделить список на две части и функция слияния отсортированных списков. С их помощью реализуем функцию сортировки слиянием.
Сортировка слиянием для односвязного списка
Функция рекурсивно вызывает сама себя, передавая части списка. Если в функцию пришёл список длинной менее двух элементов, то рекурсия прекращается. Идёт обратная сборка списка. Сначала из двух списков, каждый из которых хранит один элемент, создаётся отсортированный список, далее из таких списков собирается новый отсортированный список, пока все элементы не будут включены.
void mergeSort(Node **head) {
Node *low = NULL;
Node *high = NULL;
if ((*head == NULL) || ((*head)->next == NULL)) {
return;
}
split(*head, &low, &high);
mergeSort(&low);
mergeSort(&high);
merge(low, high, head);
}
Если Вы желаете изучать этот материал с преподавателем, советую обратиться к
репетитору по информатике
Q&A
Всё ещё не понятно? – пиши вопросы на ящик
Линейный односвязный список
Линейным односвязным списком называется организация данных, которые состоят из однотипных компонентов, имеющих последовательные связи друг с другом при помощи указателей. У каждого компонента из списка имеется указатель на последующий компонент. У конечного элемента списка указатель указывает на нуль. Начальным в списке расположен компонент, на который не ссылаются никакие указатели. А указатель каждого узла ведёт на соседний узел списка. Если список односвязный, то движение внутри списка возможно лишь в направлении окончания списка. Выяснить адрес компонента, расположенного ранее, по данным текущего узла, не представляется возможным. В дисциплине информатика под линейным списком понимается абстрактный вид информационных данных, который формализует термин упорядоченных данных в коллекции. Обычно, линейный список можно организовать в виде массива или связного списка. Бывают моменты, когда понятие списка в произвольной трактовке применяется в виде синонима связного списка. Например, абстрактный тип данных нетипичного, с возможностью изменения, списка определяется в виде набора из конструктора алгебраического типа данных и базовых процедур:
- Процедура, которая проверяет, что список не нулевой.
- Внесение объекта в список при помощи трёх операций (первым, последним или за любым N-м компонентом из списка.
- Процедура вычисления начального компонента списка.
- Процедура организации доступа к списку, который включает все компоненты начального списка, исключая первый.
Удаление повторяющихся значений
Данная функция должна применяться к уже отсортированному списку. В качестве параметра в неё передается головной узел списка, и если в ходе итерации текущий элемент оказывается равным следующему за ним, то текущий элемент удаляется.
Листинг 20. Си – удаление повторяющихся значений
void RemoveDuplicates(struct node* head)
{
struct node* current = head;
if (current == NULL) return;
while(current->next!=NULL)
{
if (current->data == current->next->data)
{
struct node* nextNext = current->next->next;
free(current->next);
current->next = nextNext;
}
else
{
current = current->next;
}
}
}
В версии на языке Python добавляется флаг, отмечающий наличие повторяющегося элемента. Этот флаг устанавливается при удалении повторяющегося элемента, и итерация прекращается, в противном случае итерация продолжается.
Листинг 21. Python – удаление повторяющихся значений
def RemoveDuplicates(self):
if (self.first == None):
return
old = curr = self.first
while curr != None:
_del = 0
if curr.next != None:
if curr.value == curr.next.value:
curr.next = curr.next.next
_del = 1
if _del == 0:
curr = curr.next
Линейный односвязный список в языке Си
использование односвязного списка:
Одной из модификаций связного списка считается список, который замкнут в кольцо. То есть представляет собой замкнутый цикл. По структуре он бывает односвязный или двусвязный. В конечном компоненте замкнутого списка содержится указание на начальный компонент, в котором, в свою очередь, при двусвязном списке может быть указатель на конечный компонент. Обычно, такое построение основывается на линейном списке, в котором не должно быть ссылок на нуль. Есть ещё списки в виде цикла, где выделяется головной элемент. Это значительно облегчает полное прохождение списка.
4 Вставка элемента в связный список
Чтобы добавить человека в такую очередь, нужно просто согласие двух соседних людей. Первый из них запоминает новичка как нового: «этот человек за мной», а второй — как нового «этот человек передо мной».
Всего-то и нужно изменить ссылки двух соседних объектов:
Мы добавили в наш список новый элемент и поменяли ссылки второго и третьего объектов. Теперь новичок, следующий за вторым и предыдущий для третьего. Ну и у самого объекта-новичка нужно прописать правильные ссылки: предыдущий объект — второй, следующий объект — третий.
Удаление еще проще. Если мы хотим удалить, допустим 100-й объект из списка, нужно просто у 99-го объекта поменять next, чтобы он указывал на 101-й объект, а у 101-го объекта поменять , чтобы он указывал на 99. И все.
Вот только получить 100-й объект не так просто.
Файл «List_Two.h»
/****************************************/
/* Двусвязный список */
/****************************************/
#ifndef _LIST_TWO_H_
#define _LIST_TWO_H_
/*Описание исключительных ситуаций*/
const int listTwoOk = 0; // Все впорядке
const int listTwoEmpty = 1; // Список пуст
const int listTwoNoMem = 2; // Недостаточно памяти
const int listTwoEnd = 3; // Указатель в конце
const int listTwoBegin = 4; // Указатель в начале
/**********************************/
/*Переменная ошибок*/
extern int listTwoError;
/*Базовый тип списка*/
typedef int listTwoBaseType;
/*Структура элемента списка*/
struct elementTwo {
listTwoBaseType data; // Данные
elementTwo *predLink; // Указатель на предыдущий элемент
elementTwo *nextLink; // Указатель на следующий элемент
};
/*Дескриптор списка*/
typedef struct {
elementTwo *Start; // Указатель на левый фиктивный элемент
elementTwo *End; // Указатель на правый фиктивный элемент
elementTwo *ptr; // Рабочий указатель
} ListTwo;
/*Функции работы со списком*/
void initListTwo(ListTwo *L); // Инициализация списка
void predPut(ListTwo *L, listTwoBaseType E); // Включение до рабочего указателя
void postPut(ListTwo *L, listTwoBaseType E); // Включение после рабочего указателя
void predGet(ListTwo *L, listTwoBaseType *E); // Исключение до рабочего указателя
void postGet(ListTwo *L, listTwoBaseType *E); // Исключение после рабочего указателя
void movePtrListTwoLeft(ListTwo *L); // Сдвиг рабочего указателя назад
void movePtrListTwoRight(ListTwo *L); // Сдвиг рабочего указателя вперед
void beginPtrListTwo(ListTwo *L); // Установить рабочий указатель в начало
void endPtrListTwo(ListTwo *L); // Установить рабочий указатель в конец
void doneListTwo(ListTwo *L); // Удаление списка
int isEmptyListTwo(ListTwo *L); // Предикат: пуст ли список
/***************************/
#endif
PHP код, реализующий работу сервера
В PHP у нас производится отработка команд клиента, запросы к базе данных. Запросов всего два:
- вернуть список опций ветки дерева, по указанному айди родителя (команда load-brunch),
- вернуть данные об единице вооружения (команда load-object).
<?php
//формируем заголовки документа — указываем, что кодировка UTF8
header(‘Content-Type: text/html; charset=utf-8’);
//если команда не задана — выходим сразу
if (empty($_POST)) exit;
//подключаю хелпер для работы с базой
//(там подключение к базе и пара функций)
require_once dirname(__FILE__) . ‘/db.php’;
//инициализация выходного массива данных
$data = array();
//обработка команд
switch ($_POST) {
case ‘load-brunch’:
//загрузка перечня опций
$pid = empty($_POST)? 0 : $_POST;
$res = db_query(«SELECT * FROM tree WHERE pID = :pid», array(‘:pid’ => $pid));
if ($res->num_rows)
while ($r = $res->fetch_object())
$data[] = $r;
break;
case ‘load-object’:
//загрузка карточки вооружения
$id = empty($_POST)? 0 : $_POST;
$res = db_query(«SELECT * FROM items WHERE IDobj = :id», array(‘:id’ => $id));
if ($res->num_rows)
$data = $res->fetch_object();
}
//вывод в JSON формате
echo json_encode($data, true);
|
1 |
<?php //формируем заголовки документа — указываем, что кодировка UTF8 header(‘Content-Type: text/html; charset=utf-8’); //если команда не задана — выходим сразу if(empty($_POST’commmand’))exit; //подключаю хелпер для работы с базой require_once dirname(__FILE__).’/db.php’; $data=array(); switch($_POST’commmand’){ case’load-brunch’ //загрузка перечня опций $pid=empty($_POST’parentID’)?$_POST’parentID’; $res=db_query(«SELECT * FROM tree WHERE pID = :pid»,array(‘:pid’=>$pid)); if($res->num_rows) while($r=$res->fetch_object()) $data=$r; break; case’load-object’ //загрузка карточки вооружения $id=empty($_POST’objectID’)?$_POST’objectID’; $res=db_query(«SELECT * FROM items WHERE IDobj = :id»,array(‘:id’=>$id)); if($res->num_rows) $data=$res->fetch_object(); } echo json_encode($data,true); |
Надеюсь, загрузка данных пояснений не требует. 🙂
Подсписок списка
Метод subList () может создавать новый List с подмножеством элементов из исходного List.
Метод subList () принимает 2 параметра: начальный индекс и конечный индекс. Начальный индекс — это индекс первого элемента из исходного списка для включения в подсписок.
Конечный индекс является последним индексом подсписка, но элемент в последнем индексе не включается в подсписок. Это похоже на то, как работает метод подстроки Java String.
List list = new ArrayList();
list.add("element 1");
list.add("element 2");
list.add("element 3");
list.add("element 4");
List sublist = list.subList(1, 3);
После выполнения list.subList (1,3) подсписок будет содержать элементы с индексами 1 и 2.
Преобразовать list в set
Вы можете преобразовать список Java в набор(set), создав новый набор и добавив в него все элементы из списка. Набор удалит все дубликаты.
Таким образом, результирующий набор будет содержать все элементы списка, но только один раз.
List list = new ArrayList();
list.add("element 1");
list.add("element 2");
list.add("element 3");
list.add("element 3");
Set set = new HashSet();
set.addAll(list);
Обратите внимание, что список содержит элемент String 3 два раза. Набор будет содержать эту строку только один раз
Таким образом, результирующий набор будет содержать строки: , and .
Общие списки
По умолчанию вы можете поместить любой объект в список, но Java позволяет ограничить типы объектов, которые вы можете вставить в список.
List<MyObject> list = new ArrayList<MyObject>();
Этот список теперь может содержать только экземпляры MyObject. Затем вы можете получить доступ к итерации его элементов без их приведения.
MyObject myObject = list.get(0);
for(MyObject anObject : list){
//do someting to anObject...
}
HTML код
Практически идентичен прошлому примеру.
Мы подключаем библиотеку jQuery и класс — TSEL, создающий связанные списки. TSEL работает с двумя HTML контейнерами, идентификаторы которых мы передадим при инициализации TSEL. Третьим параметром будет url к файлу сервера для обработки ajax запросов.
<!DOCTYPE html>
<html>
<head>
<meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″ />
<script type=»text/javascript» src=»https://ajax.googleapis.com/ajax/libs/jquery/1.12.4/jquery.min.js»></script>
<script type=»text/javascript» src=»tsel.js»></script>
</head>
<body>
<div id=»selector»>
<!— Здесь будут выпадающие списки —>
</div>
<div id=»result»>
<!— Здесь будет описание ед. вооружения —>
</div>
<script type=»text/javascript»>
//получаем экземпляр, управляющего списками класса
//попутно инициализируем его
$(function () {
var TS = new TSEL({
selectorID: «selector»,
resultID: «result»,
ajaxUrl: «/ajax.php»});
});
</script>
</body>
</html>
|
1 |
<!DOCTYPE html> <html> <head> <meta http-equiv=»Content-Type»content=»text/html; charset=utf-8″> <script type=»text/javascript»src=»https://ajax.googleapis.com/ajax/libs/jquery/1.12.4/jquery.min.js»></script> <script type=»text/javascript»src=»tsel.js»></script> <head> <body> <div id=»selector»> <!—Здесьбудутвыпадающиесписки—> <div> <div id=»result»> <!—Здесьбудетописаниеед.вооружения—> <div> <script type=»text/javascript»> //получаем экземпляр, управляющего списками класса $(function(){ varTS=newTSEL({ selectorID»selector», resultID»result», ajaxUrl»/ajax.php»}); }); </script> <body> <html> |
Двусвязные списки
Последнее обновление: 02.09.2016
Двусвязные списки также представляют последовательность связанных узлов, однако теперь каждый узел хранит ссылку на следующий и на предыдущий элементы.
Двунаправленность списка приходится учитывать при добавлении или удалении элемента,
так как кроме ссылки на следующий элемент надо устанавливать и ссылку на предыдущий. Но в то же время у нас появляется возможность обходить список как от первого к последнему
элементу, так и наоборот — от последнего к первому элементу. В остальном двусвязный список ни чем не будет отличаться от односвязного списка.
Для создания двусвязного списка вначале надо определить класс узла, который будет представлять элемент списка:
public class DoublyNode<T>
{
public DoublyNode(T data)
{
Data = data;
}
public T Data { get; set; }
public DoublyNode<T> Previous { get; set; }
public DoublyNode<T> Next { get; set; }
}
Далее определим сам класс списка:
using System.Collections.Generic;
using System.Collections;
namespace SimpleAlgorithmsApp
{
public class DoublyLinkedList<T> : IEnumerable<T> // двусвязный список
{
DoublyNode<T> head; // головной/первый элемент
DoublyNode<T> tail; // последний/хвостовой элемент
int count; // количество элементов в списке
// добавление элемента
public void Add(T data)
{
DoublyNode<T> node = new DoublyNode<T>(data);
if (head == null)
head = node;
else
{
tail.Next = node;
node.Previous = tail;
}
tail = node;
count++;
}
public void AddFirst(T data)
{
DoublyNode<T> node = new DoublyNode<T>(data);
DoublyNode<T> temp = head;
node.Next = temp;
head = node;
if (count == 0)
tail = head;
else
temp.Previous = node;
count++;
}
// удаление
public bool Remove(T data)
{
DoublyNode<T> current = head;
// поиск удаляемого узла
while (current != null)
{
if (current.Data.Equals(data))
{
break;
}
current = current.Next;
}
if(current!=null)
{
// если узел не последний
if(current.Next!=null)
{
current.Next.Previous = current.Previous;
}
else
{
// если последний, переустанавливаем tail
tail = current.Previous;
}
// если узел не первый
if(current.Previous!=null)
{
current.Previous.Next = current.Next;
}
else
{
// если первый, переустанавливаем head
head = current.Next;
}
count--;
return true;
}
return false;
}
public int Count { get { return count; } }
public bool IsEmpty { get { return count == 0; } }
public void Clear()
{
head = null;
tail = null;
count = 0;
}
public bool Contains(T data)
{
DoublyNode<T> current = head;
while (current != null)
{
if (current.Data.Equals(data))
return true;
current = current.Next;
}
return false;
}
IEnumerator IEnumerable.GetEnumerator()
{
return ((IEnumerable)this).GetEnumerator();
}
IEnumerator<T> IEnumerable<T>.GetEnumerator()
{
DoublyNode<T> current = head;
while (current != null)
{
yield return current.Data;
current = current.Next;
}
}
public IEnumerable<T> BackEnumerator()
{
DoublyNode<T> current = tail;
while (current != null)
{
yield return current.Data;
current = current.Previous;
}
}
}
}
По большому счету этот двусвязный список реализует те же действия, что и односвязный, разница заключается в необходимости установки свойства Previous для узлов списка.
В методе добавления , если в списке уже есть элементы, то у добавляемого узла свойство указывает на узел, который до этого
хранился в переменной tail:
if (head == null)
head = node;
else
{
tail.Next = node;
node.Previous = tail;
}
tail = node;
Аналогично в методе добавлении в начало списка для головного элемента свойство Previous начинает указывать на новый элемент, а новый
элемент, таким образом, становиться первым элементом в списке.
При удалении вначале необходимо найти удаляемый элемент. Затем в общем случае надо переустановить две ссылки:
current.Next.Previous = current.Previous; current.Previous.Next = current.Next;
Если удаляются первый и последний элемент, соответственно надо переустановить переменные head и tail.
И также в отличие от односвязной реализации здесь добавлен метод для перебора элементов с конца.
Применение списка:
DoublyLinkedList<string> linkedList = new DoublyLinkedList<string>();
// добавление элементов
linkedList.Add("Bob");
linkedList.Add("Bill");
linkedList.Add("Tom");
linkedList.AddFirst("Kate");
foreach (var item in linkedList)
{
Console.WriteLine(item);
}
// удаление
linkedList.Remove("Bill");
// перебор с последнего элемента
foreach (var t in linkedList.BackEnumerator())
{
Console.WriteLine(t);
}
НазадВперед